JavaSE-萬字長文-加載時間長-小白文
Java語法規範
所有的Java語句必須以;結尾!
無論是()、[]還是{},所有的括號必須一一匹配!
主方法的代碼只能寫在{}中!
Java基礎語法(面向過程)
在學習面向對象之前,我們需要了解面向過程的編程思維,如果你學習過C語言和Python就會很輕鬆!
變量和關鍵字
變量
變量就是一個可變的量,例如定義一個int類型的變量(int就是整數類型):
int a = 10;
a = 20;
a = 30;
我們能夠隨意更改它的值,也就是說它的值是隨時可變的,我們稱為變量。變量可以是類的變量,也可以是方法內部的局部變量(我們現階段主要用局部變量,類變量在面向對象再講解)
變量和C語言中的變量不同,Java中的變量是存放在JVM管理的內存中,C語言的變量存放在內存(某些情況下需要手動釋放內存,而Java會自動幫助我們清理變量佔據的內存)Java和C++很類似,但是沒有指針!Java也叫C++–
Java是強類型語言,只有明確定義了變量之後,你才能使用!一旦被指定某個數據類型,那麼它將始終被認為是對應的類型(和JS不一樣!)
定義一個變量的格式如下:
[類型] [標識符(名字)] = [初始值(可選)]
int a = 10;
注意:標識符不能為以下內容:
- 標識符以由大小寫字母、數字、下劃線(_)和美元符號($)組成,但是不能以數字開頭。
- 大小寫敏感!
- 不能有空格、@、#、+、-、/ 等符號
- 應該使用有意義的名稱,達到見名知意的目的,最好以小寫字母開頭
- 不可以是 true 和 false
- 不能與Java語言的關鍵字重名
關鍵字

包括基本數據類型、流程控制語句等,了解就行,不用去記,後面我們會一點一點帶大家認識!
常量
常量就是無法修改值的變量,常量的值,只能定義一次:
final int a = 10;
a = 10; //報錯!
常量前面必須添加final關鍵字(C語言裏面是const,雖然Java也有,但是不能使用!)
這只是final關鍵字的第一個用法,後面還會有更多的用法。
注釋
養成注釋的好習慣,不然以後自己都看不懂自己的代碼!注釋包括單行注釋和多行注釋:
//我是單行注釋
/**
* 我是
* 多行注釋
*/
//TODO 待做標記
基本數據類型
Java中的數據類型分為基本數據類型和引用類型兩大類,引用類型我們在面向對象時再提,基本數據類型是重點中的重點!首先我們需要了解有哪些類型。然後,我們需要知道的,並不是他們的精度如何,能夠表示的範圍有多大,而是為什麼Java會給我們定義這些類型,計算機是怎麼表示這些類型的,這樣我們才能夠更好的記憶他們的精度、表示的範圍大小。所以,我們從計算機原理的角度出發,帶領大家走進Java的基本數據類型。
這一部分稍微有點燒腦,但是是重中之重,如果你掌握了這些,任何相關的面試題都難不倒你!(如果你學習過計算機組成原理就很好理解了)
計算機中的二進制表示
在計算機中,所有的內容都是二進制形式表示。十進制是以10為進位,如9+1=10;二進制則是滿2進位(因為我們的計算機是電子的,電平信號只有高位和低位,你也可以暫且理解為通電和不通電,高電平代表1,低電平代表0,由於只有0和1,因此只能使用2進制表示我們的數字!)比如1+1=10=2^1+0,一個位也叫一個bit,8個bit稱為1位元組,16個bit稱為一個字,32個bit稱為一個雙字,64個bit稱為一個四字,我們一般採用位元組來描述數據大小。
十進制的7 -> 在二進制中為 111 = 2^2 + 2^1 + 2^0
現在有4個bit位,最大能夠表示多大的數字呢?
- 最小:0000 => 0
- 最大:1111 => 23+22+21+20 => 8 + 4 + 2 + 1 = 15
在Java中,無論是小數還是整數,他們都要帶有符號(和C語言不同,C語言有無符號數)所以,首位就作為我們的符號位,還是以4個bit為例,首位現在作為符號位(1代表負數,0代表正數):
- 最小:1111 => -(22+21+2^0) => -7
- 最大:0111 => +(22+21+2^0) => +7 => 7
現在,我們4bit能夠表示的範圍變為了-7~+7,這樣的表示方式稱為原碼。
計算機中的加減法
原碼
雖然原碼錶示簡單,但是原碼在做加減法的時候,很麻煩!以4bit位為例:
1+(-1) = 0001 + 1001 = 怎麼讓計算機去計算?(雖然我們知道該去怎麼算,但是計算機不知道!)
我們得創造一種更好的表示方式!於是我們引入了反碼:
反碼
- 正數的反碼是其本身
- 負數的反碼是在其原碼的基礎上, 符號位不變,其餘各個位取反
經過上面的定義,我們再來進行加減法:
1+(-1) = 0001 + 1110 = 1111 => -0 (直接相加,這樣就簡單多了!)
思考:1111代表-0,0000代表+0,在我們實數的範圍內,0有正負之分嗎?
- 0既不是正數也不是負數,那麼顯然這樣的表示依然不夠合理!
補碼
根據上面的問題,我們引入了最終的解決方案,那就是補碼,定義如下:
- 正數的補碼就是其本身 (不變!)
- 負數的補碼是在其原碼的基礎上, 符號位不變, 其餘各位取反, 最後+1. (即在反碼的基礎上+1)
其實現在就已經能夠想通了,-0其實已經被消除了!我們再來看上面的運算:
1+(-1) = 0001 + 1111 = (1)0000 => +0 (現在無論你怎麼算,也不會有-0了!)
所以現在,4bit位能夠表示的範圍是:-8~+7(Java使用的就是補碼!)
以上內容是重點, 是一定要掌握的知識,這些知識是你在面試中的最終防線!有了這些理論基礎,無論面試題如何變換,都能夠通過理論知識來破解
整數類型
整數類型是最容易理解的類型!既然我們知道了計算機中的二進制數字是如何表示的,那麼我們就可以很輕鬆的以二進制的形式來表達我們十進制的內容了。
在Java中,整數類型包括以下幾個:
- byte 位元組型 (8個bit,也就是1個位元組)範圍:-128~+127
- short 短整形(16個bit,也就是2個位元組)範圍:-32768~+32767
- int 整形(32個bit,也就是4個位元組)最常用的類型!
- long 長整形(64個bit,也就是8個位元組)最後需要添加l或L
long都裝不下怎麼辦?BigInteger!
數字已經達到byte的最大值了,還能加嗎?為了便於理解,以4bit為例:
0111 + 0001 = 1000 => -8(你沒看錯,就是這樣!)
整數還能使用8進制、16進制表示:
- 十進制為15 = 八進制表示為017 = 十六進制表示為 0xF = 二進制表示 1111 (代碼裏面不能使用二進制!)
字符類型和字符串
在Java中,存在字符類型,它能夠代表一個字符:
- char 字符型(16個bit,也就是2位元組,它不帶符號!)範圍是0 ~ 65535
- 使用Unicode表示就是:\u0000 ~ \uffff
字符要用單引號擴起來!比如 char c = ‘淦’;
字符其實本質也是數字,但是這些數字通過編碼表進行映射,代表了不同的字符,比如字符'A'的ASCII碼就是數字65,所以,char類型其實可以轉換為上面的整數類型。
Java的char採用Unicode編碼表(不是ASCII編碼!),Unicode編碼表包含ASCII的所有內容,同時還包括了全世界的語言,ASCII只有1位元組,而Unicode編碼是2位元組,能夠代表65536種文字,足以包含全世界的文字了!(我們編譯出來的位元組碼文件也是使用Unicode編碼的,所以利用這種特性,其實Java支持中文變量名稱、方法名稱甚至是類名)
既然char只能代表一個字符,那怎麼才能包含一句話呢?(關於數組,我們這裡先不了解,數組我們放在面向對象章節講解)
String就是Java中的字符串類型(注意,它是一個類,創建出來的字符串本質是一個對象,不是我們的基本類型)字符串就像它的名字一樣,代表一串字符,也就是一句完整的話。
字符串用雙引號括起來!比如:String str = “一日三餐沒煩惱”;
小數類型
小數類型比較難理解(比較難理解指的是原理,不是使用)首先來看看Java中的小數類型包含哪些:
- float 單精度浮點型 (32bit,4位元組)
- double 雙精度浮點型(64bit,8位元組)
思考:小數的範圍該怎麼定義呢?我們首先要了解的是小數在計算機裏面是如何存放的:

根據國際標準 IEEE 754,任意一個二進制浮點數 V 可以表示成下面的形式:
V = (-1)^S × M × 2^E
(1)(-1)^S 表示符號位,當 S=0,V 為正數;當 S=1,V 為負數。
(2)M 表示有效數字,大於等於 1,小於 2,但整數部分的 1 不變,因此可以省略。(例如尾數為1111010,那麼M實際上就是1.111010,尾數首位必須是1,1後面緊跟小數點,如果出現0001111這樣的情況,去掉前面的0,移動1到首位;題外話:隨着時間的發展,IEEE 754標準默認第一位為1,故為了能夠存放更多數據,就捨去了第一位,比如保存1.0101 的時候, 只保存 0101,這樣能夠多存儲一位數據)
(3)2^E 表示指數位。(用於移動小數點)
比如: 對於十進制的 5.25 對應的二進制為:101.01,相當於:1.0101*2^2。所以,S 為 0,M 為 1.0101,E 為 2。所以,對於浮點類型,最大值和最小值不僅取決於符號和尾數,還有它的階碼。我們在這裡就不去計算了,想了解的可以去搜索相關資料。
思考:就算double有64bit位數,但是依然存在精度限制,如果我要進行高精度的計算,怎麼辦?BigDecimal!
布爾類型
布爾類型(boolean)只有true和false兩種值,也就是要麼為真,要麼為假,布爾類型的變量通常用作流程控制判斷語句。(C語言一般使用0表示false,除0以外的所有數都表示true)布爾類型佔據的空間大小並未明確定義,而是根據不同的JVM會有不同的實現。
類型轉換
隱式類型轉換
隱式類型轉換支持位元組數小的類型自動轉換為位元組數大的類型,整數類型自動轉換為小數類型,轉換規則如下:
- byte→short(char)→int→long→float→double
問題:為什麼long比float大,還能轉換為float呢?小數的存儲規則讓float的最大值比long還大,只是可能會丟失某些位上的精度!
所以,如下的代碼就能夠正常運行:
byte b = 9;
short s = b;
int i = s;
long l = i;
float f = l;
double d = f;
System.out.println(d);
//輸出 9.0
顯示類型轉換
顯示類型轉換也叫做強制類型轉換,也就是說,違反隱式轉換的規則,犧牲精度強行進行類型轉換。
int i = 128;
byte b = (byte)i;
System.out.println(b);
//輸出 -128
為什麼結果是-128?精度丟失了!
- int 類型的128表示:00000000 00000000 00000000 10000000
- byte類型轉換後表示:xxxxxxxx xxxxxxxx xxxxxxxx 10000000 => -128
數據類型自動提升
在參與運算時(也可以位於表達式中時,自增自減除外),所有的byte型、short型和char的值將被提升到int型:
byte b = 105;
b = b + 1; //報錯!
System.out.println(b);
這個特性是由 Java虛擬機規範 定義的,也是為了提高運行的效率。其他的特性還有:
- 如果一個操作數是long型,計算結果就是long型
- 如果一個操作數是float型,計算結果就是float型
- 如果一個操作數是double型,計算結果就是double型
運算符
賦值和算術運算符
賦值運算符=是最常用的運算符,其實就是將我們等號右邊的結果,傳遞給等號左邊的變量,例如:
int a = 10;
int b = 1 + 8;
int c = 5 * 5;
算術運算符也就是我們在小學階段學習的+ - * / %,分別代表加減乘除還有取余,例如:
int a = 2;
int b = 3;
int c = a * b;
//結果為6
需要注意的是,+還可以用作字符串連接符使用:
System.out.println("lbw" + "nb"); //lbwnb
當然,字符串可以直接連接其他類型,但是會全部當做字符串處理:
int a = 7, b = 15;
System.out.println("lbw" + a + b); //lbw715
算術運算符還包括++和--也就是自增和自減,以自增為例:
int a = 10;
a++;
System.out.println(a); //輸出為11
自增自減運算符放在變量的前後的返回值是有區別的:
int a = 10;
System.out.println(a++); //10 (先返回值,再自增)
System.out.println(a); //11
int a = 10;
System.out.println(++a); //11 (先自增,再返回值)
System.out.println(a); //11
int a = 10;
int b = 2;
System.out.println(b+++a++); //猜猜看結果是多少
為了使得代碼更簡潔,你還可以使用擴展的賦值運算符,包括+=、-=、/=、*=、%=,和自增自減類似,先執行運算,再返回結果,同時自身改變:
int a = 10;
System.out.println(a += 2); //等價於 a = a + 2
關係運算符
關係運算符的結果只能是布爾類型,也就是要麼為真要麼為假,關係運算符包括:
> < == //大於小於等於
>= <= != //大於等於,小於等於,不等於
關係運算符一般只用於基本類型的比較,運算結果只能是boolean:
int a = 10;
int b = 2;
boolean x = a > b;
System.out.println(x);
//結果為 true
邏輯運算符
邏輯運算符兩邊只能是boolean類型或是關係/邏輯運算表達式,返回值只能是boolean類型!邏輯運算符包括:
&& //與運算,要求兩邊同時為true才能返回true
|| //或運算,要求兩邊至少要有一個為true才能返回true
! //非運算,一般放在表達式最前面,表達式用括號擴起來,表示對表達式的結果進行反轉
實際案例來看看:
int a = 10;
int b = 2;
boolean x = a > b && a < b; //怎麼可能同時滿足呢
System.out.println(x); //false
int a = 10;
int b = 2;
boolean x = a > b || a <= b; //一定有一個滿足!
System.out.println(x); //true
int a = 10;
int b = 2;
boolean x = !(a > b); //對結果進行反轉,本來應該是true
System.out.println(x); //false
位運算符
& //按位與,注意,返回的是運算後的同類型值,不是boolean!
| //按位或
^ //按位異或 0 ^ 0 = 0
~ //按位非
按位運算實際上是根據值的二進制編碼來計算結果,例如按位與,以4bit為例:
0101 & 0100 = 0100 (只有同時為1對應位才得1)
int a = 7, b = 15;
System.out.println(a & b); //結果為7
三目運算符
三目運算符其實是為了簡化代碼而生,可以根據條件是否滿足來決定返回值,格式如下:
int a = 7, b = 15;
String str = a > b ? "行" : "不行"; // 判斷條件(只能是boolean,或返回boolean的表達式) ? 滿足的返回值 : 不滿足的返回值
System.out.println("漢堡做的行不行?"+str); //漢堡做的行不行?不行
理解三目運算符,就很容易理解後面的if-else語句了。
流程控制
我們的程序都是從上往下依次運行的,但是,僅僅是這樣還不夠,我們需要更加高級的控制語句來幫我進行更靈活的控制。比如,判斷用戶輸入的數字,大於1則輸出ok,小於1則輸出no,這時我們就需要用到選擇結構來幫助我們完成條件的判斷和程序的分支走向。學習過C語言就很輕鬆!
選擇結構
選擇結構包含if和switch類型,選擇結構能夠幫助我們根據條件判斷,再執行哪一塊代碼。
if語句
就像上面所說,判斷用戶輸入的數字,大於1則輸出ok,小於1則輸出no,要實現這種效果,我們首先可以採用if語句:
if(判斷條件){
//判斷成功執行的內容
}else{
//判斷失敗執行的內容
}
//if的內容執行完成後,後面的內容正常執行
其中,else語句不是必須的。
現在,又來了一個新的需求,用戶輸入的是1打印ok,輸入2,打印yes,其他打印no,那麼這樣就需要我們進行多種條件的判斷了,當然if能進行多分支判斷:
if(判斷條件1){
//判斷成功執行的內容
}else if(判斷條件2){
//再次判斷,如果判斷成功執行的內容
}else{
//上面的都沒成功,只能走這裡
}
同樣,else語句不是必須的。
現在,又來了一個新的需求,用戶輸入1之後,在判斷用戶下一次輸入的是什麼,如果是1,打印yes,不是就打印no,這樣就可以用嵌套if了:
if(判斷條件1){
//前提是判斷條件1要成功才能進來!
if(判斷條件2){
//判斷成功執行的內容
}else{
//判斷失敗執行的內容
}
}
switch語句
我們不難發現,雖然else-if能解決多分支判斷的問題,但是效率實在是太低了,多分支if採用的是逐級向下判斷,顯然費時費力,那麼有沒有一直更專業的解決多分支判斷問題的東西呢?
switch(判斷主體){
case 值1:
//運行xxx
break; //break用於跳出switch語句,不添加會導致程序繼續向下運行!
case 值2:
//運行xxx
break;
case 值3:
//運行xxx
break;
}
在上述語句中,只有判斷主體等於case後面的值時,才會執行case中的語句,同時需要使用break來跳出switch語句,否則會繼續向下運行!
為什麼switch效率更高呢,因為switch採用二分思想進行查找(這也是為什麼switch只能判斷值相等的原因),能夠更快地找到我們想要的結果!
循環結構
小明想向小紅表白,於是他在屏幕上打印了520個 “我愛你”,我們用Java該如何實現呢?
for語句
for語句是比較靈活的循環控制語句,一個for語句的定義如下:
for(初始條件;循環條件;更新){
//循環執行的內容
}
//循環結束後,繼續執行
- 初始條件:循環開始時的條件,一般用於定義控制循環的變量。
- 循環條件:每輪循環開始之前,進行一次判斷,如果滿足則繼續,不滿足則結束,要求為boolean變量或是boolean表達式。
- 更新:每輪循環結束後都會執行的內容,一般寫增量表達式。
初始條件、循環條件、更新條件不是缺一不可,甚至可以都缺!
for(int i = 0;i < 520;i++){
System.out.println("我愛你");
}
for(;;){
//這裡的內容將會永遠地進行下去!
}
增強for循環在數組時再講解!
while循環
while循環和for循環類似,但是它更加的簡單,只需要添加維持循環的判斷條件即可!
while(循環條件){
//循環執行的內容
}
和for一樣,每次循環開始,當循環條件不滿足時,自動退出!那麼有時候我們希望先執行了我們的代碼再去判斷怎麼辦呢,我們可以使用do-while語句:
do{
//執行內容
}while(循環條件);
一定會先執行do裏面的內容,再做判斷!
思考:
for(;;){
}
while(true){
}
//它們的性能誰更高?
Java對象和多態 (面向對象)
面向對象基礎
面向對象程序設計(Object Oriented Programming)
對象基於類創建,類相當於一個模板,對象就是根據模板創建出來的實體(就像做月餅,我們要做一個月餅首先需要一個模具,模具就是我們的類,而做出來的月餅,就是類的實現,也叫做對象),類是抽象的數據類型,並不能代表某一個具體的事物,類是對象的一個模板。類具有自己的屬性,包括成員變量、成員方法等,我們可以調用類的成員方法來讓類進行一些操作。
Scanner sc = new Scanner(System.in);
String str = sc.nextLine();
System.out.println("你輸入了:"+str);
sc.close();
所有的對象,都需要通過new關鍵字創建,基本數據類型不是對象!Java不是純面對對象語言!
不是基本類型的變量,都是引用類型,引用類型變量代表一個對象,而基本數據類型變量,保存的是基本數據類型的值,我們可以通過引用來對對象進行操作。(最好不要理解為引用指向對象的地址,初學者不要談內存,學到JVM時再來討論)
對象佔用的內存由JVM統一管理,不需要手動釋放內存,當一個對象不再使用時(比如失去引用或是離開了作用域)會被JVM自動清理,內存管理更方便!
類的基本結構
為了快速掌握,我們自己創建一個自己的類,創建的類文件名稱應該和類名一致。
成員變量
在類中,可以包含許多的成員變量,也叫成員屬性,成員字段(field)通過.來訪問我們類中的成員變量,我們可以通過類創建的對象來訪問和修改這些變量。成員變量是屬於對象的!
public class Test {
int age;
String name;
}
public static void main(String[] args) {
Test test = new Test();
test.name = "奧利給";
System.out.println(test.name);
}
成員變量默認帶有初始值,也可以自己定義初始值。
成員方法
我們之前的學習中接觸過方法(Method)嗎?主方法!
public static void main(String[] args) {
//Body
}
方法是語句的集合,是為了完成某件事情而存在的。完成某件事情,可以有結果,也可以做了就做了,不返回結果。比如計算兩個數字的和,我們需要得到計算後的結果,所以說方法需要有返回值;又比如,我們只想吧數字打印在控制台,只需要打印就行,不用給我結果,所以說方法不需要有返回值。
方法的定義和使用
在類中,我們可以定義自己的方法,格式如下:
[返回值類型] 方法名稱([參數]){
//方法體
return 結果;
}
- 返回值類型:可以是引用類型和基本類型,還可以是void,表示沒有返回值
- 方法名稱:和標識符的規則一致,和變量一樣,規範小寫字母開頭!
- 參數:例如方法需要計算兩個數的和,那麼我們就要把兩個數到底是什麼告訴方法,那麼它們就可以作為參數傳入方法
- 方法體:方法具體要乾的事情
- 結果:方法執行的結果通過return返回(如果返回類型為void,可以省略return)
非void方法中,return關鍵字不一定需要放在最後,但是一定要保證方法在任何情況下都具有返回值!
int test(int a){
if(a > 0){
//缺少retrun語句!
}else{
return 0;
}
}
return也能用來提前結束整個方法,無論此時程序執行到何處,無論return位於哪裡,都會立即結束個方法!
void main(String[] args) {
for (int i = 0; i < 10; i++) {
if(i == 1) return; //在循環內返回了!和break區別?
}
System.out.println("淦"); //還會到這裡嗎?
}
傳入方法的參數,如果是基本類型,會在調用方法的時候,對參數的值進行複製,方法中的參數變量,不是我們傳入的變量本身!
public static void main(String[] args) {
int a = 10, b = 20;
new Test().swap(a, b);
System.out.println("a="+a+", b="+b);
}
public class Test{
void swap(int a, int b){ //傳遞的僅僅是值而已!
int temp = a;
a = b;
b = temp;
}
}
傳入方法的參數,如果是引用類型,那麼傳入的依然是該對象的引用!(類似於C語言的指針)
public class B{
String name;
}
public class A{
void test(B b){ //傳遞的是對象的引用,而不是值
System.out.println(b.name);
}
}
public static void main(String[] args) {
int a = 10, b = 20;
B b = new B();
b.name = "lbw";
new A().test(b);
System.out.println("a="+a+", b="+b);
}
方法之間可以相互調用
void a(){
//xxxx
}
void b(){
a();
}
當方法在自己內部調用自己時,稱為遞歸調用(遞歸很危險,慎重!)
int a(){
return a();
}
成員方法和成員變量一樣,是屬於對象的,只能通過對象去調用!
對象設計練習
- 學生應該具有以下屬性:名字、年齡
- 學生應該具有以下行為:學習、運動、說話
方法的重載
一個類中可以包含多個同名的方法,但是需要的形式參數不一樣。(補充:形式參數就是定義方法需要的參數,實際參數就傳入的參數)方法的返回類型,可以相同,也可以不同,但是僅返回類型不同,是不允許的!
public class Test {
int a(){ //原本的方法
return 1;
}
int a(int i){ //ok,形參不同
return i;
}
void a(byte i){ //ok,返回類型和形參都不同
}
void a(){ //錯誤,僅返回值類型名稱不同不能重載
}
}
現在我們就可以使用不同的參數,但是支持調用同樣的方法,執行一樣的邏輯:
public class Test {
int sum(int a, int b){ //只有int支持,不靈活!
return a+b;
}
double sum(double a, double b){ //重寫一個double類型的,就支持小數計算了
return a+b;
}
}
現在我們有很多種重寫的方法,那麼傳入實參後,到底進了哪個方法呢?
public class Test {
void a(int i){
System.out.println("調用了int");
}
void a(short i){
System.out.println("調用了short");
}
void a(long i){
System.out.println("調用了long");
}
void a(char i){
System.out.println("調用了char");
}
void a(double i){
System.out.println("調用了double");
}
void a(float i){
System.out.println("調用了float");
}
public static void main(String[] args) {
Test test = new Test();
test.a(1); //直接輸入整數
test.a(1.0); //直接輸入小數
short s = 2;
test.a(s); //會對號入座嗎?
test.a(1.0F);
}
}
構造方法
構造方法(構造器)沒有返回值,也可以理解為,返回的是當前對象的引用!每一個類都默認自帶一個無參構造方法。
//反編譯結果
package com.test;
public class Test {
public Test() { //即使你什麼都不編寫,也自帶一個無參構造方法,只是默認是隱藏的
}
}
反編譯其實就是把我們編譯好的class文件變回Java源代碼。
Test test = new Test(); //實際上存在Test()這個的方法,new關鍵字就是用來創建並得到引用的
// new + 你想要使用的構造方法
這種方法沒有寫明返回值,但是每個類都必須具有這個方法!只有調用類的構造方法,才能創建類的對象!
類要在一開始準備的所有東西,都會在構造方法裏面執行,完成構造方法的內容後,才能創建出對象!
一般最常用的就是給成員屬性賦初始值:
public class Student {
String name;
Student(){
name = "傘兵一號";
}
}
我們可以手動指定有參構造,當遇到名稱衝突時,需要用到this關鍵字
public class Student {
String name;
Student(String name){ //形參和類成員變量衝突了,Java會優先使用形式參數定義的變量!
this.name = name; //通過this指代當前的對象屬性,this就代表當前對象
}
}
//idea 右鍵快速生成!
注意,this只能用於指代當前對象的內容,因此,只有屬於對象擁有的部分才可以使用this,也就是說,只能在類的成員方法中使用this,不能在靜態方法中使用this關鍵字。
在我們定義了新的有參構造之後,默認的無參構造會被覆蓋!
//反編譯後依然只有我們定義的有參構造!
如果同時需要有參和無參構造,那麼就需要用到方法的重載!手動再去定義一個無參構造。
public class Student {
String name;
Student(){
}
Student(String name){
this.name = name;
}
}
成員變量的初始化始終在構造方法執行之前
public class Student {
String a = "sadasa";
Student(){
System.out.println(a);
}
public static void main(String[] args) {
Student s = new Student();
}
}
靜態變量和靜態方法
靜態變量和靜態方法是類具有的屬性(後面還會提到靜態類、靜態代碼塊),也可以理解為是所有對象共享的內容。我們通過使用static關鍵字來聲明一個變量或一個方法為靜態的,一旦被聲明為靜態,那麼通過這個類創建的所有對象,操作的都是同一個目標,也就是說,對象再多,也只有這一個靜態的變量或方法。那麼,一個對象改變了靜態變量的值,那麼其他的對象讀取的就是被改變的值。
public class Student {
static int a;
}
public static void main(String[] args) {
Student s1 = new Student();
s1.a = 10;
Student s2 = new Student();
System.out.println(s2.a);
}
不推薦使用對象來調用,被標記為靜態的內容,可以直接通過類名.xxx的形式訪問
public static void main(String[] args) {
Student.a = 10;
System.out.println(Student.a);
}
簡述類加載機制
類並不是在一開始就全部加載好,而是在需要時才會去加載(提升速度)以下情況會加載類:
- 訪問類的靜態變量,或者為靜態變量賦值
- new 創建類的實例(隱式加載)
- 調用類的靜態方法
- 子類初始化時
- 其他的情況會在講到反射時介紹
所有被標記為靜態的內容,會在類剛加載的時候就分配,而不是在對象創建的時候分配,所以說靜態內容一定會在第一個對象初始化之前完成加載。
public class Student {
static int a = test(); //直接調用靜態方法,只能調用靜態方法
Student(){
System.out.println("構造類對象");
}
static int test(){ //靜態方法剛加載時就有了
System.out.println("初始化變量a");
return 1;
}
}
思考:下面這種情況下,程序能正常運行嗎?如果能,會輸出什麼內容?
public class Student {
static int a = test();
static int test(){
return a;
}
public static void main(String[] args) {
System.out.println(Student.a);
}
}
定義和賦值是兩個階段,在定義時會使用默認值(上面講的,類的成員變量會有默認值)定義出來之後,如果發現有賦值語句,再進行賦值,而這時,調用了靜態方法,所以說會先去加載靜態方法,靜態方法調用時拿到a,而a這時僅僅是剛定義,所以說還是初始值,最後得到0
代碼塊和靜態代碼塊
代碼塊在對象創建時執行,也是屬於類的內容,但是它在構造方法執行之前執行(和成員變量初始值一樣),且每創建一個對象時,只執行一次!(相當於構造之前的準備工作)
public class Student {
{
System.out.println("我是代碼塊");
}
Student(){
System.out.println("我是構造方法");
}
}
靜態代碼塊和上面的靜態方法和靜態變量一樣,在類剛加載時就會調用;
public class Student {
static int a;
static {
a = 10;
}
public static void main(String[] args) {
System.out.println(Student.a);
}
}
String和StringBuilder類
字符串類是一個比較特殊的類,他是Java中唯一重載運算符的類!(Java不支持運算符重載,String是特例)
String的對象直接支持使用+或+=運算符來進行拼接,並形成新的String對象!(String的字符串是不可變的!)
String a = "dasdsa", b = "dasdasdsa";
String l = a+b;
System.out.println(l);
大量進行字符串的拼接似乎不太好,編譯器是很聰明的,String的拼接有可能會被編譯器優化為StringBuilder來減少對象創建(對象頻繁創建時很費時間同時占內存的!)
String result="String"+"and"; //會被優化成一句!
String str1="String";
String str2="and";
String result=str1+str2;
//變量隨時可變,在編譯時無法確定result的值,那麼只能在運行時再去確定
String str1="String";
String str2="and";
String result=(new StringBuilder(String.valueOf(str1))).append(str2).toString();
//使用StringBuilder,會採用類似於第一種實現,顯然會更快!
StringBuilder也是一個類,但是它能夠存儲可變長度的字符串!
StringBuilder builder = new StringBuilder();
builder
.append("a")
.append("bc")
.append("d"); //鏈式調用
String str = builder.toString();
System.out.println(str);
包和訪問控制
包聲明和導入
包其實就是用來區分類位置的東西,也可以用來將我們的類進行分類,類似於C++中的namespace!
package com.test;
public class Test{
}
包其實是文件夾,比如com.test就是一個com文件夾中包含一個test文件夾,再包含我們Test類。
一般包按照個人或是公司域名的規則倒過來寫 頂級域名.一級域名.二級域名 com.java.xxxx
如果需要使用其他包裏面的類,那麼我們需要import(類似於C/C++中的include)
import com.test.Student;
也可以導入包下的全部(一般導入會由編譯器自帶幫我們補全,但是一定要記得我們需要導包!)
import com.test.*
Java默認為我們導入了以下的包,不需要去聲明
import java.lang.*
靜態導入
靜態導入可以直接導入某個類的靜態方法或者是靜態變量,導入後,相當於這個方法或是類在定義在當前類中,可以直接調用該方法。
import static com.test.ui.Student.test;
public class Main {
public static void main(String[] args) {
test();
}
}
靜態導入不會進行類的初始化!
訪問控制
Java支持對類屬性訪問的保護,也就是說,不希望外部類訪問類中的屬性或是方法,只允許內部調用,這種情況下我們就需要用到權限控制符。

