JVM學習筆記——內存模型篇
JVM學習筆記——內存模型篇
在本系列內容中我們會對JVM做一個系統的學習,本片將會介紹JVM的內存模型部分
我們會分為以下幾部分進行介紹:
- 內存模型
- 樂觀鎖與悲觀鎖
- synchronized優化
內存模型
這一小節我們來詳細介紹一下內存模型和內存模型的三個特性
內存模型簡介
首先我們來簡單介紹一下內存模型:
- 內存模型,全稱Java Memory Model,也就是我們常說的JMM
- JMM中定義了一套在多線程讀寫共享數據時,對數據的可見性,有序性和原子性的規則和保障
內存模型之原子性
我們將在下面仔細介紹原子性的特點
原子性介紹
我們首先介紹一下原子性:
- 原子性是指將一系列操作規劃為一個操作,全稱不可分離進行
原子性的注意點:
- 我們在單線程下不會出現原子性的問題
- 但在多線程下,每條語句的實際底層操作不止一步,可能就會導致操作錯誤
原子性問題
我們給出一個簡單的例子來解釋原子性:
package cn.itcast.jvm.t4.avo;
// 在下述操作中,我們分別創造兩個線程,分別執行i++和i--50000次,按正常邏輯來說結果應該為0
public class Demo4_1 {
static int i = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int j = 0; j < 50000; j++) {
i++;
}
});
Thread t2 = new Thread(() -> {
for (int j = 0; j < 50000; j++) {
i--;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(i);
}
}
但我們多次運行的結果如下:
// 每次結果均不相同
302
-986
0
原子性分析
首先我們分別給出i++和i–的底層操作:
// i++
getstatic i // 獲取靜態變量i的值
iconst_1 // 準備常量1
iadd // 加法
putstatic i // 將修改後的值存入靜態變量i
// i--
getstatic i // 獲取靜態變量i的值
iconst_1 // 準備常量1
isub // 減法
putstatic i // 將修改後的值存入靜態變量i
我們的原子性分為兩種情況:
- 單線程情況下:我們的順序肯定是按照正常順序來執行
- 多線程情況下:我們i++的操作按順序執行,i–的操作按順序執行,但兩者操作可能會交替進行
首先我們給出單線程情況下底層代碼:
// 單線程
// 假設i的初始值為0
getstatic i // 線程1-獲取靜態變量i的值 線程內i=0
iconst_1 // 線程1-準備常量1
iadd // 線程1-自增 線程內i=1
putstatic i // 線程1-將修改後的值存入靜態變量i 靜態變量i=1
getstatic i // 線程1-獲取靜態變量i的值 線程內i=1
iconst_1 // 線程1-準備常量1
isub // 線程1-自減 線程內i=0
putstatic i // 線程1-將修改後的值存入靜態變量i 靜態變量i=0
然後我們分別給出多線程情況下多種結果的底層代碼:
// 多線程
// 負數
// 假設i的初始值為0
getstatic i // 線程1-獲取靜態變量i的值 線程內i=0
