從頭訓練一個神經網絡!教它學會莫奈風格作畫!⛵
- 2022 年 11 月 9 日
- 筆記
- AI繪畫, DCGAN, PyTorch, 人工智能, 深度學習, 深度學習實戰通關指南 ⛵ 頂級「煉丹師」案例驅動成長之路, 生成對抗網絡, 莫奈, 計算機視覺

💡 作者:韓信子@ShowMeAI
📘 深度學習實戰系列://www.showmeai.tech/tutorials/42
📘 PyTorch 實戰系列://www.showmeai.tech/tutorials/44
📘 本文地址://www.showmeai.tech/article-detail/324
📢 聲明:版權所有,轉載請聯繫平台與作者並註明出處
📢 收藏ShowMeAI查看更多精彩內容

如今 AI 藝術創作能力越來越強大,在藝術作畫上表現也異常驚人,大家在ShowMeAI的文章 📘AI繪畫 | 使用Hugging Face發佈的diffuser模型快速繪畫 和 📘AI繪畫 | 使用Disco Diffusion基於文本約束繪畫 了解新技術進展和 AI 作畫效果展示,其中 OpenAI 的 DALL-E 2 和 Google 的 ImageGen 等項目基於文本提示作畫的結果和真實藝術家的成品難辨真假。
但上述效果好的大廠項目通常是付費而非開源的,即使有少數開源項目,也遠遠超出了本地電腦的計算能力(至少對於那些電腦沒有 GPU 的寶寶來說)。 本篇我們用不同於 diffuser 模型的另外一種方法:GAN(生成對抗網絡)來完成AI作畫。
本篇內容中ShowMeAI將帶大家來使用 GAN 生成對抗網絡完成莫奈風格作畫。

💡 GAN簡介
我們本篇使用到的技術是GAN,中文名是『生成對抗網絡』,它由兩個部分組成:
-
生成器:『生成器』負責生成所需的內容(在當前場景下是圖像),未經訓練的生成器隨機生成的效果類似噪聲,但隨着訓練過程推進,生成器會產出越來越逼真的結果,直至『判別器』無法分辨真實圖像與AI繪製的圖像。
-
判別器:『判別器』負責監督生成器學習,它將真實圖像與生成器生成的圖像進行比較,檢測和分辨真假。隨着訓練過程推進,它越來越有分辨能力,並督促生成器不斷優化。
下圖是一個簡易的 GAN 示意圖:
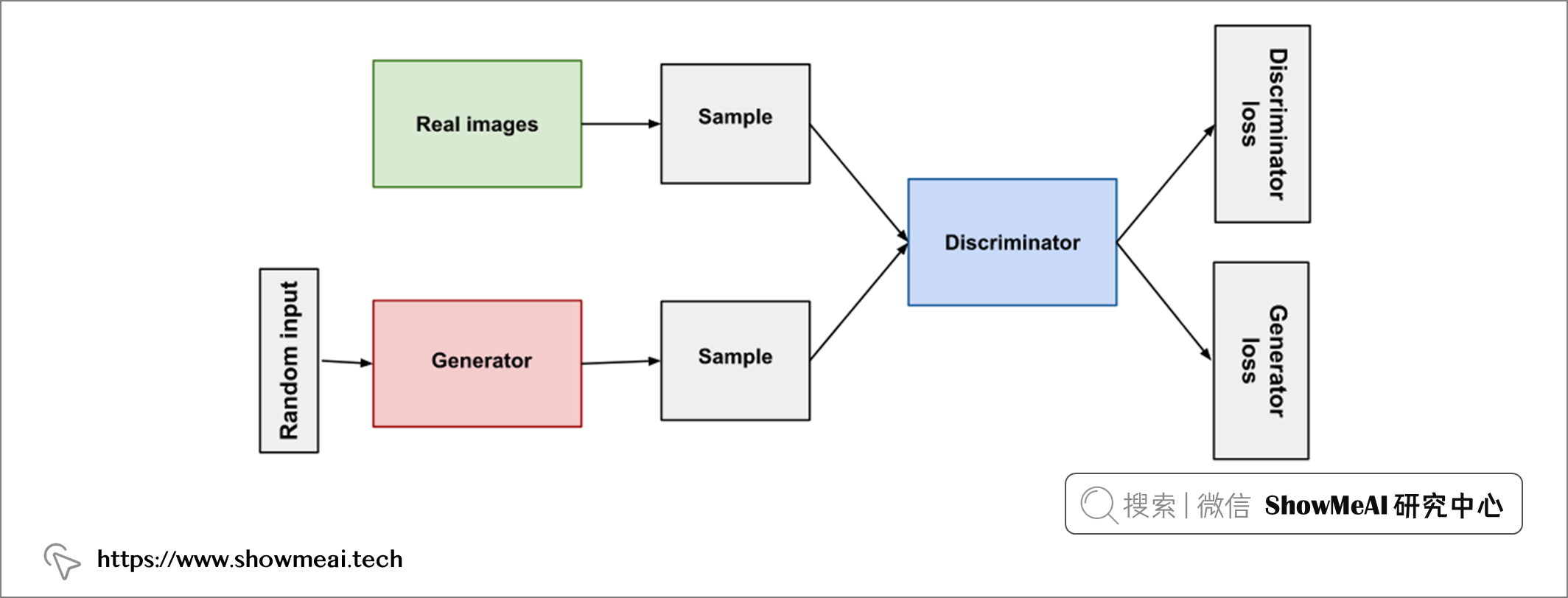
自2014年第一個 GAN 被研究者提出,經過多年它已經有非常長足的進步,產生越來越好的結果。在本教程中,ShowMeAI將基於 Pytorch 基礎上的一個 GAN 工具庫 torchgan 完成一個 DCGAN 並應用於莫奈風格的圖像繪製任務上。

