基礎數論學習筆記
CHANGE LOG
- 2021.12.6. 重構文章,刪去線性篩部分,修改部分表述。
- 2022.3.15 二次重構文章。
- 2022.3.23 三次重構文章。
- 2022.3.24 重構完成,新增威爾遜定理,素數在階乘和組合數中的冪次,階與原根,高次剩餘和盧卡斯定理。
0. 前置知識
0.1 基本定義與記號
Abstractness is the price of generality.
讀者需要知道一些數論相關的基本概念,如同餘符號 \(\equiv\) 及其含義,最大公約數 \(\gcd\),並掌握基本數論算法如快速冪,輾轉相除法求解 \(\gcd\)。
- 整除:若非零整數 \(a\) 是整數 \(b\) 的因數即 \(b \bmod a = 0\),則稱 \(a\) 整除 \(b\) 或 \(b\) 被 \(a\) 整除,記作 \(a\mid b\)。若反之則稱 \(a\) 不能整除 \(b\) 或 \(b\) 不能被 \(a\) 整除,記作 \(a\nmid b\)。
- 同餘:\(a\equiv b\pmod p\) 表示整數 \(a\) 和 \(b\) 模正整數 \(p\) 的餘數相等。
- 最大公約數:整數 \(a\) 和 \(b\) 的最大公約數是最大的整數 \(d\) 使得 \(d\) 整除 \(a\) 且 \(d\) 整除 \(b\),記作 \(\gcd(a, b)\)。\(\gcd(a, b)\) 在不引起歧義的前提下有時會簡寫為 \((a, b)\)。
- 互質:若整數 \(a, b\) 滿足 \(\gcd(a, b) = 1\),則稱 \(a, b\) 互質,記作 \(a\perp b\)。一般 \(a, b\) 均為非負整數。注意,\(\gcd(0, i) = i(i \geq 0)\),\(1\) 和任何整數互質。
- \(\mathbb P\) 表示素數集。
- 剩餘類:模 \(n\) 同餘的所有數構成的等價類被稱為模 \(n\) 的剩餘類。它們等價,因為我們在模 \(n\) 意義下討論它們。模 \(n\) 余 \(i\) 的剩餘類記作 \(K_i\)。容易發現模 \(n\) 的剩餘類共 \(n\) 個。
- 完全剩餘系:從 \(n\) 個模 \(n\) 剩餘類中各選一個數 \(a_0, a_1, \cdots, a_{n – 1}\),它們構成模 \(n\) 的完全剩餘系。
- 簡化剩餘系:從與 \(n\) 互質的剩餘類中各選一個數 \(a_1, a_2, \cdots, a_k\),它們構成模 \(n\) 的簡化剩餘系。讀者在接下來的章節中將了解到,\(k\) 等於 \(\varphi(n)\)。簡化剩餘系又稱為 既約剩餘系 或 縮系。
- 乘法逆元:若 \(ax \equiv 1 \pmod p\),則稱 \(x\) 為 \(a\) 在模 \(p\) 意義下的乘法逆元,記作 \(a ^ {-1}\)。
- 質因子次數:\(n\) 當中質因子 \(p\) 的次數記作 \(v_p(n)\)。即 \(p ^ {v_p(n)} \mid n\) 且 \(p ^ {v_p(n) + 1} \nmid n\)。嚴格意義上應記為 \(\nu_p(n)\)(希臘字母 nu)。為方便,本文暫記為 \(v_p(n)\)。
- 各位數字之和:\(n\) 在 \(p\) 進制下的各位數字之和記作 \(s_p(n)\)。
0.2 費馬小定理
當 \(p\) 是質數時,其因子只有 \(1\) 和 \(p\) 兩個。因此,若兩個數相乘是 \(p\) 的倍數,其中必然至少有一個是 \(p\) 的倍數。
當 \(a\) 不是 \(p\) 的倍數時,不存在 \(x \neq y\) 且 \(1 \leq x, y < p\) 使得 \(xa \equiv ya\pmod p\),因為這需要 \(x – y\) 是 \(p\) 的倍數,與 \(1\leq x, y< p\) 的限制矛盾。
考慮 \(1\sim p – 1\) 的所有數,它們乘以 \(a\) 之後在模 \(p\) 意義下互不相同,說明仍然得到 \(1\sim p – 1\) 的所有數。
因此,\(\prod\limits_{i = 1} ^ {p – 1} i \equiv \prod\limits_{i = 1} ^ {p – 1} ai \pmod p\),即
\]
上述結論稱為 費馬小定理。根據推導過程,它適用於 \(p\) 是質數且 \(a\) 不是 \(p\) 的倍數的情形。
0.3 模意義下乘法逆元
根據費馬小定理,當 \(p\) 為質數時,
\]
據此可快速冪求出一個數在模質數意義下的乘法逆元。
當 \(p\) 非質數時,\(a\) 有乘法逆元的充要條件為 \(a \perp p\)。我們將在第一章展開討論。
給出一些模 質數 \(p\) 意義下求乘法逆元的常見技巧。
-
線性求逆元:考慮 增量法。假設 \(1\sim i-1\) 的逆元已知。設 \(p = ki + r(0\leq r < i)\),即 \(k\) 和 \(r\) 分別是 \(p\) 對 \(i\) 做帶余除法的商和餘數。因為 \(ki + r \equiv 0 \pmod p\),兩邊同時除以 \(ir\),得 \(i ^ {-1} \equiv -kr ^ {-1}\equiv -\left\lfloor \dfrac p i \right\rfloor (p\bmod i) ^ {-1}\)。時間複雜度線性。
-
線性求任意 \(n\) 個數 \(a_i(1 \leq a_i < p)\) 的逆元:設 \(s\) 為 \(a\) 的前綴積。算出 \(s_n ^ {-1}\) 後通過 \(s_i ^ {-1} = s_{i + 1} ^ {-1} \times a_{i + 1}\) 得到前綴積的逆元,則 \(a_i^{-1}=s_{i-1}\times s_i^{-1}\)。時間複雜度 \(\mathcal{O}(n+\log p)\)。
0.4 威爾遜定理
由於乘法逆元成對出現,這啟發我們思考,\(1\sim p – 1\) 所有數能否兩兩配對互為逆元?若可以,那麼說明當 \(p\) 是質數時,\((p – 1)! \equiv 1\pmod p\)。
可以,但不完全可以,因為 \(1\) 和 \(-1\) 的逆元均為它本身,且僅有這兩個數滿足 \(x ^ 2\equiv 1\pmod p\)。這符合我們的直觀認知,畢竟在實數域下 \(x ^ 2 = 1\) 有且僅有解 \(\pm 1\)。
證明:求解方程 \(x ^ 2\equiv 1\pmod p\)。移項,使用平方差公式,\((x – 1)(x + 1) \equiv 0\pmod p\)。顯然,為使等式左端等於 \(0\),必然有 \(x \equiv \pm 1\pmod p\)。證畢。
因此,我們需要對結論進行一些修正,即當 \(p\) 是質數時,\((p – 1) ! \equiv 1 \times (p – 1) \equiv -1\pmod p\)。特殊考慮 \(p = 2\),發現符合該結論。
既然有了充分條件,我們自然會考慮 \(p\) 不是質數的情況。
-
當 \(p\) 為完全平方數 \(q ^ 2\) 時,考慮 \(q\) 和 \(2q\)。它們相乘後模 \(p\) 等於 \(0\)。因此,若 \(2q < p\) 即 \(p\) 為大於 \(4\) 的完全平方數時,\((p – 1)!\equiv 0\)。
-
當 \(p = 4\) 時,\(3 ! \equiv 2\pmod 4\)。
-
當 \(p\) 為大於 \(4\) 的非完全平方數時,令 \(q\) 為 \(p\) 的最小質因子,則 \(q \neq \dfrac p q\),故 \((p – 1)!\equiv 0\pmod p\)。
綜上,我們得到了 威爾遜定理:\((p – 1)!\equiv 1\pmod p\) 與 \(p\) 是質數等價。
我們嘗試將威爾遜定理擴展至素數的冪的情形,即考慮 \(p ^ k\) 以內所有與 \(p\) 互質的數的乘積模 \(p ^ k\),記為 \((p ^ k!)_p\)。
仍然考慮求解 \(x ^ 2 \equiv 1\pmod {p ^ k}\) 即求出逆元為本身的數,並將非 \(x\) 的其它所有數與其逆元兩兩配對(因為我們只考慮與 \(p\) 互質的數,所以其在模 \(p ^ k\) 意義下顯然存在逆元),這說明我們只需考慮所有 \(x\) 的乘積。
因式分解得到 \((x + 1)(x – 1)\equiv 0\pmod {p ^ k}\)。
注意到當 \(p > 2\) 時,\(x + 1\) 和 \(x – 1\) 不可能均是 \(p\) 的倍數,因此必然有 \(x + 1\equiv 0\pmod {p ^ k}\) 或 \(x – 1\equiv 0\pmod {p ^ k}\)。這和一般情況等價,因此仍然有 \((p ^ k!)_p\equiv -1\pmod {p ^ k}\)。
當 \(p = 2\) 時,\(x + 1\) 和 \(x – 1\) 可能同時為 \(2\) 的倍數,但不可能同時為 \(4\) 的倍數。因此,若 \(x + 1\) 和 \(x – 1\) 同時為 \(2\) 的倍數,除掉不能被 \(4\) 整除的那個數的質因子,得到 \(x + 1\equiv 0\pmod {2 ^ {k – 1}}\) 或 \(x – 1\equiv 0\pmod {2 ^ {k – 1}}\)。這說明當 \(p = 2\) 時方程有四個解 \(\pm 1\) 和 \(2 ^ {k – 1}\pm 1\)。注意,當 \(k = 1\) 時四個根均重合,此時 \(1!\equiv 1\equiv -1\pmod 2\);當 \(k = 2\) 時兩對根重合,此時 \(1\times 3\equiv -1\pmod 4\)。否則 \(1\times (-1) \times (2 ^ {k – 1} + 1) \times (2 ^ {k – 1} – 1)\equiv 1\pmod {2 ^ k}\)。
綜合上述兩種情況,我們得到如下推論
\]
在 exLucas 中用到了該結論。
0.5 素數在階乘中的冪次
給定正整數 \(n\) 和質數 \(p\),求 \(v_p(n!)\)。
我們考慮將 \(1\sim n\) 當中所有 \(p\) 的倍數提出來,然後全部除以 \(p\)。這一步消掉的質因子個數為 \(\left\lfloor \dfrac n p \right\rfloor\),因為 \(1\sim n\) 當中 \(p\) 的倍數有 \(\left\lfloor \dfrac n p \right\rfloor\) 個。
上一步操作後,我們得到了 \(1 \sim \left\lfloor \dfrac n p \right\rfloor\)。我們將其中所有 \(p\) 的倍數提出來,然後全部除以 \(p\)。這一步消掉的質因子個數為 \(\left\lfloor \dfrac n {p ^ 2} \right\rfloor\)。
以此類推,直到 \(\left\lfloor \dfrac n {p ^ k} \right\rfloor < p\)。此時已經沒有 \(p\) 的倍數了。
因此,我們有如下結論:
\]
- 這一定理由勒讓德(Legendre)在 1808 年提出。
考慮換一種方法求和。我們嘗試對 \(n\) 在 \(p\) 進制下的每一位,求出它對每次提出因子個數的貢獻之和。不妨設 \(n = \sum\limits_{i = 0} ^ c a_i p ^ i\),則
v_p(n!) & = \sum_{i = 1} ^ {c} \sum_{j = 0} ^ c\left\lfloor \dfrac {a_j p ^ j} {p ^ i} \right\rfloor \\
& = \sum_{j = 0} ^ c \sum_{i = 1} ^ {j} \dfrac {a_j p ^ j} {p ^ i} \\
& = \sum_{j = 0} ^ c a_j\sum_{i = 0} ^ {j – 1} p ^ i \\
& = \sum_{j = 0} ^ c a_j\dfrac {p ^ j – 1} {p – 1} \\
& = \dfrac {\left(\sum_{j = 0} ^ c a_j p ^ j\right) – \left(\sum_{j = 0} ^ c a_j\right)}{p – 1} \\
& = \dfrac {n – s_p(n)}{p – 1}
\end{aligned}
\]
通過上述推導,我們得到了 \(v_p(n!)\) 的另一種表示方法 \(\dfrac {n – s_p(n)}{p – 1}\)。
特別地,當 \(p = 2\) 時,\(v_2(n) = n – \mathrm{popcount}(n)\)。
0.6 素數在組合數中的冪次
根據 0.5 節的結論以及組合數公式 \(\dbinom n m = \dfrac {n!} {m!(n – m)!}\),我們有
& v_p\left(\dbinom n m\right) \\
= \ &\dfrac {n – s_p(n) – (m – s_p(m)) – (n – m – s_p(n – m))}{p – 1} \\
= \ &\dfrac {s_p(m) + s_p(n – m) – s_p(n)}{p – 1}
\end{aligned}
\]
考慮 \(n – m\) 和 \(m\) 在 \(p\) 進制 下相加得到 \(n\) 的過程,其中 \(p\) 是質數。每產生一次進位,各位數字之和就會減少 \(p – 1\),因此 \(p\) 在組合數 \(\dbinom n m\) 中的冪次 \(v_p\left(\dbinom n m\right)\) 即 \(p\) 進制下 \(n – m\) 加上 \(m\) 需要進位的次數,也等於 \(n\) 減去 \(m\) 需要借位的次數。
上述結論被稱為 Kummer 定理,在 Lucas 定理中有用。
0.7 其它有用的事實
因為這個結論非常經典且容易理解,但證明較繁瑣,故寫在此處。
在一個長為 \(n\) 的環上每一步走 \(k\) 條邊,形成的子環個數為 \(\gcd(n, k)\) 且環長為 \(\dfrac n {\gcd(n, k)}\)。
感性理解:給環編號,走到的點的編號模 \(\gcd(n, k)\) 一定相同,且可以證明一定能走到所有編號模 \(\gcd(n, k)\) 相同的點。
證明:令 \(d = \gcd(n, k)\),按順序為環上的每個點標號 \(0, 1, 2, \cdots, n – 1\),即 \(0\to 1 \to \cdots\to n – 1 \to 0\)。從 \(r\) 開始每一步走 \(k\) 條邊,到達的點必然與 \(r\) 在模 \(d\) 意義下同餘,因為 \(n,k\) 均為 \(d\) 的倍數,為 \(r\) 加上 \(k\) 之後對 \(n\) 取余並不影響 \(r\bmod d\)。
首先證明一個引理:當 \(n \perp k\) 時,從環上任意一個節點出發,能夠走遍所有點。
證明:不妨設從點 \(r\) 開始,則走 \(x\) 步後到達的節點編號即 \((r + kx)\bmod n\)。欲證原結論,只需證明對於任意 \(0\leq i < j < n\),均有 \(r + ik \not \equiv r + jk\pmod n\),即走 \(0\sim n – 1\) 步到達的節點互不相同。
考慮反證法,假設存在 \(r +ik\equiv r +jk\pmod n\),移項得到 \((j – i)k \equiv 0\pmod n\)。因為 \(k\perp n\),所以 \(n \mid j – i\),這與 \(0\leq i, j < n\) 矛盾。得證。
通過上述推導過程我們也可以看出,反證法在證明兩個數不相等時非常有用。
不妨設 \(0\leq r < d\)。考慮 \(0\sim n – 1\) 當中所有模 \(d\) 余 \(r\) 的數 \(r, r + d, \cdots, r + \left(\dfrac n d – 1\right)d\),將其重標號為 \(0, 1, \cdots, \dfrac n d – 1\),形成一個長為 \(\dfrac n d\) 的子環。因為 \(d = \gcd(n, k)\),所以 \(\dfrac n d\perp \dfrac k d\)。根據引理,在這個長為 \(\dfrac n d\) 的子環上每一步走 \(\dfrac k d\) 條邊(相當於在原環上走 \(k\) 條邊),能夠走遍子環上每一個點。
