JVM學習筆記——垃圾回收篇
JVM學習筆記——垃圾回收篇
在本系列內容中我們會對JVM做一個系統的學習,本片將會介紹JVM的垃圾回收部分
我們會分為以下幾部分進行介紹:
- 判斷垃圾回收對象
- 垃圾回收算法
- 分代垃圾回收
- 垃圾回收器
- 垃圾回收調優
判斷垃圾回收對象
本小節將會介紹如何判斷垃圾回收對象
引用計數法
首先我們先來介紹引用計數法的定義:
- 我們為對象附上一個當前使用量
- 當有線程使用時,我們將該值加一;當線程停止使用時,我們將該值減一
- 噹噹前使用量大於零時,我們創建該對象;噹噹前使用量減少為零時,我們將該對象當作垃圾回收對象
但該方法存在一個致命問題:
- 當兩個對象互相調用對方時,就會導致當前使用量一直不為空,佔用內存
可達性分析算法
同樣我們先來簡單介紹可達性分析算法:
- 我們首先判定一些對象為Root對象
- 我們根據這些對象來選擇判定其他對象是否為垃圾回收對象
- 當該對象直接或間接被Root對象所引用時,我們不設置為垃圾回收對象;當沒有被Root對象連接時,設置為垃圾回收對象
然後我們來簡單介紹一下Root對象的分類(來自MAT工具統計):
- System Class:直屬於Java包下的相關類,包括有Object,String,Stream,Buffer等
- Native Stack:直屬於操作系統交互的類,包括有wait等
- Busy Monitor:讀鎖機制相關的類,當前狀態下被鎖定的對象是無法當作垃圾回收對象的
- Thread:互動線程,線程相關的類也無法當作垃圾回收對象
可達性分析算法就是目前Java虛擬機所使用的垃圾回收器判定方法
五種引用
下面我們將會介紹JVM中常用的五種引用方法,他們分別對應着不同的回收對象判定情況:
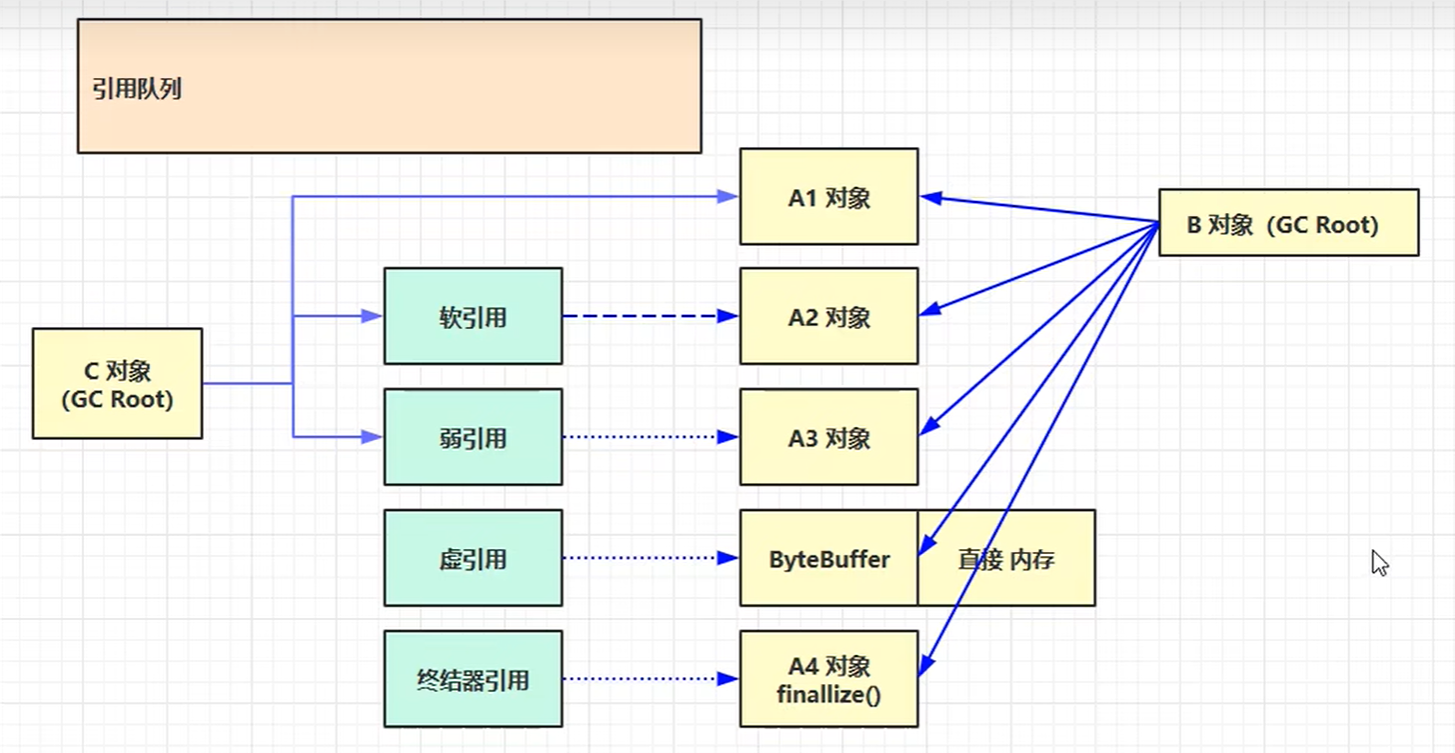
我們下面來一一介紹
強引用
上述圖片中的A1對象就是強引用示例
我們下面介紹強引用的概念:
- 強引用就是由Root對象直接引用的對象
然後我們介紹強引用的回收概念:
- 只有當所有強引用連接都消失時,該對象才會被列為垃圾回收對象
- 例如上圖,A1對象由B,C兩個對象所強引用連接,只有當兩個對象都取消引用後,A1對象才會被列入回收對象
軟引用
上述圖片中的A2對象就是軟引用示例
我們下面介紹軟引用的概念:
- 軟引用不是由根Root直接引用,而是採用一個軟引用對象SoftReference連接
然後我們介紹軟引用的回收概念:
- 當該對象沒有被強引用連接,被軟引用連接時有可能會被回收
- 每次發生垃圾回收,如果垃圾回收後的內存夠用,則不進行軟引用對象的垃圾回收;若內存不足,則進行軟引用對象的垃圾回收
此外我們的軟引用對象也是會佔用內存的,所以我們也需要採用其他方法將軟引用對象回收:
- 我們通常將軟引用對象綁定一個引用隊列
- 當該軟引用對象不再連接任何對象時,將其放入引用隊列,引用隊列會進行檢測,檢測到軟引用對象就會對其進行垃圾回收
我們首先給出軟引用對象的相關測試代碼:
package cn.itcast.jvm.t2;
import java.io.IOException;
import java.lang.ref.SoftReference;
import java.util.ArrayList;
import java.util.List;
/**
* 演示軟引用
* -Xmx20m -XX:+PrintGCDetails -verbose:gc
*/
public class Demo2_3 {
private static final int _4MB = 4 * 1024 * 1024;
public static void main(String[] args) throws IOException {
// 這部分是強引用對象,我們會發現所有內存都放在內部,導致內存不足
List<byte[]> list = new ArrayList<>();
for (int i = 0; i < 5; i++) {
list.add(new byte[_4MB]);
}
System.in.read();
// 調用下列方法(軟引用)
soft();
}
// 軟引用
public static void soft() {
// 軟引用邏輯:list --> SoftReference --> byte[]
// 創建軟引用
List<SoftReference<byte[]>> list = new ArrayList<>();
for (int i = 0; i < 5; i++) {
// 首先new一個SoftReference並賦值
SoftReference<byte[]> ref = new SoftReference<>(new byte[_4MB]);
System.out.println(ref.get());
// 將SoftReference加入list
list.add(ref);
System.out.println(list.size());
}
System.out.println("循環結束:" + list.size());
for (SoftReference<byte[]> ref : list) {
System.out.println(ref.get());
}
}
}
/*
調試過程:
如果我們採用強引用方法,正常情況下會在第五次循環時報錯
但是如果我們採用軟引用,我們會在第五次循環時發生gc清理,這時我們前四次的添加(list的前四位)就會被軟引用清除
所以我們在最後循環結束後查看數組會發現:
null
null
null
null
[B@330bedb4
*/
我們再給出軟引用對象回收的相關測試代碼:
package cn.itcast.jvm.t2;
import java.lang.ref.Reference;
import java.lang.ref.ReferenceQueue;
import java.lang.ref.SoftReference;
import java.util.ArrayList;
import java.util.List;
/**
* 演示軟引用, 配合引用隊列
*/
public class Demo2_4 {
private static final int _4MB = 4 * 1024 * 1024;
public static void main(String[] args) {
// 這裡設置了List,裏面的SoftReference是軟引用對象,再在裏面添加的數據就是軟引用對象所引用的A2對象
List<SoftReference<byte[]>> list = new ArrayList<>();
// 引用隊列(類型和引用對象的類型相同即可)
ReferenceQueue<byte[]> queue = new ReferenceQueue<>();
for (int i = 0; i < 5; i++) {
// 關聯了引用隊列, 當軟引用所關聯的 byte[]被回收時,軟引用自己會加入到 queue 中去
SoftReference<byte[]> ref = new SoftReference<>(new byte[_4MB], queue);
System.out.println(ref.get());
list.add(ref);
System.out.println(list.size());
}
// 從隊列中獲取無用的 軟引用對象,並移除
Reference<? extends byte[]> poll = queue.poll();
while( poll != null) {
list.remove(poll);
poll = queue.poll();
}
System.out.println("===========================");
for (SoftReference<byte[]> reference : list) {
System.out.println(reference.get());
}
}
}
/*
和之前那此調試相同,前四次正常運行,在第五次時進行了gc清理
但是在循環結束之後,我們將軟引用對象放入到了引用隊列中並進行了清理,所以這時我們的list中前四次軟引用對象直接消失
我們只能看到list中只有一個對象:
[B@330bedb4
*/
弱引用
上述圖片中的A3對象就是弱引用示例
我們下面介紹強弱引用的概念:
- 弱引用不是由根Root直接引用,而是採用一個弱引用對象WeakReference連接
然後我們介紹弱引用的回收概念:
- 當該對象沒有被強引用連接,被弱引用連接時在進行Full gc時會被強制回收
- 每次進行老年代的Full gc(後面會講到Full gc,這裡就當作大型垃圾回收)時都會被強制回收
此外我們的弱引用對象也是會佔用內存的,所以我們也需要採用相同方法將弱引用對象回收:
- 我們通常將弱引用對象綁定一個引用隊列
- 當該弱引用對象不再連接任何對象時,將其放入引用隊列,引用隊列會進行檢測,檢測到弱引用對象就會對其進行垃圾回收
我們同樣給出弱引用對象的垃圾回收示例代碼:
package cn.itcast.jvm.t2;
import java.lang.ref.Reference;
import java.lang.ref.ReferenceQueue;
import java.lang.ref.SoftReference;
import java.lang.ref.WeakReference;
import java.util.ArrayList;
import java.util.List;
/**
* 演示弱引用
* -Xmx20m -XX:+PrintGCDetails -verbose:gc
*/
public class Demo2_5 {
private static final int _4MB = 4 * 1024 * 1024;
public static void main(String[] args) {
// list --> WeakReference --> byte[]
List<WeakReference<byte[]>> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
WeakReference<byte[]> ref = new WeakReference<>(new byte[_4MB]);
list.add(ref);
for (WeakReference<byte[]> w : list) {
System.out.print(w.get()+" ");