權限控制符可以聲明在方法、成員變量、類前面,一旦聲明private,只能類內部訪問!
public class Student {
private int a = 10; //具有私有訪問權限,只能類內部訪問
}
public static void main(String[] args) {
Student s = new Student();
System.out.println(s.a); //還可以訪問嗎?
}
和文件名稱相同的類,只能是public,並且一個java文件中只能有一個public class!
// Student.java
public class Student {
}
class Test{ //不能添加權限修飾符!只能是default
}
數組類型
假設出現一種情況,我想記錄100個數字,定義100個變量還可行嗎?

我們可以使用到數組,數組是相同類型數據的有序集合。數組可以代表任何相同類型的一組內容(包括引用類型和基本類型)其中存放的每一個數據稱為數組的一個元素,數組的下標是從0開始,也就是第一個元素的索引是0!
int[] arr = new int[10]; //需要new關鍵字來創建!
String[] arr2 = new String[10];
數組本身也是類(編程不可見,C++寫的),不是基本數據類型!
int[] arr = new int[10];
System.out.println(arr.length); //數組有成員變量!
System.out.println(arr.toString()); //數組有成員方法!
一維數組
一維數組中,元素是依次排列的(線性),每個數組元素可以通過下標來訪問!聲明格式如下:
類型[] 變量名稱 = new 類型[數組大小];
類型 變量名稱n = new 類型[數組大小]; //支持C語言樣式,但不推薦!
類型[] 變量名稱 = new 類型[]{...}; //靜態初始化(直接指定值和大小)
類型[] 變量名稱 = {...}; //同上,但是只能在定義時賦值
創建出來的數組每個元素都有默認值(規則和類的成員變量一樣,C語言創建的數組需要手動設置默認值),我們可以通過下標去訪問:
int[] arr = new int[10];
arr[0] = 626;
System.out.println(arr[0]);
System.out.println(arr[1]);
我們可以通過數組變量名稱.length來獲取當前數組長度:
int[] arr = new int[]{1, 2, 3};
System.out.println(arr.length); //打印length成員變量的值
數組在創建時,就固定長度,不可更改!訪問超出數組長度的內容,會出現錯誤!
String[] arr = new String[10];
System.out.println(arr[10]); //出現異常!
//Exception in thread "main" java.lang.ArrayIndexOutOfBoundsException: 11
// at com.test.Application.main(Application.java:7)
思考:能不能直接修改length的值來實現動態擴容呢?
int[] arr = new int[]{1, 2, 3};
arr.length = 10;
數組做實參,因為數組也是類,所以形參得到的是數組的引用而不是複製的數組,操作的依然是數組對象本身
public static void main(String[] args) {
int[] arr = new int[]{1, 2, 3};
test(arr);
System.out.println(arr[0]);
}
private static void test(int[] arr){
arr[0] = 2934;
}
數組的遍歷
如果我們想要快速打印數組中的每一個元素,又怎麼辦呢?
傳統for循環
我們很容易就聯想到for循環
int[] arr = new int[]{1, 2, 3};
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
foreach
傳統for循環雖然可控性高,但是不夠省事,要寫一大堆東西,有沒有一種省事的寫法呢?
int[] arr = new int[]{1, 2, 3};
for (int i : arr) {
System.out.println(i);
}
foreach屬於增強型的for循環,它使得代碼更簡潔,同時我們能直接拿到數組中的每一個數字。
二維數組
二維數組其實就是存放數組的數組,每一個元素都存放一個數組的引用,也就相當於變成了一個平面。

//三行兩列
int[][] arr = { {1, 2},
{3, 4},
{5, 6}};
System.out.println(arr[2][1]);
二維數組的遍歷同一維數組一樣,只不過需要嵌套循環!
int[][] arr = new int[][]{ {1, 2},
{3, 4},
{5, 6}};
for (int i = 0; i < 3; i++) {
for (int j = 0; j < 2; j++) {
System.out.println(arr[i][j]);
}
}
多維數組
不止二維數組,還存在三維數組,也就是存放數組的數組的數組,原理同二維數組一樣,逐級訪問即可。
可變長參數
可變長參數其實就是數組的一種應用,我們可以指定方法的形參為一個可變長參數,要求實參可以根據情況動態填入0個或多個,而不是固定的數量
public static void main(String[] args) {
test("AAA", "BBB", "CCC"); //可變長,最後都會被自動封裝成一個數組
}
private static void test(String... test){
System.out.println(test[0]); //其實參數就是一個數組
}
由於是數組,所以說只能使用一種類型的可變長參數,並且可變長參數只能放在最後一位!
實戰:三大基本排序算法
現在我們有一個數組,但是數組裏面的數據是亂序排列的,如何使它變得有序?
int[] arr = {8, 5, 0, 1, 4, 9, 2, 3, 6, 7};
排序是編程的一個重要技能,掌握排序算法,你的技術才能更上一層樓,很多的項目都需要用到排序!三大排序算法:
- 冒泡排序
冒泡排序就是冒泡,其實就是不斷使得我們無序數組中的最大數向前移動,經歷n輪循環逐漸將每一個數推向最前。
- 插入排序
插入排序其實就跟我們打牌是一樣的,我們在摸牌的時候,牌堆是亂序的,但是我們一張一張摸到手中進行排序,使得它變成了有序的!

- 選擇排序
選擇排序其實就是每次都選擇當前數組中最大的數排到最前面!
封裝、繼承和多態
封裝、繼承和多態是面向對象編程的三大特性。
封裝
封裝的目的是為了保證變量的安全性,使用者不必在意具體實現細節,而只是通過外部接口即可訪問類的成員,如果不進行封裝,類中的實例變量可以直接查看和修改,可能給整個代碼帶來不好的影響,因此在編寫類時一般將成員變量私有化,外部類需要同getter和setter方法來查看和設置變量。
設想:學生小明已經創建成功,正常情況下能隨便改他的名字和年齡嗎?
public class Student {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
}
也就是說,外部現在只能通過調用我定義的方法來獲取成員屬性,而我們可以在這個方法中進行一些額外的操作,比如小明可以修改名字,但是名字中不能包含”小”這個字。
public void setName(String name) {
if(name.contains("小")) return;
this.name = name;
}
單獨給外部開放設置名稱的方法,因為我還需要做一些額外的處理,所以說不能給外部直接操作成員變量的權限!
封裝思想其實就是把實現細節給隱藏了,外部只需知道這個方法是什麼作用,而無需關心實現。
封裝就是通過訪問權限控制來實現的。
繼承
繼承屬於非常重要的內容,在定義不同類的時候存在一些相同屬性,為了方便使用可以將這些共同屬性抽象成一個父類,在定義其他子類時可以繼承自該父類,減少代碼的重複定義,子類可以使用父類中非私有的成員。
現在學生分為兩種,藝術生和體育生,他們都是學生的分支,但是他們都有自己的方法:
public class SportsStudent extends Student{ //通過extends關鍵字來繼承父類
public SportsStudent(String name, int age) {
super(name, age); //必須先通過super關鍵字(指代父類),實現父類的構造方法!
}
public void exercise(){
System.out.println("我超勇的!");
}
}
public class ArtStudent extends Student{
public ArtStudent(String name, int age) {
super(name, age);
}
public void art(){
System.out.println("隨手畫個畢加索!");
}
}
子類具有父類的全部屬性,protected可見但外部無法使用(包括private屬性,不可見,無法使用),同時子類還能有自己的方法。繼承只能繼承一個父類,不支持多繼承!
每一個子類必須定義一個實現父類構造方法的構造方法,也就是需要在構造方法開始使用super(),如果父類使用的是默認構造方法,那麼子類不用手動指明。
所有類都默認繼承自Object類,除非手動指定類型,但是依然改變不了最頂層的父類是Object類。所有類都包含Object類中的方法,比如:
public static void main(String[] args) {
Object obj = new Object;
System.out.println(obj.hashCode()); //求對象的hashcode,默認是對象的內存地址
System.out.println(obj.equals(obj)); //比較對象是否相同,默認比較的是對象的內存地址,也就是等同於 ==
System.out.println(obj.toString()); //將對象轉換為字符串,默認生成對象的類名稱+hashcode
}
關於Object類的其他方法,我們會在Java多線程中再來提及。
多態
多態是同一個行為具有多個不同表現形式或形態的能力。也就是同樣的方法,由於實現類不同,執行的結果也不同!
方法的重寫
我們之前學習了方法的重載,方法的重寫和重載是不一樣的,重載是原有的方法邏輯不變的情況下,支持更多參數的實現,而重寫是直接覆蓋原有方法!
//父類中的study
public void study(){
System.out.println("學習");
}
//子類中的study
@Override //聲明這個方法是重寫的,但是可以不要,我們現階段不接觸
public void study(){
System.out.println("給你看點好康的");
}
再次定義同樣的方法後,父類的方法就被覆蓋!子類還可以給父類方法提升訪問權限!
public static void main(String[] args) {
SportsStudent student = new SportsStudent("lbw", 20);
student.study(); //輸出子類定義的內容
}
思考:靜態方法能被重寫嗎?
當我們在重寫方法時,不僅想使用我們自己的邏輯,同時還希望執行父類的邏輯(也就是調用父類的方法)怎麼辦呢?
public void study(){
super.study();
System.out.println("給你看點好康的");
}
同理,如果想訪問父類的成員變量,也可以使用super關鍵字來訪問,注意,子類可以具有和父類相同的成員變量!而在方法中訪問的默認是 形參列表中 > 當前類的成員變量 > 父類成員變量
public void setTest(int test){
test = 1;
this.test = 1;
super.test = 1;
}
再談類型轉換
我們曾經學習過基本數據類型的類型轉換,支持一種數據類型轉換為另一種數據類型,而我們的類也是支持類型轉換的(僅限於存在親緣關係的類之間進行轉換)比如子類可以直接向上轉型:
Student student = new SportsStudent("lbw", 20); //父類變量引用子類實例
student.study(); //得到依然是具體實現的結果,而不是當前類型的結果
我們也可以把已經明確是由哪個類實現的父類引用,強制轉換為對應的類型:
Student student = new SportsStudent("lbw", 20); //是由SportsStudent進行實現的
//... do something...
SportsStudent ps = (SportsStudent)student; //讓它變成一個具體的子類
ps.sport(); //調用具體實現類的方法
這樣的類型轉換稱為向下轉型。
instanceof關鍵字
那麼我們如果只是得到一個父類引用,但是不知道它到底是哪一個子類的實現怎麼辦?我們可以使用instanceof關鍵字來實現,它能夠進行類型判斷!
private static void test(Student student){
if (student instanceof SportsStudent){
SportsStudent sportsStudent = (SportsStudent) student;
sportsStudent.sport();
}else if (student instanceof ArtStudent){
ArtStudent artStudent = (ArtStudent) student;
artStudent.art();
}
}
通過進行類型判斷,我們就可以明確類的具體實現到底是哪個類!
思考:student instanceof Student的結果是什麼?
再談final關鍵字
我們目前只知道final關鍵字能夠使得一個變量的值不可更改,那麼如果在類前面聲明final,會發生什麼?
public final class Student { //類被聲明為終態,那麼它還能被繼承嗎
}
類一旦被聲明為終態,將無法再被繼承,不允許子類的存在!而方法被聲明為final呢?
public final void study(){ //還能重寫嗎
System.out.println("學習");
}
如果類的成員屬性被聲明為final,那麼必須在構造方法中或是在定義時賦初始值!
private final String name; //引用類型不允許再指向其他對象
private final int age; //基本類型值不允許發生改變
public Student(String name, int age) {
this.name = name;
this.age = age;
}
學習完封裝繼承和多態之後,我們推薦在不會再發生改變的成員屬性上添加final關鍵字,JVM會對添加了final關鍵字的屬性進行優化!
抽象類
類本身就是一種抽象,而抽象類,把類還要抽象,也就是說,抽象類可以只保留特徵,而不保留具體呈現形態,比如方法可以定義好,但是我可以不去實現它,而是交由子類來進行實現!
public abstract class Student { //抽象類
public abstract void test(); //抽象方法
}
通過使用abstract關鍵字來表明一個類是一個抽象類,抽象類可以使用abstract關鍵字來表明一個方法為抽象方法,也可以定義普通方法,抽象方法不需要編寫具體實現(無方法體)但是必須由子類實現(除非子類也是一個抽象類)!
抽象類由於不是具體的類定義,因此無法直接通過new關鍵字來創建對象!
Student s = new Student(){ //只能直接創建帶實現的匿名內部類!
public void test(){
}
}
因此,抽象類一般只用作繼承使用!抽象類使得繼承關係之間更加明確:
public void study(){ //現在只能由子類編寫,父類沒有定義,更加明確了多態的定義!同一個方法多種實現!
System.out.println("給你看點好康的");
}
接口
接口甚至比抽象類還抽象,他只代表某個確切的功能!也就是只包含方法的定義,甚至都不是一個類!接口包含了一些列方法的具體定義,類可以實現這個接口,表示類支持接口代表的功能(類似於一個插件,只能作為一個附屬功能加在主體上,同時具體實現還需要由主體來實現)
public interface Eat {
void eat();
}
通過使用interface關鍵字來表明是一個接口(注意,這裡class關鍵字被替換為了interface)接口只能包含public權限的抽象方法!(Java8以後可以有默認實現)我們可以通過聲明default關鍵字來給抽象方法一個默認實現:
public interface Eat {
default void eat(){
//do something...
}
}
接口中定義的變量,默認為public static final
public interface Eat {
int a = 1;
void eat();
}
一個類可以實現很多個接口,但是不能理解為多繼承!(實際上實現接口是附加功能,和繼承的概念有一定出入,頂多說是多繼承的一種替代方案)一個類可以附加很多個功能!
public class SportsStudent extends Student implements Eat, ...{
@Override
public void eat() {
}
}
類通過implements關鍵字來聲明實現的接口!每個接口之間用逗號隔開!
實現接口的類也能通過instanceof關鍵字判斷,也支持向上和向下轉型!
內部類
類中可以存在一個類!各種各樣的長相怪異的代碼就是從這裡開始出現的!
成員內部類
我們的類中可以在嵌套一個類:
public class Test {
class Inner{ //類中定義的一個內部類
}
}
成員內部類和成員變量和成員方法一樣,都是屬於對象的,也就是說,必須存在外部對象,才能創建內部類的對象!
public static void main(String[] args) {
Test test = new Test();
Test.Inner inner = test.new Inner(); //寫法有那麼一絲怪異,但是沒毛病!
}
靜態內部類
靜態內部類其實就和類中的靜態變量和靜態方法一樣,是屬於類擁有的,我們可以直接通過類名.去訪問:
public class Test {
static class Inner{
}
}
public static void main(String[] args) {
Test.Inner inner = new Test.Inner(); //不用再創建外部類對象了!
}
局部內部類
對,你沒猜錯,就是和局部變量一樣噠~
public class Test {
public void test(){
class Inner{
}
Inner inner = new Inner();
}
}
反正我是沒用過!內部類 -> 累不累 -> 反正我累了!
匿名內部類
匿名內部類才是我們的重點,也是實現lambda表達式的原理!匿名內部類其實就是在new的時候,直接對接口或是抽象類的實現:
public static void main(String[] args) {
Eat eat = new Eat() {
@Override
public void eat() {
//DO something...
}
};
}
我們不用單獨去創建一個類來實現,而是可以直接在new的時候寫對應的實現!但是,這樣寫,無法實現復用,只能在這裡使用!
lambda表達式
讀作λ表達式,它其實就是我們接口匿名實現的簡化,比如說:
public static void main(String[] args) {
Eat eat = new Eat() {
@Override
public void eat() {
//DO something...
}
};
}
public static void main(String[] args) {
Eat eat = () -> {}; //等價於上述內容
}
lambda表達式(匿名內部類)只能訪問外部的final類型或是隱式final類型的局部變量!
為了方便,JDK默認就為我們提供了專門寫函數式的接口,這裡只介紹Consumer
枚舉類
假設現在我們想給小明添加一個狀態(跑步、學習、睡覺),外部可以實時獲取小明的狀態:
public class Student {
private final String name;
private final int age;
private String status;
//...
public void setStatus(String status) {
this.status = status;
}
public String getStatus() {
return status;
}
}
但是這樣會出現一個問題,如果我們僅僅是存儲字符串,似乎外部可以不按照我們規則,傳入一些其他的字符串。這顯然是不夠嚴謹的!
有沒有一種辦法,能夠更好地去實現這樣的狀態標記呢?我們希望開發者拿到使用的就是我們定義好的狀態,我們可以使用枚舉類!
public enum Status {
RUNNING, STUDY, SLEEP //直接寫每個狀態的名字即可,分號可以不打,但是推薦打上
}
使用枚舉類也非常方便,我們只需要直接訪問即可
public class Student {
private final String name;
private final int age;
private Status status;
//...
public void setStatus(Status status) { //不再是String,而是我們指定的枚舉類型
this.status = status;
}
public Status getStatus() {
return status;
}
}
public static void main(String[] args) {
Student student = new Student("小明", 18);
student.setStatus(Status.RUNNING);
System.out.println(student.getStatus());
}
枚舉類型使用起來就非常方便了,其實枚舉類型的本質就是一個普通的類,但是它繼承自Enum類,我們定義的每一個狀態其實就是一個public static final的Status類型成員變量!
// Compiled from "Status.java"
public final class com.test.Status extends java.lang.Enum<com.test.Status> {
public static final com.test.Status RUNNING;
public static final com.test.Status STUDY;
public static final com.test.Status SLEEP;
public static com.test.Status[] values();
public static com.test.Status valueOf(java.lang.String);
static {};
}
既然枚舉類型是普通的類,那麼我們也可以給枚舉類型添加獨有的成員方法
public enum Status {
RUNNING("睡覺"), STUDY("學習"), SLEEP("睡覺"); //無參構造方法被覆蓋,創建枚舉需要添加參數(本質就是調用的構造方法!)
private final String name; //枚舉的成員變量
Status(String name){ //覆蓋原有構造方法(默認private,只能內部使用!)
this.name = name;
}
public String getName() { //獲取封裝的成員變量
return name;
}
}
public static void main(String[] args) {
Student student = new Student("小明", 18);
student.setStatus(Status.RUNNING);
System.out.println(student.getStatus().getName());
}
枚舉類還自帶一些繼承下來的實用方法
Status.valueOf("") //將名稱相同的字符串轉換為枚舉
Status.values() //快速獲取所有的枚舉
基本類型包裝類
Java並不是純面向對象的語言,雖然Java語言是一個面向對象的語言,但是Java中的基本數據類型卻不是面向對象的。在學習泛型和集合之前,基本類型的包裝類是一定要講解的內容!
我們的基本類型,如果想通過對象的形式去使用他們,Java提供的基本類型包裝類,使得Java能夠更好的體現面向對象的思想,同時也使得基本類型能夠支持對象操作!

