數據結構:7種哈希散列算法,你知道幾個?
作者:小傅哥
沉澱、分享、成長,讓自己和他人都能有所收穫!😄
一、前言
哈希錶的歷史
哈希散列的想法在不同的地方獨立出現。1953 年 1 月,漢斯·彼得·盧恩 ( Hans Peter Luhn ) 編寫了一份IBM內部備忘錄,其中使用了散列和鏈接。開放尋址後來由 AD Linh 在 Luhn 的論文上提出。大約在同一時間,IBM Research的Gene Amdahl、Elaine M. McGraw、Nathaniel Rochester和Arthur Samuel為IBM 701彙編器實現了散列。 線性探測的開放尋址歸功於 Amdahl,儘管Ershov獨立地有相同的想法。「開放尋址」一詞是由W. Wesley Peterson在他的文章中創造的,該文章討論了大文件中的搜索問題。
二、哈希數據結構
哈希表的存在是為了解決能通過O(1)時間複雜度直接索引到指定元素。
這是什麼意思呢?通過我們使用數組存放元素,都是按照順序存放的,當需要獲取某個元素的時候,則需要對數組進行遍歷,獲取到指定的值。如圖所示;
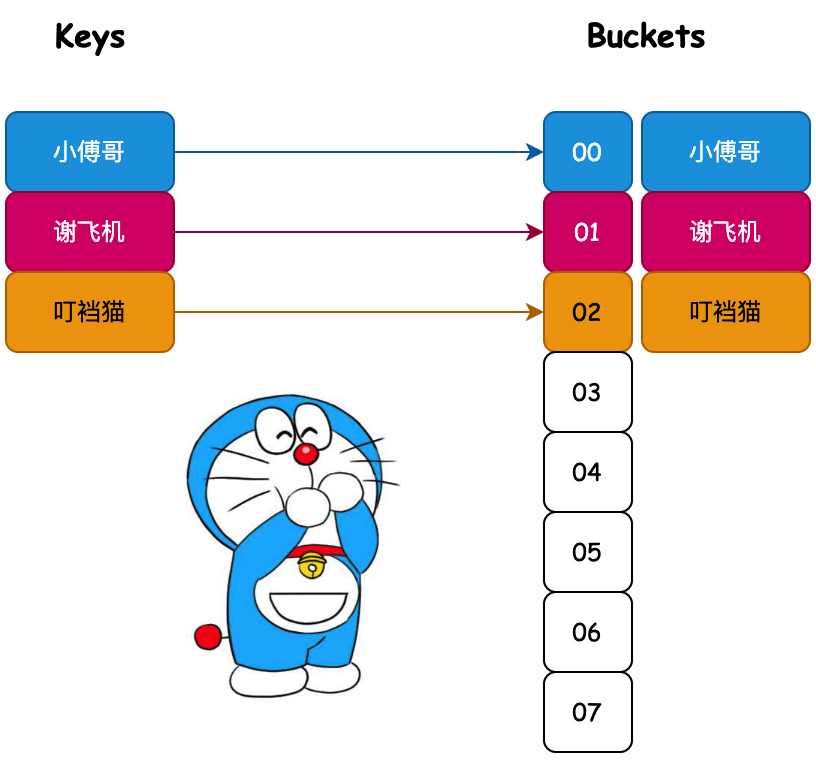
而這樣通過循環遍歷比對獲取指定元素的操作,時間複雜度是O(n),也就是說如果你的業務邏輯實現中存在這樣的代碼是非常拉胯的。那怎麼辦呢?這就引入了哈希散列表的設計。
在計算機科學中,一個哈希表(hash table、hash map)是一種實現關聯數組的抽象數據結構,該結構將鍵通過哈希計算映射到值。
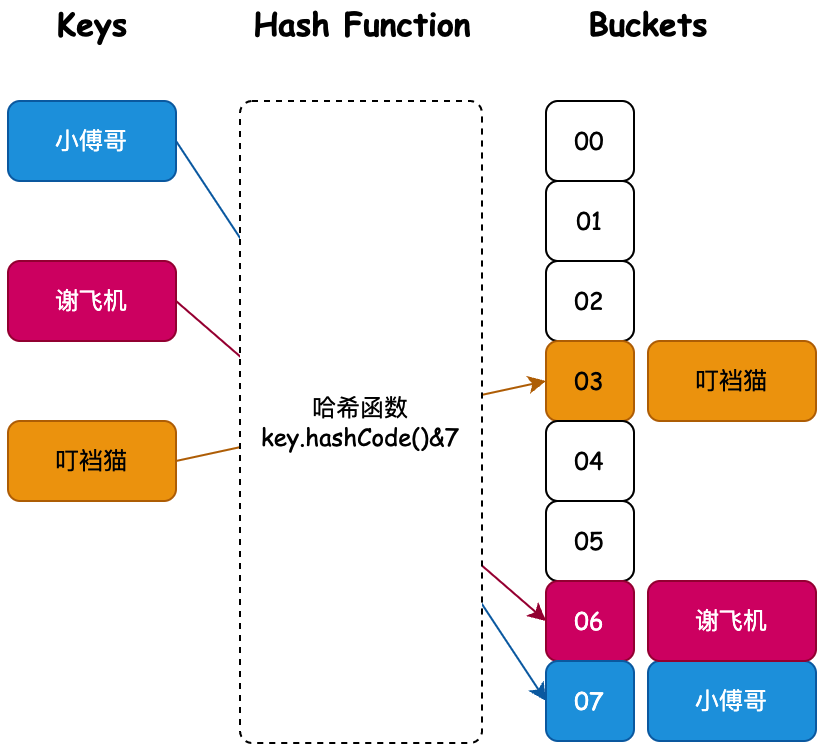
也就是說我們通過對一個 Key 值計算它的哈希並與長度為2的n次冪的數組減一做與運算,計算出槽位對應的索引,將數據存放到索引下。那麼這樣就解決了當獲取指定數據時,只需要根據存放時計算索引ID的方式再計算一次,就可以把槽位上對應的數據獲取處理,以此達到時間複雜度為O(1)的情況。如圖所示;
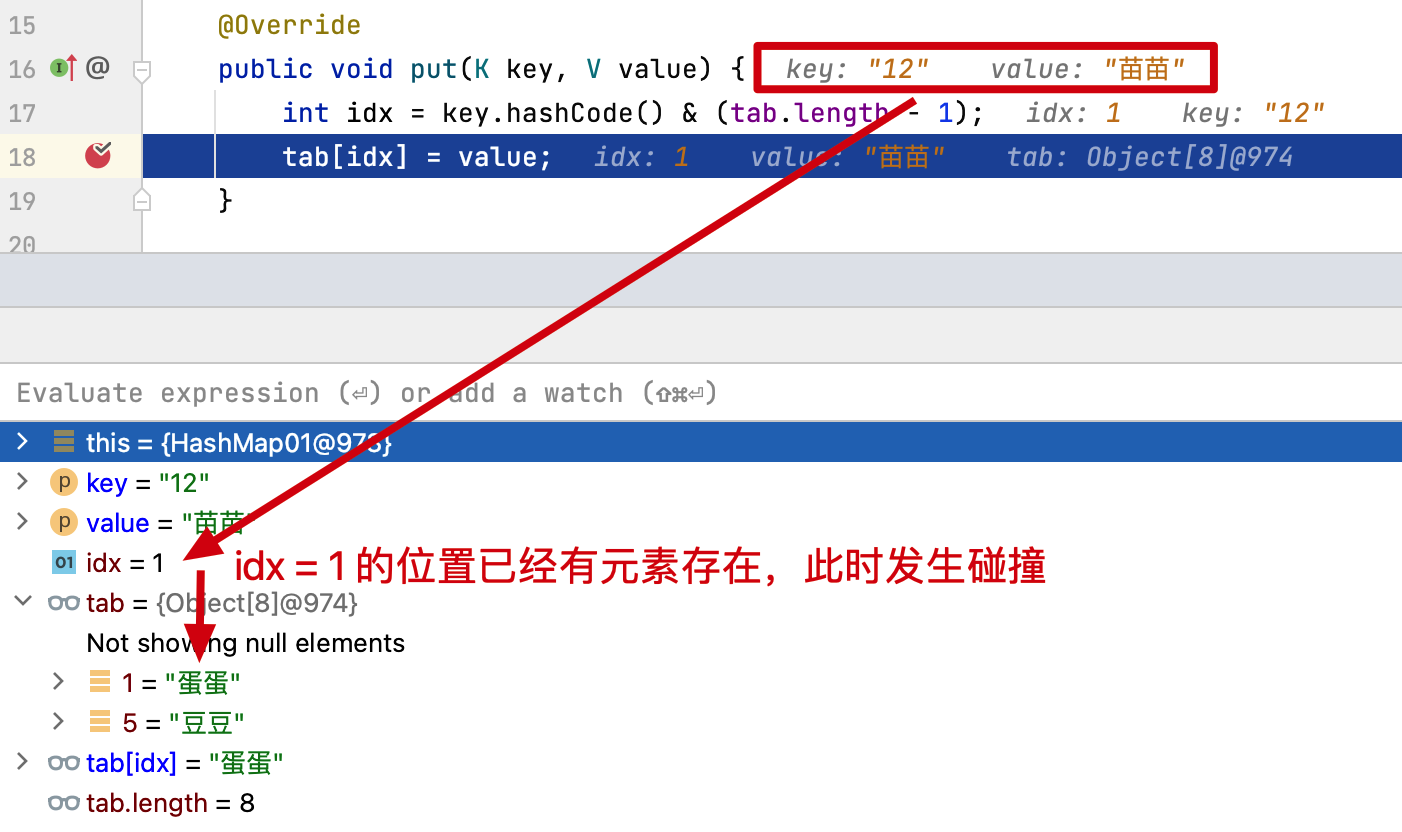
哈希散列雖然解決了獲取元素的時間複雜度問題,但大多數時候這只是理想情況。因為隨着元素的增多,很可能發生哈希衝突,或者哈希值波動不大導致索引計算相同,也就是一個索引位置出現多個元素情況。如圖所示;
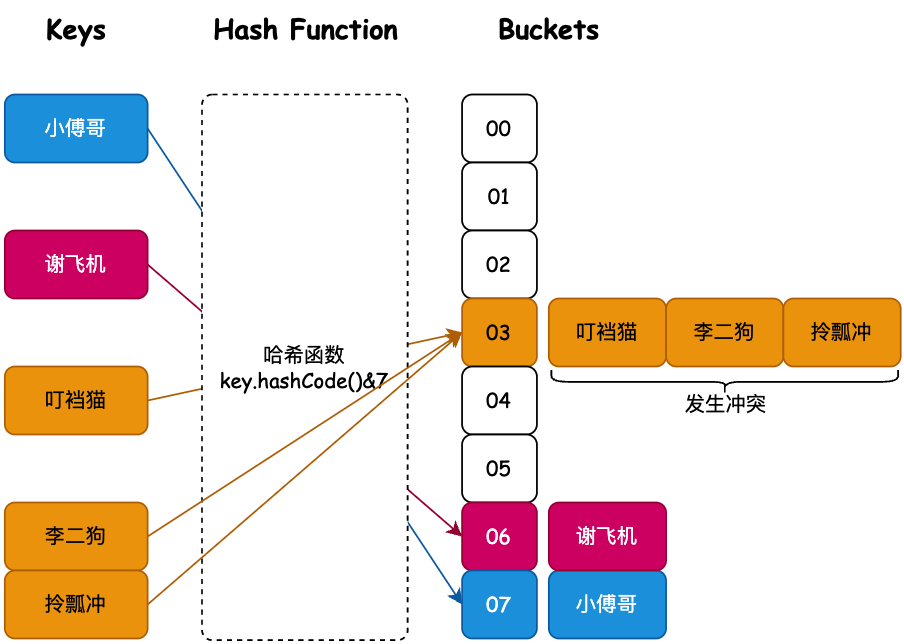
當李二狗、拎瓢沖都有槽位的下標索引03的 叮襠貓 發生衝突時,情況就變得糟糕了,因為這樣就不能滿足O(1)時間複雜度獲取元素的訴求了。
那麼此時就出現了一系列解決方案,包括;HashMap 中的拉鏈尋址 + 紅黑樹、擾動函數、負載因子、ThreadLocal 的開放尋址、合併散列、杜鵑散列、跳房子哈希、羅賓漢哈希等各類數據結構設計。讓元素在發生哈希衝突時,也可以存放到新的槽位,並儘可能保證索引的時間複雜度小於O(n)
三、實現哈希散列
哈希散列是一個非常常見的數據結構,無論是我們使用的 HashMap、ThreaLocal 還是你在刷題中位了提升索引效率,都會用到哈希散列。
只要哈希桶的長度由負載因子控制的合理,每次查找元素的平均時間複雜度與桶中存儲的元素數量無關。另外許多哈希表設計還允許對鍵值對的任意插入和刪除,每次操作的攤銷固定平均成本。
好,那麼介紹了這麼多,小傅哥帶着大家做幾個關於哈希散列的數據結構,通過實踐來了解會更加容易搞懂。
- 對應源碼://github.com/fuzhengwei/java-algorithms/tree/main/data-structures/src/main/java/hash_table