getstatic i // 線程2-獲取靜態變量i的值 線程內i=0
iconst_1 // 線程1-準備常量1
iadd // 線程1-自增 線程內i=1
putstatic i // 線程1-將修改後的值存入靜態變量i 靜態變量i=1
iconst_1 // 線程2-準備常量1
isub // 線程2-自減 線程內i=-1
putstatic i // 線程2-將修改後的值存入靜態變量i 靜態變量i=-1
// 正數
// 假設i的初始值為0
getstatic i // 線程1-獲取靜態變量i的值 線程內i=0
getstatic i // 線程2-獲取靜態變量i的值 線程內i=0
iconst_1 // 線程1-準備常量1
iadd // 線程1-自增 線程內i=1
iconst_1 // 線程2-準備常量1
isub // 線程2-自減 線程內i=-1
putstatic i // 線程2-將修改後的值存入靜態變量i 靜態變量i=-1
putstatic i // 線程1-將修改後的值存入靜態變量i 靜態變量i=1
原子性實現
那麼我們該如何實現多線程的原子性:
- 使用synchronized(同步關鍵字)
我們這裡給出synchronized的使用方式:
synchronized( 對象 ) {
// 要作為原子操作代碼
}
我們如果要實現之前的代碼,我們可以將代碼修改為:
package cn.itcast.jvm.t4.avo;
public class Demo4_1 {
// 這裡的i應該被多線程共用,設為靜態變量
static int i = 0;
// 這裡是Obj對象,我們設置它為鎖,注意兩個線程中的synchronized所對應的鎖應該是同一個對象(鎖)
static Object obj = new Object();
public static void main(String[] args) throws InterruptedException {
// 採用synchronized設置鎖實現原子性,這樣i++操作就會完整進行
Thread t1 = new Thread(() -> {
synchronized (obj) {
for (int j = 0; j < 50000; j++) {
i++;
}
}
});
Thread t2 = new Thread(() -> {
// 採用synchronized設置鎖實現原子性,這樣i--操作就會完整進行
synchronized (obj) {
for (int j = 0; j < 50000; j++) {
i--;
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
// 我們的輸出結果自然是0了~
System.out.println(i);
}
}
內存模型之可見性
我們將在下面仔細介紹可見性的特點
可見性介紹
首先我們簡單介紹一下可見性的定義:
- 我們需要保證,在多個線程中,對同一變量的修改需要被其他線程所知道並且可以調用
可見性的注意點:
- 我們的程序往往具有自動優化,對於多次取同一值的數據可能會封裝在自己的程序中而不是在源程序讀取,這就會導致可見性失效
可見性問題
我們同樣給出一段代碼作為可見性的案例:
package cn.itcast.jvm.t4.avo;
public class Demo4_2 {
static boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){
}
});
t.start();
Thread.sleep(1000);
run = false; // 線程t不會如預想的停下來
}
}
我們的運行結果如下:
// 我們上述代碼希望:程序在執行1s後停止運行,但我們的程序卻一直運行不會停止
...
可見性分析
首先我們回顧開頭的注意點:
- 程序具有自身很多的優化步驟,可能哪一步就會導致我們的程序出錯
我們來簡單分析:
- 初始狀態, t 線程剛開始從主內存讀取了 run 的值到工作內存。
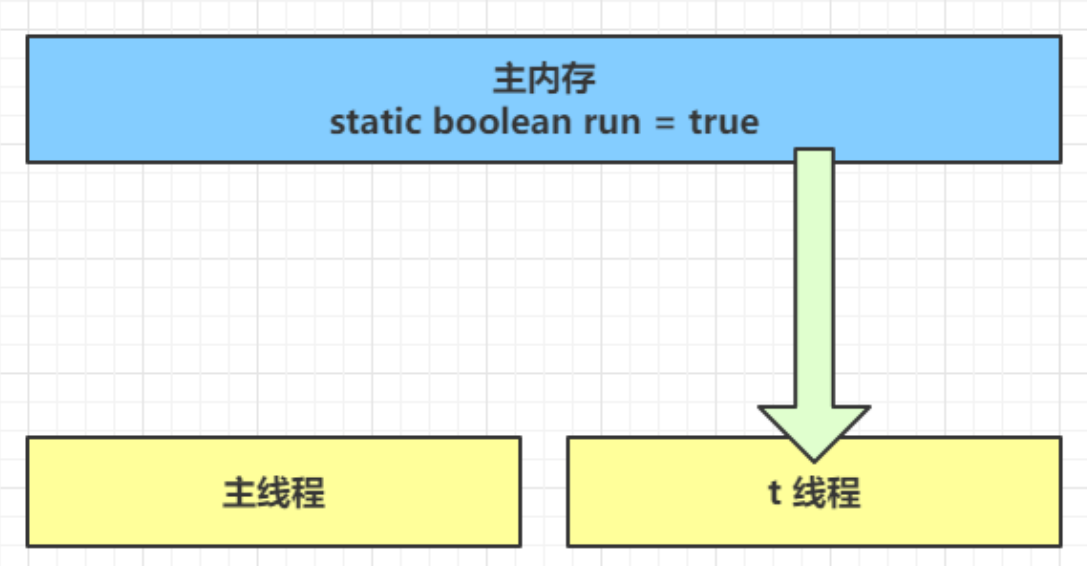
- 線程要頻繁從主內存中讀取 run 的值,JIT 編譯器會將 run 的值緩存至自己工作內存中的高速緩存中,減少對主存中 run 的訪問
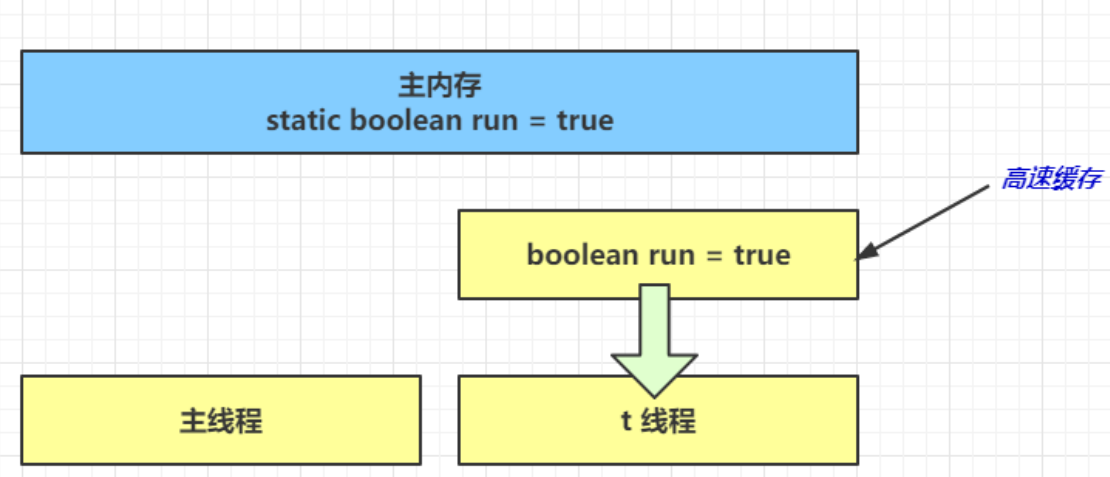
- 1 秒之後,main 線程修改了 run 的值,並同步至主存,而 t 是從自己工作內存中的高速緩存中讀取這個變量的值,結果永遠是舊值
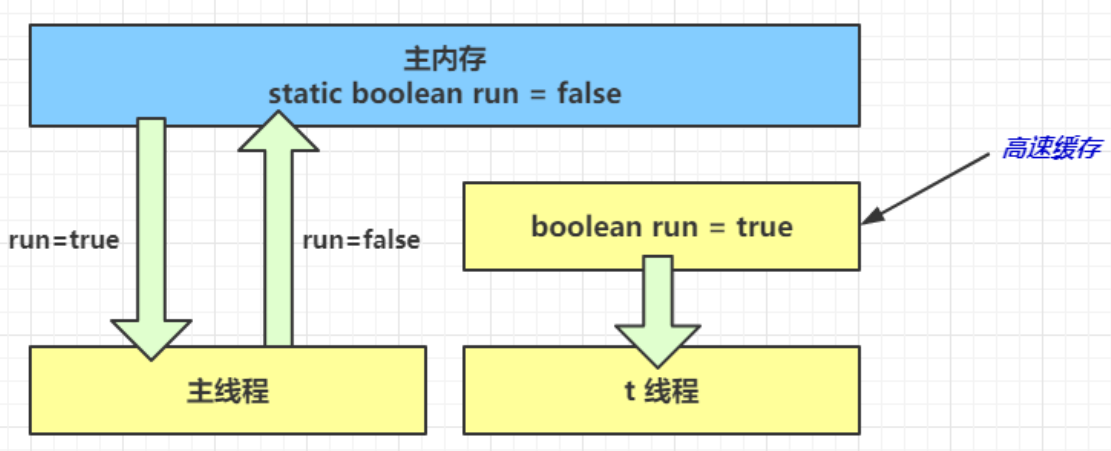
可見性實現
我們的可見性經常通過一種修飾詞來實現:
- volatile(易變關鍵字)
- 它可以用來修飾成員變量和靜態成員變量
- 他可以避免線程從自己的工作緩存中查找變量的值,必須到主存中獲取它的值,線程操作 volatile 變量都是直接操作主存
同時我們給出另一種方法:
- synchronized 語句塊
- synchronized既可以保證代碼塊的原子性,也同時保證代碼塊內變量的可見性
- 但缺點是synchronized是屬於重量級操作,性能相對更低
我們如果修改之前代碼,就可以採用volatile修改:
package cn.itcast.jvm.t4.avo;
public class Demo4_2 {
static volatile boolean run = true;
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(()->{
while(run){
}
});
t.start();
Thread.sleep(1000);
run = false; // 線程t不會如預想的停下來
}
}
內存模型之有序性
我們將在下面仔細介紹有序性的特點
有序性介紹
首先我們簡單介紹一下有序性的定義:
- 有序性就是指我們底層代碼實現的具體順序,在正常情況下是按正常順序執行
有序性的注意點:
- 同樣底層也會進行部分優化,對於有序性的優化常常被稱為指令重排,是指在不影響操作的前提下進行語句的優化調整
有序性問題
我們同樣給出一段代碼:
int num = 0;
boolean ready = false;
// 線程1 執行此方法
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
// 線程2 執行此方法
public void actor2(I_Result r) {
num = 2;
ready = true;
}
我們下面會給出其所有情況:
// 具體分為四種情況,前三種屬於正常的多線程無鎖導致的情況