- byte -> Byte
- boolean -> Boolean
- short -> Short
- char -> Character
- int -> Integer
- long -> Long
- float -> Float
- double -> Double
包裝類實際上就行將我們的基本數據類型,封裝成一個類(運用了封裝的思想)
private final int value; //Integer內部其實本質還是存了一個基本類型的數據,但是我們不能直接操作
public Integer(int value) {
this.value = value;
}
現在我們操作的就是Integer對象而不是一個int基本類型了!
public static void main(String[] args) {
Integer i = 1; //包裝類型可以直接接收對應類型的數據,並變為一個對象!
System.out.println(i + i); //包裝類型可以直接被當做一個基本類型進行操作!
}
自動裝箱和拆箱
那麼為什麼包裝類型能直接使用一個具體值來賦值呢?其實依靠的是自動裝箱和拆箱機制
Integer i = 1; //其實這裡只是簡寫了而已
Integer i = Integer.valueOf(1); //編譯後真正的樣子
調用valueOf來生成一個Integer對象!
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high) //注意,Java為了優化,有一個緩存機制,如果是在-128~127之間的數,會直接使用已經緩存好的對象,而不是再去創建新的!(面試常考)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i); //返回一個新創建好的對象
}
而如果使用包裝類來進行運算,或是賦值給一個基本類型變量,會進行自動拆箱:
public static void main(String[] args) {
Integer i = Integer.valueOf(1);
int a = i; //簡寫
int a = i.intValue(); //編譯後實際的代碼
long c = i.longValue(); //其他類型也有!
}
既然現在是包裝類型了,那麼我們還能使用==來判斷兩個數是否相等嗎?
public static void main(String[] args) {
Integer i1 = 28914;
Integer i2 = 28914;
System.out.println(i1 == i2); //實際上判斷是兩個對象是否為同一個對象(內存地址是否相同)
System.out.println(i1.equals(i2)); //這個才是真正的值判斷!
}
注意IntegerCache帶來的影響!
思考:下面這種情況結果會是什麼?
public static void main(String[] args) {
Integer i1 = 28914;
Integer i2 = 28914;
System.out.println(i1+1 == i2+1);
}
在集合類的學習中,我們還會繼續用到我們的包裝類型!
Java異常機制
在理想的情況下,我們的程序會按照我們的思路去運行,按理說是不會出現問題的,但是,代碼實際編寫後並不一定是完美的,可能會有我們沒有考慮到的情況,如果這些情況能夠正常得到一個錯誤的結果還好,但是如果直接導致程序運行出現問題了呢?
public static void main(String[] args) {
test(1, 0); //當b為0的時候,還能正常運行嗎?
}
private static int test(int a, int b){
return a/b; //沒有任何的判斷而是直接做計算
}
Exception in thread "main" java.lang.ArithmeticException: / by zero
at com.test.Application.test(Application.java:9)
at com.test.Application.main(Application.java:5)
當程序運行出現我們沒有考慮到的情況時,就有可能出現異常或是錯誤!
異常
我們在之前其實已經接觸過一些異常了,比如數組越界異常,空指針異常,算術異常等,他們其實都是異常類型,我們的每一個異常也是一個類,他們都繼承自Exception類!異常類型本質依然類的對象,但是異常類型支持在程序運行出現問題時拋出(也就是上面出現的紅色報錯)也可以提前聲明,告知使用者需要處理可能會出現的異常!
運行時異常
異常的第一種類型是運行時異常,如上述的列子,在編譯階段無法感知代碼是否會出現問題,只有在運行的時候才知道會不會出錯(正常情況下是不會出錯的),這樣的異常稱為運行時異常。所有的運行時異常都繼承自RuntimeException。
編譯時異常
異常的另一種類型是編譯時異常,編譯時異常是明確會出現的異常,在編譯階段就需要進行處理的異常(捕獲異常)如果不進行處理,將無法通過編譯!默認繼承自Exception類的異常都是編譯時異常。
File file = new File("my.txt");
file.createNewFile(); //要調用此方法,首先需要處理異常
錯誤
錯誤比異常更嚴重,異常就是不同尋常,但不一定會導致致命的問題,而錯誤是致命問題,一般出現錯誤可能JVM就無法繼續正常運行了,比如OutOfMemoryError就是內存溢出錯誤(內存佔用已經超出限制,無法繼續申請內存了)
int[] arr = new int[Integer.MAX_VALUE]; //能創建如此之大的數組嗎?
運行後得到以下內容:
Exception in thread "main" java.lang.OutOfMemoryError: Requested array size exceeds VM limit
at com.test.Main.main(Main.java:14)
錯誤都繼承自Error類,一般情況下,程序中只能處理異常,錯誤是很難進行處理的,Error和Execption都繼承自Throwable類。當程序中出現錯誤或異常時又沒有進行處理時,程序(當前線程)將終止運行:
int[] arr = new int[Integer.MAX_VALUE];
System.out.println("lbwnb"); //還能正常打印嗎?
異常的處理
當程序沒有按照我們想要的樣子運行而出現異常時(默認會交給JVM來處理,JVM發現任何異常都會立即終止程序運行,並在控制台打印棧追蹤信息),我們希望能夠自己處理出現的問題,讓程序繼續運行下去,就需要對異常進行捕獲,比如:
int[] arr = new int[5];
arr[5] = 1; //我們需要處理這種情況,保證後面的代碼正常運行!
System.out.println("lbwnb");
我們可以使用try和catch語句塊來處理:
int[] arr = new int[5];
try{ //在try塊中運行代碼
arr[5] = 1; //當代碼出現異常時,異常會被捕獲,並在catch塊中得到異常類型的對象
}catch (ArrayIndexOutOfBoundsException e){ //捕獲的異常類型
System.out.println("程序運行出現異常!"); //出現異常時執行
}
//後面的代碼會正常運行
System.out.println("lbwnb");
當異常被捕獲後,就由我們自己進行處理(不再交給JVM處理),因此就不會導致程序終止運行。
我們可以通過使用e.printStackTrace()來打印棧追蹤信息,定位我們的異常出現位置:
java.lang.ArrayIndexOutOfBoundsException: 5
at com.test.Main.main(Main.java:7) //Main類的第7行出現問題
程序運行出現異常!
lbwnb
運行時異常在編譯時可以不用捕獲,但是編譯時異常必須進行處理:
File file = new File("my.txt");
try {
file.createNewFile();
} catch (IOException e) { //捕獲聲明的異常類型
e.printStackTrace();
}
可以捕獲到類型不止是Exception的子類,只要是繼承自Throwalbe的類,都能被捕獲,也就是說,Error也能被捕獲,但是不建議這樣做,因為錯誤一般是虛擬機相關的問題,出現Error應該從問題的根源去解決。
異常的拋出
當別人調用我們的方法時,如果傳入了錯誤的參數導致程序無法正常運行,這時我們就需要手動拋出一個異常來終止程序繼續運行下去,同時告知上一級方法執行出現了問題:
public static void main(String[] args) {
try {
test(1, 0);
} catch (Exception e) { //捕獲方法中會出現的異常
e.printStackTrace();
}
}
private static int test(int a, int b) throws Exception { //聲明拋出的異常類型
if(b == 0) throw new Exception("0不能做除數!"); //創建異常對象並拋出異常
return a/b; //拋出異常會終止代碼運行
}
通過throw關鍵字拋出異常(拋出異常後,後面的代碼不再執行)當程序運行到這一行時,就會終止執行,並出現一個異常。
如果方法中拋出了非運行時異常,但是不希望在此方法內處理,而是交給調用者來處理異常,就需要在方法定義後面顯式聲明拋出的異常類型!如果拋出的是運行時異常,則不需要在方法後面聲明異常類型,調用時也無需捕獲,但是出現異常時同樣會導致程序終止(出現運行時異常同時未被捕獲會默認交給JVM處理,也就是直接中止程序並在控制台打印棧追蹤信息)
如果想要調用聲明編譯時異常的方法,但是依然不想去處理,可以同樣的在方法上聲明throws來繼續交給上一級處理。
public static void main(String[] args) throws Exception { //出現異常就再往上拋,而不是在此方法內處理
test(1, 0);
}
private static int test(int a, int b) throws Exception { //聲明拋出的異常類型
if(b == 0) throw new Exception("0不能做除數!"); //創建異常對象並拋出異常
return a/b;
}
當main方法都聲明拋出異常時,出現異常就由JVM進行處理,也就是默認的處理方式(直接中止程序並在控制台打印棧追蹤信息)
異常只能被捕獲一次,當異常捕獲出現嵌套時,只會在最內層被捕獲:
public static void main(String[] args) throws Exception {
try{
test(1, 0);
}catch (Exception e){
System.out.println("外層");
}
}
private static int test(int a, int b){
try{
if(b == 0) throw new Exception("0不能做除數!");
}catch (Exception e){
System.out.println("內層");
return 0;
}
return a/b;
}
自定義異常
JDK為我們已經提前定義了一些異常了,但是可能對我們來說不夠,那麼就需要自定義異常:
public class MyException extends Exception { //直接繼承即可
}
public static void main(String[] args) throws MyException {
throw new MyException(); //直接使用
}
也可以使用父類的帶描述的構造方法:
public class MyException extends Exception {
public MyException(String message){
super(message);
}
}
public static void main(String[] args) throws MyException {
throw new MyException("出現了自定義的錯誤");
}
捕獲異常指定的類型,會捕獲其所有子異常類型:
try {
throw new MyException("出現了自定義的錯誤");
} catch (Exception e) { //捕獲父異常類型
System.out.println("捕獲到異常");
}
多重異常捕獲和finally關鍵字
當代碼可能出現多種類型的異常時,我們希望能夠分不同情況處理不同類型的異常,就可以使用多重異常捕獲:
try {
//....
} catch (NullPointerException e) {
} catch (IndexOutOfBoundsException e){
} catch (RuntimeException e){
}
注意,類似於if-else if的結構,父異常類型只能放在最後!
try {
//....
} catch (RuntimeException e){ //父類型在前,會將子類的也捕獲
} catch (NullPointerException e) { //永遠都不會被捕獲
} catch (IndexOutOfBoundsException e){ //永遠都不會被捕獲
}
如果希望把這些異常放在一起進行處理:
try {
//....
} catch (NullPointerException | IndexOutOfBoundsException e) { //用|隔開每種類型即可
}
當我們希望,程序運行時,無論是否出現異常,都會在最後執行的任務,可以交給finally語句塊來處理:
try {
//....
}catch (Exception e){
}finally {
System.out.println("lbwnb"); //無論是否出現異常,都會在最後執行
}
try語句塊至少要配合catch或finally中的一個:
try {
int a = 10;
a /= 0;
}finally { //不捕獲異常,程序會終止,但在最後依然會執行下面的內容
System.out.println("lbwnb");
}
思考:try、catch和finally執行順序:
private static int test(int a){
try{
return a;
}catch (Exception e){
return 0;
}finally {
a = a + 1;
}
}
Java泛型與集合類
在前面我們學習了最重要的類和對象,了解了面向對象編程的思想,注意,非常重要,面向對象是必須要深入理解和掌握的內容,不能草草結束。在本章節,我們會繼續深入了解,從我們的泛型開始,再到我們的數據結構,最後再開始我們的集合類學習。
走進泛型
為了統計學生成績,要求設計一個Score對象,包括課程名稱、課程號、課程成績,但是成績分為兩種,一種是以優秀、良好、合格 來作為結果,還有一種就是 60.0、75.5、92.5 這樣的數字分數,那麼現在該如何去設計這樣的一個Score類呢?現在的問題就是,成績可能是String類型,也可能是Integer類型,如何才能很好的去存可能出現的兩種類型呢?
public class Score {
String name;
String id;
Object score; //因為Object是所有類型的父類,因此既可以存放Integer也能存放String
public Score(String name, String id, Object score) {
this.name = name;
this.id = id;
this.score = score;
}
}
以上的方法雖然很好地解決了多種類型存儲問題,但是Object類型在編譯階段並不具有良好的類型判斷能力,很容易出現以下的情況:
public static void main(String[] args) {
Score score = new Score("數據結構與算法基礎", "EP074512", "優秀"); //是String類型的
//....
Integer number = (Integer) score.score; //獲取成績需要進行強制類型轉換,雖然並不是一開始的類型,但是編譯不會報錯
}
//運行時出現異常!
Exception in thread "main" java.lang.ClassCastException: java.lang.String cannot be cast to java.lang.Integer
at com.test.Main.main(Main.java:14)
使用Object類型作為引用,取值只能進行強制類型轉換,顯然無法在編譯期確定類型是否安全,項目中代碼量非常之大,進行類型比較又會導致額外的開銷和增加代碼量,如果不經比較就很容易出現類型轉換異常,代碼的健壯性有所欠缺!(此方法雖然可行,但並不是最好的方法)
為了解決以上問題,JDK1.5新增了泛型,它能夠在編譯階段就檢查類型安全,大大提升開發效率。
public class Score<T> { //將Score轉變為泛型類<T>
String name;
String id;
T score; //T為泛型,根據用戶提供的類型自動變成對應類型
public Score(String name, String id, T score) { //提供的score類型即為T代表的類型
this.name = name;
this.id = id;
this.score = score;
}
}
public static void main(String[] args) {
//直接確定Score的類型是字符串類型的成績
Score<String> score = new Score<String>("數據結構與算法基礎", "EP074512", "優秀");
Integer i = score.score; //編譯不通過,因為成員變量score類型被定為String!
}
泛型將數據類型的確定控制在了編譯階段,在編寫代碼的時候就能明確泛型的類型!如果類型不符合,將無法通過編譯!
泛型本質上也是一個語法糖(並不是JVM所支持的語法,編譯後會轉成編譯器支持的語法,比如之前的foreach就是),在編譯後會被擦除,變回上面的Object類型調用,但是類型轉換由編譯器幫我們完成,而不是我們自己進行轉換(安全)
//反編譯後的代碼
public static void main(String[] args) {
Score score = new Score("數據結構與算法基礎", "EP074512", "優秀");
String i = (String)score.score; //其實依然會變為強制類型轉換,但是這是由編譯器幫我們完成的
}
像這樣在編譯後泛型的內容消失轉變為Object的情況稱為類型擦除(重要,需要完全理解),所以泛型只是為了方便我們在編譯階段確定類型的一種語法而已,並不是JVM所支持的。
綜上,泛型其實就是一種類型參數,用於指定類型。
泛型的使用
泛型類
上一節我們已經提到泛型類的定義,實際上就是普通的類多了一個類型參數,也就是在使用時需要指定具體的泛型類型。泛型的名稱一般取單個大寫字母,比如T代表Type,也就是類型的英文單詞首字母,當然也可以添加數字和其他的字符。
public class Score<T> { //將Score轉變為泛型類<T>
String name;
String id;
T score; //T為泛型,根據用戶提供的類型自動變成對應類型
public Score(String name, String id, T score) { //提供的score類型即為T代表的類型
this.name = name;
this.id = id;
this.score = score;
}
}
在一個普通類型中定義泛型,泛型T稱為參數化類型,在定義泛型類的引用時,需要明確指出類型:
Score<String> score = new Score<String>("數據結構與算法基礎", "EP074512", "優秀");
此時類中的泛型T已經被替換為String了,在我們獲取此對象的泛型屬性時,編譯器會直接告訴我們類型:
Integer i = score.score; //編譯不通過,因為成員變量score明確為String類型
注意,泛型只能用於對象屬性,也就是非靜態的成員變量才能使用:
static T score; //錯誤,不能在靜態成員上定義
由此可見,泛型是只有在創建對象後編譯器才能明確泛型類型,而靜態類型是類所具有的屬性,不足以使得編譯器完成類型推斷。
泛型無法使用基本類型,如果需要基本類型,只能使用基本類型的包裝類進行替換!
Score<double> score = new Score<double>("數據結構與算法基礎", "EP074512", 90.5); //編譯不通過
那麼為什麼泛型無法使用基本類型呢?回想上一節提到的類型擦除,其實就很好理解了。由於JVM沒有泛型概念,因此泛型最後還是會被編譯器編譯為Object,並採用強制類型轉換的形式進行類型匹配,而我們的基本數據類型和引用類型之間無法進行類型轉換,所以只能使用基本類型的包裝類來處理。
類的泛型方法
泛型方法的使用也很簡單,我們只需要把它當做一個未知的類型來使用即可:
public T getScore() { //若方法的返回值類型為泛型,那麼編譯器會自動進行推斷
return score;
}
public void setScore(T score) { //若方法的形式參數為泛型,那麼實參只能是定義時的類型
this.score = score;
}
Score<String> score = new Score<String>("數據結構與算法基礎", "EP074512", "優秀");
score.setScore(10); //編譯不通過,因為只接受String類型
同樣地,靜態方法無法直接使用類定義的泛型(注意是無法直接使用,靜態方法可以使用泛型)
自定義泛型方法
那麼如果我想在靜態方法中使用泛型呢?首先我們要明確之前為什麼無法使用泛型,因為之前我們的泛型定義是在類上的,只有明確具體的類型才能開始使用,也就是創建對象時完成類型確定,但是靜態方法不需要依附於對象,那麼只能在使用時再來確定了,所以靜態方法可以使用泛型,但是需要單獨定義:
public static <E> void test(E e){ //在方法定義前聲明泛型
System.out.println(e);
}
同理,成員方法也能自行定義泛型,在實際使用時再進行類型確定:
public <E> void test(E e){
System.out.println(e);
}
其實,無論是泛型類還是泛型方法,再使用時一定要能夠進行類型推斷,明確類型才行。
注意一定要區分類定義的泛型和方法前定義的泛型!
泛型引用
可以看到我們在定義一個泛型類的引用時,需要在後面指出此類型:
Score<Integer> score; //聲明泛型為Integer類型
如果不希望指定類型,或是希望此引用類型可以引用任意泛型的Score類對象,可以使用?通配符,來表示自動匹配任意的可用類型:
Score<?> score; //score可以引用任意的Score類型對象了!
那麼使用通配符之後,得到的泛型成員變量會是什麼類型呢?
Object o = score.getScore(); //只能變為Object
因為使用了通配符,編譯器就無法進行類型推斷,所以只能使用原始類型。
在學習了泛型的界限後,我們還會繼續了解通配符的使用。
泛型的界限
現在有一個新的需求,現在沒有String類型的成績了,但是成績依然可能是整數,也可能是小數,這時我們不希望用戶將泛型指定為除數字類型外的其他類型,我們就需要使用到泛型的上界定義:
public class Score<T extends Number> { //設定泛型上界,必須是Number的子類
private final String name;
private final String id;
private T score;
public Score(String name, String id, T score) {
this.name = name;
this.id = id;
this.score = score;
}
public T getScore() {
return score;
}
}
通過extends關鍵字進行上界限定,只有指定類型或指定類型的子類才能作為類型參數。
同樣的,泛型通配符也支持泛型的界限:
Score<? extends Number> score; //限定為匹配Number及其子類的類型
同理,既然泛型有上限,那麼也有下限:
Score<? super Integer> score; //限定為匹配Integer及其父類
通過super關鍵字進行下界限定,只有指定類型或指定類型的父類才能作為類型參數。
圖解如下:


那麼限定了上界後,我們再來使用這個對象的泛型成員,會變成什麼類型呢?
Score<? extends Number> score = new Score<>("數據結構與算法基礎", "EP074512", 10);
Number o = score.getScore(); //得到的結果為上界類型
也就是說,一旦我們指定了上界後,編譯器就將範圍從原始類型Object提升到我們指定的上界Number,但是依然無法明確具體類型。思考:那如果定義下限呢?
那麼既然我們可以給泛型類限定上界,現在我們來看編譯後結果呢:
//使用javap -l 進行反編譯
public class com.test.Score<T extends java.lang.Number> {
public com.test.Score(java.lang.String, java.lang.String, T);
LineNumberTable:
line 8: 0
line 9: 4
line 10: 9
line 11: 14
line 12: 19
LocalVariableTable:
Start Length Slot Name Signature
0 20 0 this Lcom/test/Score;
0 20 1 name Ljava/lang/String;
0 20 2 id Ljava/lang/String;
0 20 3 score Ljava/lang/Number; //可以看到score的類型直接被編譯為Number類
public T getScore();
LineNumberTable:
line 15: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/test/Score;
}
因此,一旦確立上限後,編譯器會自動將類型提升到上限類型。
鑽石運算符
我們發現,每次創建泛型對象都需要在前後都標明類型,但是實際上後面的類型聲明是可以去掉的,因為我們在傳入參數時或定義泛型類的引用時,就已經明確了類型,因此JDK1.7提供了鑽石運算符來簡化代碼:
Score<Integer> score = new Score<Integer>("數據結構與算法基礎", "EP074512", 10); //1.7之前
Score<Integer> score = new Score<>("數據結構與算法基礎", "EP074512", 10); //1.7之後
泛型與多態
泛型不僅僅可以可以定義在類上,同時也能定義在接口上:
public interface ScoreInterface<T> {
T getScore();
void setScore(T t);
}
當實現此接口時,我們可以選擇在實現類明確泛型類型或是繼續使用此泛型,讓具體創建的對象來確定類型。
public class Score<T> implements ScoreInterface<T>{ //將Score轉變為泛型類<T>
private final String name;
private final String id;
private T score;
public Score(String name, String id, T score) {
this.name = name;
this.id = id;
this.score = score;
}
public T getScore() {
return score;
}
@Override
public void setScore(T score) {
this.score = score;
}
}
public class StringScore implements ScoreInterface<String>{ //在實現時明確類型
@Override
public String getScore() {
return null;
}
@Override
public void setScore(String s) {
}
}
抽象類同理,這裡就不多做演示了。
多態類型擦除
思考一個問題,既然繼承後明確了泛型類型,那麼為什麼@Override不會出現錯誤呢,重寫的條件是需要和父類的返回值類型、形式參數一致,而泛型默認的原始類型是Object類型,子類明確後變為Number類型,這顯然不滿足重寫的條件,但是為什麼依然能編譯通過呢?
class A<T>{
private T t;
public T get(){
return t;
}
public void set(T t){
this.t=t;
}
}
class B extends A<Number>{
private Number n;
@Override
public Number get(){ //這並不滿足重寫的要求,因為只能重寫父類同樣返回值和參數的方法,但是這樣卻能夠通過編譯!
return t;
}
@Override
public void set(Number t){
this.t=t;
}
}
通過反編譯進行觀察,實際上是編譯器幫助我們生成了兩個橋接方法用於支持重寫:
@Override
public Object get(){
return this.get();//調用返回Number的那個方法
}
@Override
public void set(Object t ){
this.set((Number)t ); //調用參數是Number的那個方法
}
數據結構基礎
學習集合類之前,我們還有最關鍵的內容需要學習,自底向上才是最佳的學習方向,比起直接帶大家認識集合類,不如先了解一下數據結構,只有了解了數據結構基礎,才能更好地學習集合類。
同時,數據結構也是你以後深入學習JDK源碼的必備條件!(學習不要快餐式!)當然,我們主要是講解Java,數據結構作為鋪墊作用,所以我們只會講解關鍵的部分,其他部分可以下去自行了解。
在計算機科學中,數據結構是一種數據組織、管理和存儲的格式,它可以幫助我們實現對數據高效的訪問和修改。更準確地說,數據結構是數據值的集合,可以體現數據值之間的關係,以及可以對數據進行應用的函數或操作。
通俗地說,我們需要去學習在計算機中如何去更好地管理我們的數據,才能讓我們對我們的數據控制更加靈活!
線性表
線性表是最基本的一種數據結構,它是表示一組相同類型數據的有限序列,你可以把它與數組進行參考,但是它並不是數組,線性表是一種表結構,它能夠支持數據的插入、刪除、更新、查詢等,同時數組可以隨意存放在數組中任意位置,而線性表只能依次有序排列,不能出現空隙,因此,我們需要進一步的設計。
順序表
將數據依次存儲在連續的整塊物理空間中,這種存儲結構稱為順序存儲結構,而以這種方式實現的線性表,我們稱為順序表。
同樣的,表中的每一個個體都被稱為元素,元素左邊的元素(上一個元素),稱為前驅,同理,右邊的元素(後一個元素)稱為後驅。
我們設計線性表的目標就是為了去更好地管理我們的數據,也就是說,我們可以基於數組,來進行封裝,實現增刪改查!既然要存儲一組數據,那麼很容易聯想到我們之前學過的數組,數組就能夠容納一組同類型的數據。
目標:以數組為底層,編寫以下抽象類的具體實現
/**
* 線性表抽象類
* @param <E> 存儲的元素(Element)類型
*/
public abstract class AbstractList<E> {
/**
* 獲取表的長度
* @return 順序表的長度
*/
public abstract int size();
/**
* 添加一個元素
* @param e 元素
* @param index 要添加的位置(索引)
*/
public abstract void add(E e, int index);
/**
* 移除指定位置的元素
* @param index 位置
* @return 移除的元素
*/
public abstract E remove(int index);
/**
* 獲取指定位置的元素
* @param index 位置
* @return 元素
*/
public abstract E get(int index);
}
鏈表
數據分散的存儲在物理空間中,通過一根線保存着它們之間的邏輯關係,這種存儲結構稱為鏈式存儲結構
實際上,就是每一個結點存放一個元素和一個指向下一個結點的引用(C語言裏面是指針,Java中就是對象的引用,代表下一個結點對象)