- 擴展資料:《Java 面經手冊》 – 本章涉及到的拉鏈尋址、開放尋址在 Java API 中的 HashMap、ThreadLocal 有完整實現,同時涉及了擾動函數、負載因子、斐波那契散列,可以擴展學習。
1. 哈希碰撞
說明:通過模擬簡單 HashMap 實現,去掉拉鏈尋址等設計,驗證元素哈新索引位置碰撞。
public class HashMap01<K, V> implements Map<K, V> {
private final Object[] tab = new Object[8];
@Override
public void put(K key, V value) {
int idx = key.hashCode() & (tab.length - 1);
tab[idx] = value;
}
@Override
public V get(K key) {
int idx = key.hashCode() & (tab.length - 1);
return (V) tab[idx];
}
}
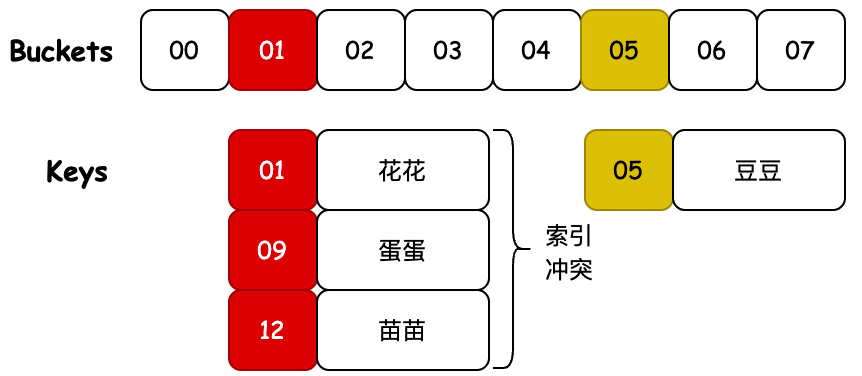
- HashMap01 的實現只是通過哈希計算出的下標,散列存放到固定的數組內。那麼這樣當發生元素下標碰撞時,原有的元素就會被新的元素替換掉。
測試
@Test
public void test_hashMap01() {
Map<String, String> map = new HashMap01<>();
map.put("01", "花花");
map.put("02", "豆豆");
logger.info("碰撞前 key:{} value:{}", "01", map.get("01"));
// 下標碰撞
map.put("09", "蛋蛋");
map.put("12", "苗苗");
logger.info("碰撞前 key:{} value:{}", "01", map.get("01"));
}
06:58:41.691 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 碰撞前 key:01 value:花花
06:58:41.696 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 碰撞前 key:01 value:苗苗
Process finished with exit code 0
- 通過測試結果可以看到,碰撞前 map.get(“01”) 的值是
花花,兩次下標索引碰撞後存放的值則是苗苗 - 這也就是使用哈希散列必須解決的一個問題,無論是在已知元素數量的情況下,通過擴容數組長度解決,還是把碰撞的元素通過鏈表存放,都是可以的。
2. 拉鏈尋址
說明:既然我們沒法控制元素不碰撞,但我們可以對碰撞後的元素進行管理。比如像 HashMap 中拉鏈法一樣,把碰撞的元素存放到鏈表上。這裡我們就來簡化實現一下。
public class HashMap02BySeparateChaining<K, V> implements Map<K, V> {
private final LinkedList<Node<K, V>>[] tab = new LinkedList[8];
@Override
public void put(K key, V value) {
int idx = key.hashCode() & (tab.length - 1);
if (tab[idx] == null) {
tab[idx] = new LinkedList<>();
tab[idx].add(new Node<>(key, value));
} else {
tab[idx].add(new Node<>(key, value));
