布隆过滤器(Bloom Filters)的原理及代码实现(Python + Java)
- 2020 年 8 月 17 日
- 笔记
本文介绍了布隆过滤器的概念及变体,这种描述非常适合代码模拟实现。重点在于标准布隆过滤器和计算布隆过滤器,其他的大都在此基础上优化。文末附上了标准布隆过滤器和计算布隆过滤器的代码实现(Java版和Python版)
本文内容皆来自 《Foundations of Computers Systems Research》一书,自己翻译的,转载请注明出处,不准确的部分请告知,欢迎讨论。
-
布隆过滤器是什么?
布隆过滤器是一个高效的数据结构,用于集合成员查询,具有非常低的空间复杂度。
-
标准布隆过滤器(Standard Bloom Filters,SBF)
基本情况
布隆过滤器是一个含有 m 个元素的位数组(元素为0或1),在刚开始的时候,它的每一位都被设为0。同时还有 k 个独立的哈希函数 h1, h2,…, hk 。需要将集合中的元素加入到布隆过滤器中,然后就可以支持查询了。说明如下:- 计算h1(x), h2(x),…,hk(x),其计算结果对应数组的位置,并将其全部置1。一个位置可以被多次置1,但只有一次有效。
- 当查询某个元素是否在集合中时,计算这 k 个哈希函数,只有当其计算结果全部为1时,我们就认为该元素在集合内,否则认为不在。
- 布隆过滤器存在假阳性的可能,即当所有哈希值都为1时,该元素也可能不在集合内,但该算法认为在里面。
- 假阳性出现的概率被哈希函数的数量、位数组大小、以及集合元素等因素决定。
假阳性率评估
为了评估假阳性率,需要基于一个假设:哈希函数都是完美随机的。约定几个变量:- k 哈希函数的数量
- n 集合 S 中元素的数量
- m 位数组的大小
- p 位数组中某一位为0的概率
- f 假阳性的概率
最后得出: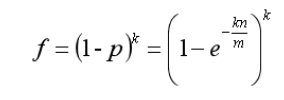
最佳的哈希函数数量
根据数学推理得(过程就算了):当 p = 1/2, k = ln2 * (m/n)时,f 最小为(1/2)^k
可以看出,当位数组中有一半零一半一时,结果最好。
事实上,m 是 n 的倍数,而且 k 常取最接近但小于理论值的整数值。部分布隆过滤器(partial bloom filters) -
计算布隆过滤器(Counting Bloom Filters,CBF)
标准的布隆过滤器有一个致命的缺点:不支持删除元素。CBF协议解决的这个问题。 - 将标准布隆过滤器中的位数组变成整数数组,即可以用多位表示。
- 标准布隆过滤器每个位置可以被多次置1,但只有一次有效,这样,某一个位置被多个元素哈希映射,当要删除其中一个元素时,该元素哈希映射的位置都应该变为零,那么就会破坏其他元素的映射,会出现假阴性。
- 由于计算布隆过滤器的数组可以表示更大的整数,那么当某个位置被映射到时,该位置的计数值就自增1,而当某个元素被删除时,就将其映射位置的计数值减1。这样就解决了SBF的问题。
- CBF同样存在问题,因为当计数值自增时可能会溢出,当计数值为4比特时,溢出的概率为:1.37 * 10^-15 * m,虽然很低,但对某些应用可能不够。一个简单的解决方法是,当计数值到达最大值时,就不在自增,但这导致假阴性。
-
压缩布隆过滤器(Compressed Bloom Filters)
在网络应用中,布隆过滤器通常被作为信息在各节点间传送,为了节约资源,自然而然就想能不能压缩布隆过滤器后再传送。 - 由前面我们知道,要使得布隆过滤器有最小的假阳性概率,数组中包含的0或1的概率应该是一样的,根据香农编码原理(Shannon coding principle),这样的布隆过滤器不能被压缩。虽然这样的布隆过滤器不能被直接压缩,但我们可以用其他方法达到一样的效果。
