JUC學習筆記——並發工具線程池
JUC學習筆記——並發工具線程池
在本系列內容中我們會對JUC做一個系統的學習,本片將會介紹JUC的並發工具線程池
我們會分為以下幾部分進行介紹:
- 線程池介紹
- 自定義線程池
- 模式之Worker Thread
- JDK線程池
- Tomcat線程池
- Fork/Join
線程池介紹
我們在這一小節簡單介紹一下線程池
線程池簡介
首先我們先來介紹線程池的產生背景:
- 在最開始我們對應每一個任務,都會創建一個線程,但該方法極度耗費資源
- 後來我們就產生了線程池,在線程池中規定存放指定數目的線程,由線程池的指定系統來控制接受任務以及處理任務的規定
我們給出一張線程池基本圖:
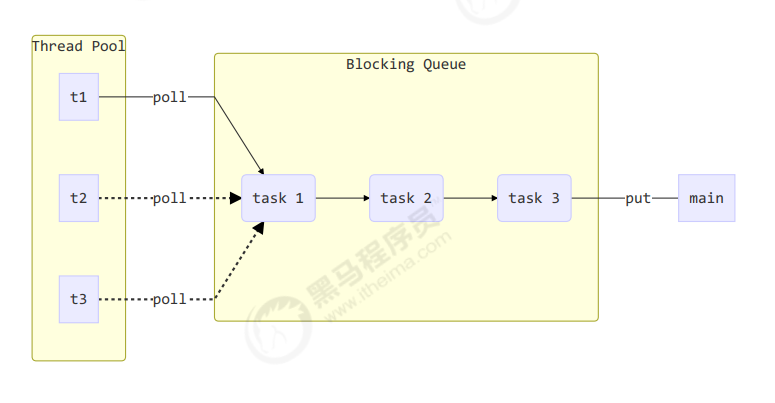
自定義線程池
我們在這一小節根據線程池基本圖來自定義一個線程池
自定義拒絕策略接口
我們先來介紹一下拒絕策略接口:
- 我們定義該接口是為了處理線程池中暫時無法接收的數據的內容
- 我們可以在該接口的抽象方法中重新定義各種處理方法,實現多種方法處理
- 我們直接定義一個接口,裏面只有一個方法,後續我們可以採用Lambda表達式或者方法來調用
我們給出拒絕策略接口代碼:
// 拒絕策略
// 這裡採用T來代表接收任務類型,可能是Runnable類型也可能是其他類型線程
// 這裡的reject就是抽象方法,我們後續直接採用Lambda表達式重新構造即可
// BlockingQueue是阻塞隊列,我們在後續創建;task是任務,我們直接傳入即可
@FunctionalInterface
interface RejectPolicy<T>{
void reject(BlockingQueue<T> queue,T task);
}
自定義任務隊列
我們來介紹一下任務隊列:
- 我們的任務隊列從根本上來說就是由隊列組成的
- 裏面會存放我們需要完成的任務,同時我們需要設置相關參數以及方法完成線程對任務的調取以及結束任務
我們給出任務隊列代碼:
class BlockingQueue<T>{
//阻塞隊列,存放任務
private Deque<T> queue = new ArrayDeque<>();
//隊列的最大容量
private int capacity;
//鎖
private ReentrantLock lock = new ReentrantLock();
//生產者條件變量
private Condition fullWaitSet = lock.newCondition();
//消費者條件變量
private Condition emptyWaitSet = lock.newCondition();
//構造方法
public BlockingQueue(int capacity) {
this.capacity = capacity;
}
//超時阻塞獲取
public T poll(long timeout, TimeUnit unit){
lock.lock();
//將時間轉換為納秒
long nanoTime = unit.toNanos(timeout);
try{
while(queue.size() == 0){
try {
//等待超時依舊沒有獲取,返回null
if(nanoTime <= 0){
return null;
}
//awaitNanos方法返回的是剩餘時間
nanoTime = emptyWaitSet.awaitNanos(nanoTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.pollFirst();
fullWaitSet.signal();
return t;
}finally {
lock.unlock();
}
}
//阻塞獲取
public T take(){
lock.lock();
try{
while(queue.size() == 0){
try {
emptyWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
T t = queue.pollFirst();
fullWaitSet.signal();
return t;
}finally {
lock.unlock();
}
}
//阻塞添加
public void put(T t){
lock.lock();
try{
while (queue.size() == capacity){
try {
System.out.println(Thread.currentThread().toString() + "等待加入任務隊列:" + t.toString());
fullWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().toString() + "加入任務隊列:" + t.toString());
queue.addLast(t);
emptyWaitSet.signal();
}finally {
lock.unlock();
}
}
//超時阻塞添加
public boolean offer(T t,long timeout,TimeUnit timeUnit){
lock.lock();
try{
long nanoTime = timeUnit.toNanos(timeout);
while (queue.size() == capacity){
try {
if(nanoTime <= 0){
System.out.println("等待超時,加入失敗:" + t);
return false;
}
System.out.println(Thread.currentThread().toString() + "等待加入任務隊列:" + t.toString());
nanoTime = fullWaitSet.awaitNanos(nanoTime);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println(Thread.currentThread().toString() + "加入任務隊列:" + t.toString());
queue.addLast(t);
emptyWaitSet.signal();
return true;
}finally {
lock.unlock();
}
}
// 獲得當前任務隊列長度
public int size(){
lock.lock();
try{
return queue.size();
}finally{
lock.unlock();
}
}
// 從形參接收拒絕策略的put方法
public void tryPut(RejectPolicy<T> rejectPolicy,T task){
lock.lock();
try{
if(queue.size() == capacity){
rejectPolicy.reject(this,task);
}else{
System.out.println("加入任務隊列:" + task);
queue.addLast(task);
emptyWaitSet.signal();
}
}finally {
lock.unlock();
}
}
}
自定義線程池
我們來介紹一下線程池:
- 線程池中用於存放線程Thread,用於完成任務隊列中的任務
- 我們需要設置相關參數,例如線程數量,存在時間,交互方法等內容
我們給出線程池代碼:
class ThreadPool{
//阻塞隊列
BlockingQueue<Runnable> taskQue;
//線程集合
HashSet<Worker> workers = new HashSet<>();
//拒絕策略
private RejectPolicy<Runnable> rejectPolicy;
//構造方法
public ThreadPool(int coreSize,long timeout,TimeUnit timeUnit,int queueCapacity,RejectPolicy<Runnable> rejectPolicy){
