沉浸式視聽體驗:全景聲技術是如何實現的?
- 2022 年 11 月 14 日
- 筆記
大眾對沉浸體驗的追求,不再僅局限於「視覺」。聲之切,境尤升。
隨着硬件技術的升級、軟件內容的豐富以及5G網絡環境的優化,推動幾經浮沉的VR產業走向正循環。
就在去年,「Roblox上市」、「Facebook更名為Meta」、「微軟收購暴雪」等將元宇宙相關產業推向風口,而Oculus Quest 2(VR一體機)出貨量破千萬台的成績,更是一件將沉浸式VR從概念落地場景實踐的標誌性事件。
在本次雲棲大會阿里雲視頻雲的8K VR視頻技術展台,體驗者通過佩戴Pico VR頭顯,感受清晰度高達8K的360度VR視頻,實時捕捉超高清細節。
不僅如此,體驗者還能以「聲」臨其境,感受令人驚艷的全景聲技術帶來的沉浸式視聽體驗。


01「視」之外的沉浸之「聲」
「沉浸式視聽體驗」一詞已多次出現在大眾視野,究竟什麼是沉浸式視聽體驗呢?
「沉浸式視聽體驗」是指通過視頻、音頻及特效系統,構建大視角、高畫質、三維聲特性,從而具備畫面包圍和聲音環繞的主觀感受特徵,觀眾在所處位置就能獲得周圍多方位的視覺、聽覺信息,帶來身臨其境之感。
聽覺作為僅次於視覺的重要感官通道,對沉浸式的視聽體驗至關重要。隨着用戶對視聽體驗的極致追求,在「視」之外,沉浸之「聲」技術應運而生。
「沉浸式音頻」是指能夠呈現空間的還音系統的聲輻射,至少能覆蓋觀眾的前、後、左、右、上五個方位。除此之外,還能真實地營造出聲場的水平縱深和垂直高度,即從聽者角度能精準地定位聲音的方向和位置。
從技術角度是如何實現呢?
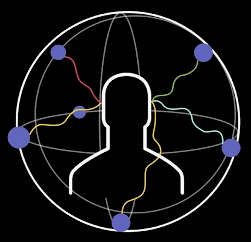
其實,真實世界的聲音來自環境的四面八方,人耳往往可以通過聲波的時間差、強度差、相位差、頻率差等辨別聲音的方位。
但現有的立體聲和5.1環繞聲只能呈現部分方向傳來的聲音信息,若想獲得聲音帶來的沉浸感,需要儘可能全方位再現真實世界的聲音,也需要一種沉浸式音頻技術來實現。

