管正雄:基於預訓練模型、智能運維的QA生成算法落地
- 2022 年 7 月 21 日
- 筆記
- DataFunTalk, 人工智能, 大數據, 算法
分享嘉賓:管正雄 阿里雲 高級算法工程師
出品平台:DataFunTalk
導讀:面對海量的用戶問題,有限的支持人員該如何高效服務好用戶?智能QA生成模型給業務帶來的提效以及如何高效地構建算法服務,為業務提供支持。本文將介紹:阿里雲計算平台大數據產品答疑場景;基於達摩院AliceMind預訓練模型實現的智能QA生成算法核心能力及背後實現原理;如何通過智能運維服務平台將算法能力輸出,給業務提供一站式服務,優化答疑體驗。主要分為以下幾部分:
- 背景介紹
- QA生成框架
- QA生成在業務場景中的應用
- 總結與規劃
- 精彩問答
—
01 背景介紹
1、計算平台產品介紹
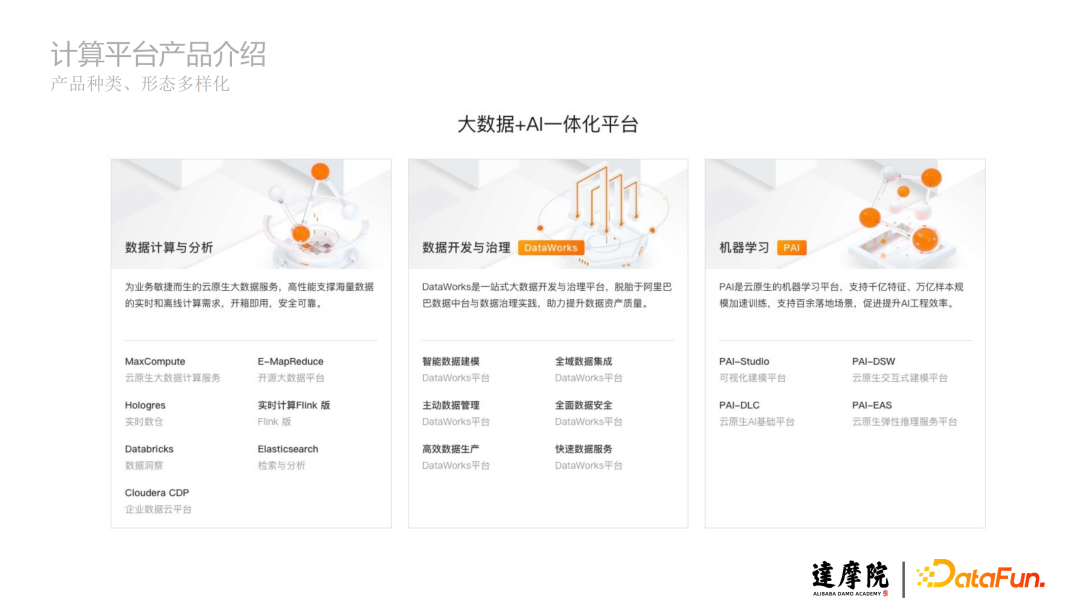
阿里雲計算平台的產品種類多,形態多樣化,主要包括數據計算與分析、數據開發與治理、機器學習三大模塊,其中包括阿里雲自研產品像MaxCompute、Hologres等,以及開源產品像Flink、Elasticsearch等阿里雲提供資源和託管的服務。