因此形成的子環長為 \(\dfrac n d\) 即 \(\dfrac n {\gcd(n, k)}\),且每一個模 \(d\) 的剩餘系均恰好形成一個子環,因此子環個數為 \(d\),即 \(\gcd(n, k)\)。或者說,子環長乘以子環個數等於環長,因為每個模 \(d\) 的剩餘系即每一個子環是等價的,均為在 \(0\sim n – 1\) 內模 \(d\) 相同的所有數,只是子環之間在原環上的標號模 \(d\) 不同。證畢
相關應用見 P5582 [SWTR-01] Escape,P5887 Ringed Genesis,P6187 [NOI Online #1 提高組] 最小環。
1. 擴展歐幾里得算法
擴展歐幾里得算法簡稱擴歐或 exgcd。它是求解最大公約數的歐幾里得算法的擴展,用於求解形如 \(ax + by = c\) 的 二元 線性不定方程。
我們將看到擴展歐幾里得算法與最大公約數的聯繫。
1.1 解的存在性
在求解形如 \(ax + by = c\) 的不定方程之前,我們首先需要知道如何 判定 它有解。
- 在求解方程之前,首先需要判斷解的存在性。
先考慮一些較弱的結論。容易發現,無論 \(x, y\) 的取值,左式一定是 \(d = \gcd(a, b)\) 的倍數。因此,當 \(d\nmid c\) 時,方程顯然無解。這使得我們可以為方程兩側同時除以 \(d\)。
同時,我們注意到為 \(a\) 和 \(b\) 同時除以 \(d\) 之後,\(a, b\) 互質。這說明我們將問題簡化為求解 \(a, b\) 互質時的情形。可見優先判斷解的存在性的重要性。
根據直觀感受,對於 \(a\perp b\),\(ax + by\) 似乎能組合成任意一個整數,因為它們沒有共同質因子。顯然,這隻需證明 \(ax\bmod b\) 可以取到 \(0 \sim b – 1\) 當中的任何一個數。
證明是容易的,因為 \(a\perp b\) 提供了很強的性質。注意到這實際上是將費馬小定理的證明中,\(p\) 為質數的條件去掉了,換成了 \(a \perp p\),本質並沒有差別。
考慮 \(ax\) 和 \(ay\) 滿足 \(1\leq x, y \leq b\) 且 \(x\neq y\),則 \(ax\not\equiv ay \pmod b\)。若存在,則 \(a(x – y)\equiv 0\pmod b\)。因為 \(a\perp b\),所以 \(x – y \equiv 0\pmod b\)(\(a\) 能夠約去的原因是它不提供任何 \(b\) 含有的質因子,也就是對使得 \(a(x – y)\equiv 0\pmod b\) 成立沒有任何 「貢獻」),這與 \(1\leq x, y \leq b\) 的限制矛盾。證畢。
因為 \(ax + by\) 在 \(a\perp b\) 時取遍所有整數,所以若 \(d\mid c\),方程就一定有解。
綜合上述結論,我們得到了判斷二元線性不定方程 \(ax + by = c\) 存在解的 充要條件:\(\gcd(a, b) \mid c\)。這被稱為 裴蜀定理 或 貝祖定理。
1.2 算法介紹
欲求解 \(ax + by = c\),設 \(d = \gcd(a, b)\),我們只需求解 \(ax + by = d\),並將解乘以 \(\dfrac c d\)。根據裴蜀定理,方程的解必然存在。
注意到等式右端等於 \(x, y\) 前係數的最大公約數。回顧歐幾里得算法(即輾轉相除法),我們用到了關鍵結論 \(\gcd(a, b) = \gcd(b, a\bmod b)\),將問題縮至更小的規模上。利用這一思想,我們嘗試將求解的方程也縮至更小的規模上。
考慮 遞歸構造。假設我們已經得到了 \(bx’ + (a \bmod b) y’ = d\) 的一組解,則
ax + by & = bx’ + (a\bmod b) y’ \\
& = bx’ + \left(a – b \times \left\lfloor \dfrac a b \right\rfloor \right)y’ \\
& = ay’ + b \left(x’ – \left\lfloor \dfrac a b \right\rfloor y’ \right)
\end{aligned}
\]
對比等式兩端,有 \(x = y’\),\(y = x’ – \left\lfloor \dfrac a b \right\rfloor y’\),遞歸計算即可。遞歸邊界即當 \(b = 0\) 時,根據輾轉相除法,\(a = d\),故此時 \(x = 1\),\(y = 0\) 即為一組解。
上述過程即擴展歐幾里得算法,時間複雜度是輾轉相除法的 \(\log V\)。代碼如下。
void exgcd(int a, int b, int &x, int &y) {
if(!b) return x = 1, y = 0, void();
exgcd(b, a % b, y, x), y -= a / b * x;
}
注意,擴歐求得的解為 \(ax + by = d\) 的一組特解。為求得原方程 \(ax + by = c\) 的一組特解,還需將 \(x, y\) 乘以 \(\dfrac c d\)。
1.3 解的形式與數值範圍
顯然,不定方程 \(ax + by = c\) 若存在解,則存在無窮解。我們需要通解的表示形式。
擴歐可以求得一組特解 \(x_0, y_0\)。根據 \(\Delta(ax)+\Delta(by)=0\),設 \(\Delta=|{\Delta(ax)}|=|\Delta(by)|\),那麼 \(a,b\mid \Delta\),故 \(\mathrm{lcm}(a,b)\mid \Delta\)。因此 \(|\Delta x|\) 是 \(\dfrac{\mathrm{lcm}(a, b)} a = \dfrac b d\) 的倍數,\(|\Delta y|\) 同理。故通解形如
x = x_0 + \dfrac b d k \\
y = y_0 – \dfrac a d k
\end{cases}
\quad (k \in \Z)
\]
特解的數值範圍詳見 ycx 的博客 關於 exgcd 求得特解的數值範圍。這裡僅給出結論:對於非平凡情況,有 \(|x| \leq \left| \dfrac b {2d} \right|\) 且 \(|y| \leq \left |\dfrac a {2d}\right|\)。平凡情況:\(a = b = 1\) 或 \(b = 0\)。
1.4 應用
-
exgcd 的重要應用是求解一元線性同餘方程 \(ax\equiv b \pmod p\)。只需將其看成二元不定方程 \(ax + py = b\) 並使用 exgcd 求解即可。
-
當模數不是質數時,費馬小定理不再適用,但模意義下的乘法逆元仍可能存在。\(a\) 在模 \(p\) 意義下存在逆元當且僅當 \(a \perp p\),因為求逆元相當於求解 \(ax \equiv 1 \pmod p\) 即使得 \(ax + py \equiv 1\pmod p\) 成立的 \(x\)。根據裴蜀定理,\(x\) 存在當且僅當 \(a\perp p\)。求解模 \(p\) 意義下 \(a\) 逆元只需求解線性同餘方程 \(ax\equiv 1\pmod p\) 即可。
int inv(int a, int p) {return exgcd(a % p, p, a, *new int), (a % p + p) % p;}
- 通過 exgcd 我們可以證明 \(ax\equiv b\pmod p\) 在當 \(\gcd(a, p)\nmid b\) 時無解,否則在 \(0\sim p – 1\) 中有 \(\gcd(a, p)\) 個整數解。這是因為其通解可寫為 \(x_0 + \dfrac p {\gcd(a, p)}\) 的形式,其中 \(0\leq x_0 < \dfrac {p}{\gcd(a, p)}\):將方程兩側同時除以 \(\gcd(a, p)\),則 \(\dfrac {a}{\gcd(a, p)} x_0 \equiv \dfrac {b}{\gcd(a, p)} \pmod {\dfrac p{\gcd(a, p)}}\)。
- 從裴蜀定理的推導過程中,我們證明了這樣一個引理:若 \(a\perp b\),則 \(ax \bmod b\) 取遍 \(0\sim b – 1\)。這是一個很有用的事實。
1.5 例題
I. UVA10104 Euclid Problem
exgcd 的模板題。
II. P5656【模板】二元一次不定方程 (exgcd)
題目要求 \(x\) 是正整數,可以先求出 \(x\) 的最小正整數值 \(x_0 = x \bmod {\dfrac b d}\),此時 \(y_{\max} = \dfrac {c – ax_0} b\)。若 \(y_{\max} > 0\) 則有正整數解,且 \(y_{\max}\) 對應正整數解中最大的 \(y\),否則沒有正整數解。對於 \(y_0\) 和 \(x_{\max}\) 同理。
#include <bits/stdc++.h>
using namespace std;
#define int long long
int T, a, b, c;
void exgcd(int a, int b, int &x, int &y) {
if(!b) return x = 1, y = 0, void();
exgcd(b, a % b, y, x), y -= a / b * x;
}
signed main() {
cin >> T;
while(T--) {
scanf("%lld %lld %lld", &a, &b, &c);
int d = __gcd(a, b), x, y, xx, xy, yx, yy;
if(c % d) {puts("-1"); continue;}
exgcd(a, b, x, y);
x *= c / d, y *= c / d;
xx = x % (b / d);
if(xx <= 0) xx += b / d;
xy = (c - a * xx) / b;
yy = y % (a / d);
if(yy <= 0) yy += a / d;
yx = (c - b * yy) / a;
if(xy <= 0) cout << xx << " " << yy << "\n";
else cout << (yx - xx) / (b / d) + 1 << " " << xx << " " << yy << " " << yx << " " << xy << "\n";
}
return 0;
}
*III. UVA12775 Gift Dilemma
題意簡述:給出 \(a, b, c, p\),求 \(ax + by + cz = p\) 非負整數解的個數。
題目條件 \(c\geq 200\times \gcd(a, b, c)\) 即 \(c\geq 200\)。對於這種三元不定方程,考慮枚舉 \(c\) 前的係數 \(z\),再求 \(ax + by = p – cz\) 的非負整數解的個數。
記 \(z=\dfrac{p}{c}\),則時間複雜度為 \(\mathcal{O}(Tz\log z)\)。
IV. 某模擬賽 你還沒有 AK 嗎
\(x, y\) 分別從 \([0, n]\) 和 \([0, m]\) 中隨機選擇,求執行任意正整數次 \(x\gets x + y\) 以及 \(y\gets x + y\) 後使得 \(x = X\) 的初始值 \(x, y\) 的個數。\(T\le 10^5\),\(n, m, X\leq 10 ^ {18}\)。時限 1s。
轉化題意,令 \(f_1 = f_2 = 1\),\(f_i = f_{i – 1} + f_{i – 2}\) 則相當於求有多少對 \((x, y)\) 滿足 \(f_{2k + 1}x + f_{2k + 2}y = X\)。
注意到斐波那契數列的增長相當快,當 \(k >\mathcal{O}(\log X)\) 光是 \(f_{2k+1}\) 就已經 \(>X\) 顯然不符題意,故考慮直接枚舉 \(k\)。
問題轉化為求關於 \(x, y\) 的二元一次方程 \(ax + by = X\) 有多少解滿足 \(x\in[0, n]\),\(y\in[0, m]\)(斐波那契數列相鄰兩項 \(\gcd = 1\),故不需求 \(\gcd\))容易 exgcd 求解。但 \(T\log ^ 2 X\) 無法通過。
不難發現只有本質不同的 \(k\) 對 \(a, b\),故預先存儲下來即可將複雜度優化至 \(\mathcal{O}(T\log X)\)。更進一步地,我們有 \(f_{2k + 1} ^ 2\equiv 1 \pmod {f_{2k + 2}}\)(可以歸納證明 \(f_{2k} ^ 2\equiv -1\pmod {f_{2k + 1}}\) 以及上述結論),故直接令 \(x \gets f_{2k + 1}\) 即一個合法解,甚至不需要使用 exgcd。
*V. P3421 [POI2005]SKO-Knights
巧妙線性代數題。題目要求我們找到兩個向量 \(d, e\),使得它們的 整係數 線性組合得到的線性空間(簡稱整係數線性空間)等價於給出的所有向量的整係數線性空間。定義 \(\mathrm{span}(S)\) 表示向量集合 \(S\) 的整係數線性空間,即
\]
如果我們能將三個向量 \(a, b, c\) 合併成與之等價的兩個向量 \(d, e\),就能夠解決本題。根據基礎的線性代數知識,不改變矩陣行空間的初等行變換有三種:
- 兌換:對應本題即可以任意交換 \(a, b, c\)。
- 倍乘變換:對應本題即向量可以乘以任意非 \(0\) 整數。
- 倍加變換:對應本題即向量可以加上任意整數倍其它向量。
當然,上述性質僅在 實係數 線性組合的前提下成立。當要求係數為 整數 時,
- 兌換顯然不改變矩陣行空間。
- 倍乘變換 可能改變 矩陣行空間,因為 整數乘法不可逆。如 \(\mathrm{span}((0, 1), (1, 0))\neq \mathrm{span}((0, 2), (1, 0))\),前者是任意整點,後者是任意縱坐標是偶數的整點。
- 倍加變換 不改變 矩陣行空間:對於任意 \(p = y(a + xb) + zb\in \mathrm{span}(a + xb, b)\),它本質上仍是 \(a, b\) 的整係數線性組合 \(ya + (xy + z)b\)。對於任意 \(p = ya + zb \in \mathrm{span}(a, b)\),我們也總可以將其表示為 \(a + xb\) 和 \(b\) 的整係數線性組合 \(y(a + xb) + (z – xy) b\)。
很好!如果整係數倍加變換不改變整係數意義下的矩陣行空間,就可以使用 輾轉相減法。具體地,考慮兩個向量 \(a, b\),我們能夠在 不改變其整係數線性空間 的前提下,將 \(b\) 的某一維變為 \(0\)。只需對 \(a, b\) 在這一維進行輾轉相減法即可。
考慮三個向量 \(a, b, c\),我們對 \(a, b\) 在 \(x\) 這一維進行輾轉相減,再對 \(a, c\) 在 \(x\) 這一維進行輾轉相減。此時 \(x_b, x_c\) 均為 \(0\),意味着 \(b, c\) 共線。因此,對 \(b, c\) 在 \(y\) 這一維進行輾轉相減,就可以使 \(y_b\gets \mathrm{gcd}(y_b, y_c)\),而 \(c\) 變成了 零向量,對 \(\mathrm{span}(a, b, c)\) 沒有任何貢獻,可以 直接捨去,即此時 \(\mathrm{span}(a, b, c) = \mathrm{span}(a, b)\)。
綜上,我們在 \(\mathcal{O}(n\log V)\) 的時間內解決了問題,其中 \(V\) 是值域。
注意點:題目限制了坐標絕對值不超過 \(10 ^ 4\),因此輾轉相減法得到最終的 \(a\) 時,\(x_a\) 和 \(y_b\) 是原坐標的 \(\gcd\),顯然滿足坐標限制。但 \(y_a\) 不一定,因此要對 \(y_b\) 取模,也相當於做了一步輾轉相減(此時 \(x_b = 0\) 所以不需要改變 \(x_a\))。故最終得到的坐標絕對值不超過 \(10 ^ 2\),比題目限制優一個數量級。
從上述過程中,我們也可以發現一個有趣的性質:整係數 意義下,兩個向量可以在不改變其張成的前提下,使其中一個向量的 某一維變成 \(0\),而另一個向量的對應維變成原來兩個向量在這一維上的 \(\gcd\)。這也是解決本題的關鍵性質。
因此,推廣到任意維度 \(k\),給定 \(n\) 個 \(k\) 維向量,我們可以 \(nk ^ 2\log V\) 求出這組向量在整係數意義下的基。誒,等等?這不就是 線性基 么!
