设计模式的使用——实现一个简单的缓存
- 2019 年 10 月 3 日
- 笔记
一、背景介绍
我们日常开发网站时,经常会用到下图这样的下拉框。其中下拉框里面的选项,不会经常变动。对于不会经常变动的数据,如果每次都从数据库读取,可能会影响网站的响应速度。所以通常会把这部分数据缓存起来,使用时直接从缓存读取。如果在项目中引入Redis这一类缓存框架,好像又不太划算,所以我们可以选择自己实现一个简单的缓存
这篇文章的目的不是具体的介绍设计模式,而是结合一个做缓存的案列,介绍设计模式的使用,加深对设计模式的理解。这里实现的缓存也可以应用于实际项目中。为了方便说明,我先用 Entity Framework 的 Code-First 建立三个实体类(我使用的是.Net的EF和AutoMapper,对于其他的开发工具,比如Java的Hibernate、ModelMapper,道理是一样的)。
public class Department { [Key] public int DepartmentId { get; set; } public string Name { get; set; } public virtual ICollection<Employee> Employees { get; set; } }
public class Employee { [Key] public int EmploeeId { get; set; } public string Name { get; set; } public virtual Department Department { get; set; } public virtual ICollection<AttendanceRecord> AttendanceRecords { get; set; }
}
public class AttendanceRecord { public int AttendanceRecordId { get; set; } public DateTime RecordTime { get; set; } public virtual Employee Employee { get; set; } }
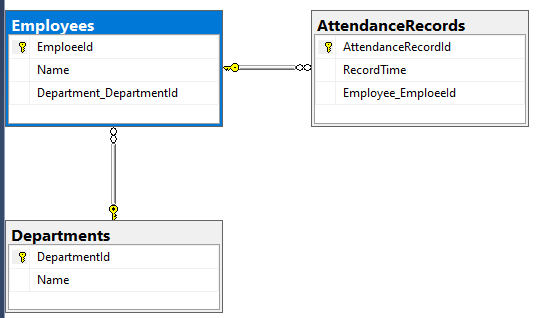
一个部门有多个雇员,一个雇员有多条考勤记录(然后在数据库中添加了一些数据)。
二、最简单的缓存——静态字段
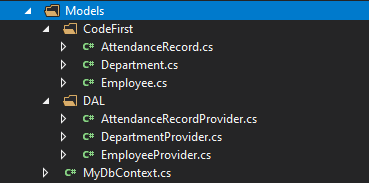
通常我们会为一个实体类建立一个数据访问类,在这个数据访问类里面管理这个实体类的CRUD。如下图所示,我建立了三个Provider类(后面用”Provider“代指数据访问类)。
现在我们需要缓存部门数据,最简单的方式,就是在 DepartmentProvider 里面增加一个静态字段。第一次读取数据后,把数据保存在这个静态字段里,后面的读取直接返回静态字段中的数据。
public class DepartmentProvider { private MyDbContext DbContext = new MyDbContext(); private static List<Department> departmentList; public List<Department> GetAll() { if (departmentList == null) { departmentList = DbContext.Departments.ToList(); } return departmentList; } public void Update(Department department) { var oldDepartment = DbContext.Set<Department>().Find(department.DepartmentId); if (oldDepartment != null) { DbContext.Entry(oldDepartment).CurrentValues.SetValues(department); DbContext.SaveChanges(); departmentList = null; } } }
这里我加了一个 departmentList 静态字段。并且当 Department 有更新时,我们把这个缓存清除掉,使得缓存的数据也能被更新。当然,更新缓存数据有两种方式。一是设置缓存过期时间,定期更新。二是数据库有更新时,也更新缓存。我这里选择的是第二种方式。
用这种方式缓存数据,会存在许多问题。比如每一个 Provider 单独管理自己的缓存,不方便维护代码,也不方便我们集中管理缓存(假设需要给管理员增加一键清空所有缓存的功能,我们就需要修改所有的 Provider)。所以我们需要改进代码,把所有的缓存集中在一个地方管理。
三、集中管理缓存——门面、策略、简单工厂模式
我们现在的想法是 Provider 类不直接管理缓存,而是把缓存集中在一个地方管理。在这里,我们可以把缓存看成是一个子系统。Provider 不需要知道缓存子系统是如何工作的,只需要能使用缓存这个功能就可以了。这种情况正好符合门面模式的使用场景——我们建立一个 CacheManager 类,Provider 只与 CacheManager 打交道。缓存的具体实现,交给 CacheManager 处理。下面开始修改代码,建立一个 CacheManager 类,在里面写管理缓存的代码。