圖片來源於網絡
02一個「球面」的聲場?
沉浸式音頻主要技術有三大類: 基於聲道 Channel Based Audio(CBA)、基於對象Object Based Audio (OBA)、基於場景 Scene Based Audio(SBA)。
❖ 基於聲道技術(CBA):在傳統 5.1 環繞聲的基礎上,增加了 4 個頂部聲道,通過增加聲道的方式來補充空間中的聲音信息,但只能呈現部分方向來的聲音信息。
❖ 基於對象的技術(OBA):是目前主流技術,並在電影領域已廣泛應用,如 Dolby Atmos 全景聲。該技術會產生大量的數據和運算,除了聲道的音頻外,還有關於聲源的元數據Metadata,即:聲源(位置/大小/速度/形狀等屬性)、聲源所在的環境(混響Reverb/回聲Reflection/衰減Attenuate/幾何形態等),該技術在VR領域只適合主機VR上的大型遊戲,對於普通移動端的硬件設備來講,算力及帶寬承載具有較大壓力。
❖ 基於場景的技術(SBA):用來描述場景的聲場,其核心的底層算法是Ambisonics 技術,可被映射到任意揚聲器布局中。Ambisonics技術的特點是:聲源貼在提前渲染好的全景球上,即所有聲源將被壓縮在了這個球上。
圖片來源於網絡
本文的音頻體驗展示便採用了Ambisonics的錄製格式(文末體驗DEMO)。
Ambisonics作為全景聲的一種錄取格式,在上世紀70年代就已經問世,但一直沒有獲得商業上的成功。
隨着近幾年VR,AR等相關領域的興起,Ambisonics開始逐漸被討論。與其它多聲道環繞聲格式不同,Ambisonics傳輸通道不帶揚聲器信號,允許音頻工作者根據聲源方向而不是揚聲器的位置來思考設計,並且為聽眾提供了用於播放揚聲器的布局和數量,因此,大大增加了靈活性。
Ambisonics音頻格式可以解碼任何揚聲器陣列,並且可以完整地、不間斷地還原音源而不受任何特定編解碼播放系統的限制。
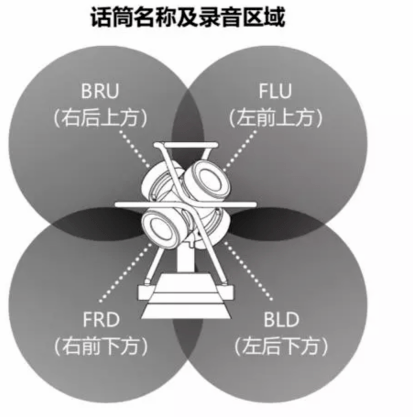
下圖是一個一階的Ambisonics結構,4個MIC垂直部署在一個四面體上,播放效果與Dolby Atmos類似,但和Dolby Atmos不同的地方是:Dolby Atmos 只解決了半球的聲場。
而Ambisonics除了水平環繞聲音,還可以支持拾音位置或者聽眾上下的聲源,即整個球面的聲場。

圖片來源於網絡
03實現聲聲入耳的引擎:AliBiAudio
全景聲不僅僅是增加幾個聲道那麼簡單,而是把整個聲音系統架構都顛覆了,從之前基於聲道來混音的技術上升為基於對象的音頻處理技術,使人在環境中的聽覺感受與現場實際聲音一致。
將全景聲音頻重建成用戶可測聽的形式有兩種途徑,一種是多揚聲器重建,即電影院或家庭影院中的音響系統,其本質是將全景聲音頻轉換到5.1.4或7.1.4格式;另一種是耳機重建,即將全景聲音頻通過雙耳渲染技術轉換為雙聲道音頻,並保留其全部空間信息。
相對於多揚聲器重建,耳機重建成本低、易部署、效果好。
不言而喻,耳機重建全景聲音頻,需要一個雙耳渲染的過程,以此來通過兩個立體聲通道創建空間和維度的聽覺感知效果。

