vivo霍金實驗平台設計與實踐-平台產品系列02
vivo 互聯網平台產品研發團隊 – Bao Dawei
本篇介紹了vivo霍金實驗平台的系統架構以及業務發展過程中遇到的問題以及對應的解決方案。
《平台產品》系列文章:
一、前言
互聯網企業經歷過野蠻生長的開拓紅利期之後,逐漸越發重視產品發展的科學化、精細化,從粗放型向集約型轉換。在美國,增長黑客等數據驅動增長的方法論,正在幫助如Google、Microsoft、Facebook等全球科技巨頭實現持續的業務增長;在國內,數據精細運營、AB實驗分析來驅動業務有效增長也逐漸成為共識,成為核心手段。其中,A/B測試平台作為典型代表,自然成為了國內主流公司中必不可少的核心工具,有效的提升流量的轉化效率和產研的迭代效率。
在過去幾年,vivo互聯網持續重視科學的實驗決策,這意味着所有對用戶的改動的發佈,都要決策者以相應的實驗結論作為依據。比如,修改頂部廣告的背景色、測試一個新的廣告點擊率 (CTR) 預測算法,都需要通過實驗的方式進行,那麼一個強大的A/B實驗平台就非常重要了。vivo霍金實驗平台(以下簡稱霍金)已經從一個單一系統成長為了解決A/B實驗相關問題的公司級一站式平台,助力互聯網核心業務的快速、準確實驗,高效推動業務增長。
二、項目介紹
2.1 A/B實驗
在互聯網領域,A/B實驗通常指一種迭代方法,這種方法可以指導如何改進現有產品或者服務。以提升某個產品下單轉化率為例,AB實驗過程中,我們設計了新的下單頁面,和原頁面相比,頁面布局和文案做了調整。我們將用戶流量隨機分成A/B兩組(分別對應新舊頁面),50%用戶看到A版本頁面,50%用戶看到B版本頁面,經過一段時間的觀察和統計,發現A版本用戶下單轉化率為70%,高於B版本的50%。那麼我們得出A版本效果好,進而將新頁面推送並展示給所有用戶。
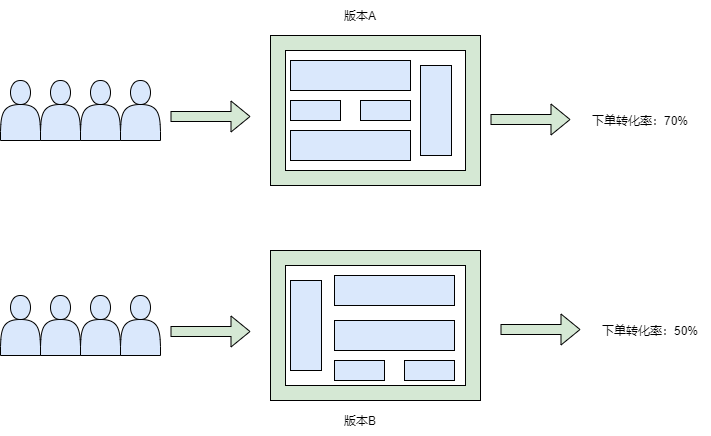
以上就是一個利用AB測試迭代產品功能的具體應用,我們將A/B實驗的完整生命周期分為三個階段:
-
實驗前,明確改進目標,定義實驗指標,完成相關功能開發和上線;
-
實驗中,制定每個實驗組流量比例,按照分流比例開放線上流量進行測試;
-
實驗後,實驗效果評估並決策。
2.2 分層實驗模型
霍金的分層實驗模型參考谷歌發佈的重疊實驗框架論文:《Overlapping Experiment Infrastructure: More, Better, Faster Experimentation》完成設計。