public class CacheManager { private static ConcurrentDictionary<string, object> caches = new ConcurrentDictionary<string, object>(); public static void Set(string key, object o) { caches.AddOrUpdate(key, o, (k, v) => v); } public static void Remove(string key) { object output; caches.TryRemove(key, out output); } public static T Get<T>(string key) { object output; caches.TryGetValue(key, out output); if (output != null) return (T)output; return default(T); } }
这里我们使用 ConcurrentDictionary<string, object> 字典来保存数据(这个字典是线程安全的)。并且添加了相应的添加、删除和读取缓存的方法。这样每一个 Provider 就只需要保存自己的 key 就可以了,不再单独保管缓存。下面是对 Provider 的修改。
public class DepartmentProvider { private MyDbContext DbContext = new MyDbContext(); private static string cacheKey = "departmentList"; public List<Department> GetAll() { var departmentList = CacheManager.Get<List<Department>>(cacheKey); if (departmentList == null) { departmentList = DbContext.Departments.ToList(); CacheManager.Set(cacheKey, departmentList); } return departmentList; } public void Update(Department department) { var oldDepartment = DbContext.Set<Department>().Find(department.DepartmentId); if (oldDepartment != null) { DbContext.Entry(oldDepartment).CurrentValues.SetValues(department); DbContext.SaveChanges(); CacheManager.Remove(cacheKey); } } }
现在我们已经把 Provider 和缓存隔离开了,也可以集中在 CacheManager 里管理缓存了,避免了以后修改所有的 Provider。新的问题来了,假如以后要需要替换保存数据的方式,不使用 ConcurrentDictionary<string, object> 字典保存数据了。那是不是就需要在 CacheManager 里面找到所有使用 ConcurrentDictionary<string, object> 字典的地方,一个一个的修改(示例里面只有3个方法,好像改起来也不麻烦,但是不排除真实的项目中,CacheManager 在多处使用字典)?
那么当这种情况发生时,如何让我们用最小的代价修改代码呢? 仔细一想,对于 CacheManager 来说,只需要可以对数据进行CRUD就可以了。具体的数据是如何保存的,CacheManager 根本就不关心。那这就符合策略模式的使用场景了——将保存数据的具体方式封装起来,当 CacheManager 需要替换保存数据的方式时,替换一个用来保存数据的对象就可以了。
首先,我们需要对实现保存数据的对象抽象分析一下。分析的结果是,这个对象需要能够设置数据、读取数据、删除数据。所以我们写一个 ICache 接口,代码如下。
public interface ICache { void Set(string key, object o); void Remove(string key); object Get(string key); }
然后继续先使用 ConcurrentDictionary<string, object> 实现这个接口,下面是代码。
public class MemoryCache : ICache { private static ConcurrentDictionary<string, object> caches = new ConcurrentDictionary<string, object>(); public void Set(string key, object o) { caches.AddOrUpdate(key, o, (k, v) => v); } public void Remove(string key) { object output; caches.TryRemove(key, out output); } public object Get(string key) { object output; caches.TryGetValue(key, out output); return output; } }
