MindStudio模型訓練場景精度比對全流程和結果分析
摘要:MindStudio是一套基於華為昇騰AI處理器開發的AI全棧開發平台
本文分享自華為雲社區《MindStudio模型訓練場景精度比對全流程和結果分析》,作者:yd_247302088 。
一、基於MindStudio模型精度比對介紹
1.1 MindStudio介紹
MindStudio是一套基於華為昇騰AI處理器開發的AI全棧開發平台,包括基於芯片的算子開發、以及自定義算子開發,同時還包括網絡層的網絡移植、優化和分析,另外在業務引擎層提供了可視化的AI引擎拖拽式編程服務,極大的降低了AI引擎的開發門檻。MindStudio工具中的功能框架如圖1所示:

圖1 MindStudio功能框架
MindStudio工具中的主要幾個功能特性如下:
- 工程管理:為開發人員提供創建工程、打開工程、關閉工程、刪除工程、新增工程文件目錄和屬性設置等功能。
- SSH管理:為開發人員提供新增SSH連接、刪除SSH連接、修改SSH連接、加密SSH密碼和修改SSH密碼保存方式等功能。
- 應用開發:針對業務流程開發人員,MindStudio工具提供基於AscendCL(Ascend Computing Language)和集成MindX SDK的應用開發編程方式,編程後的編譯、運行、結果顯示等一站式服務讓流程開發更加智能化,可以讓開發者快速上手。
- 自定義算子開發:提供了基於TBE和AI CPU的算子編程開發的集成開發環境,讓不同平台下的算子移植更加便捷,適配昇騰AI處理器的速度更快。
- 離線模型轉換:訓練好的第三方網絡模型可以直接通過離線模型工具導入並轉換成離線模型,並可一鍵式自動生成模型接口,方便開發者基於模型接口進行編程,同時也提供了離線模型的可視化功能。
- 日誌管理:MindStudio為昇騰AI處理器提供了覆蓋全系統的日誌收集與日誌分析解決方案,提升運行時算法問題的定位效率。提供了統一形式的跨平台日誌可視化分析能力及運行時診斷能力,提升日誌分析系統的易用性。
- 性能分析:MindStudio以圖形界面呈現方式,實現針對主機和設備上多節點、多模塊異構體系的高效、易用、可靈活擴展的系統化性能分析,以及針對昇騰AI處理器的性能和功耗的同步分析,滿足算法優化對系統性能分析的需求。
- 設備管理:MindStudio提供設備管理工具,實現對連接到主機上的設備的管理功能。
- 精度比對:可以用來比對自有模型算子的運算結果與Caffe、TensorFlow、ONNX標準算子的運算結果,以便用來確認神經網絡運算誤差發生的原因。
- 開發工具包的安裝與管理:為開發者提供基於昇騰AI處理器的相關算法開發套件包Ascend-cann-toolkit,旨在幫助開發者進行快速、高效的人工智能算法開發。開發者可以將開發套件包安裝到MindStudio上,使用MindStudio進行快速開發。Ascend-cann-toolkit包含了基於昇騰AI處理器開發依賴的頭文件和庫文件、編譯工具鏈、調優工具等。
1.2 精度比對介紹
自有實現的算子在昇騰AI處理器上的運算結果與業界標準算子(如Caffe、ONNX、TensorFlow、PyTorch)的運算結果可能存在差異:
- 在模型轉換過程中對模型進行了優化,包括算子消除、算子融合、算子拆分,這些動作可能會造成自有實現的算子運算結果與業界標準算子(如Caffe、TensorFlow、ONNX)運算結果存在偏差。
- 用戶原始網絡可以遷移到昇騰910 AI處理器上執行訓練,網絡遷移可能會造成自有實現的算子運算結果與用業界標準算子(如TensorFlow、PyTorch)運算結果存在偏差。
為了幫助開發人員快速解決算子精度問題,需要提供比對自有實現的算子運算結果與業界標準算子運算結果之間差距的工具。精度比對工具提供Vector比對能力,包含餘弦相似度、最大絕對誤差、累積相對誤差、歐氏相對距離、KL散度、標準差、平均絕對誤差、均方根誤差、最大相對誤差、平均相對誤差的算法比對維度。
二、環境準備
在進行實驗之前需要配置好遠端Linux服務器並下載安裝MindStudio。
首先在Linux服務器上安裝部署好Ascend-cann-toolkit開發套件包、Ascend-cann-tfplugin框架插件包和TensorFlow 1.15.0深度學習框架。之後在Windows上安裝MindStudio,安裝完成後通過配置遠程連接的方式建立MindStudio所在的Windows服務器與Ascend-cann-toolkit開發套件包所在的Linux服務器的連接,實現全流程開發功能。
接下來配置環境變量,以運行用戶登錄服務器,在任意目錄下執行vi ~/.bashrc命令,打開.bashrc文件,在文件最後一行後面添加以下內容(以非root用戶的默認安裝路徑為例)。

然後執行:wq!命令保存文件並退出。
最後執行source ~/.bashrc命令使其立即生效。
關於MindStudio的具體安裝流程可以參考Windows安裝MindStudio(點我跳轉),MindStudio環境搭建指導視頻(點我跳轉)。MindStudio官方下載地址:點我跳轉。
本文教程基於MindStudio5.0.RC2 x64,CANN版本5.1.RC2實現。
三、準備基於GPU運行生成的原始訓練網絡npy數據文件
3.1 獲取項目代碼
本樣例選擇resnet50模型,利用git克隆代碼(git clone -b r1.13.0 //github.com/tensorflow/models.git),下載成功後如下圖所示:

3.2 生成數據前處理
數據比對前,需要先檢查並去除訓練腳本內部使用到的隨機處理,避免由於輸入數據不一致導致數據比對結果不可用。
編輯resnet_run_loop.py文件,修改如下(以下行數僅為示例,請以實際為準):
注釋掉第83、85行
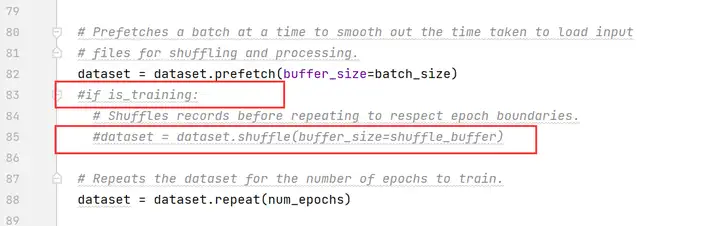
注釋掉第587~594行