利用這種思想,我們再來嘗試實現上面的抽象類,從實際的代碼中感受!
比較:順序表和鏈表的優異?
順序表優缺點:
- 訪問速度快,隨機訪問性能高
- 插入和刪除的效率低下,極端情況下需要變更整個表
- 不易擴充,需要複製並重新創建數組
鏈表優缺點:
- 插入和刪除效率高,只需要改變連接點的指向即可
- 動態擴充容量,無需擔心容量問題
- 訪問元素需要依次尋找,隨機訪問元素效率低下
鏈表只能指向後面,能不能指向前面呢?雙向鏈表!
棧和隊列實際上就是對線性表加以約束的一種數據結構,如果前面的線性表的掌握已經ok,那麼棧和隊列就非常輕鬆了!
棧
棧遵循先入後出原則,只能在線性表的一端添加和刪除元素。我們可以把棧看做一個杯子,杯子只有一個口進出,最低處的元素只能等到上面的元素離開杯子後,才能離開。

向棧中插入一個元素時,稱為入棧(壓棧),移除棧頂元素稱為出棧,我們需要嘗試實現以下抽象類型:
/**
* 抽象類型棧,待實現
* @param <E> 元素類型
*/
public abstract class AbstractStack<E> {
/**
* 出棧操作
* @return 棧頂元素
*/
public abstract E pop();
/**
* 入棧操作
* @param e 元素
*/
public abstract void push(E e);
}
其實,我們的JVM在處理方法調用時,也是一個棧操作:
所以說,如果玩不好遞歸,就會像這樣:
public class Main {
public static void main(String[] args) {
go();
}
private static void go(){
go();
}
}
Exception in thread "main" java.lang.StackOverflowError
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
at com.test.Main.go(Main.java:13)
...
棧的深度是有限制的,如果達到限制,將會出現StackOverflowError錯誤(注意是錯誤!說明是JVM出現了問題)
隊列
隊列同樣也是受限制的線性表,不過隊列就像我們排隊一樣,只能從隊尾開始排,從隊首出。
所以我們要實現以下內容:
/**
*
* @param <E>
*/
public abstract class AbstractQueue<E> {
/**
* 進隊操作
* @param e 元素
*/
public abstract void offer(E e);
/**
* 出隊操作
* @return 元素
*/
public abstract E poll();
}
二叉樹
本版塊主要學習的是二叉樹,樹也是一種數據結構,但是它使用起來更加的複雜。
樹
我們前面已經學習過鏈表了,我們知道鏈表是單個結點之間相連,也就是一種一對一的關係,而樹則是一個結點連接多個結點,也就是一對多的關係。
一個結點可以有N個子結點,就像上圖一樣,看起來就像是一棵樹。而位於最頂端的結點(沒有父結點)我們稱為根結點,而結點擁有的子節點數量稱為度,每向下一級稱為一個層次,樹中出現的最大層次稱為樹的深度(高度)。
二叉樹
二叉樹是一種特殊的樹,每個結點最多有兩顆子樹,所以二叉樹中不存在度大於2的結點,位於兩邊的子結點稱為左右子樹(注意,左右子樹是明確區分的,是左就是左,是右就是右)

數學性質:
- 在二叉樹的第i層上最多有2^(i-1) 個節點。
- 二叉樹中如果深度為k,那麼最多有2^k-1個節點。
設計一個二叉樹結點類:
public class TreeNode<E> {
public E e; //當前結點數據
public TreeNode<E> left; //左子樹
public TreeNode<E> right; //右子樹
}
二叉樹的遍歷
順序表的遍歷其實就是依次有序去訪問表中每一個元素,而像二叉樹這樣的複雜結構,我們有四種遍歷方式,他們是:前序遍歷、中序遍歷、後序遍歷以及層序遍歷,本版塊我們主要討論前三種遍歷方式:
- 前序遍歷:從二叉樹的根結點出發,到達結點時就直接輸出結點數據,按照先向左在向右的方向訪問。ABCDEF
- 中序遍歷:從二叉樹的根結點出發,優先輸出左子樹的節點的數據,再輸出當前節點本身,最後才是右子樹。CBDAEF
- 後序遍歷:從二叉樹的根結點出發,優先遍歷其左子樹,再遍歷右子樹,最後在輸出當前節點本身。CDBFEA
滿二叉樹和完全二叉樹
滿二叉樹和完全二叉樹其實就是特殊情況下的二叉樹,滿二叉樹左右的所有葉子節點都在同一層,也就是說,完全把每一個層級都給加滿了結點。完全二叉樹與滿二叉樹不同的地方在於,它的最下層葉子節點可以不滿,但是最下層的葉子節點必須靠左排布。

其實滿二叉樹和完全二叉樹就是有一定規律的二叉樹,很容易理解。
快速查找
我們之前提到的這些數據結構,很好地幫我們管理了數據,但是,如果需要查找某一個元素是否存在於數據結構中,如何才能更加高效的去完成呢?
哈希表
通過前面的學習,我們發現,順序表雖然查詢效率高,但是插入刪除有嚴重表更新的問題,而鏈表雖然彌補了更新問題,但是查詢效率實在是太低了,能否有一種折中方案?哈希表!
不知大家在之前的學習中是否發現,我們的Object類中,定義了一個叫做hashcode()的方法?而這個方法呢,就是為了更好地支持哈希表的實現。hashcode()默認得到的是對象的內存地址,也就是說,每個對象的hashCode都不一樣。
哈希表,其實本質上就是一個存放鏈表的數組,那麼它是如何去存儲數據的呢?我們先來看看長啥樣:

數組中每一個元素都是一個頭結點,用於保存數據,那我們怎麼確定數據應該放在哪一個位置呢?通過hash算法,我們能夠瞬間得到元素應該放置的位置。
//假設hash表長度為16,hash算法為:
private int hash(int hashcode){
return hashcode % 16;
}
設想這樣一個問題,如果計算出來的hash值和之前已經存在的元素相同了呢?這種情況我們稱為hash碰撞,這也是為什麼要將每一個表元素設置為一個鏈表的頭結點的原因,一旦發現重複,我們可以往後繼續添加節點。
當然,以上的hash表結構只是一種設計方案,在面對大額數據時,是不夠用的,在JDK1.8中,集合類使用的是數組+二叉樹的形式解決的(這裡的二叉樹是經過加強的二叉樹,不是前面講得簡單二叉樹,我們下一節就會開始講)
二叉排序樹
我們前面學習的二叉樹效率是不夠的,我們需要的是一種效率更高的二叉樹,因此,基於二叉樹的改進,提出了二叉查找樹,可以看到結構像下面這樣:

不難發現,每個節點的左子樹,一定小於當前節點的值,每個節點的右子樹,一定大於當前節點的值,這樣的二叉樹稱為二叉排序樹。利用二分搜索的思想,我們就可以快速查找某個節點!
平衡二叉樹
在了解了二叉查找樹之後,我們發現,如果根節點為10,現在加入到結點的值從9開始,依次減小到1,那麼這個表就會很奇怪,就像下面這樣:

顯然,當所有的結點都排列到一邊,這種情況下,查找效率會直接退化為最原始的二叉樹!因此我們需要維持二叉樹的平衡,才能維持原有的查找效率。
現在我們對二叉排序樹加以約束,要求每個結點的左右兩個子樹的高度差的絕對值不超過1,這樣的二叉樹稱為平衡二叉樹,同時要求每個結點的左右子樹都是平衡二叉樹,這樣,就不會因為一邊的瘋狂增加導致失衡。我們來看看以下幾種情況:

左左失衡

右右失衡

左右失衡

右左失衡
通過以上四種情況的處理,最終得到維護平衡二叉樹的算法。
紅黑樹
紅黑樹也是二叉排序樹的一種改進,同平衡二叉樹一樣,紅黑樹也是一種維護平衡的二叉排序樹,但是沒有平衡二叉樹那樣嚴格(平衡二叉樹每次插入新結點時,可能會出現大量的旋轉,而紅黑樹保證不超過三次),紅黑樹降低了對於旋轉的要求,因此效率有一定的提升同時實現起來也更加簡單。但是紅黑樹的效率卻高於平衡二叉樹,紅黑樹也是JDK1.8中使用的數據結構!

紅黑樹的特性:
(1)每個節點或者是黑色,或者是紅色。
(2)根節點是黑色。
(3)每個葉子節點的兩邊也需要表示(雖然沒有,但是null也需要表示出來)是黑色。
(4)如果一個節點是紅色的,則它的子節點必須是黑色的。
(5)從一個節點到該節點的子孫節點的所有路徑上包含相同數目的黑節點。
我們來看看一個節點,是如何插入到紅黑樹中的:
基本的 插入規則和平衡二叉樹一樣,但是在插入後:
- 將新插入的節點標記為紅色
- 如果 X 是根結點(root),則標記為黑色
- 如果 X 的 parent 不是黑色,同時 X 也不是 root:
-
3.1 如果 X 的 uncle (叔叔) 是紅色
-
- 3.1.1 將 parent 和 uncle 標記為黑色
- 3.1.2 將 grand parent (祖父) 標記為紅色
- 3.1.3 讓 X 節點的顏色與 X 祖父的顏色相同,然後重複步驟 2、3
-
3.2 如果 X 的 uncle (叔叔) 是黑色,我們要分四種情況處理
-
- 3.2.1 左左 (P 是 G 的左孩子,並且 X 是 P 的左孩子)
- 3.2.2 左右 (P 是 G 的左孩子,並且 X 是 P 的右孩子)
- 3.2.3 右右 (P 是 G 的右孩子,並且 X 是 P 的右孩子)
- 3.2.4 右左 (P 是 G 的右孩子,並且 X 是 P 的左孩子)
- 其實這種情況下處理就和我們的平衡二叉樹一樣了
認識集合類
源碼解析://www.cnblogs.com/zwtblog/tag/源碼/
集合表示一組對象,稱為其元素。一些集合允許重複的元素,而另一些則不允許。一些集合是有序的,而其他則是無序的。
集合類其實就是為了更好地組織、管理和操作我們的數據而存在的,包括列表、集合、隊列、映射等數據結構。從這一塊開始,我們會從源碼角度給大家講解(數據結構很重要!),不僅僅是教會大家如何去使用。
集合類最頂層不是抽象類而是接口,因為接口代表的是某個功能,而抽象類是已經快要成形的類型,不同的集合類的底層實現是不相同的,同時一個集合類可能會同時具有兩種及以上功能(既能做隊列也能做列表),所以採用接口會更加合適,接口只需定義支持的功能即可。

數組與集合
相同之處:
- 它們都是容器,都能夠容納一組元素。
不同之處:
- 數組的大小是固定的,集合的大小是可變的。
- 數組可以存放基本數據類型,但集合只能存放對象。
- 數組存放的類型只能是一種,但集合可以有不同種類的元素。
集合根接口Collection
本接口中定義了全部的集合基本操作,我們可以在源碼中看看。
我們再來看看List和Set以及Queue接口。
集合類的使用
List列表
首先介紹ArrayList,它的底層是用數組實現的,內部維護的是一個可改變大小的數組,也就是我們之前所說的線性表!跟我們之前自己寫的ArrayList相比,它更加的規範,同時繼承自List接口。
先看看ArrayList的源碼!
基本操作
List<String> list = new ArrayList<>(); //默認長度的列表
List<String> listInit = new ArrayList<>(100); //初始長度為100的列表
向列表中添加元素:
List<String> list = new ArrayList<>();
list.add("lbwnb");
list.add("yyds");
list.contains("yyds"); //是否包含某個元素
System.out.println(list);
移除元素:
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("lbwnb");
list.add("yyds");
list.remove(0); //按下標移除元素
list.remove("yyds"); //移除指定元素
System.out.println(list);
}
也支持批量操作:
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.addAll(new ArrayList<>()); //在尾部批量添加元素
list.removeAll(new ArrayList<>()); //批量移除元素(只有給定集合中存在的元素才會被移除)
list.retainAll(new ArrayList<>()); //只保留某些元素
System.out.println(list);
}
我們再來看LinkedList,其實本質就是一個鏈表!我們來看看源碼。
其實與我們之前編寫的LinkedList不同之處在於,它內部使用的是一個雙向鏈表:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
當然,我們發現它還實現了Queue接口,所以LinkedList也能被當做一個隊列或是棧來使用。
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.offer("A"); //入隊
System.out.println(list.poll()); //出隊
list.push("A");
list.push("B"); //進棧
list.push("C");
System.out.println(list.pop());
System.out.println(list.pop()); //出棧
System.out.println(list.pop());
}
利用代碼塊來快速添加內容
前面我們學習了匿名內部類,我們就可以利用代碼塊,來快速生成一個自帶元素的List
List<String> list = new LinkedList<String>(){{ //初始化時添加
this.add("A");
this.add("B");
}};
如果是需要快速生成一個只讀的List,後面我們會講解Arrays工具類。
集合的排序
List<Integer> list = new LinkedList<Integer>(){ //Java9才支持匿名內部類使用鑽石運算符
{
this.add(10);
this.add(2);
this.add(5);
this.add(8);
}
};
list.sort((a, b) -> { //排序已經由JDK實現,現在只需要填入自定義規則,完成Comparator接口實現
return a - b; //返回值小於0,表示a應該在b前面,返回值大於0,表示b應該在a後面,等於0則不進行交換
});
System.out.println(list);
迭代器
集合的遍歷
所有的集合類,都支持foreach循環!
public static void main(String[] args) {
List<Integer> list = new LinkedList<Integer>(){ //Java9才支持匿名內部類使用鑽石運算符
{
this.add(10);
this.add(2);
this.add(5);
this.add(8);
}
};
for (Integer integer : list) {
System.out.println(integer);
}
}
當然,也可以使用JDK1.8新增的forEach方法,它接受一個Consumer接口實現:
list.forEach(i -> {
System.out.println(i);
});
從JDK1.8開始,lambda表達式開始逐漸成為主流,我們需要去適應函數式編程的這種語法,包括批量替換,也是用到了函數式接口來完成的。
list.replaceAll((i) -> {
if(i == 2) return 3; //將所有的2替換為3
else return i; //不是2就不變
});
System.out.println(list);
Iterable和Iterator接口
我們之前學習數據結構時,已經得知,不同的線性表實現,在獲取元素時的效率也不同,因此我們需要一種更好地方式來統一不同數據結構的遍歷。
由於ArrayList對於隨機訪問的速度更快,而LinkedList對於順序訪問的速度更快,
因此在上述的傳統for循環遍歷操作中,ArrayList的效率更勝一籌,因此我們要使得LinkedList遍歷效率提升,就需要採用順序訪問的方式進行遍歷,
如果沒有迭代器幫助我們統一標準,那麼我們在應對多種集合類型的時候,就需要對應編寫不同的遍歷算法,很顯然這樣會降低我們的開發效率,而迭代器的出現就幫助我們解決了這個問題。
我們先來看看迭代器裏面方法:
public interface Iterator<E> {
//...
}
每個集合類都有自己的迭代器,通過iterator()方法來獲取:
Iterator<Integer> iterator = list.iterator(); //生成一個新的迭代器
while (iterator.hasNext()){ //判斷是否還有下一個元素
Integer i = iterator.next(); //獲取下一個元素(獲取一個少一個)
System.out.println(i);
}
迭代器生成後,默認指向第一個元素,每次調用next()方法,都會將指針後移,當指針移動到最後一個元素之後,調用hasNext()將會返回false,迭代器是一次性的,用完即止,如果需要再次使用,需要調用iterator()方法。
//List還有一個更好地迭代器實現ListIterator
ListIterator<Integer> iterator = list.listIterator();
ListIterator是List中獨有的迭代器,在原有迭代器基礎上新增了一些額外的操作。
Set集合
我們之前已經看過Set接口的定義了,我們發現接口中定義的方法都是Collection中直接繼承的,因此,Set支持的功能其實也就和Collection中定義的差不多,只不過使用方法上稍有不同。
Set集合特點:
- 不允許出現重複元素
- 不支持隨機訪問(不允許通過下標訪問)
首先認識一下HashSet,它的底層就是採用哈希表實現的(我們在這裡先不去探討實現原理,因為底層實質上維護的是一個HashMap,我們學習了Map之後再來討論)
public static void main(String[] args) {
HashSet<Integer> set = new HashSet<>();
set.add(120); //支持插入元素,但是不支持指定位置插入
set.add(13);
set.add(11);
for (Integer integer : set) {
System.out.println(integer);
}
}
運行上面代碼發現,最後Set集合中存在的元素順序,並不是我們的插入順序,這是因為HashSet底層是採用哈希表來實現的,實際的存放順序是由Hash算法決定的。
那麼我們希望數據按照我們插入的順序進行保存該怎麼辦呢?我們可以使用LinkedHashSet:
public static void main(String[] args) {
LinkedHashSet<Integer> set = new LinkedHashSet<>(); //會自動保存我們的插入順序
set.add(120);
set.add(13);
set.add(11);
for (Integer integer : set) {
System.out.println(integer);
}
}
LinkedHashSet底層維護的不再是一個HashMap,而是LinkedHashMap,它能夠在插入數據時利用鏈表自動維護順序,因此這樣就能夠保證我們插入順序和最後的迭代順序一致了。
還有一種Set叫做TreeSet,它會在元素插入時進行排序:
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>();
set.add(1);
set.add(3);
set.add(2);
System.out.println(set);
}
可以看到最後得到的結果並不是我們插入順序,而是按照數字的大小進行排列。當然,我們也可以自定義排序規則:
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>((a, b) -> b - a); //在創建對象時指定規則即可
set.add(1);
set.add(3);
set.add(2);
System.out.println(set);
}
現在的結果就是我們自定義的排序規則了。
雖然Set集合只是粗略的進行了講解,但是學習Map之後,我們還會回來看我們Set的底層實現,所以說最重要的還是Map。本節只需要記住Set的性質、使用即可。
Map映射
什麼是映射
我們在高中階段其實已經學習過映射了,映射指兩個元素的之間相互「對應」的關係,也就是說,我們的元素之間是兩兩對應的,是以鍵值對的形式存在。
Map接口
Map就是為了實現這種數據結構而存在的,我們通過保存鍵值對的形式來存儲映射關係。
我們先來看看Map接口中定義了哪些操作。
HashMap和LinkedHashMap
HashMap的實現過程,相比List,就非常地複雜了,它並不是簡簡單單的表結構,而是利用哈希表存放映射關係,我們來看看HashMap是如何實現的,首先回顧我們之前學習的哈希表,它長這樣:

哈希表的本質其實就是一個用於存放後續節點的頭結點的數組,數組裏面的每一個元素都是一個頭結點(也可以說就是一個鏈表),當要新插入一個數據時,會先計算該數據的哈希值,找到數組下標,然後創建一個新的節點,添加到對應的鏈表後面。
而HashMap就是採用的這種方式,我們可以看到源碼中同樣定義了這樣的一個結構:
/**
* The table, initialized on first use, and resized as
* necessary. When allocated, length is always a power of two.
* (We also tolerate length zero in some operations to allow
* bootstrapping mechanics that are currently not needed.)
*/
transient Node<K,V>[] table;
這個表會在第一次使用時初始化,同時在必要時進行擴容,並且它的大小永遠是2的倍數!
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
我們可以看到默認的大小為2的4次方,每次都需要是2的倍數,也就是說,下一次增長之後,大小會變成2的5次方。
我們現在需要思考一個問題,當我們表中的數據不斷增加之後,鏈表會變得越來越長,這樣會嚴重導致查詢速度變慢,首先想到辦法就是,我們可以對數組的長度進行擴容,來存放更多的鏈表,那麼什麼情況下會進行擴容呢?
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
我們還發現HashMap源碼中有這樣一個變量,也就是負載因子,那麼它是幹嘛的呢?
負載因子其實就是用來衡量當前情況是否需要進行擴容的標準。我們可以看到默認的負載因子是0.75
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
那麼負載因子是怎麼控制擴容的呢?0.75的意思是,在插入新的結點後,如果當前數組的佔用率達到75%則進行擴容。在擴容時,會將所有的數據,重新計算哈希值,得到一個新的下標,組成新的哈希表。
但是這樣依然有一個問題,鏈表過長的情況還是有可能發生,所以,為了從根源上解決這個問題,在JDK1.8時,引入了紅黑樹這個數據結構。
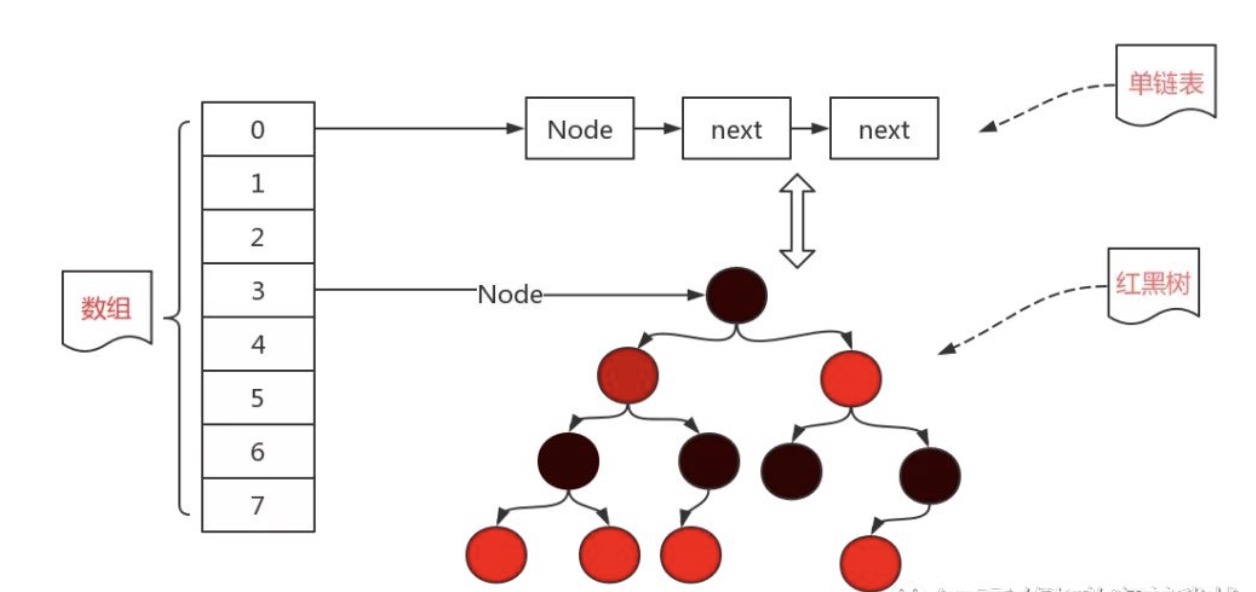
當鏈表的長度達到8時,會自動將鏈錶轉換為紅黑樹,這樣能使得原有的查詢效率大幅度降低!當使用紅黑樹之後,我們就可以利用二分搜索的思想,快速地去尋找我們想要的結果,而不是像鏈表一樣挨個去看。
/**
* Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn
* extends Node) so can be used as extension of either regular or
* linked node.
*/
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
除了Node以外,HashMap還有TreeNode,很明顯這就是為了實現紅黑樹而設計的內部類。不過我們發現,TreeNode並不是直接繼承Node,而是使用了LinkedHashMap中的Entry實現,它保存了前後節點的順序(也就是我們的插入順序)。
/**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
LinkedHashMap是直接繼承自HashMap,具有HashMap的全部性質,同時得益於每一個節點都是一個雙向鏈表,保存了插入順序,這樣我們在遍歷LinkedHashMap時,順序就同我們的插入順序一致。當然,也可以使用訪問順序,也就是說對於剛訪問過的元素,會被排到最後一位。
public static void main(String[] args) {
LinkedHashMap<Integer, String> map = new LinkedHashMap<>(16, 0.75f, true); //以訪問順序
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
map.get(2);
System.out.println(map);
}
觀察結果,我們發現,剛訪問的結果被排到了最後一位。
TreeMap
TreeMap其實就是自動維護順序的一種Map,就和我們前面提到的TreeSet一樣:
/**
* The comparator used to maintain order in this tree map, or
* null if it uses the natural ordering of its keys.
*
* @serial
*/
private final Comparator<? super K> comparator;
private transient Entry<K,V> root;
/**
* Node in the Tree. Doubles as a means to pass key-value pairs back to
* user (see Map.Entry).
*/
static final class Entry<K,V> implements Map.Entry<K,V> {
我們發現它的內部直接維護了一個紅黑樹,就像它的名字一樣,就是一個Tree,因為它默認就是有序的,所以說直接採用紅黑樹會更好。我們在創建時,直接給予一個比較規則即可。
Map的使用
我們首先來看看Map的一些基本操作:
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
System.out.println(map.get(1)); //獲取Key為1的值
System.out.println(map.getOrDefault(0, "K")); //不存在就返回K
map.remove(1); //移除這個Key的鍵值對
}
由於Map並未實現迭代器接口,因此不支持foreach,但是JDK1.8為我們提供了forEach方法使用:
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
map.forEach((k, v) -> System.out.println(k+"->"+v));
for (Map.Entry<Integer, String> entry : map.entrySet()) { //也可以獲取所有的Entry來foreach
int key = entry.getKey();
String value = entry.getValue();
System.out.println(key+" -> "+value);
}
}
我們也可以單獨獲取所有的值或者是鍵:
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.put(3, "C");
System.out.println(map.keySet()); //直接獲取所有的key
System.out.println(map.values()); //直接獲取所有的值
}
再談Set原理
通過觀察HashSet的源碼發現,HashSet幾乎都在操作內部維護的一個HashMap,也就是說,HashSet只是一個錶殼,而內部維護的HashMap才是靈魂!
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
我們發現,在添加元素時,其實添加的是一個鍵為我們插入的元素,而值就是PRESENT常量:
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element <tt>e</tt> to this set if
* this set contains no element <tt>e2</tt> such that
* <tt>(e==null ? e2==null : e.equals(e2))</tt>.
* If this set already contains the element, the call leaves the set
* unchanged and returns <tt>false</tt>.
*
* @param e element to be added to this set
* @return <tt>true</tt> if this set did not already contain the specified
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
觀察其他的方法,也幾乎都是在用HashMap做事,所以說,HashSet利用了HashMap內部的數據結構,輕鬆地就實現了Set定義的全部功能!
再來看TreeSet,實際上用的就是我們的TreeMap:
/**
* The backing map.
*/
private transient NavigableMap<E,Object> m;
同理,這裡就不多做闡述了。
JDK1.8新增方法使用
最後,我們再來看看JDK1.8中集合類新增的一些操作(之前沒有提及的)首先來看看compute方法:
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.compute(1, (k, v) -> { //compute會將指定Key的值進行重新計算,若Key不存在,v會返回null
return v+"M"; //這裡返回原來的value+M
});
map.computeIfPresent(1, (k, v) -> { //當Key存在時存在則計算並賦予新的值
return v+"M"; //這裡返回原來的value+M
});
System.out.println(map);
}
也可以使用computeIfAbsent,當不存在Key時,計算並將鍵值對放入Map
public static void main(String[] args) {
Map<Integer, String> map = new HashMap<>();
map.put(1, "A");
map.put(2, "B");
map.computeIfAbsent(0, (k) -> { //若不存在則計算並插入新的值
return "M"; //這裡返回M
});
System.out.println(map);
}
merge方法用於處理數據:
public static void main(String[] args) {
List<Student> students = Arrays.asList(
new Student("yoni", "English", 80),
new Student("yoni", "Chiness", 98),
new Student("yoni", "Math", 95),
new Student("taohai.wang", "English", 50),
new Student("taohai.wang", "Chiness", 72),
new Student("taohai.wang", "Math", 41),
new Student("Seely", "English", 88),
new Student("Seely", "Chiness", 89),
new Student("Seely", "Math", 92)
);
Map<String, Integer> scoreMap = new HashMap<>();
students.forEach(student -> scoreMap.merge(student.getName(), student.getScore(), Integer::sum));
scoreMap.forEach((k, v) -> System.out.println("key:" + k + "總分" + "value:" + v));
}
static class Student {
private final String name;
private final String type;
private final int score;
public Student(String name, String type, int score) {
this.name = name;
this.type = type;
this.score = score;
}
public String getName() {
return name;
}
public int getScore() {
return score;
}
public String getType() {
return type;
}
}
集合的嵌套
既然集合類型中的元素類型是泛型,那麼能否嵌套存儲呢?
public static void main(String[] args) {
Map<String, List<Integer>> map = new HashMap<>(); //每一個映射都是 字符串<->列表
map.put("卡布奇諾今猶在", new LinkedList<>());
map.put("不見當年倒茶人", new LinkedList<>());
System.out.println(map.keySet());
System.out.println(map.values());
}
通過Key獲取到對應的值後,就是一個列表:
map.get("卡布奇諾今猶在").add(10);
System.out.println(map.get("卡布奇諾今猶在").get(0));
讓套娃繼續下去:
public static void main(String[] args) {
Map<Integer, Map<Integer, Map<Integer, String>>> map = new HashMap<>();
}
你也可以使用List來套娃別的:
public static void main(String[] args) {
List<Map<String, Set<String>>> list = new LinkedList<>();
}
流Stream和Optional的使用
Java 8 API添加了一個新的抽象稱為流Stream,可以讓你以一種聲明的方式處理數據。Stream 使用一種類似用 SQL 語句從數據庫查詢數據的直觀方式來提供一種對 Java 集合運算和表達的高階抽象。Stream API可以極大提高Java程序員的生產力,讓程序員寫出高效率、乾淨、簡潔的代碼。這種風格將要處理的元素集合看作一種流, 流在管道中傳輸, 並且可以在管道的節點上進行處理, 比如篩選, 排序,聚合等。元素流在管道中經過中間操作(intermediate operation)的處理,最後由最終操作(terminal operation)得到前面處理的結果。

它看起來就像一個工廠的流水線一樣!我們就可以把一個Stream當做流水線處理:
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("A");
list.add("B");
list.add("C");
//移除為B的元素
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
if(iterator.next().equals("B")) iterator.remove();
}
//Stream操作
list = list //鏈式調用
.stream() //獲取流
.filter(e -> !e.equals("B")) //只允許所有不是B的元素通過流水線
.collect(Collectors.toList()); //將流水線中的元素重新收集起來,變回List
System.out.println(list);
}
可能從上述例子中還不能感受到流處理帶來的便捷,我們通過下面這個例子來感受一下:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(3);
list = list
.stream()
.distinct() //去重(使用equals判斷)
.sorted((a, b) -> b - a) //進行倒序排列
.map(e -> e+1) //每個元素都要執行+1操作
.limit(2) //只放行前兩個元素
.collect(Collectors.toList());
System.out.println(list);
}
當遇到大量的複雜操作時,我們就可以使用Stream來快速編寫代碼,這樣不僅代碼量大幅度減少,而且邏輯也更加清晰明了(如果你學習過SQL的話,你會發現它更像一個Sql語句)
注意:不能認為每一步是直接依次執行的!
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(3);
list = list
.stream()
.distinct() //斷點
.sorted((a, b) -> b - a)
.map(e -> {
System.out.println(">>> "+e); //斷點
return e+1;
})
.limit(2) //斷點
.collect(Collectors.toList());
//實際上,stream會先記錄每一步操作,而不是直接開始執行內容,當整個鏈式調用完成後,才會依次進行!
接下來,我們用一堆隨機數來進行更多流操作的演示:
public static void main(String[] args) {
Random random = new Random(); //Random是一個隨機數工具類
random
.ints(-100, 100) //生成-100~100之間的,隨機int型數字(本質上是一個IntStream)
.limit(10) //只獲取前10個數字(這是一個無限制的流,如果不加以限制,將會無限進行下去!)
.filter(i -> i < 0) //只保留小於0的數字
.sorted() //默認從小到大排序
.forEach(System.out::println); //依次打印
}
我們可以生成一個統計實例來幫助我們快速進行統計:
public static void main(String[] args) {
Random random = new Random(); //Random是一個隨機數工具類
IntSummaryStatistics statistics = random
.ints(0, 100)
.limit(100)
.summaryStatistics(); //獲取語法統計實例
System.out.println(statistics.getMax()); //快速獲取最大值
System.out.println(statistics.getCount()); //獲取數量
System.out.println(statistics.getAverage()); //獲取平均值
}
普通的List只需要一個方法就可以直接轉換到方便好用的IntStream了:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.stream()
.mapToInt(i -> i) //將每一個元素映射為Integer類型(這裡因為本來就是Integer)
.summaryStatistics();
}
我們還可以通過flat來對整個流進行進一步細分:
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("A,B");
list.add("C,D");
list.add("E,F"); //我們想讓每一個元素通過,進行分割,變成獨立的6個元素
list = list
.stream() //生成流
.flatMap(e -> Arrays.stream(e.split(","))) //分割字符串並生成新的流
.collect(Collectors.toList()); //匯成新的List
System.out.println(list); //得到結果
}
我們也可以只通過Stream來完成所有數字的和,使用reduce方法:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
int sum = list
.stream()
.reduce((a, b) -> a + b) //計算規則為:a是上一次計算的值,b是當前要計算的參數,這裡是求和
.get(); //我們發現得到的是一個Optional類實例,不是我們返回的類型,通過get方法返回得到的值
System.out.println(sum);
}
通過上面的例子,我們發現,Stream不喜歡直接給我們返回一個結果,而是通過Optinal的方式,那麼什麼是Optional呢?
Optional類是Java8為了解決null值判斷問題,使用Optional類可以避免顯式的null值判斷(null的防禦性檢查),避免null導致的NPE(NullPointerException)。總而言之,就是對控制的一個判斷,為了避免空指針異常。
public static void main(String[] args) {
String str = null;
if(str != null){ //當str不為空時添加元素到List中
list.add(str);
}
}
有了Optional之後,我們就可以這樣寫:
public static void main(String[] args) {
String str = null;
Optional<String> optional = Optional.ofNullable(str); //轉換為Optional
optional.ifPresent(System.out::println); //當存在時再執行方法
}
就類似於Kotlin中的:
var str : String? = null
str?.upperCase()
我們可以選擇直接get或是當值為null時,獲取備選值:
public static void main(String[] args) {
String str = null;
Optional optional = Optional.ofNullable(str); //轉換為Optional(可空)
System.out.println(optional.orElse("lbwnb"));
// System.out.println(optional.get()); 這樣會直接報錯
}
同樣的,Optional也支持過濾操作和映射操作,不過是對於單對象而言:
public static void main(String[] args) {
String str = "A";
Optional optional = Optional.ofNullable(str); //轉換為Optional(可空)
System.out.println(optional.filter(s -> s.equals("B")).get()); //被過濾了,此時元素為null,獲取時報錯
}
public static void main(String[] args) {
List<String> list = new ArrayList<>();
String str = "A";
Optional optional = Optional.ofNullable(str); //轉換為Optional(可空)
System.out.println(optional.map(s -> s + "A").get()); //在尾部追加一個A
}
其他操作自學了解。
Arrays和Collections的使用
Arrays是一個用於操作數組的工具類,它給我們提供了大量的工具方法:
/**
* This class contains various methods for manipulating arrays (such as
* sorting and searching). This class also contains a static factory
* that allows arrays to be viewed as lists. <- 注意,這句話很關鍵
*
* @author Josh Bloch
* @author Neal Gafter
* @author John Rose
* @since 1.2
*/
public class Arrays {
由於操作數組並不像集合那樣方便,因此JDK提供了Arrays類來增強對數組操作,比如:
public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
Arrays.sort(array); //直接進行排序(底層原理:進行判斷,元素少使用插入排序,大量元素使用雙軸快速/歸併排序)
System.out.println(array); //由於int[]是一個對象類型,而數組默認是沒有重寫toString()方法,因此無法打印到想要的結果
System.out.println(Arrays.toString(array)); //我們可以使用Arrays.toString()來像集合一樣直接打印每一個元素出來
}
public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
Arrays.sort(array);
System.out.println("排序後的結果:"+Arrays.toString(array));
System.out.println("目標元素3位置為:"+Arrays.binarySearch(array, 3)); //二分搜素,必須是已經排序好的數組!
}
public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
Arrays
.stream(array) //將數組轉換為流進行操作
.sorted()
.forEach(System.out::println);
}
public static void main(String[] args) {
int[] array = {1, 5, 2, 4, 7, 3, 6};
int[] array2 = Arrays.copyOf(array, array.length); //複製一個一模一樣的數組
System.out.println(Arrays.toString(array2));
System.out.println(Arrays.equals(array, array2)); //比較兩個數組是否值相同
Arrays.fill(array, 0); //將數組的所有值全部填充為指定值
System.out.println(Arrays.toString(array));
Arrays.setAll(array2, i -> array2[i] + 2); //依次計算每一個元素(注意i是下標位置)
System.out.println(Arrays.toString(array2)); //這裡計算讓每個元素值+2
}
思考:當二維數組使用Arrays.equals()進行比較以及Arrays.toString()進行打印時,還會得到我們想要的結果嗎?
public static void main(String[] args) {
Integer[][] array = {{1, 5}, {2, 4}, {7, 3}, {6}};
Integer[][] array2 = {{1, 5}, {2, 4}, {7, 3}, {6}};
System.out.println(Arrays.toString(array)); //這樣還會得到我們想要的結果嗎?
System.out.println(Arrays.equals(array2, array)); //這樣還會得到true嗎?
System.out.println(Arrays.deepToString(array)); //使用deepToString就能到打印多維數組
System.out.println(Arrays.deepEquals(array2, array)); //使用deepEquals就能比較多維數組
}
那麼,一開始提到的當做List進行操作呢?我們可以使用Arrays.asList()來將數組轉換為一個 固定長度的List
public static void main(String[] args) {
Integer[] array = {1, 5, 2, 4, 7, 3, 6};
List<Integer> list = Arrays.asList(array); //不支持基本類型數組,必須是對象類型數組
Arrays.asList("A", "B", "C"); //也可以逐個添加,因為是可變參數
list.add(1); //此List實現是長度固定的,是Arrays內部單獨實現的一個類型,因此不支持添加操作
list.remove(0); //同理,也不支持移除
list.set(0, 8); //直接設置指定下標的值就可以
list.sort(Comparator.reverseOrder()); //也可以執行排序操作
System.out.println(list); //也可以像List那樣直接打印
}
文字遊戲:allows arrays to be viewed as lists,實際上只是當做List使用,本質還是數組,因此數組的屬性依然存在!因此如果要將數組快速轉換為實際的List,可以像這樣:
public static void main(String[] args) {
Integer[] array = {1, 5, 2, 4, 7, 3, 6};
List<Integer> list = new ArrayList<>(Arrays.asList(array));
}
通過自行創建一個真正的ArrayList並在構造時將Arrays的List值傳遞。
既然數組操作都這麼方便了,集合操作能不能也安排點高級的玩法呢?那必須的,JDK為我們準備的Collocations類就是專用於集合的工具類:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
Collections.max(list);
Collections.min(list);
}
當然,Collections提供的內容相比Arrays會更多,希望大家下去自行了解,這裡就不多做介紹了。
Java I/O
注意:這塊會涉及到操作系統和計算機組成原理相關內容。
操作系統詳解://www.cnblogs.com/zwtblog/p/15265331.html
計算機組成原理://www.cnblogs.com/zwtblog/p/15266143.html
I/O簡而言之,就是輸入輸出,那麼為什麼會有I/O呢?其實I/O無時無刻都在我們的身邊,比如讀取硬盤上的文件,網絡文件傳輸,鼠標鍵盤輸入,也可以是接受單片機發回的數據,而能夠支持這些操作的設備就是I/O設備。
我們可以大致看一下整個計算機的總線結構:

常見的I/O設備一般是鼠標、鍵盤這類通過USB進行傳輸的外設或者是通過Sata接口或是M.2連接的硬盤。一般情況下,這些設備是由CPU發出指令通過南橋芯片間接進行控制,而不是由CPU直接操作。
而我們在程序中,想要讀取這些外部連接的I/O設備中的內容,就需要將數據傳輸到內存中。
而需要實現這樣的操作,單單憑藉一個小的程序是無法做到的,而操作系統(如:Windows/Linux/MacOS)就是專門用於控制和管理計算機硬件和軟件資源的軟件,我們需要讀取一個IO設備的內容時,可以向操作系統發出請求,由操作系統幫助我們來和底層的硬件交互以完成我們的讀取/寫入請求。從讀取硬盤文件的角度來說,不同的操作系統有着不同的文件系統(也就是文件在硬盤中的存儲排列方式,如Windows就是NTFS、MacOS就是APFS),硬盤只能存儲一個個0和1這樣的二進制數據,至於0和1如何排列,各自又代表什麼意思,就是由操作系統的文件系統來決定的。從網絡通信角度來說,網絡信號通過網卡等設備翻譯為二進制信號,再交給系統進行讀取,最後再由操作系統來給到程序。
JDK提供了一套用於IO操作的框架,根據流的傳輸方向和讀取單位,分為位元組流InputStream和OutputStream以及字符流Reader和Writer,當然,這裡的Stream並不是前面集合框架認識的Stream,這裡的流指的是數據流,通過流,我們就可以一直從流中讀取數據,直到讀取到盡頭,或是不斷向其中寫入數據,直到我們寫入完成。而這類IO就是我們所說的BIO,
位元組流一次讀取一個位元組,也就是一個byte的大小,而字符流顧名思義,就是一次讀取一個字符,也就是一個char的大小(在讀取純文本文件的時候更加適合),有關這兩種流,會在後面詳細介紹,這個章節我們需要學習16個關鍵的流。
文件流
要學習和使用IO,首先就要從最易於理解的讀取文件開始說起。
文件位元組流
首先介紹一下FileInputStream,通過它來獲取文件的輸入流。
public static void main(String[] args) {
try {
FileInputStream inputStream = new FileInputStream("路徑");
//路徑支持相對路徑和絕對路徑
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
相對路徑是在當前運行的路徑下尋找文件,而絕對路徑,是從根目錄開始尋找。路徑分割符支持使用/或是\\,但是不能寫為\因為它是轉義字符!
在使用完成一個流之後,必須關閉這個流來完成對資源的釋放,否則資源會被一直佔用!
public static void main(String[] args) {
FileInputStream inputStream = null; //定義可以先放在try外部
try {
inputStream = new FileInputStream("路徑");
} catch (FileNotFoundException e) {
e.printStackTrace();
} finally {
try { //建議在finally中進行,因為這個是任何情況都必須要執行的!
if(inputStream != null) inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
雖然這樣的寫法才是最保險的,但是顯得過於繁瑣了,尤其是finally中再次嵌套了一個try-catch塊,因此在JDK1.7新增了try-with-resource語法,用於簡化這樣的寫法(本質上還是和這樣的操作一致,只是換了個寫法)
public static void main(String[] args) {
//注意,這種語法只支持實現了AutoCloseable接口的類!
try(FileInputStream inputStream = new FileInputStream("路徑")) { //直接在try()中定義要在完成之後釋放的資源
} catch (IOException e) { //這裡變成IOException是因為調用close()可能會出現,而FileNotFoundException是繼承自IOException的
e.printStackTrace();
}
//無需再編寫finally語句塊,因為在最後自動幫我們調用了close()
}
之後為了方便,我們都使用此語法進行教學。
public static void main(String[] args) {
//test.txt:a
try(FileInputStream inputStream = new FileInputStream("test.txt")) {
//使用read()方法進行字符讀取
System.out.println((char) inputStream.read()); //讀取一個位元組的數據(英文字母只佔1位元組,中文佔2位元組)
System.out.println(inputStream.read()); //唯一一個位元組的內容已經讀完了,再次讀取返回-1表示沒有內容了
}catch (IOException e){
e.printStackTrace();
}
}
使用read可以直接讀取一個位元組的數據,注意,流的內容是有限的,讀取一個少一個!我們如果想一次性全部讀取的話,可以直接使用一個while循環來完成:
public static void main(String[] args) {
//test.txt:abcd
try(FileInputStream inputStream = new FileInputStream("test.txt")) {
int tmp;
while ((tmp = inputStream.read()) != -1){ //通過while循環來一次性讀完內容
System.out.println((char)tmp);
}
}catch (IOException e){
e.printStackTrace();
}
}
使用方法能查看當前可讀的剩餘位元組數量(注意:並不一定真實的數據量就是這麼多,尤其是在網絡I/O操作時,這個方法只能進行一個預估也可以說是暫時能一次性讀取的數量)
try(FileInputStream inputStream = new FileInputStream("test.txt")) {
System.out.println(inputStream.available()); //查看剩餘數量
}catch (IOException e){
e.printStackTrace();
}
當然,一個一個讀取效率太低了,那能否一次性全部讀取呢?我們可以預置一個合適容量的byte[]數組來存放。
public static void main(String[] args) {
//test.txt:abcd
try(FileInputStream inputStream = new FileInputStream("test.txt")) {
byte[] bytes = new byte[inputStream.available()]; //我們可以提前準備好合適容量的byte數組來存放
System.out.println(inputStream.read(bytes)); //一次性讀取全部內容(返回值是讀取的位元組數)
System.out.println(new String(bytes)); //通過String(byte[])構造方法得到字符串
}catch (IOException e){
e.printStackTrace();
}
}
也可以控制要讀取數量:
System.out.println(inputStream.read(bytes, 1, 2)); //第二個參數是從給定數組的哪個位置開始放入內容,第三個參數是讀取流中的位元組數
注意:一次性讀取同單個讀取一樣,當沒有任何數據可讀時,依然會返回-1
通過skip()方法可以跳過指定數量的位元組:
public static void main(String[] args) {
//test.txt:abcd
try(FileInputStream inputStream = new FileInputStream("test.txt")) {
System.out.println(inputStream.skip(1));
System.out.println((char) inputStream.read()); //跳過了一個位元組
}catch (IOException e){
e.printStackTrace();
}
}
注意:FileInputStream是不支持reset()的,雖然有這個方法,但是這裡先不提及。
既然有輸入流,那麼文件輸出流也是必不可少的:
public static void main(String[] args) {
//輸出流也需要在最後調用close()方法,並且同樣支持try-with-resource
try(FileOutputStream outputStream = new FileOutputStream("output.txt")) {
//注意:若此文件不存在,會直接創建這個文件!
}catch (IOException e){
e.printStackTrace();
}
}
輸出流沒有read()操作而是write()操作,使用方法同輸入流一樣,只不過現在的方向變為我們向文件里寫入內容:
public static void main(String[] args) {
try(FileOutputStream outputStream = new FileOutputStream("output.txt")) {
outputStream.write('c'); //同read一樣,可以直接寫入內容
outputStream.write("lbwnb".getBytes()); //也可以直接寫入byte[]
outputStream.write("lbwnb".getBytes(), 0, 1); //同上輸入流
outputStream.flush(); //建議在最後執行一次刷新操作(強制寫入)來保證數據正確寫入到硬盤文件中
}catch (IOException e){
e.printStackTrace();
}
}
那麼如果是我只想在文件尾部進行追加寫入數據呢?我們可以調用另一個構造方法來實現:
public static void main(String[] args) {
try(FileOutputStream outputStream = new FileOutputStream("output.txt", true)) {
outputStream.write("lb".getBytes()); //現在只會進行追加寫入,而不是直接替換原文件內容
outputStream.flush();
}catch (IOException e){
e.printStackTrace();
}
}
利用輸入流和輸出流,就可以輕鬆實現文件的拷貝了:
public static void main(String[] args) {
try(FileOutputStream outputStream = new FileOutputStream("output.txt");
FileInputStream inputStream = new FileInputStream("test.txt")) { //可以寫入多個
byte[] bytes = new byte[10]; //使用長度為10的byte[]做傳輸媒介
int tmp; //存儲本地讀取位元組數
while ((tmp = inputStream.read(bytes)) != -1){ //直到讀取完成為止
outputStream.write(bytes, 0, tmp); //寫入對應長度的數據到輸出流
}
}catch (IOException e){
e.printStackTrace();
}
}
文件字符流
字符流不同於位元組,字符流是以一個具體的字符進行讀取,因此它只適合讀純文本的文件,如果是其他類型的文件不適用:
public static void main(String[] args) {
try(FileReader reader = new FileReader("test.txt")){
reader.skip(1); //現在跳過的是一個字符
System.out.println((char) reader.read()); //現在是按字符進行讀取,而不是位元組,因此可以直接讀取到中文字符
}catch (IOException e){
e.printStackTrace();
}
}
同理,字符流只支持char[]類型作為存儲:
public static void main(String[] args) {
try(FileReader reader = new FileReader("test.txt")){
char[] str = new char[10];
reader.read(str);
System.out.println(str); //直接讀取到char[]中
}catch (IOException e){
e.printStackTrace();
}
}
既然有了Reader肯定也有Writer:
public static void main(String[] args) {
try(FileWriter writer = new FileWriter("output.txt")){
writer.getEncoding(); //支持獲取編碼(不同的文本文件可能會有不同的編碼類型)
writer.write('牛');
writer.append('牛'); //其實功能和write一樣
writer.flush(); //刷新
}catch (IOException e){
e.printStackTrace();
}
}
我們發現不僅有write()方法,還有一個append()方法,但是實際上他們效果是一樣的,看源碼:
/**
* Appends the specified character to this writer.
*
* <p> An invocation of this method of the form <tt>out.append(c)</tt>
* behaves in exactly the same way as the invocation
*
* <pre>
* out.write(c) </pre>
*
* @param c
* The 16-bit character to append
*
* @return This writer
*
* @throws IOException
* If an I/O error occurs
*
* @since 1.5
*/
public Writer append(char c) throws IOException {
write(c);
return this;
}
append支持像StringBuilder那樣的鏈式調用,返回的是Writer對象本身。
練習:嘗試一下用Reader和Writer來拷貝純文本文件
File類
File類專門用於表示一個文件或文件夾,只不過它只是代表這個文件,但並不是這個文件本身。通過File對象,可以更好地管理和操作硬盤上的文件。
public static void main(String[] args) {
File file = new File("test.txt"); //直接創建文件對象,可以是相對路徑,也可以是絕對路徑
System.out.println(file.exists()); //此文件是否存在
System.out.println(file.length()); //獲取文件的大小
System.out.println(file.isDirectory()); //是否為一個文件夾
System.out.println(file.canRead()); //是否可讀
System.out.println(file.canWrite()); //是否可寫
System.out.println(file.canExecute()); //是否可執行
}
通過File對象,我們就能快速得到文件的所有信息,如果是文件夾,還可以獲取文件夾內部的文件列表等內容:
File file = new File("/");
System.out.println(Arrays.toString(file.list())); //快速獲取文件夾下的文件名稱列表
for (File f : file.listFiles()){ //所有子文件的File對象
System.out.println(f.getAbsolutePath()); //獲取文件的絕對路徑
}
如果我們希望讀取某個文件的內容,可以直接將File作為參數傳入位元組流或是字符流:
File file = new File("test.txt");
try (FileInputStream inputStream = new FileInputStream(file)){ //直接做參數
System.out.println(inputStream.available());
}catch (IOException e){
e.printStackTrace();
}
練習:嘗試拷貝文件夾下的所有文件到另一個文件夾
緩衝流
雖然普通的文件流讀取文件數據非常便捷,但是每次都需要從外部I/O設備去獲取數據,由於外部I/O設備的速度一般都達不到內存的讀取速度,很有可能造成程序反應遲鈍,因此性能還不夠高,而緩衝流正如其名稱一樣,它能夠提供一個緩衝,提前將部分內容存入內存(緩衝區)在下次讀取時,如果緩衝區中存在此數據,則無需再去請求外部設備。同理,當向外部設備寫入數據時,也是由緩衝區處理,而不是直接向外部設備寫入。