2、售後技術支持及痛點
在用戶購買了阿里雲的產品後,在使用過程中如果遇到問題,可以通過以下方式尋求解決方案,但同時又存在一些痛點:
a. 機械人問答:機械人語料覆蓋有限。
b. 文檔查詢:內容過多,查找效率低。
c. 社區問答:集中於高頻問題,中長尾問題較少。
d. 提工單:無法實時解答問題。
3、解決方案:漏斗式答疑支撐模型
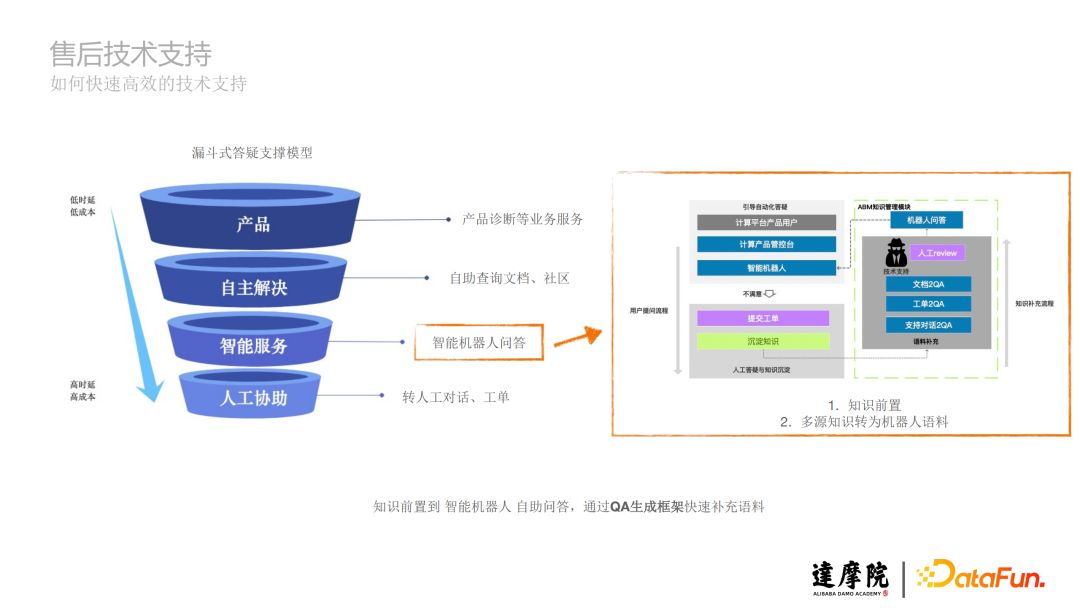
a. 產品:產品診斷等業務服務。
b. 自主解決:自助查詢文檔、社區。
c. 智能服務:智能機械人問答,分為用戶提問流程和知識補充流程,實現知識前置,多源知識轉為機械人語料。
d. 人工協助:轉人工對話、工單。
接下來重點介紹在智能服務中,知識前置到智能機械人自助問答,通過QA生成框架快速補充語料。
—
02 QA生成框架
1、框架介紹
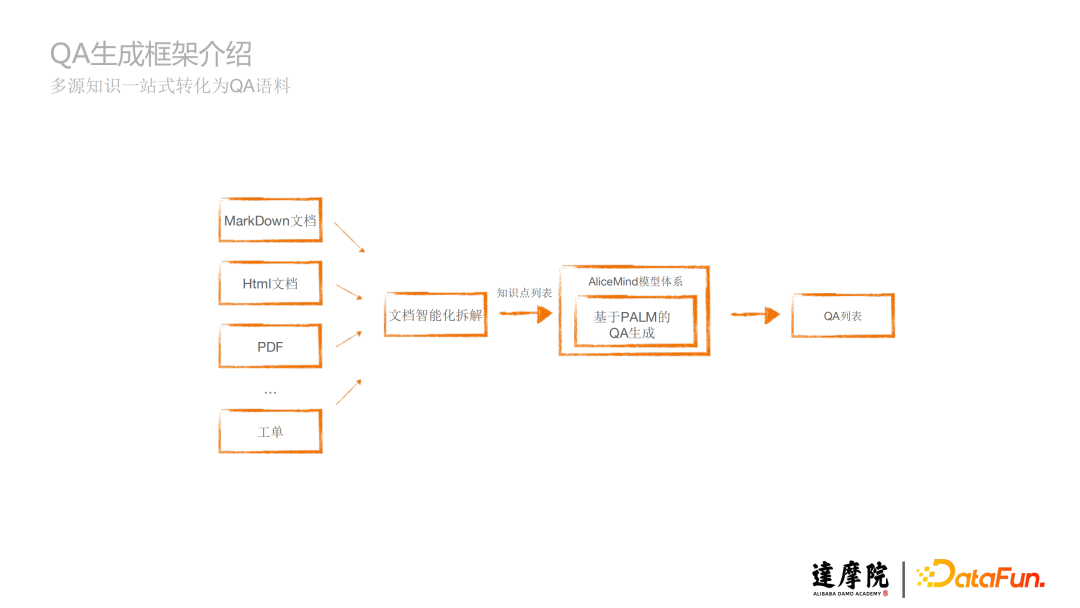