}
}
@Override
public V get(K key) {
int idx = key.hashCode() & (tab.length - 1);
for (Node<K, V> kvNode : tab[idx]) {
if (key.equals(kvNode.getKey())) {
return kvNode.value;
}
}
return null;
}
static class Node<K, V> {
final K key;
V value;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
public K getKey() {
return key;
}
public V getValue() {
return value;
}
}
}
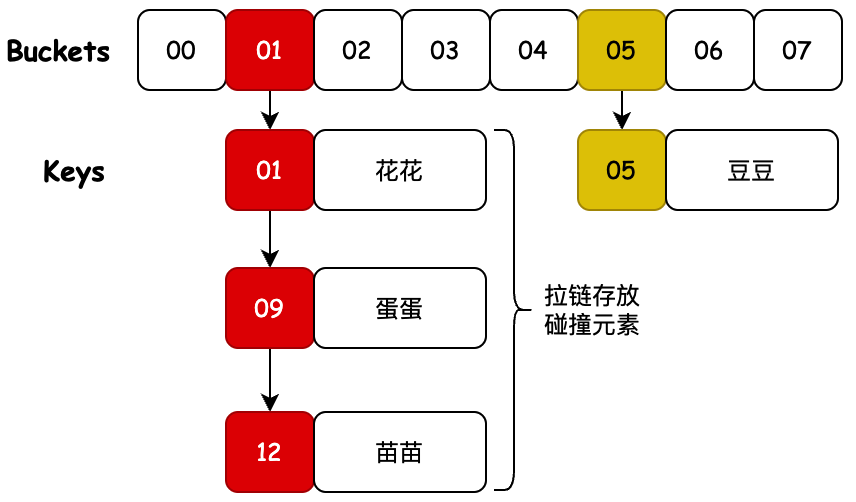
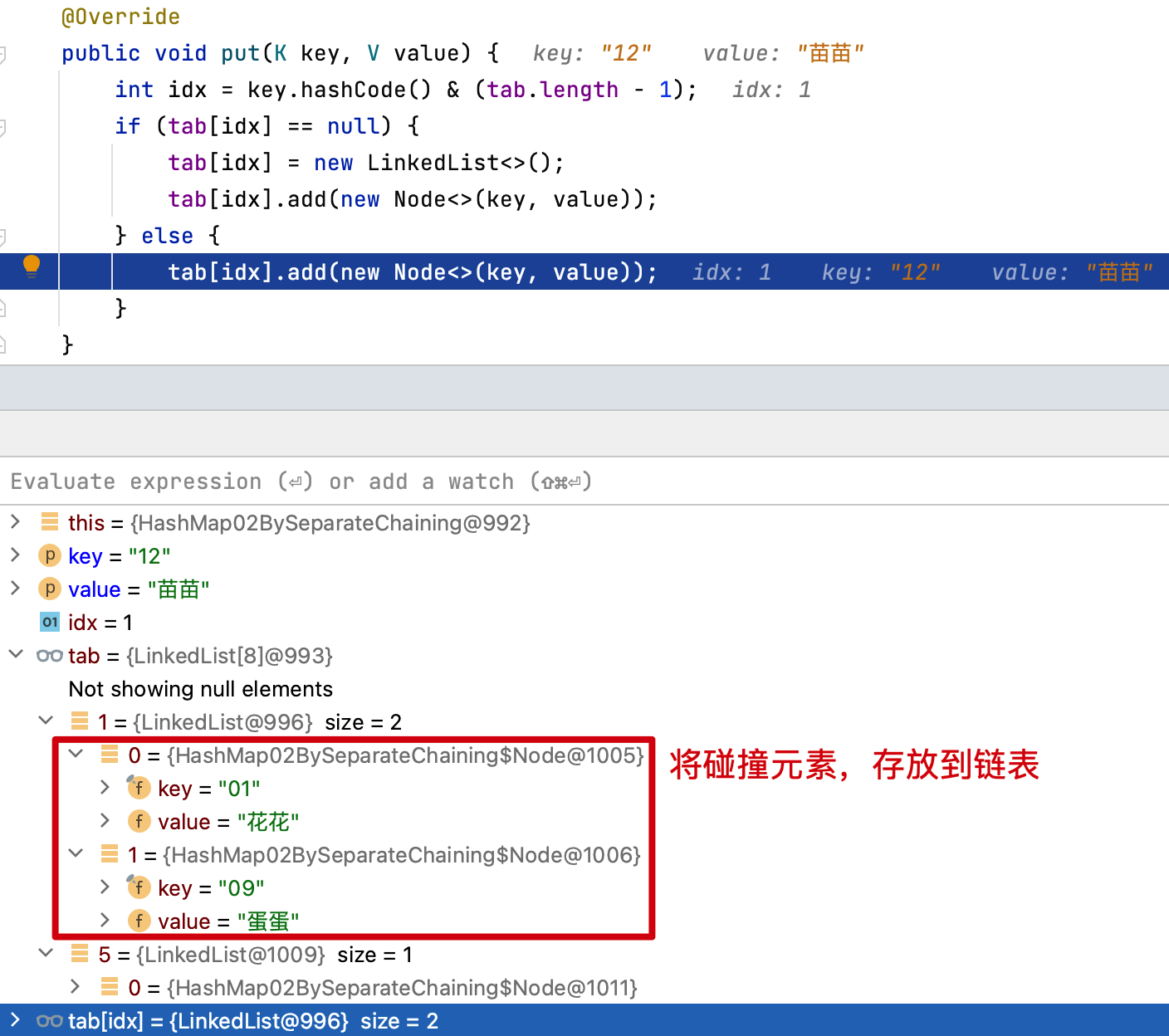
- 因為元素在存放到哈希桶上時,可能發生下標索引膨脹,所以這裡我們把每一個元素都設定成一個 Node 節點,這些節點通過 LinkedList 鏈表關聯,當然你也可以通過 Node 節點構建出鏈表 next 元素即可。
- 那麼這時候在發生元素碰撞,相同位置的元素就都被存放到鏈表上了,獲取的時候需要對存放多個元素的鏈表進行遍歷獲取。
測試
@Test
public void test_hashMap02() {
Map<String, String> map = new HashMap02BySeparateChaining<>();
map.put("01", "花花");
map.put("05", "豆豆");
logger.info("碰撞前 key:{} value:{}", "01", map.get("01"));
// 下標碰撞
map.put("09", "蛋蛋");
map.put("12", "苗苗");
logger.info("碰撞前 key:{} value:{}", "01", map.get("01"));
}
07:21:16.654 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 碰撞前 key:01 value:花花
07:22:44.651 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 碰撞前 key:01 value:花花
Process finished with exit code 0
- 此時第一次和第二次獲取01位置的元素就都是
花花了,元素沒有被替代。因為此時的元素是被存放到鏈表上了。
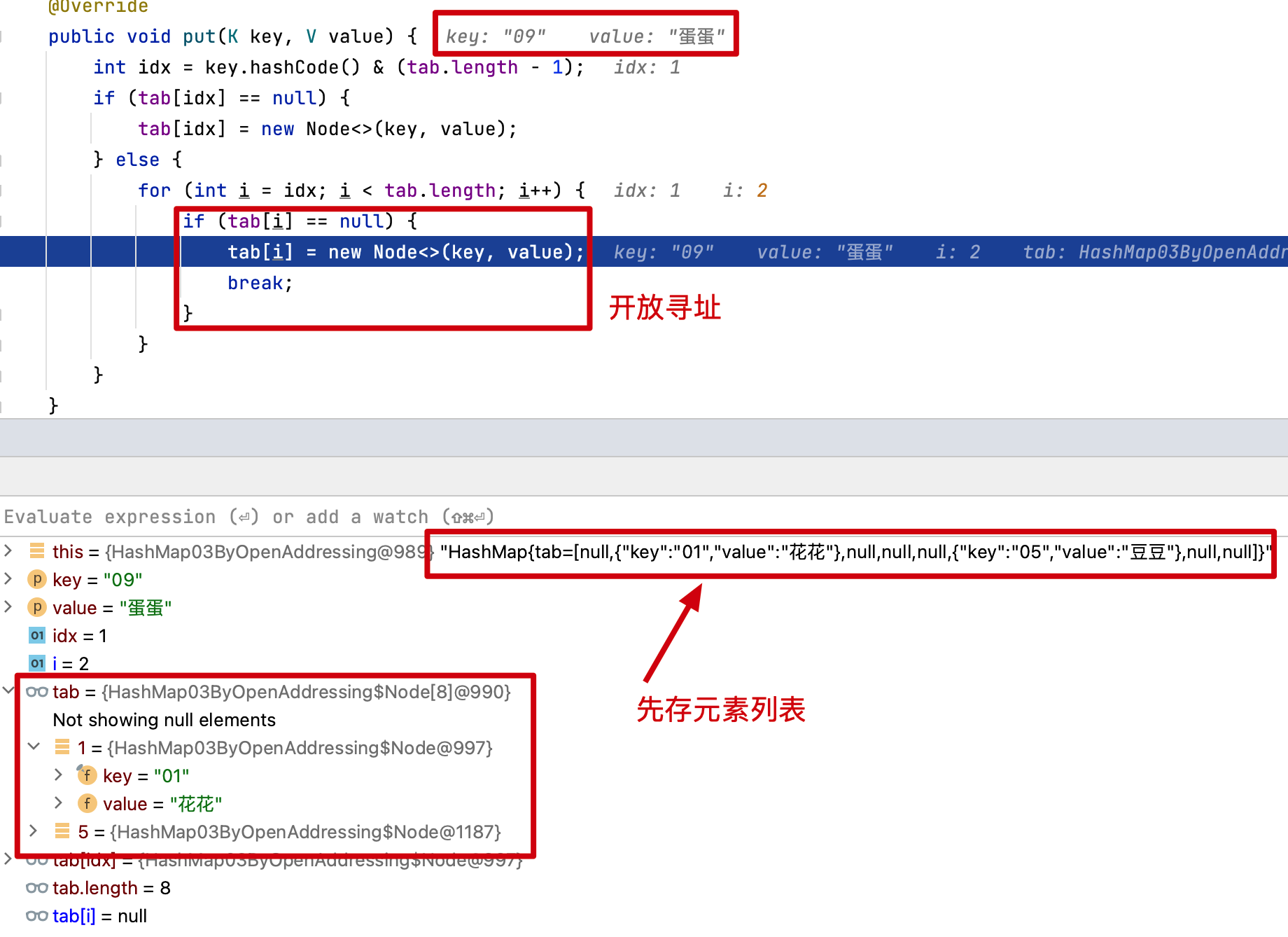
3. 開放尋址
說明:除了對哈希桶上碰撞的索引元素進行拉鏈存放,還有不引入新的額外的數據結構,只是在哈希桶上存放碰撞元素的方式。它叫開放尋址,也就是 ThreaLocal 中運用斐波那契散列+開放尋址的處理方式。
public class HashMap03ByOpenAddressing<K, V> implements Map<K, V> {
private final Node<K, V>[] tab = new Node[8];
@Override
public void put(K key, V value) {
int idx = key.hashCode() & (tab.length - 1);
if (tab[idx] == null) {
tab[idx] = new Node<>(key, value);
