《程序員數學:斐波那契》—— 為什麼不能用斐波那契散列,做數據庫路由算法?
- 2022 年 11 月 15 日
- 筆記
- CodeGuide | 程序員編碼指南, 哈希散列, 小傅哥, 數據庫路由, 數據結構, 斐波那契(Fibonacci)散列法
作者:小傅哥
博客://bugstack.cn
源碼://github.com/fuzhengwei/java-algorithms
沉澱、分享、成長,讓自己和他人都能有所收穫!😄
2022年,大促備戰進行中。因為了保障系統在流量洪峰下可以穩定運行,其中一條是需要對分庫分表的數據庫進行擴容,以滿足更大體量的業務承載能力。
但擴容計劃並不順利,因為擴容後的數據並沒有如預期散列到不同的庫表,而是集中到了數據庫的少部分表。擴容失敗。經檢查,因為這個數據庫路由算法並不是公司統一使用的算法,而是研發自己基於斐波那契散列實現的。那為什麼使用斐波那契散列會出現這樣的問題?
一、關於斐波那契
斐波那契的歷史
斐波那契數列出現在印度數學中,與梵文韻律有關。在梵語詩歌傳統中,人們對列舉所有持續時間為 2 單位的長 (L) 音節與 1 單位持續時間的短 (S) 音節並列的模式很感興趣。用給定的總持續時間計算連續 L 和 S 的不同模式會產生斐波那契數:持續時間m單位的模式數量是F(m + 1)。
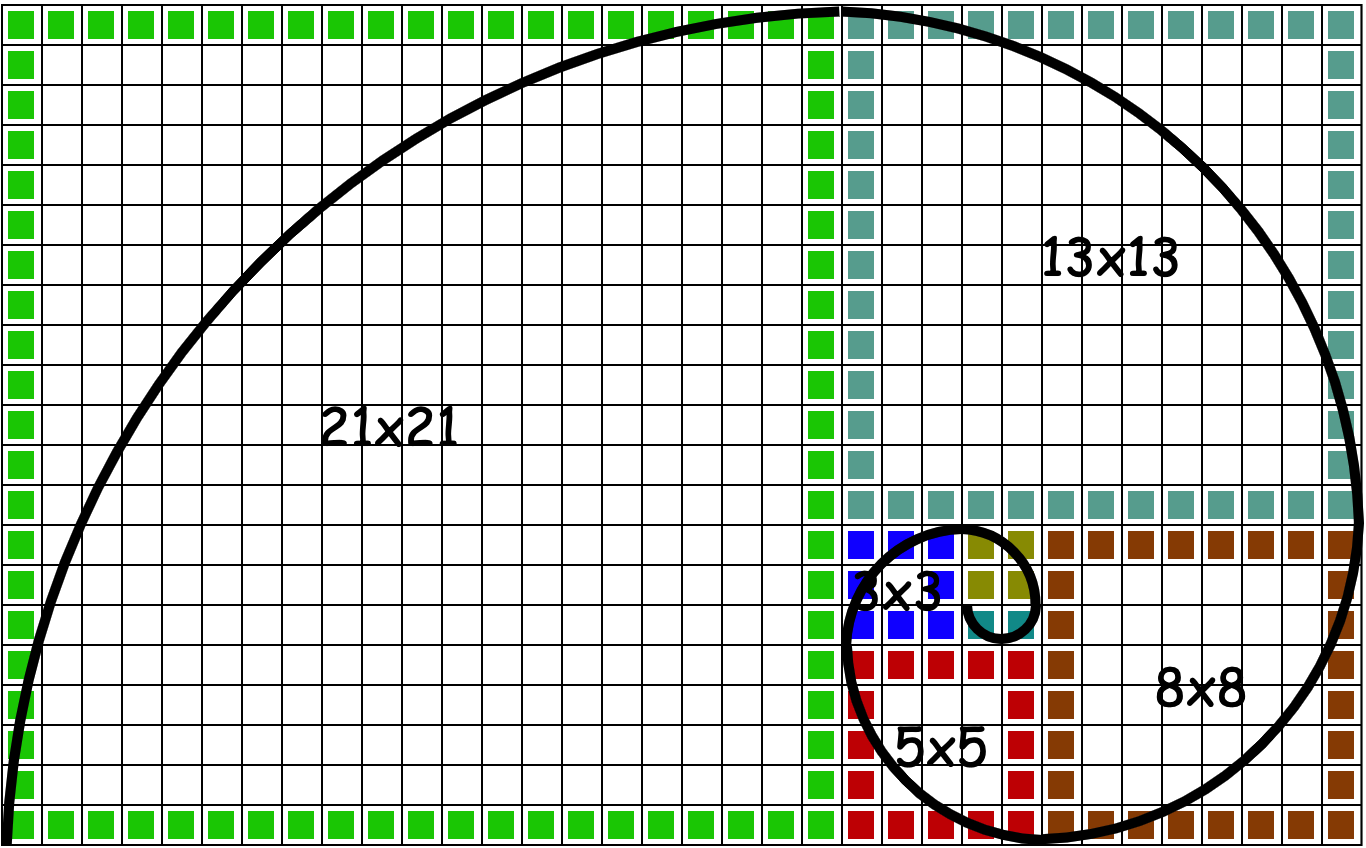
斐波那契數列可以由遞歸關係定義
F0 = 0,F1 = 1,Fn = Fn-1 + Fn-2
| F0 | F1 | F2 | F3 | F4 | F5 | F6 | F7 | F8 | F9 | F10 | F11 | F12 | F13 | F14 | F15 | F16 | F17 | F18 | F19 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 2 | 3 | 5 | 8 | 13 | 21 | 34 | 55 | 89 | 144 | 233 | 377 | 610 | 987 | 1597 | 2584 | 4181 |
- 從 F2 開始任意一位都是前兩位之和。
- 從 F2 開始任意一位與前一位相比的比值,都無限趨近於 (√5 – 1)/2 = 0.618 因此基於黃金分割的計算應用,也被稱為斐波那契應用。
那這個就是斐波那契的基本定義和特性,並且基於這樣的特性在計算機科學中,斐波那契常用於;偽隨機數生成、AVL二叉樹、最大公約數、合併排序算法等。
而大部分程序員👨🏻💻包括小傅哥最開始意識到斐波那契的應用則來自於,Java 源碼 ThreadLocal 中 HASH_INCREMENT = 0x61c88647 這樣一個常量的定義。因為這用作數據散列的特殊值 0x61c88647 就是基於黃金分割點計算得來的,公式: (1L << 32) - (long) ((1L << 32) * (Math.sqrt(5) - 1))/2 。
