vivo 短視頻推薦去重服務的設計實踐
一、概述
1.1 業務背景
vivo短視頻在視頻推薦時需要對用戶已經看過的視頻進行過濾去重,避免給用戶重複推薦同一個視頻影響體驗。在一次推薦請求處理流程中,會基於用戶興趣進行視頻召回,大約召回2000~10000條不等的視頻,然後進行視頻去重,過濾用戶已經看過的視頻,僅保留用戶未觀看過的視頻進行排序,選取得分高的視頻下發給用戶。
1.2 當前現狀
當前推薦去重基於Redis Zset實現,服務端將播放埋點上報的視頻和下發給客戶端的視頻分別以不同的Key寫入Redis ZSet,推薦算法在視頻召回後直接讀取Redis里對應用戶的播放和下發記錄(整個ZSet),基於內存中的Set結構實現去重,即判斷當前召回視頻是否已存在下發或播放視頻Set中,大致的流程如圖1所示。
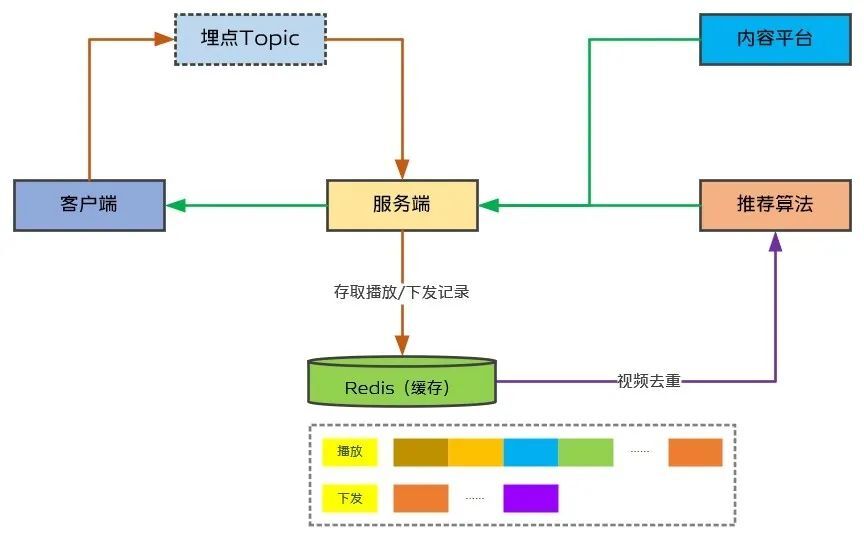
(圖1:短視頻去重當前現狀)
視頻去重本身是基於用戶實際觀看過的視頻進行過濾,但考慮到實際觀看的視頻是通過客戶端埋點上報,存在一定的時延,因此服務端會保存用戶最近100條下發記錄用於去重,這樣就保證了即使客戶端埋點還未上報上來,也不會給用戶推薦了已經看過的視頻(即重複推薦)。而下發給用戶的視頻並不一定會被曝光,因此僅保存100條,使得未被用戶觀看的視頻在100條下發記錄之後仍然可以繼續推薦。
當前方案主要問題是佔用Redis內存非常大,因為視頻ID是以原始字符串形式存在Redis Zset中,為了控制內存佔用並且保證讀寫性能,我們對每個用戶的播放記錄最大長度進行了限制,當前限制單用戶最大存儲長度為10000,但這會影響重度用戶產品體驗。
二、方案調研
2.1 主流方案
第一,存儲形式。視頻去重場景是典型的只需要判斷是否存在即可,因此並不需要把原始的視頻ID存儲下來,目前比較常用的方案是使用布隆過濾器存儲視頻的多個Hash值,可降低存儲空間數倍甚至十幾倍。
第二,存儲介質。如果要支持存儲90天(三個月)播放記錄,而不是當前粗暴地限制最大存儲10000條,那麼需要的Redis存儲容量非常大。比如,按照5000萬用戶,平均單用戶90天播放10000條視頻,每個視頻ID占內存25B,共計需要12.5TB。視頻去重最終會讀取到內存中完成,可以考慮犧牲一些讀取性能換取更大的存儲空間。而且,當前使用的Redis未進行持久化,如果出現Redis故障會造成數據丟失,且很難恢復(因數據量大,恢復時間會很長)。