} else {
for (int i = idx; i < tab.length; i++) {
if (tab[i] == null) {
tab[i] = new Node<>(key, value);
break;
}
}
}
}
@Override
public V get(K key) {
int idx = key.hashCode() & (tab.length - 1);
for (int i = idx; i < tab.length; i ++){
if (tab[idx] != null && tab[idx].key == key) {
return tab[idx].value;
}
}
return null;
}
static class Node<K, V> {
final K key;
V value;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
}
}
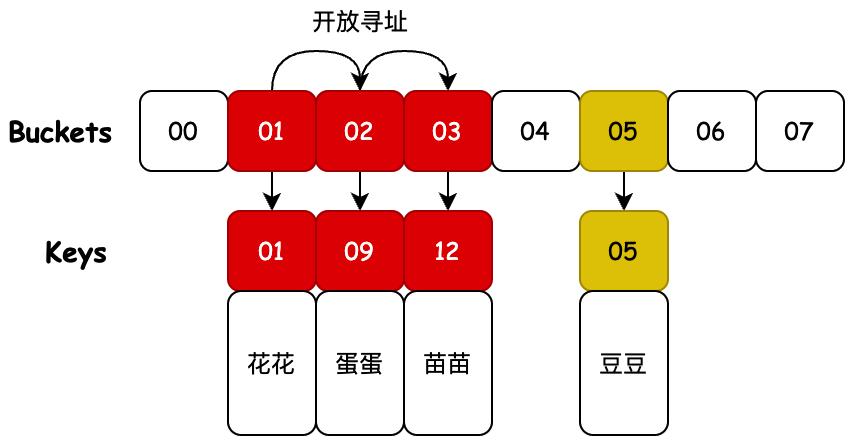
- 開放尋址的設計會對碰撞的元素,尋找哈希桶上新的位置,這個位置從當前碰撞位置開始向後尋找,直到找到空的位置存放。
- 在 ThreadLocal 的實現中會使用斐波那契散列、索引計算累加、啟發式清理、探測式清理等操作,以保證儘可能少的碰撞。
測試
@Test
public void test_hashMap03() {
Map<String, String> map = new HashMap03ByOpenAddressing<>();
map.put("01", "花花");
map.put("05", "豆豆");
logger.info("碰撞前 key:{} value:{}", "01", map.get("01"));
// 下標碰撞
map.put("09", "蛋蛋");
map.put("12", "苗苗");
logger.info("碰撞前 key:{} value:{}", "01", map.get("01"));
}
07:20:22.382 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 碰撞前 key:01 value:花花
07:20:22.387 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 碰撞前 key:01 value:花花
07:20:22.387 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 數據結構:HashMap{tab=[null,{"key":"01","value":"花花"},{"key":"09","value":"蛋蛋"},{"key":"12","value":"苗苗"},null,{"key":"05","value":"豆豆"},null,null]}
Process finished with exit code 0
- 通過測試結果可以看到,開放尋址對碰撞元素的尋址存放,也是可用解決哈希索引衝突問題的。
4. 合併散列
說明:合併散列是開放尋址和單獨鏈接的混合,碰撞的節點在哈希表中鏈接。此算法適合固定分配內存的哈希桶,通過存放元素時識別哈希桶上的最大空槽位來解決合併哈希中的衝突。
public class HashMap04ByCoalescedHashing<K, V> implements Map<K, V> {
private final Node<K, V>[] tab = new Node[8];
@Override
public void put(K key, V value) {