// 情況1:線程1 先執行,這時 ready = false,所以進入 else 分支結果為 1
// 情況2:線程2 先執行 num = 2,但沒來得及執行 ready = true,線程1 執行,還是進入 else 分支,結果為1
// 情況3:線程2 執行到 ready = true,線程1 執行,這回進入 if 分支,結果為 4(因為 num 已經執行過了)
// 但是第四種!卻是因為代碼重排所導致的情況:
有序性分析
首先我們在重新介紹一下指令重排:
- JIT 編譯器在運行時的一些優化,這個現象需要通過大量測試才能復現
我們可以給出結果為0的執行順序:
線程2:ready = true;(由於操作更加簡單,導致JIT將它放在前面編譯)
線程1:if判斷 true
線程1:r.r1 = num + num;(此時num為0),結果r1=0
JVM 會在不影響正確性的前提下,可以調整語句的執行順序:
// 下面是模擬情況:
static int i;
static int j;
// 在某個線程內執行如下賦值操作
// i為較為耗時的操作,j為簡單操作
i = ...;
j = ...;
// 底層代碼會認為i和j的賦值操作毫無關係,他們誰先執行都可以,所以會優先執行簡單的操作
// 所以我們的代碼可能變為:
static int i;
static int j;
j = ...;
i = ...;
有序性實現
我們的可見性經常通過一種修飾詞來實現:
- volatile 修飾的變量,可以禁用指令重排
所以我們的代碼經過修改後可以改造為以下代碼:
int num = 0;
boolean volatile ready = false;
// 線程1 執行此方法
public void actor1(I_Result r) {
if(ready) {
r.r1 = num + num;
} else {
r.r1 = 1;
}
}
// 線程2 執行此方法
public void actor2(I_Result r) {
num = 2;
ready = true;
}
happens-before
我們在最後插入一個簡單的內容happens-before :
- 規定了哪些寫操作對其它線程的讀操作可見,它是可見性與有序性的一套規則總結
我們來簡單介紹一些:
- 線程 start 前對變量的寫,對該線程開始後對該變量的讀可見
static int x;
x = 10;
new Thread(()->{
System.out.println(x);
},"t2").start();
- 線程對 volatile 變量的寫,對接下來其它線程對該變量的讀可見
volatile static int x;
new Thread(()->{
x = 10;
},"t1").start();
new Thread(()->{
System.out.println(x);
},"t2").start();
- 線程解鎖 m 之前對變量的寫,對於接下來對 m 加鎖的其它線程對該變量的讀可見
static int x;
static Object m = new Object();
new Thread(()->{
synchronized(m) {
x = 10;
}
},"t1").start();
new Thread(()->{
synchronized(m) {
System.out.println(x);
}