this.coreSize = coreSize;
this.timeout = timeout;
this.timeUnit = timeUnit;
this.rejectPolicy = rejectPolicy;
taskQue = new BlockingQueue<Runnable>(queueCapacity);
}
//線程數
private int coreSize;
//任務超時時間
private long timeout;
//時間單元
private TimeUnit timeUnit;
//線程池的執行方法
public void execute(Runnable task){
//當線程數大於等於coreSize的時候,將任務放入阻塞隊列
//當線程數小於coreSize的時候,新建一個Worker放入workers
//注意workers類不是線程安全的, 需要加鎖
synchronized (workers){
if(workers.size() >= coreSize){
//死等
//帶超時等待
//讓調用者放棄執行任務
//讓調用者拋出異常
//讓調用者自己執行任務
taskQue.tryPut(rejectPolicy,task);
}else {
Worker worker = new Worker(task);
System.out.println(Thread.currentThread().toString() + "新增worker:" + worker + ",task:" + task);
workers.add(worker);
worker.start();
}
}
}
//工作類
class Worker extends Thread{
private Runnable task;
public Worker(Runnable task){
this.task = task;
}
@Override
public void run() {
//巧妙的判斷
while(task != null || (task = taskQue.poll(timeout,timeUnit)) != null){
try{
System.out.println(Thread.currentThread().toString() + "正在執行:" + task);
task.run();
}catch (Exception e){
}finally {
task = null;
}
}
synchronized (workers){
System.out.println(Thread.currentThread().toString() + "worker被移除:" + this.toString());
workers.remove(this);
}
}
}
}
測試調用
我們給出自定義線程池的測試代碼:
public class ThreadPoolTest {
public static void main(String[] args) {
// 注意:這裡最後傳入的參數,也就是下面一大溜的方法就是拒絕策略接口,我們可以任意選擇,此外put和offer是已經封裝的方法
ThreadPool threadPool = new ThreadPool(1, 1000, TimeUnit.MILLISECONDS, 1, (queue,task)->{
//死等
// queue.put(task);
//帶超時等待
// queue.offer(task, 1500, TimeUnit.MILLISECONDS);
//讓調用者放棄任務執行
// System.out.println("放棄:" + task);
//讓調用者拋出異常
// throw new RuntimeException("任務執行失敗" + task);
//讓調用者自己執行任務
task.run();
});
for (int i = 0; i <3; i++) {
int j = i;
threadPool.execute(()->{
try {
System.out.println(Thread.currentThread().toString() + "執行任務:" + j);
Thread.sleep(1000L);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
}
模式之Worker Thread
我們在這一小節將介紹一種新的模式WorkThread
模式定義
首先我們給出Worker Thread的基本定義:
- 讓有限的工作線程(Worker Thread)來輪流異步處理無限多的任務。
- 也可以將其歸類為分工模式,它的典型實現就是線程池,也體現了經典設計模式中的享元模式。
- 注意,不同任務類型應該使用不同的線程池,這樣能夠避免飢餓,並能提升效率
我們給出一種具體的解釋:
- 例如,海底撈的服務員(線程),輪流處理每位客人的點餐(任務),如果為每位客人都配一名專屬的服務員,那 么成本就太高了(對比另一種多線程設計模式:Thread-Per-Message)
- 例如,如果一個餐館的工人既要招呼客人(任務類型A),又要到後廚做菜(任務類型B)顯然效率不咋地,分成 服務員(線程池A)與廚師(線程池B)更為合理,當然你能想到更細緻的分工
正常飢餓現象
首先我們先來展示沒有使用Worker Thread所出現的問題:
/*
例如我們採用newFixedThreadPool創建一個具有規定2的線程的線程池
如果我們不為他們分配職責,就有可能導致兩個線程都處於等待狀態而造成飢餓現象
- 兩個工人是同一個線程池中的兩個線程
- 他們要做的事情是:為客人點餐和到後廚做菜,這是兩個階段的工作
- 客人點餐:必須先點完餐,等菜做好,上菜,在此期間處理點餐的工人必須等待
- 後廚做菜:做菜
- 比如工人A 處理了點餐任務,接下來它要等着 工人B 把菜做好,然後上菜
- 但現在同時來了兩個客人,這個時候工人A 和工人B 都去處理點餐了,這時沒人做飯了,造成飢餓
*/
/*實際代碼展示*/
public class TestDeadLock {
static final List<String> MENU = Arrays.asList("地三鮮", "宮保雞丁", "辣子雞丁", "烤雞翅");
static Random RANDOM = new Random();
static String cooking() {
return MENU.get(RANDOM.nextInt(MENU.size()));
}
public static void main(String[] args) {
// 我們這裡創建一個固定線程池,裏面涵蓋兩個線程
ExecutorService executorService = Executors.newFixedThreadPool(2);
executorService.execute(() -> {
log.debug("處理點餐...");
Future<String> f = executorService.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜: {}", f.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
// 開啟下面代碼即兩人同時負責點餐
/*
executorService.execute(() -> {
log.debug("處理點餐...");
Future<String> f = executorService.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜: {}", f.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
*/
}
}
/*正確運行*/
17:21:27.883 c.TestDeadLock [pool-1-thread-1] - 處理點餐...
