PSS:你距離NMS-free+提點只有兩個卷積層 | 2021論文
論文提出了簡單高效的PSS分支,僅需在原網絡的基礎上添加兩個卷積層就能去掉NMS後處理,還能提升模型的準確率,而stop-grad的訓練方法也挺有意思的,值得一看
來源:曉飛的算法工程筆記 公眾號
論文: Object Detection Made Simpler by Eliminating Heuristic NMS

Introduction
當前主流的目標檢測算法訓練時大都一個GT對應多個正樣本,使得推理時也會多個輸出對應一個目標,不得不對結果進行NMS過濾。而論文的目標是設計一個簡單的高性能全卷積網絡,在不使用NMS情況下,能夠進行完全的端到端訓練。論文提出的方法十分簡單,核心在於添加一個正樣本選擇分支(positive sample selector, PSS)。
論文的主要貢獻如下:
- 檢測流程在去掉NMS後變得更加簡單,從FCOS到FCOS_{PSS}的修改能植入到其他的FCN解決方案中。
- 實驗證明可以通過引入簡單的PSS分支來代替NMS,植入FCOS僅需增加少量的計算量。
- PSS分支十分靈活,本質上相當於可學習的NMS,由於加入PSS分支沒有影響到原有結構,可直接去掉PSS分支直接使用NMS。
- 在COCO上,得到與FCOS、ATSS以及最近的NMS-free方法相當或更好的結果。
- 提出的PSS分支可應用於其他anchor-based檢測器中,在每個位置一個anchor box的設定下,僅通過PSS分支的動態訓練樣本選擇也能達到不錯的結果。
- 同樣的想法也可用於其他目標識別任務中,如去掉實例分割中的NMS操作。
Our Method

FCOS_{PSS}的整體結構如圖1所示,僅在FCOS的基礎上添加了包含兩個卷積層的SPP分支。
Overall Training Objective
完整的訓練損失函數為:

\mathcal{L}_{fcos}為原版FCOS的損失項,包含分類損失、回歸損失和center-ness損失。此外,還有PSS分支損失和ranking損失。在訓練時\lambda_2設置為0.25,因為ranking損失對準確率只有些許提升。
-
PSS損失
PSS分支是NMS-free的關鍵,如圖1所示,該分支的特徵圖輸出為\mathbb{R}^{H\times W\times 1}。定義\sigma(pss)為特徵圖上的一個點,僅當該點為正樣本時才設為1,所以可以把PSS分支當作二分類加入訓練。但為了借用FCOS多分類的優勢,論文將其與分類特徵、center-ness特徵進行融合:
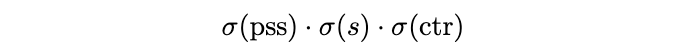
用上面的分數計算focal loss,與原本的FCOS分類的區別是,這裡每個GT有且僅有一個正樣本。
-
Ranking損失
論文通過實驗發現,在訓練時加入ranking損失能提升性能,ranking損失的定義為:

\gamma代表正負樣本間的距離,默認設置為0.5。n_{+}和n_{-}為正負樣本數量,\hat{P}_{i_{+}}(c_{i_{+}})為正樣本i_{+}對應類別c_{i_{+}}的分類分數,\hat{P}_{i_{-}}(c_{i_{-}})為負樣本i_{-}對應類別c_{i_{-}}的分類分數。在實驗中,取top 100負樣本分數進行計算。
One-to-many Label Assignment
一個GT選擇多個anchor作為正樣本進行訓練是當前目標檢測廣泛採用的一種做法,這樣的做法能夠極大地簡化標註要求,同時也能夠兼容數據增強。即使標註位置有些許偏差,也不會改變選擇的正樣本。另外,多個正樣本能夠提供更豐富的特徵,幫助訓練更強大的分類器,比如尺寸不變性、平移不變性。因此,對於原生的FCOS分支的訓練依然採用一對多的方式。
One-to-one Label Assignment
一對一的訓練方式需要每次為GT選擇最佳正樣本,選擇的時候需要考慮分類匹配程度和定位匹配程度,這裡,先定義一個匹配分數Q_{i,j}:

i為預測框編號,j為GT編號,超參數\alpha用來調整分類和定位間的比值。\Omega_j表示GT j的候選正樣本,採用FCOS的規則,在GT的中心區域的點對應的anchor均為候選正樣本。最後,對所有的GT及其正樣本採用二分圖匹配,通過匈牙利算法選擇最大化\sum_{j}Q_{i,j}的匹配方案。
Conflict in the Two Classification Loss Terms
在論文提出的方案中,損失項\mathcal{L}_{fcos}採用一對多的匹配方案,而損失項\mathcal{L}_{pss}採用一對一的匹配方案,這意味着有部分anchor可能會被同時劃分為正樣本和負樣本,導致模型難以收斂。為此,論文提出了stop-grad的概念,即阻止PSS分支的梯度回傳到FCOS中。
Stop Gradient
stop-gradient操作在訓練的時候將其中一部分網絡設置為常數,定義\theta=\{\theta_{fcos},\theta_{pss}\}為網絡需要優化的參數,訓練的目標是求解:

將上述求解分成兩個步驟:

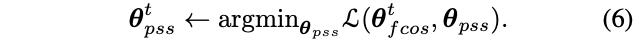
即在一輪迭代中,交替優化參數\theta_{fcos}和\theta_{pss}。比如在求解公式5時,\theta_{pss}的梯度置為零,按作者的說法,這塊直接用pytorch的detach()進行分離。另外一種方法是直接分開訓練,當求解公式5時,設置\theta_{pss}=0直到收斂,等同於原本的FCOS訓練。而在訓練PSS分支時,凍結FCOS參數直到收斂。論文通過實驗發現分開訓練可以極大地縮短訓練時間,但性能稍差些。
Experiment
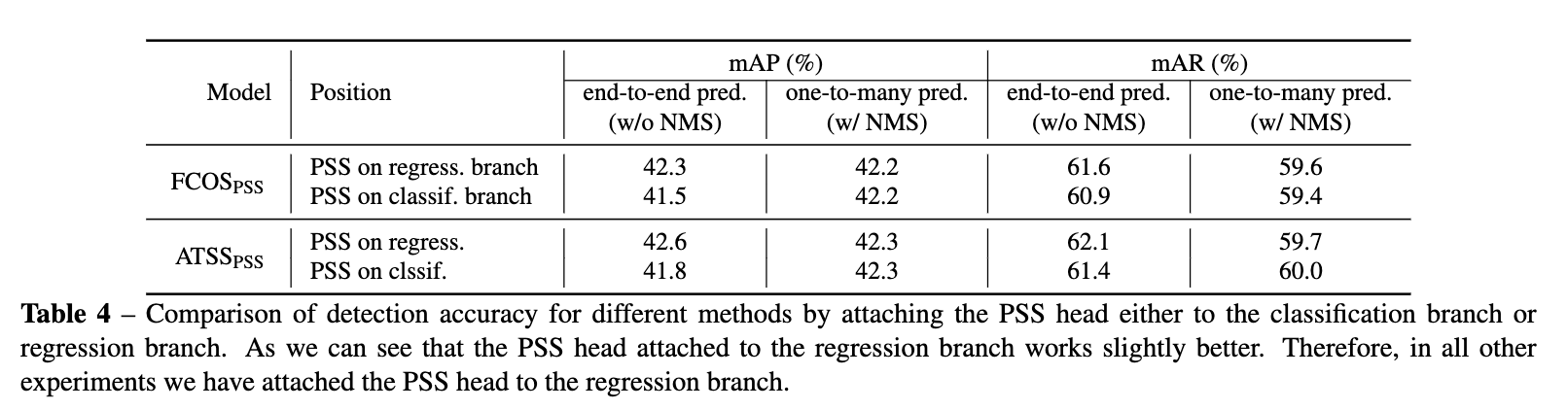
從論文的實驗來看,PSS分支+stop grad的效果還是不錯的。論文還有很大對比實驗,有興趣的可以去看看。
Conclusion
論文提出了簡單高效的PSS分支,僅需在原網絡的基礎上添加包含兩個卷積層就能去掉NMS後處理,還能提升模型的準確率,而stop-grad的訓練方法也挺有意思的,值得一看。
如果本文對你有幫助,麻煩點個贊或在看唄~
更多內容請關注 微信公眾號【曉飛的算法工程筆記】



