如何使用 python 爬取酷我在線音樂
- 2022 年 4 月 9 日
- 筆記
- javascript, Python, 爬蟲
前言
寫這篇博客的初衷是加深自己對網絡請求發送和響應的理解,僅供學習使用,請勿用於非法用途!文明爬蟲,從我做起。下面進入正題。
獲取歌曲信息列表
在酷我的搜索框中輸入關鍵詞 aiko,回車之後可以看到所有和 aiko 相關的歌曲。打開開發者模式,在網絡面板下按下 ctrl + f,搜索 二人,可以找到響應結果中包含 二人 的請求,這個請求就是用來獲取歌曲信息列表的。
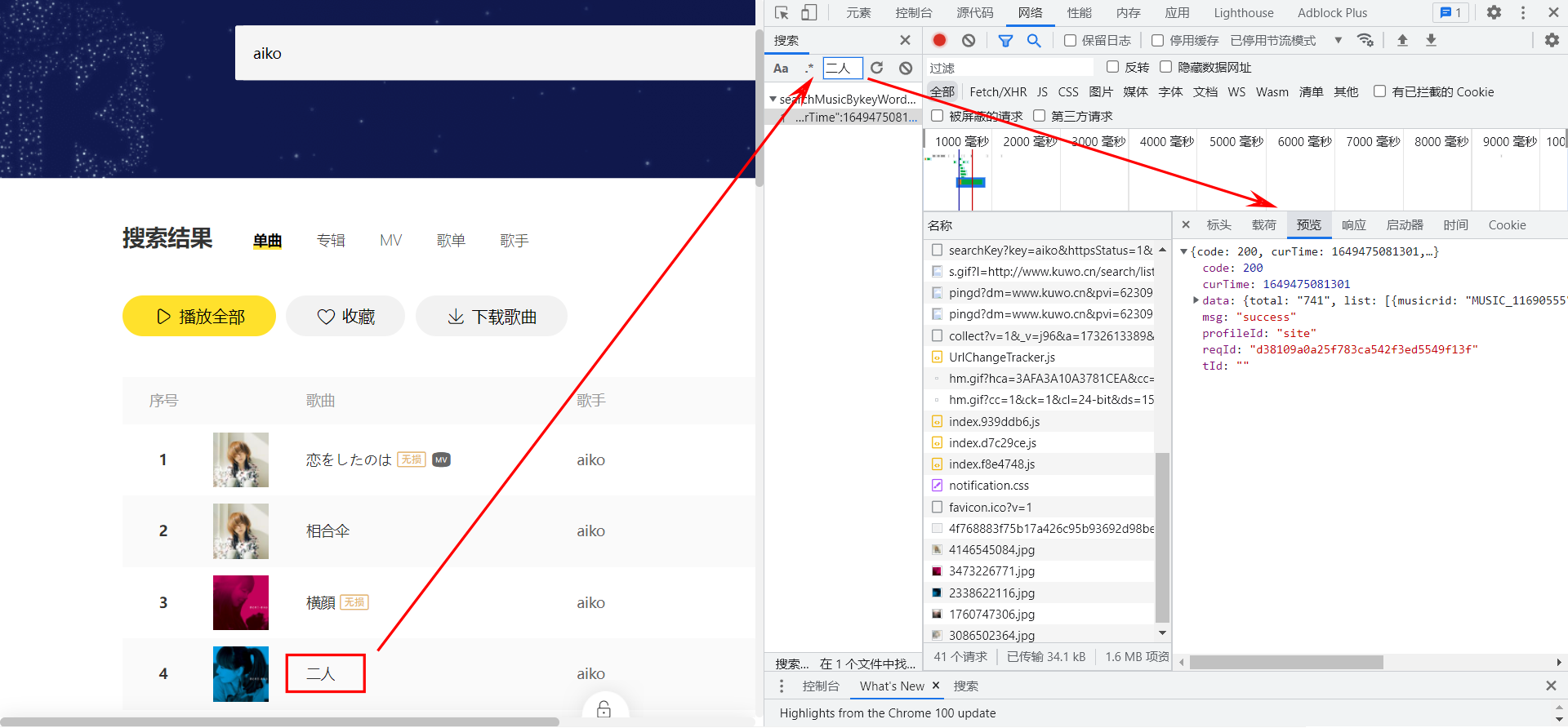
請求參數分析
請求的具體格式如下圖所示,可以看到請求路徑為 //www.kuwo.cn/api/www/search/searchMusicBykeyWord,請求參數包括:
key: 搜索關鍵詞,此處為aikopn: 頁碼,page number的縮寫,此處為1rn: 每頁條目數,應該是row number的縮寫,默認為30httpsStatus:https 的狀態?感覺沒啥大用,看了源代碼裏面是直接寫死t.url = t.url + "?reqId=".concat(n, "&httpsStatus=1")reqId:請求標識,刷新頁面之後值會發生改變,不知道有啥用,待會兒模擬請求的時候試着不帶上他會怎麼樣
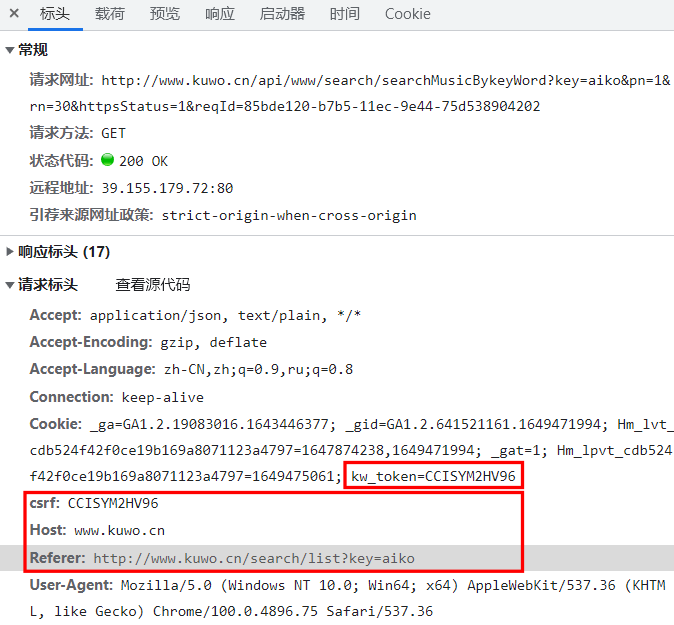
打開 Apifox(當然 postman 也行),新建一個接口,把請求路徑和參數設置為下圖所示的樣子,為了讓響應結果簡短點,這裡把每頁的條目數設置為 1 而非默認的 30:
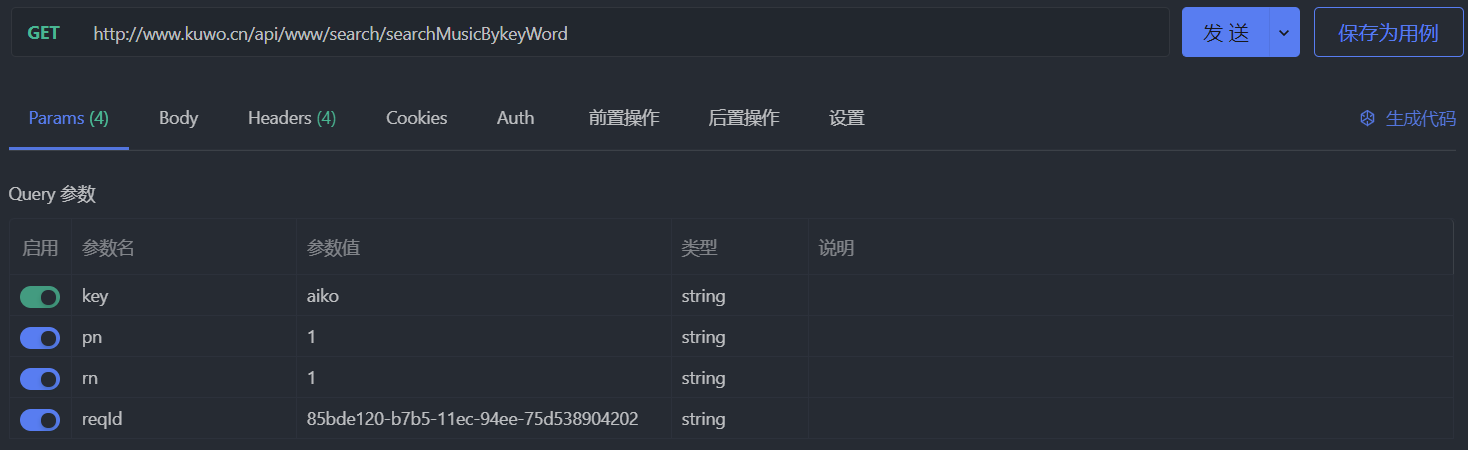
在沒有設置額外請求頭的情況下發個請求試試,發現 403 Forbidden 了,emmmmm,應該是防盜鏈所致:
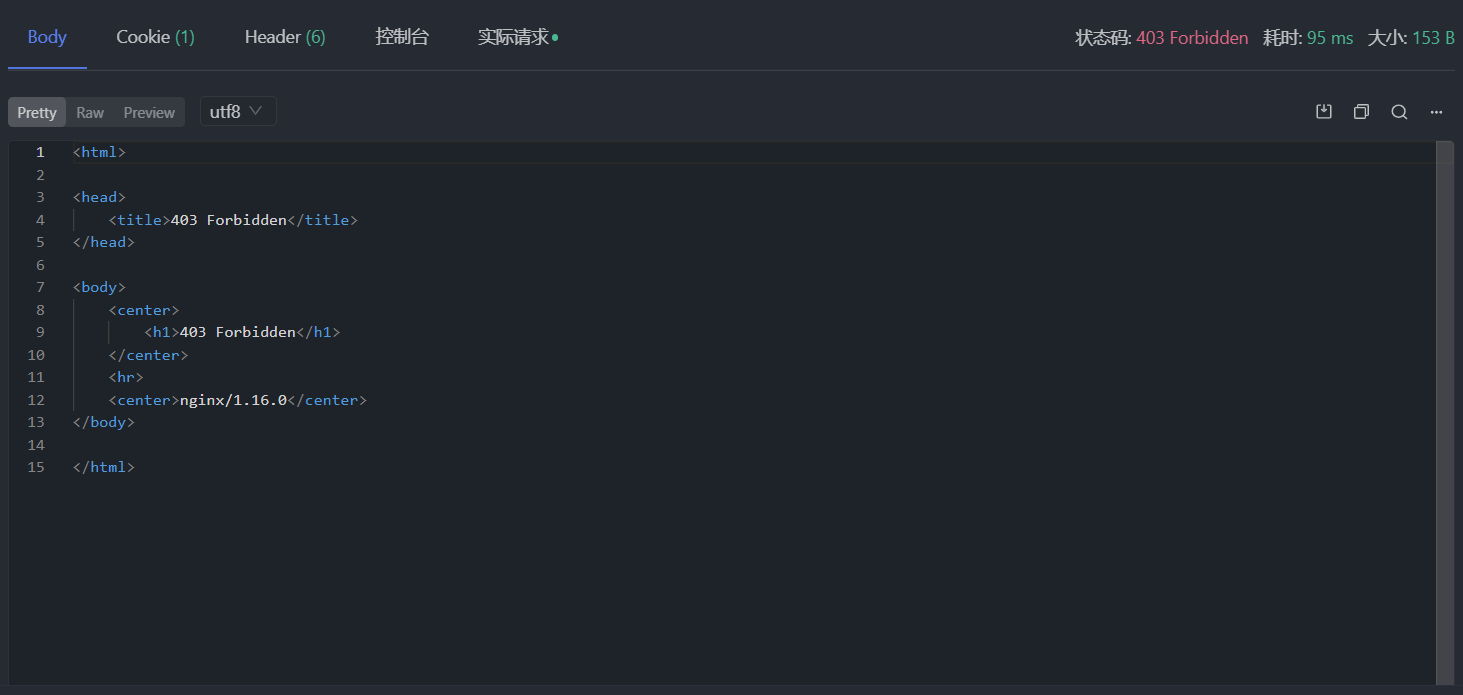
可以看到瀏覽器發出的請求的請求頭中有設置 Referer 字段,把它加上,應該不會再報錯了吧:
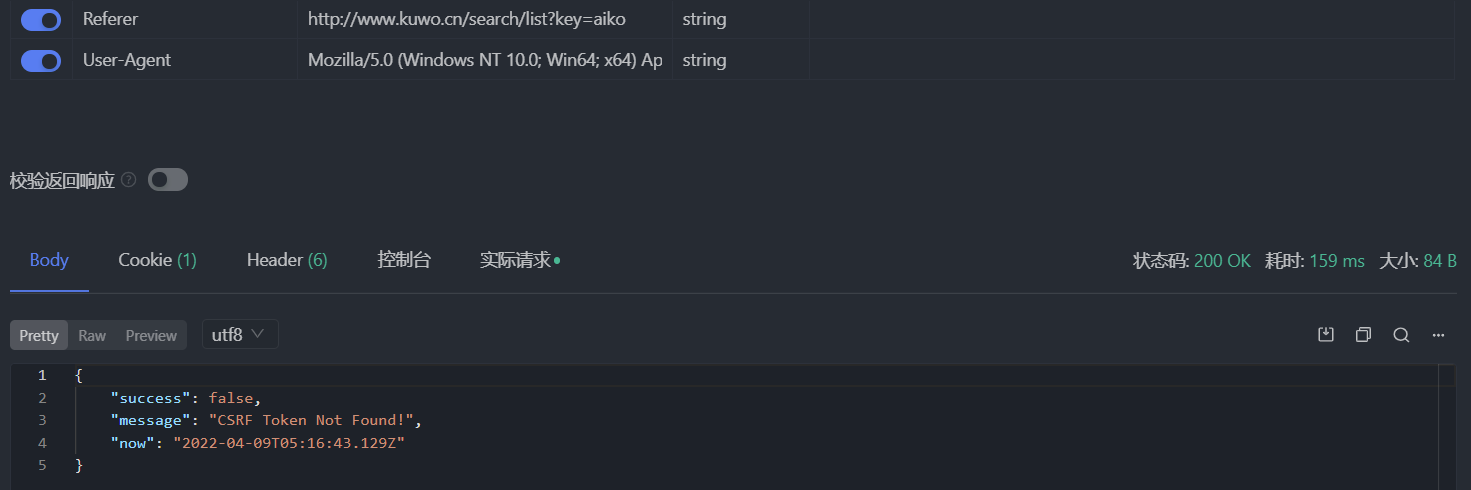