💡 數據集&數據處理
本篇使用到的數據集來源於著名大師莫奈的畫作,我們基於這些優秀的畫作,讓神經網絡學習和嘗試產生類似的內容。法國畫家 📘克勞德·莫奈 生活在 19 世紀,他的畫作可以在 📘//www.wikiart.org/en/claude-monet 獲取。

因為希望模型學習到的信息更充分,我們還擴充使用了很多類似大師風格的圖像,更大的數據量可以使訓練過程更容易。我們人類有很多背景知識先驗知識,例如天空是藍色的,樹木是綠色的,但從神經網絡的角度來看,任何圖像都只是一個 RGB 數組,更多的數據可以幫助它們掌握這些基本規律。

關於數據處理與神經網絡的詳細原理知識,大家可以查看ShowMeAI製作的深度學習系列教程和對應文章
不過,即使採用了外觀相似的圖像,數據量依舊有點小。我們將使『數據增強』技術——它通過對圖像的變換來構建新的圖像達到數據擴增的效果。
我們創建一個自定義 Dataset 類,藉助於 pytorch 的 transforms 功能,可以輕鬆完成數據擴增中的各種變換:
import torch.nn as nn
import torch.utils.data as data
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import torchvision.utils as vutils
from PIL import Image
import globimg_size = 256
class ImagesDataset(data.Dataset):
def __init__(self, images_path: str):
self.files = glob.glob(images_path)
self.images = [None] * self.__len__()
def __len__(self):
return 1000
def __getitem__(self, index):
if self.images[index] is None:
self.images[index] = self.generate_image()
return self.images[index]
def generate_image(self):
index = random.randint(0, len(self.files) - 1)
img = Image.open(self.files[index]).convert('RGB')
transform = transforms.Compose(
[transforms.Resize(img_size + img_size//2),
transforms.RandomCrop(img_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()])
resized = transform(img)
return resized, index
上面的代碼中,我們將所有圖像調整為稍大的尺寸,然後應用隨機裁剪和翻轉構建新的輸出圖像。 對於莫奈的畫,只使用了水平翻轉和裁剪比較穩妥,但對於現代藝術樣本,垂直翻轉或隨機旋轉可能也是適用的。
我們隨機取一點數據集,做可視化和驗證有效性:
import torchvision.utils as vutils
import matplotlib.pyplot as plt
def show_images(batch):
plt.figure(figsize=(12, 12))
plt.axis("off")
plt.title("Training Images")
plt.imshow(np.transpose(vutils.make_grid(batch, padding=2,
normalize=True).cpu(), (1, 2, 0)))
plt.show()dataset = ImagesDataset(images_path="Paintings/Monet/*.png")
dataloader = data.DataLoader(dataset, batch_size=batch_size,
shuffle=True)
batch = next(iter(dataloader))
show_images(batch[0][:64])
運行代碼後,我們可以看到如下結果:

莫奈創作了大約 2500 幅畫作,當然完整的畫作集中可能會包含不同的內容物,大家看可以稍作篩選。
💡 構建神經網絡
我們準備好數據集後,下一步就開始創建神經網絡模型了。我們基於 📘torchgan 工具庫,構建 GAN 並不複雜:
import torch
from torchgan.models import *
from torchgan.losses import *
dcgan_network = {
"generator": {
"name": DCGANGenerator,
"args": {
"encoding_dims": 100,
"step_channels": 40,
"out_channels": 3,
"out_size": img_size,
"nonlinearity": nn.LeakyReLU(0.3),
"last_nonlinearity": nn.Tanh()
},
"optimizer": {"name": Adam,
"args": {"lr": 0.0005, "betas": (0.5, 0.999)}}
},
"discriminator": {
"name": DCGANDiscriminator,
"args": {
"in_channels": 3,
"in_size": img_size,
"step_channels": 40,
"nonlinearity": nn.LeakyReLU(0.3),
"last_nonlinearity": nn.LeakyReLU(0.2)
},
"optimizer": {"name": Adam,
"args": {"lr": 0.0006, "betas": (0.5, 0.999)}}
}
}
lsgan_losses = [LeastSquaresGeneratorLoss(),
LeastSquaresDiscriminatorLoss()]
我們通過配置的方式,通過字典對網絡結構和參數進行了設置。我們這裡定義的DCGAN模型包含一個生成器 DCGANGenerator 和一個判別器 DCGANDiscriminator 。
下一步我們訓練網絡:
# 使用GPU或者CPU
if torch.cuda.is_available():
device = torch.device("cuda:0")
torch.backends.cudnn.deterministic = True
else:
device = torch.device("cpu")batch_size = 64
# 迭代輪次
epochs = 2000
# 訓練器
trainer = Trainer(dcgan_network, lsgan_losses,
sample_size=batch_size, epochs=epochs,
device=device,
recon="./torchgan_images",
checkpoints="./torchgan_model/gan2",
log_dir="./torchgan_logs",
retain_checkpoints=2)
# 訓練
trainer(dataloader)
trainer.complete()
上述代碼中涉及的參數都可以調整,每一輪訓練後會在 torchgan_images 文件夾中生成圖像樣本,訓練得到的模型保存在 torchgan_model 文件夾中(模型文件不小,對於 256×256 的小尺寸圖像,它的大小約為 440M Bytes),但我們僅在磁盤上保留最後 2 個模型 checkpoint。
訓練過程中的中間數據日誌記錄在 torchgan_logs 文件夾下,我們可以通過 TensorBoard 工具實時查看訓練中間狀態,只需要運行 tensorboard -logdir torchgan_logs 命令即可,運行後我們可以在瀏覽器界面的 //localhost:6006 URL中查看中間訓練過程,如下圖所示:
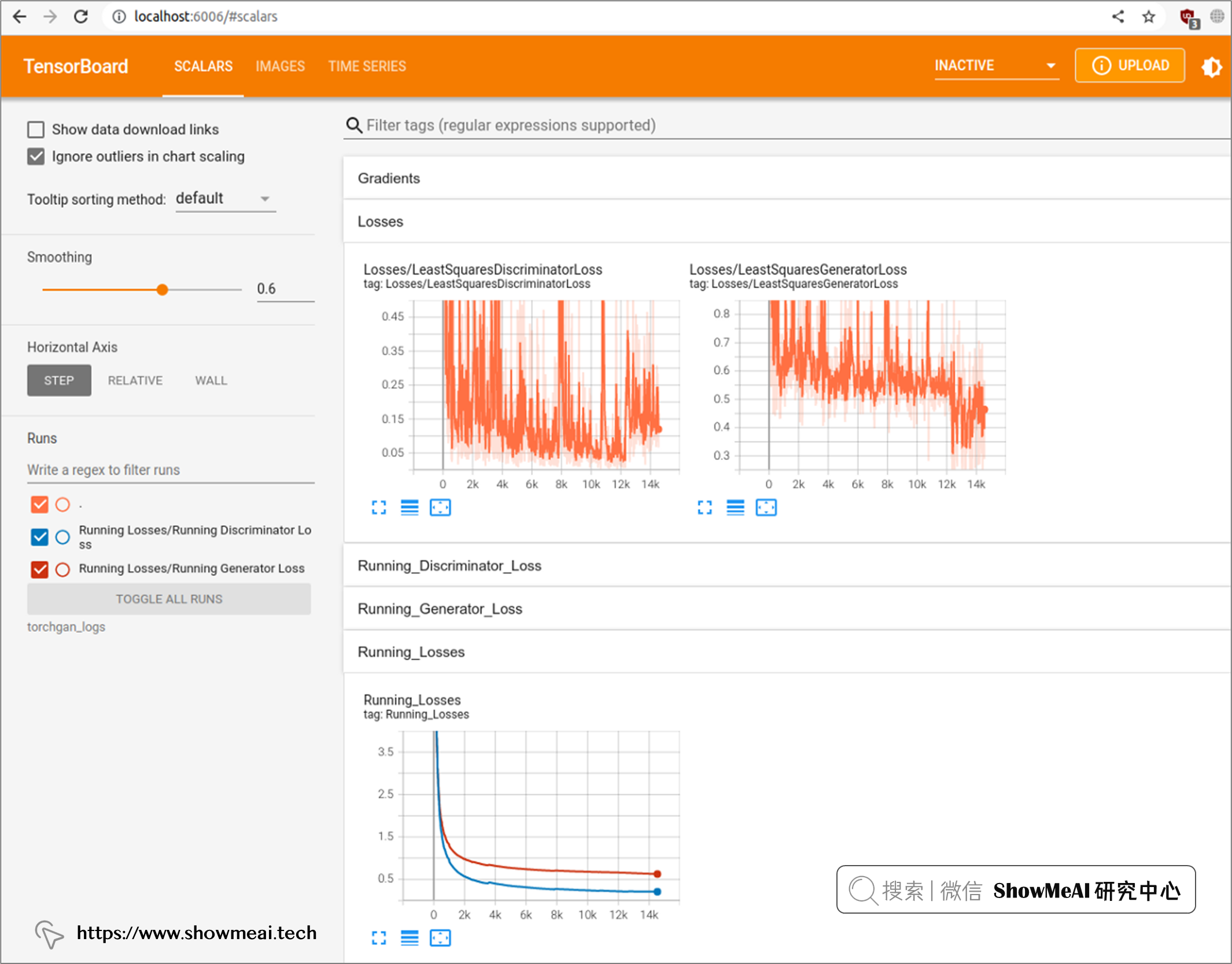
💡 訓練與優化
GAN的訓練過程是比較緩慢的,大家可能需要一些耐心。 GeForce RTX 3060 顯卡 GPU + Ryzen 9 CPU 的設備上,對尺寸為 256×256 的圖像數據集進行 2000 次訓練大約需要 4 小時。
整個訓練過程中,可以看到神經網絡逐步生成越來越好的圖像,我們把不同階段的生產效果做成動圖,如下所示:

有興趣大家可以試着調整一下輸入參數,也可以採集和提供更多的訓練圖片,效果可能會更好。
💡 總結
對比之前 ShowMeAI 提到過的 diffuser 模型,我們這裡使用 📘DALL-E Mini 的在線版本 也生成了莫奈畫作的圖像,如下所示:

我們的DCGAN代碼生成的結果分辨率會弱一點:

DALL-E Mini 的模型結構做過調整,且在數百萬張圖像進行過訓練,比我們幾個小時訓練完的小模型效果好是正常的。大家如果採集更多的數據,嘗試不同模型參數,結果可能會更好,快來一起試一試吧。
參考資料
- 📘 AI繪畫 | 使用Hugging Face發佈的diffuser模型快速繪畫://www.showmeai.tech/article-detail/312
- 📘 AI繪畫 | 使用Disco Diffusion基於文本約束繪畫://www.showmeai.tech/article-detail/313
- 📘 克勞德·莫奈://en.wikipedia.org/wiki/Claude_Monet
- 📘 Claude Monet 畫作://www.wikiart.org/en/claude-monet
- 📘 深度學習教程:吳恩達專項課程 · 全套筆記解讀://www.showmeai.tech/tutorials/35
- 📘 深度學習教程 | 深度學習的實用層面://www.showmeai.tech/article-detail/216
- 📘 深度學習與計算機視覺教程:斯坦福CS231n · 全套筆記解讀://www.showmeai.tech/tutorials/37
- 📘 深度學習與CV教程(7) | 神經網絡訓練技巧 (下) ://www.showmeai.tech/article-detail/266
- 📘 torchgan://github.com/torchgan/torchgan
- 📘 DALL-E Mini 的在線版本://huggingface.co/spaces/dalle-mini/dalle-mini