2.3 平台發展及在vivo業務中的應用和價值
霍金啟動於2019年,歷經三年多的發展,目前日均實驗數量達到900多個,高峰期1000+。
-
支撐vivo國內與海外業務,服務公司20多個部門。
-
通過標準化的實驗流程降低了實驗門檻,提升實驗效率。
-
通過自動化的數據分析工具輔助業務快速決策,提升產品迭代速度,有效助力業務發展。
-
平台能力復用,避免不同組織重複建設的情況,有效的提升了生產效率。
三、霍金系統架構
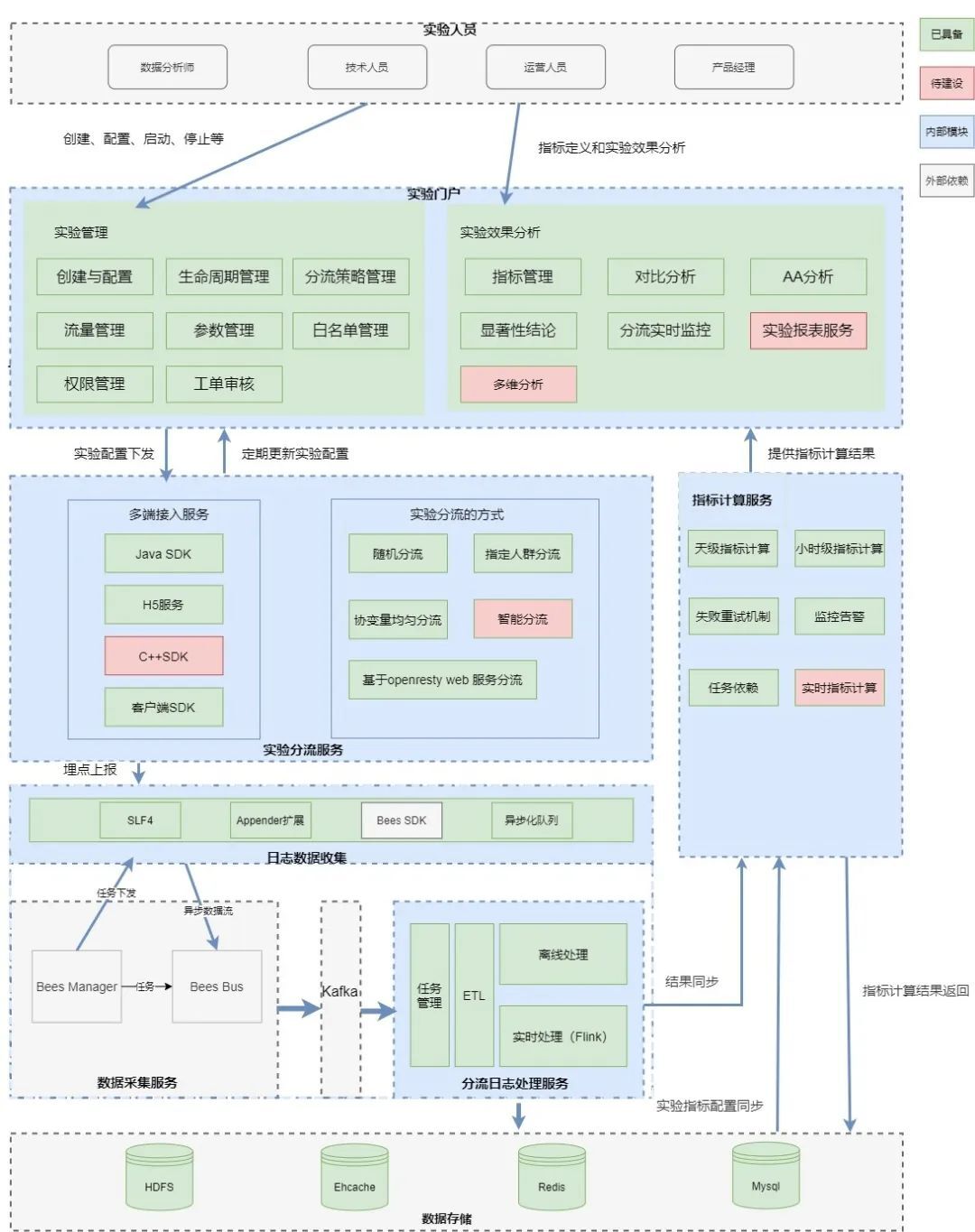
3.1【實驗人員】
實驗人員包含多個角色,供業務方在霍金管理後台進行實驗、指標的管理和實驗效果的分析。
3.2【實驗門戶】
包括兩部分功能:實驗管理和實驗效果分析。
3.2.1 實驗管理
平台提供可視化頁面供業務方進行實驗配置、分流策略的選擇、流量的分配以及白名單的管理。
3.2.2 實驗效果分析
包括如下4個核心能力:
1. 指標管理
不同實驗關注指標不同,為了實現效果評估自動化,平台提供了指標配置和集成能力。
【必看指標】:通常為業務核心指標,每個實驗都需要保障不能有明顯負向的指標,平台通過集成大數據指標管理系統,這部分指標結果直接復用指標管理系統的數據服務。
【個性化指標】:通常為實驗中臨時分析的指標,如某banner樣式實驗,觀察的指定banner的曝光點擊率。平台提供了自定義指標配置的能力,並通過大數據計算平台自動生成計算任務,實現自定義指標自動化產出數據的能力。
2. 對比分析和顯著性結論
效果評估的可視化展示,平台沉澱了對比分析和顯著性結論等可視化組件。非常直觀的告知實驗者,每個實驗方案相比對照方案整體提升幅度以及每日的漲跌幅。同時給出指標的置信區間和顯著性結論。
3. AA分析
平台提供的AA分析,目的是幫助實驗者驗證實際進入實驗的不同方案的人群,實驗前在業務核心指標上是否存在顯著差異,輔助實驗者判斷實驗結論是否可靠。
4.分流實時監控
可以直觀的看到實時分流的效果,針對流量異常可以及時人工干預和解決。
3.3 【實驗分流服務】
1. 多端接入服務
平台根據業務的不同訴求提供豐富的接入能力,如針對安卓客戶端的Android SDK、服務端的JAVA SDK、基於NGINX進行分流的H5實驗服務、dubbo/http服務,C++ SDK待建設。
2.實驗分流的方式
平台提供了穩定高效的在線實時分流服務。