那麼既然 ThreadLocal 是基於斐波那契散列計算的下標索引,那為啥數據庫路由算法不能使用同樣的方式計算散列索引呢?因為通過驗證可以得知,斐波那契散列並不滿足嚴格的雪崩標準(SAC)。接下來小傅哥就帶着大家一起來使用數據驗證下。
二、斐波那契計算
斐波那契數列可以通過循環、遞歸以及封閉式表達式(比奈公式) 的方式進行計算。讀者可在單元測試中驗證://github.com/fuzhengwei/java-algorithms
1. 循環計算
public double fibonacci(int n) {
double currentVal = 1;
double previousVal = 0;
if (n == 1) return 1;
int iterationsCounter = n - 1;
while (iterationsCounter > 0) {
currentVal += previousVal;
previousVal = currentVal - previousVal;
iterationsCounter -= 1;
}
return currentVal;
}
2. 遞歸計算
public int fibonacciRecursion(int n) {
if (n == 1 || n == 2) {
return 1;
} else {
return (fibonacciRecursion(n - 1) + fibonacciRecursion(n - 2));
}
}
3. 比奈公式
public double fibonacciClosedForm(long position) {
int maxPosition = 75;
if (position < 1 || position > maxPosition) {
throw new RuntimeException("Can't handle position smaller than 1 or greater than 75");
}
double sqrt = Math.sqrt(5);
double phi = (1 + sqrt) / 2;
return Math.floor((Math.pow(phi, position)) / sqrt + 0.5);
}
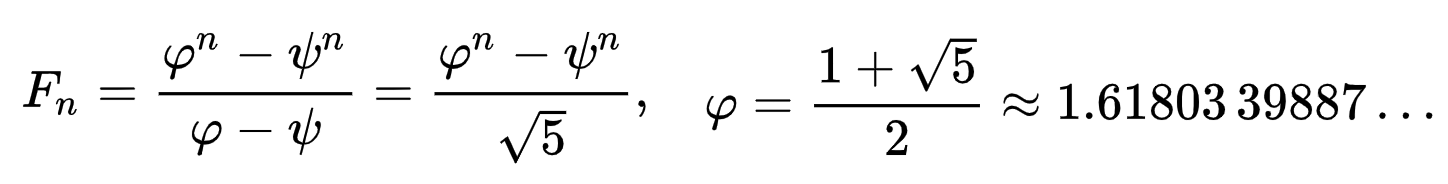
- 封閉式表達式:與由具有常數係數的線性遞歸定義的每個序列一樣,斐波那契數具有封閉形式的表達式。它被稱為比奈公式,以法國數學家雅克·菲利普·瑪麗·比內命名,儘管亞伯拉罕·德·莫弗和丹尼爾·伯努利已經知道它。
三、散列函數分類
散列函數(英語:Hash function)又稱散列算法、哈希函數,是一種將任意大小的數據映射到固定大小值的計算方式。散列函數計算結果被稱為散列值、散列碼,也就是對應的 HashMap 中哈希桶的索引以及數據庫中庫表的路由信息。
