Java并发容器篇
作者:汤圆
个人博客:javalover.cc
前言
断断续续一个多月,也写了十几篇原创文章,感觉真的很不一样;
不能说技术有很大的进步,但是想法确实跟以前有所不同;
还没开始的时候,想着要学的东西太多,总觉得无从下手;
但是当你真正下定决心去做了几天后,就会发现 原来路真的是一步步走出来的;
如果总是原地踏步东张西望,对自己不会有帮助;
好了,下面开始今天的话题,并发容器篇
简介
前面我们介绍了同步容器,它的很大一个缺点就是在高并发下的环境下,性能差;
针对这个,于是就有了专门为高并发设计的并发容器类;
因为并发容器类都位于java.util.concurrent下,所以我们也习惯把并发容器简称为JUC容器;
相对应的还有JUC原子类、JUC锁、JUC工具类等等(这些后面再介绍)
今天就让我们简单来了解下JUC中并发容器的相关知识点
文章如果有问题,欢迎大家批评指正,在此谢过啦
目录
- 什么是并发容器
- 为什么会有并发容器
- 并发容器、同步容器、普通容器的区别
正文
1. 什么是并发容器
并发容器是针对高并发专门设计的一些类,用来替代性能较低的同步容器
常见的并发容器类如下所示:
这节我们主要以第一个ConcurrentHashMap为例子来介绍并发容器
其他的以后有空会单独开篇分析
2. 为什么会有并发容器
其实跟同步容器的出现的道理是一样的:
同步容器是为了让我们在编写多线程代码时,不用自己手动去同步加锁,为我们解放了双手,去做更多有意义的事情(有意义?双手?);
而并发容器则又是为了提高同步容器的性能,相当于同步容器的升级版;
这也是为什么Java一直在被人唱衰,却又一直没有衰退的原因(大佬们也很焦虑啊!!!);
不过话说回来,大佬们焦虑地有点过头了;不敢想Java现在都升到16级了,而我们始终还在8级徘徊。
3. 并发容器、同步容器、普通容器的区别
这里的普通容器,指的是没有同步和并发的容器类,比如HashMap
三个对比着来介绍,这样会更加清晰一点
下面我们分别以HashMap, HashTable, ConcurrentHashMap为例来介绍
性能分析
下面我们来分析下他们三个之间的性能区别:
注:这里普通容器用的是单线程来测试的,因为多线程不安全,所以我们就不考虑了
有的朋友可能会说,你这不公平啊,可是没办法呀,谁让她多线程不安全呢。
如果非要让我在安全和性能之间选一个的话,那我选 ConcurrentHashMap(我都要)
他们三个之间的关系,如下图
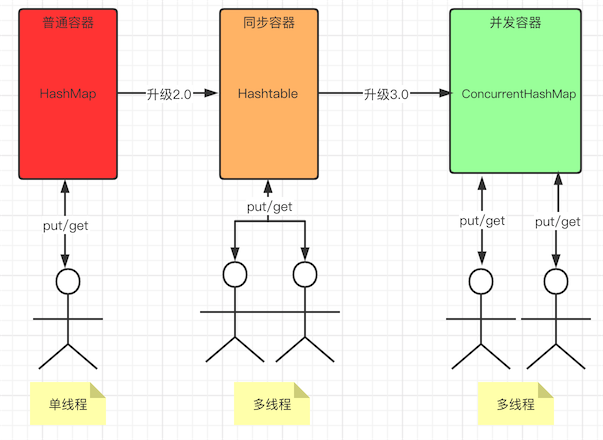
(红色表示堵的厉害,橙色表示堵的一般,绿色表示畅通)
可以看到:
-
在单线程中操作普通容器时,代码都是串行执行的,同一时刻只能put或get一个数据到容器中
-
在多线程中操作同步容器时,可以多个线程排队去执行,同一时刻也是只能put或get一个数据到同步容器中
-
在多线程中操作并发容器时,可以多个线程同时去执行,也就是说同一时刻可以有多个线程去put或get多个数据到并发容器中(可同时读读,可同时读写,可同时写写-有可能会阻塞,这里是以ConcurrentHashMap为参考)
下面我们用代码来复现下上面图中所示的效果(慢-中-快)
- HashMap 测试方法
public static void hashMapTest(){
Map<String, String> map = new HashMap<>();
long start = System.nanoTime();
// 创建10万条数据 单线程
for (int i = 0; i < 100_000; i++) {
// 用UUID作为key,保证key的唯一
map.put(UUID.randomUUID().toString(), String.valueOf(i));
map.get(UUID.randomUUID().toString());
}
long end = System.nanoTime();
System.out.println("hashMap耗时:");
System.out.println(end - start);
}
- HashTable 测试方法
public static void hashTableTest(){
Map<String, String> map = new Hashtable<>();
long start = System.nanoTime();
// 创建10个线程 - 多线程
for (int i = 0; i < 10; i++) {
new Thread(()->{
// 每个线程创建1万条数据
for (int j = 0; j < 10000; j++) {
// UUID保证key的唯一性
map.put(UUID.randomUUID().toString(), String.valueOf(j));
map.get(UUID.randomUUID().toString());
}
}).start();
}
// 这里是为了等待上面的线程执行结束,之所以判断>2,是因为在IDEA中除了main thread,还有一个monitor thread
while (Thread.activeCount()>2){
Thread.yield();
}
long end = System.nanoTime();