目前業界比較常用的方案是使用磁盤KV(一般底層基於RocksDB實現持久化存儲,硬盤使用SSD),讀寫性能相比Redis稍遜色,但是相比內存而言,磁盤在容量上的優勢非常明顯。
2.2 技術選型
第一,播放記錄。因需要支持至少三個月的播放歷史記錄,因此選用布隆過濾器存儲用戶觀看過的視頻記錄,這樣相比存儲原始視頻ID,空間佔用上會極大壓縮。我們按照5000萬用戶來設計,如果使用Redis來存儲布隆過濾器形式的播放記錄,也將是TB級別以上的數據,考慮到我們最終在主機本地內存中執行過濾操作,因此可以接受稍微低一點的讀取性能,選用磁盤KV持久化存儲布隆過濾器形式的播放記錄。
第二,下發記錄。因只需存儲100條下發視頻記錄,整體的數據量不大,而且考慮到要對100條之前的數據淘汰,仍然使用Redis存儲最近100條的下發記錄。
三、方案設計
基於如上的技術選型,我們計劃新增統一去重服務來支持寫入下發和播放記錄、根據下發和播放記錄實現視頻去重等功能。其中,重點要考慮的就是接收到播放埋點以後將其存入布隆過濾器。在收到播放埋點以後,以布隆過濾器形式寫入磁盤KV需要經過三步,如圖2所示:第一,讀取並反序列化布隆過濾器,如布隆過濾器不存在則需創建布隆過濾器;第二,將播放視頻ID更新到布隆過濾器中;第三,將更新後的布隆過濾器序列化並回寫到磁盤KV中。
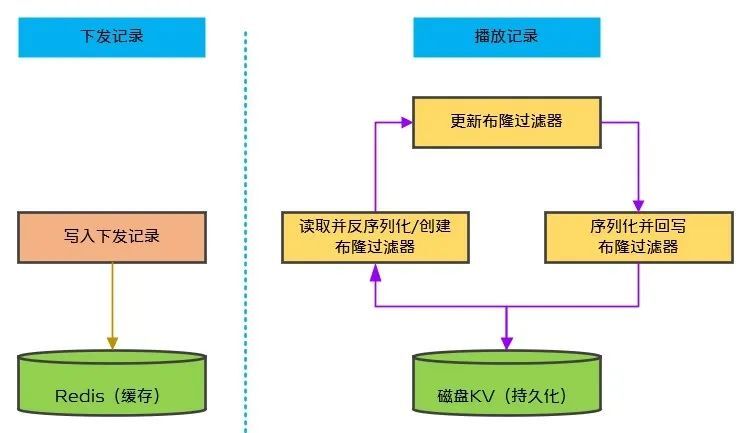
(圖2:統一去重服務主要步驟)
整個過程很清晰,但是考慮到需要支持千萬級用戶量,假設按照5000萬用戶目標設計,我們還需要考慮四個問題:
-
第一,視頻按刷次下發(一刷5~10條視頻),而播放埋點按照視頻粒度上報,那麼就視頻推薦消重而言,數據的寫入QPS比讀取更高,然而,相比Redis磁盤KV的性能要遜色,磁盤KV本身的寫性能比讀性能低,要支持5000萬用戶量級,那麼如何實現布隆過濾器寫入磁盤KV是一個要考慮的重要問題。
-
第二,由於布隆過濾器不支持刪除,超過一定時間的數據需要過期淘汰,否則不再使用的數據將會一直佔用存儲資源,那麼如何實現布隆過濾器過期淘汰也是一個要考慮的重要問題。