17:21:27.891 c.TestDeadLock [pool-1-thread-2] - 做菜
17:21:27.891 c.TestDeadLock [pool-1-thread-1] - 上菜: 烤雞翅
/*代碼注釋後運行*/
17:08:41.339 c.TestDeadLock [pool-1-thread-2] - 處理點餐...
17:08:41.339 c.TestDeadLock [pool-1-thread-1] - 處理點餐...
飢餓解決方法
如果想要解除之前的飢餓現象,正確的方法就是採用Worker Thread模式為他們分配角色,讓他們只專屬於一份工作:
/*代碼展示*/
public class TestDeadLock {
static final List<String> MENU = Arrays.asList("地三鮮", "宮保雞丁", "辣子雞丁", "烤雞翅");
static Random RANDOM = new Random();
static String cooking() {
return MENU.get(RANDOM.nextInt(MENU.size()));
}
public static void main(String[] args) {
// 我們這裡創建兩個線程池,分別包含一個線程,用於不同的分工
ExecutorService waiterPool = Executors.newFixedThreadPool(1);
ExecutorService cookPool = Executors.newFixedThreadPool(1);
// 我們這裡採用waiterPool線程池來處理點餐,採用cookPool來處理做菜
waiterPool.execute(() -> {
log.debug("處理點餐...");
Future<String> f = cookPool.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜: {}", f.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
// 無論多少線程他們都會正常運行
waiterPool.execute(() -> {
log.debug("處理點餐...");
Future<String> f = cookPool.submit(() -> {
log.debug("做菜");
return cooking();
});
try {
log.debug("上菜: {}", f.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
}
}
/*結果展示*/
17:25:14.626 c.TestDeadLock [pool-1-thread-1] - 處理點餐...
17:25:14.630 c.TestDeadLock [pool-2-thread-1] - 做菜
17:25:14.631 c.TestDeadLock [pool-1-thread-1] - 上菜: 地三鮮
17:25:14.632 c.TestDeadLock [pool-1-thread-1] - 處理點餐...
17:25:14.632 c.TestDeadLock [pool-2-thread-1] - 做菜
17:25:14.632 c.TestDeadLock [pool-1-thread-1] - 上菜: 辣子雞丁
線程池大小設計
最後我們來思考一下線程池大小的問題:
- 如果線程池設計過小,CPU利用不完善,並且同時任務過多,就會導致大量任務等待
- 如果線程池設計過大,CPU需要不斷進行上下文切換,也會耗費大量時間,導致速率反而降低
我們給出兩種形式下的線程池大小規範:
- CPU 密集型運算
/*
通常採用 `cpu 核數 + 1` 能夠實現最優的 CPU 利用率
+1 是保證當線程由於頁缺失故障(操作系統)或其它原因導致暫停時,額外的這個線程就能頂上去,保證 CPU 時鐘周期不被浪費
*/
- I/O 密集型運算
/*
CPU 不總是處於繁忙狀態,例如,當你執行業務計算時,這時候會使用 CPU 資源
但當你執行 I/O 操作時、遠程 RPC 調用時,包括進行數據庫操作時,這時候 CPU 就閑下來了,你可以利用多線程提高它的利用率。
經驗公式如下
`線程數 = 核數 * 期望 CPU 利用率 * 總時間(CPU計算時間+等待時間) / CPU 計算時間`
例如 4 核 CPU 計算時間是 50% ,其它等待時間是 50%,期望 cpu 被 100% 利用,套用公式
`4 * 100% * 100% / 50% = 8`
例如 4 核 CPU 計算時間是 10% ,其它等待時間是 90%,期望 cpu 被 100% 利用,套用公式
`4 * 100% * 100% / 10% = 40`
*/
JDK線程池
下面我們來介紹JDK中為我們提供的線程池設計
線程池構建圖
首先我們要知道JDK為我們提供的線程池都是通過Executors的方法來構造的
我們給出繼承圖:

其中我們所使用的線程創造類分為兩種:
- ScheduledThreadPoolExecutor是帶調度的線程池
- ThreadPoolExecutor是不帶調度的線程池
線程池狀態
我們首先給出線程池狀態的構造規則:
- ThreadPoolExecutor 使用 int 的高 3 位來表示線程池狀態,低 29 位表示線程數量
我們給出具體線程狀態:
| 狀態名 | 高3位 | 接收新任務 | 處理阻塞隊列任務 | 說明 |
|---|---|---|---|---|
| RUNNING | 111 | Y | Y | 正常運行 |
| SHUTDOWN | 000 | N | Y | 不會接收新任務,但會處理阻塞隊列剩餘 任務 |
| STOP | 001 | N | N | 會中斷正在執行的任務,並拋棄阻塞隊列 任務 |
| TIDYING | 010 | 任務全執行完畢,活動線程為 0 即將進入 終結 | ||
| TERMINATED | 011 | 終結狀態 |
從數字上比較,TERMINATED > TIDYING > STOP > SHUTDOWN > RUNNING (因為RUNNING為負數)
構造方法
我們給出線程池中ThreadPoolExecutor最完善的構造方法的參數展示:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
我們對上述各種類型進行一一介紹:
- corePoolSize 核心線程數目 (最多保留的線程數)
