Expectation Maximization Algorithm
- 2022 年 5 月 10 日
- 筆記
- EM算法, Machine Learning
Expectation Maximization Algorithm
Introduction
極大似然
假設我們需要調查我們學校的身高發佈,並且假設這個身高分佈滿足正態分佈,那麼我們的目的就是找到滿足最符合這個分佈的參數\(\mu和\sigma^2\),對此我們抽樣取得數據,並且抽樣樣本\(n=200\)
似然函數
對於以上問題,由於我們對參數\(\mu和\sigma^2\)未知,也就是我們對概率函數未知,並且我們的目的是由已知數據推導我們的概率參數,暫且對每個數據建立概率模型
L(\theta)=L\left(x_{1}, x_{2}, \cdots, x_{n} ; \theta\right)=\prod_{i=1}^{n} p\left(x_{i} \mid \theta\right), \quad \theta \in \Theta
\]
上述公式的\(\theta\)表示概率參數的\(\mu和\sigma,L(\theta)\)表示多個數據的聯合概率函數,那麼對於這個函數的處理就用到了我們極大似然的思想,即我們的目的是\(max \ L(\theta)\),由於連乘符號不便於計算,以此取對數得到對數似然函數
\]
極大似然思想
就像我們對於線性回歸時希望我們構造出來的曲線對已有數據的擬合最佳,這樣才能更好的預測未來數據,極大似然的思想也是如此,希望對已有數據的解釋最佳,也就是我們的概率函數要”站的住腳”,就需要似然函數越大越好,這有點像數據的反推
計算極大似然的一般步驟
- 寫出似然函數;
- 對似然函數取對數,並整理;
- 求導數,令導數為 0,得到似然方程;
- 解似然方程,得到的參數。
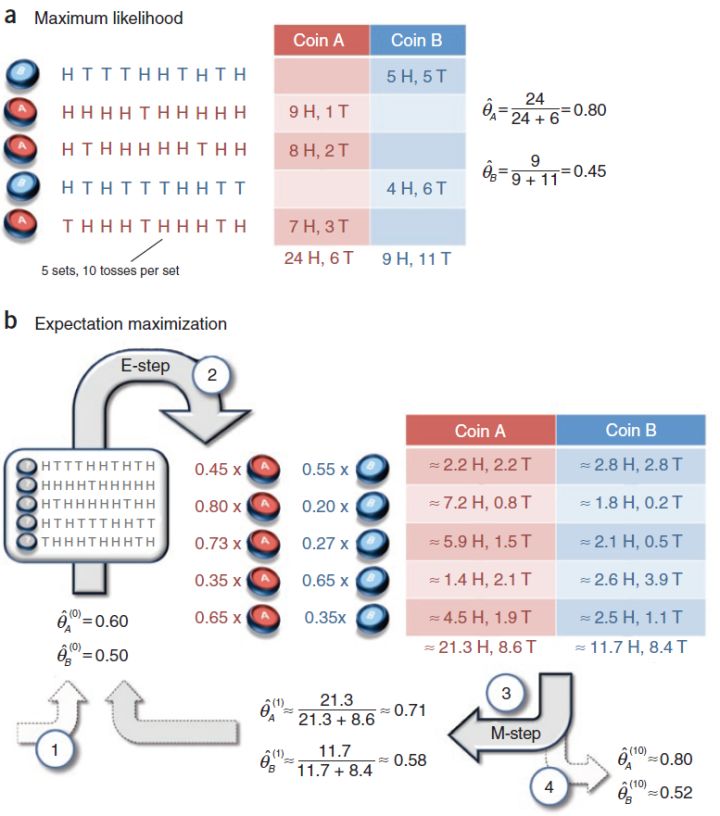
三硬幣問題 — 計算極大似然的困境
對於一個拋硬幣的問題,我們可以取隨機變量X,它滿足伯努利分佈,假設\(p\)是硬幣朝上的概率,\(q=1-p\),\(f(x|p)\)表示概率函數
\]
但是我們假設我們獲得了三個神奇的硬幣,這三個硬幣我們並不知道它正面朝上的概率,於是我們只能通過試驗獲得樣本反推它的概率,這裡就要用到我們的極大似然的方法,我們對這個問題建立相應的概率模型
試驗
由於技術問題,我們只能進行一下試驗,對於三個硬幣\(a,b,c\),我們拋三次硬幣,如果\(a\)=1,那麼我們取\(b\)的值,反之我們取\(c\)的值,(這裡的取值是0和1,正面表示1,反面表示0)
\begin{aligned}
P(y \mid \theta) &=\sum_{z} P(y, z \mid \theta)=\sum_{z} P(z \mid \theta) P(y \mid z, \theta) \\
&=\pi p^{y}(1-p)^{1-y}+(1-\pi) q^{y}(1-q)^{1-y}
\end{aligned}
\]
符號說明: \(P(y|\theta)\)表示再概率參數\(\pi,p,q\)下y的取值概率,\(z\)表示硬幣\(a\)的取值,作為本次試驗的隱數據(因為我們並不對\(a\)的取值做統計,所以是為觀測數據)
極大似然
似然函數:
\]
極大似然估計:
\]
好的,我們省略了中間的許多步驟,但是最終的目的是明確的,就是找到最佳的\(\theta\)來最大化我們的聯合似然函數,但是問題來了,這個似然函數似乎不好計算,
- 變量不止一個,包含概率參數\(\pi,p,q\)
- 聯合概率密度,要通過對數化計算
如果用一般的方法,我們似乎要廢掉很多頭髮,但是這就是我要引入的EM算法,也就是說EM算法可以用來計算這種極大似然非常複雜的情況
Algorithm
STEP
- 選取初值
- 獲取樣本
- 通過樣本更新迭代參數值
- 多次迭代直到收斂
我們用三硬幣問題來解釋這個算法的步驟,