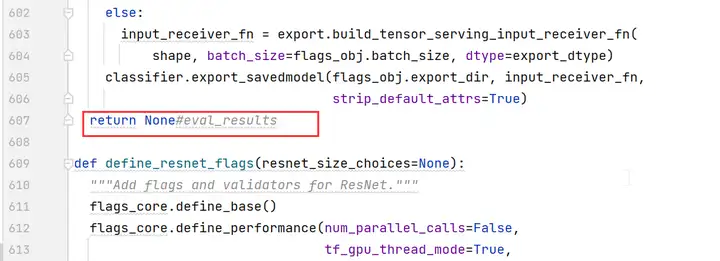
第607行,修改為「return None」
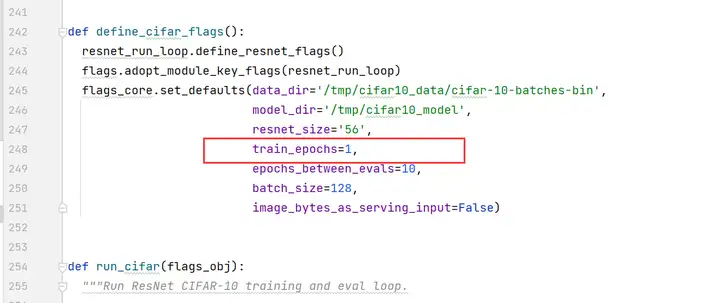
編輯cifar10_main.py文件,將train_epochs的值改為1。
3.3 生成npy文件
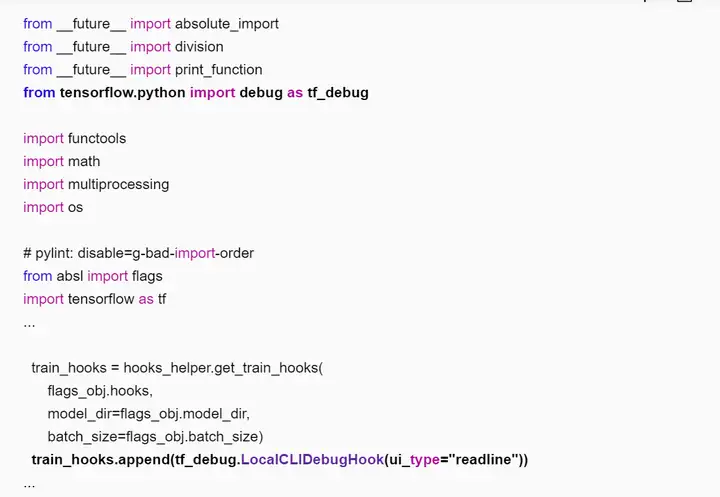
進入訓練腳本所在目錄(如「~/models/official/resnet」),修改訓練腳本,添加tfdbg的hook。編輯resnet_run_loop.py文件,添加如下加粗字體的信息。
配置環境變量

執行訓練腳本

訓練任務停止後,在命令行輸入run,訓練會往下執行一個step。
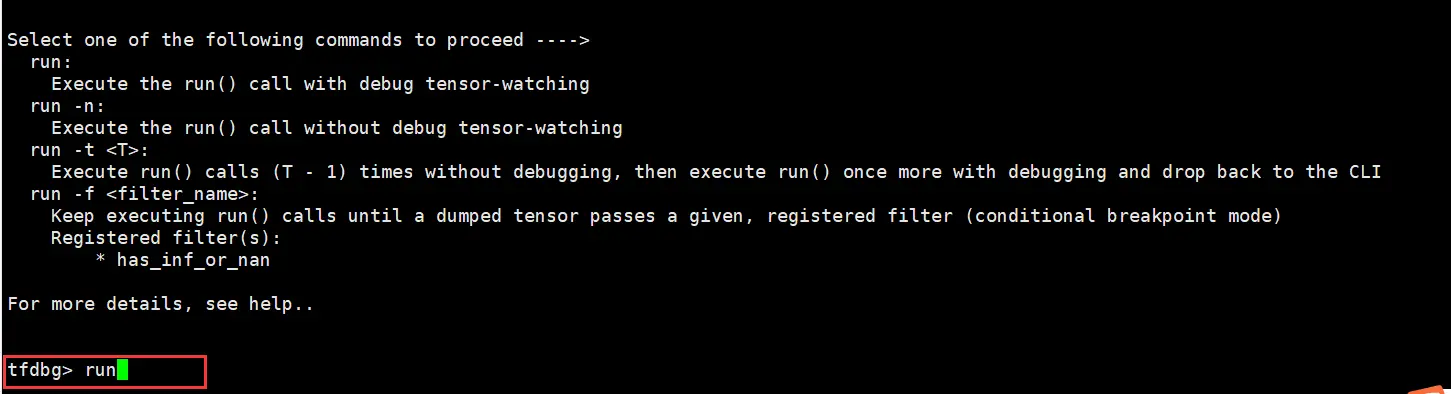
執行lt>gpu_dump命令將所有tensor的名稱暫存到自定義名稱的gpu_dump文件里。命令行中會有如下回顯。

另外開啟一個終端,在linux命令行下進入gpu_dump文件所在目錄,執行下述命令,用以生成在tfdbg命令行執行的命令。
timestamp=$[$(date +%s%N)/1000] ; cat gpu_dump | awk ‘{print “pt”,$4,$4}’ | awk ‘{gsub(“/”, “_”, $3);gsub(“:”, “.”, $3);print($1,$2,”-n 0 -w “$3″.””‘$timestamp'””.npy”)}’>dump.txt
將上一步生成的dump.txt文件中所有tensor存儲的命令複製(所有以「pt」開頭的命令),然後回到tfdbg命令行(剛才執行訓練腳本的控制台)粘貼執行,即可存儲所有的npy文件,存儲路徑為訓練腳本所在目錄。

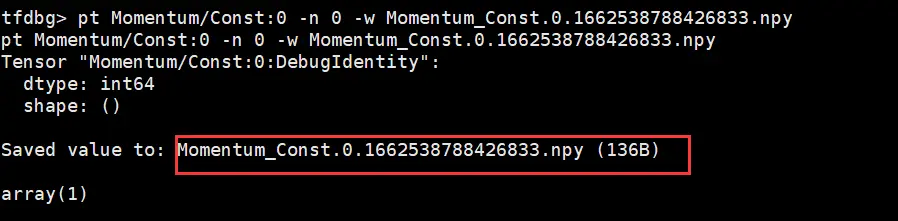
退出tfdbg命令行,將生成的npy文件保存到tf_resnet50_gpu_dump_data(用戶可自定義)目錄下。

四、準備基於NPU運行生成的訓練網絡dump數據和計算圖文件
4.1 分析遷移
單擊菜單欄「File > New > Project…」彈出「New Project」窗口。
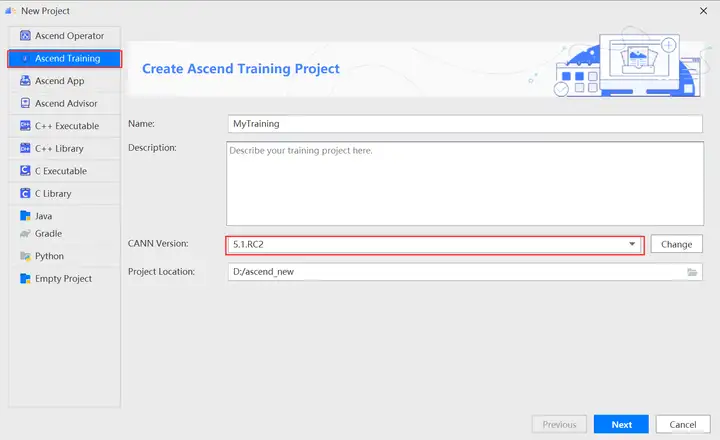
在New Project窗口中,選擇Ascend Training。輸入項目的名稱、CANN遠程地址以及本地地址。點擊Change配置CANN,如下圖所示:
- Name:工程名稱,可自定義。
- Description:工程描述,可按需補充關於工程的詳細信息。
- CANN Version:CANN軟件包版本,如未識別或想要更換使用的版本,可單擊「Change」,在彈出界面中選擇Ascend-cann-toolkit開發套件包的安裝路徑(注意需選擇到版本號一級)。
- Project Location:工程目錄,默認在「$HOME/AscendProjects」下創建。
點擊右側 + 進行配置遠程服務器,如下圖所示:

在出現的信息配置框輸入相關配置信息,如下圖所示:
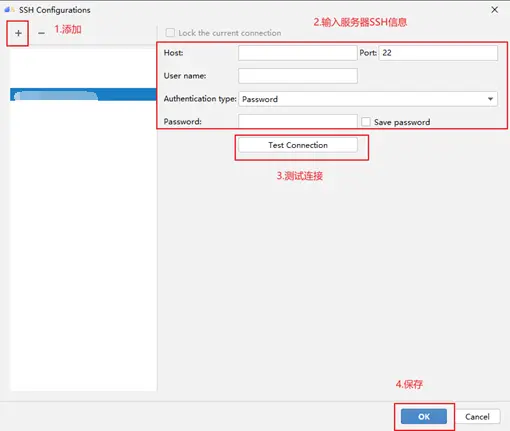
輸入服務器的SSH信息,如果測試連接失敗,建議使用CMD或XShell等工具進行排查。
選擇遠程 CANN 安裝位置,如下圖所示:
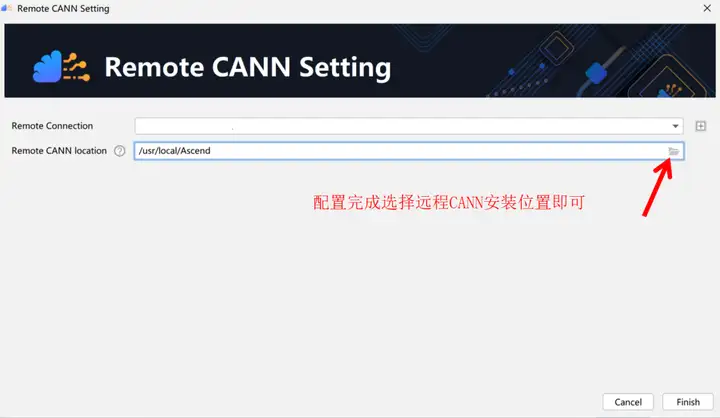
在Remote CANN location中選擇CANN的路徑,需要注意的是必須選擇到CANN的版本號目錄,這裡選擇的是5.1.RC2版本,如下圖所示:
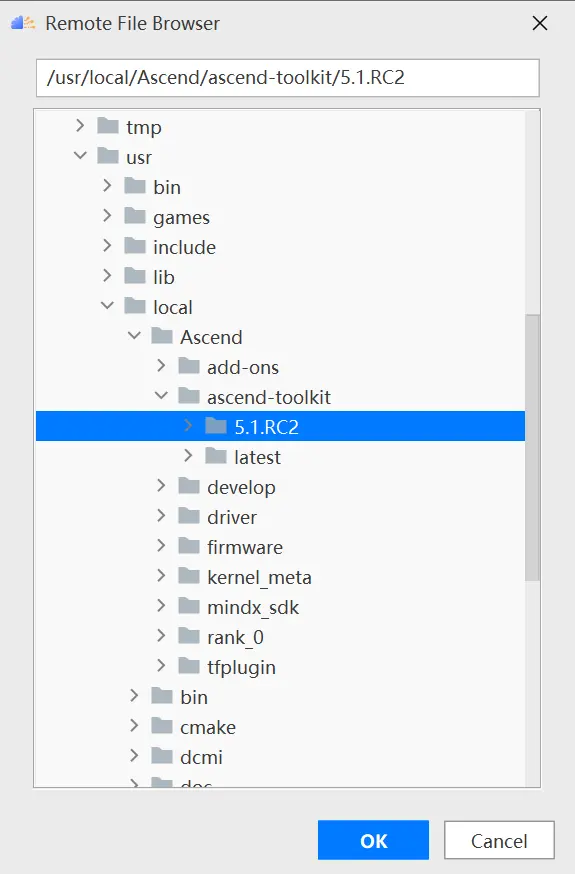
點擊確定後,需要等待MindStudio進行文件同步操作,這個過程會持續數分鐘,期間如果遇到Sync remote CANN files error.錯誤,考慮是否無服務器root權限。

配置完成CANN點擊下一步
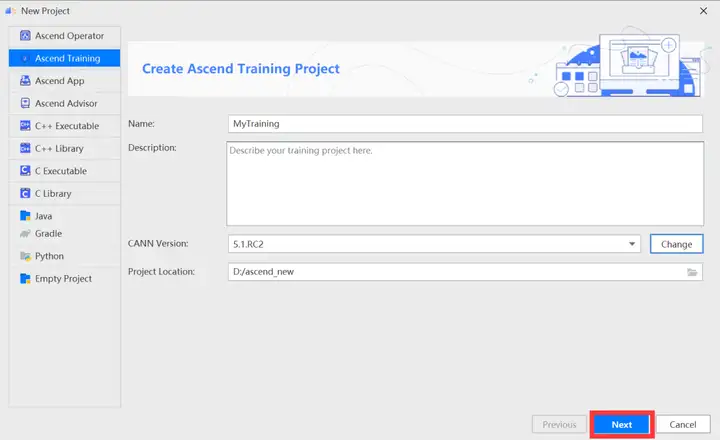
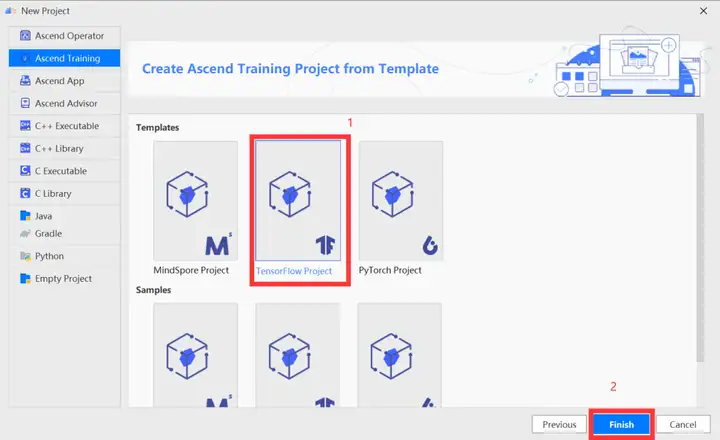
在訓練工程選擇界面,選擇「TensorFlow Project」,單擊「Finish」。
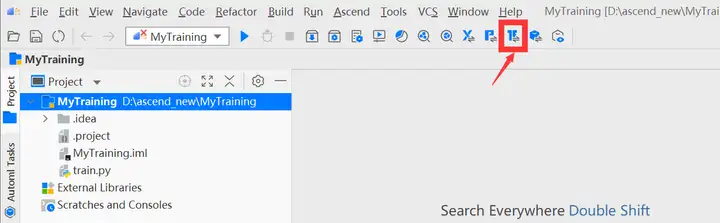
進入工程界面,單擊工具欄中