- maximumPoolSize 最大線程數目
- keepAliveTime 生存時間 – 針對救急線程
- unit 時間單位 – 針對救急線程
- workQueue 阻塞隊列
- threadFactory 線程工廠 – 可以為線程創建時起個好名字
- handler 拒絕策略
工作方式
我們首先給出工作方式展示圖:
subgraph 阻塞隊列
size=2
t3(任務3)
t4(任務4)
end
subgraph 線程池c-2,m=3
ct1(核心線程1)
ct2(核心線程2)
mt1(救急線程1)
ct1 –> t1(任務1)
ct2 –> t2(任務2)
end
t1(任務1)
style ct1 fill:#ccf,stroke:#f66,stroke-width:2px
style ct2 fill:#ccf,stroke:#f66,stroke-width:2px
style mt1 fill:#ccf,stroke:#f66,stroke-width:2px,stroke-dasharray:5,5
我們對此進行簡單解釋:
-
線程池中剛開始沒有線程,當一個任務提交給線程池後,線程池會創建一個新線程來執行任務。
-
當線程數達到 corePoolSize 並沒有線程空閑,這時再加入任務,新加的任務會被加入workQueue 隊列排 隊,直到有空閑的線程。
-
如果隊列選擇了有界隊列,那麼任務超過了隊列大小時,會創建 maximumPoolSize – corePoolSize 數目的線程來救急。
-
如果線程到達 maximumPoolSize 仍然有新任務這時會執行拒絕策略。
-
當高峰過去後,超過corePoolSize 的救急線程如果一段時間沒有任務做,需要結束節省資源,這個時間由keepAliveTime和unit來控制。
拒絕策略 jdk 提供了 4 種實現,其它著名框架也提供了實現:
- AbortPolicy 讓調用者拋出 RejectedExecutionException 異常,這是默認策略
- CallerRunsPolicy 讓調用者運行任務
- DiscardPolicy 放棄本次任務
- DiscardOldestPolicy 放棄隊列中最早的任務,本任務取而代之
- Dubbo 的實現,在拋出 RejectedExecutionException 異常之前會記錄日誌,並 dump 線程棧信息,方 便定位問題
- Netty 的實現,是創建一個新線程來執行任務
- ActiveMQ 的實現,帶超時等待(60s)嘗試放入隊列,類似我們之前自定義的拒絕策略
- PinPoint 的實現,它使用了一個拒絕策略鏈,會逐一嘗試策略鏈中每種拒絕策略
newFixedThreadPool
我們首先來介紹一下newFixedThreadPool:
- 創造一個具有固定線程大小的線程池
我們給出構造方法:
/*我們正常調用的方法*/
// 我們只需要提供線程數量nThreads,就會創建一個大小為nThreads的線程池
// 下面會返回一個相應配置的線程池,這裡的核心線程和最大線程都是nThreads,就意味着沒有救急線程,同時也不需要設置保存時間
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
/*底層實現方法*/
// 這和我們前面的構造方法是完全相同的
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
/*默認工廠以及默認構造線程的方法*/
// 對應上述構造方法中的默認工廠以及線程構造,主要是控制了命名以及優先級並設置不為守護線程等內容
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
/*默認拒絕策略:拋出異常*/
private static final RejectedExecutionHandler defaultHandler = new AbortPolicy();
我們最後給出具體特點:
- 核心線程數 == 最大線程數(沒有救急線程被創建),因此也無需超時時間
- 阻塞隊列是無界的,可以放任意數量的任務
- 適用於任務量已知,相對耗時的任務
newCachedThreadPool
我們首先來介紹一下newCachedThreadPool:
- 創造一個只有救急線程的線程池
我們給出構造方法:
/*調用方法*/
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
/*測試代碼*/
SynchronousQueue<Integer> integers = new SynchronousQueue<>();
new Thread(() -> {
try {
log.debug("putting {} ", 1);
integers.put(1);
log.debug("{} putted...", 1);
log.debug("putting...{} ", 2);
integers.put(2);
log.debug("{} putted...", 2);
} catch (InterruptedException e) {
e.printStackTrace();
}
},"t1").start();
sleep(1);
new Thread(() -> {
try {
log.debug("taking {}", 1);
integers.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
},"t2").start();
sleep(1);
new Thread(() -> {
try {
log.debug("taking {}", 2);
integers.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
},"t3").start();
/*輸出結果*/
11:48:15.500 c.TestSynchronousQueue [t1] - putting 1
11:48:16.500 c.TestSynchronousQueue [t2] - taking 1
11:48:16.500 c.TestSynchronousQueue [t1] - 1 putted...
11:48:16.500 c.TestSynchronousQueue [t1] - putting...2
11:48:17.502 c.TestSynchronousQueue [t3] - taking 2
11:48:17.503 c.TestSynchronousQueue [t1] - 2 putted...