上圖是QA生成框架概覽。文檔智能化拆解模塊,將不同的文檔如MarkDown文檔、Html文檔、PDF文檔、工單等等拆解成知識點,生成知識點列表,知識點列表經過基於AliceMind模型體系里的PALM生成模型,將這些知識點生成QA,最終得到QA列表,從而實現多源知識一站式轉化為QA語料。
2、文檔智能化拆解
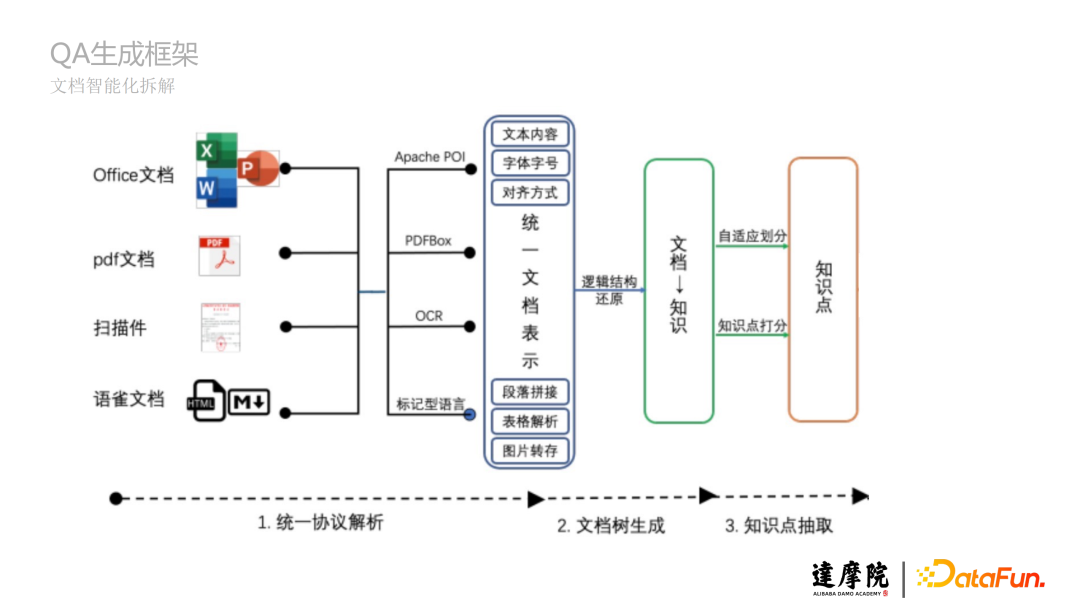
a. 統一協議解析:不同的文檔有不同的協議,將諸如Office文檔、PDF文檔、掃描件、語雀文檔等的協議進行統一文檔表示。
b. 文檔樹生成:將文檔的結構比如一、二、三標題等生成樹狀結構,將文檔的內容梳理成知識點的樹狀匯總。
c. 知識點抽取:基於自適應劃分或知識點打分,將知識樹拆解成具體的知識點。
下圖是HTML文檔拆解和PDF文檔拆解的舉例:

3、AliceMind
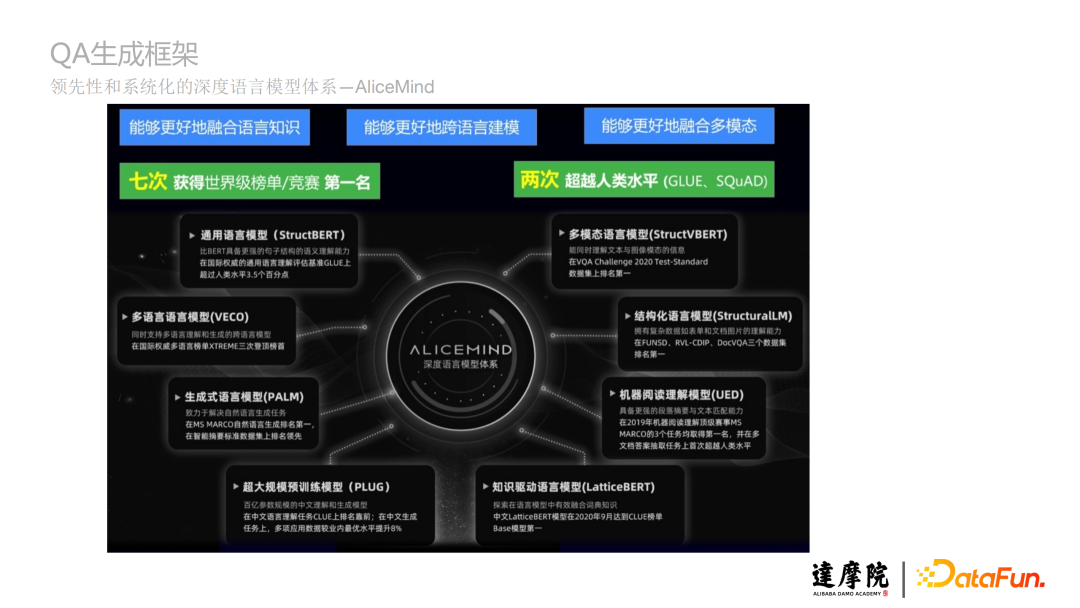
AliceMind是領先性和系統化的深度語言模型體系,本文將重點介紹AliceMind中的生成式語言模型(PALM)如何生成QA。
a. AliceMind的業務價值和應用領域舉例
- 醫療:技術——醫療翻譯、醫療搜索、醫療信息抽取、醫療文本結構化;產品——病歷質檢和健康檔案產品、疫情問答機械人;