按鈕( TensorFlow GPU2Ascend工具)。
進入「TensorFlow GPU2Ascend」參數配置頁,配置command file
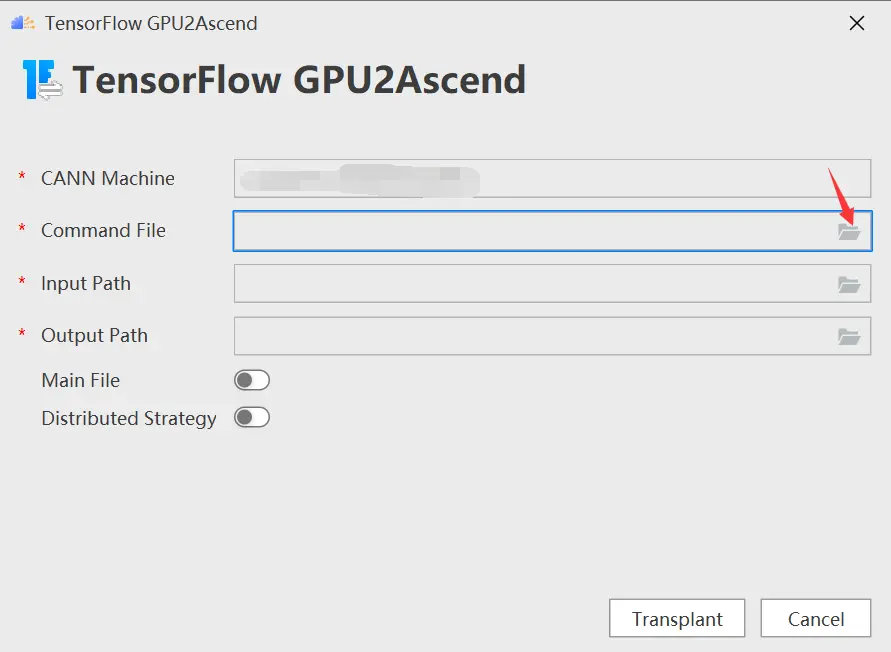
- Command File:tfplugin插件包中的工具腳本文件。
- Input Path:待轉換腳本文件的路徑。
- Output Path:腳本轉換後的輸出路徑。
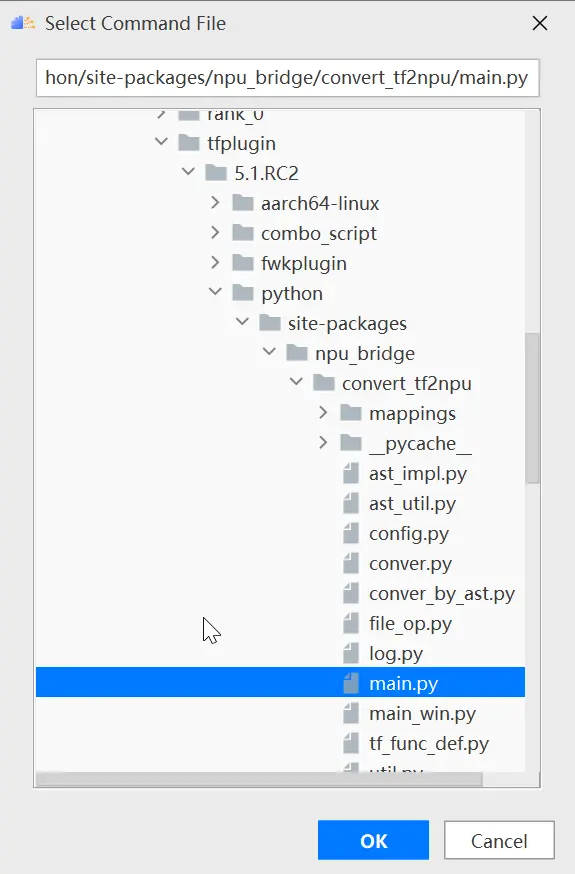
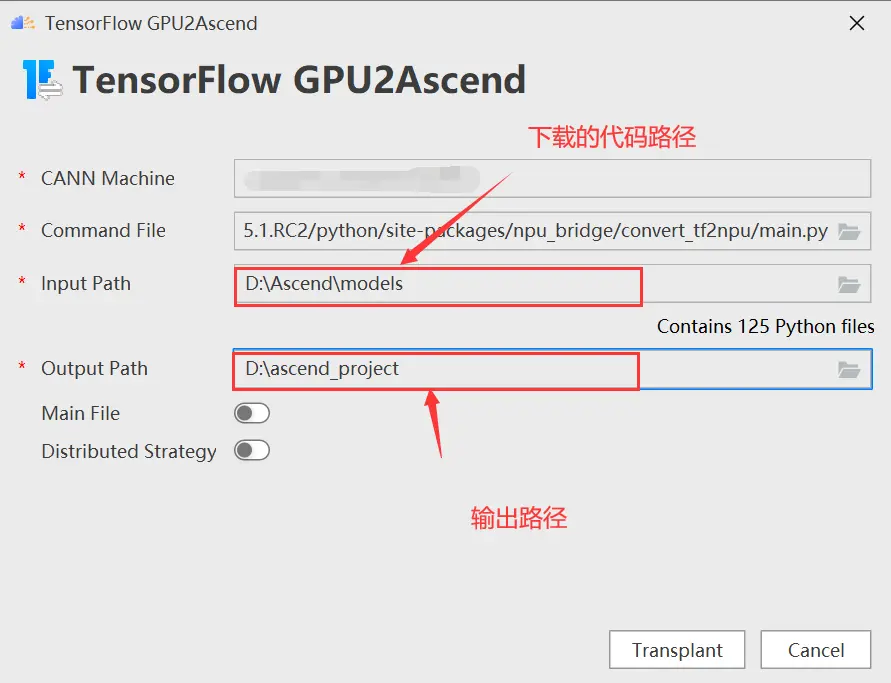
根據tfplugin文件所在路徑選擇/Ascend/tfplugin/5.1.RC2/python/site-packages/npu_bridge/convert_tf2npu/main.py,如下圖所示
同樣的,選擇下載的代碼路徑作為input path,並選擇輸出路徑,如下圖所示:
點擊Transplant進行轉換,如下圖所示:
出現「Transplant success!」的回顯信息,即轉換成功。如下圖所示:

4.2 生成dump數據和計算圖文件
步驟一 dump前準備。
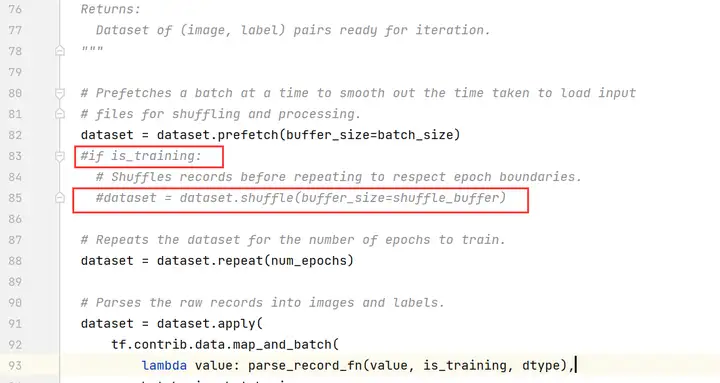
編輯resnet_run_loop.py文件,修改如下(以下行數僅為示例,請以實際為準):
注釋掉第83、85行
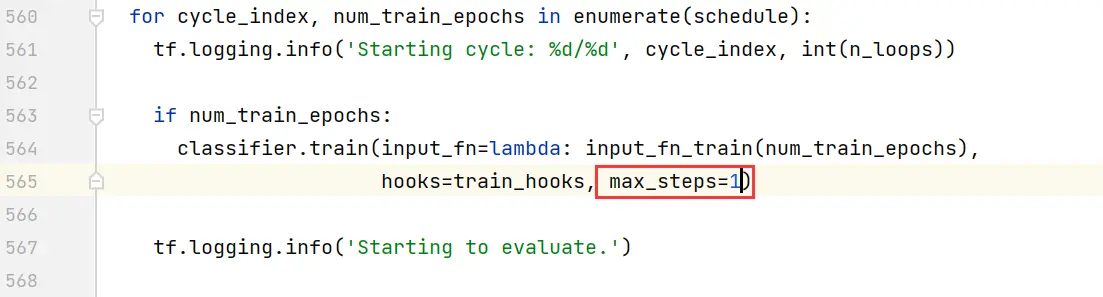
把max_steps設置為1。
注釋掉第575~582行
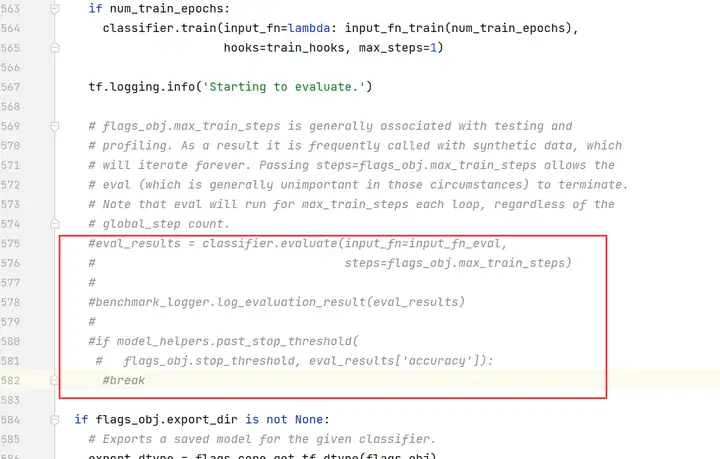
注釋掉第595行,修改為「return None」。
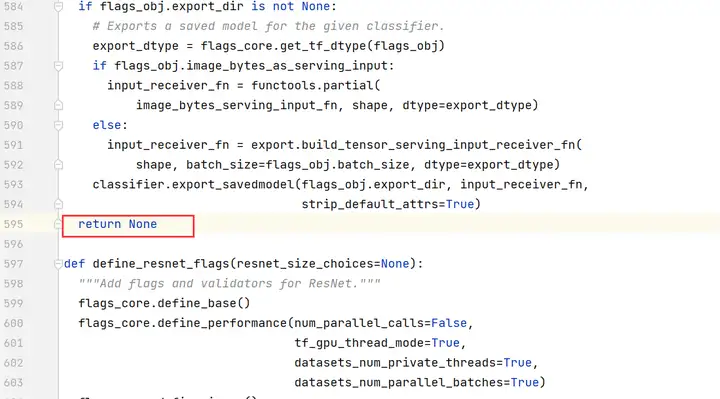
編輯cifar10_main.py文件,將train_epochs的值改為1。
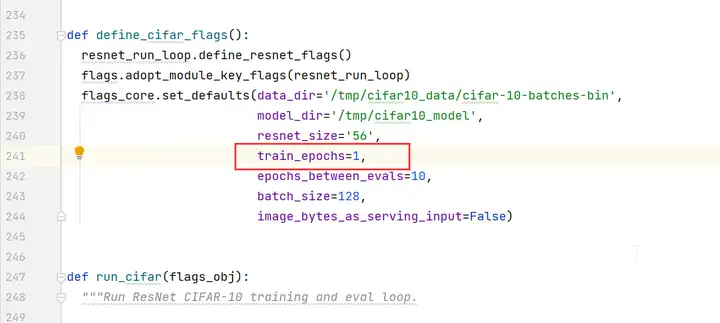
步驟二 dump參數配置。
為了讓訓練腳本能夠dump出計算圖,我們在訓練腳本中的包引用區域引入os,並在構建模型前設置DUMP_GE_GRAPH參數。配置完成後,在訓練過程中,計算圖文件會保存在訓練腳本所在目錄中。
編輯cifar10_main.py,添加如下方框中的信息。