现在来思考一下如何修改 CacheManager 的代码。因为替换保存数据的方式就是替换一个对象,也就是说我们需要根据参数来实例化不同的对象。这么一说是不是想到了另一个常见的设计模式——简单工厂模式。所以我们添加一个 CacheFactory 类(下面是示例代码,所以我只实现了一个类)。
public class CacheFactory { public static ICache GetDefaultCache(string cacheType) { switch (cacheType) { case "Memory": return new MemoryCache(); default: return new MemoryCache(); } } }
然后再来看对 CacheManager 的修改:
public class CacheManager { private static ICache cache = CacheFactory.GetDefaultCache("Memory"); public static void Set(string key, object o) { cache.Set(key, o); } public static void Remove(string key) { cache.Remove(key); } public static T Get<T>(string key) { object o = cache.Get(key); if (o != null) return (T)o; return default(T); } }
现在,如果我们想换一种保存数据的方式。只需要新建一个实现了 ICache 接口的类,然后在 CacheFactory 里面返回这个类的实例就可以了。
总结一下这一部分的内容。我们使用门面模式,分离了 Provider 与缓存的代码,将所有的缓存交给 CacheManager 管理。然后用 ICache 接口抽象了具体的保存数据的方式,使用策略模式和简单工厂模式,让 CacheManager 可扩展、易维护。现在我们启动项目看一下效果。第一次读取部门信息的时候,是从数据库读取的。之后再读信息,就从缓存中获取数据了。
到了这里,这个缓存还是不完善——数据过期的问题没有很好的解决。
四、互相关联的数据更新了怎么办——观察者、中介者模式处理缓存过期
在 DepartmentProvider 类里面,我们处理了 Department 缓存过期的问题——当Department 更新了,清空缓存,重新加载数据。假设现在有这么一条业务逻辑,根据一组Employee 的 Id,查找部门信息。具体的代码如下:
public List<Department> GetDepartmentByEmployeeIds(List<int> empIds) { var departmentList = CacheManager.Get<List<Department>>(cacheKey); if (departmentList == null) { departmentList = DbContext.Departments.Include(d => d.Employees) .ToList(); CacheManager.Set(cacheKey, departmentList); } return departmentList.Where(d => d.Employees.Any(e => empIds.Contains(e.EmploeeId))) .ToList(); }
第一次读取所有的 Department,并且立即加载 Employees 这个导航属性。 把读取的数据缓存起来,再从缓存数据中,根据传来的参数筛选结果。
我们需要根据 EmployeeId 筛选 Department,所以缓存了 Employees 这个导航属性。但是如果 Employee 表中的数据更新了怎么办? 我们这里缓存的数据不就不准确了! 所以我们需要有一种方式,监听 Employee 表的变化。当 Employee 有更新时,我们要清空 Department 的缓存数据。
第一反应想到的是,在 EmployeeProvider 里面加代码,发现 Employee 有更新时,清空 Department 的缓存数据。这样写虽然可以达到目的,但是我们这里是示例代码,代码又少又简单。如果一个真实的项目里面,有很多地方有这种关联的数据。想在Provider 里面处理缓存过期是非常困难的,也是特别容易出错的。我们需要一种方式写出易维护的代码。
分析这里的场景,EmployeeProvider的变化,需要通知 DepartmentProvider。 这不正好是观察者模式的使用场景吗? 另外,为了保持 Provider 的职责单一,我们不希望在 Provider 里面写响应其他 Provider 变化的代码。我们需要把这种对象间的相互影响交给一个中间者处理。这不就是中介者模式的使用场景吗?