緩衝位元組流
要創建一個緩衝位元組流,只需要將原本的流作為構造參數傳入BufferedInputStream即可:
public static void main(String[] args) {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("test.txt"))){ //傳入FileInputStream
System.out.println((char) bufferedInputStream.read()); //操作和原來的流是一樣的
}catch (IOException e){
e.printStackTrace();
}
}
實際上進行I/O操作的並不是BufferedInputStream,而是我們傳入的FileInputStream,而BufferedInputStream雖然有着同樣的方法,但是進行了一些額外的處理然後再調用FileInputStream的同名方法,這樣的寫法稱為裝飾者模式
public void close() throws IOException {
byte[] buffer;
while ( (buffer = buf) != null) {
if (bufUpdater.compareAndSet(this, buffer, null)) { //CAS無鎖算法,並發會用到,暫時不管
InputStream input = in;
in = null;
if (input != null)
input.close();
return;
}
// Else retry in case a new buf was CASed in fill()
}
}
實際上這種模式是父類FilterInputStream提供的規範,後面我們還會講到更多FilterInputStream的子類。
我們可以發現在BufferedInputStream中還存在一個專門用於緩存的數組:
/**
* The internal buffer array where the data is stored. When necessary,
* it may be replaced by another array of
* a different size.
*/
protected volatile byte buf[];
I/O操作一般不能重複讀取內容(比如鍵盤發送的信號,主機接收了就沒了),而緩衝流提供了緩衝機制,一部分內容可以被暫時保存,BufferedInputStream支持reset()和mark()操作,首先我們來看看mark()方法的介紹:
/**
* Marks the current position in this input stream. A subsequent
* call to the <code>reset</code> method repositions this stream at
* the last marked position so that subsequent reads re-read the same bytes.
* <p>
* The <code>readlimit</code> argument tells this input stream to
* allow that many bytes to be read before the mark position gets
* invalidated.
* <p>
* This method simply performs <code>in.mark(readlimit)</code>.
*
* @param readlimit the maximum limit of bytes that can be read before
* the mark position becomes invalid.
* @see java.io.FilterInputStream#in
* @see java.io.FilterInputStream#reset()
*/
public synchronized void mark(int readlimit) {
in.mark(readlimit);
}
當調用mark()之後,輸入流會以某種方式保留之後讀取的readlimit數量的內容,當讀取的內容數量超過readlimit則之後的內容不會被保留,當調用reset()之後,會使得當前的讀取位置回到mark()調用時的位置。
public static void main(String[] args) {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("test.txt"))){
bufferedInputStream.mark(1); //只保留之後的1個字符
System.out.println((char) bufferedInputStream.read());
System.out.println((char) bufferedInputStream.read());
bufferedInputStream.reset(); //回到mark時的位置
System.out.println((char) bufferedInputStream.read());
System.out.println((char) bufferedInputStream.read());
}catch (IOException e) {
e.printStackTrace();
}
}
我們發現雖然後面的部分沒有保存,但是依然能夠正常讀取,其實mark()後保存的讀取內容是取readlimit和BufferedInputStream類的緩衝區大小兩者中的最大值,而並非完全由readlimit確定。因此我們限制一下緩衝區大小,再來觀察一下結果:
public static void main(String[] args) {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("test.txt"), 1)){ //將緩衝區大小設置為1
bufferedInputStream.mark(1); //只保留之後的1個字符
System.out.println((char) bufferedInputStream.read());
System.out.println((char) bufferedInputStream.read()); //已經超過了readlimit,繼續讀取會導致mark失效
bufferedInputStream.reset(); //mark已經失效,無法reset()
System.out.println((char) bufferedInputStream.read());
System.out.println((char) bufferedInputStream.read());
}catch (IOException e) {
e.printStackTrace();
}
}
了解完了BufferedInputStream之後,我們再來看看BufferedOutputStream,其實和BufferedInputStream原理差不多,只是反向操作:
public static void main(String[] args) {
try (BufferedOutputStream outputStream = new BufferedOutputStream(new FileOutputStream("output.txt"))){
outputStream.write("lbwnb".getBytes());
outputStream.flush();
}catch (IOException e) {
e.printStackTrace();
}
}
操作和FileOutputStream一致,這裡就不多做介紹了。
緩衝字符流
緩存字符流和緩衝位元組流一樣,也有一個專門的緩衝區,BufferedReader構造時需要傳入一個Reader對象:
public static void main(String[] args) {
try (BufferedReader reader = new BufferedReader(new FileReader("test.txt"))){
System.out.println((char) reader.read());
}catch (IOException e) {
e.printStackTrace();
}
}
使用和reader也是一樣的,內部也包含一個緩存數組:
private char cb[];
相比Reader更方便的是,它支持按行讀取:
public static void main(String[] args) {
try (BufferedReader reader = new BufferedReader(new FileReader("test.txt"))){
System.out.println(reader.readLine()); //按行讀取
}catch (IOException e) {
e.printStackTrace();
}
}
讀取後直接得到一個字符串,當然,它還能把每一行內容依次轉換為集合類提到的Stream流:
public static void main(String[] args) {
try (BufferedReader reader = new BufferedReader(new FileReader("test.txt"))){
reader
.lines()
.limit(2)
.distinct()
.sorted()
.forEach(System.out::println);
}catch (IOException e) {
e.printStackTrace();
}
}
它同樣也支持mark()和reset()操作:
public static void main(String[] args) {
try (BufferedReader reader = new BufferedReader(new FileReader("test.txt"))){
reader.mark(1);
System.out.println((char) reader.read());
reader.reset();
System.out.println((char) reader.read());
}catch (IOException e) {
e.printStackTrace();
}
}
BufferedReader處理純文本文件時就更加方便了,BufferedWriter在處理時也同樣方便:
public static void main(String[] args) {
try (BufferedWriter reader = new BufferedWriter(new FileWriter("output.txt"))){
reader.newLine(); //使用newLine進行換行
reader.write("漢堡做滴彳亍不彳亍"); //可以直接寫入一個字符串
reader.flush(); //清空緩衝區
}catch (IOException e) {
e.printStackTrace();
}
}
轉換流
有時會遇到這樣一個很麻煩的問題:我這裡讀取的是一個字符串或是一個個字符,但是我只能往一個OutputStream里輸出,但是OutputStream又只支持byte類型,如果要往裏面寫入內容,進行數據轉換就會很麻煩,那麼能否有更加簡便的方式來做這樣的事情呢?
public static void main(String[] args) {
try(OutputStreamWriter writer = new OutputStreamWriter(new FileOutputStream("test.txt"))){ //雖然給定的是FileOutputStream,但是現在支持以Writer的方式進行寫入
writer.write("lbwnb"); //以操作Writer的樣子寫入OutputStream
}catch (IOException e){
e.printStackTrace();
}
}
同樣的,我們現在只拿到了一個InputStream,但是我們希望能夠按字符的方式讀取,我們就可以使用InputStreamReader來幫助我們實現:
public static void main(String[] args) {
try(InputStreamReader reader = new InputStreamReader(new FileInputStream("test.txt"))){ //雖然給定的是FileInputStream,但是現在支持以Reader的方式進行讀取
System.out.println((char) reader.read());
}catch (IOException e){
e.printStackTrace();
}
}
InputStreamReader和OutputStreamWriter本質也是Reader和Writer,因此可以直接放入BufferedReader來實現更加方便的操作。
打印流
打印流其實我們從一開始就在使用了,比如System.out就是一個PrintStream,PrintStream也繼承自FilterOutputStream類因此依然是裝飾我們傳入的輸出流,但是它存在自動刷新機制,例如當向PrintStream流中寫入一個位元組數組後自動調用flush()方法。PrintStream也永遠不會拋出異常,而是使用內部檢查機制checkError()方法進行錯誤檢查。最方便的是,它能夠格式化任意的類型,將它們以字符串的形式寫入到輸出流。
public final static PrintStream out = null;
可以看到System.out也是PrintStream,不過默認是向控制台打印,我們也可以讓它向文件中打印:
public static void main(String[] args) {
try(PrintStream stream = new PrintStream(new FileOutputStream("test.txt"))){
stream.println("lbwnb"); //其實System.out就是一個PrintStream
}catch (IOException e){
e.printStackTrace();
}
}
我們平時使用的println方法就是PrintStream中的方法,它會直接打印基本數據類型或是調用對象的toString()方法得到一個字符串,並將字符串轉換為字符,放入緩衝區再經過轉換流輸出到給定的輸出流上。
因此實際上內部還包含這兩個內容:
/**
* Track both the text- and character-output streams, so that their buffers
* can be flushed without flushing the entire stream.
*/
private BufferedWriter textOut;
private OutputStreamWriter charOut;
與此相同的還有一個PrintWriter,不過他們的功能基本一致,PrintWriter的構造方法可以接受一個Writer作為參數,這裡就不再做過多闡述了。
數據流
數據流DataInputStream也是FilterInputStream的子類,同樣採用裝飾者模式,最大的不同是它支持基本數據類型的直接讀取:
public static void main(String[] args) {
try (DataInputStream dataInputStream = new DataInputStream(new FileInputStream("test.txt"))){
System.out.println(dataInputStream.readBoolean()); //直接將數據讀取為任意基本數據類型
}catch (IOException e) {
e.printStackTrace();
}
}
用於寫入基本數據類型:
public static void main(String[] args) {
try (DataOutputStream dataOutputStream = new DataOutputStream(new FileOutputStream("output.txt"))){
dataOutputStream.writeBoolean(false);
}catch (IOException e) {
e.printStackTrace();
}
}
注意,寫入的是二進制數據,並不是寫入的字符串,使用DataInputStream可以讀取,一般他們是配合一起使用的。
對象流
既然基本數據類型能夠讀取和寫入基本數據類型,那麼能否將對象也支持呢?ObjectOutputStream不僅支持基本數據類型,通過對對象的序列化操作,以某種格式保存對象,來支持對象類型的IO,注意:它不是繼承自FilterInputStream的。
public static void main(String[] args) {
try (ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("output.txt"));
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream("output.txt"))){
People people = new People("lbw");
outputStream.writeObject(people);
outputStream.flush();
people = (People) inputStream.readObject();
System.out.println(people.name);
}catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
static class People implements Serializable{ //必須實現Serializable接口才能被序列化
String name;
public People(String name){
this.name = name;
}
}
在我們後續的操作中,有可能會使得這個類的一些結構發生變化,而原來保存的數據只適用於之前版本的這個類,因此我們需要一種方法來區分類的不同版本:
static class People implements Serializable{
private static final long serialVersionUID = 123456; //在序列化時,會被自動添加這個屬性,它代表當前類的版本,我們也可以手動指定版本。
String name;
public People(String name){
this.name = name;
}
}
當發生版本不匹配時,會無法反序列化為對象:
java.io.InvalidClassException: com.test.Main$People; local class incompatible: stream classdesc serialVersionUID = 123456, local class serialVersionUID = 1234567
at java.io.ObjectStreamClass.initNonProxy(ObjectStreamClass.java:699)
at java.io.ObjectInputStream.readNonProxyDesc(ObjectInputStream.java:2003)
at java.io.ObjectInputStream.readClassDesc(ObjectInputStream.java:1850)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2160)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1667)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:503)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:461)
at com.test.Main.main(Main.java:27)
如果我們不希望某些屬性參與到序列化中進行保存,我們可以添加transient關鍵字:
public static void main(String[] args) {
try (ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("output.txt"));
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream("output.txt"))){
People people = new People("lbw");
outputStream.writeObject(people);
outputStream.flush();
people = (People) inputStream.readObject();
System.out.println(people.name); //雖然能得到對象,但是name屬性並沒有保存,因此為null
}catch (IOException | ClassNotFoundException e) {
e.printStackTrace();
}
}
static class People implements Serializable{
private static final long serialVersionUID = 1234567;
transient String name;
public People(String name){
this.name = name;
}
}
其實我們可以看到,在一些JDK內部的源碼中,也存在大量的transient關鍵字,使得某些屬性不參與序列化,取消這些不必要保存的屬性,可以節省數據空間佔用以及減少序列化時間。
Java多線程
注意:本章節會涉及到 操作系統 相關知識。
在了解多線程之前,讓我們回顧一下操作系統中提到的進程概念:
進程是程序執行的實體,每一個進程都是一個應用程序(比如我們運行QQ、瀏覽器、LOL、網易雲音樂等軟件),都有自己的內存空間,CPU一個核心同時只能處理一件事情,當出現多個進程需要同時運行時,CPU一般通過時間片輪轉調度算法,來實現多個進程的同時運行。

在早期的計算機中,進程是擁有資源和獨立運行的最小單位,也是程序執行的最小單位。但是,如果我希望兩個任務同時進行,就必須運行兩個進程,由於每個進程都有一個自己的內存空間,進程之間的通信就變得非常麻煩(比如要共享某些數據)而且執行不同進程會產生上下文切換,非常耗時,那麼能否實現在一個進程中就能夠執行多個任務呢?

後來,線程橫空出世,一個進程可以有多個線程,線程是程序執行中一個單一的順序控制流程,現在線程才是程序執行流的最小單元,各個線程之間共享程序的內存空間(也就是所在進程的內存空間),上下文切換速度也高於進程。
在Java中,我們從開始,一直以來編寫的都是單線程應用程序(運行main()方法的內容),也就是說只能同時執行一個任務(無論你是調用方法、還是進行計算,始終都是依次進行的,也就是同步的),而如果我們希望同時執行多個任務(兩個方法同時在運行或者是兩個計算同時在進行,也就是異步的),就需要用到Java多線程框架。實際上一個Java程序啟動後,會創建很多線程,不僅僅只運行一個主線程:
public static void main(String[] args) {
ThreadMXBean bean = ManagementFactory.getThreadMXBean();
long[] ids = bean.getAllThreadIds();
ThreadInfo[] infos = bean.getThreadInfo(ids);
for (ThreadInfo info : infos) {
System.out.println(info.getThreadName());
}
}
關於除了main線程默認以外的線程,涉及到JVM相關底層原理,在這裡不做講解,了解就行。
線程的創建和啟動
通過創建Thread對象來創建一個新的線程,Thread構造方法中需要傳入一個Runnable接口的實現(其實就是編寫要在另一個線程執行的內容邏輯)同時Runnable只有一個未實現方法,因此可以直接使用lambda表達式:
@FunctionalInterface
public interface Runnable {
/**
* When an object implementing interface <code>Runnable</code> is used
* to create a thread, starting the thread causes the object's
* <code>run</code> method to be called in that separately executing
* thread.
* <p>
* The general contract of the method <code>run</code> is that it may
* take any action whatsoever.
*
* @see java.lang.Thread#run()
*/
public abstract void run();
}
創建好後,通過調用start()方法來運行此線程:
public static void main(String[] args) {
Thread t = new Thread(() -> { //直接編寫邏輯
System.out.println("我是另一個線程!");
});
t.start(); //調用此方法來開始執行此線程
}
可能上面的例子看起來和普通的單線程沒兩樣,那我們先來看看下面這段代碼的運行結果:
public static void main(String[] args) {
Thread t = new Thread(() -> {
System.out.println("我是線程:"+Thread.currentThread().getName());
System.out.println("我正在計算 0-10000 之間所有數的和...");
int sum = 0;
for (int i = 0; i <= 10000; i++) {
sum += i;
}
System.out.println("結果:"+sum);
});
t.start();
System.out.println("我是主線程!");
}
我們發現,這段代碼執行輸出結果並不是按照從上往下的順序了,因為他們分別位於兩個線程,他們是同時進行的!如果你還是覺得很疑惑,我們接着來看下面的代碼運行結果:
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 50; i++) {
System.out.println("我是一號線程:"+i);
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 50; i++) {
System.out.println("我是二號線程:"+i);
}
});
t1.start();
t2.start();
}
我們可以看到打印實際上是在交替進行的,也證明了他們是在同時運行!
注意:我們發現還有一個run方法,也能執行線程裏面定義的內容,但是run是直接在當前線程執行,並不是創建一個線程執行!