int idx = key.hashCode() & (tab.length - 1);
if (tab[idx] == null) {
tab[idx] = new Node<>(key, value);
return;
}
int cursor = tab.length - 1;
while (tab[cursor] != null && tab[cursor].key != key) {
--cursor;
}
tab[cursor] = new Node<>(key, value);
// 將碰撞節點指向這個新節點
while (tab[idx].idxOfNext != 0){
idx = tab[idx].idxOfNext;
}
tab[idx].idxOfNext = cursor;
}
@Override
public V get(K key) {
int idx = key.hashCode() & (tab.length - 1);
while (tab[idx].key != key) {
idx = tab[idx].idxOfNext;
}
return tab[idx].value;
}
static class Node<K, V> {
final K key;
V value;
int idxOfNext;
public Node(K key, V value) {
this.key = key;
this.value = value;
}
}
}
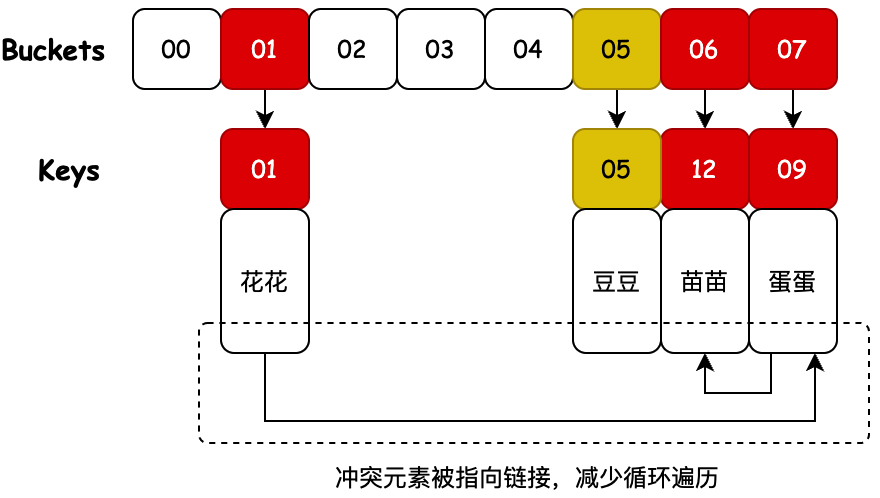
- 合併散列的最大目的在於將碰撞元素鏈接起來,避免因為需要尋找碰撞元素所發生的循環遍歷。也就是A、B元素存放時發生碰撞,那麼在找到A元素的時候可以很快的索引到B元素所在的位置。
測試
07:18:43.613 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 碰撞前 key:01 value:花花
07:18:43.618 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 碰撞前 key:01 value:苗苗
07:18:43.619 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 數據結構:HashMap{tab=[null,{"idxOfNext":7,"key":"01","value":"花花"},null,null,null,{"idxOfNext":0,"key":"05","value":"豆豆"},{"idxOfNext":0,"key":"12","value":"苗苗"},{"idxOfNext":6,"key":"09","value":"蛋蛋"}]}
Process finished with exit code 0
- 相對於直接使用開放尋址,這樣的掛在鏈路指向的方式,可以提升索引的性能。因為在實際的數據存儲上,元素的下一個位置不一定空元素,可能已經被其他元素佔據,這樣就增加了索引的次數。所以使用直接指向地址的方式,會更好的提高索引性能。
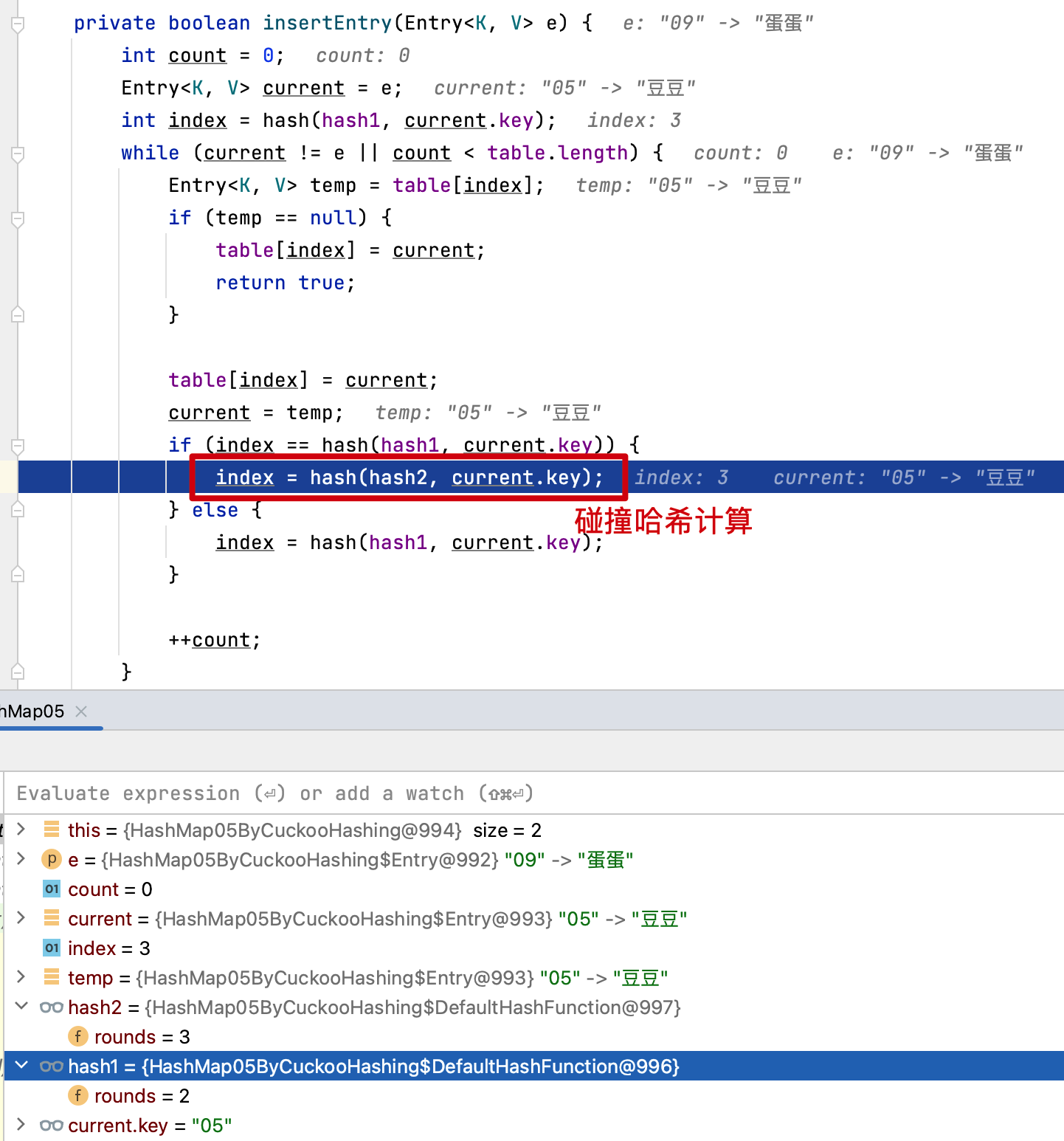
5. 杜鵑散列
說明:這個名字起的比較有意思,也代表着它的數據結構。杜鵑鳥在孵化🐣的時候,雛鳥會將其他蛋或幼崽推出巢穴;類似的這個數據結構會使用2組key哈希表,將衝突元素推到另外一個key哈希表中。
private V put(K key, V value, boolean isRehash) {
Object k = maskNull(key);
if (containsKey(k)) {