讓我們更加深入地鑽研一下題解區的做法。
實際上兩者的核心思想是等價的,均為剛才提到的性質:將兩個向量的其中一個的某一維變成 \(0\),另一個的對應維變成 \(\gcd\)。不同點在於本文的線性代數做法是從 倍加變換 和 輾轉相除法 開始,推得 這一核心思想,即我們運用正確性有保證的方法,最終得到的結果是這樣一個性質。而題解區做法是首先令這一條件成立,再根據得到的線性方程組,使用 exgcd 和一些數學推導求解。這也體現了 exgcd 與輾轉相除的本質聯繫。
不妨設對於向量 \(a, b\),我們要將 \(x_b\) 變為 \(0\)。此時 \(x_{a’}\) 已經確定,即 \(\gcd(x_a, x_b)\)。因此,對於方程 \(xx_a + yx_b = \gcd(x_a, x_b)\),容易用 擴展歐幾里得 算法求得一組解,則 \(y_{a’} = xy_a + yy_b\)。這是因為 \(a’ = xa + yb\)。對於向量 \(b’\),有 \(x_{b’} = 0\),因此有線性方程組
xx_a + yx_b = 0 \\
xy_a + yy_b = y_{b’}
\end{cases}
\]
注意該方程組的 \(x, y\) 與之前 exgcd 求得的 \(x, y\) 不同。同時我們需使 \(y_{b’}\) 絕對值最小,否則可能出現 \(y_{b’} = 2\),但 \((0, 1) \in \mathrm{span}(a, b)\) 的情況,即對於 \(\mathrm{span}(a, b)\) 中橫坐標為 \(0\) 的所有點,\((0, y_{b’})\) 不是與 \((0, 0)\) 相鄰的那一個,這樣與 \((0, 0)\) 相鄰的點無法表示。
根據第一個方程,得到 \(x, y\) 的關係式 \(y = \dfrac{-xx_a}{x_b}\)。帶入第二個方程,得到 \(xy_a – \dfrac{xx_ay_b}{x_b} = y_{b’}\),即
\]
我們的目標很明確:找到 絕對值 最小的合法的 \(x\)。把 \(x\) 寫成 \(\dfrac {x_b}d\) 的形式(因為分母是 \(x_b\)),那麼 \(y = -\dfrac{x_a} d\),因此 \(d\) 滿足
d \mid x_b \\
d \mid x_a \\
d \mid y_ax_b – x_ay_b
\end{cases}
\]
注意到若滿足前兩條限制,則第三條限制自動滿足,故忽略。為使 \(x\) 的絕對值最小,\(d\) 的絕對值應盡量大。到這一步,大家應該都能看出 \(d\) 應取 \(\gcd(x_a, x_b)\)。因此,\(y_{b’} = \dfrac{y_ax_b – x_ay_b}{\gcd(x_a, x_b)}\)。
綜上,我們將原向量 \(a, b\) 寫成了另兩個向量 \(a’, b’\),其中 \(x_{a’} = \gcd(x_a, y_a)\),\(y_{a’}\) 用 exgcd 求解,\(x_{b’} = 0\),\(y_{b’} = \dfrac{y_ax_b – x_ay_b}{\gcd(x_a, x_b)}\)。對 \(a, c\) 做一遍類似的操作,再合併 \(b, c\)(即類似線性代數解法,令 \(y_b \gets \gcd(y_b, y_c)\),然後丟棄 \(c\))即可。時間複雜度也是線性對數。
另一種求解 \(y_{b’}\) 的思路(來源於 TheLostWeak 的博客):\(a’, b’\) 可以整係數線性組合出 \(a, b\),否則顯然不滿足條件,因為 \(a, b\in \mathrm{span}(a, b)\)。
根據上述性質,考慮 \(a’\)。由於 \(x_{a’} = \gcd(x_a, x_b)\),所以為了使橫坐標等於 \(x_a\),需要為 \(a’\) 乘以 \(\dfrac{x_a}{\gcd(x_a, x_b)}\) 即 \(\dfrac{x_a}{x_{a’}}\) 的係數,得到 \(\left(x_a, \dfrac{x_ay_{a’}}{x_{a’}}\right)\)。由於我們可以通過向量 \(b’ = (0, y_{b’})\) 得到 \((x_a, y_a)\),因此 \(y_{b’} \left |\ y_a – \dfrac{x_ay_{a’}}{x_{a’}}\right.\) 。同理,\(y_{b’} \left |\ y_b – \dfrac{x_by_{a’}}{x_{a’}}\right.\)。故
\]
易證若 \(y_{b’}\) 小於上述 \(\gcd\),將導致存在 \(p\in \mathrm{span}(a’, b’)\),\(p\notin \mathrm{span}(a, b)\)。若 \(y_{b’}\) 大於上述 \(\gcd\),\(a’, b’\) 無法整係數線性組合出 \(a, b\) 中的至少一個。
聯立後兩種方法描述 \(y_{b’}\) 的式子,稍作化簡後得到等式 \(y_ax_b – x_ay_b = \gcd(y_ax_{a’} – x_a y_{a’}, {y_bx_{a’} – x_by_{a’}})\)。這也許說明了某些性質,但筆者已經不想研究了 QAQ,感興趣的讀者可自行鑽研。
VI. P3518 [POI2011]SEJ-Strongbox
若 \(v\) 在群里,則所有 \(\leq n\) 且是 \(\gcd(v, n)\) 的倍數的數也在群里。這是因為 \(kv \bmod n\) 取到了所有這樣的數。證明:設 \(d = \gcd(v, n)\),\(d\mid t\) 且 \(t\) 不在群里,這意味着 \(kv \equiv t\pmod n\) 即 \(kv + yn \equiv t \pmod n\) 無解,根據裴蜀定理,它等價於 \(\gcd(v, n) \nmid t\) 即 \(d\nmid t\),矛盾。證畢。
因此,考慮枚舉這個 \(d = \gcd(v, n)\),若合法則答案即 \(\max\dfrac n d\),即我們需要找到最小的合法的 \(d\)。
如何判斷合法:不妨設 \(d_i = \gcd(m_i, n)\),\(d\) 首先得是密碼與 \(n\) 的 \(\gcd\) 即 \(d_k\) 的因數,其次任何 \(d_i(1\leq i < k)\) 不能是 \(d\) 的倍數。
考慮後者限制:給所有 \(d_i(1\leq i < k)\) 打上標記,從大到小枚舉 \(n\) 的每個因數 \(c\),若 \(c\) 被打上標記,則 \(\dfrac{c}{p_j}\) 也應被打上標記(其中 \(p_j\) 表示能整除 \(c\) 的 \(n\) 的質因子),表示若 \(c\) 是某個 \(d_i(1 \leq i < k)\) 的因數,則 \(\dfrac c {p_j}\) 顯然也是。
剩下來沒有被打上標記的所有 \(n\) 的因數 \(d\),若 \(d\) 能被 \(d_k\) 整除則合法。找到最小的這樣的 \(d\),則答案為 \(\dfrac n d\)。
打標記的過程用哈希表實現,時間複雜度 \(\mathcal{O}(\sqrt n + k\log n + d(n)\omega(n))\)。\(\omega(i)\) 表示 \(i\) 的質因數個數。
2. 歐拉函數
歐拉函數是一類非常重要的數論函數。
2.1 定義與性質
歐拉函數定義為在 \([1, n]\) 中與 \(n\) 互質的整數的個數,記作 \(\varphi(n)\) 。
性質 1:若 \(p\) 為質數,則 \(\varphi(p ^ k) = (p – 1) \times p ^ {k – 1}\)。
證明:在 \([1, p ^ k]\) 中所有不是 \(p\) 的倍數的數都與 \(p ^ k\) 互質。因此 \(\varphi(p ^ k) = p ^ k – p ^ {k – 1} = (p – 1)p ^ {k – 1}\),或者寫成 \(p ^ k \times \dfrac{p – 1}{p}\)。得證。
性質 2(積性):\(\varphi\) 是 積性函數。即若 \(a \perp b\),則 \(\varphi(ab) = \varphi(a)\times \varphi(b)\)。
證明:設與 \(a\) 互質的數為 \(\{a_1, a_2, \cdots, a_{\varphi(a)}\}\),那麼在 \([1, ab]\) 內與 \(a\) 互質的整數可以表示為 \(i \times a + a_j(0\leq i < b,1\leq j \leq \varphi(a))\)。
因為 \(a \perp b\),所以 \(ia(0 \leq i < b)\) 在模 \(b\) 意義下互不相同(1.4 節性質 4),即對於每一個 \(a_j\),\(\{i \times a + a_j\}(0\leq i < b)\) 均構成 \(b\) 的完全剩餘系 \(\{\overline 0, \overline 1, \cdots, \overline{b – 1}\}\),即隨着 \(i\) 從 \(0\) 變為 \(b – 1\),\(i\times a + a_j\) 模 \(b\) 的餘數取遍 \(0\sim b – 1\)。
因此,對於每一個 \(a_j\),滿足 \(b\perp i\times a + a_j\) 的 \(i\) 的個數為 \(\varphi(b)\)。因此,與 \(ab\) 互質的數的個數為 \(\varphi(ab) = \varphi(a) \times \varphi(b)\),即 \(\varphi\) 為積性函數。得證。
性質 3(計算式):根據算數基本定理,設 \(n\) 被唯一分解為 \(\prod\limits_{i = 1} ^ m p_i ^ {c_i}\),則 \(\varphi(n) = n \times \prod\limits_{i = 1} ^ m \dfrac{p_i – 1} {p_i}\)。
證明:根據性質 1 和性質 2,
\]
得證。這是求解 \(\varphi(n)\) 的常用方法。
這個性質也可以通過 容斥原理 證明,而不需要性質 1,2。考慮去掉所有被至少一個 \(n\) 的質因子整除的數,再加上至少被兩個 \(n\) 的質因子整除的數,以此類推,最終可以得到式子 \(\varphi(n) = n \times \sum\limits_S \dfrac {(-1) ^ {|S|}}{\prod_{p\in S} p}\),其中 \(S\) 是 \(n\) 的質因子集合的子集。容易證明其等於 \(n \times \prod\limits_{p_i} \left(1 – \dfrac 1 {p_i} \right)\)。
這樣可以反推出性質 2:設 \(a = \prod\limits_{i = 1} ^ {m_1} {p_i} ^ {c_i}\),\(b = \prod\limits_{i = 1} ^ {m_2} {q_i} ^ {d_i}\)。由於 \(a \perp b\),所以 \(p_i,q_i\) 互不相同。因此 \(ab = \prod\limits_{i = 1} ^ {m_1} {p_i} ^ {c_i} \times \prod\limits_{i = 1} ^ {m_2} {q_i} ^ {d_i}\),即
\]
int phi(int x) {
int ans = x;
for(int i = 2; i * i <= x; i++)
if(x % i == 0) {
while(x % i == 0) x /= i;
ans = ans / i * (i - 1);
}
return ans / x * max(1, x - 1);
}
性質 4:若 \(p\) 為質數,則 \(\varphi(p) = p – 1\)。
證明:根據質數的定義可知 \(i \perp p(1 \leq i < p)\),故 \(\varphi(p) = p-1\)。
性質 5:若 \(a \mid b\),則 \(\varphi(ab) = a \times \varphi(b)\)。
證明:對比 \(\varphi(ab)\) 與 \(\varphi(b)\) 的公式,因為 \(a \mid b\),所以 \(\prod\limits_{i = 1} ^ m \dfrac{p_i – 1}{p_i}\) 是相同的,只是左邊的 \(b\) 變成了 \(ab\)。故 \(\varphi(ab) = a \times \varphi(b)\)。
- 直觀理解:因為 \(ab\) 相較於 \(b\) 並沒有增加更多質因子,所以原來與 \(b\) 互質的數仍然與 \(ab\) 互質,而 \([1, ab]\) 當中與 \(b\) 互質的數的個數顯然為 \(a \varphi(b)\),因為一個與 \(b\) 互質的數加上 \(kb(k\in \Z)\) 後仍然與 \(b\) 互質。
性質 6(線性篩歐拉函數):若 \(p\) 為質數且 \(p\mid n\),則
\]
由性質 1,4,5 可得。這一性質是線性篩歐拉函數的關鍵結論。
性質 7(歐拉反演):\(\sum\limits_{d\mid n} \varphi(d) = n\)。
證明:令 \(i\) 是 \(1\sim n\) 的整數,\(d = \gcd(i, n)\),則 \(\dfrac i d \perp \dfrac n d\)。根據這一點,使得 \(\gcd(i, n) = d\) 的 \(i\) 的個數即 \(\varphi \left(\dfrac n d \right)\)。因為 \(\gcd(i, n) \in [1, n]\),則
\]
得證。如果讀者了解狄利克雷卷積,會發現這是 \(1 * \varphi = \mathrm{id}\)。
性質 8:\(2 \mid \varphi(n) (n > 2)\)。證明:若 \(x \perp n\),則 \(n – x\perp n\),故所有小於 \(n\) 且與 \(n\) 互質的數能一一配對。一個特例是 \(x = n – x\) 時,此時 \(x = \dfrac n 2\),\(\gcd(x,n) = x \neq 1\)。得證。
性質 9:若 \(a \mid b\),則 \(\varphi(a) \mid \varphi(b)\)。根據歐拉定理的計算式易證。
性質 10:使得 \(\gcd(n, x) = d\) 且 \(1\leq x \leq n\) 的 \(x\) 的個數為 \(\varphi\left(\dfrac n d\right)\)。
證明:容易證明 \(\gcd(n, x) = d\) 的充分必要條件為 \(\dfrac n d \perp \dfrac x d\)。因為 \(1\leq x \leq n\),所以 \(1\leq \dfrac x d \leq \dfrac n d\)。因此合法的 \(\dfrac x d\) 的個數為 \(\varphi\left(\dfrac n d\right)\)。得證。
將 \(x\) 的限制改為 \(0\leq x < n\),命題仍成立。因為在模 \(n\) 意義下 \(0\) 等於 \(n\),或者理解為 \(\gcd(n, n) = \gcd(0, n) = n\)。
- 簡單地說,首先顯然 \(x\) 得是 \(d\) 的倍數,其次 \(\dfrac x d\) 不能和 \(\dfrac n d\) 有公因子,否則 \(\gcd(x, n)\) 就會大於 \(d\)。
2.2 歐拉定理
回顧費馬小定理的證明過程,我們發現不需要 \(p\) 是質數這一條件,當 \(a \perp p\) 時 \(ax\bmod p\) 即互不相同。
同時我們知道,兩個模 \(p\) 互質的數相乘後仍與 \(p\) 互質,因此,我們嘗試將費馬小定理擴展至更一般的情況。
為了防止出現乘積等於零的情況,我們將研究目標設為 \(p\) 的 簡化剩餘系 而非完全剩餘系。
設 \(S=\{p_1,p_2,\cdots,p_{\varphi(p)}\}\) 為 \(p\) 的簡化剩餘系,即所有與 \(p\) 互質且模 \(p\) 互不相同的數組成的集合。對於任意 \(p_i, p_j\),若 \(i \neq j\),則根據上述分析,\(ap_i\) 與 \(ap_j\) 在模 \(p\) 意義下的餘數不相等且仍與 \(p\) 互質。
因此在模 \(p\) 意義下,\(S\) 中每個數乘以 \(a\) 後仍與 \(S\) 相等。故 \(\prod\limits_{i = 1} ^ {\varphi(p)} p_i \equiv \prod\limits_{i = 1} ^ {\varphi(p)} ap_i\pmod p\)。顯然 \(\prod p_i\perp p\)。等式兩邊同時除以 \(\prod\limits_{i = 1} ^ {\varphi(p)} p_i\) 得到
\]
在計算與模數互質的某個數的冪時,指數可以對模數的歐拉函數取模。可以用來化簡公式或減小常數(前提是模數是定值或其歐拉函數容易求得)。
擴展歐拉定理:歐拉定理的擴展版本,如下。
a ^ {b\ \bmod\ \varphi(p)} & \gcd(a,p) = 1 \\
a ^ b & \gcd(a, p) \neq 1, b < \varphi(p) \\
a ^ {b\ \bmod\ \varphi(p) + \varphi(p)} & \gcd(a, p)\neq 1, b \geq \varphi(p)
\end{cases} \pmod p
\]
感性證明:當 \(\gcd(a, p) \neq 1\) 時,不斷乘以 \(a\) 會讓 \(a ^ i\) 和 \(p\) 的 \(\gcd\) 不斷變大,直到某個特定的 \(a ^ r\) 之後 \(\gcd\) 不再變化,因為此時 \(\gcd(a ^ r, p)\) 受到 \(p\) 的每個與 \(a\) 相同的質因子的次數的限制。令這個 \(\gcd\) 為 \(d\),考慮 \(a ^ r \bmod p, a ^ {r + 1} \bmod p, \cdots\),顯然它們均為 \(d\) 的倍數,且除以 \(d\) 之後會取遍所有與 \(\dfrac p d\) 互質的數,這是因為 \(a \perp \dfrac p d\)。根據歐拉定理,\(a ^ k \bmod {\dfrac p d}\) 有循環節 \(\varphi \left(\dfrac p d \right)\),因此 \(\left(a ^ k \bmod {\dfrac p d} \right)\times d\) 即 \(a ^ k \bmod p\) 也有循環節 \(\varphi \left(\dfrac p d \right)\)。故從 \(a ^ r\) 開始,\(a ^ {r + k} \bmod p\) 有循環節 \(\varphi(p)\)。
嚴謹證明 摘自 OI wiki,如下。
對於 \(a\) 的 \(i\) 次冪模 \(p\) 構成的無窮序列 \(a ^ 0, a ^ 1, \cdots\),必然存在循環節的開始位置 \(r\) 和循環節長度 \(s\),使得 \(a ^ i\) 從 \(r\) 開始以 \(s\) 為循環節長度循環,即對於任意 \(i \geq r\) 滿足 \(a ^ i \equiv a ^ {i + s}\)。欲證擴展歐拉定理,可證 \(r \leq \varphi(p)\) 且 \(s\mid \varphi(p)\)。
當 \(a\) 是質數時,令 \(p’\) 為 \(p\) 去掉所有質因子 \(a\) 後的結果,\(p = a ^ r p’\)。此時 \(a \perp p’\),顯然 \(\varphi(p’) \mid \varphi(p)\)(\(p\) 是 \(p’\) 的倍數)。因為 \(a ^ {\varphi(p’)} \equiv 1 \pmod {p’}\),故 \(a ^ {\varphi(p)} \equiv 1 \pmod {p’}\),故 \(a ^ {\varphi(p) + r} \equiv a ^ r \pmod {p}\)。因為 \(\varphi(p) = a ^ {r – 1}(a – 1) \varphi(p’) \geq a ^ {r – 1}(a – 1) \geq r\),得證。
當 \(a\) 是質數的 \(k\) 次冪時,令 \(a = q ^ k\),\(p = q ^ r p’\)。由上一條,\(q ^ {\varphi(p)} \equiv 1 \pmod {p’}\)。因此 \(q ^ {k\varphi(p)} \equiv 1 \pmod {p’}\),即 \(a ^ {\varphi(p)} \equiv 1 \pmod {p’}\)。考慮令 \(r’ = \left\lceil \dfrac r k \right\rceil\),由於 \(q ^ {k\varphi(p) + r} \equiv q ^ r\pmod p\),且 \(r’k \geq r\),所以 \(q ^ {k\varphi(p) + r’k} \equiv q ^ {r’k}\pmod p\),即 \(a ^ {\varphi(p) + r’} \equiv a ^ {r’} \pmod p\)。因為 \(r’ \leq r\),所以由上一條,\(r’ \leq \varphi(p)\),得證。
當 \(a = q_1 ^ {k_1} q_2 ^ {k_2}\) 時,因為 \(q_1 ^ {k_1\varphi(p)} \equiv 1 \pmod {p’}\) 且 \(q_2 ^ {k_2\varphi(p)} \equiv 1 \pmod {p’}\),所以 \(a ^ {\varphi(p)} \equiv \pmod {p’}\)。如法炮製,令 \(r’ = \max\left(\left\lceil \dfrac {r_1} {k_1} \right\rceil, \left\lceil \dfrac {r_2} {k_2} \right\rceil \right)\),容易證明 \(a ^ {\varphi(p) + r’} \equiv a ^ {r’} \pmod {p’}\) 且 \(r’ \leq \max(r_i) \leq \varphi(p)\),得證。
當 \(a\) 為多個質數的乘積時,可以利用上一條類似證明。擴展歐拉定理得證。
擴展歐拉定理的應用見例 IV, V.