-
第三,服務端和算法當前直接通過Redis交互,我們希望構建統一去重服務,算法調用該服務來實現過濾已看視頻,而服務端基於Java技術棧,算法基於C++技術棧,那麼需要在Java技術棧中提供服務給C++技術棧調用。我們最終採用gRPC提供接口給算法調用,註冊中心採用了Consul,該部分非重點,就不詳細展開闡述。
-
第四,切換到新方案後我們希望將之前存儲在Redis ZSet中的播放記錄遷移到布隆過濾器,做到平滑升級以保證用戶體驗,那麼設計遷移方案也是要考慮的重要問題。
3.1 整體流程
統一去重服務的整體流程及其與上下游之間的交互如圖3所示。服務端在下發視頻的時候,將當次下發記錄通過統一去重服務的Dubbo接口保存到Redis下發記錄對應的Key下,使用Dubbo接口可以確保立即將下發記錄寫入。同時,監聽視頻播放埋點並將其以布隆過濾器形式存放到磁盤KV中,考慮到性能我們採用了批量寫入方案,具體下文詳述。統一去重服務提供RPC接口供推薦算法調用,實現對召回視頻過濾掉用戶已觀看的視頻。
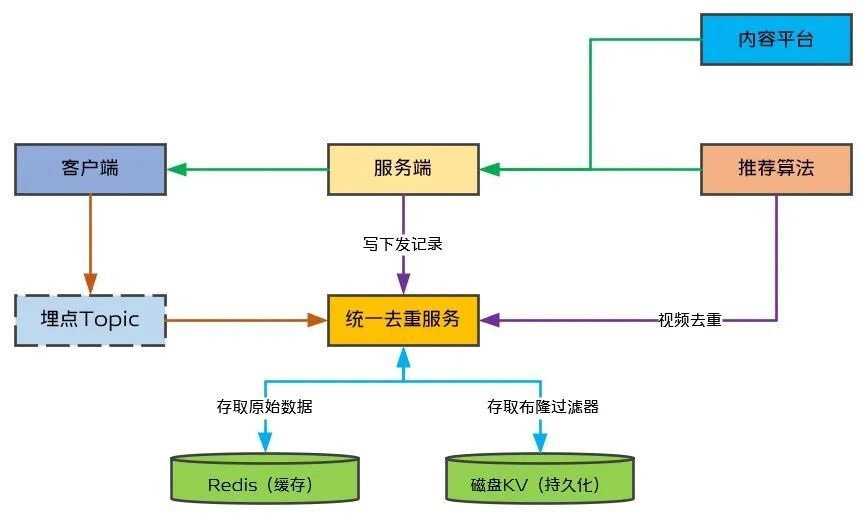
(圖3:統一去重服務整體流程)
磁盤KV寫性能相比讀性能差很多,尤其是在Value比較大的情況下寫QPS會更差,考慮日活千萬級情況下磁盤KV寫性能沒法滿足直接寫入要求,因此需要設計寫流量匯聚方案,即將一段時間以內同一個用戶的播放記錄匯聚起來一次寫入,這樣就大大降低寫入頻率,降低對磁盤KV的寫壓力。
3.2 流量匯聚
為了實現寫流量匯聚,我們需要將播放視頻先暫存在Redis匯聚起來,然後隔一段時間將暫存的視頻生成布隆過濾器寫入磁盤KV中保存,具體而言我們考慮過N分鐘僅寫入一次和定時任務批量寫入兩種方式。接下來詳細闡述我們在流量匯聚和布隆過濾器寫入方面的設計和考慮。
3.2.1 近實時寫入
監聽到客戶端上報的播放埋點後,原本應該直接將其更新到布隆過濾器並保存到磁盤KV,但是考慮到降低寫頻率,我們只能將播放的視頻ID先保存到Redis中,N分鐘內僅統一寫一次磁盤KV,這種方案姑且稱之為近實時寫入方案吧。
