【大数据】MapReduce开发小实战
Before:前提:hadoop集群应部署完毕。
一、实战科目:做一个Map Reduce分布式开发,开发内容为统计文件中的单词出现次数。
二、战前准备
1、本人在本地创建了一个用于执行MR的的文件,文件中有209行,每行写了“这是一个测试文件”的句子。
2、将该文件上传至HDFS中。你可以使用idea中的插件上传、也可以使用HDFS的可视化页面上传、也可以使用HDFS的命令上传,都可以。目的达到就行。
3、准备好开发环境,准备开发。
三、开战!
1、打开idea,创建com.test.hadoop.mr的包
2、在该包下创建MyWordCount的Java类,并进行如下编程
package com.test.hadoop.mr; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MyWordCount { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(true); Job job = Job.getInstance(conf); job.setJarByClass(MyWordCount.class); // Specify various job-specific parameters job.setJobName("myJob"); Path input = new Path("/testApi/testUploadFile.txt"); FileInputFormat.addInputPath(job, input);//文件输入格式化;还有其他的数据源的输入格式化 Path output = new Path("/testApi/mr_output.txt"); if (output.getFileSystem(conf).exists(output)){ output.getFileSystem(conf).delete(output,true);//一般不删除! } FileOutputFormat.setOutputPath(job, output); job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setReducerClass(MyReducer.class); // Submit the job, then poll for progress until the job is complete job.waitForCompletion(true); } }
3、创建对应的MyMapper和MyReducer类
MyMapper
package com.test.hadoop.mr; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; import java.util.StringTokenizer; public class MyMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { //AAA BBB CCC StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one);//引用传参,减少创建对象的次数。 } } }
MyReducer
package com.test.hadoop.mr; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class MyReducer extends Reducer<Text, IntWritable, Text, IntWritable> { //相同的key为一组,调用方法,然后在方法内迭代一组数据进行计算(sum/max/min/count/...)。 private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } }
4、打jar包
右键项目根目录,点击Open Module Settings;然后选择Artifacts,然后右边栏选择要打包的主类以及是否添加lib(lib可能会很大,建议不要在jar中添加lib)。
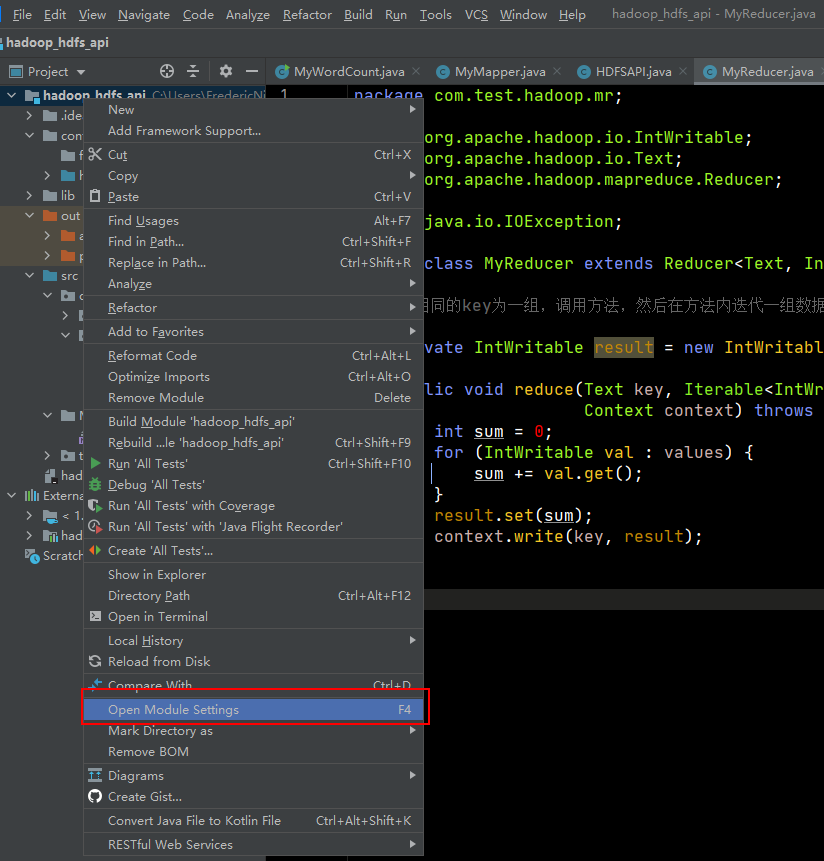

然后,在build中选择build Artifacts进行编译。
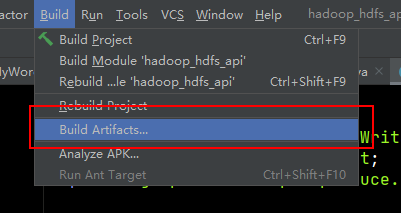

在你设置的目录下,发现输出的jar文件。

5、上传集群
将该文件上传集群某节点,这里选择节点1。
6、执行
定位到jar目录,输入命令,并执行
hadoop jar hadoop_hdfs_api.jar com.test.hadoop.mr.MyWordCount
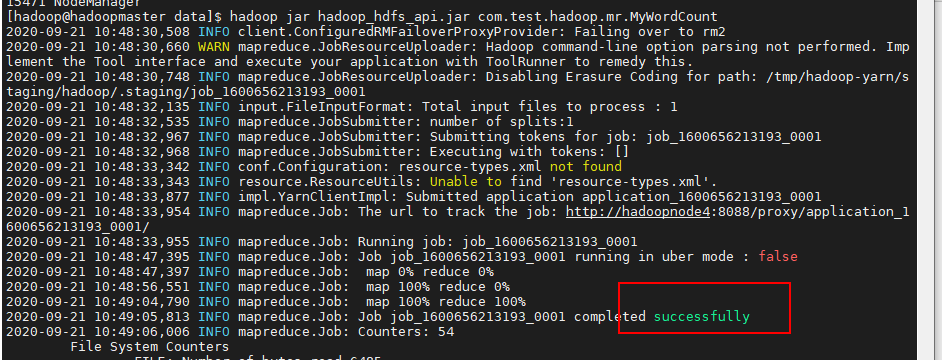
成功执行!
7、查看结果
在节点1的对应位置找到结果文件,cat查看内容

成功统计,说明逻辑以及实战运行均无误!
四、实战总结
首先,要了解MapReduce的运行机制,在客户端的开发中,我们不仅要使用Java实现客户端的基础配置外,还要实现Map Task即对应的MyMapper类,还要实现Reduce Task即对应的MyReducer类。
其次,在进行运行时,可能会报编译版本过高的错误,即你的服务器版本使用java8,而idea本身使用更高版本的Java编译,就会导致此问题,博主就遇到了。因此,要不就是升级服务器Java版本,要么就要用低版本Java进行编译,生成jar。两种策略中,服务器能不动就不动,因为改动成本太大。所以使用idea低版本进行编译,具体如何设置请自行百度或Google。
最后,Java类的编写要参考源码中的例子,在知道了MR的逻辑运行之后,要懂得代码的实现,这条路还很漫长,要加油!