2.3 線性篩歐拉函數
根據歐拉函數的性質 6,我們可以線性篩出所有數的歐拉函數。關於線性篩,見 各類反演與狄利克雷卷積 第六章線性篩部分。
初始化 \(\varphi(1) = 1\)。對於每個質數 \(p\),\(\varphi(p) = p – 1\)。枚舉所有數 \(i\) 並遍歷所有篩到的素數 \(pr_j\)。若 \(pr_j\nmid i\),則 \(\varphi(i \times pr_j) = (pr_j – 1) \times \varphi(i)\)。否則 \(\varphi(i \times pr_j) = pr_j \times \varphi(i)\),同時根據線性篩的算法,此時應退出遍歷。
int cnt, pr[N], phi[N], vis[N];
void sieve() {
phi[1] = 1;
for(int i = 2; i < N; i++) {
if(!vis[i]) pr[++cnt] = i, phi[i] = i - 1;
for(int j = 1; j <= cnt && i * pr[j] < N; j++) {
vis[i * pr[j]] = 1, phi[i * pr[j]] = (pr[j] - 1) * phi[i];
if(i % pr[j] == 0) {phi[i * pr[j]] = pr[j] * phi[i]; break;}
}
}
}
2.4 例題
I. SP4141 ETF – Euler Totient Function
歐拉函數模板題。
II. UVA10179 Irreducable Basic Fractions
根據既約分數 \(\dfrac m n\) 的定義 \(m \perp n\) 且 \(0 \leq m < n\) 可知答案即 \(\varphi(n)\)。
III. UVA11327 Enumerating Rational Numbers
本題是上題的變形。樣例告訴我們分母不大於 \(2\times 10^5\)。因此預處理出 \([1,2\times 10^5]\) 每個數的歐拉函數。從小到大枚舉分母,求出分母后再根據剩餘個數從小到大枚舉分子。
*IV. P4139 上帝與集合的正確用法
題意簡述:求 \(2 ^ {2 ^ {2 ^ {2 ^ {2 ^ {\cdots}}}}} \bmod p\),\(1 \leq p \leq 10 ^ 7\)。
初看這個無限冪塔讀者可能摸不着頭腦,因為直覺告訴我們這個值不存在,就好像 \(\infty\) 是一個不確定的數一樣。但反直覺的是當 \(x\) 足夠大時,\(2\uparrow\uparrow x\) 與 \(2\uparrow\uparrow (x+1)\) 在模 \(p\) 意義下相同。\(\uparrow\) 見 高德納箭號表示法。
為什麼呢?根據擴展歐拉定理,上面的冪塔等於 \(2^{2^{2^{2^{\cdots}}}\bmod \varphi(p)+\varphi(p)}\bmod p\),不斷使用擴展歐拉定理得到
2 ^ {2 ^ {2 ^ {2 ^ {\cdots}
\bmod \varphi(\varphi(\varphi(p))) +\varphi(\varphi(\varphi(p)))}
\bmod \varphi(\varphi(p)) + \varphi(\varphi(p))}
\bmod \varphi(p) + \varphi(p)}
\bmod p
\]
因為冪指數無窮疊加,所以不需要擔心出現 \(2^{2^{2^{\cdots}}}<\varphi(p)\) 導致擴展歐拉定理失效,可以遞歸實現。
又因為 \(2\mid \varphi(n)\) 且 \(\varphi(2n)\leq n\),所以 \(\varphi(p)\) 的迭代值會以指數方式減小為 \(1\)。此時不用關心繼續往上的冪次是多少了,因為任何數模 \(1\) 都得 \(0\),這是終止條件。綜上,線性篩出 \(p\) 以內所有數的歐拉函數即可做到時間複雜度 \(\mathcal{O}(p+T\log p)\)。每次直接暴力算 \(\varphi(p)\) \(\mathcal{O}(T\sqrt p\log p)\) 也可以通過。
int F(int x) {
if(x <= 2) return 0; int v = phi(x);
return ksm(2, F(v) + v, x); // 2 ^ {F(v) + v} % x
}
*V. P3747 [六省聯考 2017] 相逢是問候
根據上一題的結論,\(c ^ {c ^ {c ^ {\cdots ^ {a_i}}}} \bmod p\) 在迭代次數足夠多時為定值:迭代次數 \(cnt\) 為使得 \(\varphi(\varphi(\cdots\varphi(\varphi(p))\cdots)) = 1\) 的迭代次數,為 \(\log p\) 級別。
預處理出每個數迭代 \(i\) 次後的結果,即對每個位置預處理冪塔迭代 \(1\sim cnt\) 次 \(c\) 之後的結果(不是 \(cnt – 1\),因為最頂上的模 \(1\) 的數是 \(a_i\) 而不是 \(c\)),然後對每個線段樹上的葉子結點記錄操作次數最小值 \(d_i\),如果還有可以操作的區間即 \(d_i<cnt\) 則遞歸下去暴力修改。
此外,判斷指數是否大於等於 \(p\) 可以在快速冪時實現:乘完先不取模,如果值不小於模數再記錄並取模。這部分比較細節,需要多加註意。
時間複雜度是 \(\mathcal{O}(n\log n\log^2 p)\) :歐拉函數有 \(\log p\) 種,線段樹上 \(n\) 個位置每種歐拉函數遞歸 \(\log p\) 層,每次修改都要快速冪。注意到只有 \(\log p\) 種模數,所以可把快速冪換為光速冪。時間複雜度 \(\mathcal{O}(n\log^2 p)\)。代碼。
3. 離散對數問題
離散對數問題即在模 \(p\) 意義下求解 \(\log_a b\)。這等價於求解離散對數方程
\]
其中 \(x\) 即 \(\log_a b\)。模 \(p\) 意義下的 \(\log_a b\) 可能不存在,也可能存在多個,我們的目標是找到任意一個。
當 \(a, p\) 互質時,我們可以使用大步小步算法求解。當 \(a, p\) 不互質時,可以使用擴展大步小步算法求解。
3.1 大步小步算法
大步小步算法全稱 Baby Step, Giant Step,簡稱 BSGS。普通 BSGS 適用於 \(a\perp p\) 的情況。
大步小步算法運用了 根號平衡(或稱為 meet-in-the-middle)的技巧:設塊長為 \(M\) 且 \(x = AM – B(0\leq B < M)\),則有 \(a ^ {AM} \equiv ba ^ B \pmod p\)。直接枚舉 \(a ^ {AM}\) 與 \(ba ^ B\) 所有可能的取值並通過哈希表(pb_ds 的 gp_hash_table <int, int>)判斷是否相等,即可 \(\mathcal{O}(\max(A, B))\) 求出 \(x\)。注意到 \(0\leq B < M, 0\leq A\leq \lceil\frac{p – 1} M \rceil\)(根據歐拉定理,若 \(x\) 有解,則必然存在解在 \([0, p – 2]\) 範圍內),將塊長 \(M\) 設為 \(\lceil\sqrt{p}\rceil\) 即可取到最優複雜度 \(\mathcal{O}(\sqrt{p})\)。
int BSGS(int a, int b, int p) {
int A = 1, B = sqrt(p) + 1; a %= p, b %= p;
gp_hash_table <int, int> mp;
for(int i = 1; i <= B; i++) mp[1ll * (A = 1ll * A * a % p) * b % p] = i;
for(int i = 1, AA = A; i <= B; i++, AA = 1ll * AA * A % p)
if(mp.find(AA) != mp.end()) return i * B - mp[AA];
return -1;
}
容易發現 BSGS 求得的是 \(\log_a b\) 的最小的非負整數解,因為我們從小到大枚舉指數。
關於 \(\log_a b\) 即使得 \(a ^ x \equiv b \pmod p\) 成立的 \(x\) 的循環節長度,詳見 6.1 階。
3.2 擴展大步小步算法
對於更加 general 的離散對數方程 \(a^x\equiv b\pmod p\),如果沒有 \(a\perp p\) 該怎麼辦呢?
核心思想是從已知到未知:既然有了可以解決 \(a\perp p\) 的 BSGS,那麼我們嘗試把 \(a,p\) 湊成互質。如果給等式兩邊同時除以 \(d = \gcd(a, p)\),則方程變為 \(\dfrac a d a ^ {x – 1} \equiv \dfrac b d \pmod{\dfrac p d}\)。若 \(d \nmid b\) 顯然無解。
注意到 \(\dfrac a d \perp \dfrac p d\),因此前者在模後者意義下存在逆元。但因為 \(p\) 可能不是質數,故需 exgcd 求解逆元。移項,方程變為 \(a ^ {x – 1} \equiv \dfrac b d \times \left(\dfrac a d \right) ^ {-1} \pmod {\dfrac p d}\),等式右邊可視作常數。
因為 \(a\) 與 \(\dfrac p {\gcd(a, p)}\) 可能不互質,如 \(a = 2\),\(p = 4\),故重複上述操作直到 \(a, p\) 互質,此時直接使用 BSGS 求解即可。
設提出的 \(a\) 的個數為 \(k\),即 \(\gcd(a, p) \neq 1\) 時上述操作的次數,則求得的解還應加上 \(k\)。注意在每一次操作開始前特判 \(b = 1\),此時答案等於 \(k\)。
時間複雜度 \(\mathcal{O}(\sqrt p + \log ^ 2 p)\),分別是 BSGS 以及求 \(\log\) 次 \(\gcd\) 和乘法逆元的複雜度。代碼見例題 III.
3.3 例題
I. P3846 [TJOI2007] 可愛的質數 /【模板】BSGS
BSGS 模板題。
II. P2485 [SDOI2011]計算器
操作 1 快速冪,操作 2 exGCD 求逆元,操作 3 BSGS。
III. SP3105 MOD – Power Modulo Inverted
exBSGS 模板題。
#include <bits/stdc++.h>
#include <ext/pb_ds/assoc_container.hpp>
using namespace std;
using namespace __gnu_pbds;
int a, p, b;
void exgcd(int a, int b, int &x, int &y) {
if(!b) return x = 1, y = 0, void();
exgcd(b, a % b, y, x), y -= a / b * x;
}
int inv(int x, int p) {return exgcd(x, p, x, *new int), (x % p + p) % p;}
int BSGS(int a, int b, int p) {
a %= p, b %= p;
int A = 1, B = sqrt(p) + 1;
gp_hash_table <int, int> mp;
for(int i = 1; i <= B; i++) mp[1ll * (A = 1ll * A * a % p) * b % p] = i;
for(int i = 1, AA = A; i <= B; i++, AA = 1ll * AA * A % p) if(mp.find(AA) != mp.end()) return i * B - mp[AA];
return -1;
}
int exBSGS(int a, int b, int p) {
int d = __gcd(a, p), cnt = 0;
a %= p, b %= p;
while(d > 1) {
if(b == 1) return cnt;
if(b % d) return -1;
p /= d, b = 1ll * b / d * inv(a / d, p) % p;
d = __gcd(p, a %= p), cnt++;
}
int ans = BSGS(a, b, p);
return ~ans ? ans + cnt : -1;
}
int main() {
cin >> a >> p >> b;
while(a) {
int ans = exBSGS(a, b, p);
if(~ans) cout << ans << "\n";
else puts("No Solution");
cin >> a >> p >> b;
}
return 0;
}
IV. P3306 [SDOI2013] 隨機數生成器
我們嘗試用《具體數學》給出的方法推公式。不妨令下標左移一位,即題目中給出的數視作 \(x_0\)。
令 \(s_i = \dfrac{x_i} {a ^ i}\),那麼 \(a ^ i s_i = a ^ i s_{i – 1} + b\),即 \(s_i = s_{i – 1} + \dfrac b{a ^ i}\),同時 \(s_0 = x_0\)。不難發現 \(s_i = x_0 + \sum\limits_{j = 1} ^ i \dfrac b {a ^ j}\),那麼
x_i & = a ^ i s_i \\
& = a ^ i x_0 + b \sum_{j = 0} ^ {i – 1} a ^ j \\
& = a ^ i x_0 + b \dfrac {a ^ i – 1} {a – 1} \\
& = a ^ i \left(x_0 + \dfrac b {a – 1} \right) – \dfrac b {a – 1}
\end{aligned}
\]
是裸的 BSGS。注意特判 \(a = 0\) 和 \(a = 1\)。時間複雜度 \(\mathcal{O}(T\sqrt p)\)。
4. 線性同餘方程組
前置知識:擴展歐幾里得算法。
求解形如
x \equiv a_1 \pmod {m_1} \\
x \equiv a_2 \pmod {m_2} \\
\cdots \\
x \equiv a_k \pmod {m_k}
\end{cases}
\]
的 線性同餘方程組 是信息學競賽的常見內容。線性同餘方程組涉及方面十分廣泛(從多模 NTT 到高次剩餘),因為它可以處理模數不是質數的情況,或者合併問題中的循環節。
- Note:excrt 比 crt 更容易理解且適用範圍更廣泛,因此筆者在合併線性同餘方程組時一般使用 excrt。
4.1 中國剩餘定理
中國剩餘定理全稱 Chinese Remainder Theorem,簡稱 CRT。它用於求解 模數兩兩互質 的線性同餘方程組,即對於任意 \(i \neq j\),均有 \(m_i \perp m_j\)。
CRT 的大致思想是求出若干數,使得這些數依次滿足某一個同餘方程組,且在其它模數意義下均為 \(0\)。則這些數的和即為所求。
根據上述初步感知,我們令 \(M = \prod m_i\),並嘗試為每個同餘方程構造 \(x_i \equiv a_i\pmod {m_i}\),記為條件一;且對於 \(j \neq i\) 均有 \(x_i\equiv 0 \pmod {m_j}\),記為條件二。我們將目光放在單個同餘方程 \(x_i \equiv a_i \pmod {m_i}\) 上。
首先,為滿足條件二,\(x_i\) 應為 \(\prod\limits_{j \neq i} m_j\) 即 \(\dfrac M {m_i}\) 的倍數。令其為 \(c_i\)。我們發現令 \(x_i\) 等於 \(a_i c_i\) 即可滿足條件二。為滿足條件一,我們發現 \(c_i\) 和 \(m_i\) 互質(題目條件可推得),因此只需為 \(c_i\) 再乘上其在模 \(m_i\) 意義下的逆元即可。令 \(d_i\) 為 \(c_i ^ {-1} \pmod {m_i}\),則 \(x_i = a_ic_id_i\) 滿足兩個條件。注意,\(d_i\) 需要通過 exgcd 求解,因為 \(m_i\) 可能不是質數。
對每個模數均進行一遍上述流程,則 \(\sum a_ic_id_i\) 即為所求。時間複雜度線性對數。模板題代碼見例題 I.
4.2 擴展中國剩餘定理
擴展中國剩餘定理簡稱 excrt。它用於求解 一般形式 的線性同餘方程組。它和中國剩餘定理在本質上沒有任何聯繫,僅是求解的問題形式相同。
- 筆者認為 excrt 更簡單一些。
當模數不互質時,考慮合併兩個同餘方程 \(x\equiv a_1\pmod {m_1}\) 和 \(x\equiv a_2\pmod {m_2}\)。因為 \(x\) 可以表示成 \(a_1+pm_1\),所以 \(a_1+pm_1\equiv a_2\pmod {m_2}\),即 \(pm_1+qm_2\equiv a_2-a_1\pmod {m_2}\),exgcd 求解即可(或者可以理解為 \(p \equiv \dfrac {a_2 – a_1}{m_1} \pmod {m_2}\) 用 exgcd 求逆元,兩種方法本質相同)。合併後的方程即 \(x\equiv a_1+pm_1\pmod {\mathrm{lcm}(m_1,m_2)}\)。
根據裴蜀定理,若 \(\gcd(m_1,m_2)\nmid a_2-a_1\),則方程組無解。時間複雜度線性對數,模板題代碼見例題 II.