},"t2").start();
- 線程結束前對變量的寫,對其它線程得知它結束後的讀可見(比如其它線程調用 t1.isAlive() 或t1.join()等待它結束)
static int x;
Thread t1 = new Thread(()->{
x = 10;
},"t1");
t1.start();
t1.join();
System.out.println(x);
- 線程 t1 打斷 t2(interrupt)前對變量的寫,對於其他線程得知 t2 被打斷後對變量的讀可見
static int x;
public static void main(String[] args) {
Thread t2 = new Thread(()->{
while(true) {
if(Thread.currentThread().isInterrupted()) {
System.out.println(x);
break;
}
}
},"t2");
t2.start();
new Thread(()->{
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
x = 10;
t2.interrupt();
},"t1").start();
while(!t2.isInterrupted()) {
Thread.yield();
}
System.out.println(x);
}
- 對變量默認值(0,false,null)的寫,對其它線程對該變量的讀可見
- 具有傳遞性,如果 x hb-> y 並且 y hb-> z 那麼有 x hb-> z
樂觀鎖與悲觀鎖
這一小節我們來詳細介紹一下樂觀鎖和悲觀鎖的概念以及原型
樂觀鎖與悲觀鎖簡介
我們首先分別簡單介紹一下樂觀鎖和悲觀鎖:
- 樂觀鎖的思想:最樂觀的估計,不怕別的線程來修改共享變量,就算改了也沒關係,我繼續重試即可。
- 悲觀鎖的思想:最悲觀的估計,得防着其它線程來修改共享變量,針對共享數據直接上鎖,只有我解鎖後你們才能搶奪
我們在這裡再簡單講一下兩種鎖的日常選用:
- 樂觀鎖用於競爭不激烈且為多核CPU的情況,因為其實樂觀鎖的不斷嘗試需要cpu處理並且也會消耗一定內存
- 悲觀鎖用於競爭激烈需要搶奪資源的情況下,我們直接停止其他操作可以減少其他不必要的內耗
樂觀鎖實現
樂觀鎖的實現是採用CAS:
- CAS 即 Compare and Swap ,它體現的一種樂觀鎖的思想
我們通過一個簡單示例展示:
// 需要不斷嘗試
while(true) {
int 舊值 = 共享變量 ; // 比如拿到了當前值 0
int 結果 = 舊值 + 1; // 在舊值 0 的基礎上增加 1 ,正確結果是 1
/*
這時候如果別的線程把共享變量改成了 5,本線程的正確結果 1 就作廢了,這時候
compareAndSwap 返回 false,重新嘗試,直到:
compareAndSwap 返回 true,表示我本線程做修改的同時,別的線程沒有干擾
*/
if( compareAndSwap ( 舊值, 結果 )) {
// 成功,退出循環
}
}
悲觀鎖實現
樂觀鎖的實現是採用synchronized:
- synchronized體現的是一種悲觀鎖的思想
我們通過一個簡單示例展示:
package cn.itcast.jvm.t4.avo;
// 我們進行操作時,直接上鎖,不允許其他進程涉及!