-
【隨機分流】:根據用戶標識符基於哈希算法對人群進行隨機分組並分流
-
【指定人群分流】:實驗前圈定一撥人群並打上標籤進行分流
-
【協變量均勻分流】:在基於哈希算法對人群隨機分組的時候,雖然分組的人群數量等比例劃分,但是分組的人群分佈的指標存在不均勻的情況,導致實驗效果達不到預期。為了解決這個痛點,平台推出了協變量平衡算法,
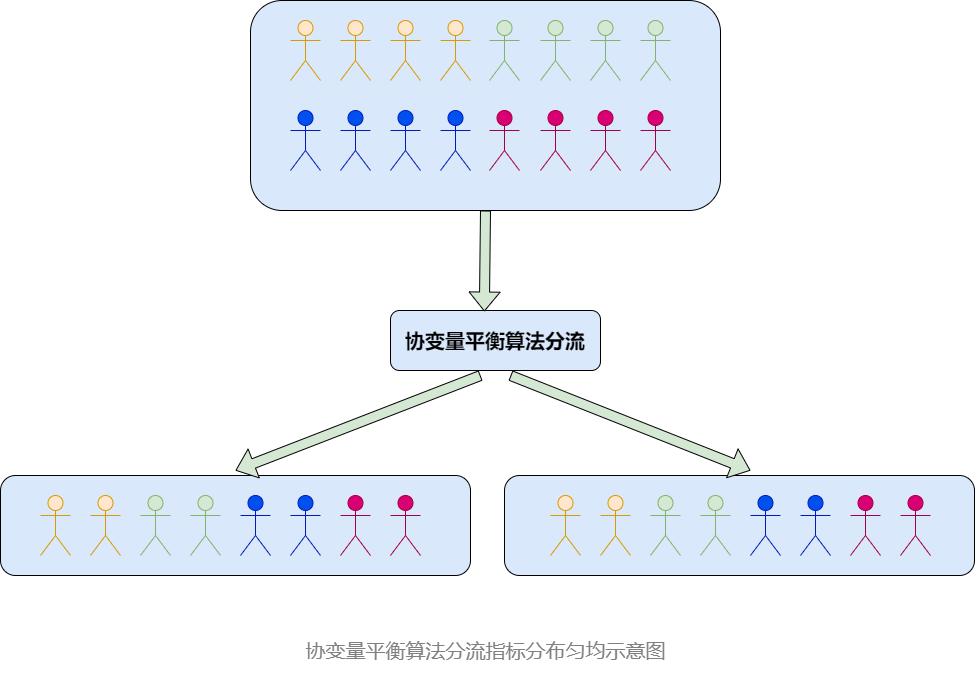
該算法能夠保證人群在進行分組樣本量均勻的同時,人群上指標分佈也是均勻的。
詳見本文:4. vivo霍金實驗平台實踐→4.1 協變量平衡算法 的詳細介紹。
-
【基於openresty web服務分流】:針對服務端非JAVA語言,對性能有着嚴苛要求的業務方,我們在NGINX基於OpenResty採用lua腳本實現了一套實驗分流功能,以http接口提供服務,平均響應時間小於1ms,p9999<20ms。
3.4 【分流數據處理服務】
採用公司統一的數據採集組件進行分流數據的採集、加工,並最終存儲至HDFS。
3.5【指標計算服務】
獨立的服務用於高效計算指標結果,同時配備了指標計算失敗重試和監控告警機制,有效的保證了指標計算成功率。
3.6【數據存儲】
主要是利用MySQL來進行業務數據的存儲,同時採用Ehcahe進行實驗配置的主要緩存,Redis作為輔助緩存,最後實驗分流的數據經過加工處理後保存到HDSF中,供後續的實驗數據分析使用。
四、霍金實踐
上面介紹了霍金的發展情況以及整體的系統架構,接下來介紹下在平台發展過程中遇到的問題以及對應的解決方案。
4.1 協變量平衡算法
4.1.1 遇到的問題
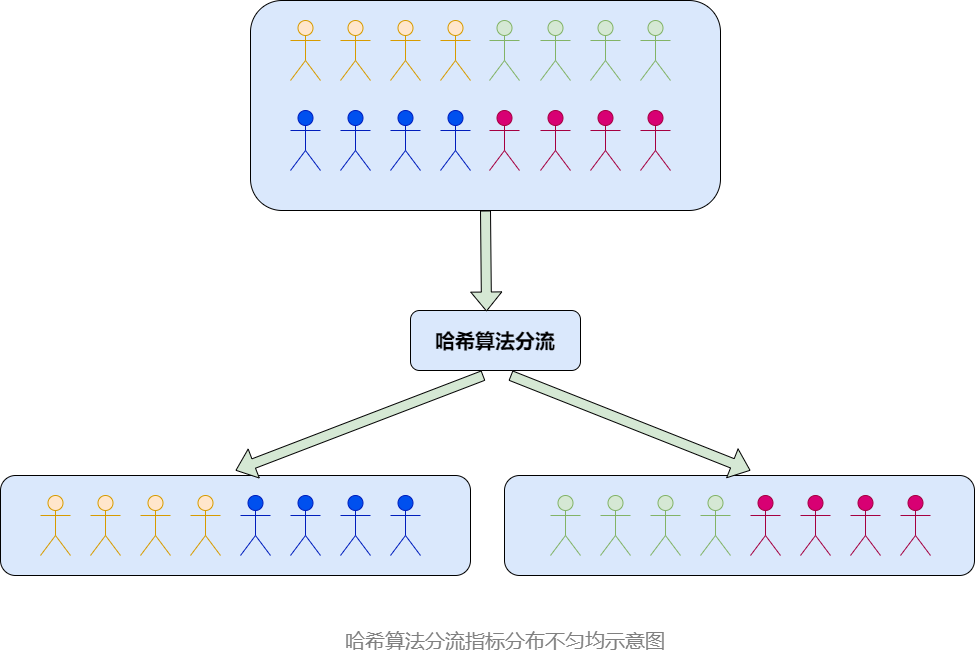
業務方在進行實驗對象分組的時候,最常用的做法是根據實驗對象的某個屬性進行哈希後對100取模,根據結果分到不同組。雖然hash算法分流可以做到尾號號段分佈均勻,但是分完組後,可能存在不同組的實驗對象在某些指標特徵上分佈不勻均,導致實驗效果評估不準確。如下圖所示(圖中四個不同顏色代表不同的人群以及對應的指標類型):
有沒有一種方式能夠實現對人群進行均勻分組的同時,保證人群對應的指標分佈也是均勻的呢,如下圖所示:
4.1.2 解決方案
1. 協變量平衡算法
該算法能夠保證對人群進行均勻分組的同時,人群對應的指標分佈也是均勻的。整體由三部分組成,示意圖如下:
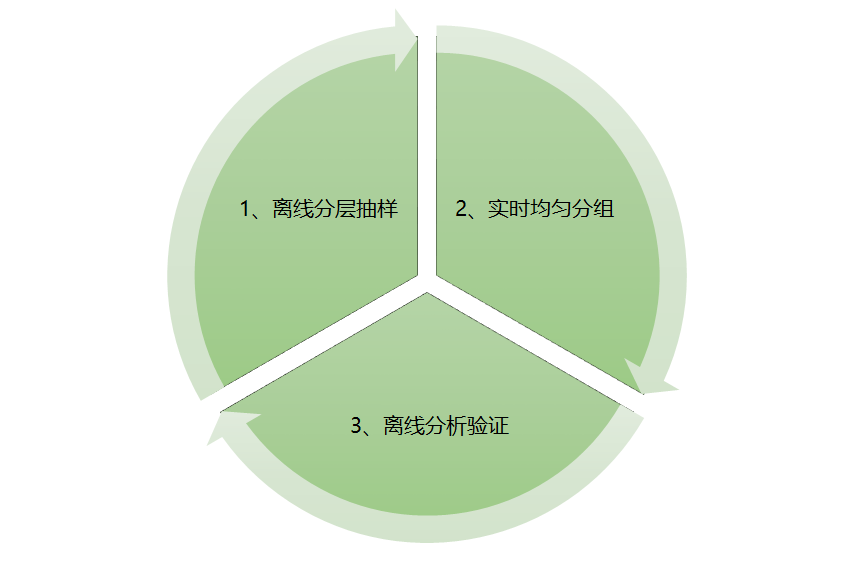
(1)離線分層抽樣
需要經歷如下3個步驟:
-
和業務方確定核心指標
-
採用等比例分層+Kmeans聚類模型完成指標對應的用戶的分層抽樣
-
將分層抽樣好的數據寫入hive庫相關表中
這裡介紹下等比例分層抽樣
等比例分層抽樣:
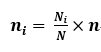
第i層應抽取的樣本數量;第i層的總體樣本數量;N 全體可用的流量總數;n 本次實驗設定的流量樣本數量
假設N為3kw,n為50w。按照以下維度進行分類:
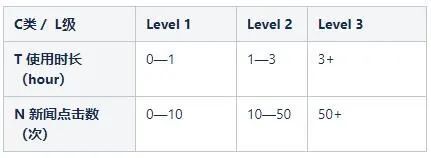
共有9種組合,確定每種組合別在總量中的佔比(總數N=3kw,通過在全體可用流量中篩取特定人群):
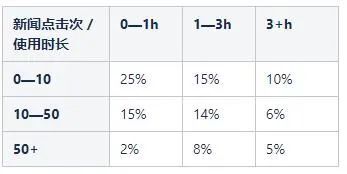
通過公式計算得到每層的樣本數量;對應分類的樣本數量(總樣本量60w):
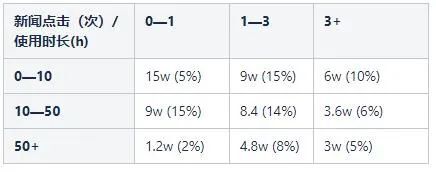
至此完成了整個離線分層抽樣的工作,接下來介紹下實時均勻分組。
(2)實時均勻分組
需要經歷如下4個步驟:
-
數據同步
通過配置的定時任務將準備好的分層抽樣數據由hive庫相關表同步至redis,數據包括每天的用戶標識符(uid,下同)到層的映射,以及每天每層所擁有的用戶佔比。
-
實驗創建
通過實驗編號,實驗組編號和每個實驗組的樣本量創建實驗。創建的實驗會與當前最新一天的用戶數據相關聯,通過 樣本量 * 層用戶佔比可以確定該層每個實驗組的樣本量。
-
實驗分流
通過實驗編號和用戶標識符(uid) 先找到用戶所在的層,之後將用戶均勻的分配到該層下的實驗組中,保證實驗組之間在不同層上分流的用戶均勻。如下圖所示:
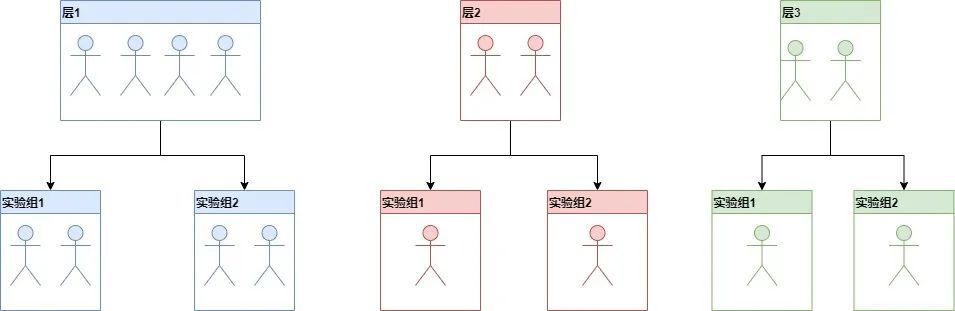
-
用戶數據刪除
因為我們採取的方案需要每天同步大量數據,所以對於無用的用戶數據需要及時刪除,增加資源利用率。
實時均勻分組整體流程圖如下:
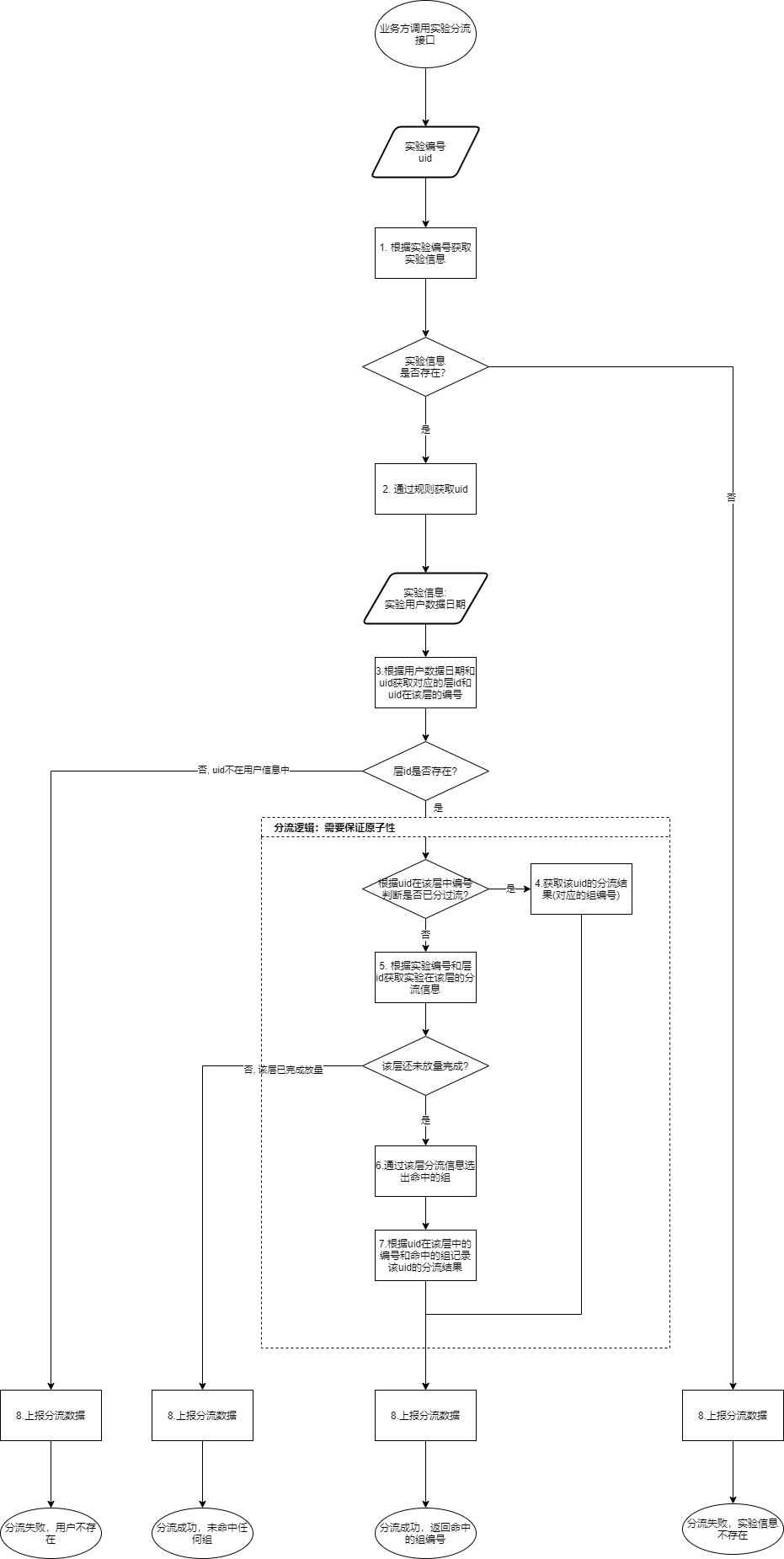
在做實時均勻分組的時候,面臨性能和存儲的壓力,為此我們分別設計了高性能分流方案和高內存利用率用戶信息存儲方案設計。
高性能分流方案
我們通過不同的redis數據結構和lua腳本完成層下桶的均勻分配
方案1