return null;
}
if (insertEntry(new Entry<K, V>((K) k, value))) {
if (!isRehash) {
size++;
}
return null;
}
rehash(2 * table.length);
return put((K) k, value);
}
private boolean insertEntry(Entry<K, V> e) {
int count = 0;
Entry<K, V> current = e;
int index = hash(hash1, current.key);
while (current != e || count < table.length) {
Entry<K, V> temp = table[index];
if (temp == null) {
table[index] = current;
return true;
}
table[index] = current;
current = temp;
if (index == hash(hash1, current.key)) {
index = hash(hash2, current.key);
} else {
index = hash(hash1, current.key);
}
++count;
}
return false;
}
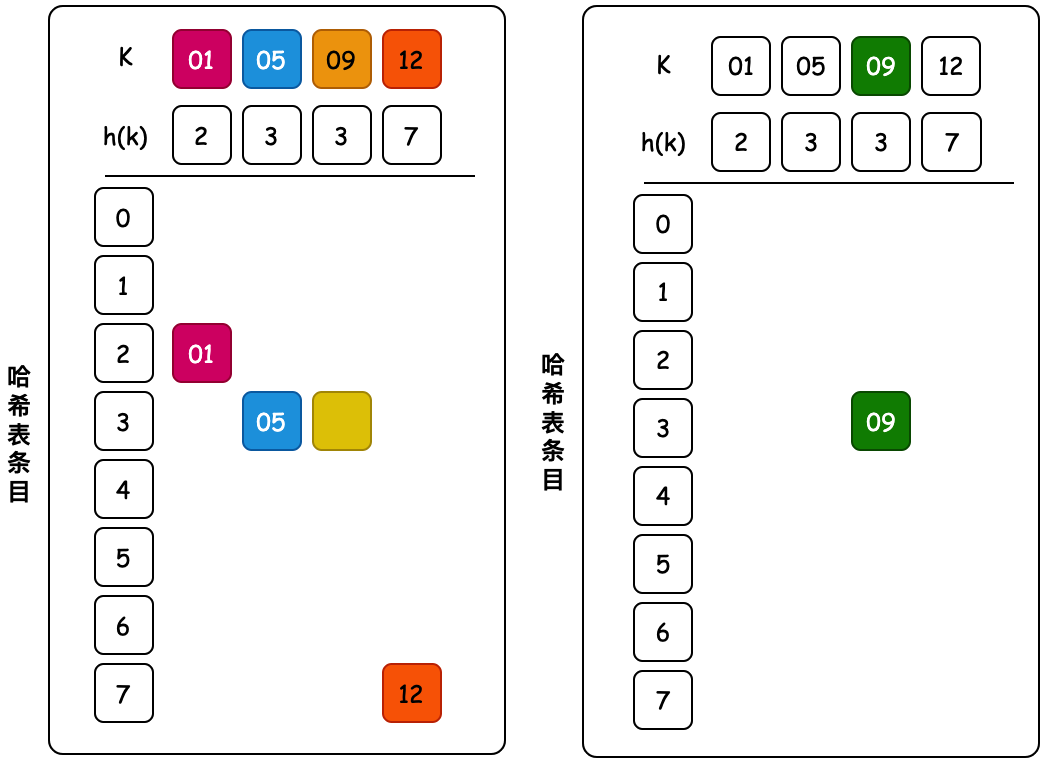
- 當多個鍵映射到同一個單元格時會發生這種情況。杜鵑散列的基本思想是通過使用兩個散列函數而不是僅一個散列函數來解決衝突。
- 這為每個鍵在哈希表中提供了兩個可能的位置。在該算法的一種常用變體中,哈希表被分成兩個大小相等的較小的表,每個哈希函數都為這兩個表之一提供索引。兩個散列函數也可以為單個表提供索引。
- 在實踐中,杜鵑哈希比線性探測慢約 20-30%,線性探測是常用方法中最快的。然而,由於它對搜索時間的最壞情況保證,當需要實時響應率時,杜鵑散列仍然很有價值。杜鵑散列的一個優點是它的無鏈接列表屬性,非常適合 GPU 處理。
測試
07:52:04.010 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 碰撞前 key:01 value:花花
07:52:04.016 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 碰撞前 key:01 value:苗苗
07:52:04.016 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 數據結構:{01=花花, 12=苗苗, 05=豆豆, 09=蛋蛋}
Process finished with exit code 0
- 從測試結果可以看到,杜鵑散列可以通過兩個散列函數解決索引衝突問題。不過這個探測的過程比較耗時。
6. 跳房子散列
說明:跳房子散列是一種基於開放尋址的算法,它結合了杜鵑散列、線性探測和鏈接的元素,通過桶鄰域的概念——任何給定佔用桶周圍的後續桶,也稱為「虛擬」桶。 該算法旨在在哈希表的負載因子增長超過 90% 時提供更好的性能;它還在並發設置中提供了高吞吐量,因此非常適合實現可調整大小的並發哈希表。
public boolean insert(AnyType x) {
if (!isEmpty()) {
return false;
}
int currentPos = findPos(x);
if (currentPos == -1) {
return false;
}
if (array[currentPos] != null) {