例如在 Java 中對數據的散列算法:HashMap 用到的是一次擾動函數下的哈希散列、ThreadLocal 用到的斐波那契散列。而通常數據庫路由組件用到的是整數模除法散列,這也是實踐中最簡單和最常用的方法之一。
接下來就給大家介紹這幾種常用的散列算法,其他更多散列可以參考 HashFunction
1. 除法散列
在用來設計散列函數的除法散列法中,通過取 K 除以 M 的餘數,將關鍵字 K 映射到 M 個槽中的某一個位置上,即散列函數為:h(K) = K mod M 表格大小通常是 2 的冪。
另外除法散列的一個顯着缺點是除法在大多數現代架構(包括 x86)上都是微編程的,並且可能比乘法慢 10 倍。
2. 乘法散列
乘法散列法整體包含兩步:
- 用關鍵字k乘上常數
A(0<A<1),並去除kA的小數部分 - 用m乘以這個值,再取結果的底
floor
公式:h(K)=Math.floor[m(aK mod 1)]
步驟:
- 假設某計算機的字長為 ww 位,而 kk 正好可容於一個字中
(k<2wk<2w) - 現在選取範圍
[0,2w]內的任意數值 ss,k×sk×s 即可用R1·2w+R0R1·2w+R0來表示 - 因此
(k·A)mod1=k·s/2w(k·A)mod1=k·s/2w就是將k×sk×s整體向右平移 ww 位,此時R0R0即為小數部分 - 再乘以 2m2m 相當於左移 mm 位,散列值
h(k)h(k)為 R0R0 的前 m 位。
乘法散列只需要單個整數乘法和右移,使其成為計算速度最快的哈希函數之一。但乘法散列可能會在變更計算因子後,較高值的輸入位不會影響較低值的輸出位,問題體現在元素分散不均,不滿足嚴格的雪崩標準。所以通常在會進行異或操作
乘法散列容易受到導致擴散不良的「常見錯誤」的影響——較高值的輸入位不會影響較低值的輸出位。在乘法步驟對此進行校正之前,輸入上的變換將保留的最高位的跨度向下移動,並將它們異或或加到鍵上。所以在輸入上的變換將保留的最高位的跨度向下移動,並將它們異或操作或者加到鍵上。例如 HashMap 的擾動函數。
3. 斐波那契散列
其實斐波那契散列是一種特殊形式的乘法散列,只不過它的乘法因子選擇的是一個黃金分割比例值,所以叫做斐波那契散列。
斐波那契散列的特性在於將「大數映射到小數」的計算結果在表空間上是均勻分佈的,且計算滿足乘法散列效率高。那為什麼並不能使用它作為數據庫路由算法呢?
四、雪崩標準測試
在數據庫路由實現方面,通常我們都是使用整數模除法散列求模的方式進行元素的索引計算。那既然乘法散列效率高,斐波那契散列分散均勻,為什麼不使用這樣的方式處理數據庫路由算法呢?
在檢索的資料中並沒有一個專門的文章來說明這一事項,這也倒置很多在學習過 HashMap、ThreadLocal 源碼的研發人員嘗試把這兩種源碼中的乘法散列算法搬到數據庫路由算法中使用。在保證每次擴容數據庫表都是2的次冪的情況下,並沒有出現什麼樣的問題。那麼對於這樣情況下,是否隱藏着什麼潛在的風險呢?