}
System.out.println();
}
System.out.println("循環結束:" + list.size());
}
}
/*
這時我們的小型gc(新生代gc)是不會觸發弱引用全部刪除的(新生代我們後面會講到)
只有當內存全部佔滿後,觸發的Full gc才會導致弱引用的必定回收
例如我們在第5,7次新生代發生內存佔滿,這時觸發了新生代的gc,但是只會刪除部分WeakReference
當我們第9次新生代,老生代內存全部佔滿後會發生一次Full gc,這時就會引起全部弱引用數據刪除,所以我們的數據會變成:
null
null
null
null
null
null
null
null
null
[B@330bedb4
*/
虛引用
上述圖片中的ByteBuffer對象就是虛引用示例
我們下面介紹虛引用的概念:
- 虛引用實際上就是直接內存的引用,我們內存結構篇所學習的ByteBuffer就是例子
- 系統首先會創建一個虛引用,然後這個虛引用會創建一個ByteBuffer對象,ByteBuffer對象通過unsafe來管理直接內存
- 此外,我們的虛引用必定需要綁定一個引用隊列,因為我們的byteBuffer對象是無法控制直接內存的,我們需要檢測虛引用來刪除
然後我們介紹虛引用的回收概念:
- 首先我們會手動刪除或者系統垃圾回收掉ByteBuffer對象
- 這時我們的虛引用和直接內存是不會消失的,但是我們的虛引用會被帶到引用隊列中
- 虛引用中攜帶者Cleaner對象,引用隊列會一直檢測是否有Cleaner對象進入,當檢測到時會執行這個Cleaner方法來刪除直接內存
我們需要注意的是:
- 引用隊列中檢測Cleaner對象的優先級較高,所以效率相關而言比較快
終結器引用
上述圖片的A4對象就是終結器引用
我們下面介紹終結器引用的概念:
- 終結器引用實際上是對象自己定義的finallize方法
- 終結器對象同樣也需要綁定引用隊列,因為他需要靠終結器對象來清除內部對象
然後我們介紹終結器引用的回收概念:
- 如果我們希望清除終結器引用的對象,那麼我們需要先將終結器引用對象導入到引用隊列中
- 引用隊列中同樣也會一直檢測是否出現終結器對象,若出現終結器對象,那麼針對該終結器對象調用其內部對象的finallize方法刪除
我們需要注意的是:
- 引用隊列中檢測終結器對象的優先級較低,所以效率相關而言比較慢
垃圾回收算法
本小節將會介紹垃圾回收的三種基本回收算法
標記清除法
我們首先給出簡單圖示:

我們來做簡單解釋:
- 首先我們找出需要進行垃圾回收的部分並進行標記
- 然後我們將該標記地址部分清除即可(注意:這裡的清除僅僅是記錄起始地址和終止地址,然後在其他內存佔用時再次覆蓋)
該算法的優缺點:
- 執行速度極快
- 但會產生內存碎片,當內存碎片逐漸增多會導致問題
標記整理法
我們首先給出簡單圖示:

我們來做簡單解釋:
- 首先我們根據Root標記出需要垃圾回收的部分
- 然後我們將垃圾回收的部分拋出之後,將後面的部分進行地址騰挪,使其緊湊
該算法的優缺點:
- 不會產生內存碎片,導致內存問題
- 速度較慢,同時整理過程中其他進程全部停止(因為會涉及內存地址重塑,進行其他進程可能會導致內存放置地址錯誤)
區域複製法
我們首先給出簡單圖示:
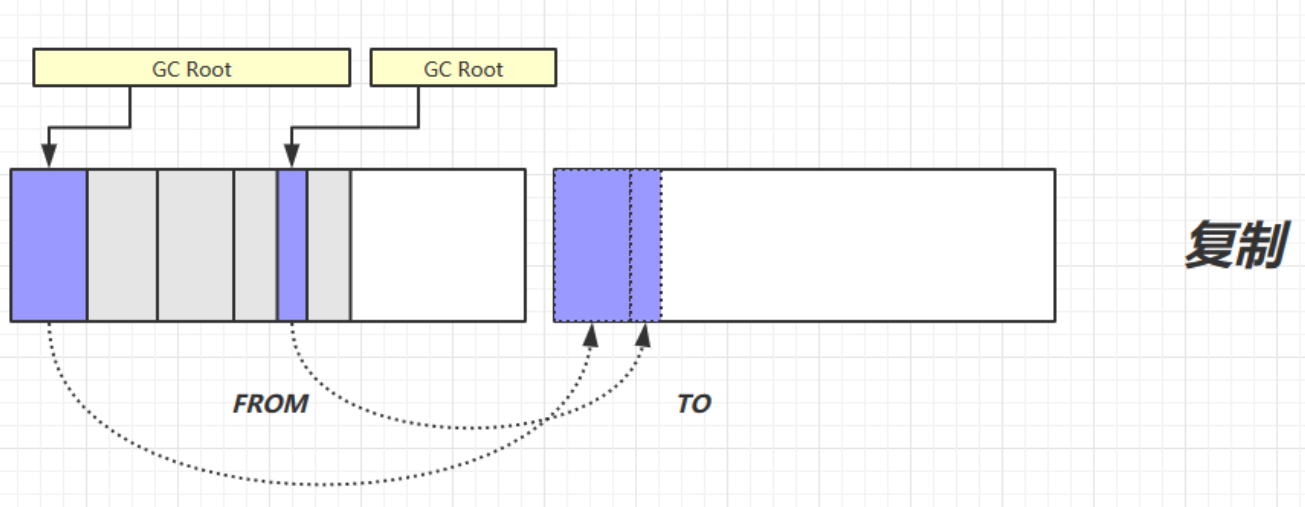
我們來做簡單解釋:
- 我們準備兩塊完全相同的區間,將他們分為From和To區間
- 我們首先在from區間存儲數據,我們直接進行垃圾回收判定
- 然後將需要保存的數據直接放入To區間,垃圾回收的部分不需要管理
- 最後我們將From和To區間的定義交換,將新添加的數據放入現在的From區間(之前騰挪的To區間)
該算法的優缺點:
- 不會產生內存碎片,相對而言比較迅速
- 但需要佔用兩塊相同的地址空間,導致佔用空間較多
分代垃圾回收機制
本小節將會介紹垃圾回收的常用機制
分代垃圾回收機制介紹
我們前面已經介紹了三種垃圾回收算法,但實際上我們的垃圾回收採用的是三種方法的組合方法:
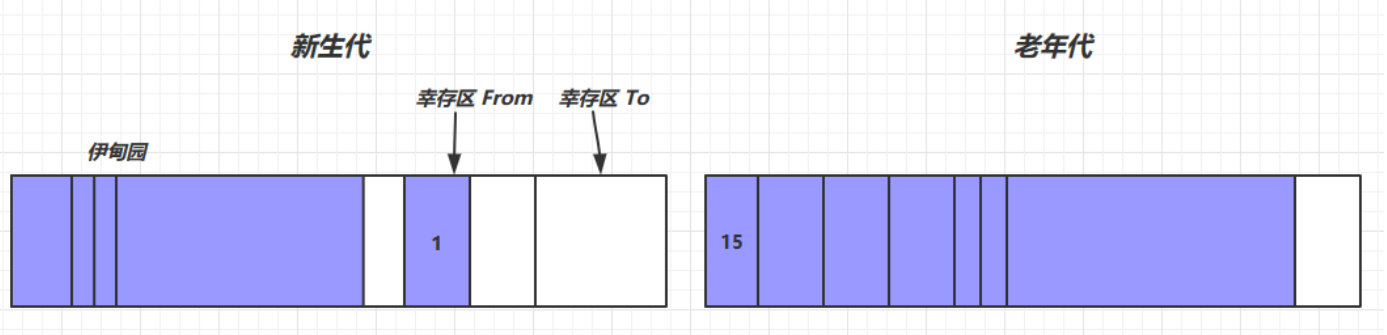
我們首先對大概念進行介紹:
- 新生代:用於存放新產生的內存數據,清除頻繁
- 老生代:用於存放一直使用的內存數據,只有當內存佔滿時才會清理
然後我們對小概念進行介紹:
- 伊甸園:用於存放所有的新產生的內存數據
- 倖存區From:用於存放未被垃圾回收的數據
- 倖存區To:用於進行未被垃圾回收的數據的複製方法
- 倖存值:用於表示內存數據的常用程度,所有內存數據進入時默認值為0,
然後我們對整個回收機制進行介紹:
- 首先我們的新數據都會進入到新生代的伊甸園中去,默認倖存值為0
- 當伊甸園數據滿後,會進行gc,這時我們進行標記清除法,將不需要的內存篩出
- 同時將倖存下來的內存數據放入到倖存區From,倖存值+1,同時進行From和To區間的對調
- 我們繼續進行儲存直到伊甸園再次佔滿,對整個新生代進行gc
- 首先將倖存區From的倖存內存放入To中並將伊甸園的倖存數據放入To,進行區間調換,倖存值+1
- 直到倖存值達到一個閾值(默認為6或者15),該內存數據就會被移動到老年代,新生代仍舊繼續工作
- 直至新生代和老年代全部都佔滿後,這時我們就需要進行大型的垃圾回收,也就是我們之前提到的Full gc!
