java集合
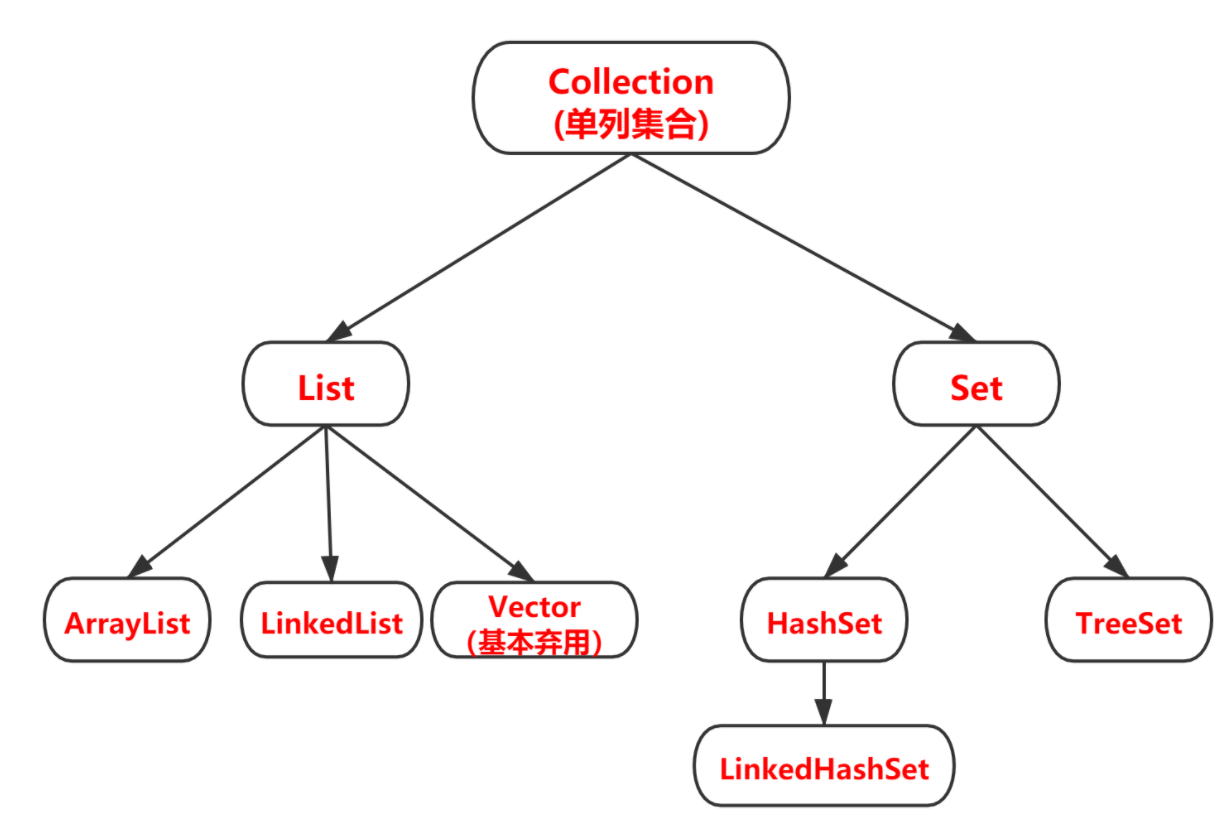
- ArrayList的底层数据结构:数组。
- LinkedList的底层数据结构:链表。既实现了
List接口,又实现了Queue接口,在使用的时候,如果我们把它当作List,就获取List的引用,如果我们把它当作Queue,就获取Queue的引用 - TreeSet,TreeMap的底层数据结构:红黑树。
- HashSet的底层数据结构:哈希表(数组+链表+红黑树)。当链表长度超过阈值(8)时,将链表转换为红黑树
- HashMap的底层数据结构: 位桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树
List接口
- 元素有序
- 有索引
- 元素可以重复
ArrayList
- ArrayList的底层就是数组。数组查询快,故ArrayList常用来查询数据
- 如何扩容? 创建一个新的数组,再将旧数组复制进去,这样长度就增加了
LinkedList
- 底层是链表。链表增删快,故LinkedList常用来增删数据.