那麼為了證實斐波那契散列是否可以用在數據庫路由散列算法中,我們可以嘗試使用 嚴格雪崩標準(SAC) 進行驗證測試。
那麼什麼是嚴格雪崩標準( SAC ) ,在密碼學中,雪崩效應是密碼算法的理想屬性,通常是分組密碼和密碼散列函數,其中如果輸入發生輕微變化(例如,翻轉單個位),輸出會發生顯着變化(例如,50%輸出位翻轉)
SAC 建立在完整性和雪崩的概念之上,由 Webster 和 Tavares 於 1985 年引入。SAC 的高階概括涉及多個輸入位。滿足最高階 SAC 的最大非線性函數,也稱為「完全非線性」函數。
簡單來說,當我們對數據庫從8庫32表擴容到16庫32表的時候,每一個表中的數據總量都應該以50%的數量進行減少。這樣才是合理的。
好,那麼接下來我們就來做下雪崩測試;
- 準備10萬個單詞用作樣本數據。
- 對比測試除法散列、乘法散列、斐波那契散列。
- 基於條件1、2,對數據通過不同的散列算法分兩次路由到8庫32表和16庫32表中,驗證每個區間內數據的變化數量,是否在50%左右。
- 準備一個 excel 表,來做數據的統計計算。
測試代碼
public Map<Integer, Map<Integer, Integer>> hashFunction(int dbCount, int tbCount, Long hashIncrementVal, int hashType) {
int size = dbCount * tbCount;
System.out.print("庫數:" + dbCount + " 表數:" + tbCount + " 總值:" + size + " 冪值:" + Math.log(size) / Math.log(2));
int HASH_INCREMENT = (int) ((null == hashIncrementVal ? size : hashIncrementVal) * (Math.sqrt(5) - 1) / 2);
System.out.print(" 黃金分割:" + HASH_INCREMENT + "/" + size + " = " + (double) HASH_INCREMENT / size);
Map<Integer, Map<Integer, Integer>> map = new ConcurrentHashMap<>();
Set<String> words = FileUtil.readWordList("/Users/fuzhengwei/1024/github/java-algorithms/logic/src/main/java/math/fibonacci/103976個英語單詞庫.txt");
System.out.println(" 單詞總數:" + words.size() + "\r\n");
for (String word : words) {
int idx = 0;
switch (hashType) {