- 能源:技術——智能企業知識庫構建及閱讀理解;產品——阿里雲電網智能化運維平台,應用於變壓器檢修、供電搶修等業務;
- 法律:技術——立案及裁判文書生成,法律信息抽取;產品——法院的全流程智能化審判系統,實現從立案到裁判文書生成的全流程智能;
- 金融:技術——金融客服、金融搜索、金融預測;產品——螞蟻智能客服,大幅降低轉人工頻次、天機鏡行為預測。
b. 基於PALM的QA生成模型
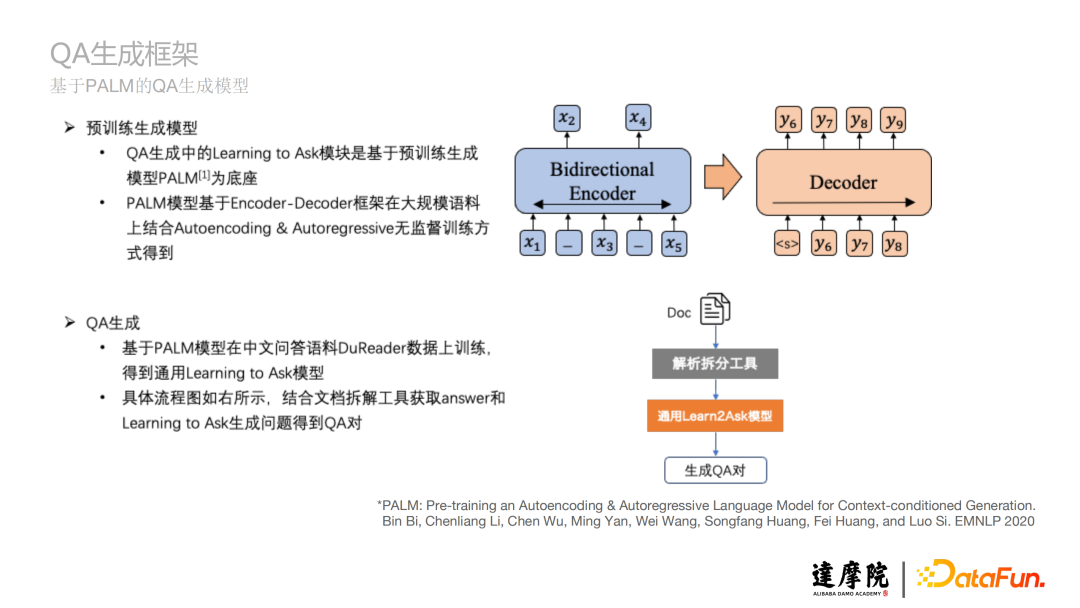
- 預訓練生成模型
QA生成中的Learning to Ask模塊是基於預訓練生成模型PALM為底座;
PALM模型基於Encoder-Decoder框架在大規模語料上結合Autoencoding & Autoregressive無監督訓練方式得到。
- QA生成
基於PALM模型在中文問答語料DuReader數據上訓練,得到通用Learning to Ask模型;
具體流程圖如上圖下半部分所示,結合文檔拆解工具獲取answer和Learning to Ask生成問題得到QA對。
更多閱讀:
PALM: Pre-training an Autoencoding & Autoregressive Language Model for Context-conditioned Generation.
BinBi, Chenliang Li, Chen Wu, Ming Yan, Wei Wang, Songfang Huang, Fei Huang, and Luo Si. EMNLP 2020
4、文檔轉化成QA舉例
a. 文檔:

- b. QA對:
Q:Dataworks的工作空間是什麼
A:工作空間是Dataworks管理任務、成員……
Q:DataWorks的解決方案的優勢是什麼
A:一個解決方案可以包括多個業務流程,解決方案……
—
03 QA生成在業務場景中的應用
1、ABM運維管控平台
ABM運維管控平台即飛天大數據管控平台(ABM,Apsara Big Data Manager),是支撐平台服務與集群的全生命周期管理,智能化運維、運營和交付,面向大數據的業務方、運營方及研發方提供企業級運維平台。

2、ABM智能算法平台
ABM智能算法平台提供算法從開發-構建-部署的全生命周期的支撐。

如圖所示,算法開發可以添加算法配置和註冊算法檢測器,SRE用戶或運維可以創建場景生成檢測實例,這個檢測實例就是QA生成算法的應用實例,然後算法調度框架去調度,最後再給到用戶。這一系列過程可以通過智能場景運營大盤進行整個生命周期的管理。
3、知識管理業務流程圖
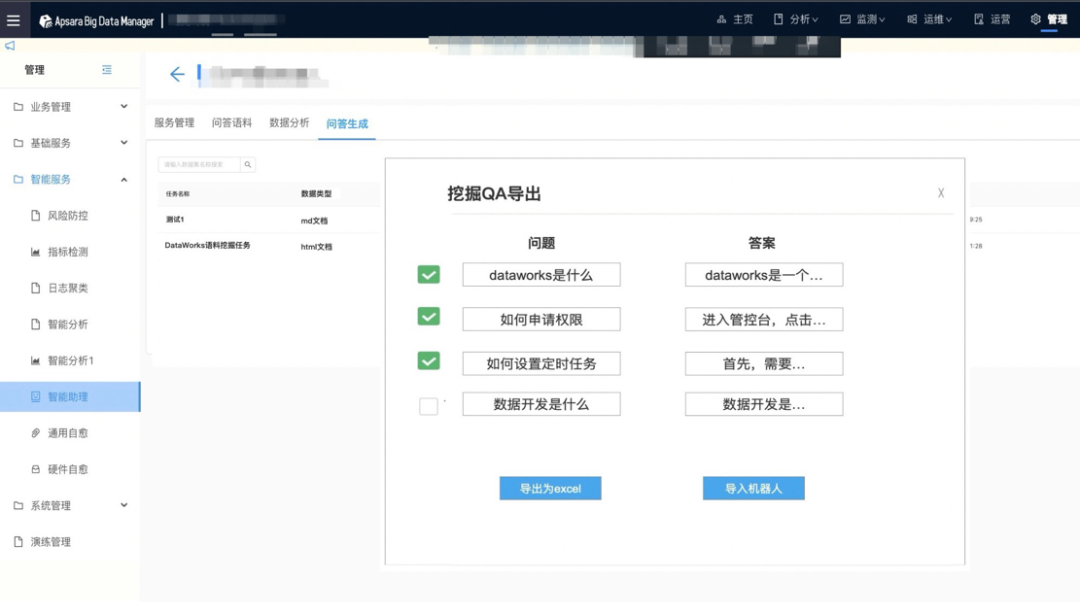
基於前面的QA生成框架概覽圖,最終生成的QA列表可能不是100%準確的,那麼還要通過一些指標對其進行評估是否符合預期,同時經過我們專家的review,符合預期的QA將灌入到機械人語料、FAQ頁面、知識圖譜等裏面。這就是整體的業務流程。
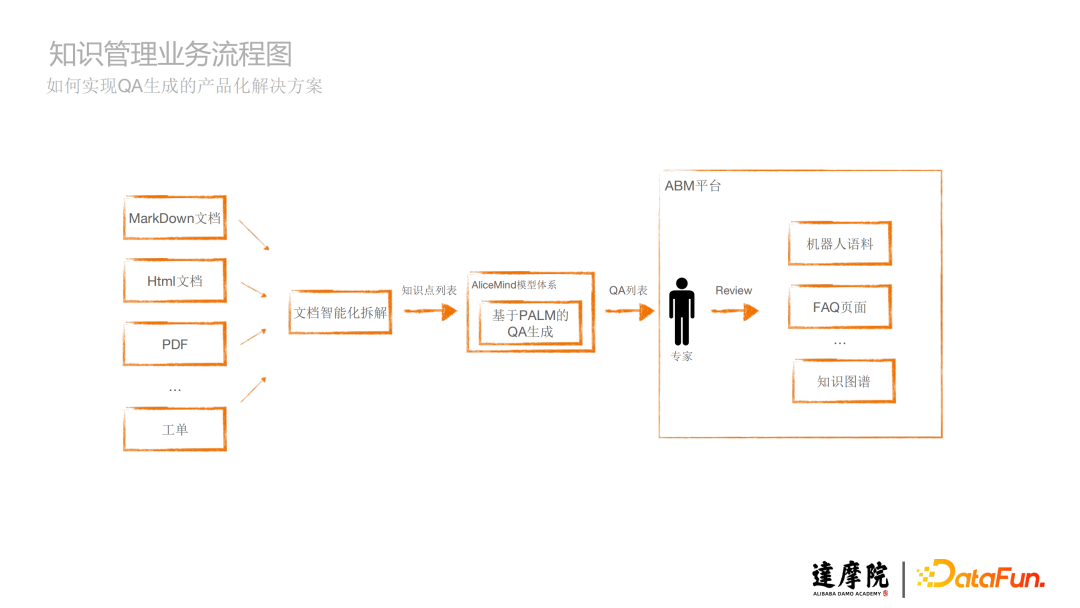
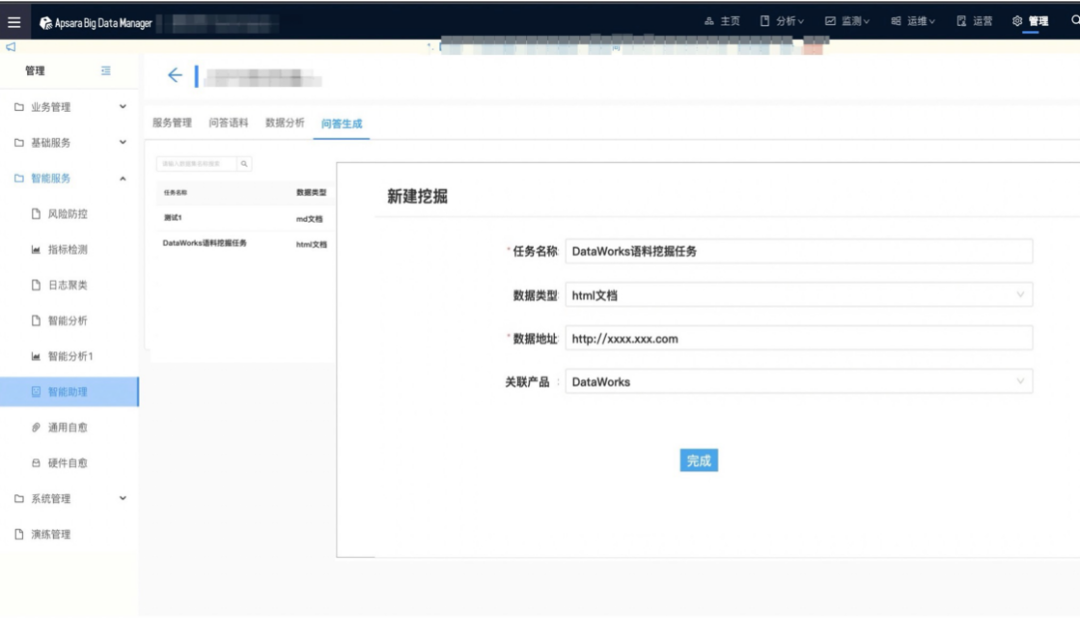
4、QA生成產品界面
a. 新建挖掘任務
b. 導出生成QA語料
—
04 總結與規劃
1、沉澱
提取對話、論壇、工單等中的不同形式,有效知識通過某種方式沉澱到統一的知識庫中。
關鍵詞:多源數據、格式化。
規劃:增加更多的數據源,格式化方法能力進一步提升。
2、消費
通過人機交互接口,精準推送知識,解用戶內心之惑。