- 要使得布隆过滤器 x 与布隆过滤器 y( 包含的0或1的概率应该是一样的)具有相同的假阳性概率,那么,x 的大小要大于 y 的,x 的哈希函数的数量不同于 y 的,这样 x 中包含的0和1的数量就不同,x 就可以被压缩。
- 问题出来了,压缩布隆过滤器的原因是更节省空间,我们找了个更大的布隆过滤器压缩,那么压缩后的布隆过滤器的空间效率比原布隆过滤器更加优秀吗?是的。
- 压缩后,布隆过滤器的本地存储空间会变大,但哈希函数数量会变小(更少的映射操作)、传送的位更少。
-
D-left 计算布隆过滤器(D-left Counting Bloom Filters)
上面提到的计算布隆过滤器存在这样的缺点:存储空间是标准布隆过滤器的数倍(取决于计数值的位数)和计数值的不均匀(有些始终为0,有些则可能溢出)。下面看看 D-left Counting Bloom Filters 的特点。D-left Counting Bloom Filters 基于 D-left Hashing。 D-left Hashing 基本结构
- 将一个哈希表分成几个不相交的子表(subtable)
- 每个子表里都有数量相同的桶(bucket)
- 每个桶里都有一定数量的单元(cell,单元包括特征值和计数值)
- 每个单元都是固定的位数组成,用来保存元素的特征值(fingerprint)
- 只有一个哈希函数,该哈希函数可以生成和子表数量相同的桶地址和一个特征值
插入操作
假设有 d 个子表,元素为 x,哈希函数为 f- 计算 f(x),生成桶地址 addr0, addr1, …, addr(d-1),特征值 p
- 我们检查子表 i 中地址为 addri 的桶中的所有单元(i = 0,1,…,d-1)
- 如果某个单元中的特征值和 p 相等,那幺元素 x 就在该哈希表中
- 若没有找到这样的单元,那么需要找到存储特征值最少的桶(在上面生成的桶地址中找),然后将该特征值 p 随机放入该桶的一个空单元中,该单元的计数值变为1,这考虑了装载平衡
D-left Counting Bloom Filters
由上可知,d-left Hashing 的计数值最大为零,不支持删除操作,为了将它变成可 Counting,可以让它的计数值变成由多位组成。但这样依然会出现问题,如下:- 假设 d-left counting bloom filter 包含 4 个子表,每个子表又包含 4 个桶,初始为空。
- 现在有两个元素 x 和 y 需要映射到过滤器中,f(x) = (1, 1, 1, 1,r), f(y) = (1, 2, 3, 4, r)
- 已知插如 x 时,第四个子表的第一个桶最空,x 的特征值 r 被插入该桶的某一个单元中,该单元计数值变为1,而插入 y 时,第一个子表的第一个桶最空,y 的特征值 r 被插入该桶的某一个单元中,该单元计计数值变为1
- 现在要删除 x,那么就会寻找每个子表的第一个桶中的单元,这时,在第一个子表的第一个桶中找到了特征值 r,接下来就会将该单元的计数值减 1 变为 0,同时,存储的特征值被删除,变为空。
- 现在查找 x 是否在表中,结果返回真,而查询 y 是否在表中,结果返回假,导致错误。
为什么会出现上面的情况?由三个因素促成
- x 和 y 有相同的特征值 r
- f(x) 和 f(y) 生成的地址有相同的
- x 和 y 特征值存储的地方还不一样(存一样就不会出错)
如何解决?