// 散列:斐波那契散列 int idx = (size - 1) & (word.hashCode() * HASH_INCREMENT + HASH_INCREMENT);
case 0:
idx = (word.hashCode() * HASH_INCREMENT) & (size - 1);
break;
// 散列:哈希散列 + 擾動函數
case 1:
idx = (size - 1) & (word.hashCode() ^ (word.hashCode() >>> 16));
break;
// 散列:哈希散列
case 2:
idx = (size - 1) & (word.hashCode()/* ^ (word.hashCode() >>> 16)*/);
break;
// 散列:整數求模
case 3:
idx = Math.abs(word.hashCode()) % size;
break;
}
// 計算路由索引
int dbIdx = idx / tbCount + 1;
int tbIdx = idx - tbCount * (dbIdx - 1);
// 保存路由結果
if (map.containsKey(dbIdx)) {
Map<Integer, Integer> dbCountMap = map.get(dbIdx);
if (dbCountMap.containsKey(tbIdx)) {
dbCountMap.put(tbIdx, dbCountMap.get(tbIdx) + 1);
} else {
dbCountMap.put(tbIdx, 1);
}
} else {
Map<Integer, Integer> dbCountMap = new HashMap<>();
dbCountMap.put(tbIdx, 1);
map.put(dbIdx, dbCountMap);
}
}
return map;
}
- 整個方法的目的在於得出不同的哈希算法,對10萬個單詞散列到指定的分庫分表中,所體現的結果。
1. 斐波那契散列
1.1 最小黃金分割
斐波那契散列也是乘法散列的一種體現形式,只不過它選擇了一個黃金分割點作為乘積因子。例如 ThreadLocal 中的 0x61c88647。但如果說我們只是按照一個指定範圍長度內做黃金分割計算,並拿這個結果當成乘法散列的因子,那麼10萬單詞將不會均勻的散列到8個庫,32張表內。如圖:
@Test
public void test_hashFunction_0_hash_null() {
Map<Integer, Map<Integer, Integer>> map = fibonacci.hashFunction(8, 32, null, 0);
Set<Integer> keys = map.keySet();
for (Integer key : keys) {
Collection<Integer> values = map.get(key).values();
