分佈式系統一致性問題與Raft算法(下)
- 2020 年 3 月 4 日
- 筆記
上一篇講述了什麼是分佈式一致性問題,以及它難在哪裡,liveness和satefy問題,和FLP impossibility定理。有興趣的童鞋可以看看分佈式系統一致性問題與Raft算法(上)。
這一節主要介紹raft算法是如何解決分佈式系統中一致性問題的。說起raft大家可能比較陌生,但zookeeper應該都比較熟悉了,zookeeper的ZAB協議可以說和raft算法是非常相似的。
再PS:本篇的重點是介紹raft算法的邏輯,所以有些細節會選擇性得忽略,不然就太長了。對具體實現細節有興趣的童鞋更應該去看看具體的論文。文末附上MIT6.824的地址以及raft中英文論文,有需求可以自取。
1.raft算法的起源與paxos算法
要說raft算法,那就不得不先說paxos算法。在raft算法問世之前,paxos算法可以說一直就是分佈式一致性的代名詞。但paxos有兩個主要問題:
- paxos算法複雜且難以理解
- paxos算法難以直接應用工程化
針對第一點,儘管有很多人試圖降低它的複雜程度,但依舊改變不了它難以理解的事實。而第二點就致命了,首先paxos算法能解決分佈式系統的共識問題,這個是已經被證明了的。但要將paxos算法實際應用起來,往往需要修改其算法結構,但很可能修改後算法就變了模樣,也就是說修改後的paxos算法與原先的paxos算法相比有存在缺陷的可能,並且難以證明。
raft算法就是為了解決paxos的缺陷而產生的。它更加易於理解,並且能夠達到paxos算法的相同功能,也就是能夠解決分佈式系統的一致性問題。
那麼下面介紹下raft的具體實現吧。
2.raft算法
raft的整體架構先從這張圖看起,這是raft論文裏面的圖。
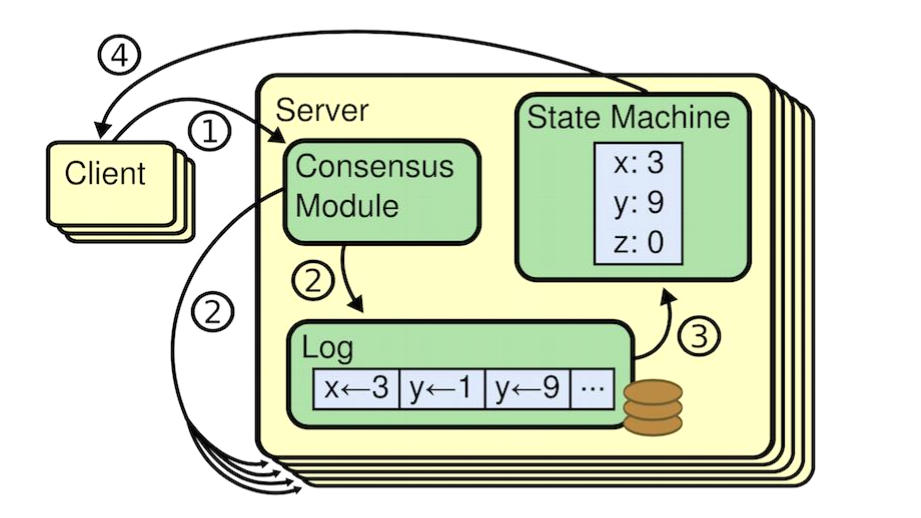
這張圖揭示了客戶端向服務器發送請求的流程,我們先簡單介紹下圖的內容,再分析下整個流程。左邊的是客戶端,右邊的是服務端(分佈式系統,即有N個節點)。客戶端負責發送請求更改分佈式系統中的狀態(變量),服務端負責接收信息,並讓系統中所有節點就某個狀態達成共識。
服務端也就是分佈式系統環境,由一個leader組成,多個follower構成。leader負責接收消息並同步給其他節點,以及負責解決節點信息不一致的問題,具體怎麼解決後面會說。而follwer負責接收leader的消息以及當接收不到消息的時候,試圖讓自己成為leader。
那麼整個流程大概是這樣:
- 客戶端發送請求給到服務端的leader(如果是追隨者,重定向到leader)
- leader接收到信息,改變自身的狀態,並將這一改變信息發送給全部的follower
- 當大多數follower節點將成功這個改變應用到自身的時候,leader確認了這次改變
- 將改變成功的消息返回給客戶端
這就是大概的流程,當然其中省略了很多細節。那麼現在,我們來看看具體的內部流程。
簡單得說,raft通過一個選定一個系統唯一的領導者(其他節點為追隨者),由它來負責管理各個節點(包括自己)的日誌信息,來實現一致性。那麼這樣就有了兩個問題,第一個是唯一的領導者選舉,第二個是保證每個節點日誌的一致性,我們逐個來說。