最樸素的想法是每次寫的時候,在Redis中保存一個Value,N分鐘以後失效,每次監聽到播放埋點以後判斷這個Value是否存在,如果存在則表示N分鐘內已經寫過一次磁盤KV本次不寫,否則執行寫磁盤KV操作。這樣的考慮主要是在數據產生時,先不要立即寫入,等N分鐘匯聚一小批流量之後再寫入。這個Value就像一把「鎖」,保護磁盤KV每隔N分鐘僅被寫入一次,如圖4所示,如果當前為已加鎖狀態,再進行加鎖會失敗,可保護在加鎖期間磁盤KV不被寫入。從埋點數據流來看,原本連續不斷的數據流,經過這把「鎖」就變成了每隔N分鐘一批的微批量數據,從而實現流量匯聚,並降低磁盤KV的寫壓力。
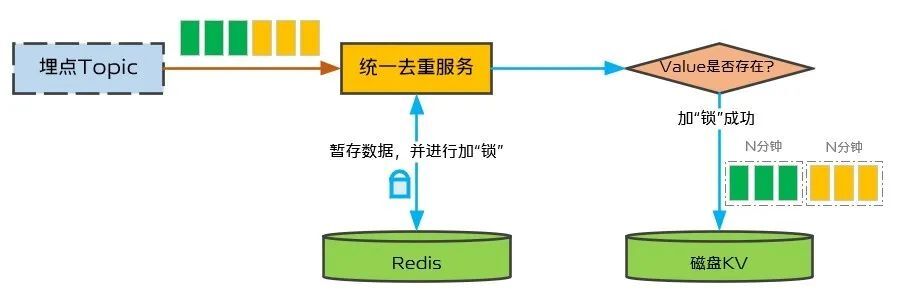
(圖4:近實時寫入方案)
近實時寫入的出發點很單純,優勢也很明顯,可以近實時地將播放埋點中的視頻ID寫入到布隆過濾器中,而且時間比較短(N分鐘),可以避免Redis Zset中暫存的數據過長。但是,仔細分析還需要考慮很多特殊的場景,主要如下:
第一,Redis中保存一個Value其實相當於一個分佈式鎖,實際上很難保證這把「鎖」是絕對安全的,因此可能會存在兩次收到播放埋點均認為可以進行磁盤KV寫操作,但這兩次讀到的暫存數據不一定一樣,由於磁盤KV不支持布隆過濾器結構,寫入操作需要先從磁盤KV中讀出當前的布隆過濾器,然後將需要寫入的視頻ID更新到該布隆過濾器,最後再寫回到磁盤KV,這樣的話,寫入磁盤KV後就有可能存在數據丟失。
第二,最後一個N分鐘的數據需要等到用戶下次再使用的時候才能通過播放埋點觸發寫入磁盤KV,如果有大量不活躍的用戶,那麼就會存在大量暫存數據遺留在Redis中佔用空間。此時,如果再採用定時任務來將這部分數據寫入到磁盤KV,那麼也會很容易出現第一種場景中的並發寫數據丟失問題。
如此看來,近實時寫入方案雖然出發點很直接,但是仔細想來,越來越複雜,只能另尋其他方案。
3.2.2 批量寫入
既然近實時寫入方案複雜,那不妨考慮簡單的方案,通過定時任務批量將暫存的數據寫入到磁盤KV中。我們將待寫的數據標記出來,假設我們每小時寫入一次,那麼我們就可以把暫存數據以小時值標記。但是,考慮到定時任務難免可能會執行失敗,我們需要有補償措施,常見的方案是每次執行任務的時候,都在往前多1~2個小時的數據上執行任務,以作補償。但是,明顯這樣的方案並不夠優雅,我們從時間輪得到啟發,並基於此設計了布隆過濾器批量寫入的方案。