for (Integer v : values) {
System.out.print(v + " ");
}
System.out.println();
}
}
庫數:8 表數:32 總值:256 冪值:8.0 黃金分割:2147483647/256 = 8388607.99609375 單詞總數:103976
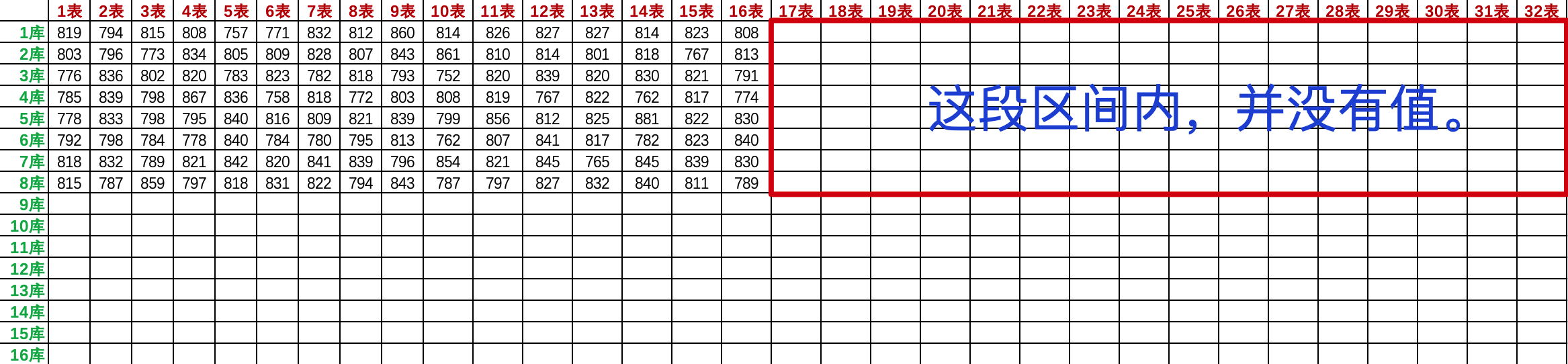
- 如果你的斐波那契散列值是根據庫表的值進行黃金切割的,那麼在最初的庫表範圍較小的階段,將有部分區域無法使用。這是因為得到的黃金分割點的二進制值沒法覆蓋整個區域,也就做不到合適的乘法散列計算。參考://bugstack.cn/md/algorithm/logic/math/2022-10-30-bits.html – 《程序員數學:位運算》
1.2 最小黃金分割
基於最小黃金分割的計算,是沒法做到均勻散列的。所以你看到的 ThreadLocal 默認就給你一個 0x61c88647 而不是隨着擴容長度實時計算的切割值。好那麼我們接下來也使用這個值來做計算,看看8庫到16庫後,數據的雪崩結果。
@Test
public void test_hashFunction_0() {
Map<Integer, Map<Integer, Integer>> map = fibonacci.hashFunction(8, 32, 1L << 32, 0);
Set<Integer> keys = map.keySet();
for (Integer key : keys) {
Collection<Integer> values = map.get(key).values();
for (Integer v : values) {
System.out.print(v + " ");
}
System.out.println();
}
}
- 分別測試 dbCount = 8、dbCount = 16
庫數:8 表數:32 總值:512 冪值:9.0 黃金分割:2147483647/512 = 4194303.998046875 單詞總數:103976
庫數:16 表數:32 總值:512 冪值:9.0 黃金分割:2147483647/512 = 4194303.998046875 單詞總數:103976
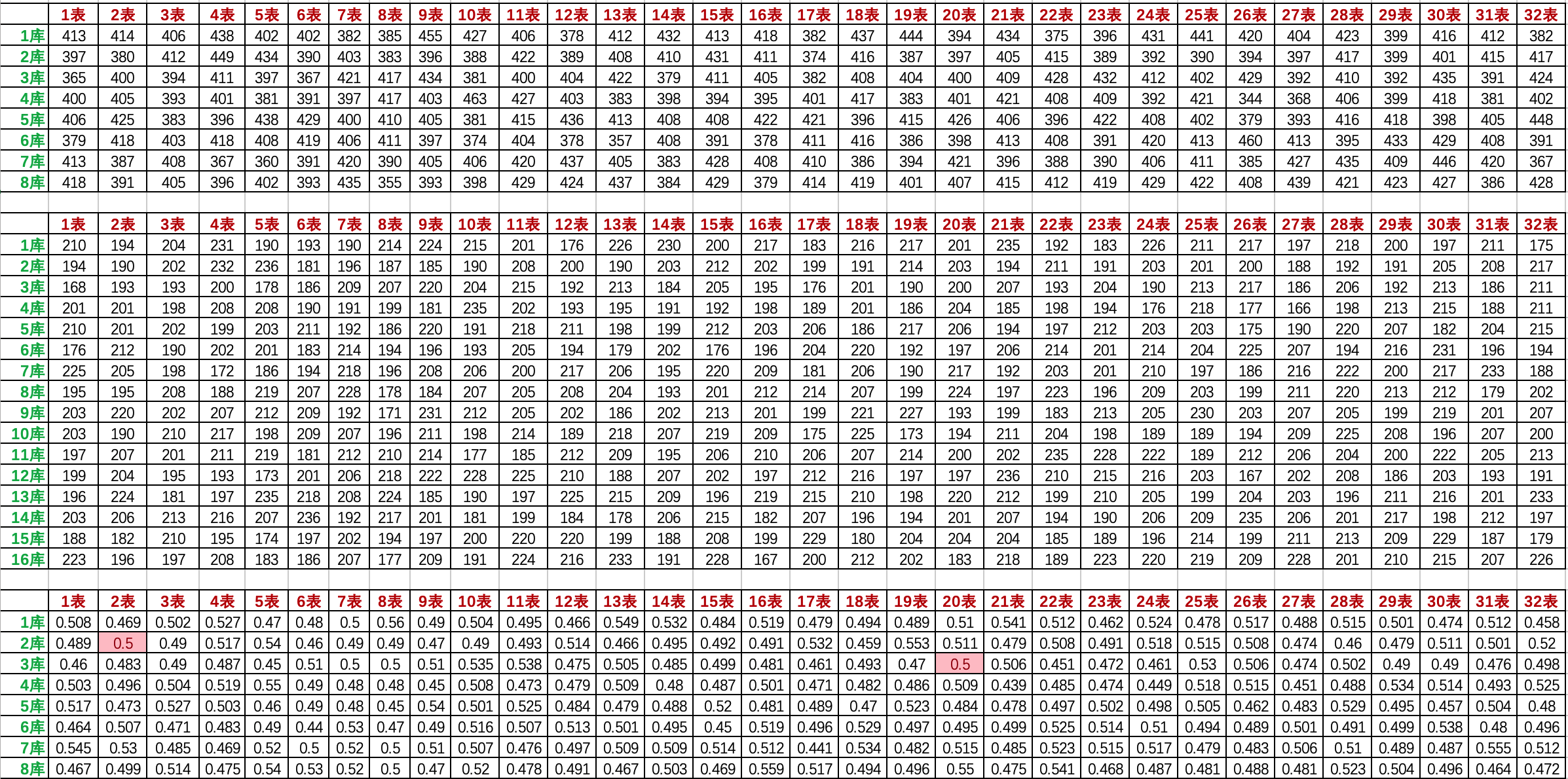
- 從8庫擴到16庫以後,滿足50%數據變化的,只有2庫2表和3庫20表。其他數據變化都不滿足嚴格的雪崩測試。
1.3 任意擴容庫表
通常情況下做分庫分表會考慮到以後的擴容操作,那如果說按照2的次冪擴容第一次是8庫32表,之後是16庫32表,在之後32庫32表。那麼這樣擴容下去,其實是扛不住的。所以大多數時候希望是從8庫擴到9庫,而不是一下翻倍。那我們來測試下9庫32表,斐波那契散列的分散效果。