這次狀態碼為 200,但是沒有收到任何數據,success 為 false 說明請求失敗了,message 指明了失敗原因是缺少 CSRF token。問題不大,接着把瀏覽器發出的請求中的 csrf 加到 Apifox 請求頭中,再發請求,還是報錯 CSRF token Invalid!。算了,還是老老實實把 Cookie 也加上吧,但也不是全部加上,只加 kw_token=CCISYM2HV96 部分,因為 Cookie 裏面只有這個字段和 token 有關係且它的值和 csrf 相同。
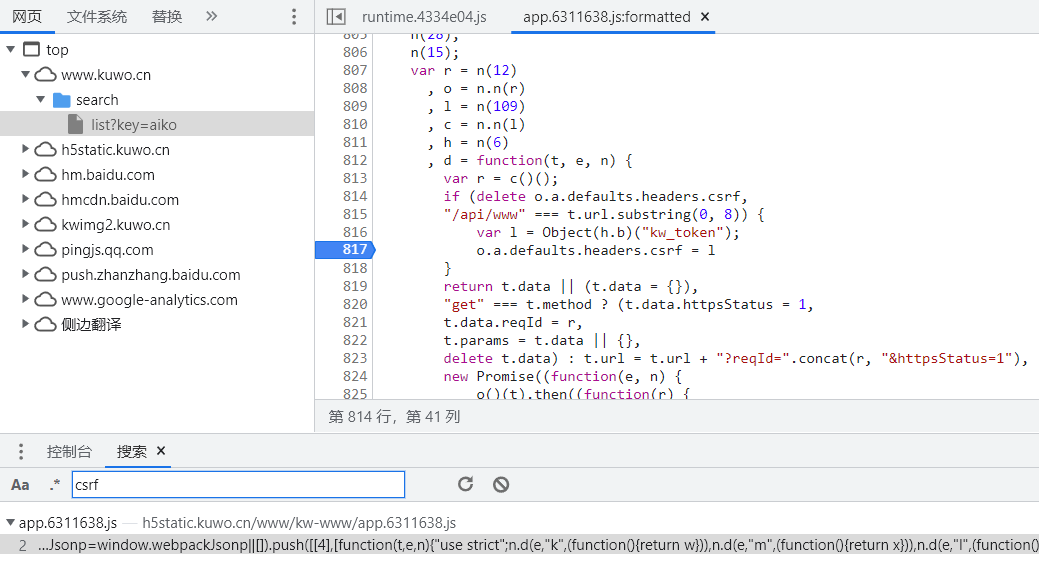
在源代碼面板按下 ctrl + shift + f,搜索一下 csrf,可以看到 csrf 本來就是來自 Object(h.b)("kw_token"),這個函數用來取出 document.cookie 中的 kw_token 字段值。至於 Cookie 中的 kw_token 怎麼計算得到的,那就是服務器的事情了,咱們只管 CV 操作即可。
準備好參數和請求頭,重新發送請求,可以得到想要的數據。如果去掉 reqId 參數,也可以拿到數據,但是會有略微的不同,這裡就不貼出來了:
{
"code": 200,
"curTime": 1649482287185,
"data": {
"total": "741",
"list": [
{
"musicrid": "MUSIC_11690555",
"barrage": "0",
"ad_type": "",
"artist": "aiko",
"mvpayinfo": {
"play": 0,
"vid": 8530326,
"down": 0
},
"nationid": "0",
"pic": "//img4.kuwo.cn/star/starheads/500/24/88/4146545084.jpg",
"isstar": 0,
"rid": 11690555,
"duration": 362,
"score100": "42",
"ad_subtype": "0",
"content_type": "0",
"track": 1,
"hasLossless": true,
"hasmv": 1,