- 記得考慮 exgcd 解出來是負數的情況。在得到解之後需要進行取模。
4.3 例題
I. P1495 【模板】中國剩餘定理(CRT)/曹沖養豬
中國剩餘定理模板題。注意要使用 int128 或慢速乘。
#include <bits/stdc++.h>
using namespace std;
const int N = 10 + 5;
int n, a[N], b[N];
long long M = 1, ans;
void exgcd(int a, int b, int &x, int &y) {
if(!b) return x = 1, y = 0, void();
exgcd(b, a % b, y, x), y -= a / b * x;
}
int inv(int x, int p) {return exgcd(x, p, x, *new int), (x % p + p) % p;}
int main() {
cin >> n;
for(int i = 1; i <= n; i++) cin >> a[i] >> b[i], M *= a[i];
for(int i = 1; i <= n; i++) ans = (ans + (__int128)b[i] * (M / a[i]) * inv(M / a[i] % a[i], a[i])) % M;
cout << ans << endl;
return 0;
}
II. P4777 【模板】擴展中國剩餘定理(EXCRT)
excrt 模板題。
#include <bits/stdc++.h>
using namespace std;
long long n, a, b, c, d;
void exgcd(long long a, long long b, long long &x, long long &y) {
if(!b) return x = 1, y = 0, void();
exgcd(b, a % b, y, x), y -= a / b * x;
}
int main() {
cin >> n >> a >> b;
for(int i = 1; i < n; i++) {
cin >> c >> d;
long long e = __gcd(a, c), f = (d - b % c + c) % c, inv;
c /= e, f /= e;
exgcd(a / e, c, inv, *new long long), inv = (inv % c + c) % c;
b += (__int128)f * inv % c * a, a *= c, b %= a;
}
cout << b << endl;
return 0;
}
III. P4774 [NOI2018] 屠龍勇士
設第 \(i\) 次選用的劍的攻擊力為 \(c_i\),可以通過 multiset 模擬確定。問題轉化為找到最小的 \(x\) 使得對於所有 \(i\) 都有 \(c_ix\equiv a_i\pmod {p_i}\) 且 \(c_ix\geq p_i\)。
先求出 \(d_i=\gcd(c_i,p_i)\),若 \(d_i\nmid a_i\) 則無解,否則將 \(a_i,c_i,p_i\) 同時除以 \(d_i\),此時有 \((c_i,p_i)=1\),把 \(c_i\) 除過去就是標準的線性同餘方程組。excrt 求解得到 \(x\)。
為滿足第二個條件,我們可以先求出 \(e_i = \left \lceil \dfrac {a_i} {c_i} \right \rceil\) 表示打敗 Boss \(i\) 至少要多少次攻擊。若最終求得的 \(x < \max e_i\),那麼需將 \(x\) 加上 \(\left \lceil \dfrac {(\max e_i) – x} {p} \right \rceil \times p\),其中 \(p\) 是最終的同餘方程的模數。時間複雜度線性對數。代碼。
IV. P4621 [COCI2012-2013#6] BAKTERIJE
細菌的運動情況會在不超過 \(4\times n^2=10^4\) 次後形成循環,因此先 BFS 找環,特判前 \(10^4\) 次運動,然後 \(4^k\) 枚舉每個細菌進入 \((x,y)\) 時的方向,從而唯一確定一個線性方程組,excrt 即可。
時間複雜度 \(\mathcal{O}(4^kk\log V)\),其中 \(V\) 是值域。由於每次添加的模數很小,只有 \(10^4\) 級別,可直接循環枚舉。
V. P2480 [SDOI2010]古代豬文
求 \(g ^ {\sum\limits_{d\mid n} \binom n d}\bmod 999911659\)。指數對 \(999911658\) 取模,分解質因數後發現是 square-free number,直接 lucas + crt 即可。時間複雜度 \(d(n) \log n\)。
lucas 見第八章。
5. 數論分塊
數論分塊又稱整除分塊,因其解決的問題與整除密切相關而得名。具體地,數論分塊用於求解形如
\]
的和式。前提是 \(f\) 的前綴和容易快速計算。
讀者需要有這樣的感性認知:使得 \(n\) 除以 \(x\) 下取整後等於 \(k\) 的正整數 \(x\) 的範圍為 \(\left(\dfrac{n}{k + 1}, \dfrac n k \right] \cup \N_{+}\),即 \(\left[\left\lfloor \dfrac n {k + 1}\right\rfloor + 1, \left\lfloor \dfrac n k\right\rfloor \right]\)。
5.1 算法介紹
部分摘自 OI wiki。
感性認知:當 \(i\) 較大時,\(i\) 的取值很多,但 \(\left\lfloor \dfrac {n} {i} \right\rfloor\) 被限制在較小的範圍內,因此很多 \(\left\lfloor \dfrac {n} {i}\right\rfloor\) 均相同。
-
數論分塊的時間複雜度基於以下引理(記作引理 5.1):對於任意 \(n\in \N_+\) 以及 \(i\in [1, n]\),不同的 \(\left\lfloor \dfrac {n} {i}\right\rfloor\) 至多 \(2\sqrt n\) 個。證明:當 \(i \leq \sqrt n\) 時,\(\left\lfloor \dfrac {n} {i}\right\rfloor\) 顯然只有 \(\sqrt n\) 個。當 \(i \geq \sqrt n\) 時,\(\left\lfloor \dfrac {n} {i}\right\rfloor \leq \sqrt n\),因此也只有 \(\sqrt n\) 個。證畢。
-
數論分塊的正確性基於以下(記作引理 5.2)引理:\(\left\lfloor \dfrac {a} {bc}\right\rfloor = \left\lfloor \dfrac {\left\lfloor \frac {a} {b}\right\rfloor} {c}\right\rfloor\)。即先除以一個數,下取整後再除以一個數再下取整,等於除以這兩個數的乘積後下取整。證明:令 \(a = db + r\),則 \(\left\lfloor \dfrac {a} {bc}\right\rfloor = \left\lfloor \dfrac {d + \frac r b} {c}\right\rfloor\)。因為 \(0\leq \dfrac r b < 1\),而 \(c, d\) 均為整數,所以 \(\dfrac r b\) 可忽略。證畢。
數論分塊的結論如下:對於 \(i \in [1, n]\),使得 \(\left\lfloor \dfrac {n} {i}\right\rfloor = \left\lfloor \dfrac {n} {j}\right\rfloor\) 的最大的 \(j\) 等於 \(\left\lfloor \dfrac {n} {\left\lfloor \frac {n} {i}\right\rfloor}\right\rfloor\)。顯然 \(j\) 存在,因為 \(i\) 是 \(j\) 的一個合法取值。
感性證明:令 \(k = \left\lfloor \dfrac {n} {i}\right\rfloor\),\(jk \leq n \Rightarrow j \leq \dfrac {n} {k}\)。因 \(j\) 是整數,故 \(j_{\max} = \left\lfloor \dfrac n k \right\rfloor\)。讀者也可根據本章開頭部分的感性認知來理解。
嚴謹證明:令 \(k = \left\lfloor \dfrac {n} {i}\right\rfloor\),則 \(k \leq \dfrac n i\)。根據引理,\(\left\lfloor \dfrac {n} {k} \right\rfloor \geq \left\lfloor \dfrac {n} {\frac n i}\right\rfloor = i\),所以 \(j\) 等於 \(i\) 的最大值即 \(\left\lfloor \dfrac {n} {k} \right\rfloor\)。若 \(j\) 還可以更大,即 \(\left\lfloor \dfrac {n} {j + 1}\right\rfloor = k\),則 \(\left\lfloor \dfrac {\left\lfloor \frac {n} {j + 1}\right\rfloor} {k}\right\rfloor = 1\),根據引理,即 \(\left\lfloor \dfrac {\left\lfloor \frac {n} {k}\right\rfloor} {j + 1}\right\rfloor = 1\),即 \(\left\lfloor \dfrac {n} {k}\right\rfloor \geq j + 1\)。這和 \(\left\lfloor \dfrac {n} {i}\right\rfloor = j\) 矛盾。證畢。
通過上述分析,我們得到了數論分塊算法的大致輪廓,如下所述。
設 \(s\) 為 \(f\) 的前綴和。\(l\) 從 \(1\) 開始,每次令 \(r \gets \left\lfloor\dfrac n {\left\lfloor\frac n l\right\rfloor}\right\rfloor\),然後將答案加上 \((s(r) – s(l – 1)) \times g\left(\left\lfloor \dfrac {n} {i}\right\rfloor\right)\)。最後令 \(l\gets r+1\),若大於 \(n\) 則退出。
根據引理 5.1,每個不同的 \(\left\lfloor \dfrac {n} {i}\right\rfloor\) 僅會被遍歷一次,故時間複雜度 \(\mathcal{O}(\sqrt n)\)。
- 注意,當 \(i\) 的上界不等於 \(n\) 時,不妨設其為 \(m\),則 \(r\) 應當與 \(m\) 取較小值(\(n > m\) 時會出現該情況),且當 \(\left\lfloor\dfrac n i\right\rfloor = 0\) 時需要特判,直接令 \(r\) 等於 \(m\)(\(n < m\) 時會出現該情況)。
5.2 擴展
5.2.1 向上取整
嘗試將向下取整變為向上取整。
對於左邊界 \(l\),我們求出使得 \(\left\lceil\dfrac n l \right\rceil = \left\lceil\dfrac n r \right\rceil\) 的最大的 \(r\)。不妨設 \(k = \left\lceil\dfrac n l\right\rceil\),則
\]
第二步轉換是因為 \(n, k\) 均為正整數。上述推導類似向下取整時的感性證明部分。
因此,我們只需令 \(r\gets \left\lfloor\dfrac{n – 1}{\left\lceil\frac n l\right\rceil – 1}\right\rfloor\) 即可。
注意特判 \(\left\lceil\dfrac n l\right\rceil=1\) 的情況,此時 \(r\) 的上界為無窮大,需要與實際上界取較小值。
5.2.2 高維數論分塊
當和式中出現若干下取整,形如
\]
時,只需稍作修改,令 \(r = \min\limits_{j = 1} ^ c\left(\left\lfloor \dfrac {n_j} {\left\lfloor \frac {n_j} {i}\right\rfloor}\right\rfloor\right)\) 即可。不要忘記對 \(n\) 取 \(\min\)。
時間複雜度為 \(\sum \sqrt {n_j}\)。將令 \(\left\lfloor \dfrac {n_j} {i}\right\rfloor \neq \left\lfloor \dfrac {n} {i + 1}\right\rfloor\) 的位置視作斷點,則總共的斷點數量為每個下取整式的端點數量相加(而非相乘),而我們只會在每個斷點處遍歷一次,故有該時間複雜度。
5.3 例題
I. 某模擬賽 你還沒有卸載嗎
給定 \(A_1, B_1, A_2, B_2, N\),求有多少 \(x\in [1, N]\) 使得 \(B_1 + \left\lfloor\dfrac{A_1}{x}\right\rfloor = B_2 + \left\lfloor\dfrac{A_2}{x}\right\rfloor\)。\(T\leq 2\times 10 ^ 3\),其他所有數 \(\in [1, 10 ^ 8]\)。時限 1s。
筆者嘗試用數學方法推導答案,無果。故考慮數論分塊固定 \(\dfrac{A_1} x\),解出 \(d = \dfrac{A_2}{x}\),從而反推出合法的 \(x\) 的範圍:\([l, r] \cap \left[\dfrac{A_2}{d + 1} + 1, \dfrac{A_2}{d}\right]\)。時間複雜度 \(\mathcal{O}(T\sqrt V)\)。
另一種方法是直接二維數論分塊。細節更少,且時間複雜度不變。
啟示:當用數學手段推導公式無果時可以考慮固定一些變量。
#include <bits/stdc++.h>
using namespace std;
int T, a1, b1, a2, b2, n;
int main() {
cin >> T;
while(T--) {
int ans = 0;
cin >> a1 >> b1 >> a2 >> b2 >> n;
for(int l = 1, r = 1; l <= n; l = r + 1) {
r = min(n, min(a1 / l ? a1 / (a1 / l) : n, a2 / l ? a2 / (a2 / l) : n));
if(b1 + a1 / l == b2 + a2 / l) ans += r - l + 1;
}
cout << ans << endl;
}
return 0;
}
II. *CF1603C. Extreme Extension
數論分塊優化 DP。
一個數如何分裂由後面分裂出來的數的最小值決定,而顯然我們一定是貪心使分出來的數盡量均勻,例如若 \(9\) 要裂成若干個比 \(4\) 小的數那麼 \(3,3,3\) 就比 \(2,3,4\) 更優。
這啟發我們從後往前考慮:對於每個數 \(a_i\) 和數值 \(j\in [1,a_i]\),求出有多少個以 \(a_i\) 開頭的子串使得分裂出的最小值為 \(j\),即求出 \(k\) 的個數使得 \(a_i,a_{i+1},\cdots,a_k\) 根據上述貪心所分裂出來的數的最小值為 \(j\)(顯然這個 \(j\) 也必須由 \(a_i\) 分裂零次或若干次得到),記為 \(f_{i,j}\),那麼答案加上 \(f_{i, j}\times \left(\left\lceil\dfrac{a_i}{j}\right\rceil – 1\right)\times i\):因為至少要分裂 \(\left\lceil\dfrac{a_i}{j}\right\rceil-1\) 次才能讓 \(a_i\leq j\),而以 \(i\) 開頭的每一個子段的左端點還可以被向左擴展 \(i\) 次。即若子段 \([i,k]\) 在 \(i\) 處至少分裂 \(j\) 次,則對於任何子序列 \([l,k](l\leq i\leq k)\),\(a_i\) 分裂的次數都是 \(j\),因為 \(a_i\) 的分裂不受前面的數的影響。這樣的 \(l\) 共有 \(i\) 個,故需乘上 \(i\)(也就是說,我們在每個位置處統計該位置在所有子段中總分裂次數之和)。
看上去有 \(n ^ 2\) 個合法狀態,但有些 \(j\) 是永遠分裂不到的,例如若 \(a_i = 10\) 則 \(j = 9\) 無用,因為如果要使得分裂出來的數 \(\leq 9\),則根據貪心思想我們會分成 \(5, 5\) 而不是 \(1, 9\)。類似的,\(j = 6, 7, 8\) 也無用。
實際上只有所有 \(j\in\left\{\left. \left\lfloor\dfrac{a_i}{d} \right\rfloor \right|\ d\in[1, a_i] \right\}\) 有用,這一點不難證明(注意,給定分裂得到的值計算 分裂次數 是上取整,但給定分裂次數計算 分裂得到的值 是下取整)。而根據數論分塊的結論,有用的 \(j\) 只有 \(\sqrt {a_i}\) 個。
因此,我們可以直接枚舉 \(l,r\) 表示用 \(a_i\) 整除 \(v \in [l, r]\) 上取整 後結果相同的一段區間,這個可以類似數論分塊實現,詳見 基礎數論學習筆記 Part 5.2.1(數論分塊是下取整後相同,而本題是上取整後相同)。則 \(f_{i, j}\) 可以由 \(\sum\limits_{k = l} ^ r f_{i + 1, k}\) 得到,其中 \(j = \left\lfloor\dfrac {a_i} {\left\lceil\frac {a_i} l \right\rceil} \right\rfloor\)。
上述轉移式的來源:給定值 \(j\),要求分裂出來的數均 \(\leq j\),因為我們需要 使分裂次數最小,因此分裂次數是固定的 \(\left\lceil\dfrac {a_i} j \right\rceil\)。因此,使分裂次數相同的值即使 \(a_i\) 整除後上取整相同的一段值域區間 \([l, r]\)。同時,我們分裂得到的數的較小值即 \(\left\lfloor\dfrac {a_i} {\left\lceil\frac {a_i} l \right\rceil} \right\rfloor\),因為分裂了 \(\left\lceil\dfrac {a_i} l \right\rceil\) 次。
用不定長數組 vector 來存儲每一位的答案,時間複雜度 \(\mathcal{O}(n\sqrt {a_i})\),空間複雜度 \(\mathcal{O}(n)\)。代碼。
III. P2260 [清華集訓2012]模積和
求 \(\sum\limits_{i = 1} ^ n n \bmod i\) 是經典問題:拆成 \(\sum\limits_{i = 1} ^ n \left(n – \left\lfloor\dfrac n i\right\rfloor\times i\right)\) 後數論分塊,時間複雜度 \(\mathcal{O}(\sqrt n)\)。
原式可以寫作
\]
全部可以使用數論分塊解決。可能需要的公式:\(\sum_{\\i=1}^ni^2=\dfrac{n(n+1)(2n+1)}6\)。時間複雜度 \(\mathcal{O}(\sqrt n)\)。
6. 階與原根
原根,數論的王!