Map<Integer, Map<Integer, Integer>> map = fibonacci.hashFunction(9, 32, 1L << 32, 0);
Set<Integer> keys = map.keySet();
for (Integer key : keys) {
Collection<Integer> values = map.get(key).values();
for (Integer v : values) {
System.out.print(v + " ");
}
System.out.println();
}
}
庫數:9 表數:32 總值:512 冪值:9.0 黃金分割:2147483647/512 = 4194303.998046875 單詞總數:103976

- 因為9庫不滿足2的次冪,也就沒法直接乘法散列。所以相當於斐波那契散列失效了。這如果是線上的生產環境,將發生災難性的事故。
2. 整數求模散列
2.1 基礎散列計算
整數求模以數據庫表總數為除數,與哈希值的絕對值進行除法散列計算。一般在數據庫路由中非常常用。另外如果根據用戶ID做散列路由,但由於ID長度波動範圍較大,則可以按照指定長度統一切割後使用。
@Test
public void test_hashFunction_3() {
Map<Integer, Map<Integer, Integer>> map = fibonacci.hashFunction(8, 32, null, 3);
Set<Integer> keys = map.keySet();
for (Integer key : keys) {
Collection<Integer> values = map.get(key).values();
for (Integer v : values) {
System.out.print(v + " ");
}
System.out.println();
}
}
- 分別測試 dbCount = 8、dbCount = 16
庫數:8 表數:32 總值:512 冪值:9.0 黃金分割:2147483647/512 = 4194303.998046875 單詞總數:103976
庫數:16 表數:32 總值:512 冪值:9.0 黃金分割:2147483647/512 = 4194303.998046875 單詞總數:103976
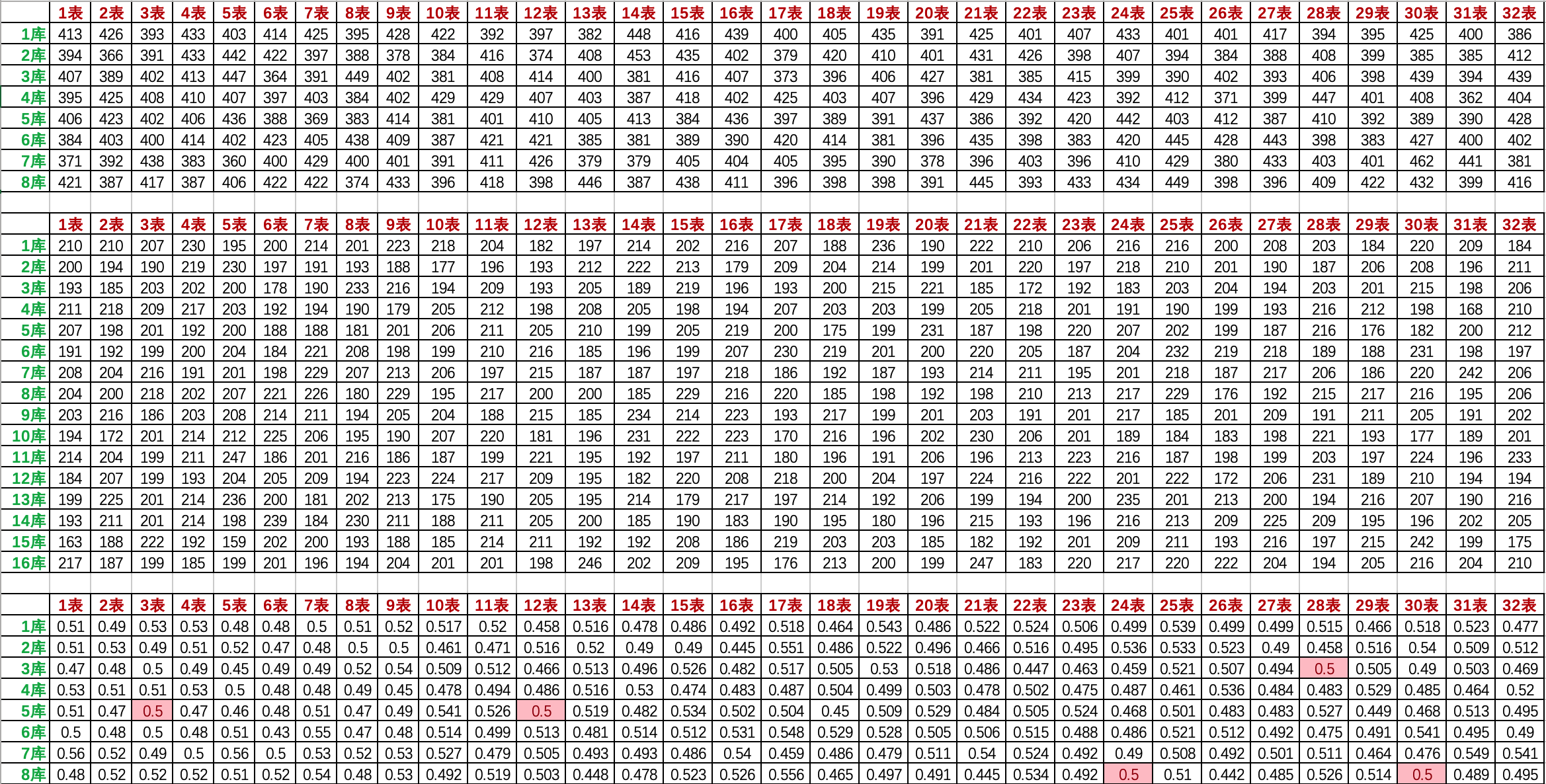
- 在使用除法散列方式後,滿足50%數據變化的有5個表。看着並不多,但這相當於是斐波那契散列下的3倍。同時其他表數據接近50%的也要大於斐波那契散列。
2.2 任意擴容計算
接下來我們任意從8庫擴容到9庫,看看數據的變化。
@Test
public void test_hashFunction_3() {
Map<Integer, Map<Integer, Integer>> map = fibonacci.hashFunction(9, 32, null, 3);