預先分配每一個桶的樣本量,每次選出當前樣本量最多的桶Redis結構:HASH,field為對應的桶編號,value為桶對應的當前樣本量
方案2
預先分配每一個桶的樣本量,每次選出當前樣本量最多的桶Redis結構:SORTED SET,key為對應的桶編號,score為桶對應的當前樣本量
方案3
通過當前層樣本量與桶大小取模選出命中的桶Redis結構:HASH
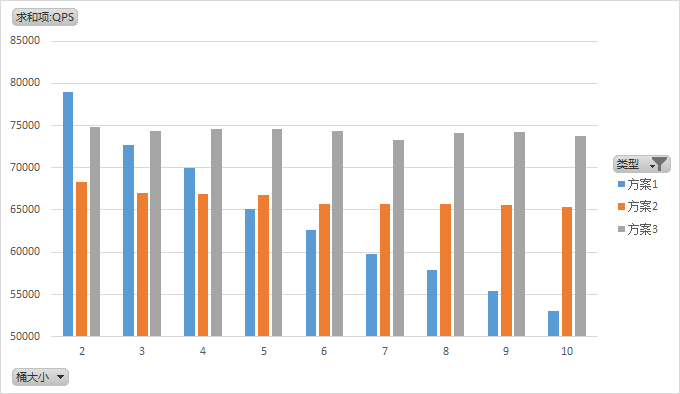
方案1:在只有兩個桶時擁有最高的性能,是方案3的1.05倍,但其性能隨着桶的增多而線性減少。方案2:擁有穩定的性能。方案3:擁有穩定的性能,但性能是方案2的1.12倍,是單GET請求性能的58%。
綜合考慮選擇方案3。
高內存利用率用戶信息存儲方案設計
uid-層的內存消耗對比
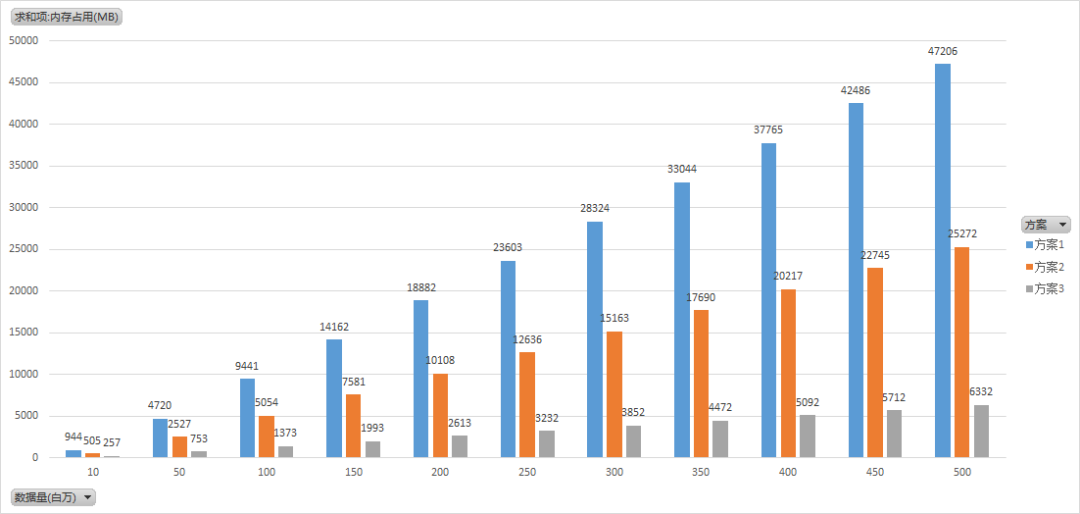
方案1:使用redis string存儲。方案2:分為10000個hash存儲。方案3:分為10000個一級桶,每個一級桶下有125個二級桶。
假設uid為15位數字,層id為2位數字,考慮過期時間,不考慮cluser模式下的額外消耗,不考慮malloc內存碎片和佔用。
綜合考慮選擇方案3。
(3)離線分析驗證
因為協變量算法實驗流程比較複雜,所以我們還是採用人工取數的方式進行實驗效果的分析。
4.2 Java SDK
4.2.1 遇到的問題
早期Java SDK的能力較弱,只提供了分流,需要接入方上報分流結果數據,對接入方而言改造成本較大;故當時主要以Dubbo接口對外分流服務,在服務內由平台服務端統一進行分流結果數據的上報。
隨着接入方越來越多,頻繁發生Dubbo線程池耗盡、或者因為網絡原因導致分流失敗的情況發生,導致分流體驗很差,影響實驗效果分析;面對上述問題,平台除了不斷地做性能優化外,還需要不停的對應用服務器等資源做擴容,造成一定的資源浪費。
4.2.2 解決方案
針對上述情況,霍金開發團隊經過充分的技術方案研究,對Java SDK進行了數次升級,成功解決上述問題。目前具備了實驗分流、分流結果的上報、實驗配置實時&增量更新、SDK自監控等核心功能,極大的提升了分流的穩定性和成功率。
4.2.3 SDK6大核心能力
1. 分流結果上報
在SDK內部依託公司的數據採集組件進行分流結果的上報。
2. 分流結果上報失敗的兜底方案
在進行分流上報的時候,因為數據鏈路無法保證數據100%的完整性,如果遇到機器宕機,業務服務異常,網絡異常等情況,實驗分流數據上報失敗,直接影響實驗效果分析。