模 \(n(n > 1)\) 的簡化剩餘系在模 \(n\) 乘法意義下封閉且構成群。容易證明其滿足封閉性和結合律,存在逆元和單位元。將群相關定義應用在其上,得到階和原根(循環群的生成元)的概念。
6.1 階
階的定義如下:使得 \(a ^ x \equiv 1\pmod m\) 的最小的 正整數 \(x\) 被稱為 \(a\) 模 \(m\) 的階,記作 \(\delta_m(a)\)。
容易發現,\(a\perp m\) 是 \(\delta_m(a)\) 存在的 充要條件。必要性:若 \(a\) 與 \(m\) 不互質,顯然 \(a ^ x\) 與 \(m\) 不互質,因此模 \(m\) 不可能得 \(1\)。充分性:若 \(a\perp m\),根據歐拉定理,\(x = \varphi(m)\) 即一解,因此階存在。
- 階就是將一個數自乘若干次後模 \(m\),第一次得到 \(1\) 的自乘次數。之所以是得到 \(1\),因為 \(1\) 的性質很好。例如它和所有數互質,且 \(1\) 的任何次冪均為 \(1\),且 \(1\) 是 \(1\) 在模任何正整數意義下的乘法逆元,因此我們可以在同餘方程的任意位置除以已經被證明等於 \(1\) 的部分,而不需要擔心不存在逆元。
接下來給出一些關於階的性質。以下討論均基於 \(a\perp m\)。
- 若 \(a ^ x\equiv 1\pmod m\),則 \(a ^ {kx}\equiv 1\pmod p\)。因此所有使得 \(a ^ x\equiv 1\pmod p\) 的 \(x\) 必然是 \(x_{\min}\) 即 \(\delta_m(a)\) 的倍數。
性質 1:\(a ^ x \equiv 1\pmod m\) 當且僅當 \(\delta_m(a)\mid x\)。若非,則令 \(r = x\bmod \delta_m(a)\),\(a ^ r\equiv 1\pmod m\),與階的最小性矛盾。
性質 2:\(\delta_m(a ^ k) = \dfrac {\delta_m(a)}{\gcd(\delta_m(a), k)} = \dfrac {\mathrm{lcm}(\delta_m(a), k)}{k}\)。OI wiki 的證明較為複雜,筆者給出一個感性理解。
- 對於第一部分,注意到 \((a ^ k) ^ x = a ^ {kx}\),因此根據性質 1,\(\delta_m(a ^ k)\) 為最小的 \(x\) 使得 \(\delta_m(a) \mid kx\),因此 \(x_{\min} = \dfrac {\delta_m(a)}{\gcd(\delta_m(a), k)}\)(我們知道,若給定 \(a, b\),則使 \(a\mid bx\) 的最小的 \(x\) 為 \(\dfrac {a}{\gcd(a, b)}\),這一點可以對 \(a\) 的每個質因子單獨分析得到)。
- 對於第二部分,因為能夠整除 \(k\) 的最小的 \(\delta_m(a)\) 的倍數為 \(\mathrm{lcm}(\delta_m(a), k)\)(根據最小公倍數的定義易得),所以使得 \(a ^ {kx} \equiv 1\pmod m\) 的最小的 \(kx\) 即 \(\mathrm{lcm}(\delta_m(a), k)\),故 \(x_{\min} = \dfrac {\mathrm{lcm}(\delta_m(a), k)}{k}\)。
- 上述兩部分也可以根據 \(ab = \gcd(a, b) \times \mathrm{lcm}(a, b)\) 互相推導。
回收前文(3.1 BSGS):當 \(a\perp p\) 時,使得 \(a ^ x\equiv b\pmod p\) 的 \(x\) 若存在,則有循環節 \(\delta_p(a)\)。證明顯然。因此,為求出 \(a ^ x\equiv b\pmod p\) 的通解,我們可以求出 \(x\) 的最小解 \(x_0\) 和次小解 \(x_1\),則 \(x = x_0 + k(x_1 – x_0)\ (k\in \N)\),因為 \(x_1 – x_0 = \delta_p(a)\)。
下面給出求解 \(\delta_m(a)\) 的若干方法,其中 \(m \perp a\)。
法一:直接使用 BSGS 求 \(a ^ x\equiv 1 \pmod m\) 的最小正整數解。時間複雜度 \(\sqrt m\)。
法二:根據階的性質 1,對於 \(x = k\delta_m(a)\),必然有 \(a ^ x \equiv 1\pmod m\)。因此考慮首先令 \(x = \varphi(m)\),然後對於 \(\varphi(m)\) 的每個質因子 \(p\),用 \(x\) 不斷試除 \(p\) 直到 \(x\) 無法整除 \(p\) 或 \(a ^ {\frac x p} \not\equiv 1\pmod m\)。時間複雜度 \(\mathcal{O}(\sqrt m + \log ^ 2 m)\),因為需要分解質因數和求解歐拉函數,用 Pollard-rho 可以優化至 \(m ^ {0.25}\)。若 \(m\) 不大,則可 \(\mathcal{O}(m)\) 線性篩預處理每個數的最小質因子,單次查詢即可 \(\log ^ 2 m\)。
6.2 原根
原根的定義如下:對於 \(m\in \N_{+}\),\(a\in \Z\) 且 \(a\perp m\),若 \(\delta_{m}(a) = \varphi(m)\),則稱 \(a\) 為模 \(m\) 的原根。
注意,並不是所有數均有原根。存在原根的模 \(m\) 縮系同構於循環群,因為原根這一概念等價於循環群的生成元。
我們需要原根的原因是它可以 生成 模 \(m\) 的縮系,即它的若干次冪在模 \(m\) 意義下取遍了所有與 \(m\) 互質的數。這使得我們在考慮解與模數互質且模數存在原根的同餘方程時可以用原根的若干次冪代替未知數。這一點在求解高次剩餘時非常有用。
- 我們將在眾多數論毒瘤題中體會到原根威力之強大:它可以將指數上的問題轉化為更簡單的一般問題。
根據原根的定義,為判定 \(a\) 是否是 \(m\) 的原根,只需檢查 \(a\) 的所有 \(\varphi(m)\) 的 真因數 次冪模 \(m\) 是否均不等於 \(1\)。這等價於檢查 \(\varphi(m)\) 除以其質因子是否是 \(a\) 的階的倍數,因為 \(\varphi(m)\) 除以其某一質因子所得的所有數覆蓋了 \(\varphi(m)\) 的所有真因數。因此,我們有
原根判定定理:對於 \(m\geq 3\),\(a\perp m\),\(a\) 是 \(m\) 的原根的 充要條件 是對於任意 \(\varphi(m)\) 的質因子 \(p\),均有 \(a ^ {\frac {\varphi(m)} p} \not\equiv 1\pmod m\)。
證明:必要性顯然。
充分性:因為 \(\dfrac {\varphi(m)} p\) 的所有因子取遍了 \(\varphi(m)\) 除了其本身的所有因子,所以若存在 \(a ^ d\equiv 1\pmod m\) 使得 \(d < \varphi(m)\)(容易證明 \(d\mid \varphi(m)\)),則必然存在 \(\varphi(m)\) 的質因子 \(p\) 使得 \(d \left|\dfrac{\varphi(m)}{p} \right.\),這說明存在 \(a ^ {\frac {\varphi(m)} p} \equiv 1\pmod m\),與假設矛盾。證畢。
除了判斷一個數是否是原根,我們也需要判斷一個數是否有原根。
原根存在定理:一個數 \(m\) 存在原根的 充要條件 是 \(m = 2, 4, p ^ \alpha, 2p ^ \alpha\),其中 \(p\) 是 奇質數。
證明過於複雜,略去。讀者可以當成重要結論記住。
以下是原根與階相結合的一些知識。
若 \(m\) 存在原根,則使得 \(\delta_m(a) = l\) 的 \(a\) 的個數為 \(\begin{cases} 0 & l \nmid \varphi(m) \\ \varphi(l) & l \mid \varphi(m) \end{cases}\)。
根據階的性質 1,第一部分顯然。
考慮證明第二部分:設 \(g\) 為 \(m\) 的一個原根。因為對於任意 \(a\perp m\) 均可表示為 \(g ^ k(0\leq k < \varphi(m))\),所以問題即求出使得 \(\delta_m(g ^ k) = l\) 的 \(k\) 的個數。根據階的性質 2,\(\delta_m(g ^ k) = \dfrac {\delta_m(g)}{\gcd(\delta_m(g), k)}\),因此 \(\dfrac {\varphi(m)}{\gcd(\varphi(m), k)} = l\),即 \(\gcd(\varphi(m), k) = \dfrac {\varphi(m)}l\)。根據歐拉函數的性質 10,滿足該式 \(k\in [0, \varphi(m) – 1]\) 的個數即 \(\varphi\left(\dfrac {\varphi(m)}{\frac{\varphi(m)} l}\right)\),即 \(\varphi(l)\)。
- 形象地說,將 \(g ^ k \bmod m\to g ^ {k + 1}\bmod m\) 看成一個長度為 \(\varphi(m)\) 的環。我們嘗試在環上每次走 \(k\) 步形成一個子環,則 \(g ^ k\) 的階即形成的環長。我們知道,如果在一個長為 \(n\) 的環上每次走 \(k\) 步,則能夠走到的位置模 \(\gcd(n, k)\) 相同,且模 \(\gcd(n, k)\) 相同的位置均能被遍歷到(這是 OI 中的經典結論,見 0.7),即環長為 \(\dfrac n {\gcd(n, k)}\)。因此,為使 \(\dfrac{\varphi(m)}{\gcd(\varphi(m), k )} = l\),即 \(\gcd(\varphi(m), k) = \dfrac {\varphi(m)}{l}\),即環長和步長的 \(\gcd\) 等於形成的子環個數,也等於環長除以子環長。根據歐拉函數的性質 10,合法的 \(k\) 的個數即 \(\varphi(l)\)。
上述結論從側面反映了歐拉函數的性質 7:\(\sum\limits_{d \mid n} \varphi(d) = n\)。\(\sum\limits_{l \mid \varphi(m)} \varphi(l) = \varphi(m)\),即模 \(m\) 的階等於 \(l\) 的數的個數之和(也即在模 \(m\) 意義下存在階的數的個數)等於與 \(m\) 互質的數的個數,而與 \(m\) 互質是在模 \(m\) 意義下存在階的充要條件。
通過上述推導我們得到推論(原根個數定理):若正整數 \(m\) 存在原根,則其原根的個數為 \(\varphi(\varphi(m))\)。
求出一個數的所有原根:考慮求出一個數的任意一個原根 \(g\),根據上述結論,\(g ^ k\bmod m(k \perp \varphi(m))\) 也是 \(m\) 的原根。在 1959 年,中國數學家王元證明了最小原根的級別為 \(\mathcal{O}(m ^ {0.25 + \epsilon})\)。結合原根存在定理和原根判定定理,我們得以在 \(\mathcal{O}(m)\) 預處理每個數的最小質因子後單次 \(\mathcal{O}(m ^ {0.25}\omega(m)\log m)\) 求出 \(m\) 的最小原根,從而求出 \(m\) 的所有原根。
- 筆者在上網查找資料時發現中國科學院院士王元於 2021 年 5 月 14 日去世,為此筆者深感痛心。可能這位前輩也沒有想到,在六十多年後的今天,他的研究成果已經成為信息學競賽中數論領域的重要一環。筆者在此對他表示崇高的敬意。
關於原根,還有一個有趣且重要的性質:
若 \(m\) 存在原根 \(g\),設 \(n = \varphi(m)\),則 \(m\) 的簡化剩餘系與 \(n\) 次單位根 同構。
這是因為對於任何一個 \(a \perp m\),其均可以寫成 \(g ^ k\) 的形式。而任何一個 \(n\) 次單位根 \(\omega_k\) 也可以寫成 \(\omega_1 ^ k\) 的形式。同時,\(g ^ k \equiv 1\pmod p\),且 \(\omega_1 ^ n = 1\)。因此,我們可以將單位圓應用在 \(m\) 的簡化剩餘繫上,為原根提供了一個形象的表示方法,如下圖。
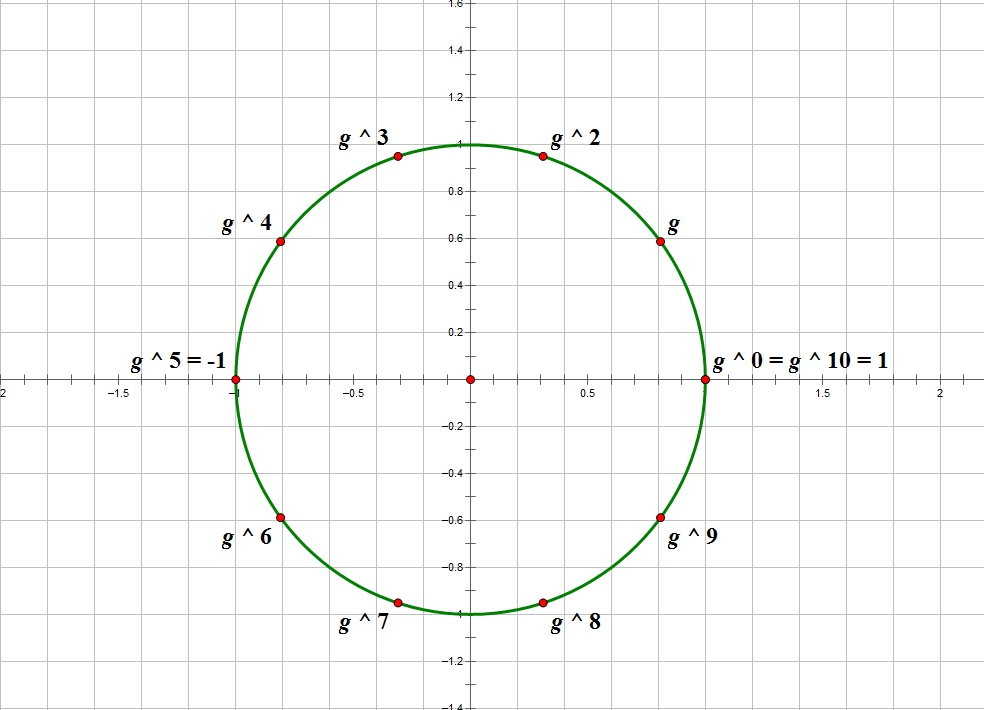
圖中,單位根的 \(0\sim 9\) 次冪將單位圓若干等分。\(10\) 次單位根 \(\omega_i \times \omega_j = \omega_{(i + j)\bmod 10}\) 恰好對應着 \(g ^ i\times g ^ j \equiv g ^ {(i + j)\bmod 10}\pmod {11}\),圓環上運算(兩個數相乘)的循環往複(體現為逆時針旋轉)體現了 模 這一操作。
這也是為什麼對於特定模數,我們可以使用原根代替 \(n\) 次單位根進行快速傅里葉變換:\(\varphi(998244353) = 2 ^ {22}\times 238\),所以當需要使用 \(2 ^ k\) 次單位根時,若 \(k\) 不超過 \(\varphi(p)\) 當中質因子 \(2\) 的個數且 \(p\) 存在原根,即可用原根代替 \(2 ^ k\) 次單位根。也就是快速數論變換 NTT。
6.3 相關應用
總結一下,我們提出階的定義是為了引出原根(至少在筆者所接觸過的所有題目中,沒有遇到直接與階相關的問題),而原根的用處在於生成模 \(m\) 的簡化剩餘系。不要小看這個性質!它在 \(m\) 是質數或質數的冪時非常好用,可以生成除了 \(0\) 以外的任何數,幾乎是神一樣的存在!
我們介紹了階的相關性質及其求法,以及原根的判定定理,存在定理與個數定理。其中,原根存在定理和最小原根級別的證明較為複雜,故略去,學有餘力的讀者可自行查閱資料。
- 在特定模數下,原根用於替換複數單位根進行快速傅里葉變換,如常見 NTT 模數 \(998244353\),\(1004535809\) 等等。
- 求解高次剩餘時,一步重要的轉化是 將未知數用原根的若干次冪代替。
7. 高次剩餘問題
- Warning:本章難度較大。
若 \(b\) 在模 \(p\) 意義下能表示為某個數 \(x\) 的 \(a\) 次方,則稱 \(b\) 為模 \(p\) 意義下的 \(a\) 次剩餘。
\(a\) 次剩餘問題即求解形如 \(x ^ a\equiv b\pmod p\) 的方程。注意未知量 \(x\) 在底數處,而非離散對數問題的指數處。
7.1 拉格朗日定理
我們知道代數學基本定理:任何 \(n\) 次多項式在複數域有且只有 \(n\) 個可重根。那麼,在模意義下是否仍然滿足多項式的 不同 的根的個數不超過多項式係數呢?