我們將小時值首尾相連,從而得到一個環,並且將對應的數據存在該小時值標識的地方,那麼同一小時值(比如每天11點)的數據是存在一起的,如果今天的數據因任務未執行或執行失敗未同步到磁盤KV,那麼在第二天將會得到一次補償。
順着這個思路,我們可以將小時值對某個值取模以進一步縮短兩次補償的時間間隔,比如圖5所示對8取模,可見1:002:00和9:0010:00的數據都會落在圖中時間環上的點1標識的待寫入數據,過8個小時將會得到一次補償的機會,也就是說這個取模的值就是補償的時間間隔。
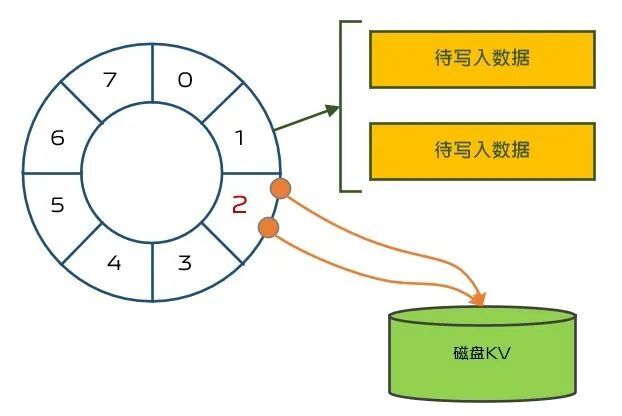
(圖5:批量寫入方案)
那麼,我們應該將補償時間間隔設置為多少呢?這是一個值得思考的問題,這個值的選取會影響到待寫入數據在環上的分佈。我們的業務一般都會有忙時、閑時,忙時的數據量會更大,根據短視頻忙閑時特點,最終我們將補償間隔設置為6,這樣業務忙時比較均勻地落在環上的各個點。
確定了補償時間間隔以後,我們覺得6個小時補償還是太長了,因為用戶在6個小時內有可能會看過大量的視頻,如果不及時將數據同步到磁盤KV,會佔用大量Redis內存,而且我們使用Redis ZSet暫存用戶播放記錄,過長的話會嚴重影響性能。於是,我們設計每個小時增加一次定時任務,第二次任務對第一次任務補償,如果第二次任務仍然沒有補償成功,那麼經過一圈以後,還可以得到再次補償(兜底)。
細心一點應該會發現在圖5中的「待寫入數據」和定時任務並不是分佈在環上的同一個點的,我們這樣設計的考慮是希望方案更簡單,定時任務只會去操作已經不再變化的數據,這樣就能避免並發操作問題。就像Java虛擬機中垃圾回收一樣,我們不能一邊回收垃圾,一邊卻還在同一間屋子裡扔着垃圾。所以,設計成環上節點對應定時任務只去處理前一個節點上的數據,以確保不會產生並發衝突,使方案保持簡單。
批量寫入方案簡單且不存在並發問題,但是在Redis Zset需要保存一個小時的數據,可能會超過最大長度,但是考慮到現實中一般用戶一小時內不會播放非常大量的視頻,這一點是可以接受的。最終,我們選擇了批量寫入方案,其簡單、優雅、高效,在此基礎上,我們需要繼續設計暫存大量用戶的播放視頻ID方案。