Set<Integer> keys = map.keySet();
for (Integer key : keys) {
Collection<Integer> values = map.get(key).values();
for (Integer v : values) {
System.out.print(v + " ");
}
System.out.println();
}
}
庫數:9 表數:32 總值:512 冪值:9.0 黃金分割:2147483647/512 = 4194303.998046875 單詞總數:103976
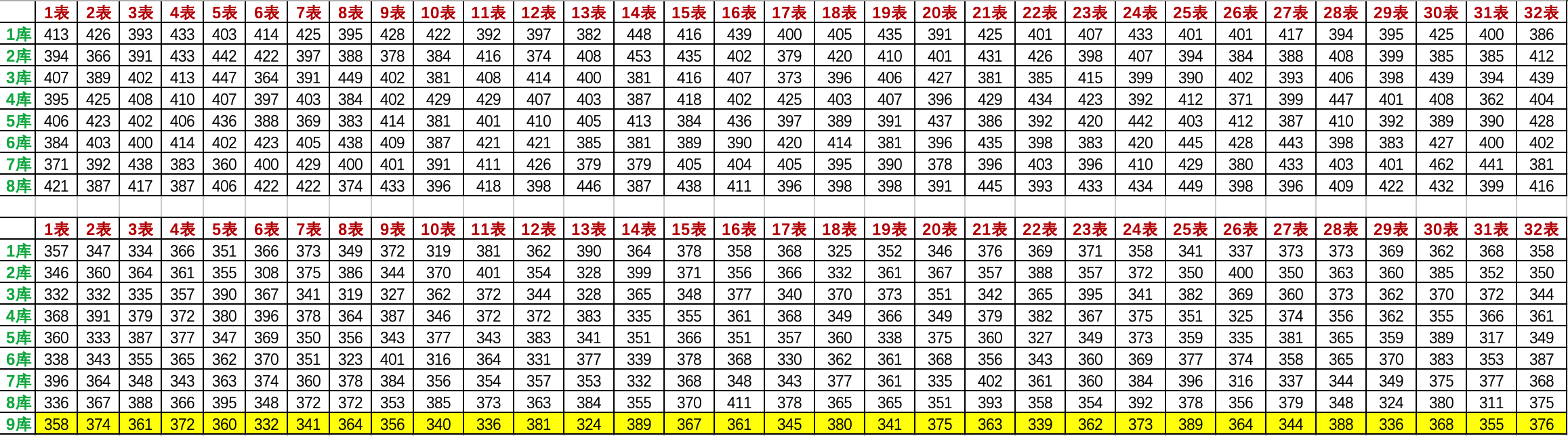
- 103976 / (9 * 32) ≈ 361,那麼也就說擴容後的數據,基本在361範圍波動,就滿足了均勻散列的目的。所以在數據庫散列算法中,除法散列是較靠譜且穩定的。
五、常見面試題
- 散列算法有哪些種?
- HashMap、ThreadLocal、數據庫路由都是用了什麼散列算法?
- 乘法散列為什麼要用2的冪值作為每次的擴容條件?
- 你有了解過
0x61c88647是怎麼計算的嗎? - 斐波那契散列的使用場景是什麼?
- The Fibonacci Association://en.wikipedia.org/wiki/The_Fibonacci_Association
- 哈希函數://en.wikipedia.org/wiki/Hash_function
- 斐波那契數://en.wikipedia.org/wiki/Fibonacci_number#Mathematics
- 散列函數://zh.wikipedia.org/wiki/%E6%95%A3%E5%88%97%E5%87%BD%E6%95%B8
- 雪崩效應://en.wikipedia.org/wiki/Avalanche_effect
- Fibonacci Hashing: The Optimization that the World Forgot (or: a Better Alternative to Integer Modulo)://probablydance.com/2018/06/16/fibonacci-hashing-the-optimization-that-the-world-forgot-or-a-better-alternative-to-integer-modulo/
- 斐波那契數://en.wikipedia.org/wiki/Fibonacci_number#Relation_to_the_golden_ratio
- C++ 中具有面向對象設計模式的數據結構和算法://book.huihoo.com/data-structures-and-algorithms-with-object-oriented-design-patterns-in-c++/html/page214.html