注意這裡只會講解大概的思路,盡量不去太深入到細節中去,還是那句話,對具體實現細節感興趣的童鞋推薦看原論文(文末附)。
領導者選舉
先大概介紹下領導者選舉的流程。首先,leader會周期性得發送心跳(非固定周期,就是說可能間隔10ms發心跳給a,15毫秒發心跳給b,再間隔8ms發給a),維繫自己的地位。當某個追隨者在時間內沒接收到leader的心跳的時候,它就會知道leader掛了,這個時候追隨者就會嘗試推舉自己成為領導者(成為候選人),並發送請求讓其他追隨者投票給自己。其他追隨者通過某種規則判斷該候選人有沒有「資質」,有則投票給他,否則不投票。最終,當超過半數的追隨者認同該候選人,那麼它就成為了新的leader。
在這個過程中,主要面臨的也是兩個問題,
- 如何讓系統中只有唯一一個領導者,也就是如何處理殭屍節點(Zombie),或者說腦裂的問題
- 當集群中沒有領導者的時候,如果選出最合適的領導者,也就是追隨者投票的時候如何進行資質認定
處理殭屍節點問題(Zombie)
處理這個問題,在raft算法中,引入了一個任期的概念。任期從0開始,隨着leader的更迭逐漸遞增,通過這個任期的概念,解決了多數分佈式系統內部不一致的問題。
比如說一個leader掛掉或不可達的時候,會有一個追隨者試圖成為新leader,這時候它的任期會自動加1。還記得嗎,競選leader的節點需要發送請求給每一個追隨者投票,這個請求信息中就包含新的任期,追隨者接收信息對比發現請求裏面的任期比自己的大,便會更新自己的任期。
這樣一來,上面說到的殭屍節點問題就解決了,當舊的leader(殭屍leader)重新返回後,發送心跳給追隨者,追隨者發現心跳請求裏面的任期比自己還低,便不再鳥它。舊的leader發現沒人鳥自己,也就明白了自己已經不再是leader,所以就變成了追隨者。
如果你足夠細心,你會發現這個邏輯裏面還隱藏着一個問題。要是某個任期在競選leader的時候,沒有獲取到足夠的選票,也就是系統內大多數節點不認可它該怎麼辦呀?很簡單,這個任期就會變成一個空任期,會直接開始下一個任期的領導者選舉。至於投票不投票的邏輯,這是我們接下來要說的。
選出最合適的領導者
我們在上面說了,每個節點會維持一個存放日誌的list。其實這個list不止存放日誌,它還存放了每條日誌對應的任期。類似
[(‘狀態5′,’任期0’),(‘狀態10′,’任期0’),(‘狀態14′,’任期1’)]
這樣的列表。
我們知道當追隨者試圖成為leader(也就是候選人)的時候,會廣播投票請求,請求裏面就包含了競選者日誌list中最後一條日誌的索引,以及對應的任期。每個進行投票的追隨者會與自身的日誌list比較,如果索引比自身list的最後索引小,那麼說明候選人的日誌沒自己的新,這時候追隨者會拒絕投票。
這樣的特性能夠保證系統儘可能得選出日誌最新的節點,為什麼說儘可能?因為依舊存在可能丟失狀態。比如leader接收到請求,還沒發給其他節點,或只發給少數節點。那麼沒來得及完成處理的這些請求就可能丟失,但即便這樣,系統在最終依舊會能維持一致,只是並非最新更改的狀態值,或者說有部分數據任然會丟失。
維持日誌一致性
首先,所有的狀態改變(可以理解為變量值改變)都是由leader執行,然後將這一改變輻射到所有的追隨者。每個節點都維持一個存日誌的list,用以存儲每一條改變狀態的信息。