说实话,没看懂英文描述的内容。。。。大致是做了排列置换等操作
性能分析
比普通的计算布隆过滤器空间少了一半甚至更多,而且效率也有提升(假阳性更低)
-
Spectral Bloom Filters
Counting Bloom Filters 可以进行元素的删除操作,然而却不能记录一个元素被映射的频率,而且很多应用中元素出现的频率相差很大,也就是说,CBF中每个计数值的位数一样,那么有些计数值很快就会溢出,而另一些则一直都很小。这些问题可以被 Spectral Bloom Filters 解决。 在SBF中,每一个计数值的位数都是动态改变的。它的构造我没看懂,先留着吧
-
Dynamic Counting Filters
Spectral bloom filter 被提出来解决元素频率查询问题,但是,它构造了一个复杂的索引数据结构去解决动态计算器的存储问题。Dynamic counting bloom filter(比SBF好理解多了) 是一个空间时间都很高效的数据结构,支持元素频率查询。相比于SBF,在实际应用中(计数器不是很大,改变不是很频繁时)它有更快的访问时间和更小的内存消耗。 构成部分
- DCBF由两部分组成,第一部分是基础的计算布隆过滤器
- 第二部分是一个同样大小的向量,用于记录第一部分中计算器溢出的次数
- 第一部分中的计算器位数固定,第二部分中每个溢出计算器位数动态改变
特点
- 当第二部分溢出计算器也面临溢出时,会重新申请一个向量,给要溢出部分增加位数,其他溢出计算器直接拷贝到新的向量中的对应位置,旧的向量会被释放
-
学习案例
Summary Cache
在网络中有极大的资源请求,如果所有的请求都由服务器来处理,网络就会出现拥堵,性能就会下降。所以网络中有大量的中间代理节点。这些代理会把一部分资源放在自己的本地缓存,当用户向服务器请求资源时,该代理先会检查该资源是否在自己的缓存中,如果在就直接发送给用户,否则再向服务器请求。一个代理能够存储的资源是非常有限的,为了进一步减轻服务器的负载,网络中相邻的代理都可以共享自己的缓存。这样,当代理 A 本地缓存没有时,就会向相邻代理广播请求,查询他们是否有该缓存。
然而,这样依旧有很大问题,假设,这里有 N 个代理,每个代理的命中率为 H,一个代理平均请求 R 次,那么广播中,一个代理收到的查询信息共有 (N-1) * (1-H) * R 条,总共的请求也就是
N * (N-1) * (1-H) * R。这是非常低效的。
再次改进,各个代理之间交换自己缓存的摘要信息。这样,当代理 A 失败后,会先查询各个代理的摘要信息,然后决定是定向向某个代理请求,还是向服务器请求资源。这就大大的减少了网络通信量。为了满足快速查询、更新摘要信息,一个非常好的选择就是计算布隆过滤器(Counting bloom filters)。IP Traceback
网络中存在许多攻击,有时候需要根据一些数据包去还原IP路径,找到攻击者。一个可行的办法是在路由器中存储数据包信息。然而,有些网络中通信量巨大,存储所有的包是不现实的,因此可以存储这些包的摘要信息。这时,选用布隆过滤器可以极大的节省空间,而且具有非常快的查询。
- 代码实现
|
标准布隆过滤器构建、测试代码(Python 面向过程版)  
1 import math 2 import random 3 import time 4 5 6 def hash_function(a, b, c, item, tablelen): 7 return (a * item ** 2 + b * item + c) % tablelen #哈希函数 8 9 10 def construction_of_SBF(tablelen = 1000, set = []): 11 12 k = int(math.log(2, math.e) * (tablelen / len(set))) 13 hash = [] 14 random.seed(time.time()) 15 for i in range(k): #随机生成哈希函数的三个参数 16 a = random.randint(1, 1000) 17 b = random.randint(1, 1000) 18 c = random.randint(1, 1000) 19 hash.append((a, b, c)) 20 21 bitArray = [0] * tablelen 22 23 for element in set: #映射集合元素到位数组 24 for i in range(k): 25 hx = hash_function(hash[i][0], hash[i][1], hash[i][2], element, tablelen) 26 bitArray[hx] = 1 27 28 filter = [bitArray, hash] 29 return filter 30 31 # 测试 32 def test_bloom_filters(bloom_filter = None): 33 if bloom_filter == None: 34 return False 35 36 testSet = [1, 3, 7, 111, 99, 54, 34, 67, 81, 121, 101, 100, 23, 0, 845, 3339, 44] 37 for item in testSet: 38 flag = True 39 for i in range(len(filter[1])): 40 hx = hash_function(filter[1][i][0], filter[1][i][1], filter[1][i][2], item, len(filter[0])) 41 if bloom_filter[0][hx] != 1: 42 flag = False 43 break 44 45 if flag is True: 46 print("%d is in filter\n" % item) 47 else: 48 print("%d is not in filter\n" % item) 49 50 return True 51 52 53 if __name__ == "__main__": 54 filter = construction_of_SBF(set = list(range(10))) 55 test_bloom_filters(filter) View Code
计算布隆过滤器构建、测试代码(Python 面向过程版)