如何保證在任何情況下實驗分流數據100%不丟失,為此霍金實驗平台設計了一套分流數據落磁盤的方案,作為異常場景的兜底措施,從而100%保證了數據的完整性,設計圖如下:
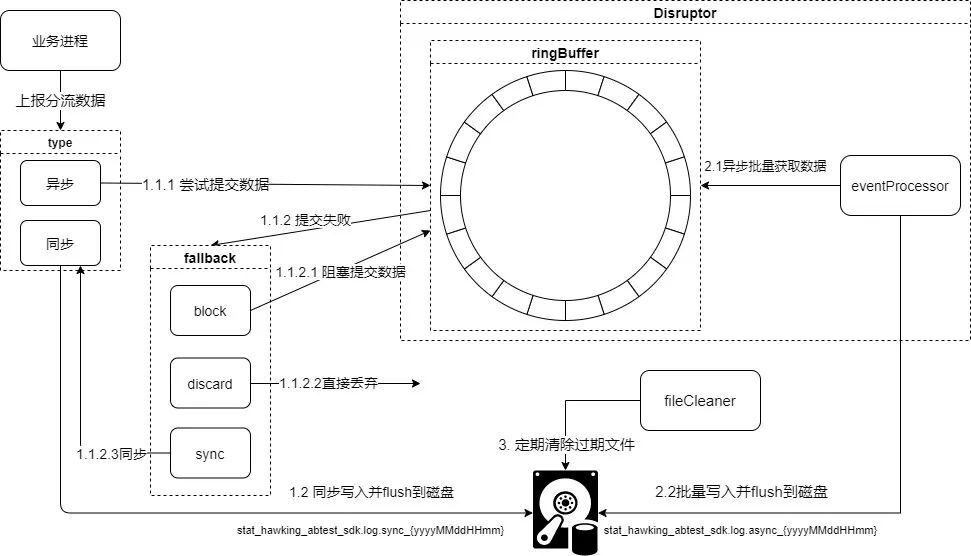
3. 實驗配置實時&增量更新
在通過定時任務拉取實驗配置至業務方本地緩存的方式外,還提供了實時和增量更新,適用於對實驗配置變更時效性要求高的業務,可以通過開關控制,動態生效,默認採用實時增量更新 + 定期全量更新,方便業務方靈活使用。下面是配置實時與增量更新的流程圖:
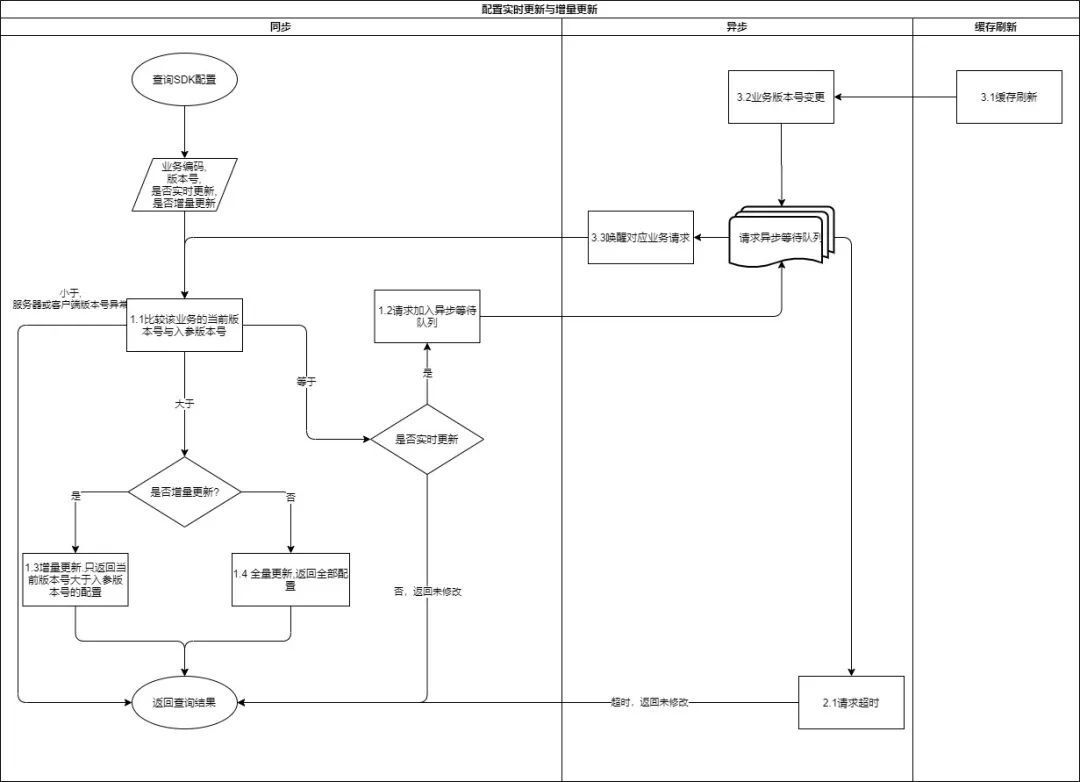
在實時更新發生失敗的情況下,我們設計了失敗退避策略:採用指數級失敗退避策略, 默認長輪詢的間隔為1s,每次失敗間隔增加2倍, 最大為60, 所以增長序列為1, 2, 4, 8, 16, 32, 60;每次成功將間隔置為1。
此外我們做了數據最終一致性的保證,保證SDK拉取配置時最終可以拉取到最新的配置,且不會出現配置回退:
-
實驗信息和模塊信息緩存的刷新是線性的。
-
同一次變更的實驗信息緩存的刷新在模塊信息緩存刷新之前(發送緩存刷新消息時保證實驗緩存刷新消息在模塊緩存刷新消息之前)。
-
模塊信息緩存的刷新時不會出現版本號跳躍問題(緩存方法入參加上版本號,刷新緩存時將數據庫的版本號與傳入的版本號對比,如果版本號不一致則打印日誌並使用傳入的版本號作為此次緩存刷新的版本號)。
-
SDK拉取配置並更新本地配置時,只更新拉取配置版本號大於等於本地配置版本號的配置
4. 多級配置管理
SDK 支持多級配置管理,優先級依次為:方法入參的配置(原有) > 業務方配置中心灰度配置 > 業務方配置中心配置 > 遠程默認配置 > 本地默認配置;業務方配置中心灰度配置是指在配置中心通過配置指定機器ip進行功能灰度。
5. 分流策略兜底
採用SDK痛點之一是新增功能後需要業務方隨之升級,否則新功能無法使用,進而影響業務。為此霍金設計了一套兜底方案,在SDK中探測到新增的策略不存在時,通過dubbo泛化調用的方式訪問霍金服務器,保證分流功能正常;有效的保證業務方有充足的時間升級到最新版本,提升用戶體驗。
6. SDK監控告警
採用SDK的另一個痛點是SDK集成在業務方服務端的進程中,所打印的錯誤信息自己看不到,依賴業務方的反饋,顯得很被動,不能第一時間跟進處理和解決問題;針對這種情況,霍金實驗平台設計一套SDK自監控方案。