3.3 數據分片
為了支持5000萬日活量級,我們需要為定時批量寫入方案設計對應的數據存儲分片方式。首先,我們依然需要將播放視頻列表存放在Redis Zset,因為在沒寫入布隆過濾器之前,我們需要用這份數據過濾用戶已觀看過的視頻。正如前文提到過,我們會暫存一個小時的數據,正常一個用戶一個小時內不會播放超過一萬條數據的,所以一般來說是沒有問題的。除了視頻ID本身以外,我們還需要保存這個小時到底有哪些用戶產生過播放數據,否則定時任務不知道要將哪些用戶的播放記錄寫入布隆過濾器,存儲5000萬用戶的話就需要進行數據分片。
結合批量同步部分介紹的時間環,我們設計了如圖6所示的數據分片方案,將5000萬的用戶Hash到5000個Set中,這樣每個Set最多保存1萬個用戶ID,不至於影響Set的性能。同時,時間環上的每個節點都按照這個的分片方式保存數據,將其展開就如同圖6下半部分所示,以played:user:${時間節點編號}😒{用戶Hash值}為Key保存某個時間節點某個分片下所有產生了播放數據的用戶ID。
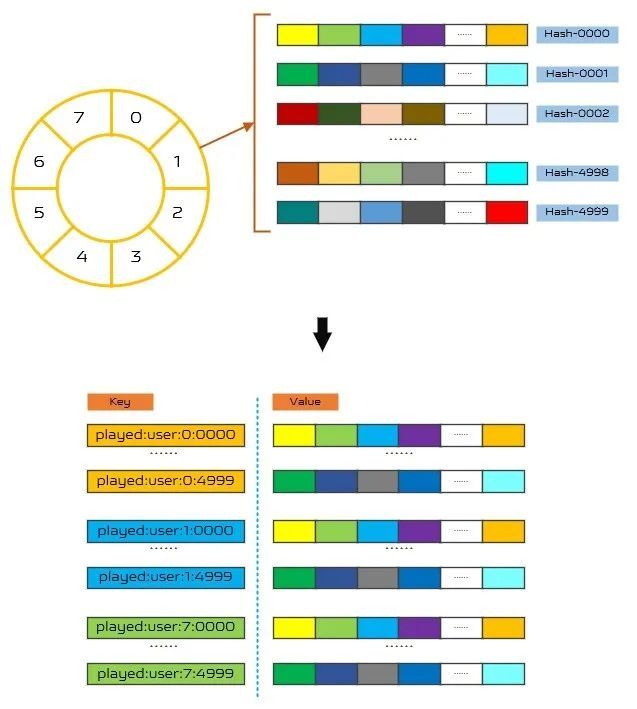
(圖6:數據分片方案)
對應地,我們的定時任務也要進行分片,每個任務分片負責處理一定數目的數據分片。否則,如果兩者一一對應的話,將分佈式定時任務分成5000個分片,雖然對於失敗重試是更好的,但是對於任務調度來說會存在壓力,實際上公司的定時任務也不支持5000分分片。我們將定時任務分為了50個分片,任務分片0負責處理數據分片0100,任務分片1負責處理數據分片100199,以此類推。
3.4 數據淘汰
對於短視頻推薦去重業務場景,我們一般保證讓用戶在看過某條視頻後三個月內不會再向該用戶推薦這條視頻,因此就涉及到過期數據淘汰問題。布隆過濾器不支持刪除操作,因此我們將用戶的播放歷史記錄添加到布隆過濾器以後,按月存儲並設置相應的過期時間,如圖7所示,目前過期時間設置為6個月。在數據讀取的時候,根據當前時間選擇讀取最近4個月數據用於去重。之所以需要讀取4個月的數據,是因為當月數據未滿一個月,為了保證三個月內不會再向用戶重複推薦,需要讀取三個完整月和當月數據。
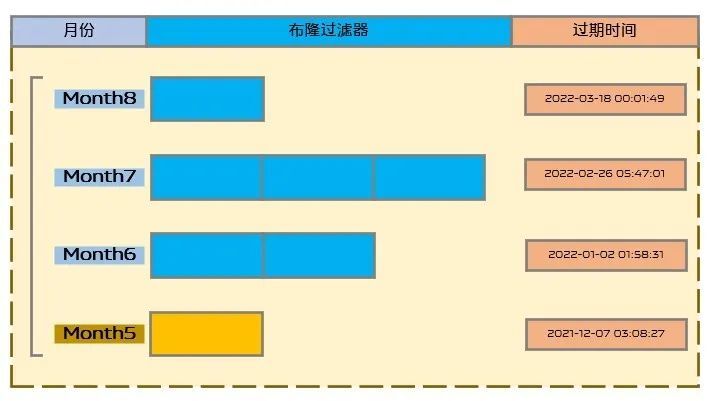