修改訓練腳本(resnet_run_loop.py),開啟dump功能。在相應代碼中,增加如下方框中的信息。
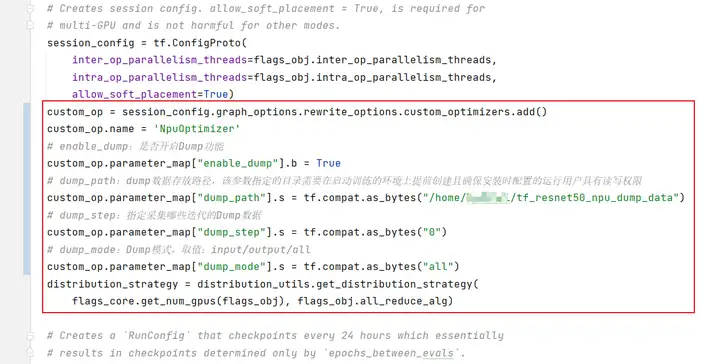
步驟三 環境配置。
單擊MindStudio菜單欄「Run > Edit Configurations…」。
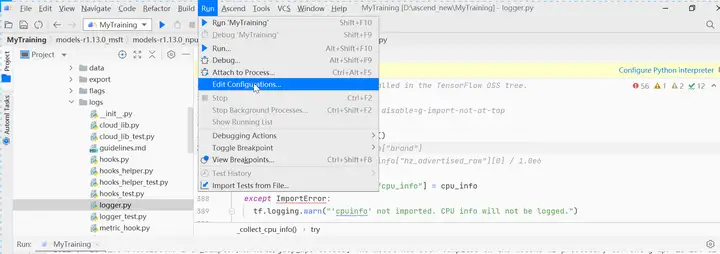
進入運行配置界面,選擇遷移後的訓練腳本。
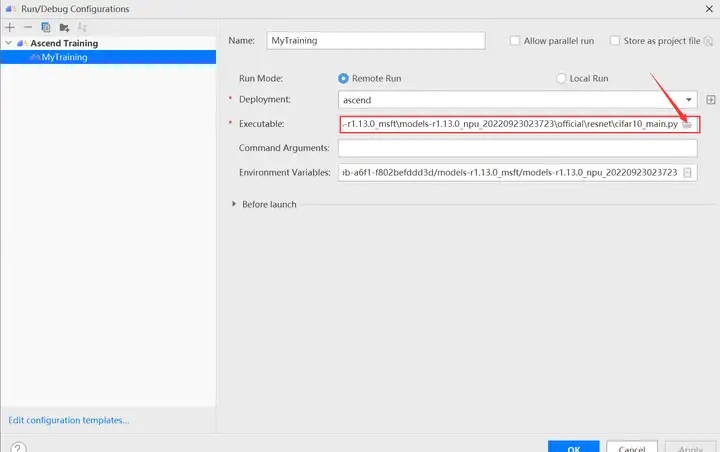
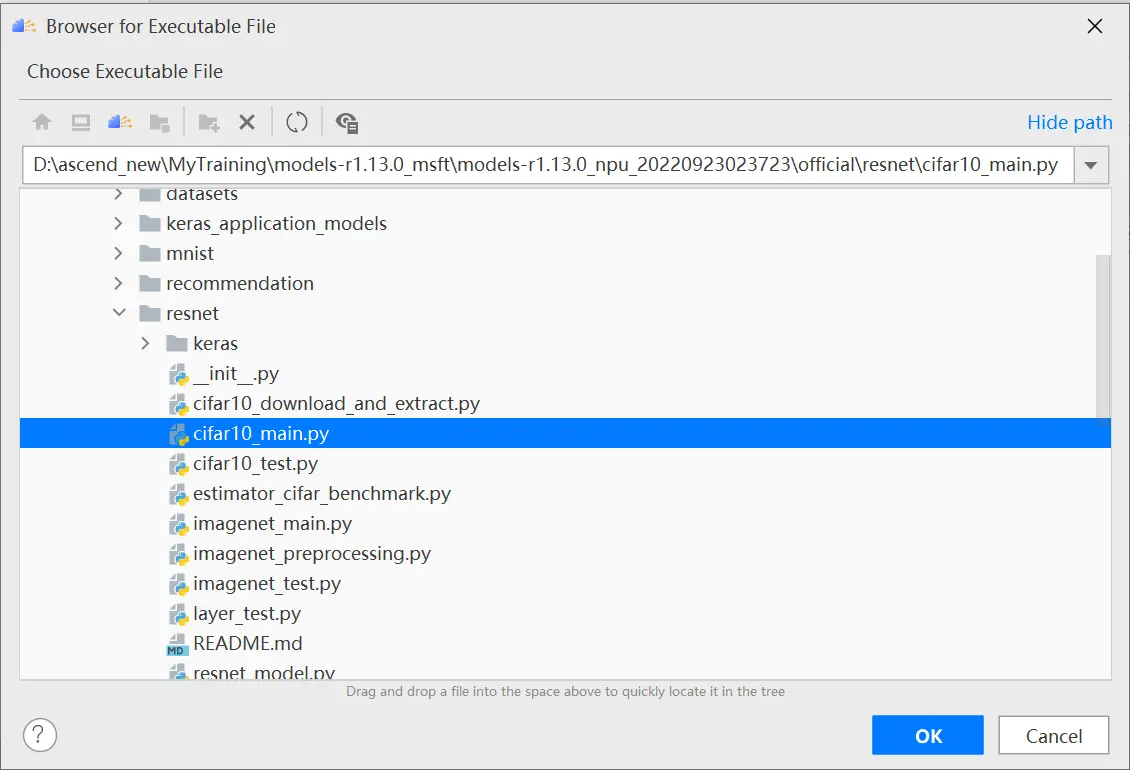
配置環境變量,打開下圖所示界面,配置訓練進程啟動依賴的環境變量,參數設置完成後,單擊「OK」,環境變量配置說明請參見下表。
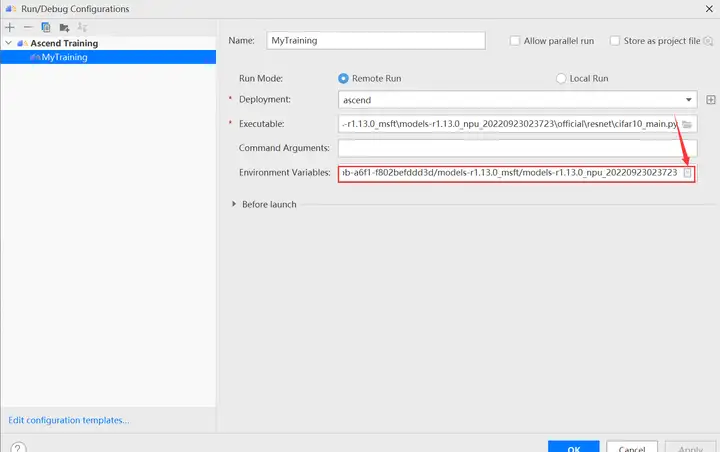
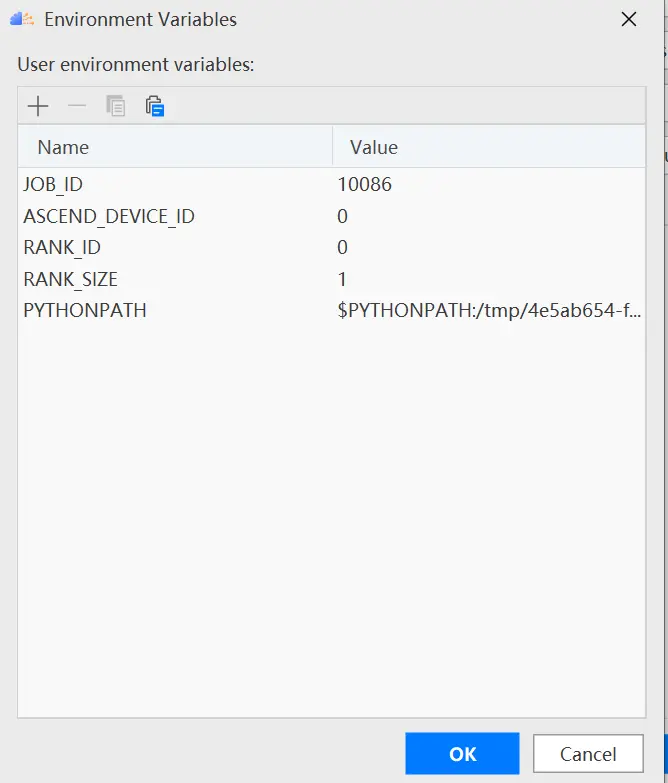
環境變量的解釋如下表所示:
步驟四 執行訓練生成dump數據。
點擊按鈕開始訓練
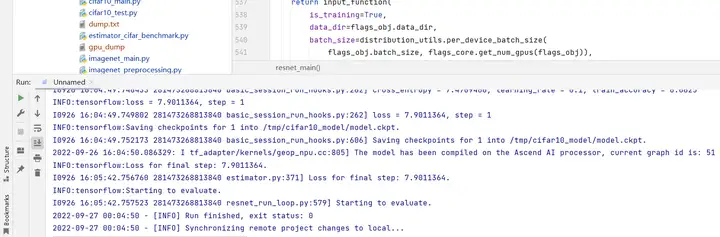
訓練時控制台輸出如下所示:
resnet目錄下生成的數據文件展示如下:

在所有以「_Build.txt」為結尾的dump圖文件中,查找「Iterator」這個關鍵詞。記住查找出的計算圖文件名稱,用於後續精度比對。

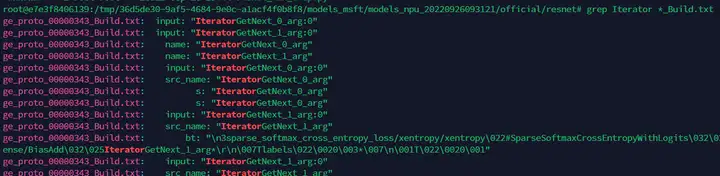
如上圖所示,「ge_proto_00000343_Build.txt」文件即是我們需要找到的計算圖文件。將此文件拷貝至用戶家目錄下,便於在執行比對操作時選擇。
打開上面找到的計算圖文件,記錄下第一個graph中的name字段值。如下示例中,記錄下「ge_default_20220926160231_NPU_61」。
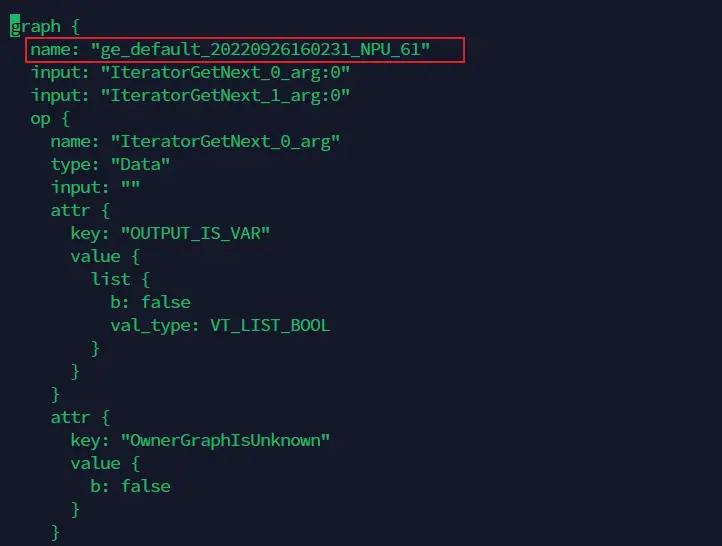
進入以時間戳命名的dump文件存放路徑下,找到剛記錄的名稱為name值的文件夾,例如ge_default_20220926160231_NPU_61,則下圖目錄下的文件即為需要的dump數據文件:

五 比對操作
在MindStudio菜單欄選擇「Ascend > Model Accuracy Analyzer > New Task」,進入精度比對參數配置界面。
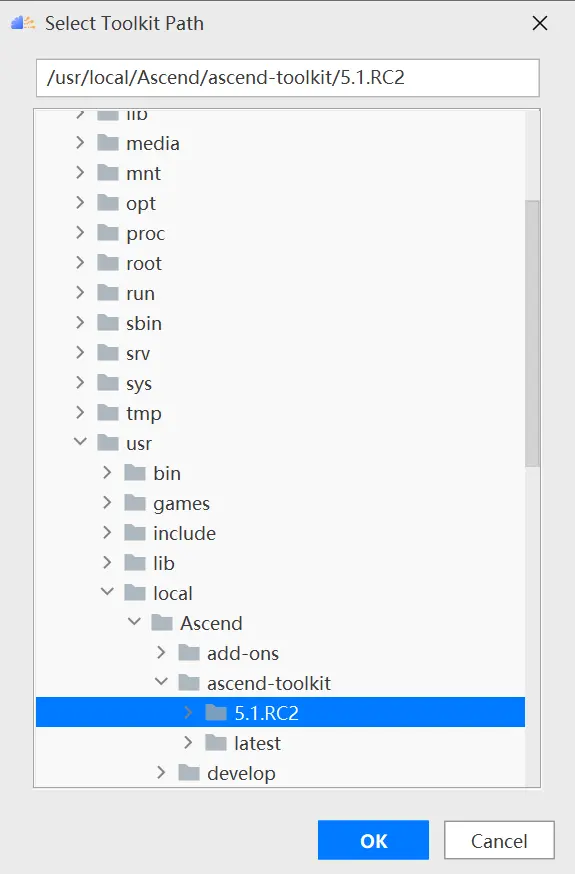
配置tookit path,點擊文件標識,如下圖所示:
選擇對應的版本,如5.1.RC2版本,單擊ok:
單擊next進入參數配置頁面:
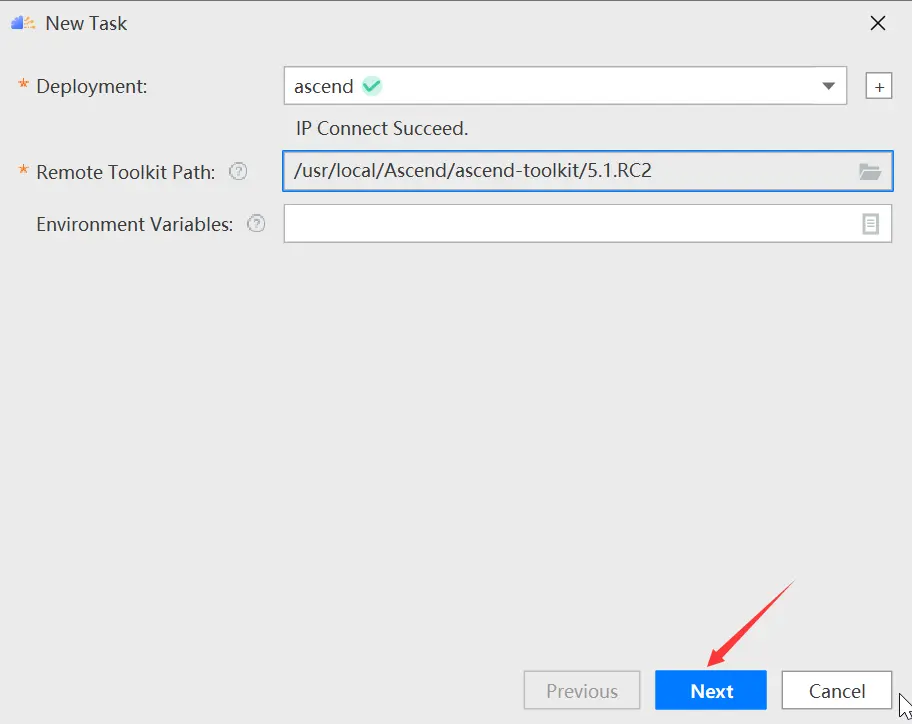
接着填寫gpu和npu的數據的相關信息,如下圖所示:
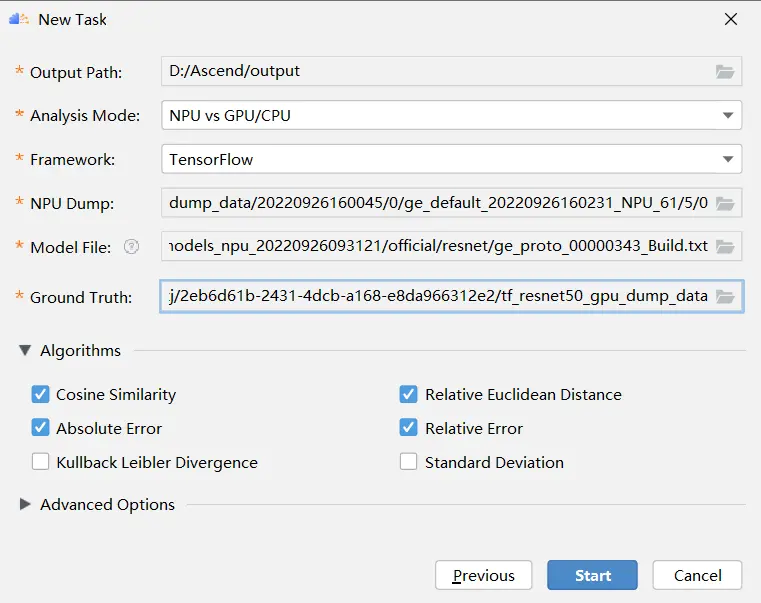
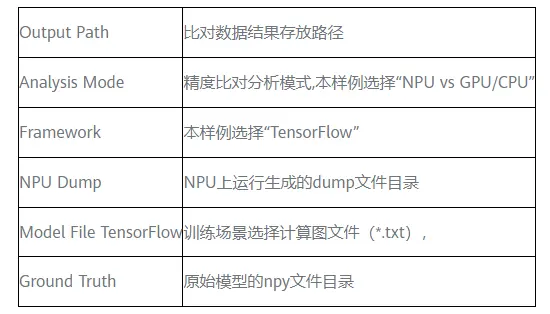
參數解釋如下所示:
點擊start:
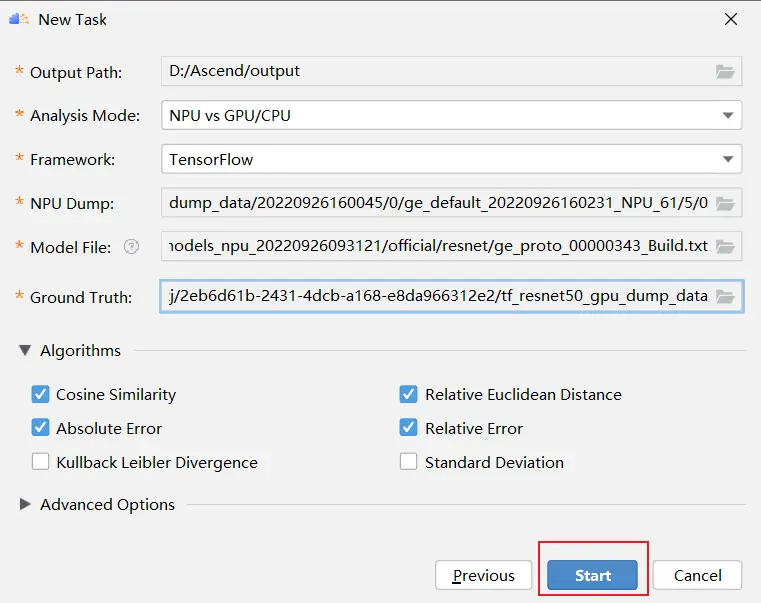