x = array[currentPos].element;
array[currentPos].isActive = true;
}
String hope;
if (array[currentPos] != null) {
hope = array[currentPos].hope;
x = array[currentPos].element;
} else {
hope = "10000000";
}
array[currentPos] = new HashEntry<>(x, hope, true);
theSize++;
return true;
}
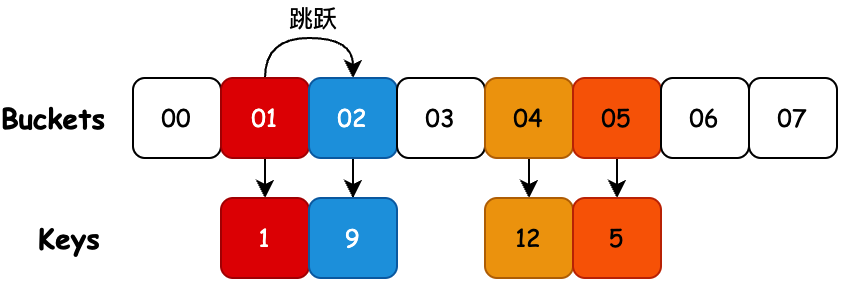
- 該算法使用一個包含n 個桶的數組。對於每個桶,它的鄰域是H個連續桶的小集合(即索引接近原始散列桶的那些)。鄰域的期望屬性是在鄰域的桶中找到一個項目的成本接近於在桶本身中找到它的成本(例如,通過使鄰域中的桶落在同一緩存行中)。在最壞的情況下,鄰域的大小必須足以容納對數個項目(即它必須容納 log( n ) 個項目),但平均只能是一個常數。如果某個桶的鄰域被填滿,則調整表的大小。
測試
@Test
public void test_hashMap06() {
HashMap06ByHopscotchHashing<Integer> map = new HashMap06ByHopscotchHashing<>();
map.insert(1);
map.insert(5);
map.insert(9);
map.insert(12);
logger.info("數據結構:{}", map);
}
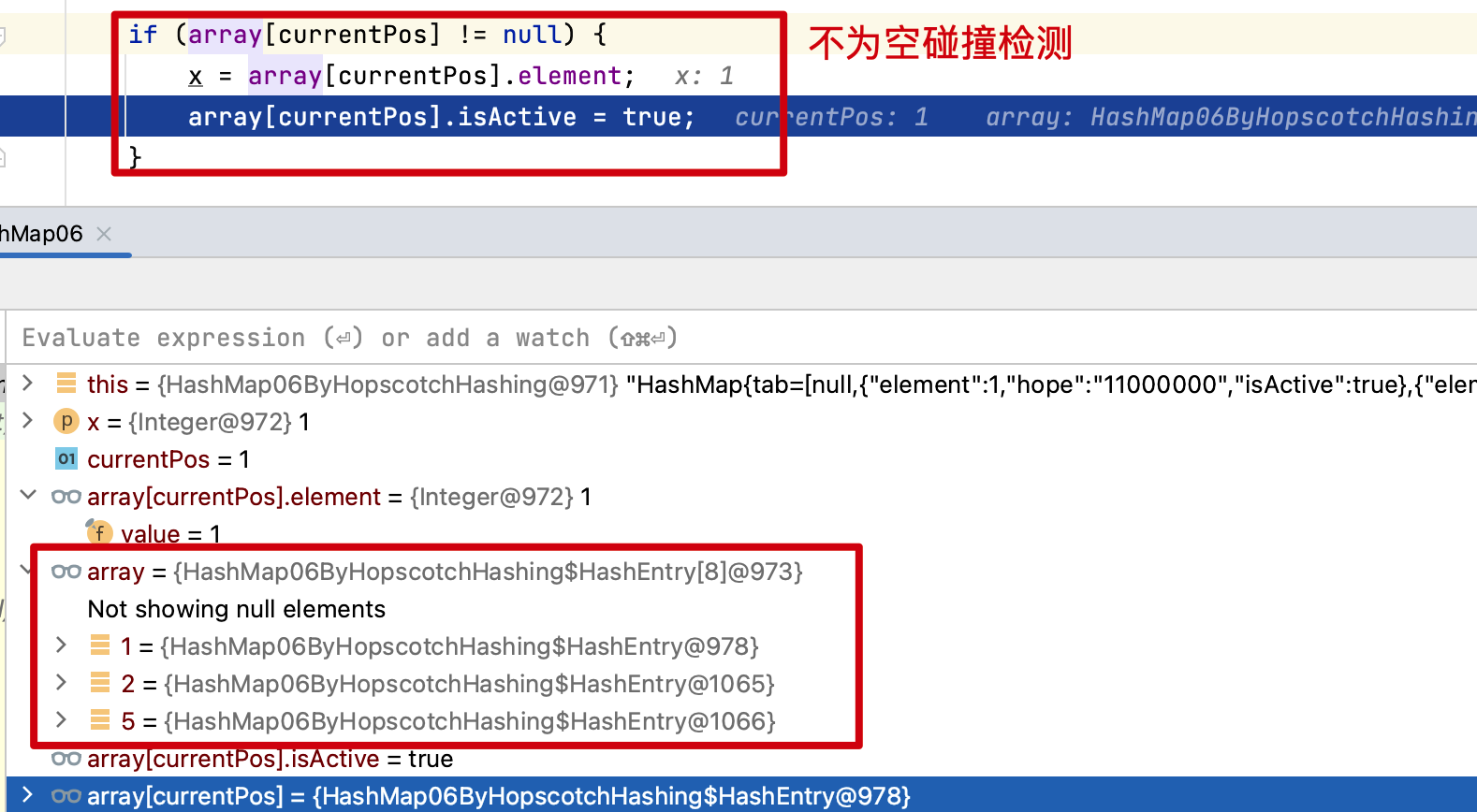
17:10:10.363 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 數據結構:HashMap{tab=[null,{"element":1,"hope":"11000000","isActive":true},{"element":9,"hope":"00000000","isActive":true},null,{"element":12,"hope":"10000000","isActive":true},{"element":5,"hope":"10000000","isActive":true},null,null]}
Process finished with exit code 0
- 通過測試可以看到,跳房子散列會在其原始散列數組條目中找到,或者在接下來的H-1個相鄰條目之一找到對應的衝突元素。
7. 羅賓漢哈希
說明:羅賓漢哈希是一種基於開放尋址的衝突解決算法;衝突是通過偏向從其「原始位置」(即項目被散列到的存儲桶)最遠或最長探測序列長度(PSL)的元素的位移來解決的。
public void put(K key, V value) {
Entry entry = new Entry(key, value);
int idx = hash(key);
// 元素碰撞檢測
while (table[idx] != null) {
if (entry.offset > table[idx].offset) {
// 當前偏移量不止一個,則查看條目交換位置,entry 是正在查看的條目,增加現在搜索的事物的偏移量和 idx
Entry garbage = table[idx];
table[idx] = entry;
entry = garbage;
idx = increment(idx);
entry.offset++;