(圖7:數據淘汰方案)
對於數據過期時間的設置我們也進行了精心考慮,數據按月存儲,因此新數據產生時間一般在月初,如果僅將過期時間設置為6個月以後,那麼會造成月初不僅產生大量新數據,也需要淘汰大量老數據,對數據庫系統造成壓力。所以,我們將過期時間進行了打散,首先隨機到6個月後的那個月任意一天,其次我們將過期時間設置在業務閑時,比如:00:00~05:00,以此來降低數據庫清理時對系統的壓力。
3.5 方案小結
通過綜合上述流量匯聚、數據分片和數據淘汰三部分設計方案,整體的設計方案如圖8所示,從左至右播放埋點數據依次從數據源Kafka流向Redis暫存,最終流向磁盤KV持久化。
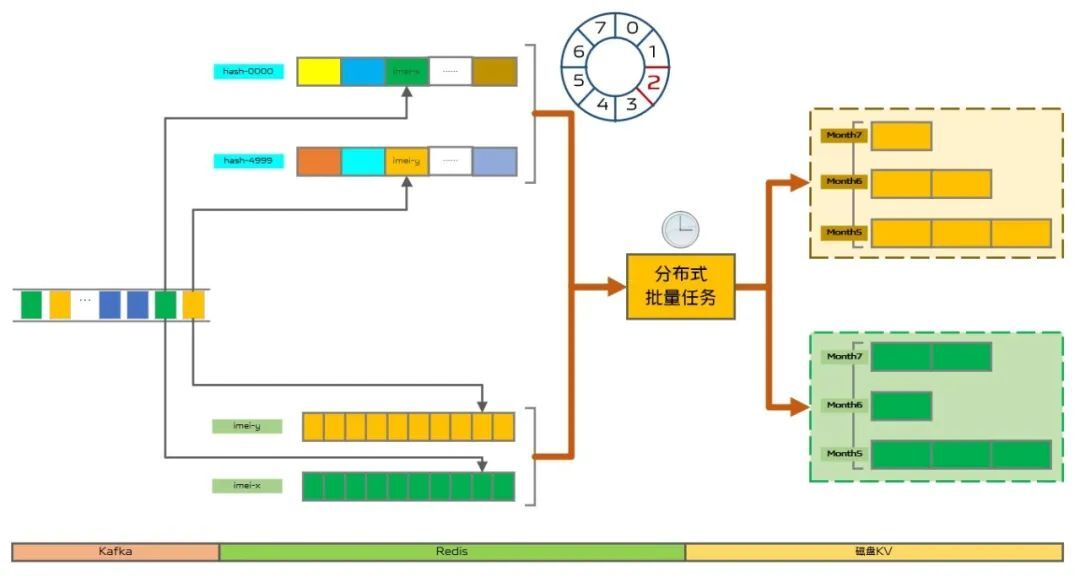
(圖8:整體方案流程)
首先,從Kafka播放埋點監聽到數據以後,我們根據用戶ID將該條視頻追加到用戶對應的播放歷史中暫存,同時根據當前時間和用戶ID的Hash值確定對應時間環,並將用戶ID保存到該時間環對應的用戶列表中。然後,每個分佈式定時任務分片去獲取上一個時間環的播放用戶數據分片,再獲取用戶的播放記錄更新到讀出的布隆過濾器,最後將布隆顧慮其序列化後寫入磁盤KV中。
四、數據遷移
為了實現從當前基於Redis ZSet去重平滑遷移到基於布隆過濾器去重,我們需要將統一去重服務上線前用戶產生的播放記錄遷移過來,以保證用戶體驗不受影響,我們設計和嘗試了兩種方案,經過對比和改進形成了最終方案。
我們已經實現了批量將播放記錄原始數據生成布隆過濾器存儲到磁盤KV中,因此,遷移方案只需要考慮將存儲在原來Redis中的歷史數據(去重服務上線前產生)遷移到新的Redis中即可,接下來就交由定時任務完成即可,方案如圖9所示。用戶在統一去重服務上線後新產生的增量數據通過監聽播放埋點寫入,新老數據雙寫,以便需要時可以降級。
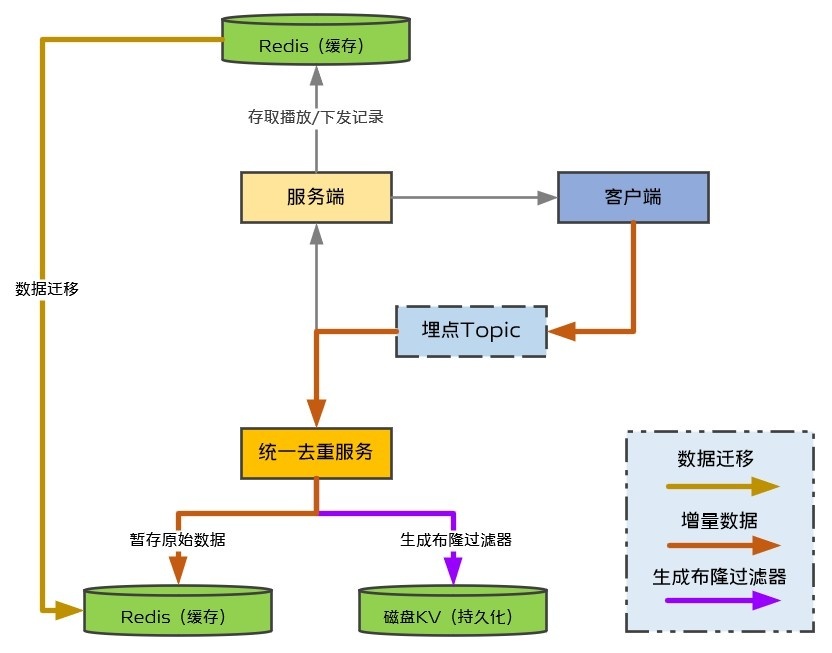
(圖9:遷移方案一)
但是,我們忽略了兩個問題:第一,新的Redis僅用作暫存,因此比老的Redis容量小很多,沒法一次性將數據遷移過去,需要分多批遷移;第二,遷移到新的Redis後的存儲格式和老的Redis不一樣,除了播放視頻列表,還需要播放用戶列表,諮詢DBA得知這樣遷移比較難實現。