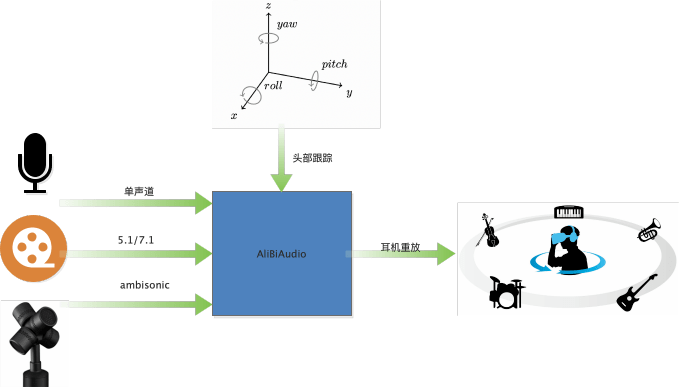
AliBiAudio 就是一個阿里自研的雙耳實時渲染引擎,結合頭部跟蹤坐標,可以達到人轉動,聲源位置不動的效果。當前雙耳渲染引擎,具有支持全平台、多場景、易部署等特性。該引擎既可以部署在移動端,也可以部署在雲端,並支持三大場景的渲染。
❖ 單聲道輸入:用於虛擬會議場景,可將不同位置的人,渲染在不同的角度發聲,通常部署在服務端。
❖ 5.1/7.1 輸入:用於影視劇渲染,得到更逼真的環繞聲,類似優酷中的「幀享」音效。既可以部署在端上(如:Apple Music 空間音頻),也可以部署在服務器上(如:作為媒體處理,將多聲道數據下混成2路數據)。
❖ Ambisonics輸入:對Ambisonics格式進行渲染,用於VR直播,VR點播,當前部署在Aliplay中。
04如何讓聲音跟隨腦袋一起搖擺
❖ HRTF
雙耳渲染引擎的核心模塊是人頭傳遞函數HRTF( Head-related Transfer Function )。
每一方向都有兩個HRTF,分別代表音源到左右耳的房間衝擊響應,通過720度掃描可以得到一個球形的HRTF庫,如下圖是一個ARI HRTF 數據庫的分佈。
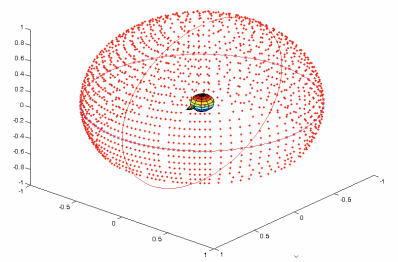
ARI HRTF 數據庫
在渲染時,通過輸入的角度信息,先從數據庫中選出當前角度的HRTF對。然後再將輸入數據分別和HRTF對進行卷積得到左右耳信號。為了得到更逼真效果,還可以添加一定量的房間混響如下圖所示:
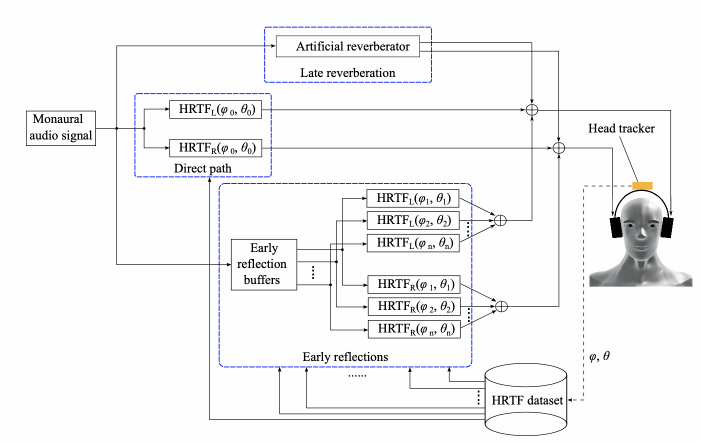
本項目對大量HRTF庫進行篩選,獲取到一個最優的數據庫。
❖ Ambisonics數據格式
Ambisonics 的基礎功能是讓來自不同方向點聲源,作為360度的球面來處理,這個中心點,就是麥克風放的位置。當前廣泛用於VR 和 360 度全景視頻的Ambisonics 格式,是一個叫做Ambisonics B-format的4聲道(還有另一種格式叫A-format)。由W, X, Y and Z組成。對應着360度球面的,中心,左右,前後,上下。
- W 是一個全向
- X 是一個雙極 8 字指向,代表前後
- Y 是一個雙極 8 字指向,代表左右
- Z 是一個雙極 8 字指向,代表上下
B-format 有兩種格式分別是ambix 和fuma(它們只是排列順序不同),而A-format 代表4個mic 採集的原始數據。B-format和A-format的關係如下:
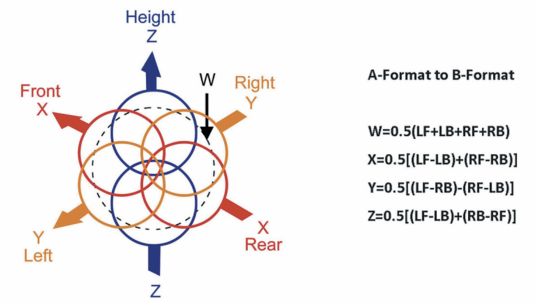
圖片來源於網絡
❖ 頭部跟蹤
該技術利用了某些特定款式耳機中的傳感器信息,如:加速度計和陀螺儀,從而更好地跟蹤頭部運動,並做出相應的音頻調整。
Apple已經從 iOS 15 開始通過兼容耳機帶來支持頭部跟蹤的空間音頻功能,目前Android 13的發佈預覽版已完全支持在兼容設備上使用頭部跟蹤的空間音頻。本次雲棲大會的展台體驗便主要利用了Pico頭顯設備中陀螺儀的信息。
圖片來源於網絡
05一起「聲」臨其境
「佩戴耳機」體驗全景聲,效果更好哦!
現場體驗中,聲音的變化會隨着頭部的轉動而轉動,本次線上DEMO體驗將依靠手動界面移動來模擬頭部轉動。
01聽:無人機掠過頭頂
無人機逐漸升起從頭頂掠過,當視角跟隨(模擬)無人機時,聲音相應地實時變化。
02聽:滴答滴答
聆聽水滴的同時,發現左方有無人機的聲音,視角隨聲而轉,一路跟隨,感受無人機由近及遠的變化。
03聽:沉浸遊園
主持人在介紹園區時,用戶向四周左右觀看(模擬),在此過程中,主持人的聲音呈現與他在你視角的位置始終保持對應。
04聽:PING PANG之聲
沉浸式場景怎能少了運動!一轉頭,乒乓之聲已被「拋之腦後」。
06音頻的未來,炫到無法想像
除此之外,全景聲雙耳渲染技術還可運用於多個場景,帶來沉浸視聽的無限想像力。
❖ VR演唱會
現場混合360度視頻和全景聲音頻, 同時將數據傳輸到相應的移動平台,並進行實時直播。讓觀眾可以達到「不在現場,勝似現場」的感覺。