public class Demo4_1 {
// 這裡的i應該被多線程共用,設為靜態變量
static int i = 0;
// 這裡是Obj對象,我們設置它為鎖,注意兩個線程中的synchronized所對應的鎖應該是同一個對象(鎖)
static Object obj = new Object();
public static void main(String[] args) throws InterruptedException {
// 採用synchronized設置鎖實現原子性,這樣i++操作就會完整進行
Thread t1 = new Thread(() -> {
synchronized (obj) {
for (int j = 0; j < 50000; j++) {
i++;
}
}
});
Thread t2 = new Thread(() -> {
// 採用synchronized設置鎖實現原子性,這樣i--操作就會完整進行
synchronized (obj) {
for (int j = 0; j < 50000; j++) {
i--;
}
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(i);
}
}
原子操作類
其實JUC中為我們提供了原子操作類:
- 可以提供線程安全的操作,例如:AtomicInteger、AtomicBoolean等,它們底層就是採用 CAS 技術 + volatile 來實現的。
我們採用改寫之前的一個例子來進行展示:
package cn.itcast.jvm.t4.avo;
import java.util.concurrent.atomic.AtomicInteger;
public class Demo4_4 {
// 創建原子整數對象
private static AtomicInteger i = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int j = 0; j < 5000; j++) {
i.getAndIncrement(); // 獲取並且自增 i++
// i.incrementAndGet(); 自增並且獲取 ++i
}
});
Thread t2 = new Thread(() -> {
for (int j = 0; j < 5000; j++) {
i.getAndDecrement(); // 獲取並且自減 i--
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(i);
}
}
synchronized 優化
這一小節我們來詳細介紹一下synchronized的優化部分
Mark Word
我們首先來介紹一個概念:
- Java HotSpot 虛擬機中,每個對象都有對象頭(包括 class 指針和 Mark Word)。
那麼我們主要需要這個Mark Word來存儲信息:
- Mark Word 平時存儲這個對象的哈希碼,分代年齡
- 當加鎖時這些信息就根據情況被替換為 標記位,線程鎖記錄指針,重量級鎖指針,線程ID 等內容
輕量級鎖
首先我們先來介紹一下輕量級鎖:
- 如果一個對象雖然有多線程訪問,但多線程訪問的時間是錯開的(也就是沒有競爭),那麼可以使用輕量級鎖來優化。
我們通過一個簡單案例展示:
static Object obj = new Object();
public static void method1() {
synchronized( obj ) {
// 同步塊 A
method2();
}
}
public static void method2() {
synchronized( obj ) {
// 同步塊 B
}
}
我們會發現即使上述為兩個鎖,但是同時都屬於當前主線程下,並且是按順序執行,這是就採用了輕量級鎖
我們通過一個表格寫出其具體流程:
| 線程 1 | 對象 Mark Word | 線程 2 |
|---|---|---|
| 訪問同步塊 A,把 Mark 複製到 線程 1 的鎖記錄 | 01(無鎖) | – |
| CAS 修改 Mark 為線程 1 鎖記錄 地址 | 01(無鎖) | – |
| 成功(加鎖) | 00(輕量鎖)線程 1 鎖記錄地址 | – |
| 執行同步塊 A | 00(輕量鎖)線程 1 鎖記錄地址 | – |
| 訪問同步塊 B,把 Mark 複製到 線程 1 的鎖記錄 | 00(輕量鎖)線程 1 鎖記錄地址 | – |
| CAS 修改 Mark 為線程 1 鎖記錄 地址 | 00(輕量鎖)線程 1 鎖記錄地址 | – |
| 失敗(發現是自己的鎖) | 00(輕量鎖)線程 1 鎖記錄地址 | – |
| 鎖重入 | 00(輕量鎖)線程 1 鎖記錄地址 | – |
| 執行同步塊 B | 00(輕量鎖)線程 1 鎖記錄地址 | – |