我們給出newCachedThreadPool的特點:
- 核心線程數是 0, 最大線程數是 Integer.MAX_VALUE,救急線程的空閑生存時間是 60s,
- 意味着全部都是救急線程(60s 後可以回收)
- 救急線程可以無限創建
- 隊列採用了 SynchronousQueue 實現特點是,它沒有容量,沒有線程來取是放不進去的
- 整個線程池表現為線程數會根據任務量不斷增長,沒有上限
- 當任務執行完畢,空閑 1分鐘後釋放線 程。 適合任務數比較密集,但每個任務執行時間較短的情況
newSingleThreadExecutor
我們先來簡單介紹一下newSingleThreadExecutor:
- 希望多個任務排隊執行。線程數固定為 1,任務數多於 1 時,會放入無界隊列排隊。任務執行完畢,這唯一的線程 也不會被釋放。
我們給出構造方法:
/*構造方法*/
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
我們給出newSingleThreadExecutor的特點:
- 自己創建一個單線程串行執行任務,如果任務執行失敗而終止那麼沒有任何補救措施,而線程池還會新建一 個線程,保證池的正常工作
- Executors.newSingleThreadExecutor() 線程個數始終為1,不能修改
- FinalizableDelegatedExecutorService 應用的是裝飾器模式,在調用構造方法時將ThreadPoolExecutor對象傳給了內部的ExecutorService接口。只對外暴露了 ExecutorService 接口,因此不能調用 ThreadPoolExecutor 中特有的方法,也不能重新設置線程池的大小。
- Executors.newFixedThreadPool(1) 初始時為1,以後還可以修改
- 對外暴露的是 ThreadPoolExecutor 對象,可以強轉後調用 setCorePoolSize 等方法進行修改
提交任務
下面我們來介紹多種提交任務的執行方法:
/*介紹*/
// 執行任務
void execute(Runnable command);
// 提交任務 task,用返回值 Future 獲得任務執行結果
<T> Future<T> submit(Callable<T> task);
// 提交 tasks 中所有任務
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
throws InterruptedException;
// 提交 tasks 中所有任務,帶超時時間,時間超時後,會放棄執行後面的任務
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException;
// 提交 tasks 中所有任務,哪個任務先成功執行完畢,返回此任務執行結果,其它任務取消
<T> T invokeAny(Collection<? extends Callable<T>> tasks)
throws InterruptedException, ExecutionException;
// 提交 tasks 中所有任務,哪個任務先成功執行完畢,返回此任務執行結果,其它任務取消,帶超時時間
<T> T invokeAny(Collection<? extends Callable<T>> tasks,
long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
/*submit*/
// 測試代碼
private static void method1(ExecutorService pool) throws InterruptedException, ExecutionException {
Future<String> future = pool.submit(() -> {
log.debug("running");
Thread.sleep(1000);
return "ok";
});
log.debug("{}", future.get());
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService pool = Executors.newFixedThreadPool(1);
method1(pool);
}
// 結果
18:36:58.033 c.TestSubmit [pool-1-thread-1] - running
18:36:59.034 c.TestSubmit [main] - ok
/*invokeAll*/
// 測試代碼
private static void method2(ExecutorService pool) throws InterruptedException {
List<Future<String>> futures = pool.invokeAll(Arrays.asList(
() -> {
log.debug("begin");
Thread.sleep(1000);
return "1";
},
() -> {
log.debug("begin");
Thread.sleep(500);
return "2";
},
() -> {
log.debug("begin");
Thread.sleep(2000);
return "3";
}
));
futures.forEach( f -> {
try {
log.debug("{}", f.get());
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
});
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService pool = Executors.newFixedThreadPool(1);
method2(pool);
}
// 結果
19:33:16.530 c.TestSubmit [pool-1-thread-1] - begin
19:33:17.530 c.TestSubmit [pool-1-thread-1] - begin
19:33:18.040 c.TestSubmit [pool-1-thread-1] - begin
19:33:20.051 c.TestSubmit [main] - 1
19:33:20.051 c.TestSubmit [main] - 2
19:33:20.051 c.TestSubmit [main] - 3
/*invokeAny*/
private static void method3(ExecutorService pool) throws InterruptedException, ExecutionException {
String result = pool.invokeAny(Arrays.asList(
() -> {
log.debug("begin 1");
Thread.sleep(1000);
log.debug("end 1");
return "1";
},
() -> {
log.debug("begin 2");
Thread.sleep(500);
log.debug("end 2");
return "2";
},
() -> {
log.debug("begin 3");
Thread.sleep(2000);
log.debug("end 3");
return "3";
}
));
log.debug("{}", result);
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService pool = Executors.newFixedThreadPool(3);
//ExecutorService pool = Executors.newFixedThreadPool(1);
method3(pool);
}
// 結果
19:44:46.314 c.TestSubmit [pool-1-thread-1] - begin 1
19:44:46.314 c.TestSubmit [pool-1-thread-3] - begin 3
19:44:46.314 c.TestSubmit [pool-1-thread-2] - begin 2
19:44:46.817 c.TestSubmit [pool-1-thread-2] - end 2
19:44:46.817 c.TestSubmit [main] - 2
19:47:16.063 c.TestSubmit [pool-1-thread-1] - begin 1
19:47:17.063 c.TestSubmit [pool-1-thread-1] - end 1
19:47:17.063 c.TestSubmit [pool-1-thread-1] - begin 2
19:47:17.063 c.TestSubmit [main] - 1
關閉線程池
我們給出關閉線程池的多種方法:
/*SHUTDOWN*/
/*
線程池狀態變為 SHUTDOWN
- 不會接收新任務
- 但已提交任務會執行完
- 此方法不會阻塞調用線程的執行
*/