分代垃圾回收相關VM參數
我們下面介紹一下分代垃圾回收機制的相關參數:
| 含義 | 參數 |
|---|---|
| 堆初始大小 | -Xms |
| 堆最大大小 | -Xmx 或 -XX:MaxHeapSize=size |
| 新生代大小 | -Xmn 或 (-XX:NewSize=size + -XX:MaxNewSize=size ) |
| 倖存區比例(動態) | -XX:InitialSurvivorRatio=ratio 和 -XX:+UseAdaptiveSizePolicy |
| 倖存區比例 | -XX:SurvivorRatio=ratio |
| 晉陞閾值 | -XX:MaxTenuringThreshold=threshold |
| 晉陞詳情 | -XX:+PrintTenuringDistribution |
| GC詳情 | -XX:+PrintGCDetails -verbose:gc |
| FullGC 前 MinorGC (小gc) | -XX:+ScavengeBeforeFullGC |
分代垃圾回收案例展示
我們通過一個簡單的實例來展示分代垃圾回收的實際演示:
// 相關配置信息:配置默認大小,設置回收方法,顯示GC詳情,開啟FullGC前進行gc
// -Xms20M -Xmx20M -Xmn10M -XX:+UseSerialGC -XX:+PrintGCDetails -verbose:gc -XX:-ScavengeBeforeFullGC
/*
首先我們展示不添加內存的狀況
*/
package cn.itcast.jvm.t2;
import java.util.ArrayList;
public class Demo2_1 {
private static final int _512KB = 512 * 1024;
private static final int _1MB = 1024 * 1024;
private static final int _6MB = 6 * 1024 * 1024;
private static final int _7MB = 7 * 1024 * 1024;
private static final int _8MB = 8 * 1024 * 1024;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
ArrayList<byte[]> list = new ArrayList<>();
}).start();
System.out.println("sleep....");
Thread.sleep(1000L);
}
}
/*
其中def new generation,eden space是新生代,tenured generation是老年代,from,to倖存區
Heap
def new generation total 9216K, used 4510K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 55% used [0x00000000fec00000, 0x00000000ff067aa0, 0x00000000ff400000)
from space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
to space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)
tenured generation total 10240K, used 0K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
the space 10240K, 0% used [0x00000000ff600000, 0x00000000ff600000, 0x00000000ff600200, 0x0000000100000000)
Metaspace used 4362K, capacity 4714K, committed 4992K, reserved 1056768K
class space used 480K, capacity 533K, committed 640K, reserved 1048576K
*/
/*
然後我們展示添加1mb的情況
*/
package cn.itcast.jvm.t2;
import java.util.ArrayList;
public class Demo2_1 {
private static final int _512KB = 512 * 1024;
private static final int _1MB = 1024 * 1024;
private static final int _6MB = 6 * 1024 * 1024;
private static final int _7MB = 7 * 1024 * 1024;
private static final int _8MB = 8 * 1024 * 1024;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
ArrayList<byte[]> list = new ArrayList<>();
list.add(new byte[_1MB]);
}).start();
System.out.println("sleep....");
Thread.sleep(1000L);
}
}
/*
我們可以發現新生代數據增加,老年代未發生變化
Heap
def new generation total 9216K, used 5534K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 67% used [0x00000000fec00000, 0x00000000ff167a40, 0x00000000ff400000)
from space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
to space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)