System.out.println("hashTable耗时:");
System.out.println(end - start);
}
- concurrentHashMap 测试方法
public static void concurrentHashMapTest(){
Map<String, String> map = new ConcurrentHashMap<>();
long start = System.nanoTime();
// 创建10个线程 - 多线程
for (int i = 0; i < 10; i++) {
new Thread(()->{
// 每个线程创建1万条数据
for (int j = 0; j < 10000; j++) {
// UUID作为key,保证唯一性
map.put(UUID.randomUUID().toString(), String.valueOf(j));
map.get(UUID.randomUUID().toString());
}
}).start();
}
// 这里是为了等待上面的线程执行结束,之所以判断>2,是因为在IDEA中除了main thread,还有一个monitor thread
while (Thread.activeCount()>2){
Thread.yield();
}
long end = System.nanoTime();
System.out.println("concurrentHashMap耗时:");
System.out.println(end - start);
}
- main 方法分别执行上面的三个测试
public static void main(String[] args) {
hashMapTest();
hashTableTest();
while (Thread.activeCount()>2){
Thread.yield();
}
concurrentHashMapTest();
}
运行可以看到,如下结果(运行多次,数值可能会变好,但是规律基本一致)
hashMap耗时:
754699874 (慢)
hashTable耗时:
609160132(中)
concurrentHashMap耗时:
261617133(快)
结论就是,正常情况下的速度:普通容器 < 同步容器 < 并发容器
但是也不那么绝对,因为这里插入的key都是唯一的,所以看起来正常一点
那如果我们不正常一点呢?比如极端到BT的那种
下面我们就不停地插入同一条数据,上面的所有put/get都改为下面的代码:
map.put("a", "a");
map.get("a");
运行后,你会发现,又是另外一个结论(大家感兴趣的可以敲出来试试)
不过结论不结论的,意义不是很大;
锁分析
普通容器没锁
同步容器中锁的都是方法级别,也就是说锁的是整个容器,我们先来看下HashTable的锁
public synchronized V put(K key, V value) {}
public synchronized V remove(Object key) {}
可以看到:因为锁是内置锁,锁住的是整个容器
所以我们在put的时候,其他线程都不能put/get
而我们在get的时候,其他线程也都不能put/get
所以同步容器的效率会比较低
并发容器,我们以1.7的ConcurrentHashMap为例来说下(之所以选1.7,是因为它里面涉及的内容都是前面章节介绍过的)
它的锁粒度很小,它不会给整个容器上锁,而是分段上锁;
分段的依据就是key.hash,根据不同的hash值映射到不同的段(默认16个段),然后插入数据时,根据这个hash值去给对应的段上锁,此时其他段还是可以被其他线程读写的;
所以这就是文章开头所说的,为啥ConcurrentHashMap会支持多个线程同时写(因为只要插入的key的hashCode不会映射到同一个段里,那就不会冲突,此时就可以同时写)
读因为没有上锁,所以当然也支持同时读
如果读操作没有锁,那么它怎么保证数据的一致性呢?
答案就是以前介绍过的volatile(保证可见性、禁止重排序),它修饰在节点Node和值val上,保证了你get的值永远是最新的
下面是ConcurrentHashMap部分源码,可以看到val和net节点都是volatile类型
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
总结下来就是:并发容器ConcurrentHashMap中,多个线程可同时读,多个线程可同时写,多个线程同时读和写
总结
- 什么是并发容器:并发容器是针对高并发专门设计的一些类,用来替代性能较低的同步容器
- 为什么会有并发容器:为了提高同步容器的性能
- 并发容器、同步容器、普通容器的区别:
- 性能:高 – 中 – 低
- 锁:粒度小 – 粒度大 – 无
- 场景:高并发 – 中并发 – 单线程
参考内容:
- 《Java并发编程实战》
- 《实战Java高并发》
- 《深入理解Java虚拟机》
后记
我这里介绍的都是比较浅的东西,其实并发容器的知识深入起来有很多;
但是因为这节是并发系列的比较靠前的,还有很多东西没涉及到,所以就分析地比较浅;
等到并发系列的内容都涉及地差不多了,再回过头来深入分析。
写在最后:
愿你的意中人亦是中意你之人。


