(數據科學學習手札145)在Python中利用yarl輕鬆操作url
本文示例代碼已上傳至我的
Github倉庫//github.com/CNFeffery/DataScienceStudyNotes
1 簡介
大家好我是費老師,在諸如網絡爬蟲、web應用開發等場景中,我們需要利用Python完成大量的url解析、生成等操作。
而在Python生態中,無論是使用諸如urllib之類的標準庫,還是各種第三方庫,可以用來有效處理url的方法都非常之豐富。而今天費老師我要給大家介紹的url處理庫,則是我在實際使用中綜合考慮簡單易用性與運算速度後,最為滿意的😋。

2 在Python中利用yarl高效處理url
這個可以用來高效便捷處理url的第三方庫叫做yarl,使用pip install yarl完成安裝後,下面我們來快速學習其主要的一些功能方法:
2.1 利用yarl解析url信息
基於yarl中的URL(),我們可以從任意合法的url中解析出下圖所示的各個構成部分:

先來看一個簡單的例子,其中對我保管每一篇博客文章附件的github倉庫路徑url進行解析:
from yarl import URL
url = URL('//github.com/CNFeffery/DataScienceStudyNotes/tree/master/%E5%8E%86%E5%8F%B2%E6%96%87%E7%AB%A0%E9%99%84%E4%BB%B6%E5%88%97%E8%A1%A8')
原始的網址由於包含了中文等非ASCII字符,所以粘貼到代碼中後變成了url編碼後的樣子,直接調用human_repr()方法即可進行解碼還原:
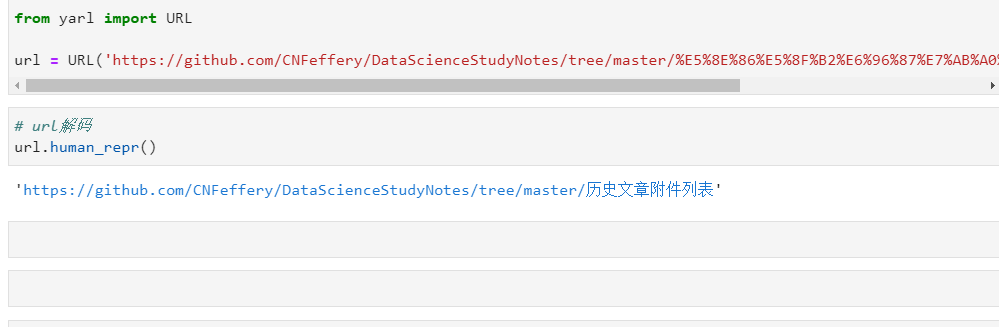
而通過獲取對應url各部分名稱的屬性,即可分別提取出相應信息:

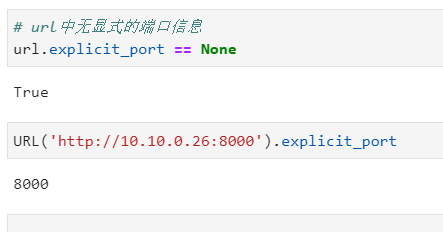
其中端口信息是基於scheme信息按照常規情況進行推斷的,http即為80,https即為443,若需要獲取url中顯式出現的端口信息,可以使用explicit_port:
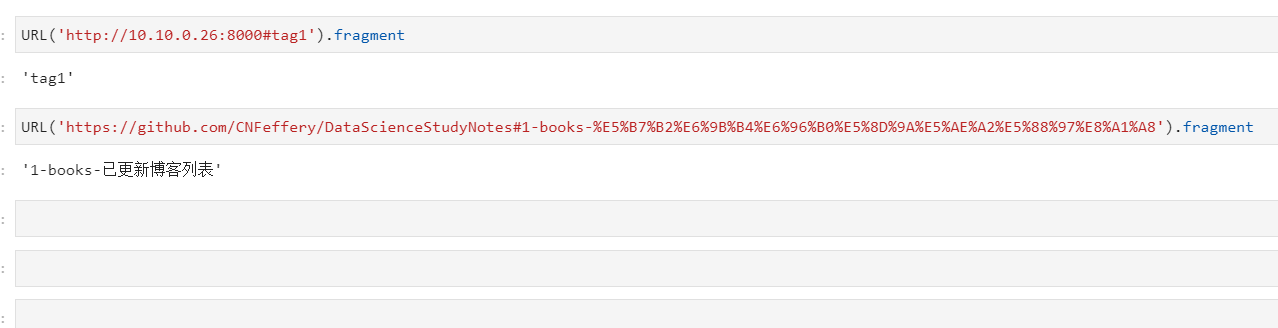
針對url中的hash標籤信息則可以通過fragment取得:
若要解析的url中包含query參數信息,則可以直接調用query得到MultiDict類型的返回結果,這是種特殊的字典類型,它允許存在重複的鍵,對於不存在重複的鍵值對,可以像普通字典那樣索引值,否則則需要通過getall()方法來返回所傳入鍵對應的所有值列表:

可以感受到通過yarl解析url非常的方便~
2.2 利用yarl構造url
當我們需要基於已有的各部分信息構造url時,yarl就更加方便了,基礎的方式是基於URL.build()方法,以函數傳參的方式定義url:

而如果你已經有了具體存在的yarl.URL對象,想在此基礎上進行其他部分內容的設置,則可以使用一系列名稱格式為with_xxx()的方法,其中xxx就對應着各個部分的名稱:
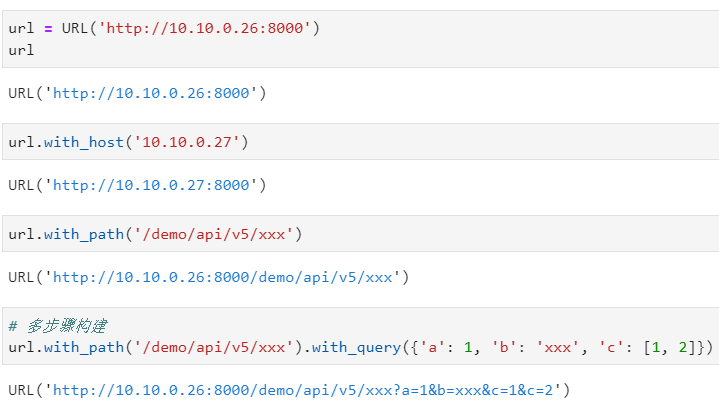
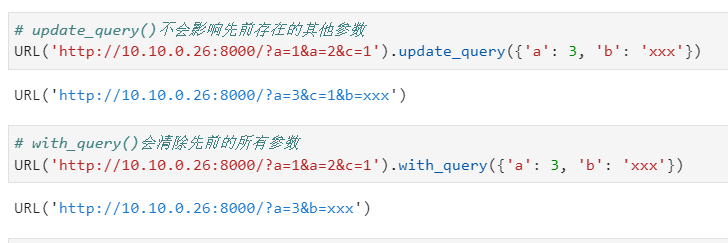
特別地,針對查詢參數部分,還專門有update_query()方法進行參數追加,它與with_query()的區別可以從下面的例子中體會到:
2.3 利用/、%運算符快捷合成url
在yarl中,針對/、%運算符進行了重寫,以支持類似下面例子的快捷操作,非常的方便:

除了上面介紹的yarl常用功能以外,還有譬如利用is_absolute()方法判斷url是否為絕對路徑等其他實用功能,感興趣的讀者朋友們可以前往官方文檔了解更多(//yarl.aio-libs.org/en/latest/index.html)。
以上就是本文的全部內容,歡迎在評論區與我進行討論~