leader接收客戶端的操作指令後,先追加這一指令到自己的日誌list,然後會將指令發送給追隨者,追隨者主要目的就是接收這些指令,並追加到自己日誌list中。leader負責管理和檢測追隨者的日誌list是否和自己的一致,由此實現整個分佈式系統的一致性。
在這個過程,主要也是有幾個問題需要解決:
- 如何在無序的網絡中控制追隨者日誌的一致
- 當追隨者出現殭屍節點,在殭屍節點恢復正常的時候,如何確保日誌和leader變得一致
日誌一致的保證
在介紹日誌一致性前,需要明白這樣兩個事實:
如果在不同的節點的日誌list中,兩個條目擁有相同的索引和任期號,那麼他們存儲了相同的指令。
如果在不同的節點的日誌list中,兩個條目擁有相同的索引和任期號,那麼他們之前的所有日誌條目也全部相同。
也就是說,兩個節點各自有一個list保存日誌,如果兩個節點各自的list中的某個索引相同點,任期也相同,那麼說明它前面的內容都是一致的。
解決日誌一致性這個問題其實不難,就是當leader將客戶端的指令輻射出去的時候,要等到所有追隨者狀態確認後再執行下一條客戶端指令,典型的用效率換取準確性。這裡的狀態確認只有三種,成功,失敗和連接不上客戶端。注意失敗和連接不上是兩種情況,失敗有可能是因為某些日誌數據不一致,這時就需要找到追隨者日誌list中與一致的那個點,然後覆蓋掉後面不一致的數據。最極端的情況就是發現追隨者全部都和leader的日誌list不一致,那麼就會將leader的list全部覆蓋追隨者的日誌list,這種做法也叫做強制複製。
而連接不上則可能是因為追隨者正忙,或者它真的掛掉了。上一篇講過,要在異步的網絡通信中真正識別這兩種情況幾乎是不可能的。這時候,我們可以直接認為它掛掉了,如果發現其實沒掛,那麼直接按照殭屍節點的邏輯來處理。
處理殭屍節點
當發現追隨者節點不可達的時候,會將它標記為殭屍節點(論文里是說無限重試,但實際操作發現無限重試存在一些問題),等待該追隨者重啟。這樣一來,當殭屍節點重新恢復時最大的問題其實就是它的任期和日誌list遠落後於leader。
解決這些問題的方法其實上面都講到了,每次leader請求,追隨者會比較任期,發現自己任期低會自動更新。如果是日誌list,那麼會找到與leader日誌list一致的那個索引,然後覆蓋後面的全部list。
最後再來結合具體的例子看看吧。
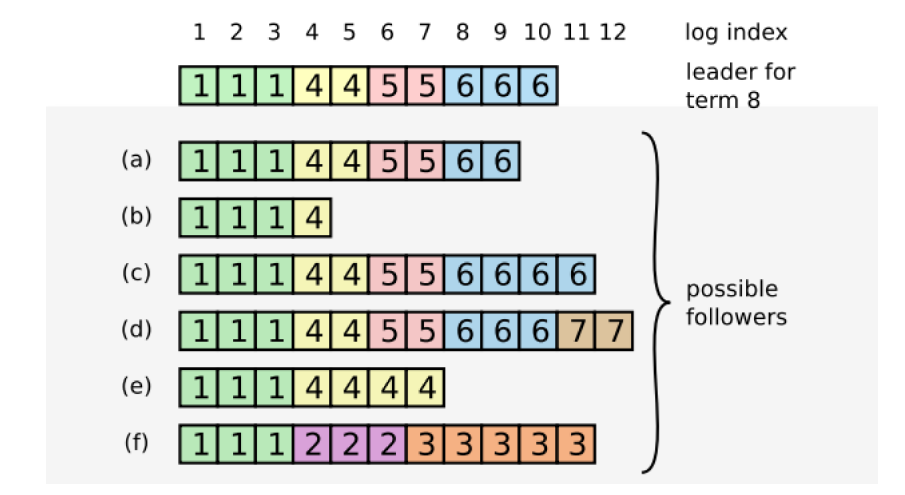
灰色方框之上的是一個剛擔任leader的節點。a,b,c,到f是不同的幾個follower節點,每個節點後面的那行代表日誌list,裏面的數字表示任期。
當一個leader當選的時候,a,b,…到f基本涵蓋了可能的情況。a和b表示追隨者缺少部分日誌,那麼這時候追加就行。c和d表示r日誌過多,那麼要刪除索引11以及之後的日誌,讓日誌和leader保持一致。e和f表明r日誌list有不一致的內容,即某些地方任期不一致,這時候e會找到索引相同的最後一個節點(這裡是5),覆蓋後面的內容,f也是同樣的道理。
OK,以上就是raft算法維持分佈式系統一致性的基本思路,當然還有一些額外的內容,比如防止日誌list過長而可以採用的checkpoint技術,以及客戶端實現exctly once語義的方法,這些比較細節的內容就不多說了。這篇文章的目的還是希望起到拋磚引玉的作用而已。
以上~