關鍵詞:搜索與推薦、個性化、評估與反饋。
規劃:通過深度模型提升搜索、推薦的能力。
3、流動
流程化,將知識的沉澱、消費在各角色間串聯,讓知識流動,實現迭代優化。
關鍵詞:機制、人機協同。
規劃:進一步優化流程,流程符合習慣的同時,進一步減少人工成本。
—
05 精彩問答
Q:如果這套QA生成方案在其它領域使用,遷移成本高嗎?有哪些注意事項?
A:不高。我們在構建下游任務的時候需要一些數據,這個量不需要很大,目前我們應用的場景主要是電力、合同領域,大概幾百條左右就可能會在該領域有一個比較好的表現。需要注意的是,訓練集的質量相對來說要高一點,更能反映這個領域的屬性。
Q:這樣構造的問答對會不會樣式比較單一?
A:這個是跟產品有關,一個問題就是一個知識點,以及對應這個知識點的答案,QA在這樣的一個場景里還是比較好用的。
Q:請問怎麼衡量問題生成的質量?
A:這個主要有兩部分。第一部分,從模型層面會有一個得分,然後會有一些評價指標來衡量,這一部分在論文里有明確說明;第二部分是通過人工來評估,需要該領域的專家來完成,比如看這個QA是不是符合用戶提問的習慣等。
Q:支持抽取多輪問答嗎?