自監控數據按照時間精度預聚合後通過埋點域名上報到通用監控,自監控支持內銷,新加坡和印度環境。通過監控我們可以直觀的看到每個業務、實驗、SDK版本等維度是否存在錯誤信息,並根據相應維度配置告警,方便開發人員第一時間跟進處理和解決問題。
4.3 H5實驗
4.3.1 遇到的問題
業界在做H5實驗時,通常做法是開發H5 SDK,讓業務方前端引入。
存在如下幾個問題:
-
需要業務方前端做代碼改動進行適配
-
另外需要對實驗的頁面或者元素做遮罩,因存在頁面跳轉對用戶體驗有一定影響
-
實驗功能發生變化時,需要業務方升級H5 SDK
-
整個H5實驗接入周期比較長,存在一定的接入門檻
4.3.2 解決方案
那麼有沒有一種簡單快捷的方式,只需要接入方在後台配置完實驗就完成整個H5實驗的接入呢?為此霍金開發團隊設計了一套方案順利解決了該問題,整個H5實驗架構基於開源apisix搭建,業務方在霍金管理後台創建實驗時,所有基於nginx的路由配置全部自動化通過接口下發完成(配合工單審核),無需接入方在代碼層面做任何修改,無侵入性,大大提升業務方做H5實驗的效率。
這裡解釋下幾個名詞:
-
【公共VUA】:vivo unified access。vivo統一接入層,可以理解是後續替換nginx的產品,基於開源apisix搭建。
-
【霍金VUA】:為霍金單獨搭建的VUA平台,做H5實驗時,公共VUA將需要做實驗的頁面代理到霍金VUA,霍金VUA通過開發的霍金分流APISIX插件完成實驗分流。
-
【VUA變更平台】:基於NGINX的配置變更通過在該平台上可視化操作後下發至VUA平台(公共VUA/霍金VUA)。
(1)H5實驗的整體時序圖
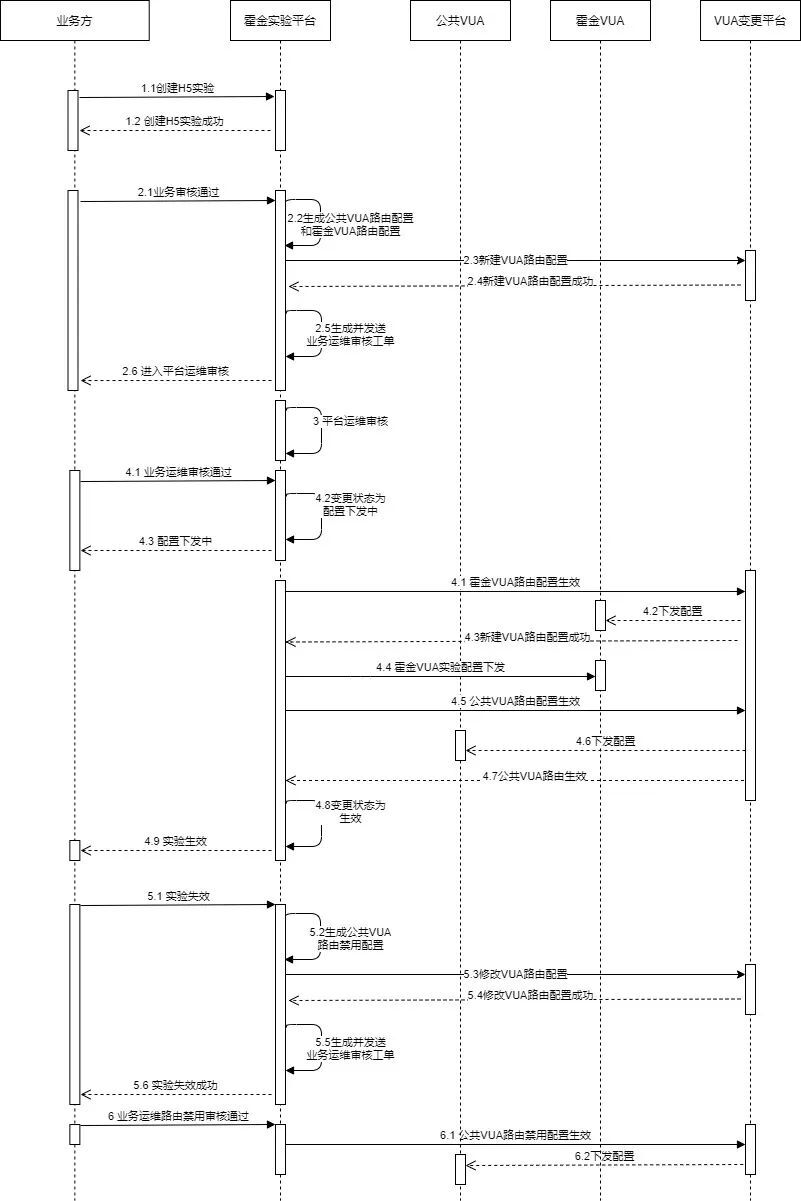
(2)NGINX → VUA 分流方案切換
公共VUA將需要做實驗的頁面代理到霍金VUA,霍金VUA通過開發的霍金實驗平台分流APISIX插件完成實驗分流。
多版本實驗分流
1)H5多版本實驗介紹
同一個url做實驗,通過霍金分流,不同用戶訪問到的url都是相同的,但是頁面訪問內容不同(因為多版本實驗是將頁面版本資源發佈到不同的機器上),然後通過霍金實驗平台分流訪問不同的資源。
2)H5多版本實驗分流原理
-
公共VUA將多版本實驗對應的靜態資源請求代理到霍金VUA。
-