拉格朗日定理告訴我們如下事實:對於模 質數 \(p\) 意義下的整係數多項式 \(f(x) = \sum\limits_{i = 0} ^ n a_i x ^ i\),其中 \(p\nmid a_n\),則 \(f(x)\equiv 0\pmod p\) 在模 \(p\) 意義下 至多 有 \(n\) 個 不同 解。
證明:考慮數學歸納法。當 \(n = 0\) 時成立,因為 \(a_0 \equiv 0\pmod p\) 無解(注意 \(p\nmid a_0\))。
當 \(n > 0\) 時,不妨設方程有 \(n + 1\) 個 不同 解 \(x_0, x_1, \cdots, x_n\)。因為 \(f(x_0) \equiv 0\pmod p\),所以 \(f(x)\) 必然可以被因式分解為 \((x – x_0)g(x)\),其中 \(g(x)\) 是一個不超過 \(n – 1\) 次的多項式。
因為 \(x_i \neq x_0(1\leq i \leq n)\) 且 \((x_i – x_0)g(x_i) \equiv 0\pmod p\),故 \(x_1, x_2, \cdots, x_n\) 均為 \(g(x)\) 的根,與歸納假設矛盾。命題得證。
7.2 二次剩餘
7.2.1 定義與符號
根據定義,若存在 \(x\) 使得 \(x ^ 2 \equiv a\pmod p\),則稱 \(a\) 為模 \(p\) 的 二次剩餘,反之則稱 \(a\) 為模 \(p\) 的 二次非剩餘。注意,這兩個定義均基於 \(a\) 不是 \(p\) 的倍數的基礎上。也就是說,若 \(a\) 是 \(p\) 的倍數,則 \(a\) 既不是模 \(p\) 的二次剩餘,也不是模 \(p\) 的二次非剩餘。
勒讓德符號:記作 \(\left(\dfrac a p\right)\)。當 \(a\) 是模 \(p\) 的二次剩餘時,該值為 \(1\);當 \(a\) 是模 \(p\) 的二次非剩餘時,該值為 \(-1\);當 \(a\) 是 \(p\) 的倍數時,該值為 \(0\)。
- 勒讓德符號在二次互反律的表示中很有用,但是我們不講二次互反律。
- 直觀認知:能被表示成 \(g ^ {2k}\) 的數是二次剩餘,反之則是二次非剩餘。設 \(a = g ^ k\),\(x = g ^ y\),則 \(x ^ 2 = g ^ {2y}\)。要使 \(x ^ 2 \equiv a\pmod p\),則 \(k\equiv 2y\pmod {p – 1}\)。因為 \(p – 1\) 是偶數,所以當 \(k\) 為奇數時,\(y\) 無解,反之則有兩解(詳見 1.4 節第三條),每一個 \(y\) 的解對應一個 \(x = g ^ y\)。
7.2.2 二次剩餘的數量
以下討論均基於 \(p\) 為奇質數。
根據拉格朗日定理,對於二次剩餘 \(a\),使得 \(x ^ 2 \equiv a\pmod p\) 成立的不同的 \(x\) 恰有兩個。不妨設 \(x_0\) 為其中一解,顯然 \(x_1 = -x_0\) 也為一解,且因 \(p\) 是奇質數所以 \(x_0\not\equiv x_1 \pmod p\)。這說明若 \(a\) 為模 \(p\) 的二次剩餘,則存在兩個不同且互為相反數的使 \(x ^ 2\equiv a \pmod p\) 成立的 \(x\)。
如果不用拉格朗日定理,我們也可以證明這一結論(思路來自 Kewth,詳見參考資料):設 \(x_0\) 和 \(x_1\) 是任意兩個不同的使方程成立的解,則 \(x_0 ^ 2 \equiv x_1 ^ 2\pmod p\),即 \((x_0 – x_1)(x_0 + x_1) \equiv 0\pmod p\)。所以 \(x_0 + x_1 \equiv 0\pmod p\)。這說明 \(x_0\) 和 \(x_1\) 互為相反數。我們知道,一個數的相反數只有一個,因此 \(x\) 至多且必然有兩解(因為 \(a\) 是二次剩餘)。
- 這和實數意義下的平方根幾乎完全一樣:正數(二次剩餘)的平方根有兩個且互為相反數,負數(二次非剩餘)沒有平方根。
因為 \(1\sim p – 1\) 當中任意一對相反數均給出相同且獨一無二的二次剩餘,故模奇質數 \(p\) 意義下二次剩餘的數量和二次非剩餘的數量均為 \(\dfrac {p – 1}2\)。
- 感性認知:所有原根的偶數次冪和所有原根的奇數次冪將 \(1\sim p – 1\) 分成了兩類,偶數類對應二次剩餘,奇數類對應二次非剩餘。
7.2.3 歐拉判別準則
- \(\dfrac {p – 1} 2\) 的偶數倍一定是 \(p – 1\) 的倍數,而 \(\dfrac {p – 1} 2\) 的奇數倍一定不是。\(g ^ {p – 1}\equiv 1\pmod p\),而 \(g ^ {\frac {p – 1} 2}\equiv -1\pmod p\)。
利用歐拉判別準則,我們可以判斷一個數 \(a\) 是否是 奇素數 \(p\) 的二次剩餘。它給出如下定理:
\]
也就是說,當 \(a\) 是二次剩餘時,\(a ^ {\frac {p – 1} 2} \equiv 1\pmod p\)。當 \(a\) 是二次非剩餘時,\(a ^ {\frac {p – 1} 2} \equiv -1\pmod p\)。
證明(來自 Kewth):\(a \mid p\) 時定理顯然成立,考慮 \(a\nmid p\)。根據費馬小定理,\(a ^ {p – 1} \equiv 1\pmod p\)。所以 \(a ^ {\frac {p – 1} 2}\) 只能等於 \(1\) 或 \(-1\)。因此欲證歐拉判別準則,只需證 \(a ^ {\frac {p – 1} 2} \equiv 1\pmod p\) 當且僅當 \(a\) 是二次剩餘。
充分性:當 \(a\) 是二次剩餘時,令 \(x ^ 2 \equiv a\pmod p\)。顯然 \(x\perp p\),因此 \(a ^ {\frac {p – 1} 2} = x ^ {p – 1} \equiv 1\pmod p\)。
必要性:因為 \(p\) 是奇素數,故存在原根 \(g\)。不妨設 \(a \equiv g ^ k\pmod p\)。根據原根的定義,\(g ^ {\frac {p – 1} 2} \not\equiv 1\pmod p\),故 \(g ^ {\frac{p – 1} 2} \equiv -1\pmod p\)。因為 \((g ^ k) ^ {\frac {p – 1} 2} \equiv (-1) ^ k \equiv 1 \pmod p\),所以 \(k\) 為偶數。因此 \(\left(g ^ {\frac k 2}\right) ^ 2 \equiv a \pmod p\),即 \(a\) 為二次剩餘。得證。
-
另一種理解方法:當 \(k\) 為奇數時,\((g ^ k) ^ {\frac {p – 1} 2} = \left(g ^ {\frac {p – 1}2}\right) ^ k \equiv (-1) ^ k = -1\pmod p\)。根據 6.2 節中提到的等價類與單位根的同構性,上述事實恰對應着 \(p – 1\) 次單位根 \(\omega_k\) 當 \(k\) 為偶數時 \(\omega_k ^ {\frac {p – 1} 2} = 1\),當 \(k\) 為奇數時 \(\omega_k ^ {\frac {p – 1}2} = -1\)。
簡單地說,\(a\) 是否是二次剩餘 等價於 \(a ^ {\frac {p – 1} 2}\) 是否等於 \(1\) 等價於 \(a\) 能否被表示成 \(p\) 的一個原根的 偶數 次冪。讀者應當仔細體會其中的等價關係。
歐拉判別準則同時也告訴我們勒讓德符號關於 \(a\) 是完全積性函數,即對於任意 \(a, b\),均有 \(\left(\dfrac a p\right)\left(\dfrac b p\right) = \left(\dfrac {ab} p\right)\)。
接下來介紹一個求解二次剩餘的常用算法。
7.2.4 Cipolla 算法
Cipolla 可以在 \(\rm polylog\) 時間內求解模 奇質數 意義下的二次剩餘,即給定 \(a\),求出使得 \(x ^ 2 \equiv a \pmod p\) 的所有 \(x\)(顯然有根號時間複雜度求解二次剩餘的算法:BSGS)。
根據 7.2.2 節的分析,我們只需求出任意一個 \(x\),然後取相反數即可。
學習 Cipolla 算法,我們首先需要了解 模意義下擴域 的技巧。讀者可以理解為從 「整數」 擴張到了 「整係數複數」。
設 \(\omega\) 為一個二次非剩餘,\(i ^ 2 \equiv \omega\pmod p\)。這樣的 \(i = \sqrt \omega\) 在模 \(p\) 意義下的整數域中不存在,但是我們可以人為規定它存在(類似規定虛數單位 \(i = \sqrt {-1}\) 存在)。因此我們得到了形如 \(a + bi\) 的數。筆者習慣將其稱為模 \(p\) 意義下以 \(\sqrt w\) 為虛數單位的複數。
即定義數域 \(F = \{a + bi \mid a, b \in [0, p – 1] \cup \Z\}\)。容易證明該數域封閉(類比複數域封閉),如乘法運算法則即 \((a + bi)(c + di) = ((ac + bd\omega) \bmod p) + ((ad + bc) \bmod p)i\),且滿足我們常見代數結構的幾乎所有代數性質,如乘法結合律,乘法分配律等。
這個技巧常見於 模意義下二次非剩餘強制開方。例如,\(5\) 在模 \(10 ^ 9 + 7\) 意義下沒有二次剩餘,故在計算斐波那契數列時,需要將一個數表示為 \(a +b\sqrt 5\) 的形式。
- Warning:前方有魔法。
考慮找到一個正整數 \(b\) 使得 \(\omega \equiv b ^ 2 – a\) 為二次非剩餘,令 \(i ^ 2 \equiv b ^ 2 – a\),即 \(i = \sqrt \omega\)。我們斷言 \((b + i) ^ {\frac {p + 1} 2}\) 為 \(a\) 的二次剩餘。
證明 Cipolla 算法的正確性需要兩個引理。
- \(i ^ p \equiv -i\pmod p\)。由歐拉判別準則,\(i ^ {p – 1} \equiv \omega ^ {\frac {n – 1} 2} \equiv -1\pmod p\)。
- \((x + y) ^ p \equiv x ^ p + y ^ p\pmod p\)。由二項式定理,\((x + y) ^ p = \sum\limits_{i = 0} ^ p\dbinom p i x ^ i y ^ {p – i}\),因為當 \(1\leq i < p\) 時,\(\dbinom p i\) 的分子含有質因子 \(p\) 而分母不含,故 \(\dbinom p i\) 為 \(p\) 的倍數。因此我們只需保留 \(i = 0\) 和 \(i = p\) 的項,即 \(x ^ p + y ^ p\)(有讀者可能會因為 \(x\) 是模意義下複數而產生疑問,設 \(x = c +di\),則 \(xp = (cp) + (dp)i \equiv 0 + 0i \equiv 0\pmod p\))。
& \left((b + i) ^ {\frac {p + 1} 2} \right) ^ 2 \\
= \ & (b + i) ^ {p + 1} \\
\equiv \ & (b + i) (b ^ p + i ^ p) \\
\equiv \ & (b + i) (b – i) & (b ^ {p – 1}\equiv 1\pmod p) \\
\equiv \ & b ^ 2 – i ^ 2 \\
\equiv \ & a \pmod p
\end{aligned}
\]
證畢。
接下來是一些需要處理的細節。
- 可以證明當 \(b\) 隨機時,\(b ^ 2 – a\) 的二次剩餘性均勻隨機(但是筆者查閱的所有資料均沒有給出完整證明,故略去)。因此,我們期望隨機兩次就可以找到這樣的 \(b\)。
- 為證明 \((b + i) ^ {\frac {p – 1} 2}\) 的虛部為 \(0\),只需證明不存在 \((c + di) ^ 2\equiv a\pmod p\),其中 \(d\neq 0\)。假設存在,對比等式兩側虛部,必然有 \(2cdi \equiv 0\pmod p\),因此 \(c\equiv 0\pmod p\)。帶入,得 \(d ^ 2\omega = a\)。因為 \(d ^ 2\) 和 \(a\) 均為二次剩餘,所以 \(\omega\) 必然為二次剩餘(勒讓德符號的完全積性),矛盾。證畢。
綜上,Cipolla 算法的時間複雜度為 \(\mathcal{O}(\log p)\)。代碼見例題部分 I.
7.2.5 任意模數二次非剩餘
什麼?怎麼會有出題人毒瘤到考這種玩意?
7.2.6 總結
二次剩餘相關知識繁多,抓住 原根可近似看做單位根 這一關鍵線索有助於更好地理解奇素數 \(p\) 的二次剩餘個數為 \(\dfrac {p – 1} 2\) 這一事實與歐拉判別準則。
從另一種角度:\(a = g ^ k\) 當中 \(k\) 的奇偶性出發,結合 exgcd 的推論(當 \(a, p\) 不互質時方程 \(ax\equiv b\pmod p\) 的解的情況,詳見 1.4 節)也可以推得這些定理。
關於歐拉判別準則,筆者的理解是,對於任意奇素數 \(p\) 均有 \(a ^ {p – 1}\equiv 1\pmod p\)。給指數除以 \(2\) 相當於為左式開根。因此,\(1\sim p – 1\) 當中的所有數會因為自身性質的不同而 分化 成兩類,一類是二次剩餘,滿足 \(a ^ {\frac {p – 1} 2} \equiv 1\pmod p\),另一類是二次非剩餘,滿足 \(a ^ {\frac {p – 1} 2} = -1\pmod p\)。這種分化,用單位根的知識來解釋,即對於 \(p – 1\) 次單位根 \(\omega_k\),當 \(k\) 為偶數時 \(\omega_k ^ {\frac {p – 1} 2} = 1\),反之則為 \(-1\)。而原根和單位根的聯繫
\]
恰好解釋了 \(a = g ^ k\),\(k\) 的奇偶性對 \(a\) 是否是二次剩餘的影響。
因此,筆者認為理解二次剩餘的核心在於體會到 原根和單位根的等價性,以及 原根指數的奇偶性起到的關鍵影響。這對於理解更高次剩餘也有極大幫助。是時候再貼出這張圖了。
Cipolla 算法的巧妙構造令人驚嘆,可惜的是,
「如果讀者或聽眾不能夠理解在人類力所能及的範圍怎樣可能找到這樣一個論證,如果他不能從推導過程中得出任何關於他自己怎樣能找到這樣一個論證的建議,那麼這個推導就可能是難以接受的,而且沒有指導意義。」
所以讀者只需記住這樣的構造:找到 \(b\) 使得 \(b ^ 2 – a\) 是二次非剩餘,令 \(i = \sqrt {b ^ 2 – a}\),則 \((b + i) ^ {\frac{p + 1} 2}\) 即為所求。需要在模意義下擴域。
擴展:注意到當指數為 \(2\) 時,\(a ^ {\frac {p – 1} 2}\) 將 \(1\sim p – 1\) 分成兩類。那麼,當 \(d \mid p – 1\) 時,是否有 \(a ^ {\frac {p – 1} d}\) 的取值將 \(1\sim p – 1\) 分成 \(d\) 類?實際上是有的,讀者可結合 \(p – 1\) 次單位根的性質和 \(k\) 模 \(d\) 的餘數嘗試推導結論。
\]
7.3 高次剩餘
咕咕咕。
7.4 例題
I. P5491 【模板】二次剩餘
#include <bits/stdc++.h>
using namespace std;
mt19937 rnd(time(0));
int T, n, p, b, w;
struct comp {
int a, b;
comp operator + (comp c) {return {(a + c.a) % p, (b + c.b) % p};}
comp operator * (comp c) {return {(1ll * a * c.a + 1ll * b * c.b % p * w) % p, (1ll * a * c.b + 1ll * b * c.a) % p};}
};
int ksm(int a, int b) {int s = 1; while(b) {if(b & 1) s = 1ll * s * a % p; a = 1ll * a * a % p, b >>= 1;} return s;}
comp ksm(comp a, int b) {comp s = {1, 0}; while(b) {if(b & 1) s = s * a; a = a * a, b >>= 1;} return s;}
void solve() {
cin >> n >> p;
if(!n) return puts("0"), void();
if(ksm(n, p - 1 >> 1) == p - 1) return puts("Hola!"), void();
do b = rnd() % p; while(ksm(w = (1ll * b * b - n + p) % p, p - 1 >> 1) != p - 1);
int x = ksm((comp){b, 1}, p + 1 >> 1).a;
cout << min(x, p - x) << " " << max(x, p - x) << "\n";
}
int main(
cin >> T;
while(T--) solve();
return 0;
}
8. 盧卡斯定理
前置知識:組合數,二項式定理。
盧卡斯定理是連接組合數學和數論的重要橋樑。
- Note:相比 Lucas,exLucas 的推導過程更加自然。
8.1 定理介紹
根據 0.6 節的結論,當 \(p\) 是質數時,\(\dbinom n m \bmod p = 0\) 當且僅當 \(n\) 減去 \(m\) 在 \(p\) 進制下需要借位,這等價於 \(n\) 在 \(p\) 進制下的每一位均不小於 \(m\)。
我們知道,當 \(i < j\) 時,\(\dbinom i j\) 定義為 \(0\)。這啟發我們思考,如果將 \(n, m\) 表示為 \(p\) 進制數 \(n = \sum\limits_{i = 0} ^ c a_i p ^ i\) 和 \(m = \sum\limits_{i = 0} ^ c b_i p ^ i\)(不足的位均補 \(0\),即 \(c = \max(\lfloor \log_p n \rfloor, \lfloor \log_p m\rfloor)\)),那麼是否有 \(\dbinom n m\equiv \prod\limits_{i = 0} ^ c \dbinom {a_i}{b_i}\pmod p\)?