下面是具体的代码实现。先添加一个 IMyObserver 接口,这个接口很简单(由于System命名空间里的IObserver接口,里面有我们不需要的东西,所以我自己定义了一个):
public interface IMyObserver { void Update(object subject); }
再添加一个 ProviderCacheObserver 实现这个接口,这个类既是一个观察者,也是一个中介者:
public class ProviderCacheObserver : IMyObserver { public void Update(object subject) { if (subject is EmployeeProvider) { // 因为不希望cacheKey被外部访问到 // 所以我们给 DepartmentProvider // 添加 RemoveCache 方法 DepartmentProvider.RemoveCache(); } } }
在 Update 里面,我们就可以单独处理 Provider 之间相互关联的关系了,不需要将处理关系的代码添加到 Provider 里面。现在再去 EmployeeProvider 里面,注册这个观察者。当 Employee 发生更新时,通知Observer,让Observer(同时是中介者)去处理关联的数据:
public class EmployeeProvider { private MyDbContext DbContext; private static string cacheKey = "employeeList"; public EmployeeProvider() { DbContext = new MyDbContext(); } private IMyObserver cacheObserver = new ProviderCacheObserver(); public void Update(Employee employee) { var oldEmployee = DbContext.Set<Employee>().Find(employee.EmploeeId); if (oldEmployee != null) { DbContext.Entry(oldEmployee).CurrentValues.SetValues(oldEmployee); DbContext.SaveChanges(); CacheManager.Remove(cacheKey); cacheObserver.Update(this); } } }
再把 DepartmentProvider 的 RemoveCache 方法贴出来:
public static void RemoveCache() { CacheManager.Remove(cacheKey); }
总结一下这一部分的内容。为了处理一张表的数据更新了,造成另一张表的缓存数据过期的问题。我们使用了观察者模式,观察 Provider 的变化,通知其他 Provider 做出响应。为了不在 Provider 里面到处写响应变化的代码,我们使用中介者模式,集中在中介者类(就是我们的Observer)里面处理Provider的关联关系。通过这些方式,我们得到了易维护、可扩展的代码。
这里我卖两个小关子。通过改变观察目标,还可以进一步的减少代码量。以及如何保证 key 是唯一的,如何处理不同的 Provider 添加缓存时,因为 key 值一样,造成其他 Provider 的缓存被覆盖掉的问题。知道答案的朋友在评论里面分享一下吧。下图是所有代码的目录结构(MapHelper 在下一节讲):
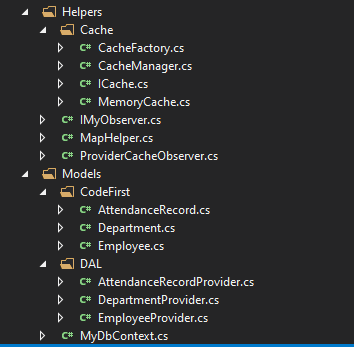
缓存的内容到这里就结束了。下面的小节,是为了解决由于 Entity Framework 的包装类、延迟加载、非跟踪查询,造成的 JSON 序列化时抛出的异常。
五、JSON序列化抛出了异常——使用深拷贝解决
我们在 Controller 里面向前台返回JSON数据:
public class HomeController : Controller { public JsonResult Index() { var data = new DepartmentProvider().GetAll(); return Json(data, JsonRequestBehavior.AllowGet); } }
打开浏览器,访问这个方法,发现抛出了下面的异常:
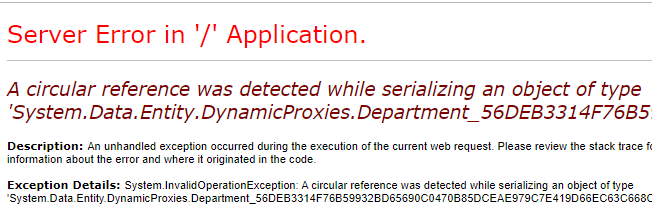
这是由于我们的 Department 和 Employee 互为导航属性,所以在 JSON 序列化时就产生了循环引用。我们确实是可以用 [JsonIgnore] 特性标签解决循环引用的问题。
我没有使用这种方式,是因为公司的项目有类似下面这种业务逻辑:查询所有的考勤记录;单条考勤记录下包含雇员作为导航属性;单条雇员下包含部门作为导航属性;然后把考勤记录用 JSON 传给前台。由于这里确实又需要把导航属性JSON 序列化,所以我没有使用 [JsonIgnore] 注解处理循环引用的问题。