"releaseDate": "1970-01-01",
"album": "",
"albumid": 0,
"pay": "16515324",
"artistid": 1907,
"albumpic": "//img4.kuwo.cn/star/starheads/500/24/88/4146545084.jpg",
"originalsongtype": 0,
"songTimeMinutes": "06:02",
"isListenFee": false,
"pic120": "//img4.kuwo.cn/star/starheads/120/24/88/4146545084.jpg",
"name": "戀をしたのは",
"online": 1,
"payInfo": {
"play": "1100",
"nplay": "00111",
"overseas_nplay": "11111",
"local_encrypt": "1",
"limitfree": 0,
"refrain_start": 89150,
"feeType": {
"song": "1",
"vip": "1"
},
"down": "1111",
"ndown": "11111",
"download": "1111",
"cannotDownload": 0,
"overseas_ndown": "11111",
"refrain_end": 126247,
"cannotOnlinePlay": 0
},
"tme_musician_adtype": "0"
}
]
},
"msg": "success",
"profileId": "site",
"reqId": "4b55cf4b0171253c33ce1d71b999c42f",
"tId": ""
}
請求代碼
響應結果的 data 字段中有很多東西,這裡只提取需要的部分。在提取之前先來定義一下歌曲信息實體類,這樣在其他函數中要一首歌曲的信息時只要把實體類的實例傳入即可。
# coding:utf-8
from copy import deepcopy
from dataclasses import dataclass
class Entity:
""" Entity abstract class """
def __setitem__(self, key, value):
self.__dict__[key] = value
def __getitem__(self, key):
return self.__dict__[key]
def get(self, key, default=None):
return self.__dict__.get(key, default)
def copy(self):
return deepcopy(self)
@dataclass
class SongInfo(Entity):
""" Song information """
file: str = None
title: str = None
singer: str = None
album: str = None
year: int = None
genre: str = None
duration: int = None
track: int = None
trackTotal: int = None
disc: int = None
discTotal: int = None
createTime: int = None
modifiedTime: int = None
上述代碼顯示定義了實體類的基類,並且重寫了 __getitem__ 和 __setitem__ 魔法方法,這樣我們可以像訪問字典一樣來訪問實體類對象的屬性。接着讓歌曲信息實體類繼承了實體類基類,並且使用 @dataclass 裝飾器,這是 python 3.7 引入的新特性,使用它裝飾之後的實體類無需實現構造函數、__str__等常用函數,python 會幫我們自動生成。
在發送請求的過程中可能會遇到各種異常,如果在代碼裏面寫 try except 語句會顯得很亂,這裡同樣可以用裝飾器來解決這個問題。
# coding:utf-8
from copy import deepcopy
def exceptionHandler(*default):
""" decorator for exception handling
Parameters
----------