1 import math 2 import random 3 import time 4 5 """ 6 结构没有设置好,按下写: 7 0. 封装函数 8 1. 哈希函数:计算哈希值 9 2. 生成哈希随机参数函数 10 3. 插入函数:被调用 11 4. 删除函数:被调用 12 5. 查询函数:测试函数调用 13 6. 测试函数:测试插入和删除 14 15 """ 16 17 18 def hash_function(params, item, tlen): 19 return (params[0] * item ** 2 + params[1] * item + params[2]) % tlen 20 21 22 def deletion_counting_bloom_filter(cbfilter = None, item = None): 23 if (cbfilter is None) or (item is None): 24 return False 25 for params in cbfilter[2]: 26 cbfilter[0][hash_function(params, item, len(cbfilter[0]))] -= 1 27 return True 28 29 30 def insertion_counting_bloom_filter(item = None, cbfilter = None): 31 if (item == None) or (cbfilter == None): 32 return False 33 for params in cbfilter[2]: 34 cbfilter[0][hash_function(params, item, len(cbfilter[0]))] += 1 35 return True 36 37 38 def query_counting_bloom_filter(item = None, cbfilter = None): 39 for params in cbfilter[2]: 40 if(cbfilter[0][hash_function(params, item, len(cbfilter[0]))]) is 0: 41 return False 42 return True 43 44 45 def construction_counting_bloom_filter(filterSet = None, filterArray = None): 46 if (filterSet is None) or (filterArray is None): 47 return None 48 # 最佳的哈希函数数量 49 hashNum = int(math.log(2, math.e) * (len(filterArray) / len(filterSet))) 50 hashParam = [] 51 random.seed(time.time()) 52 # 随机生成哈希参数 53 for i in range(hashNum): 54 a = random.randint(1, 9999) 55 b = random.randint(1, 9999) 56 c = random.randint(1, 9999) 57 hashParam.append((a, b, c)) 58 59 # 将初始集合元素映射到过滤器数组中 60 for item in filterSet: 61 for params in hashParam: 62 filterArray[hash_function(params, item, len(filterArray))] += 1 63 64 # 返回过滤器数组、过滤器集合、过滤器哈希参数 65 return (filterArray, filterSet, hashParam) 66 67 68 def test_counting_bloom_filters(cbfilter = None): 69 if cbfilter is None: 70 return None 71 testSet = cbfilter[1][10:20] 72 73 # 先测试原有元素是否正常映射 74 for item in testSet: 75 if query_counting_bloom_filter(item, cbfilter) is True: 76 print("%d is in filter\n" % item) 77 else: 78 print("%d is not in filter\n" % item) 79 80 # 删除后再查询 81 if deletion_counting_bloom_filter(cbfilter, testSet[0]) is True: 82 print("delete successfully!\n") 83 else : 84 print("delete fails\n") 85 86 if query_counting_bloom_filter(testSet[0], cbfilter) is True: 87 print("%d is in filter\n" % testSet[0]) 88 else : 89 print("%d is not in filter\n" % testSet[0]) 90 91 # 插入后再测试 92 if insertion_counting_bloom_filter(testSet[0], cbfilter) is True: 93 print("insert %d successfully\n" % testSet[0]) 94 else: 95 print("insert %d fails\n") 96 97 if query_counting_bloom_filter(testSet[0], cbfilter) is True: 98 print("%d is in filter\n" % testSet[0]) 99 else : 100 print("%d is not in filter\n" % testSet[0]) 101 102 103 # 封装后的函数 104 def counting_bloom_filters(filterSet = None, filterArray = None): 105 if (filterSet is None) or (filterArray is None): 106 return False 107 # 构造:初始集合元素的映射、哈希函数参数生成 108 cbfilter = construction_counting_bloom_filter(filterSet, filterArray) 109 110 # 测试:测试插入、删除、查询 111 test_counting_bloom_filters(cbfilter) 112 113 114 if __name__ == "__main__": 115 filterSet = list(range(100)) 116 filterArray = [0] * 10000 117 counting_bloom_filters(filterSet, filterArray) View Code