霍金VUA通過APISIX插件 按照實驗配置選擇upstream並代理到對應的靜態資源服務器。
3)流程示意圖
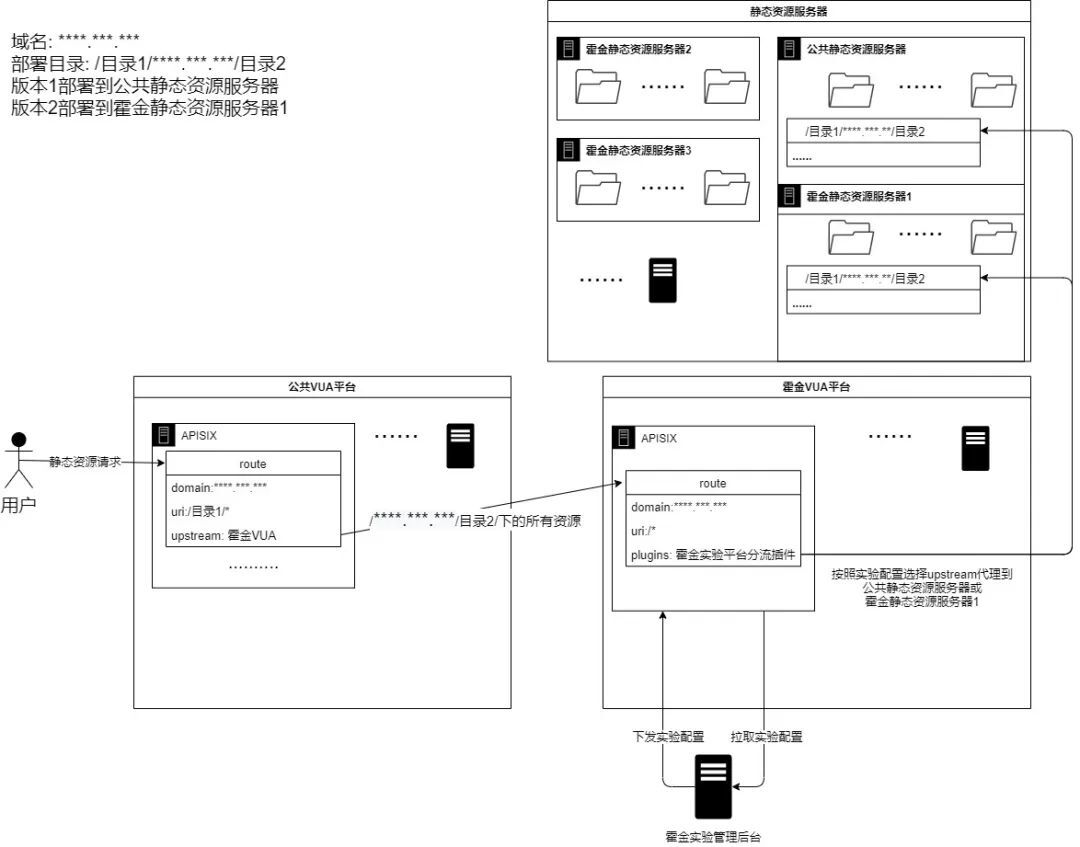
-
多版本實驗分流
-
多頁面實驗分流
-
霍金實驗平台分流APISIX插件
-
H5實驗的分流數據採集
多頁面實驗分流
1)H5多頁面實驗介紹
多個不同url做實驗,通過霍金分流,不同用戶訪問到不同的url頁面。
2)H5多頁面實驗原理
-
公共VUA將多頁面實驗對應的入口業務路徑的靜態資源請求代理到霍金VUA。
-
霍金VUA通過APISIX插件 按照實驗配置重寫路徑到不同的頁面。
3)流程示意圖
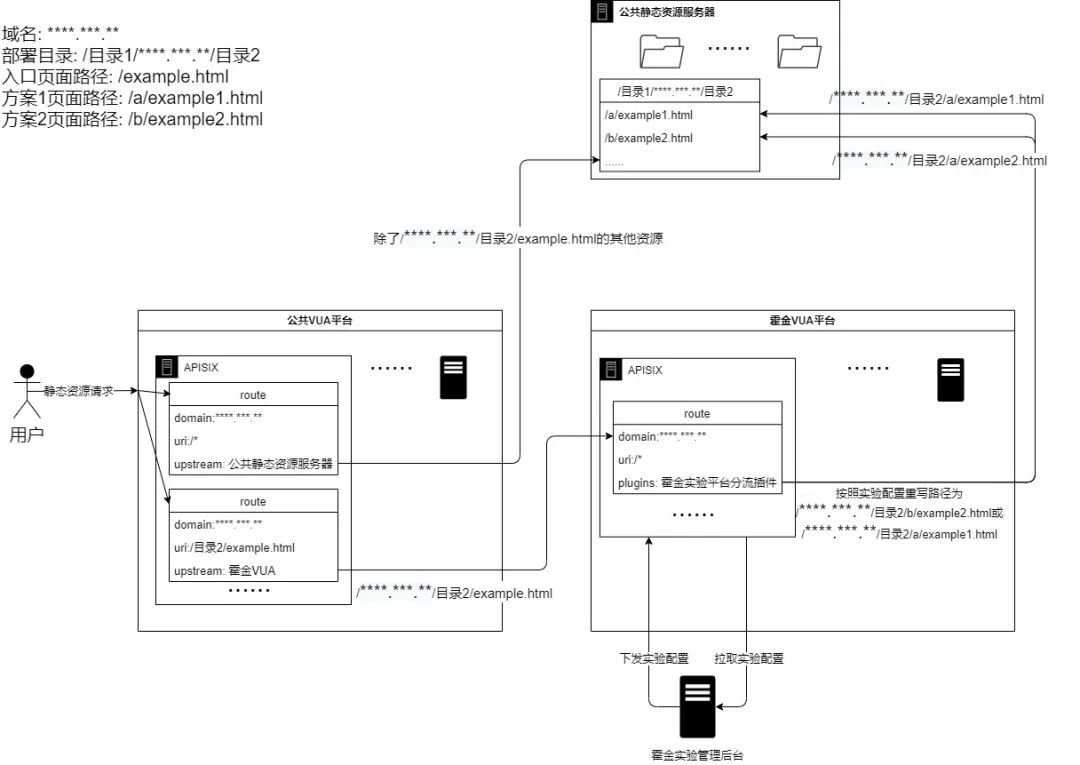
霍金實驗平台分流APISIX插件
流程示意圖如下:
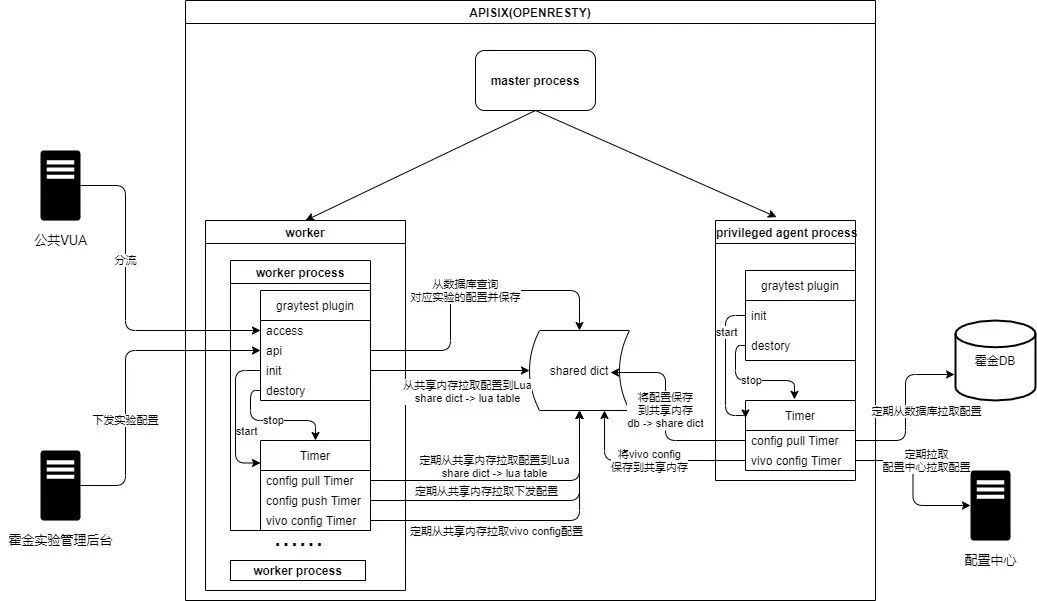
插件開發規範參考://apisix.apache.org/zh/docs/apisix/plugin-develop
H5實驗的分流數據採集
H5實驗的分流數據保存在霍金VUA平台的access_log中,經過如下幾個步驟最終存入HIVE庫的DW表中,供後續的數據分析使用。

五、實驗效果分析
該模塊包括指標服務、數據分析與效果展示、准實時指標計算、AA分析等功能,因篇幅有限,不在此展開。
六、總結與展望
本文主要通過介紹A/B實驗在vivo的平台化、產品化的建設和實踐,實現了以下的價值和能力:
-
用戶可在平台上完成創建實驗-數據分析-決策-調整實驗的閉環,操作簡單,靈活性高;
-
提供科學可靠的多層分流算法,流量可復用,無需發版即可快速驗證產品方案、運營策略、優化算法;
-
提供實時實驗分流監控、小時級的指標監控以及離線數據分析功能;
-
支持自定義指標,無需等待分析師開發報表,即配即查。
但還存在用戶體驗等問題,後續我們會重點在實驗流程,數據服務功能諸如指標配置(常用指標固化、指標配置簡化)和數據展示(交互優化、多維分析、歸因分析)等進行優化和完善,持續提升用戶體驗。
參考資料:
-
Overlapping Experiment Infrastructure:More, Better, Faster Experimentation
-
Java™ Servlet Specification(2.3.3.3 Asynchronous processing)