對於這個問題,我們首先把我們的概率參數\(\pi,p,q\)隨機初始化獲得初始值,再通過\(n\)次試驗獲得數據樣本,對於樣本的描述如下,我們已知進行了\(n\)次採樣,並且獲得了每次採樣的值\(y_i\),接下來就是算法的第三步,通過樣本結合概率函數來優化你的參數,這裡的數學原理要仔細思考
對於每一次實驗,我們可以得到我們的概率函數如下
\alpha(y_i) = \frac {\pi p} {\pi p + (1-\pi)q} \\
\lambda(y_i) = \frac {(1-\pi) q} {\pi p + (1-\pi)q} \\
\]
\beta(y_i) = \frac {\pi (1-p)} {\pi (1-p) + (1-\pi)(1-q)} \\
\gamma(y_i) = \frac {(1-\pi) (1-q)} {\pi(1-p)+(1-\pi)(1-q)}
\]
符號說明:
\(a(y_i)\)表示實驗序號\(i\)下,實驗結果\(X=1\),結果來自硬幣\(b\)的概率;\(\lambda(y_i)\)表示同樣條件下,結果來自硬幣\(c\)的概率;\(\beta(y_i)\)表示實驗結果\(X=0\),結果來源於硬幣\(b\)的概率,\(\gamma(y_i)\)表示結果出自\(c\)的概率
那麼我們可以給出下面的優化方程來迭代你概率參數
p = \frac {\sum_{x=1}\alpha(y_i)} {\sum_{x=1}\alpha(y_i)+\sum_{x=0}\beta(y_i)} \\
q = \frac {\sum_{x=1}\lambda(y_i) } {\sum_{x=1}\lambda(y_i)+\sum_{x=0}\gamma(y_i)}
\]
理解上面的優化方程,那麼EM算法的基本層面是沒有問題了,這裡就不能給出更過的解釋了,其實也是一種基於先驗計算後驗的方法
後續就是循環迭代,對於這個算法其實和K-means算法有相似之處,並且可以說明的是,它和K-means都可以用於聚類模型
再循環迭代上,可以說明的是,對於循環的結束怎麼判斷,
- 參數變動小於臨界值: $\left|\theta{(i+1)}-\theta{(i)}\right|<\varepsilon_{1} $
- Q函數變動小於臨界值:\(\left\|Q\left(\theta^{(i+1)}, \theta^{(i)}\right)-Q\left(\theta^{(i)}, \theta^{(i)}\right)\right\|<\varepsilon_{2}\)
對於\(Q\)函數的解釋: 完全數據的對數似然函數\(logP(Y,Z|Θ)\)關於在給定觀測數 據Y和當前函數\(Θ(i)\)下對未觀測數據Z的條件概率分佈$ P(Z|Y, Θ(i))\(,的期望稱為\)Q$函數
\]
對\(Q\)函數的理解具體看後面的數學推導
Mathematical Explanation of Algorithms
我們已經了解了EM算法的步驟,但是對於其中較為深刻的數學原理還不知道,這裡其中包括了一下幾個問題,
- 為什麼EM算法能近似實現對觀測數據的極大似然估計
- 為什麼在EM算法下,概率參數最終能夠收斂
對於上面的一些問題包括Q函數的來源包含複雜的數學推導,由於這些的數學推導不簡單,內容比較多,推薦取看李航的《統計學習方法》,這本書給出了詳細的解釋
Application of EM Algorithm
在高斯混合模型(GMM)上的運用
EM算法的一個重要應用是高斯混合模型的參數估計,高斯混合模型應用廣泛(比如機器學習的聚類),且由於他再極大似然上存在難度,所以EM算法是高斯混合模型參數估計的很有效的方法,
對於這個的具體內容可以詳細看我的其他博客
在無監督學習上的應用
略
Conclusion
自我收穫: EM算法是我目前學習的數學推導最多的算法,算上去,我從了解各種概率模型開始,然後先驗分佈和後驗分佈,其中看了很多他人的博客,在最開始理解算法的時候是看了B站的復旦老師的課程,後面對公式理解最多的地方是從李航的書上