void shutdown();
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 修改線程池狀態
advanceRunState(SHUTDOWN);
// 僅會打斷空閑線程
interruptIdleWorkers();
onShutdown(); // 擴展點 ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
// 嘗試終結(沒有運行的線程可以立刻終結,如果還有運行的線程也不會等)
tryTerminate();
}
/*shutdownNow*/
/*
線程池狀態變為 STOP
- 不會接收新任務
- 會將隊列中的任務返回
- 並用 interrupt 的方式中斷正在執行的任務
*/
List<Runnable> shutdownNow();
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 修改線程池狀態
advanceRunState(STOP);
// 打斷所有線程
interruptWorkers();
// 獲取隊列中剩餘任務
tasks = drainQueue();
} finally {
mainLock.unlock();
}
// 嘗試終結
tryTerminate();
return tasks;
}
/*其他方法*/
// 不在 RUNNING 狀態的線程池,此方法就返回 true
boolean isShutdown();
// 線程池狀態是否是 TERMINATED
boolean isTerminated();
// 調用 shutdown 後,由於調用線程並不會等待所有任務運行結束,因此如果它想在線程池 TERMINATED 後做些事情,可以利用此方法等待
// 一般task是Callable類型的時候不用此方法,因為futureTask.get方法自帶等待功能。
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
/*測試shutdown、shutdownNow、awaitTermination*/
// 代碼
@Slf4j(topic = "c.TestShutDown")
public class TestShutDown {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ExecutorService pool = Executors.newFixedThreadPool(2);
Future<Integer> result1 = pool.submit(() -> {
log.debug("task 1 running...");
Thread.sleep(1000);
log.debug("task 1 finish...");
return 1;
});
Future<Integer> result2 = pool.submit(() -> {
log.debug("task 2 running...");
Thread.sleep(1000);
log.debug("task 2 finish...");
return 2;
});
Future<Integer> result3 = pool.submit(() -> {
log.debug("task 3 running...");
Thread.sleep(1000);
log.debug("task 3 finish...");
return 3;
});
log.debug("shutdown");
pool.shutdown();
// pool.awaitTermination(3, TimeUnit.SECONDS);
// List<Runnable> runnables = pool.shutdownNow();
// log.debug("other.... {}" , runnables);
}
}
// 結果
#shutdown依舊會執行剩下的任務
20:09:13.285 c.TestShutDown [main] - shutdown
20:09:13.285 c.TestShutDown [pool-1-thread-1] - task 1 running...
20:09:13.285 c.TestShutDown [pool-1-thread-2] - task 2 running...
20:09:14.293 c.TestShutDown [pool-1-thread-2] - task 2 finish...
20:09:14.293 c.TestShutDown [pool-1-thread-1] - task 1 finish...
20:09:14.293 c.TestShutDown [pool-1-thread-2] - task 3 running...
20:09:15.303 c.TestShutDown [pool-1-thread-2] - task 3 finish...
#shutdownNow立刻停止所有任務
20:11:11.750 c.TestShutDown [main] - shutdown
20:11:11.750 c.TestShutDown [pool-1-thread-1] - task 1 running...
20:11:11.750 c.TestShutDown [pool-1-thread-2] - task 2 running...
20:11:11.750 c.TestShutDown [main] - other.... [java.util.concurrent.FutureTask@66d33a]
任務調度線程池
在『任務調度線程池』功能加入之前(JDK1.3),可以使用 java.util.Timer 來實現定時功能
Timer 的優點在於簡單易用,但由於所有任務都是由同一個線程來調度,因此所有任務都是串行執行的
同一時間只能有一個任務在執行,前一個 任務的延遲或異常都將會影響到之後的任務。
我們首先首先給出Timer的使用:
/*Timer使用代碼*/
public static void main(String[] args) {
Timer timer = new Timer();
TimerTask task1 = new TimerTask() {
@Override
public void run() {
log.debug("task 1");
sleep(2);
}
};
TimerTask task2 = new TimerTask() {
@Override
public void run() {
log.debug("task 2");
}
};
// 使用 timer 添加兩個任務,希望它們都在 1s 後執行
// 但由於 timer 內只有一個線程來順序執行隊列中的任務,因此『任務1』的延時,影響了『任務2』的執行
timer.schedule(task1, 1000);
timer.schedule(task2, 1000);
}
/*結果*/
20:46:09.444 c.TestTimer [main] - start...
20:46:10.447 c.TestTimer [Timer-0] - task 1
20:46:12.448 c.TestTimer [Timer-0] - task 2
我們再給出 ScheduledExecutorService 的改寫格式:
/*ScheduledExecutorService代碼書寫*/
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
// 添加兩個任務,希望它們都在 1s 後執行
executor.schedule(() -> {
System.out.println("任務1,執行時間:" + new Date());
try { Thread.sleep(2000); } catch (InterruptedException e) { }
}, 1000, TimeUnit.MILLISECONDS);
executor.schedule(() -> {
System.out.println("任務2,執行時間:" + new Date());
}, 1000, TimeUnit.MILLISECONDS);
/*結果*/
任務1,執行時間:Thu Jan 03 12:45:17 CST 2019
任務2,執行時間:Thu Jan 03 12:45:17 CST 2019
我們對其再進行更細節的測試分析:
/*scheduleAtFixedRate:任務執行時間超過了間隔時間*/
// 代碼
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
log.debug("start...");
pool.scheduleAtFixedRate(() -> {
log.debug("running...");
sleep(2);
}, 1, 1, TimeUnit.SECONDS);
// 結果
21:44:30.311 c.TestTimer [main] - start...
21:44:31.360 c.TestTimer [pool-1-thread-1] - running...