*default:
the default value returned when an exception occurs
"""
def outer(func):
def inner(*args, **kwargs):
try:
return func(*args, **kwargs)
except BaseException as e:
print(e)
value = deepcopy(default)
if len(value) == 0:
return None
elif len(value) == 1:
return value[0]
else:
return value
return inner
return outer
下面是發送獲取歌曲信息請求的代碼,使用 exception_handler 裝飾了 getSongInfos 方法,這樣發生異常時會打印異常信息並返回默認值:
# coding:utf-8
import json
from urllib import parse
from typing import List, Tuple
import requests
class KuWoMusicCrawler:
""" Crawler of KuWo Music """
def __init__(self):
super().__init__()
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Cookie': 'kw_token=C713RK6IJ8J',
'csrf': 'C713RK6IJ8J',
'Host': 'www.kuwo.cn',
'Referer': ''
}
@exceptionHandler([], 0)
def getSongInfos(self, key_word: str, page_num=1, page_size=10) -> Tuple[List[SongInfo], int]:
key_word = parse.quote(key_word)
# configure request header
headers = self.headers.copy()
headers["Referer"] = '//www.kuwo.cn/search/list?key='+key_word
# send request for song information
url = f'//www.kuwo.cn/api/www/search/searchMusicBykeyWord?key={key_word}&pn={page_num}&rn={page_size}&reqId=c06e0e50-fe7c-11eb-9998-47e7e13a7206'
response = requests.get(url, headers=headers)
response.raise_for_status()
# parse the response data
song_infos = []
data = json.loads(response.text)['data']
for info in data['list']:
song_info = SongInfo()
song_info['rid'] = info['rid']
song_info.title = info['name']
song_info.singer = info['artist']
song_info.album = info['album']
song_info.year = info['releaseDate'].split('-')[0]
song_info.track = info['track']
song_info.trackTotal = info['track']
song_info.duration = info["duration"]
song_info.genre = 'Pop'
song_info['coverPath'] = info.get('albumpic', '')
song_infos.append(song_info)
return song_infos, int(data['total'])
獲取歌曲下載鏈接
免費歌曲
雖然我們實現了搜索歌曲的功能,但是沒拿到每一首歌的播放地址,也就沒辦法把歌曲下載下來。我們先來播放一首可以不收費、可以在線收聽的歌曲看看。可以看到瀏覽器發送了一個獲取播放鏈接的請求,路徑為 //www.kuwo.cn/api/v1/www/music/playUrl,有兩個需要關注的參數:
mid:音樂 Id,此處的值為941583,和頁面 url 中的編號一致,由於我們是通過點擊搜索結果頁面中二人跳轉過來的,而二人這條結果也是動態加載出來的,超鏈接中的 Id 肯定也來自於上一節中響應結果的某個字段。二人是第四條記錄,通過對比可以發現data.list[3].rid就是mid;type:音樂類型?此處的值為music,發送請求的時候也設置為music即可
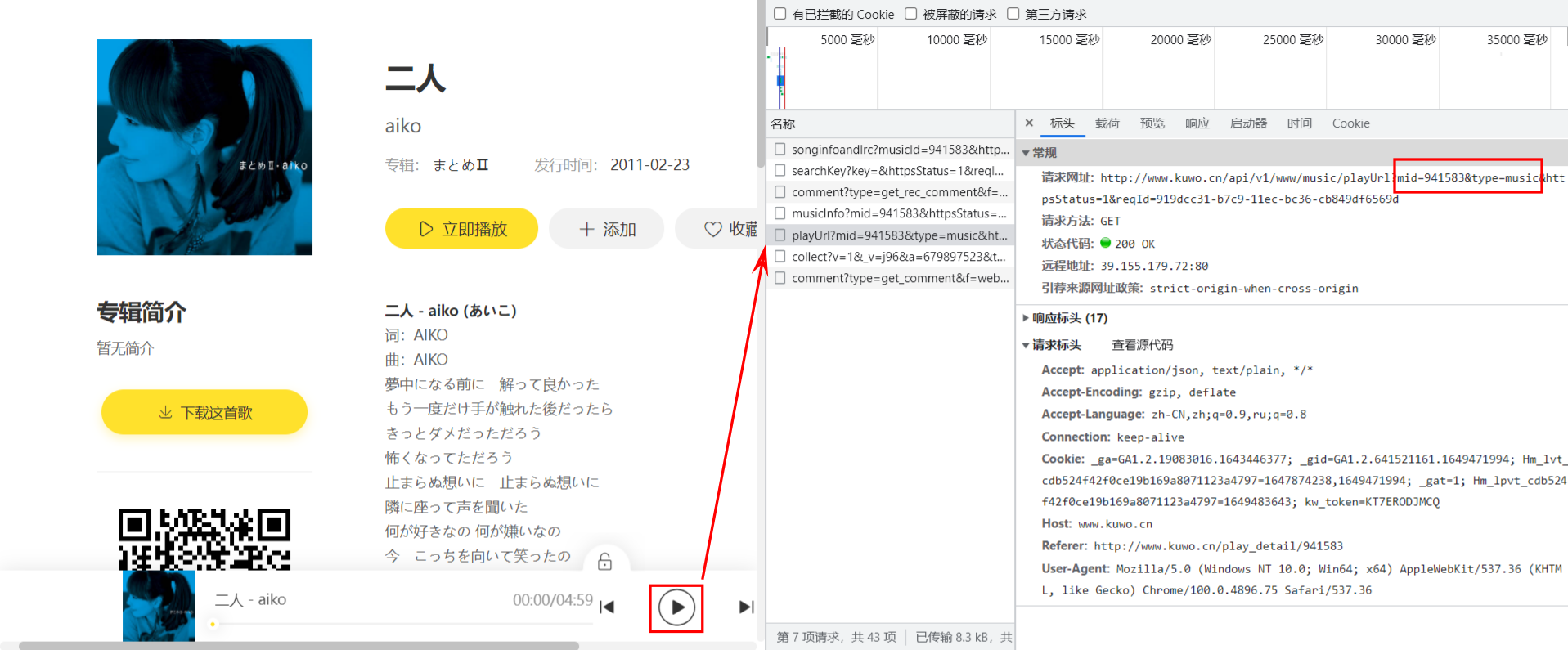
在 Apifox 中新建一個獲取歌曲播放地址的請求,如下所示,發現可以成功拿到播放地址:

付費歌曲
現在換一首歌,比如 aiko - 橫顏,點擊歌曲頁面上的播放按鈕時會彈出要求在客戶端中付費收聽的對話框。直接發送請求,響應結果會是下面這個樣子,狀態碼為 403:
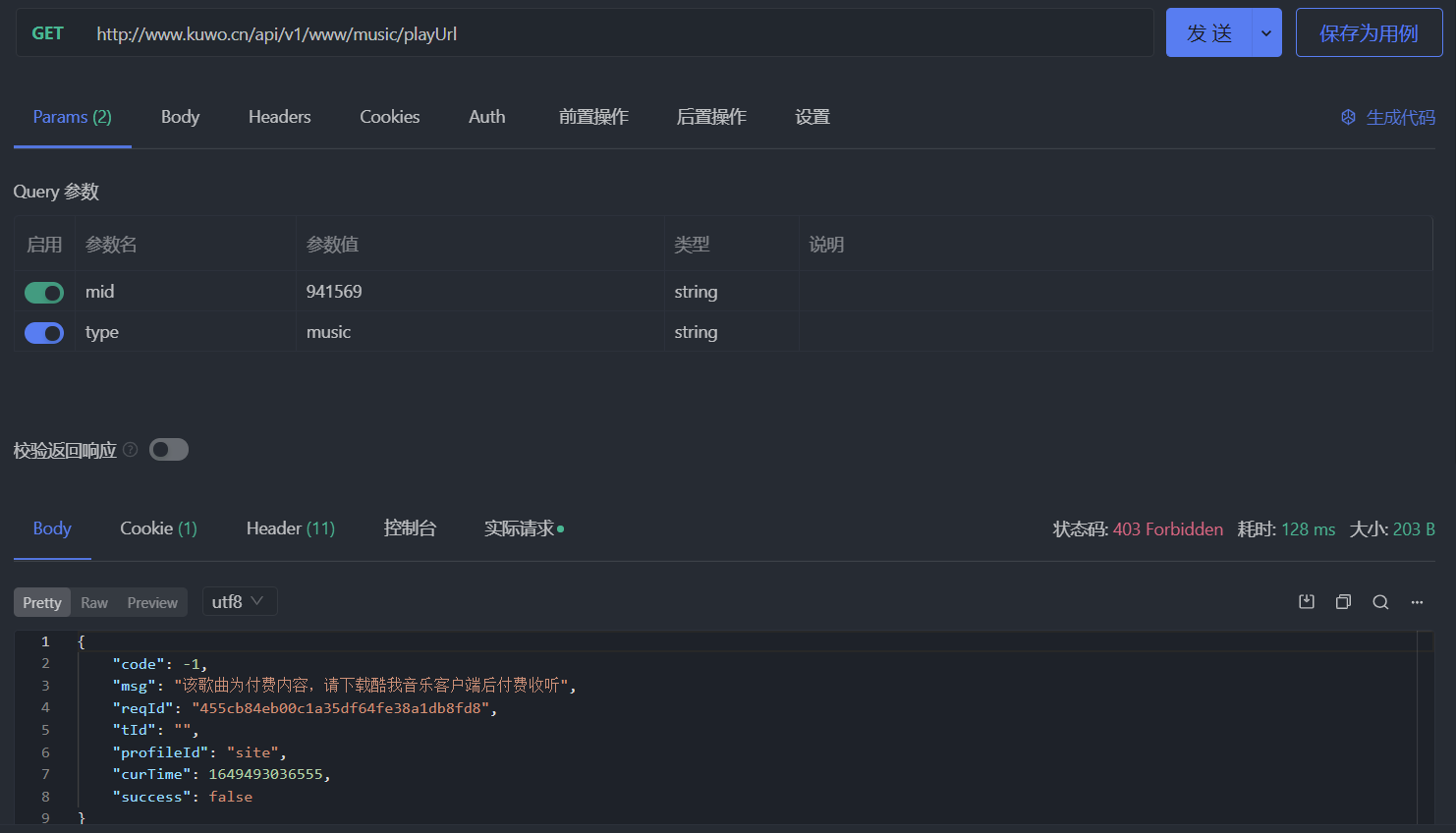
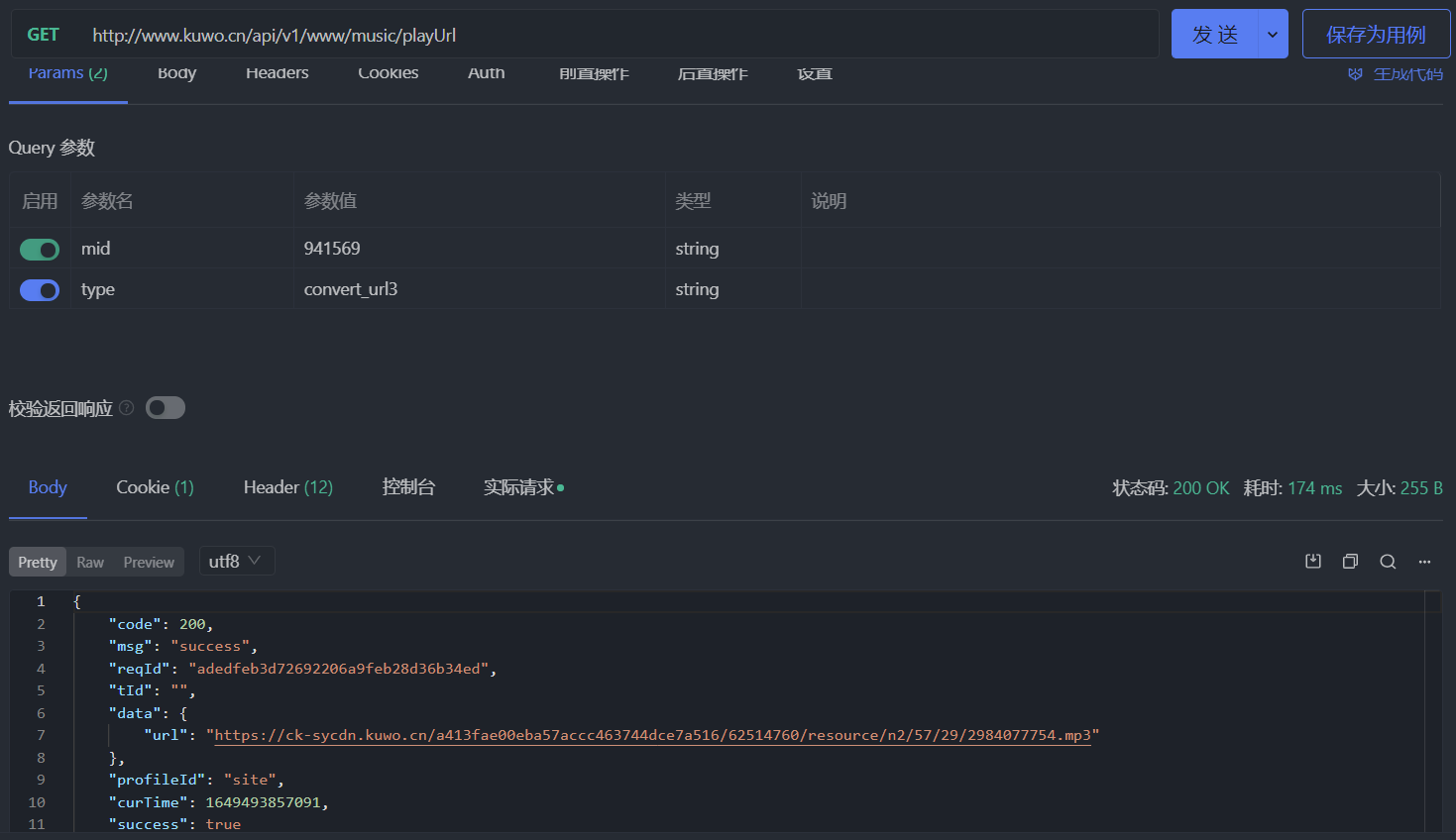
其實酷我在 2021 年 9 月份的時候換過獲取播放地址的接口,那時候的請求接口為 //www.kuwo.cn/url,支持以下幾個參數:
format: 在線音樂的格式,可以是mp3type: 和現在的接口中的type參數一樣,但是值為convert_url3rid: 音樂 Id,和mid一樣br: 在線音樂的比特率,越大則音質越高,可選的有128kmp3、192kmp3和320kmp3
這個接口不管是付費音樂還是免費音樂都可以用。如果將現在這個接口的 type 參數的值換成 convert_url3,請求結果如下所示,說明成功了:
請求代碼
下面是獲取在線音樂播放鏈接的代碼,只需調用 downloadSong 函數並把爬取到的歌曲傳入就能完成歌曲的下載:
@exceptionHandler('')
def getSongUrl(self, song_info: SongInfo) -> str:
# configure request header
headers = self.headers.copy()
headers.pop('Referer')
headers.pop('csrf')
# send request for play url
url = f"//www.kuwo.cn/api/v1/www/music/playUrl?mid={song_info['rid']}&type=convert_url3"
response = requests.get(url, headers=headers)
response.raise_for_status()
play_url = json.loads(response.text)['data']['url']
return play_url
@exceptionHandler('')
def downloadSong(self, song_info: SongInfo, save_dir: str) -> str:
# get play url
url = self.getSongUrl(song_info)
if not url:
return ''
# send request for binary data of audio
headers = self.headers.copy()
headers.pop('Referer')
headers.pop('csrf')
headers.pop('Host')
response = requests.get(url, headers=headers)
response.raise_for_status()
# save audio file
song_path = os.path.join(
save_dir, f"{song_info.singer} - {song_info.title}.mp3")
with open(song_path, 'wb') as f:
f.write(data)
return song
後記
除了獲取歌曲的詳細信息和播放地址外,我們還能拿到歌詞、歌手信息等,方法是類似的,在我的 Groove 中提供了在線歌曲的功能,一部分接口就是來自酷我,還有一些來自酷狗和網易雲,爬蟲的代碼在 app/common/crawler 目錄下,喜歡的話可以給個 star 哦,以上~~