實際上,線程和進程差不多,也會等待獲取CPU資源,一旦獲取到,就開始按順序執行我們給定的程序,當需要等待外部IO操作(比如Scanner獲取輸入的文本),就會暫時處於休眠狀態,等待通知,或是調用sleep()方法來讓當前線程休眠一段時間:
public static void main(String[] args) throws InterruptedException {
System.out.println("l");
Thread.sleep(1000); //休眠時間,以毫秒為單位,1000ms = 1s
System.out.println("b");
Thread.sleep(1000);
System.out.println("w");
Thread.sleep(1000);
System.out.println("nb!");
}
我們也可以使用stop()方法來強行終止此線程:
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
Thread me = Thread.currentThread(); //獲取當前線程對象
for (int i = 0; i < 50; i++) {
System.out.println("打印:"+i);
if(i == 20) me.stop(); //此方法會直接終止此線程
}
});
t.start();
}
雖然stop()方法能夠終止此線程,但是並不是所推薦的做法,有關線程中斷相關問題,我們會在後面繼續了解。
思考:猜猜以下程序輸出結果:
private static int value = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) value++;
System.out.println("線程1完成");
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) value++;
System.out.println("線程2完成");
});
t1.start();
t2.start();
Thread.sleep(1000); //主線程停止1秒,保證兩個線程執行完成
System.out.println(value);
}
我們發現,value最後的值並不是我們理想的結果,有關為什麼會出現這種問題,在我們學習到線程鎖的時候,再來探討。
線程的休眠和中斷
我們前面提到,一個線程處於運行狀態下,線程的下一個狀態會出現以下情況:
- 當CPU給予的運行時間結束時,會從運行狀態回到就緒(可運行)狀態,等待下一次獲得CPU資源。
- 當線程進入休眠 / 阻塞(如等待IO請求) / 手動調用
wait()方法時,會使得線程處於等待狀態,當等待狀態結束後會回到就緒狀態。 - 當線程出現異常或錯誤 / 被
stop()方法強行停止 / 所有代碼執行結束時,會使得線程的運行終止。
而這個部分我們着重了解一下線程的休眠和中斷,首先我們來了解一下如何使得線程進如休眠狀態:
public static void main(String[] args) {
Thread t = new Thread(() -> {
try {
System.out.println("l");
Thread.sleep(1000); //sleep方法是Thread的靜態方法,它只作用於當前線程(它知道當前線程是哪個)
System.out.println("b"); //調用sleep後,線程會直接進入到等待狀態,直到時間結束
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t.start();
}
通過調用sleep()方法來將當前線程進入休眠,使得線程處於等待狀態一段時間。我們發現,此方法顯示聲明了會拋出一個InterruptedException異常,那麼這個異常在什麼時候會發生呢?
public static void main(String[] args) {
Thread t = new Thread(() -> {
try {
Thread.sleep(10000); //休眠10秒
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t.start();
try {
Thread.sleep(3000); //休眠3秒,一定比線程t先醒來
t.interrupt(); //調用t的interrupt方法
} catch (InterruptedException e) {
e.printStackTrace();
}
}
我們發現,每一個Thread對象中,都有一個interrupt()方法,調用此方法後,會給指定線程添加一個中斷標記以告知線程需要立即停止運行或是進行其他操作,由線程來響應此中斷並進行相應的處理,我們前面提到的stop()方法是強制終止線程,這樣的做法雖然簡單粗暴,但是很有可能導致資源不能完全釋放,而類似這樣的發送通知來告知線程需要中斷,讓線程自行處理後續,會更加合理一些,也是更加推薦的做法。我們來看看interrupt的用法:
public static void main(String[] args) {
Thread t = new Thread(() -> {
System.out.println("線程開始運行!");
while (true){ //無限循環
if(Thread.currentThread().isInterrupted()){ //判斷是否存在中斷標誌
break; //響應中斷
}
}
System.out.println("線程被中斷了!");
});
t.start();
try {
Thread.sleep(3000); //休眠3秒,一定比線程t先醒來
t.interrupt(); //調用t的interrupt方法
} catch (InterruptedException e) {
e.printStackTrace();
}
}
通過isInterrupted()可以判斷線程是否存在中斷標誌,如果存在,說明外部希望當前線程立即停止,也有可能是給當前線程發送一個其他的信號,如果我們並不是希望收到中斷信號就是結束程序,而是通知程序做其他事情,我們可以在收到中斷信號後,複位中斷標記,然後繼續做我們的事情:
public static void main(String[] args) {
Thread t = new Thread(() -> {
System.out.println("線程開始運行!");
while (true){
if(Thread.currentThread().isInterrupted()){ //判斷是否存在中斷標誌
System.out.println("發現中斷信號,複位,繼續運行...");
Thread.interrupted(); //複位中斷標記(返回值是當前是否有中斷標記,這裡不用管)
}
}
});
t.start();
try {
Thread.sleep(3000); //休眠3秒,一定比線程t先醒來
t.interrupt(); //調用t的interrupt方法
} catch (InterruptedException e) {
e.printStackTrace();
}
}
複位中斷標記後,會立即清除中斷標記。那麼,如果現在我們想暫停線程呢?我們希望線程暫時停下,比如等待其他線程執行完成後,再繼續運行,那這樣的操作怎麼實現呢?
public static void main(String[] args) {
Thread t = new Thread(() -> {
System.out.println("線程開始運行!");
Thread.currentThread().suspend(); //暫停此線程
System.out.println("線程繼續運行!");
});
t.start();
try {
Thread.sleep(3000); //休眠3秒,一定比線程t先醒來
t.resume(); //恢復此線程
} catch (InterruptedException e) {
e.printStackTrace();
}
}
雖然這樣很方便地控制了線程的暫停狀態,但是這兩個方法我們發現實際上也是不推薦的做法,它很容易導致死鎖!有關為什麼被棄用的原因,我們會在線程鎖繼續探討。
線程的優先級
實際上,Java程序中的每個線程並不是平均分配CPU時間的,為了使得線程資源分配更加合理,Java採用的是搶佔式調度方式,優先級越高的線程,優先使用CPU資源!我們希望CPU花費更多的時間去處理更重要的任務,而不太重要的任務,則可以先讓出一部分資源。線程的優先級一般分為以下三種:
- MIN_PRIORITY 最低優先級
- MAX_PRIORITY 最高優先級
- NOM_PRIORITY 常規優先級
public static void main(String[] args) {
Thread t = new Thread(() -> {
System.out.println("線程開始運行!");
});
t.start();
t.setPriority(Thread.MIN_PRIORITY); //通過使用setPriority方法來設定優先級
}
優先級越高的線程,獲得CPU資源的概率會越大,並不是說一定優先級越高的線程越先執行!
線程的禮讓和加入
我們還可以在當前線程的工作不重要時,將CPU資源讓位給其他線程,通過使用yield()方法來將當前資源讓位給其他同優先級線程:
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
System.out.println("線程1開始運行!");
for (int i = 0; i < 50; i++) {
if(i % 5 == 0) {
System.out.println("讓位!");
Thread.yield();
}
System.out.println("1打印:"+i);
}
System.out.println("線程1結束!");
});
Thread t2 = new Thread(() -> {
System.out.println("線程2開始運行!");
for (int i = 0; i < 50; i++) {
System.out.println("2打印:"+i);
}
});
t1.start();
t2.start();
}
觀察結果,我們發現,在讓位之後,儘可能多的在執行線程2的內容。
當我們希望一個線程等待另一個線程執行完成後再繼續進行,我們可以使用join()方法來實現線程的加入:
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
System.out.println("線程1開始運行!");
for (int i = 0; i < 50; i++) {
System.out.println("1打印:"+i);
}
System.out.println("線程1結束!");
});
Thread t2 = new Thread(() -> {
System.out.println("線程2開始運行!");
for (int i = 0; i < 50; i++) {
System.out.println("2打印:"+i);
if(i == 10){
try {
System.out.println("線程1加入到此線程!");
t1.join(); //在i==10時,讓線程1加入,先完成線程1的內容,在繼續當前內容
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
t1.start();
t2.start();
}
我們發現,線程1加入後,線程2等待線程1待執行的內容全部執行完成之後,再繼續執行的線程2內容。注意,線程的加入只是等待另一個線程的完成,並不是將另一個線程和當前線程合併!我們來看看:
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
System.out.println(Thread.currentThread().getName()+"開始運行!");
for (int i = 0; i < 50; i++) {
System.out.println(Thread.currentThread().getName()+"打印:"+i);
}
System.out.println("線程1結束!");
});
Thread t2 = new Thread(() -> {
System.out.println("線程2開始運行!");
for (int i = 0; i < 50; i++) {
System.out.println("2打印:"+i);
if(i == 10){
try {
System.out.println("線程1加入到此線程!");
t1.join(); //在i==10時,讓線程1加入,先完成線程1的內容,在繼續當前內容
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
});
t1.start();
t2.start();
}
實際上,t2線程只是暫時處於等待狀態,當t1執行結束時,t2才開始繼續執行,只是在效果上看起來好像是兩個線程合併為一個線程在執行而已。
線程鎖和線程同步
在開始講解線程同步之前,我們需要先了解一下多線程情況下Java的內存管理:
線程之間的共享變量(比如之前懸念中的value變量)存儲在主內存(main memory)中,每個線程都有一個私有的工作內存(本地內存),工作內存中存儲了該線程以讀/寫共享變量的副本。它類似於我們在計算機組成原理中學習的多處理器高速緩存機制:
高速緩存通過保存內存中數據的副本來提供更加快速的數據訪問,但是如果多個處理器的運算任務都涉及同一塊內存區域,就可能導致各自的高速緩存數據不一致,在寫回主內存時就會發生衝突,這就是引入高速緩存引發的新問題,稱之為:緩存一致性。
實際上,Java的內存模型也是這樣類似設計的,當我們同時去操作一個共享變量時,如果僅僅是讀取還好,但是如果同時寫入內容,就會出現問題!好比說一個銀行,如果我和我的朋友同時在銀行取我賬戶裏面的錢,難道取1000還可能吐2000出來嗎?我們需要一種更加安全的機制來維持秩序,保證數據的安全性!
懸念破案
我們再來回顧一下之前留給大家的懸念:
private static int value = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) value++;
System.out.println("線程1完成");
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) value++;
System.out.println("線程2完成");
});
t1.start();
t2.start();
Thread.sleep(1000); //主線程停止1秒,保證兩個線程執行完成
System.out.println(value);
}
實際上,當兩個線程同時讀取value的時候,可能會同時拿到同樣的值,而進行自增操作之後,也是同樣的值,再寫回主內存後,本來應該進行2次自增操作,實際上只執行了一次!

那麼要去解決這樣的問題,我們就必須採取某種同步機制,來限制不同線程對於共享變量的訪問!
我們希望的是保證共享變量value自增操作的原子性(原子性是指一個操作或多個操作要麼全部執行,且執行的過程不會被任何因素打斷,包括其他線程,要麼就都不執行)
線程鎖
通過synchronized關鍵字來創造一個線程鎖,首先我們來認識一下synchronized代碼塊,它需要在括號中填入一個內容,必須是一個對象或是一個類,我們在value自增操作外套上同步代碼塊:
private static int value = 0;
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
synchronized (Main.class){
value++;
}
}
System.out.println("線程1完成");
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
synchronized (Main.class){
value++;
}
}
System.out.println("線程2完成");
});
t1.start();
t2.start();
Thread.sleep(1000); //主線程停止1秒,保證兩個線程執行完成
System.out.println(value);
}
我們發現,現在得到的結果就是我們想要的內容了,因為在同步代碼塊執行過程中,拿到了我們傳入對象或類的鎖(傳入的如果是對象,就是對象鎖,不同的對象代表不同的對象鎖,如果是類,就是類鎖,類鎖只有一個,實際上類鎖也是對象鎖,是Class類實例,但是Class類實例同樣的類無論怎麼獲取都是同一個),但是注意兩個線程必須使用同一把鎖!
當一個線程進入到同步代碼塊時,會獲取到當前的鎖,而這時如果其他使用同樣的鎖的同步代碼塊也想執行內容,就必須等待當前同步代碼塊的內容執行完畢,在執行完畢後會自動釋放這把鎖,而其他的線程才能拿到這把鎖並開始執行同步代碼塊裏面的內容。(實際上synchronized是一種悲觀鎖,隨時都認為有其他線程在對數據進行修改,後面有機會我們還會講到樂觀鎖,如CAS算法)
那麼我們來看看,如果使用的是不同對象的鎖,那麼還能順利進行嗎?
private static int value = 0;
public static void main(String[] args) throws InterruptedException {
Main main1 = new Main();
Main main2 = new Main();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
synchronized (main1){
value++;
}
}
System.out.println("線程1完成");
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) {
synchronized (main2){
value++;
}
}
System.out.println("線程2完成");
});
t1.start();
t2.start();
Thread.sleep(1000); //主線程停止1秒,保證兩個線程執行完成
System.out.println(value);
}
當對象不同時,獲取到的是不同的鎖,因此並不能保證自增操作的原子性,最後也得不到我們想要的結果。
synchronized關鍵字也可以作用於方法上,調用此方法時也會獲取鎖:
private static int value = 0;
private static synchronized void add(){
value++;
}
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(() -> {
for (int i = 0; i < 10000; i++) add();
System.out.println("線程1完成");
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 10000; i++) add();
System.out.println("線程2完成");
});
t1.start();
t2.start();
Thread.sleep(1000); //主線程停止1秒,保證兩個線程執行完成
System.out.println(value);
}
我們發現實際上效果是相同的,只不過這個鎖不用你去給,如果是靜態方法,就是使用的類鎖,而如果是普通成員方法,就是使用的對象鎖。通過靈活的使用synchronized就能很好地解決我們之前提到的問題了!
死鎖
其實死鎖的概念在操作系統中也有提及,它是指兩個線程相互持有對方需要的鎖,但是又遲遲不釋放,導致程序卡住:

我們發現,線程A和線程B都需要對方的鎖,但是又被對方牢牢把握,由於線程被無限期地阻塞,因此程序不可能正常終止。我們來看看以下這段代碼會得到什麼結果:
public static void main(String[] args) throws InterruptedException {
Object o1 = new Object();
Object o2 = new Object();
Thread t1 = new Thread(() -> {
synchronized (o1){
try {
Thread.sleep(1000);
synchronized (o2){
System.out.println("線程1");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread t2 = new Thread(() -> {
synchronized (o2){
try {
Thread.sleep(1000);
synchronized (o1){
System.out.println("線程2");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
t2.start();
}
那麼我們如何去檢測死鎖呢?我們可以利用jstack命令來檢測死鎖,首先利用jps找到我們的java進程:
nagocoler@NagodeMacBook-Pro ~ % jps
51592 Launcher
51690 Jps
14955
51693 Main
nagocoler@NagodeMacBook-Pro ~ % jstack 51693
...
Java stack information for the threads listed above:
===================================================
"Thread-1":
at com.test.Main.lambda$main$1(Main.java:46)
- waiting to lock <0x000000076ad27fc0> (a java.lang.Object)
- locked <0x000000076ad27fd0> (a java.lang.Object)
at com.test.Main$$Lambda$2/1867750575.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
"Thread-0":
at com.test.Main.lambda$main$0(Main.java:34)
- waiting to lock <0x000000076ad27fd0> (a java.lang.Object)
- locked <0x000000076ad27fc0> (a java.lang.Object)
at com.test.Main$$Lambda$1/396873410.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
Found 1 deadlock.
jstack自動幫助我們找到了一個死鎖,並打印出了相關線程的棧追蹤信息。
不推薦使用 suspend() 去掛起線程的原因,是因為suspend()在使線程暫停的同時,並不會去釋放任何鎖資源。
其他線程都無法訪問被它佔用的鎖。直到對應的線程執行resume()方法後,被掛起的線程才能繼續,從而其它被阻塞在這個鎖的線程才可以繼續執行。
但是,如果resume()操作出現在suspend()之前執行,那麼線程將一直處於掛起狀態,同時一直佔用鎖,這就產生了死鎖。
wait和notify方法
其實我們之前可能就發現了,Object類還有三個方法我們從來沒有使用過,分別是wait()、notify()以及notifyAll(),他們其實是需要配合synchronized來使用的,只有在同步代碼塊中才能使用這些方法,我們來看看他們的作用是什麼:
public static void main(String[] args) throws InterruptedException {
Object o1 = new Object();
Thread t1 = new Thread(() -> {
synchronized (o1){
try {
System.out.println("開始等待");
o1.wait(); //進入等待狀態並釋放鎖
System.out.println("等待結束!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread t2 = new Thread(() -> {
synchronized (o1){
System.out.println("開始喚醒!");
o1.notify(); //喚醒處於等待狀態的線程
for (int i = 0; i < 50; i++) {
System.out.println(i);
}
//喚醒後依然需要等待這裡的鎖釋放之前等待的線程才能繼續
}
});
t1.start();
Thread.sleep(1000);
t2.start();
}
我們可以發現,對象的wait()方法會暫時使得此線程進入等待狀態,同時會釋放當前代碼塊持有的鎖,這時其他線程可以獲取到此對象的鎖,當其他線程調用對象的notify()方法後,會喚醒剛才變成等待狀態的線程(這時並沒有立即釋放鎖)。注意,必須是在持有鎖(同步代碼塊內部)的情況下使用,否則會拋出異常!
notifyAll其實和notify一樣,也是用於喚醒,但是前者是喚醒所有調用wait()後處於等待的線程,而後者是看運氣隨機選擇一個。
ThreadLocal的使用
既然每個線程都有一個自己的工作內存,那麼能否只在自己的工作內存中創建變量僅供線程自己使用呢?
我們可以是ThreadLocal類,來創建工作內存中的變量,它將我們的變量值存儲在內部(只能存儲一個變量),不同的變量訪問到ThreadLocal對象時,都只能獲取到自己線程所屬的變量。
public static void main(String[] args) throws InterruptedException {
ThreadLocal<String> local = new ThreadLocal<>(); //注意這是一個泛型類,存儲類型為我們要存放的變量類型
Thread t1 = new Thread(() -> {
local.set("lbwnb"); //將變量的值給予ThreadLocal
System.out.println("變量值已設定!");
System.out.println(local.get()); //嘗試獲取ThreadLocal中存放的變量
});
Thread t2 = new Thread(() -> {
System.out.println(local.get()); //嘗試獲取ThreadLocal中存放的變量
});
t1.start();
Thread.sleep(3000); //間隔三秒
t2.start();
}
上面的例子中,我們開啟兩個線程分別去訪問ThreadLocal對象,我們發現,第一個線程存放的內容,第一個線程可以獲取,但是第二個線程無法獲取,我們再來看看第一個線程存入後,第二個線程也存放,是否會覆蓋第一個線程存放的內容:
public static void main(String[] args) throws InterruptedException {
ThreadLocal<String> local = new ThreadLocal<>(); //注意這是一個泛型類,存儲類型為我們要存放的變量類型
Thread t1 = new Thread(() -> {
local.set("lbwnb"); //將變量的值給予ThreadLocal
System.out.println("線程1變量值已設定!");
try {
Thread.sleep(2000); //間隔2秒
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("線程1讀取變量值:");
System.out.println(local.get()); //嘗試獲取ThreadLocal中存放的變量
});
Thread t2 = new Thread(() -> {
local.set("yyds"); //將變量的值給予ThreadLocal
System.out.println("線程2變量值已設定!");
});
t1.start();
Thread.sleep(1000); //間隔1秒
t2.start();
}
我們發現,即使線程2重新設定了值,也沒有影響到線程1存放的值,所以說,不同線程向ThreadLocal存放數據,只會存放在線程自己的工作空間中,而不會直接存放到主內存中,因此各個線程直接存放的內容互不干擾。
我們發現在線程中創建的子線程,無法獲得父線程工作內存中的變量:
public static void main(String[] args) {
ThreadLocal<String> local = new ThreadLocal<>();
Thread t = new Thread(() -> {
local.set("lbwnb");
new Thread(() -> {
System.out.println(local.get());
}).start();
});
t.start();
}
我們可以使用InheritableThreadLocal來解決:
public static void main(String[] args) {
ThreadLocal<String> local = new InheritableThreadLocal<>();
Thread t = new Thread(() -> {
local.set("lbwnb");
new Thread(() -> {
System.out.println(local.get());
}).start();
});
t.start();
}
在InheritableThreadLocal存放的內容,會自動向子線程傳遞。
定時器
我們有時候會有這樣的需求,我希望定時執行任務,比如3秒後執行,其實我們可以通過使用Thread.sleep()來實現:
public static void main(String[] args) {
new TimerTask(() -> System.out.println("我是定時任務!"), 3000).start(); //創建並啟動此定時任務
}
static class TimerTask{
Runnable task;
long time;
public TimerTask(Runnable runnable, long time){
this.task = runnable;
this.time = time;
}
public void start(){
new Thread(() -> {
try {
Thread.sleep(time);
task.run(); //休眠後再運行
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
我們通過自行封裝一個TimerTask類,並在啟動時,先休眠3秒鐘,再執行我們傳入的內容。那麼現在我們希望,能否循環執行一個任務呢?比如我希望每隔1秒鐘執行一次代碼,這樣該怎麼做呢?
public static void main(String[] args) {
new TimerLoopTask(() -> System.out.println("我是定時任務!"), 3000).start(); //創建並啟動此定時任務
}
static class TimerLoopTask{
Runnable task;
long loopTime;
public TimerLoopTask(Runnable runnable, long loopTime){
this.task = runnable;
this.loopTime = loopTime;
}
public void start(){
new Thread(() -> {
try {
while (true){ //無限循環執行
Thread.sleep(loopTime);
task.run(); //休眠後再運行
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
現在我們將單次執行放入到一個無限循環中,這樣就能一直執行了,並且按照我們的間隔時間進行。
但是終究是我們自己實現,可能很多方面還沒考慮到,Java也為我們提供了一套自己的框架用於處理定時任務:
public static void main(String[] args) {
Timer timer = new Timer(); //創建定時器對象
timer.schedule(new TimerTask() { //注意這個是一個抽象類,不是接口,無法使用lambda表達式簡化,只能使用匿名內部類
@Override
public void run() {
System.out.println(Thread.currentThread().getName()); //打印當前線程名稱
}
}, 1000); //執行一個延時任務
}
我們可以通過創建一個Timer類來讓它進行定時任務調度,我們可以通過此對象來創建任意類型的定時任務,包延時任務、循環定時任務等。我們發現,雖然任務執行完成了,但是我們的程序並沒有停止,這是因為Timer內存維護了一個任務隊列和一個工作線程:
public class Timer {
/**
* The timer task queue. This data structure is shared with the timer
* thread. The timer produces tasks, via its various schedule calls,
* and the timer thread consumes, executing timer tasks as appropriate,
* and removing them from the queue when they're obsolete.
*/
private final TaskQueue queue = new TaskQueue();
/**
* The timer thread.
*/
private final TimerThread thread = new TimerThread(queue);
...
}
TimerThread繼承自Thread,是一個新創建的線程,在構造時自動啟動:
public Timer(String name) {
thread.setName(name);
thread.start();
}
而它的run方法會循環地讀取隊列中是否還有任務,如果有任務依次執行,沒有的話就暫時處於休眠狀態:
public void run() {
try {
mainLoop();
} finally {
// Someone killed this Thread, behave as if Timer cancelled
synchronized(queue) {
newTasksMayBeScheduled = false;
queue.clear(); // Eliminate obsolete references
}
}
}
/**
* The main timer loop. (See class comment.)
*/
private void mainLoop() {
try {
TimerTask task;
boolean taskFired;
synchronized(queue) {
// Wait for queue to become non-empty
while (queue.isEmpty() && newTasksMayBeScheduled) //當隊列為空同時沒有被關閉時,會調用wait()方法暫時處於等待狀態,當有新的任務時,會被喚醒。
queue.wait();
if (queue.isEmpty())
break; //當被喚醒後都沒有任務時,就會結束循環,也就是結束工作線程
...
}
newTasksMayBeScheduled實際上就是標記當前定時器是否關閉,當它為false時,表示已經不會再有新的任務到來,也就是關閉,我們可以通過調用cancel()方法來關閉它的工作線程:
public void cancel() {
synchronized(queue) {
thread.newTasksMayBeScheduled = false;
queue.clear();
queue.notify(); //喚醒wait使得工作線程結束
}
}
因此,我們可以在使用完成後,調用Timer的cancel()方法以正常退出我們的程序:
public static void main(String[] args) {
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName());
timer.cancel(); //結束
}
}, 1000);
}
守護線程
不要把守護進程和守護線程相提並論!
守護進程在後台運行運行,不需要和用戶交互,本質和普通進程類似。
而守護線程就不一樣了,當其他所有的非守護線程結束之後,守護線程是自動結束,也就是說,Java中所有的線程都執行完畢後,守護線程自動結束,因此守護線程不適合進行IO操作,只適合打打雜:
public static void main(String[] args) throws InterruptedException{
Thread t = new Thread(() -> {
while (true){
try {
System.out.println("程序正常運行中...");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t.setDaemon(true); //設置為守護線程(必須在開始之前,中途是不允許轉換的)
t.start();
for (int i = 0; i < 5; i++) {
Thread.sleep(1000);
}
}
在守護線程中產生的新線程也是守護的:
public static void main(String[] args) throws InterruptedException{
Thread t = new Thread(() -> {
Thread it = new Thread(() -> {
while (true){
try {
System.out.println("程序正常運行中...");
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
it.start();
});
t.setDaemon(true); //設置為守護線程(必須在開始之前,中途是不允許轉換的)
t.start();
for (int i = 0; i < 5; i++) {
Thread.sleep(1000);
}
}
再談集合類並行方法
其實我們之前在講解集合類的根接口時,就發現有這樣一個方法:
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}
並行流,其實就是一個多線程執行的流,它通過默認的ForkJoinPool實現(這裡不講解原理),它可以提高你的多線程任務的速度。
public static void main(String[] args) {
List<Integer> list = new ArrayList<>(Arrays.asList(1, 4, 5, 2, 9, 3, 6, 0));
list
.parallelStream() //獲得並行流
.forEach(i -> System.out.println(Thread.currentThread().getName()+" -> "+i));
}
我們發現,forEach操作的順序,並不是我們實際List中的順序,同時每次打印也是不同的線程在執行!我們可以通過調用forEachOrdered()方法來使用單線程維持原本的順序:
public static void main(String[] args) {
List<Integer> list = new ArrayList<>(Arrays.asList(1, 4, 5, 2, 9, 3, 6, 0));
list
.parallelStream() //獲得並行流
.forEachOrdered(System.out::println);
}
我們之前還發現,在Arrays數組工具類中,也包含大量的並行方法:
public static void main(String[] args) {
int[] arr = new int[]{1, 4, 5, 2, 9, 3, 6, 0};
Arrays.parallelSort(arr); //使用多線程進行並行排序,效率更高
System.out.println(Arrays.toString(arr));
}
更多地使用並行方法,可以更加充分地發揮現代計算機多核心的優勢,但是同時需要注意多線程產生的異步問題!
public static void main(String[] args) {
int[] arr = new int[]{1, 4, 5, 2, 9, 3, 6, 0};
Arrays.parallelSetAll(arr, i -> {
System.out.println(Thread.currentThread().getName());
return arr[i];
});
System.out.println(Arrays.toString(arr));
}
通過對Java多線程的了解,我們就具備了利用多線程解決問題的思維!
Java反射和註解
注意:本章節涉及到JVM相關底層原理,難度會有一些大。
反射就是把Java類中的各個成分映射成一個個的Java對象。即在運行狀態中,對於任意一個類,都能夠知道這個類所有的屬性和方法,對於任意一個對象,都能調用它的任意一個方法和屬性。這種動態獲取信息及動態調用對象方法的功能叫Java的反射機制。
簡而言之,我們可以通過反射機制,獲取到類的一些屬性,包括類裏面有哪些字段,有哪些方法,繼承自哪個類,甚至還能獲取到泛型!它的權限非常高,慎重使用!
Java類加載機制
在學習Java的反射機制之前,我們需要先了解一下類的加載機制,一個類是如何被加載和使用的:

在Java程序啟動時,JVM會將一部分類(class文件)先加載(並不是所有的類都會在一開始加載),通過ClassLoader將類加載,在加載過程中,會將類的信息提取出來(存放在元空間中,JDK1.8之前存放在永久代),同時也會生成一個Class對象存放在內存(堆內存),注意此Class對象只會存在一個,與加載的類唯一對應!
思考:既然說和與加載的類唯一對應,那如果我們手動創建一個與JDK包名一樣,同時類名也保持一致,那麼JVM會加載這個類嗎?
package java.lang;
public class String { //JDK提供的String類也是
public static void main(String[] args) {
System.out.println("我姓🐴,我叫🐴nb");
}
}
我們發現,會出現以下報錯:
錯誤: 在類 java.lang.String 中找不到 main 方法, 請將 main 方法定義為:
public static void main(String[] args)
但是我們明明在自己寫的String類中定義了main方法啊,為什麼會找不到此方法呢?實際上這是ClassLoader的雙親委派機制在保護Java程序的正常運行:
實際上我們的類最開始是由BootstarpClassLoader進行加載,BootstarpClassLoader用於加載JDK提供的類,而我們自己編寫的類實際上是AppClassLoader,只有BootstarpClassLoader都沒有加載的類,才會讓AppClassLoader來加載,因此我們自己編寫的同名包同名類不會被加載,而實際要去啟動的是真正的String類,也就自然找不到main方法了!
public class Main {
public static void main(String[] args) {
System.out.println(Main.class.getClassLoader()); //查看當前類的類加載器
System.out.println(Main.class.getClassLoader().getParent()); //父加載器
System.out.println(Main.class.getClassLoader().getParent().getParent()); //爺爺加載器
System.out.println(String.class.getClassLoader()); //String類的加載器
}
}
由於BootstarpClassLoader是C++編寫的,我們在Java中是獲取不到的。
Class對象
通過前面,我們了解了類的加載,同時會提取一個類的信息生成Class對象存放在內存中,而反射機制其實就是利用這些存放的類信息,來獲取類的信息和操作類。那麼如何獲取到每個類對應的Class對象呢,我們可以通過以下方式:
public static void main(String[] args) throws ClassNotFoundException {
Class<String> clazz = String.class; //使用class關鍵字,通過類名獲取
Class<?> clazz2 = Class.forName("java.lang.String"); //使用Class類靜態方法forName(),通過包名.類名獲取,注意返回值是Class<?>
Class<?> clazz3 = new String("cpdd").getClass(); //通過實例對象獲取
}
注意Class類也是一個泛型類,只有第一種方法,能夠直接獲取到對應類型的Class對象,而以下兩種方法使用了?通配符作為返回值,但是實際上都和第一個返回的是同一個對象:
Class<String> clazz = String.class; //使用class關鍵字,通過類名獲取
Class<?> clazz2 = Class.forName("java.lang.String"); //使用Class類靜態方法forName(),通過包名.類名獲取,注意返回值是Class<?>
Class<?> clazz3 = new String("cpdd").getClass();
System.out.println(clazz == clazz2);
System.out.println(clazz == clazz3);
通過比較,驗證了我們一開始的結論,在JVM中每個類始終只存在一個Class對象,無論通過什麼方法獲取,都是一樣的。現在我們再來看看這個問題:
public static void main(String[] args) {
Class<?> clazz = int.class; //基本數據類型有Class對象嗎?
System.out.println(clazz);
}
迷了,不是每個類才有Class對象嗎,基本數據類型又不是類,這也行嗎?實際上,基本數據類型也有對應的Class對象(反射操作可能需要用到),而且我們不僅可以通過class關鍵字獲取,其實本質上是定義在對應的包裝類中的:
/**
* The {@code Class} instance representing the primitive type
* {@code int}.
*
* @since JDK1.1
*/
@SuppressWarnings("unchecked")
public static final Class<Integer> TYPE = (Class<Integer>) Class.getPrimitiveClass("int");
/*
* Return the Virtual Machine's Class object for the named
* primitive type
*/
static native Class<?> getPrimitiveClass(String name); //C++實現,並非Java定義
每個包裝類中(包括Void),都有一個獲取原始類型Class方法,注意,getPrimitiveClass獲取的是原始類型,並不是包裝類型,只是可以使用包裝類來表示。
public static void main(String[] args) {
Class<?> clazz = int.class;
System.out.println(Integer.TYPE == int.class);
}
通過對比,我們發現實際上包裝類型都有一個TYPE,其實也就是基本類型的Class,那麼包裝類的Class和基本類的Class一樣嗎?
public static void main(String[] args) {
System.out.println(Integer.TYPE == Integer.class);
}
我們發現,包裝類型的Class對象並不是基本類型Class對象。數組類型也是一種類型,只是編程不可見,因此我們可以直接獲取數組的Class對象:
public static void main(String[] args) {
Class<String[]> clazz = String[].class;
System.out.println(clazz.getName()); //獲取類名稱(得到的是包名+類名的完整名稱)
System.out.println(clazz.getSimpleName());
System.out.println(clazz.getTypeName());
System.out.println(clazz.getClassLoader()); //獲取它的類加載器
System.out.println(clazz.cast(new Integer("10"))); //強制類型轉換
}
再談instanceof
正常情況下,我們使用instanceof進行類型比較:
public static void main(String[] args) {
String str = "";
System.out.println(str instanceof String);
}
它可以判斷一個對象是否為此接口或是類的實現或是子類,而現在我們有了更多的方式去判斷類型:
public static void main(String[] args) {
String str = "";
System.out.println(str.getClass() == String.class); //直接判斷是否為這個類型
}
如果需要判斷是否為子類或是接口/抽象類的實現,我們可以使用asSubClass()方法:
public static void main(String[] args) {
Integer i = 10;
i.getClass().asSubclass(Number.class); //當Integer不是Number的子類時,會產生異常
}
獲取父類信息
通過getSuperclass()方法,我們可以獲取到父類的Class對象:
public static void main(String[] args) {
Integer i = 10;
System.out.println(i.getClass().getSuperclass());
}
也可以通過getGenericSuperclass()獲取父類的原始類型的Type:
public static void main(String[] args) {
Integer i = 10;
Type type = i.getClass().getGenericSuperclass();
System.out.println(type);
System.out.println(type instanceof Class);
}
我們發現Type實際上是Class類的父接口,但是獲取到的Type的實現並不一定是Class。
同理,我們也可以像上面這樣獲取父接口:
public static void main(String[] args) {
Integer i = 10;
for (Class<?> anInterface : i.getClass().getInterfaces()) {
System.out.println(anInterface.getName());
}
for (Type genericInterface : i.getClass().getGenericInterfaces()) {
System.out.println(genericInterface.getTypeName());
}
}
創建類對象
既然我們拿到了類的定義,那麼是否可以通過Class對象來創建對象、調用方法、修改變量呢?當然是可以的,那我們首先來探討一下如何創建一個類的對象:
public static void main(String[] args) throws InstantiationException, IllegalAccessException {
Class<Student> clazz = Student.class;
Student student = clazz.newInstance();
student.test();
}
static class Student{
public void test(){
System.out.println("薩日朗");
}
}
通過使用newInstance()方法來創建對應類型的實例,返回泛型T,注意它會拋出InstantiationException和IllegalAccessException異常,那麼什麼情況下會出現異常呢?
public static void main(String[] args) throws InstantiationException, IllegalAccessException {
Class<Student> clazz = Student.class;
Student student = clazz.newInstance();
student.test();
}
static class Student{
public Student(String text){
}
public void test(){
System.out.println("薩日朗");
}
}
當類默認的構造方法被帶參構造覆蓋時,會出現InstantiationException異常,因為newInstance()只適用於默認無參構造。
public static void main(String[] args) throws InstantiationException, IllegalAccessException {
Class<Student> clazz = Student.class;
Student student = clazz.newInstance();
student.test();
}
static class Student{
private Student(){}
public void test(){
System.out.println("薩日朗");
}
}
當默認無參構造的權限不是public時,會出現IllegalAccessException異常,表示我們無權去調用默認構造方法。在JDK9之後,不再推薦使用newInstance()方法了,而是使用我們接下來要介紹到的,通過獲取構造器,來實例化對象:
public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, InstantiationException, IllegalAccessException {
Class<Student> clazz = Student.class;
Student student = clazz.getConstructor(String.class).newInstance("what's up");
student.test();
}
static class Student{
public Student(String str){}
public void test(){
System.out.println("薩日朗");
}
}
通過獲取類的構造方法(構造器)來創建對象實例,會更加合理,我們可以使用getConstructor()方法來獲取類的構造方法,同時我們需要向其中填入參數,也就是構造方法需要的類型,當然我們這裡只演示了。那麼,當訪問權限不是public的時候呢?
public static void main(String[] args) throws NoSuchMethodException, InvocationTargetException, InstantiationException, IllegalAccessException {
Class<Student> clazz = Student.class;
Student student = clazz.getConstructor(String.class).newInstance("what's up");
student.test();
}
static class Student{
private Student(String str){}
public void test(){
System.out.println("薩日朗");
}
}
我們發現,當訪問權限不足時,會無法找到此構造方法,那麼如何找到非public的構造方法呢?
Class<Student> clazz = Student.class;
Constructor<Student> constructor = clazz.getDeclaredConstructor(String.class);
constructor.setAccessible(true); //修改訪問權限
Student student = constructor.newInstance("what's up");
student.test();
使用getDeclaredConstructor()方法可以找到類中的非public構造方法,但是在使用之前,我們需要先修改訪問權限,在修改訪問權限之後,就可以使用非public方法了(這意味着,反射可以無視權限修飾符訪問類的內容)
調用類的方法
我們可以通過反射來調用類的方法(本質上還是類的實例進行調用)只是利用反射機制實現了方法的調用,我們在包下創建一個新的類:
package com.test;
public class Student {
public void test(String str){
System.out.println("薩日朗"+str);
}
}
這次我們通過forName(String)來找到這個類並創建一個新的對象:
public static void main(String[] args) throws ReflectiveOperationException {
Class<?> clazz = Class.forName("com.test.Student");
Object instance = clazz.newInstance(); //創建出學生對象
Method method = clazz.getMethod("test", String.class); //通過方法名和形參類型獲取類中的方法
method.invoke(instance, "what's up"); //通過Method對象的invoke方法來調用方法
}
通過調用getMethod()方法,我們可以獲取到類中所有聲明為public的方法,得到一個Method對象,我們可以通過Method對象的invoke()方法(返回值就是方法的返回值,因為這裡是void,返回值為null)來調用已經獲取到的方法,注意傳參。
我們發現,利用反射之後,在一個對象從構造到方法調用,沒有任何一處需要引用到對象的實際類型,我們也沒有導入Student類,整個過程都是反射在代替進行操作,使得整個過程被模糊了,過多的使用反射,會極大地降低後期維護性。
同構造方法一樣,當出現非public方法時,我們可以通過反射來無視權限修飾符,獲取非public方法並調用,現在我們將test()方法的權限修飾符改為private:
public static void main(String[] args) throws ReflectiveOperationException {
Class<?> clazz = Class.forName("com.test.Student");
Object instance = clazz.newInstance(); //創建出學生對象
Method method = clazz.getDeclaredMethod("test", String.class); //通過方法名和形參類型獲取類中的方法
method.setAccessible(true);
method.invoke(instance, "what's up"); //通過Method對象的invoke方法來調用方法
}
Method和Constructor都和Class一樣,他們存儲了方法的信息,包括方法的形式參數列表,返回值,方法的名稱等內容,我們可以直接通過Method對象來獲取這些信息:
public static void main(String[] args) throws ReflectiveOperationException {
Class<?> clazz = Class.forName("com.test.Student");
Method method = clazz.getDeclaredMethod("test", String.class); //通過方法名和形參類型獲取類中的方法
System.out.println(method.getName()); //獲取方法名稱
System.out.println(method.getReturnType()); //獲取返回值類型
}
當方法的參數為可變參數時,我們該如何獲取方法呢?實際上,我們在之前就已經提到過,可變參數實際上就是一個數組,因此我們可以直接使用數組的class對象表示:
Method method = clazz.getDeclaredMethod("test", String[].class);
反射非常強大,尤其是我們提到的越權訪問,但是請一定謹慎使用,別人將某個方法設置為private一定有他的理由,如果實在是需要使用別人定義為private的方法,就必須確保這樣做是安全的,在沒有了解別人代碼的整個過程就強行越權訪問,可能會出現無法預知的錯誤。
修改類的屬性
我們還可以通過反射訪問一個類中定義的成員字段也可以修改一個類的對象中的成員字段值,通過getField()方法來獲取一個類定義的指定字段:
public static void main(String[] args) throws ReflectiveOperationException {
Class<?> clazz = Class.forName("com.test.Student");
Object instance = clazz.newInstance();
Field field = clazz.getField("i"); //獲取類的成員字段i
field.set(instance, 100); //將類實例instance的成員字段i設置為100
Method method = clazz.getMethod("test");
method.invoke(instance);
}
在得到Field之後,我們就可以直接通過set()方法為某個對象,設定此屬性的值,比如上面,我們就為instance對象設定值為100,當訪問private字段時,同樣可以按照上面的操作進行越權訪問:
public static void main(String[] args) throws ReflectiveOperationException {
Class<?> clazz = Class.forName("com.test.Student");
Object instance = clazz.newInstance();
Field field = clazz.getDeclaredField("i"); //獲取類的成員字段i
field.setAccessible(true);
field.set(instance, 100); //將類實例instance的成員字段i設置為100
Method method = clazz.getMethod("test");
method.invoke(instance);
}
現在我們已經知道,反射幾乎可以把一個類的老底都給扒出來,任何屬性,任何內容,都可以被反射修改,無論權限修飾符是什麼,那麼,如果我的字段被標記為final呢?現在在字段i前面添加final關鍵字,我們再來看看效果:
private final int i = 10;
這時,當字段為final時,就修改失敗了!當然,通過反射可以直接將final修飾符直接去除,去除後,就可以隨意修改內容了,我們來嘗試修改Integer的value值:
public static void main(String[] args) throws ReflectiveOperationException {
Integer i = 10;
Field field = Integer.class.getDeclaredField("value");
Field modifiersField = Field.class.getDeclaredField("modifiers"); //這裡要獲取Field類的modifiers字段進行修改
modifiersField.setAccessible(true);
modifiersField.setInt(field,field.getModifiers()&~Modifier.FINAL); //去除final標記
field.setAccessible(true);
field.set(i, 100); //強行設置值
System.out.println(i);
}
我們可以發現,反射非常暴力,就連被定義為final字段的值都能強行修改,幾乎能夠無視一切阻攔。我們來試試看修改一些其他的類型:
public static void main(String[] args) throws ReflectiveOperationException {
List<String> i = new ArrayList<>();
Field field = ArrayList.class.getDeclaredField("size");
field.setAccessible(true);
field.set(i, 10);
i.add("測試"); //只添加一個元素
System.out.println(i.size()); //大小直接變成11
i.remove(10); //瞎移除都不帶報錯的,淦
}
實際上,整個ArrayList體系由於我們的反射操作,導致被破壞,因此它已經無法正常工作了!
再次強調,在進行反射操作時,必須注意是否安全,雖然擁有了創世主的能力,但是我們不能濫用,我們只能把它當做一個不得已才去使用的工具!
自定義ClassLoader加載類
我們可以自己手動將class文件加載到JVM中嗎?先寫好我們定義的類:
package com.test;
public class Test {
public String text;
public void test(String str){
System.out.println(text+" > 我是測試方法!"+str);
}
}
通過javac命令,手動編譯一個.class文件:
nagocoler@NagodeMacBook-Pro HelloWorld % javac src/main/java/com/test/Test.java
編譯後,得到一個class文件,我們把它放到根目錄下,然後編寫一個我們自己的ClassLoader,因為普通的ClassLoader無法加載二進制文件,因此我們編寫一個自己的來讓它支持:
//定義一個自己的ClassLoader
static class MyClassLoader extends ClassLoader{
public Class<?> defineClass(String name, byte[] b){
return defineClass(name, b, 0, b.length); //調用protected方法,支持載入外部class文件
}
}
public static void main(String[] args) throws IOException {
MyClassLoader classLoader = new MyClassLoader();
FileInputStream stream = new FileInputStream("Test.class");
byte[] bytes = new byte[stream.available()];
stream.read(bytes);
Class<?> clazz = classLoader.defineClass("com.test.Test", bytes); //類名必須和我們定義的保持一致
System.out.println(clazz.getName()); //成功加載外部class文件
}
現在,我們就將此class文件讀取並解析為Class了,現在我們就可以對此類進行操作了(注意,我們無法在代碼中直接使用此類型,因為它是我們直接加載的),我們來試試看創建一個此類的對象並調用其方法:
try {
Object obj = clazz.newInstance();
Method method = clazz.getMethod("test", String.class); //獲取我們定義的test(String str)方法
method.invoke(obj, "哥們這瓜多少錢一斤?");
}catch (Exception e){
e.printStackTrace();
}
我們來試試看修改成員字段之後,再來調用此方法:
try {
Object obj = clazz.newInstance();
Field field = clazz.getField("text"); //獲取成員變量 String text;
field.set(obj, "華強");
Method method = clazz.getMethod("test", String.class); //獲取我們定義的test(String str)方法
method.invoke(obj, "哥們這瓜多少錢一斤?");
}catch (Exception e){
e.printStackTrace();
}
通過這種方式,我們就可以實現外部加載甚至是網絡加載一個類,只需要把類文件傳遞即可,這樣就無需再將代碼寫在本地,而是動態進行傳遞,不僅可以一定程度上防止源代碼被反編譯(只是一定程度上,想破解你代碼有的是方法),而且在更多情況下,我們還可以對byte[]進行加密,保證在傳輸過程中的安全性。
註解
其實我們在之前就接觸到註解了,比如@Override表示重寫父類方法(當然不加效果也是一樣的,此註解在編譯時會被自動丟棄)註解本質上也是一個類,只不過它的用法比較特殊。
註解可以被標註在任意地方,包括方法上、類名上、參數上、成員屬性上、註解定義上等,就像注釋一樣,它相當於我們對某樣東西的一個標記。而與注釋不同的是,註解可以通過反射在運行時獲取,註解也可以選擇是否保留到運行時。
預設註解
JDK預設了以下注解,作用於代碼:
- @Override – 檢查(僅僅是檢查,不保留到運行時)該方法是否是重寫方法。如果發現其父類,或者是引用的接口中並沒有該方法時,會報編譯錯誤。
- @Deprecated – 標記過時方法。如果使用該方法,會報編譯警告。
- @SuppressWarnings – 指示編譯器去忽略註解中聲明的警告(僅僅編譯器階段,不保留到運行時)
- @FunctionalInterface – Java 8 開始支持,標識一個匿名函數或函數式接口。
- @SafeVarargs – Java 7 開始支持,忽略任何使用參數為泛型變量的方法或構造函數調用產生的警告。
元註解
元註解是作用於註解上的註解,用於我們編寫自定義的註解:
- @Retention – 標識這個註解怎麼保存,是只在代碼中,還是編入class文件中,或者是在運行時可以通過反射訪問。
- @Documented – 標記這些註解是否包含在用戶文檔中。
- @Target – 標記這個註解應該是哪種 Java 成員。
- @Inherited – 標記這個註解是繼承於哪個註解類(默認 註解並沒有繼承於任何子類)
- @Repeatable – Java 8 開始支持,標識某註解可以在同一個聲明上使用多次。
看了這麼多預設的註解,你們肯定眼花繚亂了,那我們來看看@Override是如何定義的:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.SOURCE)
public @interface Override {
}
該註解由@Target限定為只能作用於方法上,ElementType是一個枚舉類型,用於表示此枚舉的作用域,一個註解可以有很多個作用域。@Retention表示此註解的保留策略,包括三種策略,在上述中有寫到,而這裡定義為只在代碼中。一般情況下,自定義的註解需要定義1個@Retention和1-n個@Target。
既然了解了元註解的使用和註解的定義方式,我們就來嘗試定義一個自己的註解:
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
}
這裡我們定義一個Test註解,並將其保留到運行時,同時此註解可以作用於方法或是類上:
@Test
public class Main {
@Test
public static void main(String[] args) {
}
}
這樣,一個最簡單的註解就被我們創建了。
註解的使用
我們還可以在註解中定義一些屬性,註解的屬性也叫做成員變量,註解只有成員變量,沒有方法。註解的成員變量在註解的定義中以「無形參的方法」形式來聲明,其方法名定義了該成員變量的名字,其返回值定義了該成員變量的類型:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
String value();
}
默認只有一個屬性時,我們可以將其名字設定為value,否則,我們需要在使用時手動指定註解的屬性名稱,使用value則無需填入:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
String test();
}
public class Main {
@Test(test = "")
public static void main(String[] args) {
}
}
我們也可以使用default關鍵字來為這些屬性指定默認值:
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
String value() default "都看到這裡了,給個三連吧!";
}
當屬性存在默認值時,使用註解的時候可以不用傳入屬性值。當屬性為數組時呢?
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface Test {
String[] value();
}
當屬性為數組,我們在使用註解傳參時,如果數組裏面只有一個內容,我們可以直接傳入一個值,而不是創建一個數組:
@Test("關注點了嗎")
public static void main(String[] args) {
}
public class Main {
@Test({"value1", "value2"}) //多個值時就使用花括號括起來
public static void main(String[] args) {
}
}
反射獲取註解
既然我們的註解可以保留到運行時,那麼我們來看看,如何獲取我們編寫的註解,我們需要用到反射機制:
public static void main(String[] args) {
Class<Student> clazz = Student.class;
for (Annotation annotation : clazz.getAnnotations()) {
System.out.println(annotation.annotationType()); //獲取類型
System.out.println(annotation instanceof Test); //直接判斷是否為Test
Test test = (Test) annotation;
System.out.println(test.value()); //獲取我們在註解中寫入的內容
}
}
通過反射機制,我們可以快速獲取到我們標記的註解,同時還能獲取到註解中填入的值,那麼我們來看看,方法上的標記是不是也可以通過這種方式獲取註解:
public static void main(String[] args) throws NoSuchMethodException {
Class<Student> clazz = Student.class;
for (Annotation annotation : clazz.getMethod("test").getAnnotations()) {
System.out.println(annotation.annotationType()); //獲取類型
System.out.println(annotation instanceof Test); //直接判斷是否為Test
Test test = (Test) annotation;
System.out.println(test.value()); //獲取我們在註解中寫入的內容
}
}
無論是方法、類、還是字段,都可以使用getAnnotations()方法(還有幾個同名的)來快速獲取我們標記的註解。
所以說呢,這玩意學來有啥用?絲毫get不到這玩意的用處。其實不是,現階段你們還體會不到註解帶來的快樂,在接觸到Spring和SpringBoot等大型框架後,就能感受到註解帶來的魅力了。