首先給出引理:當 \(p\) 是質數時,
\]
是不是感覺非常眼熟?沒錯,在證明 Cipolla 算法的正確性時我們也使用了該引理。
證明:使用二項式定理將上式拆開,當 \(1\leq i < p\) 時 \(\dbinom p i\) 是 \(p\) 的倍數。證畢。
推論:\((1 + x) ^ p \equiv 1 + x ^ p\pmod p\)。
盧卡斯定理有兩種等價的表示方法,一是
\]
二是
\]
其中 \(a_i, b_i\) 分別是 \(n, m\) 在 \(p\) 進制下的表示,即 \(n = \sum a_i p ^ i\),\(m = \sum b_i p ^ i\),且 \(p\) 為質數。
容易證明兩種形式等價,因此我們只需證明第一種形式。
證明:設 \(n = dp + r(0\leq r < p)\),即設 \(d = \left\lfloor \dfrac n p \right\rfloor\),\(r = n\bmod p\),則
& (1 + x) ^ n\\
= \ & (1 + x) ^ {dp} (1 + x) ^ {r} \\
\equiv \ & (1 + x ^ p) ^ {d} (1 + x) ^ {r} \pmod p
\end{aligned}
\]
上式 \(x ^ m\) 前的係數即 \(\dbinom n m\)。
因為 \((1 + x ^ p) ^ d\) 展開後 \(x\) 的次數均為 \(p\) 的倍數,\((1 + x) ^ r\) 展開後 \(x\) 的次數小於 \(p(r < p)\),因此 \(x ^ m\) 項只能由 \((1 + x ^ p) ^ d\) 展開後的 \(x ^ {p\times \lfloor \frac m p \rfloor}\) 項與 \((1 + x) ^ r\) 展開後的 \(x ^ {m\bmod p}\) 項相乘得到。根據二項式定理,命題得證。
根據形式 1, 遞歸實現 Lucas 即可。\(\mathcal{O}(p)\) 預處理階乘及其逆元 \(\mathcal{O}(1)\) 求組合數,單次 Lucas 的時間複雜度為 \(\mathcal{O}(\log_p n)\)。代碼見例題部分 I.
盧卡斯定理告訴我們,當計算一個大組合數對 \(p\) 取模後的值時,可以將 \(n, m\) 在 \(p\) 進制下的每一位分開考慮,再將所得結果相乘。
特別地,若 \(n\) 在 \(p\) 進制下至少有一位小於 \(m\),則 \(\dbinom n m \bmod p = 0\),這是因為對於 \(a_i < b_i\),\(\dbinom {a_i} {b_i} = 0\)。這符合我們一開始的猜想。
利用盧卡斯定理,我們可以快速計算組合數的奇偶性。為使 \(m\) 在二進制下每一位均不大於 \(n\),必然有 \(n\ \&\ m = m\)。因此,\(\dbinom n m\) 是奇數當且僅當 \(n\) 和 \(m\) 的按位與等於 \(m\),或者 \(n\) 和 \(m\) 的按位或等於 \(n\)。
8.2 擴展盧卡斯定理
當模數不是質數的時候,我們也有快速計算 \(\dbinom n m\bmod p\) 的方法。
首先,處理模數 \(p\) 為合數的情況,一般的思路是首先將 \(p\) 分解質因數為 \(\prod q_i ^ {k_i}\),對模每個質數冪的情況單獨求解,再 crt 合併。這就是 crt 的強大威力!
考慮計算 \(\dbinom n m \bmod {q ^ k}\)。自然是將組合數拆成 \(\dfrac {n !} {m!(n – m)!}\) 的形式。因為 \(m!(n – m)!\) 含有質因子 \(q\),所以我們無法直接求解逆元。既然 \(q\) 這麼麻煩,那就除掉好了。
考慮將組合數的分子和分母的所有質因子 \(q\) 全部除掉,即變形為
\]
看起來很嚇人,但實際上我們只是做了一個簡單變形。根據 0.5 節的結論,\(v_q(n!)\) 容易求得(為了求出後面那個 \(q\) 的冪次)。
此時分子和分母均不含因子 \(q\),那麼分別算出分子和分母,再對分母求逆元即可。問題轉化為求 \(\dfrac {n!}{q ^ {v_q(n!)}}\)。
設 \(d = \left\lfloor\dfrac n q\right\rfloor\),\(d_k = \left\lfloor\dfrac n {q ^ k}\right\rfloor\),\(r = n\bmod {q ^ k}\)。既然除掉了所有質因子 \(q\),自然想到將所有數分成 \(q\) 的倍數和非 \(q\) 的倍數討論。
對於 \(q\) 的倍數,有 \(q, 2q, \cdots, dq\),我們給每個數除掉一個 \(q\),驚訝地發現問題變成了求 \(\dfrac{d!}{q ^ {v_q(d!)}}\)。這是一個遞歸形式的子問題,可以遞歸求解。當 \(d = 0\) 時達到遞歸邊界。
對於非 \(q\) 的倍數,它們在模 \(q ^ k\) 意義下形成循環節
\]
因此我們只需計算 \((q ^ k!)_q ^ {d_k} \times (r!)_q \bmod {q ^ k}\)(關於記號,詳見 0.4 威爾遜定理推論部分)。預處理 \(q ^ k\) 以內所有與 \(q\) 互質的數的積的前綴和,該部分可以 \(\mathcal{O}(1)\) 計算。
- Note:根據威爾遜定理的推論(詳見 0.4 節),\((q ^ k!)_q\bmod {q ^ k}\) 等於 \(1\) 或 \(-1\)。因此第一項不需要快速冪,可以直接根據 \(d_k\) 快速計算。
綜合上述討論,我們得到
\]
當 \(n < q\) 時,直接計算返回預處理結果(因為此時 \(\dfrac {n!}{q ^ {v_q(n!)}}\) 等於 \((n!)_q\)),否則使用遞歸式計算即可。單次時間複雜度 \(\mathcal{O}(\log_q n)\)。
- Note:遞歸下去的子問題是除以 \(q\),而循環節個數是除以 \(q ^ k\),一定要注意區分!筆者因為遞歸下去的子問題直接除以 \(q ^ k\) 調了一個小時。
- Note:注意區分 \(\dfrac {n!}{q ^ {v_q(n!)}}\) 和 \((n!)_q\)。前者僅將所有質因子 \(p\) 去掉,而後者將所有含有質因子 \(p\) 的數去掉了。
綜上,我們得以在 \(\omega(p)\log n + \sum {q_i} ^ {k_i}\) 的時間內求出一個大組合數模任意數 \(p\) 的值。若模數固定且使用 \(\sum q_i ^ {k_i}\) 的時間預處理,則可以做到單次 \(\mathcal{O}(\omega(p)\log n)\)。代碼見例題 III.
8.3 例題
I. P3807 【模板】盧卡斯定理
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 5;
int T, n, m, p, fc[N], ifc[N];
int ksm(int a, int b) {int s = 1; while(b) {if(b & 1) s = 1ll * s * a % p; a = 1ll * a * a % p, b >>= 1;} return s;}
int binom(int n, int m) {return 1ll * fc[n] * ifc[m] % p * ifc[n - m] % p;}
int lucas(int n, int m) {
if(n % p < m % p) return 0;
if(n < p) return binom(n, m);
return 1ll * lucas(n / p, m / p) * binom(n % p, m % p) % p;
}
void solve() {
cin >> n >> m >> p;
for(int i = fc[0] = 1; i < p; i++) fc[i] = 1ll * fc[i - 1] * i % p;
ifc[p - 1] = ksm(fc[p - 1], p - 2);
for(int i = p - 2; ~i; i--) ifc[i] = 1ll * ifc[i + 1] * (i + 1) % p;
cout << lucas(n + m, n) << endl;
}
int main() {
cin >> T;
while(T--) solve();
return 0;
}
*II. [BZOJ2445]最大團
定義一張 \(n\) 個點的圖是 「好圖」 當且僅當它能被分成若干大小相等的完全圖。節點有標號。記 \(n\) 個點的好圖個數為 \(G(n)\)。求 \(m ^ {G(n)}\bmod 999999599\)。\(n, m\leq 2\times 10 ^ 9\)。
由於模數是質數,根據歐拉定理轉化為求 \(G(n)\bmod (10 ^ 9 – 402)\)。
被分成的完全圖大小 \(d\) 一定是 \(n\) 的約數,考慮枚舉 \(d\mid n\) 並計算完全圖大小為 \(d\) 時的方案數。
根據組合意義,從 \(n\) 個節點中選出 \(d\) 個點連成完全圖,再從剩下 \(n – d\) 個節點中選出 \(d\) 個點連成完全圖,以此類推。最後剩下的 \(d\) 個節點連成完全圖。由於完全圖之間無序,而我們枚舉完全圖的過程有序,因此還需要除以 \(\dfrac n d\) 的階乘。記 \(c = \dfrac n d\),則
ans & = \dfrac 1 {c!} \dbinom{n} {d, d, \cdots, d} \\
& = \dfrac {n!} {(d!) ^ c \times c!}
\end{aligned}
\]
我們沒有簡單的辦法在優於線性的複雜度內快速計算一個數的階乘,而且模數也不是質數。
觀察 \(99999598\),將其分解質因數後得到 \(2\times 13\times 5281\times 7283\)。這說明模數是 square-free number。考慮分別求上式對這四個質數取模後的結果,最後 crt 合併。
問題轉化為計算 \(ans\) 對質數 \(p\) 取模後的結果,其中 \(p\) 均較小。
對於給定的 \(n\),容易算出 \(n!\) 總共含有多少個質因子 \(p\),即 \(\sum_{\\i \in \N^+} \dfrac n {p ^ i}\)。因此,先求出 \(ans\) 含有多少個質因子 \(p\),若個數 \(>0\) 則直接返回 \(0\)。否則問題轉化為計算一個數 \(v\) 的階乘去掉所有質因子 \(p\) 後模 \(p\) 的結果,記為 \(\mathrm{cal}(v,p)\)。
接下來使用擴展盧卡斯定理的思想。
記 \(d=\left\lfloor\dfrac v p\right\rfloor\) 以及 \(r=v\bmod p\)。我們求出 除去 \(p\) 的倍數 後 \(v!\) 對 \(p\) 取模的值,再乘上 \(\mathrm{cal}(d, p)\)。因為\(p, 2p, \cdots dp\) 這些被忽略的數除以 \(p\) 後變成了子問題 \(\mathrm{cal}(d, p)\)。
因此我們只需求出 \(\prod\limits_{i \in[1, v] \land i \nmid p} i\)。將所有 \(i\) 對 \(p\) 取模,即 \(((p – 1)!) ^ d r!\)。根據威爾遜定理,上式即 \((-1) ^ dr!\),可以 \(\mathcal{O}(p)\) 預處理 \(\mathcal{O}(1)\) 計算。因為最多遞歸 \(\log_p v\) 次(每次將 \(v\) 除以 \(p\)),因此該部分複雜度 \(\mathcal{O}(\log v)\)。
綜上,總時間複雜度 \(\mathcal{O}(d(n)\log n)\)。
#include <bits/stdc++.h>
using namespace std;
const int N = 1e4 + 5;
const int mod = 1e9 - 401;
const int P[4] = {2, 13, 5281, 7283};
int ksm(int a, int b, int p) {
int s = 1;
while(b) {
if(b & 1) s = 1ll * s * a % p;
a = 1ll * a * a % p, b >>= 1;
}
return s;
}
int T, n, m, ans, p, fc[N];
vector <int> factor;
int num(int n) {int s = 0; while(n) s += n /= p; return s;}
int wilson(int n) {
if(n < p) return fc[n];
int d = n / p, r = n % p;
int res = 1ll * wilson(d) * fc[r] % p;
return d & 1 ? p - res : res;
}
int calc(int d) {
if(num(n) > num(n / d) + num(d) * (n / d)) return 0;
return 1ll * wilson(n) * ksm(1ll * wilson(n / d) * ksm(wilson(d), n / d, p) % p, p - 2, p) % p;
}
int query() {
for(int i = fc[0] = 1; i < p; i++) fc[i] = 1ll * fc[i - 1] * i % p;
int res = 0;
for(int d : factor) res = (res + calc(d)) % p;
return res;
}
int main() {
cin >> T;
while(T--) {
cin >> n >> m, m %= mod, ans = 0;
factor.clear(); // add this line =.=
for(int i = 1; i * i <= n; i++)
if(n % i == 0) {
factor.push_back(i);
if(i * i != n) factor.push_back(n / i);
}
int cur = 1;
for(int i = 0; i < 4; i++) {
int res = (p = P[i], query());
int k = 1ll * (res - ans % P[i] + P[i]) * ksm(cur, P[i] - 2, P[i]) % P[i];
ans += k * cur, cur *= P[i], ans %= cur; // excrt
}
cout << ksm(m, ans, mod) << endl;
}
return 0;
}
III. P4720 【模板】擴展盧卡斯定理/exLucas
#include <bits/stdc++.h>
using namespace std;
void exgcd(int a, int b, int &x, int &y) {
if(!b) return x = 1, y = 0, void();
exgcd(b, a % b, y, x), y -= a / b * x;
}
int inv(int x, int p) {return exgcd(x, p, x, *new int), (x % p + p) % p;}
long long n, m;
int p, tp, ans, curp = 1, q, qk, fc[1000005];
long long num(long long n) {long long s = 0; while(n) s += n /= q; return s;}
int calc(long long n) {return n ? 1ll * calc(n / q) * (tp && n / qk & 1 ? qk - 1 : 1) % qk * fc[n % qk] % qk : 1;} // 注意 n / q 和 n / qk!
int solve() {
tp = (qk & 1) || qk <= 4;
for(int i = fc[0] = 1; i < qk; i++) fc[i] = 1ll * fc[i - 1] * (i % q ? i : 1) % qk;
int pw = num(n) - num(m) - num(n - m), res = 1ll * calc(n) * inv(1ll * calc(m) * calc(n - m) % qk, qk) % qk;
while(pw--) res = 1ll * res * q % qk; // 根據 0.6 的結論, 質因子在組合數中的個數為對數級別
return res;
}
int main() {
cin >> n >> m >> p;
for(int i = 2; i <= p; i++) {
if(i * i > p) i = p;
if(p % i == 0) {
q = i, qk = 1;
while(p % i == 0) qk *= i, p /= i;
ans += 1ll * (solve() - ans % qk + qk) * inv(curp, qk) % qk * curp, ans %= (curp *= qk); // excrt 直接合併更方便
}
}
cout << ans << endl;
return 0;
}
9. 結語
數論是信息學競賽的一個廣闊分支。儘管近年來重大考試中涉及數論的題目日漸稀少,但熟練掌握數論相關的各種算法及其推導過程,對我們的思維水平有極大鍛煉。
因為數論,我們得以求解各種各樣的同餘方程(\(ax\equiv b\),\(a ^ x\equiv b\),\(x ^ a\equiv b\));得以利用各種各樣的數論函數和反演公式推式子;得以在模數不是質數時將模數轉化為質數的冪,為使用原根這一殺手鐧提供條件;得以快速計算大組合數取模;我們甚至能夠在亞線性時間內計算積性函數前綴和,這無疑是令人驚嘆的。希望讀者在閱讀的過程中能夠深刻體會到數論之美。
挖坑待填:
- 任意模數非二次剩餘。
- n 次剩餘。
- 莫比烏斯反演與狄利克雷卷積的博客的重構。
- 各種各樣的篩法,如杜教篩,Min_25 篩。
- 類歐幾里得算法。