tenured generation total 10240K, used 0K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
the space 10240K, 0% used [0x00000000ff600000, 0x00000000ff600000, 0x00000000ff600200, 0x0000000100000000)
Metaspace used 4354K, capacity 4714K, committed 4992K, reserved 1056768K
class space used 480K, capacity 533K, committed 640K, reserved 1048576
*/
/*
最後需要補充講解一點:當我們的新生代不足以裝載數據內存時,我們會直接將其裝入老年代(老年代能夠裝載情況下)
*/
package cn.itcast.jvm.t2;
import java.util.ArrayList;
public class Demo2_1 {
private static final int _512KB = 512 * 1024;
private static final int _1MB = 1024 * 1024;
private static final int _6MB = 6 * 1024 * 1024;
private static final int _7MB = 7 * 1024 * 1024;
private static final int _8MB = 8 * 1024 * 1024;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
ArrayList<byte[]> list = new ArrayList<>();
list.add(new byte[_8MB]);
}).start();
System.out.println("sleep....");
Thread.sleep(1000L);
}
}
/*
我們會發現eden的值未發生變化,但是tenured generation裏面裝載了8192K
Heap
def new generation total 9216K, used 4510K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 55% used [0x00000000fec00000, 0x00000000ff067a30, 0x00000000ff400000)
from space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
to space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)
tenured generation total 10240K, used 8192K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
the space 10240K, 80% used [0x00000000ff600000, 0x00000000ffe00010, 0x00000000ffe00200, 0x0000000100000000)
Metaspace used 4360K, capacity 4714K, committed 4992K, reserved 1056768K
class space used 480K, capacity 533K, committed 640K, reserved 1048576K
*/
/*
當然,當我們的新生代和老年代都不足以裝載時,系統報錯~
*/
package cn.itcast.jvm.t2;
import java.util.ArrayList;
public class Demo2_1 {
private static final int _512KB = 512 * 1024;
private static final int _1MB = 1024 * 1024;
private static final int _6MB = 6 * 1024 * 1024;
private static final int _7MB = 7 * 1024 * 1024;
private static final int _8MB = 8 * 1024 * 1024;
public static void main(String[] args) throws InterruptedException {
new Thread(() -> {
ArrayList<byte[]> list = new ArrayList<>();
list.add(new byte[_8MB]);
list.add(new byte[_8MB]);
}).start();
System.out.println("sleep....");
Thread.sleep(1000L);
}
}
/*
我們首先會看到他在Full gc之前做了一次小gc,然後做了一次Full gc,可是這並無法解決問題
[GC (Allocation Failure) [DefNew: 4345K->999K(9216K), 0.0016573 secs][Tenured: 8192K->9189K(10240K), 0.0022899 secs] 12537K->9189K(19456K), [Metaspace: 4352K->4352K(1056768K)], 0.0039931 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
[Full GC (Allocation Failure) [Tenured: 9189K->9124K(10240K), 0.0018331 secs] 9189K->9124K(19456K), [Metaspace: 4352K->4352K(1056768K)], 0.0018528 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
然後系統進行報錯