21:44:33.361 c.TestTimer [pool-1-thread-1] - running...
21:44:35.362 c.TestTimer [pool-1-thread-1] - running...
21:44:37.362 c.TestTimer [pool-1-thread-1] - running...
/*scheduleWithFixedDelay:在任務完成的基礎上,設置時間間隔*/
// 代碼
ScheduledExecutorService pool = Executors.newScheduledThreadPool(1);
log.debug("start...");
pool.scheduleWithFixedDelay(()-> {
log.debug("running...");
sleep(2);
}, 1, 1, TimeUnit.SECONDS);
// 結果
21:40:55.078 c.TestTimer [main] - start...
21:40:56.140 c.TestTimer [pool-1-thread-1] - running...
21:40:59.143 c.TestTimer [pool-1-thread-1] - running...
21:41:02.145 c.TestTimer [pool-1-thread-1] - running...
21:41:05.147 c.TestTimer [pool-1-thread-1] - running...
我們給出ScheduledExecutorService適用範圍:
- 線程數固定,任務數多於線程數時,會放入無界隊列排隊。
- 任務執行完畢,這些線程也不會被釋放,用來執行延遲或反覆執行的任務
正確處理執行任務異常
我們針對異常在之前一般會選擇拋出或者無視,但這裡我們給出應對方法:
/*try-catch*/
// 代碼
ExecutorService pool = Executors.newFixedThreadPool(1);
pool.submit(() -> {
try {
log.debug("task1");
int i = 1 / 0;
} catch (Exception e) {
log.error("error:", e);
}
});
// 結果
21:59:04.558 c.TestTimer [pool-1-thread-1] - task1
21:59:04.562 c.TestTimer [pool-1-thread-1] - error:
java.lang.ArithmeticException: / by zero
at cn.itcast.n8.TestTimer.lambda$main$0(TestTimer.java:28)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
/*Future返回*/
// 我們在之前的提交任務中已經學習了submit等提交方法,當發異常時,這類返回對象Future將會返回異常信息
// 代碼
ExecutorService pool = Executors.newFixedThreadPool(1);
Future<Boolean> f = pool.submit(() -> {
log.debug("task1");
int i = 1 / 0;
return true;
});
log.debug("result:{}", f.get());
// 結果
21:54:58.208 c.TestTimer [pool-1-thread-1] - task1
Exception in thread "main" java.util.concurrent.ExecutionException:
java.lang.ArithmeticException: / by zero
at java.util.concurrent.FutureTask.report(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:192)
at cn.itcast.n8.TestTimer.main(TestTimer.java:31)
Caused by: java.lang.ArithmeticException: / by zero
at cn.itcast.n8.TestTimer.lambda$main$0(TestTimer.java:28)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
定時任務
我們進行一個簡單的實例展示:
/*任務:在每周四下午六點執行方法*/
/* 代碼 */
// 獲得當前時間
LocalDateTime now = LocalDateTime.now();
// 獲取本周四 18:00:00.000
LocalDateTime thursday =
now.with(DayOfWeek.THURSDAY).withHour(18).withMinute(0).withSecond(0).withNano(0);
// 如果當前時間已經超過 本周四 18:00:00.000, 那麼找下周四 18:00:00.000
if(now.compareTo(thursday) >= 0) {
thursday = thursday.plusWeeks(1);
}
// 計算時間差,即延時執行時間
long initialDelay = Duration.between(now, thursday).toMillis();
// 計算間隔時間,即 1 周的毫秒值
long oneWeek = 7 * 24 * 3600 * 1000;
ScheduledExecutorService executor = Executors.newScheduledThreadPool(2);
System.out.println("開始時間:" + new Date());
executor.scheduleAtFixedRate(() -> {
System.out.println("執行時間:" + new Date());
}, initialDelay, oneWeek, TimeUnit.MILLISECONDS);
Tomcat線程池
下面我們來介紹Tomcat中所使用的線程池
Tomcat線程池介紹
我們首先給出Tomcat線程運作的展示圖:
subgraph Connector->NIO EndPoint
t1(LimitLatch)
t2(Acceptor)
t3(SocketChannel 1)
t4(SocketChannel 2)
t5(Poller)
subgraph Executor
t7(worker1)
t8(worker2)
end
t1 –> t2
t2 –> t3
t2 –> t4
t3 –有讀–> t5
t4 –有讀–> t5
t5 –socketProcessor–> t7
t5 –socketProcessor–> t8
end
我們針對上述圖給出對應解釋:
- LimitLatch 用來限流,可以控制最大連接個數,類似 J.U.C 中的 Semaphore 後面再講
- Acceptor 只負責【接收新的 socket 連接】
- Poller 只負責監聽 socket channel 是否有【可讀的 I/O 事件】
- 一旦可讀,封裝一個任務對象(socketProcessor),提交給 Executor 線程池處理
- Executor 線程池中的工作線程最終負責【處理請求】
我們需要注意Tomcat針對原本JDK提供的線程池進行了部分修改:
-
Tomcat 線程池擴展了 ThreadPoolExecutor,行為稍有不同
- 如果總線程數達到 maximumPoolSize
- 這時不會立刻拋 RejectedExecutionException 異常
- 而是再次嘗試將任務放入隊列,如果還失敗,才拋出 RejectedExecutionException 異常