} else if (entry.offset == table[idx].offset) {
// 當前偏移量與正在查看的檢查鍵是否相同,如果是則它們交換值,如果不是,則增加 idx 和偏移量並繼續
if (table[idx].key.equals(key)) {
// 發現相同值
V oldVal = table[idx].value;
table[idx].value = value;
} else {
idx = increment(idx);
entry.offset++;
}
} else {
// 當前偏移量小於我們正在查看的我們增加 idx 和偏移量並繼續
idx = increment(idx);
entry.offset++;
}
}
// 已經到達了 null 所在的 idx,將新/移動的放在這裡
table[idx] = entry;
size++;
// 超過負載因子擴容
if (size >= loadFactor * table.length) {
rehash(table.length * 2);
}
}
- 09、12 和 01 發生哈希索引碰撞,進行偏移量計算調整。通過最長位置探測碰撞元素位移來處理。
測試
public void test_hashMap07() {
Map<String, String> map = new HashMap07ByRobinHoodHashing<>();
map.put("01", "花花");
map.put("05", "豆豆");
logger.info("碰撞前 key:{} value:{}", "01", map.get("01"));
// 下標碰撞
map.put("09", "蛋蛋");
map.put("12", "苗苗");
logger.info("碰撞前 key:{} value:{}", "01", map.get("12"));
logger.info("數據結構:{}", map);
}
07:34:32.593 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 碰撞前 key:01 value:花花
09 1
12 1
01 1
09 9
12 1
05 5
07:35:07.419 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 碰撞前 key:01 value:苗苗
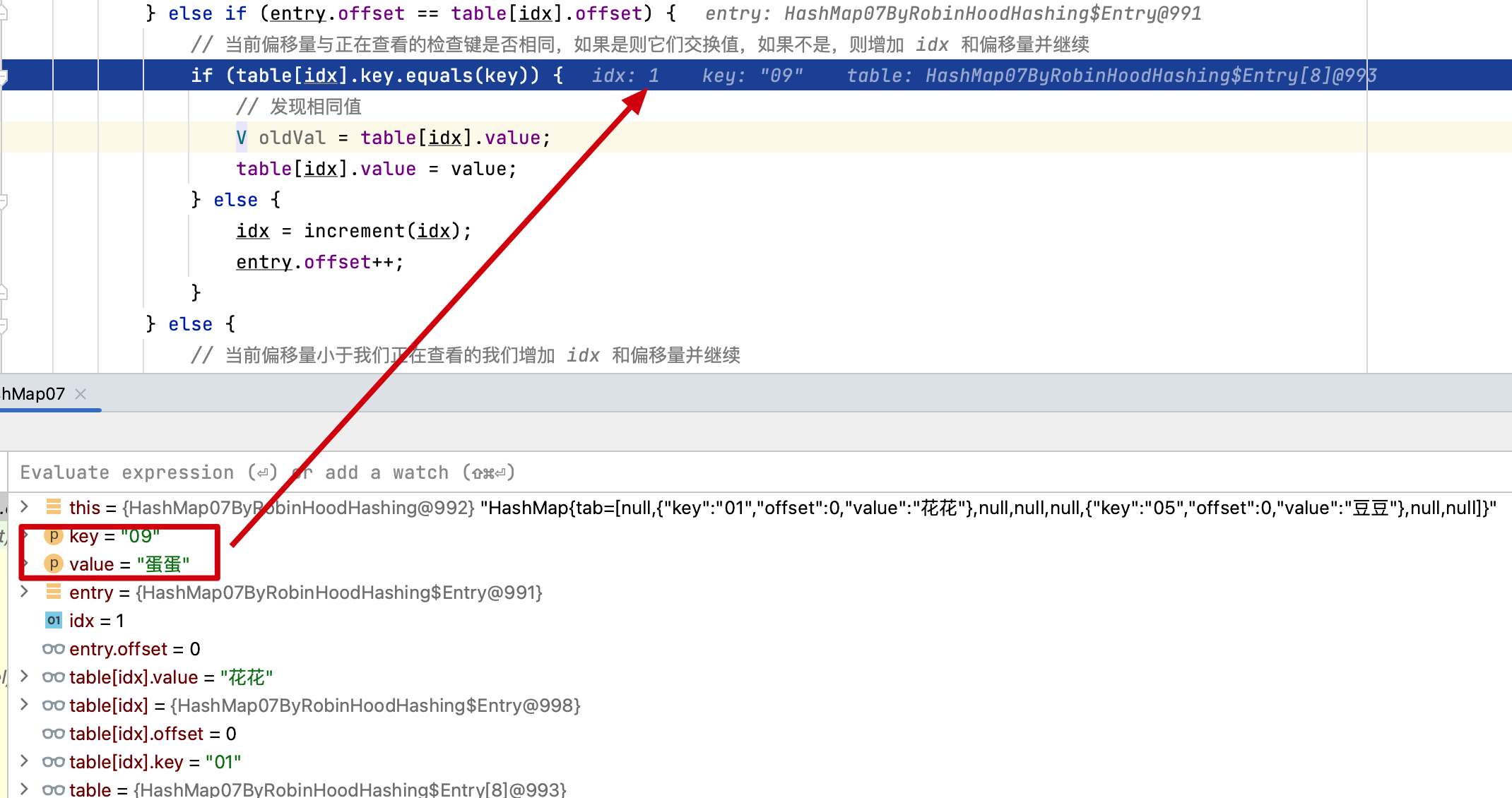
07:35:07.420 [main] INFO cn.bugstack.algorithms.test.AlgorithmsTest - 數據結構:HashMap{tab=[null,{"key":"01","offset":0,"value":"花花"},{"key":"12","offset":1,"value":"苗苗"},null,null,{"key":"05","offset":0,"value":"豆豆"},null,null,null,{"key":"09","offset":0,"value":"蛋蛋"},null,null,null,null,null,null]}
Process finished with exit code 0
- 通過測試結果和調試的時候可以看到,哈希索引衝突是通過偏向從其「原始位置」(即項目被散列到的存儲桶)最遠或最長探測序列長度(PSL)的元素的位移來解決。這塊可以添加斷點調試驗證。
四、常見面試問題
- 介紹一下散列表
- 為什麼使用散列表
- 拉鏈尋址和開放尋址的區別
- 還有其他什麼方式可以解決散列哈希索引衝突
- 對應的Java源碼中,對於哈希索引衝突提供了什麼樣的解決方案