| 同步塊 B 執行完畢 | 00(輕量鎖)線程 1 鎖記錄地址 | – |
| 同步塊 A 執行完畢 | 00(輕量鎖)線程 1 鎖記錄地址 | – |
| 成功(解鎖) | 01(無鎖) | – |
| – | 01(無鎖) | 訪問同步塊 A,把 Mark 複製到 線程 2 的鎖記錄 |
| – | 01(無鎖) | CAS 修改 Mark 為線程 2 鎖記錄 地址 |
| – | 00(輕量鎖)線程 2 鎖記錄地址 | 成功(加鎖) |
| – | … | … |
鎖的膨脹
我們同樣先來介紹鎖膨脹的概念:
- 如果在嘗試加輕量級鎖的過程中,CAS 操作無法成功
- 這時一種情況就是有其它線程為此對象加上了輕量級鎖(有競爭),這時需要進行鎖膨脹,將輕量級鎖變為重量級鎖。
我們直接給出一個表格寫出其具體流程:
| 程 1 | 對象 Mark | 線程 2 |
|---|---|---|
| 訪問同步塊,把 Mark 複製到線程 1 的鎖記錄 | 01(無鎖) | – |
| CAS 修改 Mark 為線程 1 鎖記錄地 址 | 01(無鎖) | – |
| 成功(加鎖) | 00(輕量鎖)線程 1 鎖 記錄地址 | – |
| 執行同步塊 | 00(輕量鎖)線程 1 鎖 記錄地址 | – |
| 執行同步塊 | 00(輕量鎖)線程 1 鎖 記錄地址 | 訪問同步塊,把 Mark 複製 到線程 2 |
| 執行同步塊 | 00(輕量鎖)線程 1 鎖 記錄地址 | CAS 修改 Mark 為線程 2 鎖 記錄地址 |
| 執行同步塊 | 00(輕量鎖)線程 1 鎖 記錄地址 | 失敗(發現別人已經佔了 鎖) |
| 執行同步塊 | 00(輕量鎖)線程 1 鎖 記錄地址 | CAS 修改 Mark 為重量鎖 |
| 執行同步塊 | 10(重量鎖)重量鎖指 針 | 阻塞中 |
| 執行完畢 | 10(重量鎖)重量鎖指 針 | 阻塞中 |
| 失敗(解鎖) | 10(重量鎖)重量鎖指 針 | 阻塞中 |
| 釋放重量鎖,喚起阻塞線程競爭 | 01(無鎖) | 阻塞中 |
| – | 10(重量鎖) | 競爭重量鎖 |
| – | 10(重量鎖) | 成功(加鎖) |
| – | … | … |
重量級鎖
我們這裡也來簡單介紹一下重量級鎖的優化方法:
- 重量級鎖競爭的時候,還可以使用自旋來進行優化
- 如果當前線程自旋成功(即這時候持鎖線程已經退出了同步塊,釋放了鎖),這時當前線程就可以避免阻塞
我們對自旋進行簡單補充:
- 在 Java 6 之後自旋鎖是自適應的
- 比如對象剛剛的一次自旋操作成功過,那麼認為這次自旋成功的可能性會高,就多自旋幾次;反之,就少自旋甚至不自旋
- 自旋會佔用 CPU 時間,單核 CPU 自旋就是浪費,多核 CPU 自旋才能發揮優勢。
- Java 7 之後不能控制是否開啟自旋功能
首先我們給出自旋成功的流程展示:
| 線程 1 (cpu 1 上) | 對象 Mark | 線程 2 (cpu 2 上) |
|---|---|---|
| – | 10(重量鎖) | – |
| 訪問同步塊,獲取 monitor | 10(重量鎖)重量鎖指針 | – |
| 成功(加鎖) | 10(重量鎖)重量鎖指針 | – |
| 執行同步塊 | 10(重量鎖)重量鎖指針 | – |
| 執行同步塊 | 10(重量鎖)重量鎖指針 | 訪問同步塊,獲取 monitor |
| 執行同步塊 | 10(重量鎖)重量鎖指針 | 自旋重試 |
| 執行完畢 | 10(重量鎖)重量鎖指針 | 自旋重試 |
| 成功(解鎖) | 01(無鎖) | 自旋重試 |
| – | 10(重量鎖)重量鎖指針 | 成功(加鎖) |
| – | 10(重量鎖)重量鎖指針 | 執行同步塊 |
| – | … | … |
然後我們給出自旋失敗的流程展示:
| 線程 1(cpu 1 上) | 對象 Mark | 線程 2(cpu 2 上) |
|---|---|---|
| – | 10(重量鎖) | – |
| 訪問同步塊,獲取 monitor | 10(重量鎖)重量鎖指針 | – |
| 成功(加鎖) | 10(重量鎖)重量鎖指針 | – |
| 執行同步塊 | 10(重量鎖)重量鎖指針 | – |
| 執行同步塊 | 10(重量鎖)重量鎖指針 | 訪問同步塊,獲取 monitor |
| 執行同步塊 | 10(重量鎖)重量鎖指針 | 自旋重試 |
| 執行同步塊 | 10(重量鎖)重量鎖指針 | 自旋重試 |
| 執行同步塊 | 10(重量鎖)重量鎖指針 | 自旋重試 |
| 執行同步塊 | 10(重量鎖)重量鎖指針 | 阻塞 |
| – | … | … |
偏向鎖
我們首先來介紹一下偏向鎖:
- 輕量級鎖在沒有競爭時(就自己這個線程),每次重入仍然需要執行 CAS 操作,Java 6 中引入了偏向鎖來做進一步優化
- 只有第一次使用 CAS 將線程 ID 設置到對象的 Mark Word 頭,之後發現這個線程 ID是自己的就表示沒有競爭,不用重新 CAS.