結果展示:
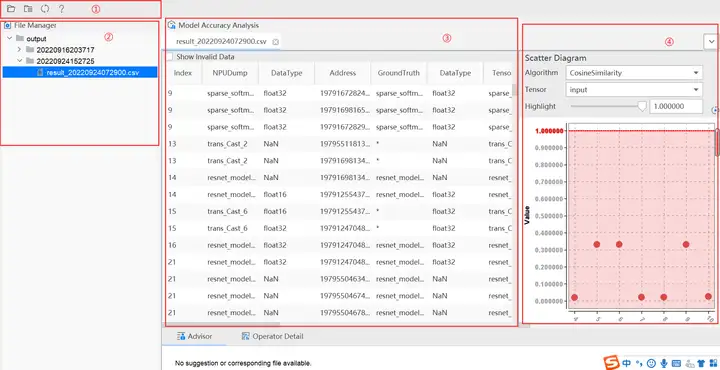
如上圖所示將Vector比對結果界面分為四個區域分別進行介紹。
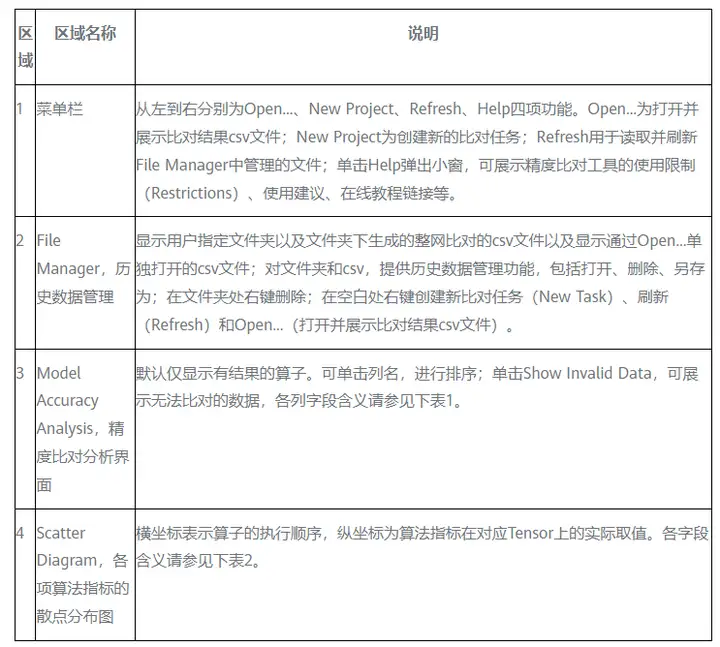
表1 精度比對分析界面字段說明
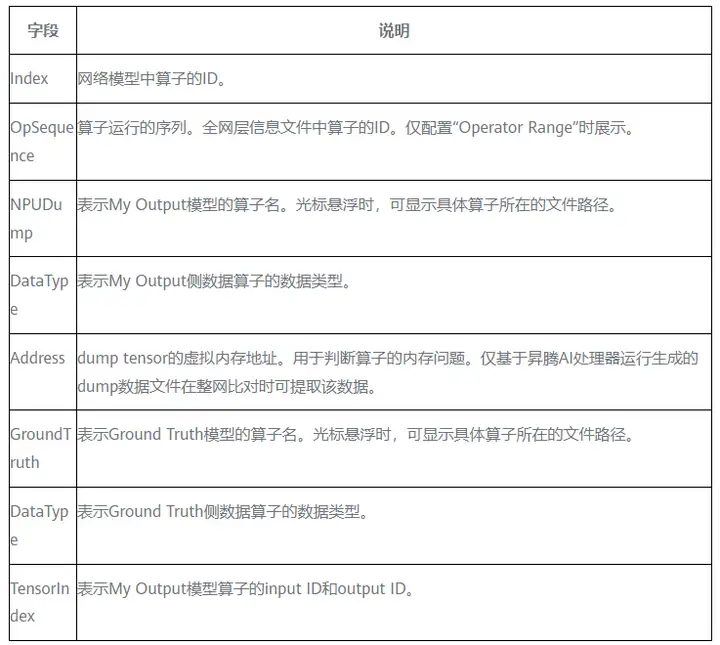
表2 散點分佈圖字段說明

六、常見問題 & 解決方案匯總
Q:tfdbg複製pt命令時執行出錯
A:由於tfdbg將多行的pt命令識別為了單個命令,使得命令執行失敗。解決辦法如下:
- 先退出tfdbg命令行
- 安裝pexpect庫,命令為 pip install pexpect –user(–user只針對普通用戶,root用戶是沒有的)
- 進入resnet所在的目錄,cd ~/models/official/resnet
- 確保目錄下有dump.txt文件,即生成的pt命令
- 編寫下述代碼,vim auto_run.py
import pexpect import sys cmd_line = 'python3 -u ./cifar10_main.py' tfdbg = pexpect.spawn(cmd_line) tfdbg.logfile = sys.stdout.buffer tfdbg.expect('tfdbg>') tfdbg.sendline('run') pt_list = [] with open('dump.txt', 'r') as f: for line in f: pt_list.append(line.strip('\n')) for pt in pt_list: tfdbg.expect('tfdbg>') tfdbg.sendline(pt) tfdbg.expect('tfdbg>') tfdbg.sendline('exit')
6.保存退出vim,執行python auto_run.py
七、從昇騰官方體驗更多內容
更多的疑問和信息可以在昇騰論壇進行討論和交流://bbs.huaweicloud.com/forum/forum-726-1.html