- 如果總線程數達到 maximumPoolSize
我們給出Tomcat相關配置信息:
- Connector 配置
| 配置項 | 默認值 | 說明 |
|---|---|---|
acceptorThreadCount |
1 | acceptor 線程數量 |
pollerThreadCount |
1 | poller 線程數量 |
minSpareThreads |
10 | 核心線程數,即 corePoolSize |
maxThreads |
200 | 最大線程數,即 maximumPoolSize |
executor |
– | Executor 名稱,用來引用下面的 Executor |
- Executor 線程配置
| 配置項 | 默認值 | 說明 |
|---|---|---|
threadPriority |
5 | 線程優先級 |
deamon |
true | 是否守護線程 |
minSpareThreads |
25 | 核心線程數,即corePoolSize |
maxThreads |
200 | 最大線程數,即 maximumPoolSize |
maxIdleTime |
60000 | 線程生存時間,單位是毫秒,默認值即 1 分鐘 |
maxQueueSize |
Integer.MAX_VALUE | 隊列長度 |
prestartminSpareThreads |
false | 核心線程是否在服務器啟動時啟動 |
Fork/Join
這一小節我們來介紹Fork/Join線程池思想
Fork/Join簡單介紹
我們首先來簡單介紹一下Fork/Join:
- Fork/Join 是 JDK 1.7 加入的新的線程池實現,它體現的是一種分治思想,適用於能夠進行任務拆分的 cpu 密集型運算
我們來介紹一下任務拆分:
- 所謂的任務拆分,是將一個大任務拆分為算法上相同的小任務,直至不能拆分可以直接求解。
- 跟遞歸相關的一些計 算,如歸併排序、斐波那契數列、都可以用分治思想進行求解
我們給出Fork/Join的一些思想:
-
Fork/Join 在分治的基礎上加入了多線程,可以把每個任務的分解和合併交給不同的線程來完成,進一步提升了運算效率
-
Fork/Join 默認會創建與 cpu 核心數大小相同的線程池
求和應用
我們給出一個簡單的應用題材來展示Fork/Join:
- 提交給 Fork/Join 線程池的任務需要繼承 RecursiveTask(有返回值)或 RecursiveAction(沒有返回值)
- 例如下 面定義了一個對 1~n 之間的整數求和的任務
我們給出對應代碼:
/*求和代碼*/
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(4);
System.out.println(pool.invoke(new AddTask1(5)));
}
@Slf4j(topic = "c.AddTask")
class AddTask1 extends RecursiveTask<Integer> {
int n;
public AddTask1(int n) {
this.n = n;
}
@Override
public String toString() {
return "{" + n + '}';
}
@Override
protected Integer compute() {
// 如果 n 已經為 1,可以求得結果了
if (n == 1) {
log.debug("join() {}", n);
return n;
}
// 將任務進行拆分(fork)
AddTask1 t1 = new AddTask1(n - 1);
t1.fork();
log.debug("fork() {} + {}", n, t1);
// 合併(join)結果
int result = n + t1.join();
log.debug("join() {} + {} = {}", n, t1, result);
return result;
}
}
/*求和結果*/
[ForkJoinPool-1-worker-0] - fork() 2 + {1}
[ForkJoinPool-1-worker-1] - fork() 5 + {4}
[ForkJoinPool-1-worker-0] - join() 1
[ForkJoinPool-1-worker-0] - join() 2 + {1} = 3
[ForkJoinPool-1-worker-2] - fork() 4 + {3}
[ForkJoinPool-1-worker-3] - fork() 3 + {2}
[ForkJoinPool-1-worker-3] - join() 3 + {2} = 6
[ForkJoinPool-1-worker-2] - join() 4 + {3} = 10
[ForkJoinPool-1-worker-1] - join() 5 + {4} = 15
15
/*改進代碼*/
public static void main(String[] args) {
ForkJoinPool pool = new ForkJoinPool(4);
System.out.println(pool.invoke(new AddTask3(1, 10)));
}
class AddTask3 extends RecursiveTask<Integer> {
int begin;
int end;
public AddTask3(int begin, int end) {
this.begin = begin;
this.end = end;
}
@Override
public String toString() {
return "{" + begin + "," + end + '}';
}
@Override
protected Integer compute() {
// 5, 5
if (begin == end) {
log.debug("join() {}", begin);
return begin;
}
// 4, 5
if (end - begin == 1) {
log.debug("join() {} + {} = {}", begin, end, end + begin);
return end + begin;
}
// 1 5
int mid = (end + begin) / 2; // 3
AddTask3 t1 = new AddTask3(begin, mid); // 1,3
t1.fork();
AddTask3 t2 = new AddTask3(mid + 1, end); // 4,5
t2.fork();
log.debug("fork() {} + {} = ?", t1, t2);
int result = t1.join() + t2.join();
log.debug("join() {} + {} = {}", t1, t2, result);
return result;
}
}
/*改進結果*/
[ForkJoinPool-1-worker-0] - join() 1 + 2 = 3
[ForkJoinPool-1-worker-3] - join() 4 + 5 = 9
[ForkJoinPool-1-worker-0] - join() 3
[ForkJoinPool-1-worker-1] - fork() {1,3} + {4,5} = ?
[ForkJoinPool-1-worker-2] - fork() {1,2} + {3,3} = ?
[ForkJoinPool-1-worker-2] - join() {1,2} + {3,3} = 6
[ForkJoinPool-1-worker-1] - join() {1,3} + {4,5} = 15
15
結束語
到這裡我們JUC的並發工具線程池就結束了,希望能為你帶來幫助~
附錄
該文章屬於學習內容,具體參考B站黑馬程序員滿老師的JUC完整教程
這裡附上視頻鏈接:08.001-本章內容_嗶哩嗶哩_bilibili