另外我们看上面的异常信息,抛出异常的并不是我们自己的实体类,而是EF的包装类。如果我们用非跟踪查询的方式加载数据,JSON 序列化时会抛出和延迟加载有关的异常。具体信息我就不贴出来了。关闭延迟加载也不太好。
所以我的解决方式是,用EF加载出数据后。把数据做一次深拷贝,然后把拷贝的数据缓存起来。这样缓存的数据就不是EF的包装类了。同时可以通过配置 AutoMapper 的映射行为,解决循环引用的问题。
在用AutoMapper做映射的时候,也遇到了问题—— AutoMapper 把导航属性的导航属性也映射了,这个导航属性的导航属性依然是一个EF包装类。AutoMapper 可以自定义映射行为,查看文档后,找出了如下的配置方式。
1.自定义一个Profile,利用反射出来的类型信息,将指定类型不做映射:
public class NotMapGenericAndModelProfile<TSource, TDestination> : Profile { public NotMapGenericAndModelProfile() { CreateMap<TSource, TDestination>(); ShouldMapProperty = pr => pr.PropertyType.Namespace != "System.Collections.Generic" && pr.PropertyType.Namespace != "System.Linq" && pr.PropertyType.Namespace != "WebApplication1.Models.CodeFirst"; } }
一对多的导航属性肯定是泛型类,所以遇到泛型类型不做映射。一对一的导航属性,其导航属性一定是一个实体类,所以遇到实体类类型不做映射。
2.使用上面的 Profile 配置一个 Mapper,用自动映射做深拷贝:
public class MapHelper { public static List<TOuter> DeepCopy<TOuter, TInner>(List<TOuter> sourceData) { var mapper = new MapperConfiguration(cfg => { cfg.CreateMap<TOuter, TOuter>(); cfg.AddProfile(new NotMapGenericAndModelProfile<TInner, TInner>()); }).CreateMapper(); var desData = mapper.Map<List<TOuter>>(sourceData); return desData; } }
解释一下为什么要传两个泛型参数。我们希望在 JSON 序列化 Department 数据时,保留 Department 的导航属性 Employees,但是去除 Employee 的导航属性 AttendanceRecords和 Department(为了解决循环引用)。所以 TOuter 的实参是 Department,TInner 的实参是 Employee,这样就能映射 Department 的导航属性,并且去除 Employee 的导航属性。
3.读取数据后深拷贝,将拷贝后的数据做缓存:
public List<Department> GetAll() { var departmentList = CacheManager.Get<List<Department>>(cacheKey); if (departmentList == null) { departmentList = DbContext.Departments.Include(d => d.Employees) .ToList(); departmentList = MapHelper.DeepCopy<Department, Employee>(departmentList); CacheManager.Set(cacheKey, departmentList); } return departmentList; }
再次启动项目,查看结果: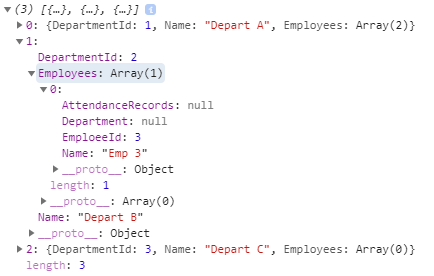
可以看到 Employee 的导航属性 Department 和 AttendanceRedords 都被去除了,只保留了我们想要的信息。
六、最后
上面就是我这次做缓存,遇到的问题以及解决方式。这让我对设计模式的感知加深了许多。以前看设计模式,总是觉得设计模式离日常工作很远,总是觉得设计模式之间是相互孤立的,总是觉得设计模式使用起来很僵化。
通过这次做缓存,现在看来,设计模式是一种分隔代码、组织代码的方式。通过这种方式分割、组织的代码,有良好的复用性、扩展性、可维护性。所以再去看没有使用过的设计模式,我关注的点就是组织代码的方式,而不是机械的死记硬背这个设计模式有哪些组成部分、有什么好处等。比如只要是动态的创建对象了,那就是简单工厂模式;把具体的实现细节封装起来,让调用者觉得调用的东西都是一样的,那就是策略模式。一个对象,通过第三方来影响另一个对象,这个第三方就是中介者,两个对象这间就是观察者和观察目标。
最后,非常感谢RDT项目组的亮哥教我如何考虑问题、如何具体的使用设计模式把代码写好。