Exception in thread "Thread-0" java.lang.OutOfMemoryError: Java heap space
at cn.itcast.jvm.t2.Demo2_1.lambda$main$0(Demo2_1.java:20)
at cn.itcast.jvm.t2.Demo2_1$$Lambda$1/1023892928.run(Unknown Source)
at java.lang.Thread.run(Thread.java:750)
最後我們可以看到老年代佔用了89%,第一個數據仍舊保存,但第二個數據無法保存導致報錯
Heap
def new generation total 9216K, used 366K [0x00000000fec00000, 0x00000000ff600000, 0x00000000ff600000)
eden space 8192K, 4% used [0x00000000fec00000, 0x00000000fec5baa8, 0x00000000ff400000)
from space 1024K, 0% used [0x00000000ff500000, 0x00000000ff500000, 0x00000000ff600000)
to space 1024K, 0% used [0x00000000ff400000, 0x00000000ff400000, 0x00000000ff500000)
tenured generation total 10240K, used 9124K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)
the space 10240K, 89% used [0x00000000ff600000, 0x00000000ffee93c0, 0x00000000ffee9400, 0x0000000100000000)
Metaspace used 4379K, capacity 4704K, committed 4992K, reserved 1056768K
class space used 480K, capacity 528K, committed 640K, reserved 1048576K
我們還需要注意的是:即使內存不足發生報錯,但該程序不會結束;系統只會釋放自己當前項目的進程而不會影響其他進程
*/
垃圾回收器
前面我們已經介紹了垃圾回收機制,現在我們來介紹常用的垃圾回收器
STW概念
我們在正式講解垃圾回收器之前,我們先來回顧一個概念STW:
- STW即Stop The World,意思是暫停所有進程處理
- 因為我們在進行垃圾處理時,會涉及到地址空間的整合(標記整理法),這時所有CPU都需要停止操作
串行垃圾回收器
我們首先來介紹串行垃圾回收器的特點:
- 單線程
- 適用於堆內存較小,適合單人電腦
我們給出串行垃圾回收器的展示圖:

我們所需配置:
// 設置 新生代回收方法複製 老年代回收方法為標記整理法
-XX:+UseSerialGC = Serial + SerialOld
我們來簡單解釋一下:
- 串行操作屬於單核CPU處理
- 我們在處理該CPU的垃圾回收時,只有該線程的CPU進行操作
- 但同時老年代採用標記整理法會涉及到內存地址重新規劃,所以其他CPU也需要暫停操作,即STW
吞吐量優先垃圾回收器
我們首先來介紹吞吐量優先垃圾回收器的特點:
- 多線程
- 適用於堆內存較大,需要多核CPU
- 讓單位時間內,STW時間最短,例如每次STW0.2秒,但執行兩次,共用0.4s(總時間最短)
我們給出吞吐量優先垃圾回收器的展示圖:
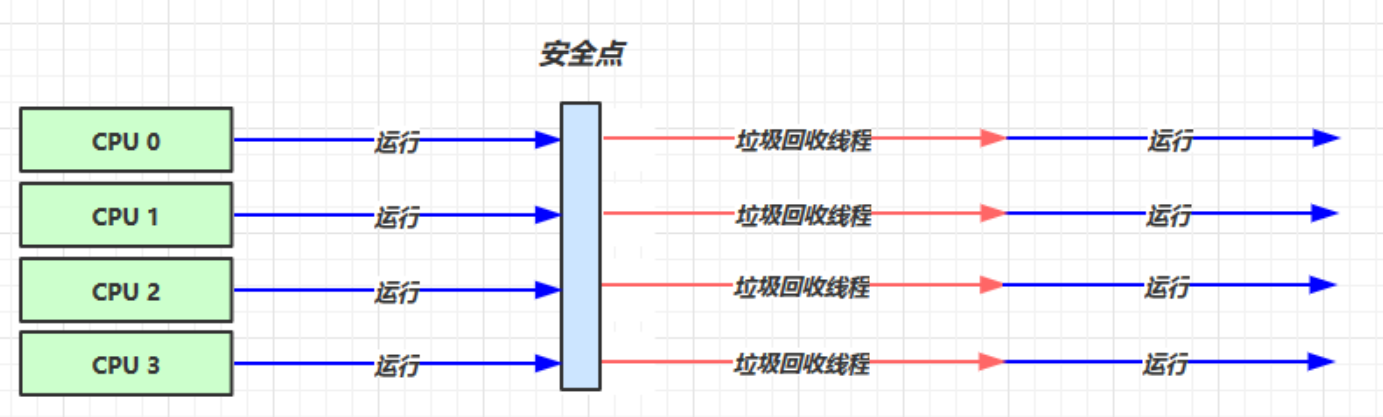
我們所需配置:
// 設置垃圾回收器方法
XX:+UseParallelGC ~ -XX:+UseParallelOldGC
// 自適應新生代晉陞老年代的閾值處理
-XX:+UseAdaptiveSizePolicy
// 設置垃圾回收時間佔總時間的比例(與-XX:MaxGCPauseMillis=ms衝突)
-XX:GCTimeRatio=ratio
// 設置最大STW時間(與-XX:GCTimeRatio=ratio衝突)
-XX:MaxGCPauseMillis=ms
// 設置最大同時進行CPU個數
-XX:ParallelGCThreads=n
我們來簡單解釋一下:
- 吞吐量優先垃圾回收器是多核CPU處理回收器
- 當一個進程發生垃圾回收時,我們會將所有CPU都用於垃圾回收,這時CPU利用率為100%
響應時間優先垃圾回收器
我們首先來介紹響應時間優先垃圾回收器的特點:
-
多線程
-
適用於堆內存較大,需要多核CPU
-
讓單次STW時間最短,例如每次STW0.1秒,但執行五次,共用0.5s(單次時間最短)
我們給出響應時間優先垃圾回收器的展示圖:
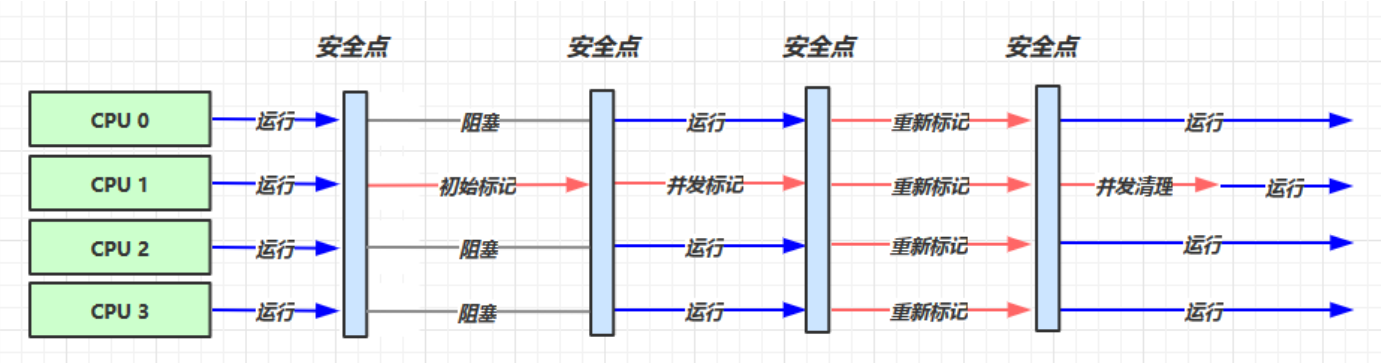
我們所需配置:
// +UseConcMarkSweepGC:設置並發標記清除算法,允許用戶進程單獨進行,但部分時間還需要阻塞
// -XX:+UseParNewGC:設置新生代算法,
// SerialOld:當老年代並發失敗,採用單線程方法
-XX:+UseConcMarkSweepGC ~ -XX:+UseParNewGC ~ SerialOld
// -XX:ParallelGCThreads=n:並行數設置為n
// -XX:ConcGCThreads=threads:並發線程最好設置為CPU的1/4個數,相當於只有1/4個CPU在處理垃圾回收
-XX:ParallelGCThreads=n ~ -XX:ConcGCThreads=threads
// 預留空間(因為並發清理時其他進程可能會產生一些垃圾,這些垃圾目前無法處理,我們需要預留一定空間進行儲存)
-XX:CMSInitiatingOccupancyFraction=percent
// 我們在重新標記階段前,先對新生代進行垃圾回收,節省其標記量
-XX:+CMSScavengeBeforeRemark
我們來簡單解釋一下:
- 響應時間優先垃圾回收器是多核CPU處理回收器
- 首先我們的CPU1進行初始標記,其他進程阻塞,僅標記一些Root對象(時間短)