Set接口
- 元素无序
- 没有索引
- 元素不能重复
Collection遍历删除元素
1.普通for循环:注意每次删除之后索引要--
2.Iterator遍历:不过要使用Iterator类中的remove方法,如果用List中的remove方法会报错
3.增强for循环foreach:不能删除,强制用List中的remove方法会报错
Map接口
HashMap
- 键值对
- 无序,不支持排序
- 采用哈希算法,查找很快
- key可以存null
- value可以重复
- 链地址法解决哈希冲突
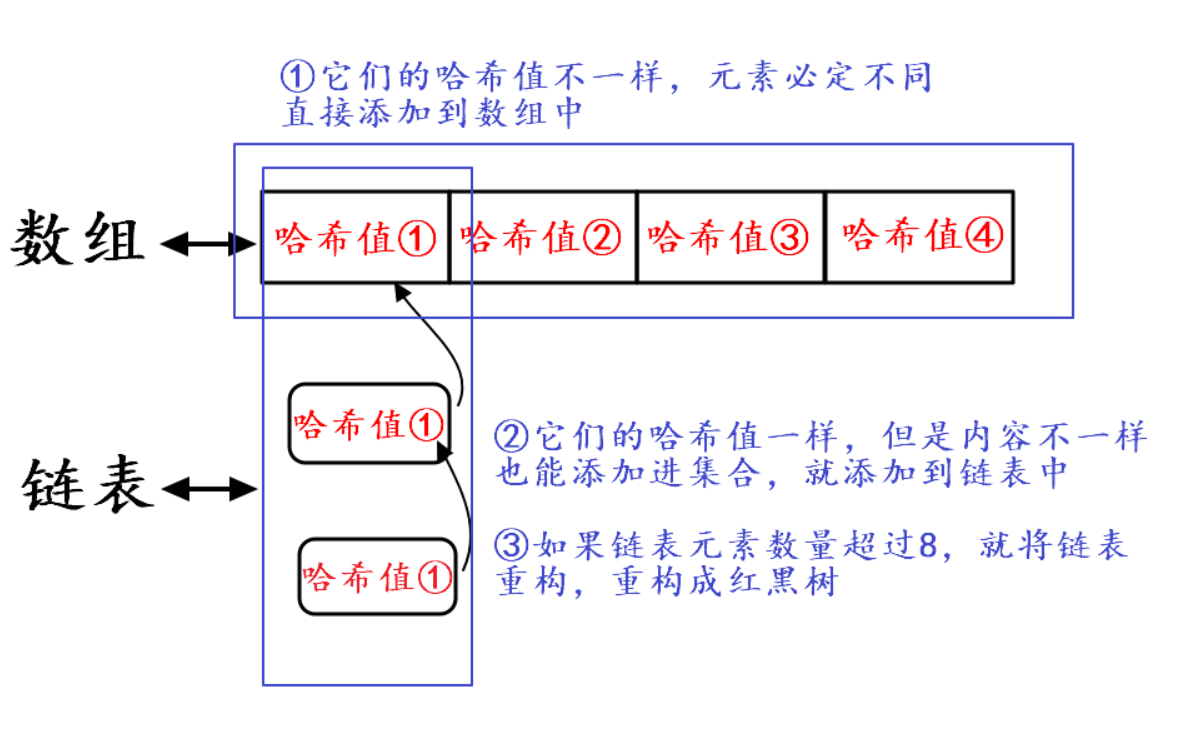
哈希表
Set的元素不可重复,这个问题该如何解决?
若是我的话,我肯定会想:将新的元素和Set中的每一个元素比较一遍不就可以了?如果有相等的,就不添加;如果有不相等的,就添加。
这样做有问题么,理论上是没问题的,但是效率太低太低了,每次添加一个元素就要将元素遍历一遍。
为了解决这个问题,就弄出了哈希表。
哈希表可以用来高效率解决元素不可重复这个问题,其本质就是:数组+链表+红黑树。
所以如果新建了一个对象,需要重写hashCode方法和equals方法
- key,value都不可为null
- 线程安全
- 哈希值就有点类似于数组中的索引,因为哈希值不同其元素必定不同
- 如果没有相同的哈希值,直接添加进集合
- 如果有相同的哈希值,再用equals方法比较内容是否一样
- 扩容
- 哈希表中数组默认长度16,如果数组中的元素超过了75%就开始扩容
- 如果链表元素数量超过8,就将链表重构成红黑树。链表查询是很慢的,所以为了查询效率,链表元素数量过多,就会重构成红黑树,红黑树查询效率比链表要快
ConcurrentHashMap
原理:类中包含两个静态内部类HashEntry和Segment,HashEntry封装了键值对映射表,一个对象表示
一个键值对,且在内部是以链表的形式存在,Segment是一个锁对象,守护整个散列映射表的若干个
桶,每个桶代表由若干个HashEntry对象连起来的链表,一个 ConcurrentHashMap 实例中包含由若
干个 Segment 对象组成的数组,在 HashEntry 类中,key,hash 和 next 域都被声明为 final 型,
value 域被声明为 volatile 型。在ConcurrentHashMap 中,在散列时如果产生“碰撞”,将采用
“分离链接法”来处理“碰撞”:把“碰撞”的 HashEntry 对象链接成一个链表。由于 HashEntry
的 next 域为 final 型,所以新节点只能在链表的表头处插入.
Segment 类继承于 ReentrantLock 类,从而使得 Segment 对象能充当锁的角色。每个
Segment 对象用来守护其(成员对象 table 中)包含的若干个桶。
- 锁分段技术:首先将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问
其中一个段数据的时候,其他段的数据也能被其他线程访问。
SortedMap接口
- 有序
- 支持排序
- 不可存null
- 查找较慢
- value可以重复
- 采用红黑树排序,可以调用Comparator类型的构造方法进行定制排序
- TreeMap是它的实现类,继承体系 Map -> SortMap -> NavigbleMap -> TreeMap