❖ 沉浸式影院
也可以稱之為沉浸式投影,是一種成熟的高度沉浸式虛擬現實系統。它將高分辨率的立體投影技術、三維計算機圖形技術和音響技術等有機地結合在一起,產生一個完全沉浸式的虛擬環境,大大增加觀影的沉浸感。
❖ 智慧教育
沉浸式教學模式逐漸受到教育界的關注。例如,IBM研究院和倫斯勒理工學院聯合開發的「認知沉浸室 」,它能讓學生置身於中國的餐館、商場、園林等虛擬場景,與AI機械人練習漢語對話,大大提升了學生的學習興趣和專註力。
❖ 虛擬會議
以Facebook基於VR開發的虛擬會議為例。而為了更貼近現實,Workrooms還加入了沉浸音頻功能,讓用戶交談時,聲音的發出的方向跟他們所處的房間位置一致,從而進一步增加參會者的沉浸感。

圖片來源於網絡
未來的沉浸音頻技術將如何發展?
以雙耳渲染引擎的核心模塊HRTF為例來說,當前的HRTF模型,是一個固定模型,無法適應不同人的聲音感知差異,尤其在正前方的外化能力還不夠好。若想得到更逼真的聲音效果,需對HRTF進行進一步優化,使其適應每個人的個體差異性。
比如:根據每個人的人頭大小,耳廓信息以及肩膀的形狀獨立建模。在國外HRTF的建模與個性化發展已經成為趨勢:
3月開始,杜比支持個性化HRTF的定製。

圖片來源於網絡
9月開始,iPhone升級了ios16,通過人臉掃描,可以定製自己的HRTF。
圖片來源於網絡
此外,用機器學習的方法,將面部,耳部圖片,轉化成HRTF也在火熱研究中。
未來,阿里雲視頻雲將繼續探索基於深度學習與信號處理的的音頻技術,為VR超高清視頻直播帶來以「聲」臨其境的超沉浸之感。
參考文獻:
[1] 5G 高新視頻—沉浸式視頻技術白皮書
[2] //m.fx361.com/news/2018/0326/3298705.html
[3] //3g.163.com/dy/article/ELBCI2OG053290QL.html?clickfrom=subscribe
[4] //www.birtv.com/Magazine/content/?246.html
[5] //m.midifan.com/article_body.php?id=6201
[6] //sound.media.mit.edu/resources/KEMAR.html
[7] //juiwang.com/assets/projects/hrtf_nn_bem/hrtf_nn_bem.pdf
[8] //www.tvoao.com/a/208656.aspx