标准布隆过滤器构建、测试代码(Java 面向对象版)
1 // package BloomFilters; 2 3 import java.util.Arrays; 4 import java.util.Random; 5 import java.io.*; 6 import java.math.BigInteger; 7 import java.nio.*; 8 import java.nio.charset.StandardCharsets; 9 import java.nio.file.Path; 10 import java.util.*; 11 12 /** 13 * 实现标准布隆过滤器的类 14 */ 15 public class SBFilters { 16 // 实例字段 17 private boolean[] bitArray; //位数组 18 private int[][] hashParams; //随机的哈希函数参数 19 20 // 方法字段 21 public SBFilters(int tLen, int[] iSet) 22 { 23 this.bitArray = new boolean[tLen]; 24 Arrays.fill(this.bitArray, Boolean.FALSE); 25 this.construction_filter(iSet); 26 } 27 28 private boolean construction_filter(int[] iSet) 29 { 30 if(iSet == null || iSet.length == 0) 31 { 32 return false; 33 } 34 var hashNum = (int)(Math.log(2) * (this.bitArray.length / iSet.length)); 35 this.construction_hashParams(hashNum); 36 for(var item: iSet) 37 { 38 for(var params: this.hashParams) 39 { 40 this.bitArray[hash_function(params, item)] = true; 41 } 42 } 43 return true; 44 } 45 46 private boolean construction_hashParams(int hashNum) 47 { 48 this.hashParams = new int[hashNum][3]; 49 var time = System.currentTimeMillis(); 50 var rd = new Random(time); 51 for(int i = 0; i < hashNum; i++) 52 { 53 this.hashParams[i][0] = rd.nextInt(9999) + 1; 54 this.hashParams[i][1] = rd.nextInt(9999) + 1; 55 this.hashParams[i][2] = rd.nextInt(9999) + 1; 56 } 57 return true; 58 } 59 60 private int hash_function(int[] params, int item) 61 { 62 return (int)((params[0] * Math.pow(item, 2.0) + 63 params[1] * item + params[2]) % bitArray.length); 64 } 65 66 public boolean query_filter(int item) 67 { 68 for(var params: this.hashParams) 69 { 70 if(this.bitArray[hash_function(params, item)] == false) 71 { 72 return false; 73 } 74 } 75 return true; 76 } 77 78 } 79 80 81 82 // package BloomFilters; 83 84 85 86 87 /** 88 * 用来测试实现的布隆过滤器是否正常工作 89 */ 90 public class FiltersTest 91 { 92 public static void main(final String[] args) 93 { 94 test_counting_bloom_filters(); 95 } 96 97 98 private static void test_counting_bloom_filters() 99 { 100 var iSet = new int[10000]; 101 for(int i = 0; i < 10000; iSet[i] = i++); 102 SBFilters sbFilter = new SBFilters(999999, iSet); 103 104 for(var item: new int[]{1, 3, 5, 78, 99, 100, 101, 9999, 10000, 3534}) 105 { 106 var isIn = sbFilter.query_filter(item); 107 if(isIn == false) 108 { 109 System.out.printf("%d is not in the filter\n", item); 110 } 111 else 112 { 113 System.out.printf("%d is in the filter\n", item); 114 } 115 } 116 } 117 118 119 } View Code
|