- 然後我們CPU1進行並發標記,其他進程繼續運行,這時用來標記所有的垃圾回收對象(時間長)
- 然後由於我們的並發標記可能會導致一些內存混亂,所以我們將所有CPU需要進行重新標記(時間短)
- 最後只需要對CPU1進行並發清理即可,其他進程繼續運行
G1垃圾回收器
下面我們將會針對jdk1.9默認垃圾回收器做一個詳細的介紹
G1垃圾回收器簡介
首先我們先來簡單介紹一下G1垃圾回收器:
- G1回收器:Garbage First
- 在2017成為JDK9的默認垃圾回收器
下面我們來介紹G1垃圾回收器的特點:
- 同時注重吞吐量和低延遲,默認的暫停目標是200ms
- 超大堆內存,將堆劃分為多個大小相等的Region
- 整體上是標記整理法,但兩個區域之間是複製算法
相關JVM參數:
- -XX:+UseG1GC 使用G1垃圾回收器(JDK9之前都不是默認回收器)
- -XX:G1HeapRegionSize=size 設置Region的大小
- -XX:MaxGCPauseMillis=time 設置最大的G1垃圾回收時間
G1垃圾回收器階段簡介
我們通過一張圖來簡單介紹G1垃圾回收器的過程:
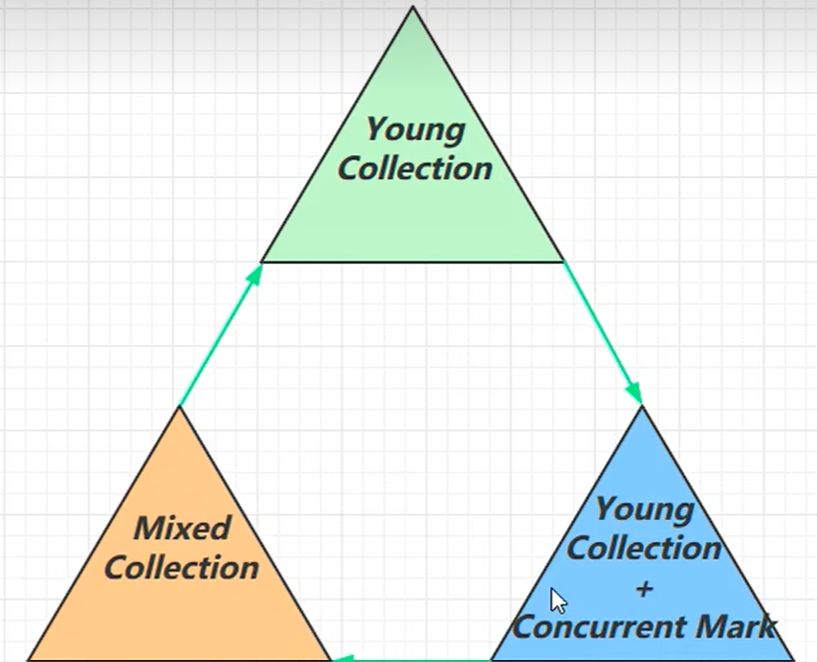
我們可以看到整個流程分為三個階段:
- YoungCollection:新生代階段
- YoungCollection+ConcurrentMark:新生代階段+並發標記階段
- MixedCollection:混合收集階段
Young Collection
我們首先給出該階段的展示圖:
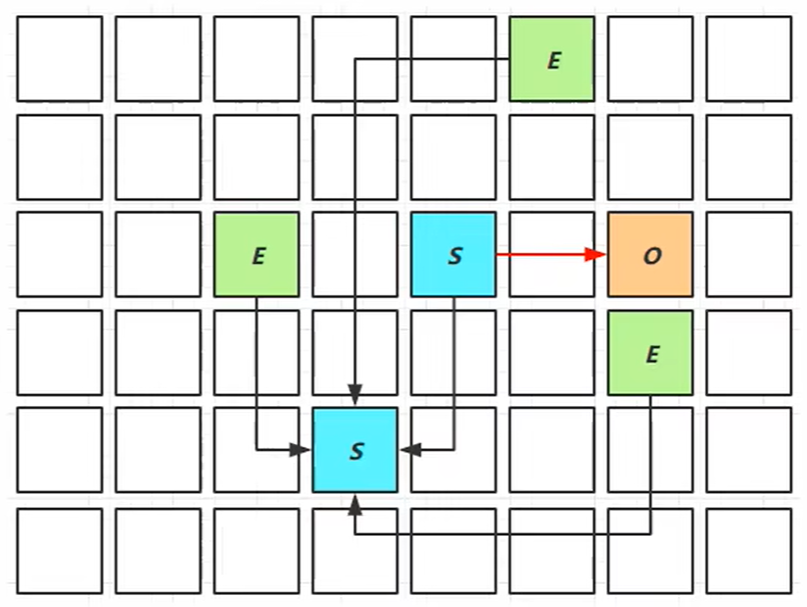
我們對其進行解釋:
- E就是伊甸園,S就是倖存區,O就是老年代
- 其產生的正常流程就和分代垃圾回收機制一樣,但這階段不會產生GC
Young Collection + CM
我們首先給出該階段的展示圖:
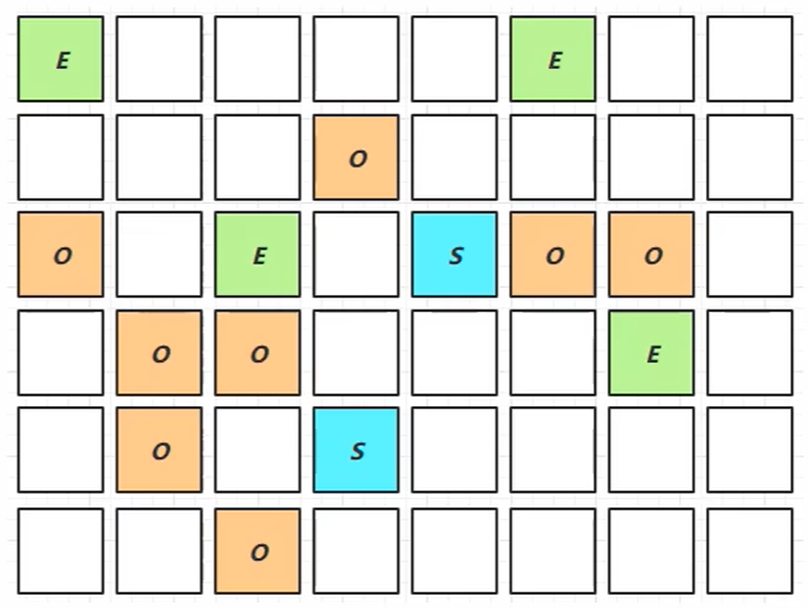
我們對其進行解釋:
- 其字符含義完全相同
- 當新生代內存佔滿後進行Young GC時會同時進行GC Root的初始標記
- 老年代佔用堆空間比例達到閾值時,進行並發標記(不會產生STW),閾值可以控制
我們給出並發標記閾值控制語句:
// 閾值控制
-XX:InitiatingHeapOccupancyPercent=percent (默認45%)
Mixed Collection
我們首先給出該階段的展示圖:
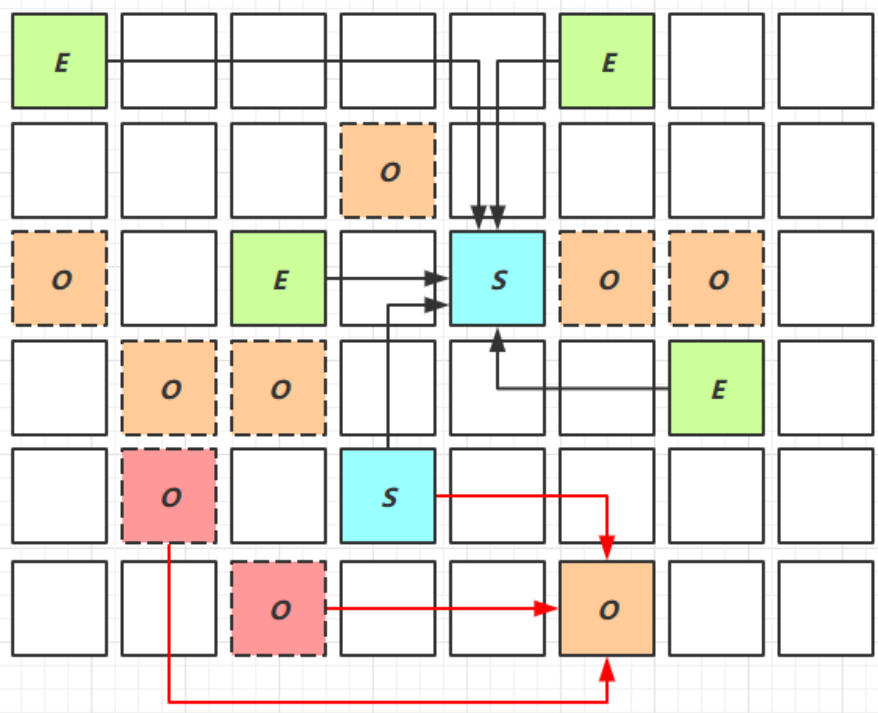
我們對其進行解釋:
- 其字符含義完全相同
- 但該階段會對E,S,O進行全面垃圾回收
- 其中最終標記(Remark)和拷貝存活(Evacation)都會STW(我們均會在後面解釋)
我們需要注意一點:
- Mixed Collection可能並不會將所有老年代的數據都刪除
- 它會根據你設置的最大暫停時間來進行抉擇,如果時間不足以刪除所有老年代數據,就會挑選部分較大的內存數據進行回收
Full GC
我們需要重新總結一下Full GC操作:
- SerialGC(串行垃圾回收)
- 新生代內存不足時發生的垃圾收集 – minor gc
- 老年代內存不足時發生的垃圾收集 – full gc
- ParalllelGC(吞吐量優先垃圾回收)
- 新生代內存不足時發生的垃圾收集 – minor gc
- 老年代內存不足時發生的垃圾收集 – full gc
- CMS(響應時間優先垃圾回收)
- 新生代內存不足時發生的垃圾收集 – minor gc
- 老年代內存不足時優先進行標記操作同步垃圾回收,當內存完全佔滿後才採用full gc
- G1(Garbage First)
- 新生代內存不足時發生的垃圾收集 – minor gc
- 老年代內存不足時優先進行MixedCollection同步垃圾回收,當內存完全佔滿後才採用full gc
G1知識點補充
我們在前面已經提到了我們將堆劃分為多個Region
但其實這個Region並不僅僅只分為了E,S,O三個空間,此外還包括以下空間:
- RSet(Remember Set :記憶集合)
/*
每一個Region都會划出一部分內存用來儲存記錄其他Region對當前持有Rset Region中Card的引用
針對G1的垃圾回收時間設置較短,在進行標記過程中可能會導致時間過長,所以我們設置了RSet來儲存部分信息
我們可以直接通過掃描每塊Region裏面的RSet來分析垃圾比例最高的Region區,放入CSet中,進行回收。
*/
- CSet(Collection Set 回收集合)
/*
收集集合代表每次GC暫停時回收的一系列目標分區。
在任意一次收集暫停中,CSet所有分區都會被釋放,內部存活的對象都會被轉移到分配的空閑分區中。
年輕代收集CSet只容納年輕代分區,而混合收集會通過啟發式算法,在老年代候選回收分區中,篩選出回收收益最高的分區添加到CSet中。
*/
新生代跨代引用
由於我們的初次標記時會去尋找Root部分
但其實大部分的Root都放入了老年代,但老年底數據較多難以查找,所以G1提供了一種方法:
- 將老年代O再次劃分為多個區間,名為卡
- 如果該卡中存儲了Root部分,那麼就將該卡標記為臟卡,同時放於RSet中存儲起來便於查找
我們給出簡單圖示:
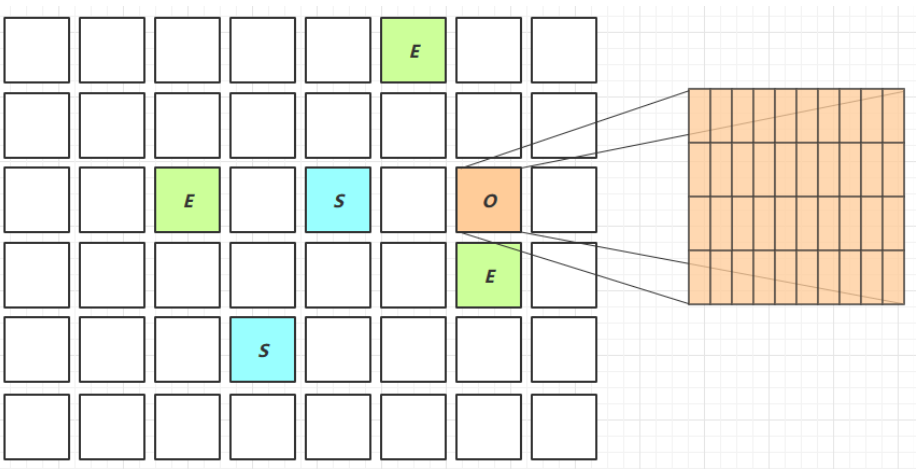
同時如果該Root地址發生變化,G1給出了另外的方法進行更換:
- 在引用變更時通過post-write barrier + dirty card queue
- concurrent refinement threads 更新 Remembered Set
Remark重新標記
我們在進行標記時通常採用三色標記法:
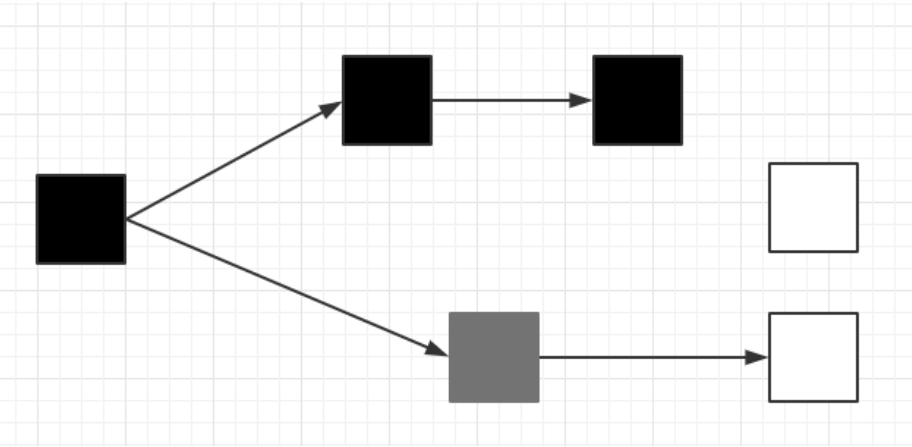
我們做簡單介紹:
- 黑色是已經標記結束的內存
- 灰色是正在標記的內存
- 白色是未標記的內存
我們針對上述進行分析:
- 最左側是根,黑色,已經被標記
- 上方為根的直接/間接引用對象,黑色,已經被標記
- 下方為根的直接/間接引用對象,灰色,正在標記,白色,還未被標記當後面會被標記
- 最右側孤零零的白色方塊,沒有被引用,不會被標記,最後會被當作垃圾回收對象處理掉
這時我們就會發現一個問題:
- 如果最右側的方塊在針對自身的CPU的並發標記結束後,又被其他進程所調用了(並發標記其他CPU正常運行)
- 但是此時它是白色的,最終會被這次的垃圾回收操作清除掉,就會導致影響其他進程操作
所以我們設計了Remark重新標記操作:
- 如果在該方塊針對自身的並發標記結束後又被其他進程調用,這時將他拖入一個隊列中,並將其變為灰色
- 在並發標記結束後進入重新標記階段,就會檢查該隊列,若發現灰色對象,在隊列中將它變為黑色對象並排出隊列
G1垃圾回收器重要更新
下面我們將會針對G1垃圾回收器在各個版本的重要更新做個介紹
JDK 8u20 字符串去重
我們首先要明白字符串在底層是採用char數組形成的:
String s1 = new String("hello"); // char[]{'h','e','l','l','o'}
String s2 = new String("hello"); // char[]{'h','e','l','l','o'}
如果重複的字符串都存放在內存中肯定會導致內存多餘佔用,所以提供了解決方案:
- 將所有新分配的字符串放入一個隊列
- 當新生代回收時,G1並發檢查是否有字符串重複
- 如果它們值一樣,讓它們引用同一個 char[]
- 注意與 String.intern() 不一樣:一個底層針對String類型,一個底層針對char[]類型
其優缺點:
- 優點:節省大量內存
- 缺點:略微增多了CPU時間,新生代回收時間略微增多
JDK 8u40 並發標記類卸載
當所有的類都經過並發標記後,就會直到哪些類不再被使用
這時如果一個類加載器的所有類都不再使用時,我們就可以卸載它所加載的所有類
JDK 8u60 回收巨型對象
首先我們介紹一下巨型對象的定義:
-
一個對象大於 region 的一半時,稱之為巨型對象
然後我們再來介紹G1對巨型對象的處理方法:
-
回收時被優先考慮
-
G1 不會對巨型對象進行拷貝
-
G1 會跟蹤老年代所有 incoming 引用,這樣老年代 incoming 引用為0 的巨型對象就可以在新生代垃圾回收時處理掉
垃圾回收調優
本小節將會介紹垃圾回收的調優機制
基本調優概念
我們進行調優需要掌握的基本知識:
- 掌握相關工具使用
- 掌握基本的空間調整
- 掌握GC相關的VM參數
- 明白調優並非固定公式,而是需要結合應用,環境
我們調優的領域並非只有垃圾回收,但是這個部分的調優確實會給項目帶來很大的速率優化,此外還有其他方法的調優:
- IO調優
- 鎖競爭調優
- CPU佔用調優
此外我們需要確定調優的目標:
- 是為了保證低延遲還是為了保證高吞吐量
最快的GC是不發生GC
首先我們需要明白GC是花費時間的,如果我們能夠控制好內存保證不發生GC,那麼才是最快的
如果我們頻繁發生GC操作,那麼我們就需要先進行自我反思:
- 存放的數據是否過多?
/*
例如我們是否設置了相同元素篩選?錯誤賬號禁止緩存?
*/
- 數據表示是否臃腫?
/*
例如我們調取數據時是否只調取了我們所需數據還是全盤托出?
例如我們選擇數據類型時是否是以最低標準為要求,數據庫能採用tiny不要使用int
*/
- 是否存在內存泄露?
/*
例如我們是否設置緩存數據時採用了Static形式的Map並不斷存儲數據?
*/
新生代調優
首先我們先來回顧一下新生代的優點:
- 所有的new操作的內存分配十分廉價:直接new出來存放在伊甸區即可
- 死亡對象的回收代價為零:我們直接採用複製將倖存內存複製出來即可,其他垃圾回收部分不用過問
- 大部分對象都是垃圾:我們實際上倖存下來的內存數據是小部分數據,所以大部分都是垃圾
- 垃圾回收時間相對短:Minor GC的時間遠低於Full GC
那麼我們該怎麼進行調優呢:
- 最簡單的方法就是適當擴大新生代空間即可
- 新生代不易太小:如果新生代過小就會導致不斷發生minor GC浪費時間,且倖存區過小導致無用數據都存入老年代
- 新生代不易太大:如果新生代過大相對老年代空間變小,容易發生Full GC,Full GC的運行時間過長
那麼官方認可的新生代大小為多少:
- 新生代能容納所有[並發量*(請求-響應)]的數據
新生代倖存區調優
首先我們需要直到新生代倖存區存放的數據主要分為兩部分:
- 當前活躍對象:並不應該晉級到老年代,只是目前階段需要使用的內存數據
- 需要晉陞對象:我們一直使用的內存數據,需要傳遞到老年代
首先我們需要保證具有一定的倖存區大小:
- 如果倖存區過小,就會導致倖存區數據提前進入到老年代
- 但如果是當前活躍對象進入到老年代,既不能發揮作用,並且也難以排出老年代
其次我們需要控制晉陞標準:
- 設置一定規格的晉陞標準,防止部分當前活躍對象進入到老年代,理由同上
老年代調優
最後我們介紹一下老年代調優,我們這裡以CMS為例:
- 首先CMS老年代內存越大越好
- 其次在不做調優的情況下,如果沒有發生Full GC就不需要調優了,否則優先調優新生代
- 如果經常發生Full GC,我們就需要將老年代空間增大了,官方推薦增大目前老年代空間大小的1/4~1/3即可
調優案例展示
最後我們介紹三個調優方法的案例:
- Full GC和Minor GC頻繁
/*
主要是因為新生代空間不足
因為新生代空間不足,經常發生minor GC,同時倖存區空間不足導致大量數據直接進入到老年代,最後導致老年代也產生Full GC
*/
- 請求高峰期發生 Full GC,單次暫停時間特別長 (CMS)
/*
首先我們已經直到是CMS的垃圾回收方法
我們在之前的學習中得知Full GC主要分為三個階段:初始標記,並發標記,重新標記
在請求高峰期期間,數據較多,我們的重新標記由於需要重新掃描所有數據空間,所以會導致單次暫停時間長
我們只需要保證在進行重新掃描前先進行一次Minor GC消除掉無用數據就可以加快暫停速度:-XX:+CMSScavengeBeforeRemark
*/
- 老年代充裕情況下,發生 Full GC (CMS jdk1.7)
/*
首先我們需要注意是jdk1.7版本
在1.7版本是由永久代負責管理方法區以及常量池,如果永久代內存滿了也會產生Full GC
所以我們只需要增加永久代的內存大小即可
*/
結束語
到這裡我們JVM的垃圾回收篇就結束了,希望能為你帶來幫助~
附錄
該文章屬於學習內容,具體參考B站黑馬程序員滿老師的JVM完整教程
這裡附上視頻鏈接:01_垃圾回收概述_嗶哩嗶哩_bilibili