我們給出偏向鎖的一些補充信息:
- 撤銷偏向需要將持鎖線程升級為輕量級鎖,這個過程中所有線程需要暫停(STW)
- 訪問對象的 hashCode 也會撤銷偏向鎖
- 如果對象雖然被多個線程訪問,但沒有競爭,這時偏向了線程 T1 的對象仍有機會重新偏向 T2,重偏向會重置對象的 Thread ID
- 撤銷偏向和重偏向都是批量進行的,以類為單位
- 如果撤銷偏向到達某個閾值,整個類的所有對象都會變為不可偏向的
- 可以主動使用 -XX:-UseBiasedLocking 禁用偏向鎖
我們採用輕量級鎖的代碼但是加入了偏向鎖之後的流程:
| 線程 1 | 對象 Mark |
|---|---|
| 訪問同步塊 A,檢查 Mark 中是否有線程 ID | 101(無鎖可偏向) |
| 嘗試加偏向鎖 | 101(無鎖可偏向)對象 hashCode |
| 成功 | 101(無鎖可偏向)線程ID |
| 執行同步塊 A | 101(無鎖可偏向)線程ID |
| 訪問同步塊 B,檢查 Mark 中是否有線程 ID | 101(無鎖可偏向)線程ID |
| 是自己的線程 ID,鎖是自己的,無需做更多操作 | 101(無鎖可偏向)線程ID |
| 執行同步塊 B | 101(無鎖可偏向)線程ID |
| 執行完畢 | 101(無鎖可偏向)對象 hashCode |
其它優化
我們下面來簡單介紹一下其他的幾種優化:
- 減少上鎖時間
/*
上鎖期間的代碼是影響上鎖時間的最大因素
我們應該確保同步代碼塊中盡量短
*/
- 減少鎖的粒度
/*
將一個鎖拆分為多個鎖提高並發度
例如:LinkedBlockingQueue 入隊和出隊使用不同的鎖,相對於LinkedBlockingArray只有一個鎖效率要高
*/
- 鎖粗化
/*
多次循環進入同步塊不如同步塊內多次循環
另外 JVM 可能會做如下優化,把多次 append 的加鎖操作粗化為一次(因為都是對同一個對象加鎖,沒必要重入多次)
例如:new StringBuffer().append("a").append("b").append("c");
*/
- 鎖消除
/*
JVM 會進行代碼的逃逸分析,例如某個加鎖對象是方法內局部變量,不會被其它線程所訪問到,這時候就會被即時編譯器忽略掉所有同步操作。
*/
- 讀寫分離
/*
CopyOnWriteArrayList
ConyOnWriteSet
*/
結束語
到這裡我們JVM的內存模型篇就結束了,希望能為你帶來幫助~
附錄
該文章屬於學習內容,具體參考B站黑馬程序員滿老師的JVM完整教程
這裡附上視頻鏈接:01-JMM-概述_嗶哩嗶哩_bilibili