A:支持的。這個取決於你的訓練集,如果訓練集是多輪的,是可以抽取多輪對話的問答的。但是多輪對話問答的訓練集,相對於文檔生成問題的訓練集,要難構建一點。
Q:能詳細說一下評估反饋機制嗎?
A:好的。從後台界面可以看到,生成QA以後,展現在界面上的是經過第一層篩選的,也就是說經過模型篩選的,然後讓技術支持的同學去評估,評估完了以後可以選定和導出,或者導入機械人,我們會記錄,作為一些正樣本和副樣本,作為後面學習過程的一個增量。除了技術支持的反饋,還有用戶的反饋,然後再去調優。
Q:問答最後是人工質量質檢,如果量大怎麼控制?
A:第一層模型篩選會過濾掉較大的部分,分配下來以後,人工評估的工作量並不是特別的大。
Q:為啥智能客服很智障?
A:人工智能的前提,都是靠人的智力去慢慢堆積出來的。我們希望做的這些工作,能夠慢慢地把智能客服從人工智障變成人工智能,這個也是我們的目標。
Q:拆解只適合格式化文件嗎?
A:不是的。這個主要是你構建的下游任務,比如你的訓練集是通過多人對話去抽取QA,還是從工單裏面抽取QA,那下游任務訓練出來的模型,就可以執行對應的任務,這取決於你的訓練集。
Q:評價通過的準確率大概有多少?會超過90%嗎?
A:根據我們之前的內部測試,大概在70%-80%左右,不同的產品可能會有一些差異性。
Q:對沒有明顯結構的網頁數據如何進行拆解?
A:沒有明顯結構的網頁數據可能會有一些HTML的Tag,可以基於Tag來拆解;如果一點都沒有的話,那隻能根據語意來拆解了,效果肯定沒有有Tag的效果好。
Q:什麼是多輪對話的知識形式?
A:多輪對話不像一問一答這麼簡單,它可能會有一些狀態。我們的場景是計算平台的產品,目前基本上用不到多輪對話,一輪對話基本上可以解決了。
Q:Query如何和用戶庫中的QA對進行檢索匹配?
A:比較簡單的,Elasticsearch就可以做了;如果有更高的個性化需求比如做Query改寫等,可以上一些深度模型。
Q:考慮過通過閱讀理解去解決這個問題嗎?
A:PALM就是基於語言理解和生成模型,它是通過閱讀理解的這個深度模型作為底座,然後再加上下游任務來完成的。
Q:有用到知識圖譜嗎?
A:目前沒有用到。目前我們的場景基本上是可以通過QA來覆蓋的,後續其實我們是有這樣一個方向的,我們做的這些可能就是知識圖譜前面的一些鋪墊。
Q:生成的問題模式會比較單一?
A:不一定。這基於兩點,第一是預訓練語料的語法是不是很靈活多變;第二是你的訓練集,訓練集裏面的問法,如果說都是同一類的話,它生成的模型也會有比較大的傾向。
Q:自動文檔抽取使用的預訓練模型,在遷移訓練時有模型改動或者輸入格式匹配嗎?
A:會有一些。這裡肯定會做格式統一,但沒有一個強制的規定,只要有一定格式上的相似性。
Q:Query同意改寫在你們團隊有實踐嗎?
A:有的。這個同意改寫其實是基於一些模型,比如說是通過一些相似性、近義詞等。在我們的大數據產品領域,對於產品的問法,我們可以為維護一個詞庫,我去收集一套可能的這個產品的所有的問法,就可以把它放到Query改寫裏面,作為一個同義詞庫。對於領域化的東西相對來說比較好找,像Query改寫在開發領域則相對難一些。
Q:有源碼嗎?
A:可以去看那篇PALM論文。因為講得比較清晰,大家也可以自己實現。
今天的分享就到這裡,謝謝大家。
分享嘉賓:

本文首發於微信公眾號「DataFunTalk」。