既然遷移數據比較麻煩,我們就考慮能不能不遷移數據呢,在去重的時候判斷該用戶是否已遷移,如未遷移則同時讀取一份老數據一起用於去重過濾,並觸發將該用戶的老數據遷移到新Redis(含寫入播放用戶列表),三個月以後,老數據已可過期淘汰,此時就完成了數據遷移,如圖10所示。這個遷移方案解決了新老Redis數據格式不一致遷移難的問題,而且是用戶請求時觸發遷移,也避免了一次性遷移數據對新Redis容量要求,同時還可以做到精確遷移,僅遷移了三個月內需要遷移數據的用戶。
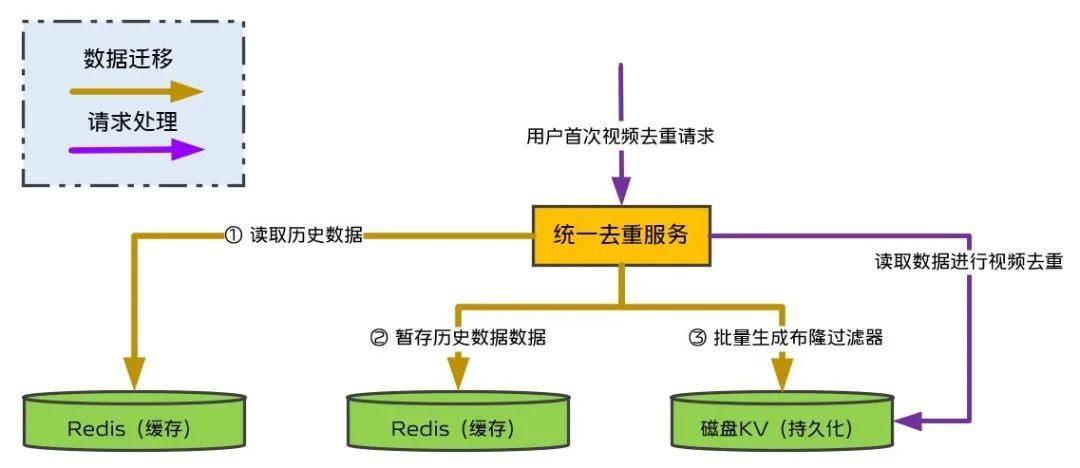
(圖10:遷移方案二)
於是,我們按照方案二進行了數據遷移,在上線測試的時候,發現由於用戶首次請求的時候需要去遷移老的數據,造成去重接口耗時不穩定,而視頻去重作為視頻推薦重要環節,對於耗時比較敏感,所以就不得不繼續思考新的遷移方案。我們注意到,在定時批量生成布隆過濾器的時候,讀取到時間環對應的播放用戶列表後,根據用戶ID獲取播放視頻列表,然後生成布隆過濾器保存到磁盤KV,此時,我們只需要增加一個從老Redis讀取用戶的歷史播放記錄即可把歷史數據遷移過來。為了觸發將某個用戶的播放記錄生成布隆過濾器的過程,我們需要將用戶ID保存到時間環上對應的播放用戶列表,最終方案如圖11所示。
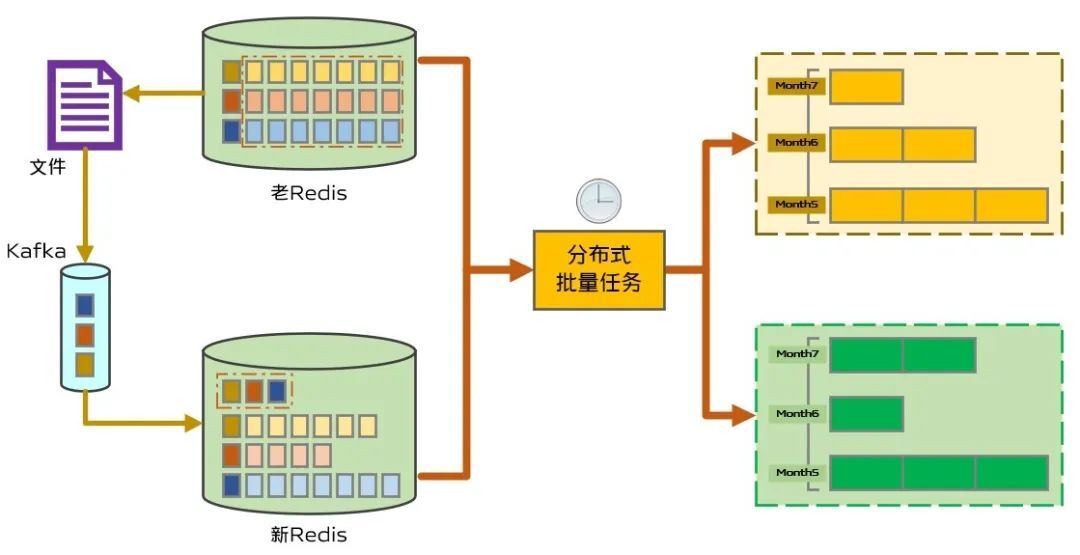
(圖11:最終遷移方案)
首先,DBA幫助我們把老Redis中播放記錄的Key(含有用戶ID)都掃描出來,通過文件導出;然後,我們通過大數據平台將導出的文件導入到Kafka,啟用消費者監聽並消費文件中的數據,解析後將其寫入到當前時間環對應的播放用戶列表。接下來,分佈式批量任務在讀取到播放用戶列表中的某個用戶後,如果該用戶未遷移數據,則從老Redis讀取歷史播放記錄,並和新的播放記錄一起更新到布隆過濾器並存入磁盤KV。
五、小結
本文主要介紹短視頻基於布隆過濾器構建推薦去重服務的設計與思考,從問題出發逐步設計和優化方案,力求簡單、完美、優雅,希望能對讀者有參考和借鑒價值。由於文章篇幅有限,有些方面未涉及,也有很多技術細節未詳細闡述,如有疑問歡迎繼續交流。
作者:vivo互聯網服務器團隊-Zhang Wei


