FPT:又是借鑒Transformer,這次多方向融合特徵金字塔 | ECCV 2020
論文提出用於特徵金字塔的高效特徵交互方法FPT,包含3種精心設計的特徵增強操作,分別用於借鑒層內特徵進行增強、借鑒高層特徵進行增強以及借鑒低層特徵進行增強,FPT的輸出維度與輸入一致,能夠自由嵌入到各種包含特徵金字塔的檢測算法中,從實驗結果來看,效果不錯
來源:曉飛的算法工程筆記 公眾號
論文: Feature Pyramid Transformer

Introduction
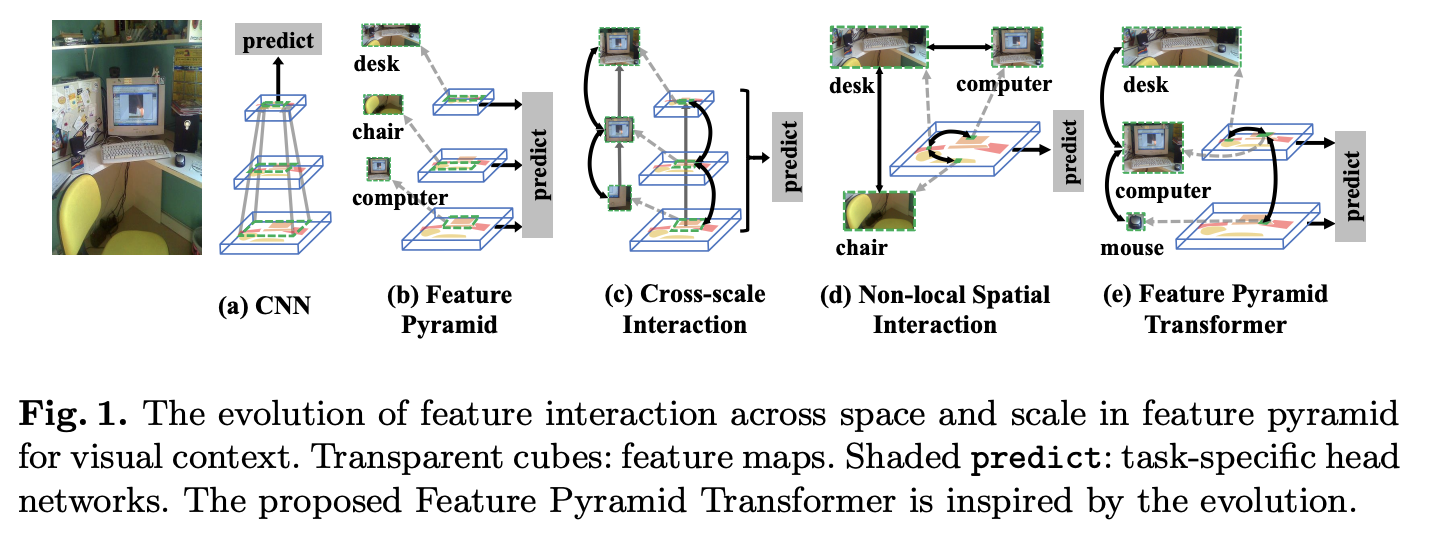
講論文前先捋一下CNN網絡結構相關的知識,論文的思想主要來自兩個,一個是特徵金字塔結構,一個是Non-local網絡:
- 首先是特徵金字塔,如圖1a,CNN網絡以層級結構的形式逐層提取更豐富的特徵,然後使用最後的特徵層進行預測。但對於一些小物體而言,最後一層的特徵圖往往沒有足夠的像素點進行預測。為了更好地對不同大小的物體進行預測,人們提出圖1b的金字塔特徵,大物體使用高層的粗粒度特徵,小物體使用底層的細粒度特徵。對於一些pixel-level任務,比如語義分割,需要綜合不同層的上下文信息進行細緻的預測,所以就需要圖1c的預測結構。
- 其次是Non-local network,該網絡借鑒了NLP模型的Self-attention思想,如圖1d所示,能夠借鑒特徵圖上的其它特徵點來對當前特徵點進行增強。
基於上面兩個思想,論文提出了FPT(Feature Pyramid Transformer),結構如圖1e所示,核心在特徵金字塔上進行類似Non-local的特徵增強,然後再使用多層特徵進行預測。FPT設計了3種特徵增強操作,也是論文的主要貢獻:
- ST(Self-Transformer):跟non-local操作一樣在對當前層進行特徵增強。
- GT(Grounding Transformer):這是top-down形式的non-local操作,將高層特徵(尺寸小的)分別用於低層特徵的增強。
- RT(Rendering Transformer):這是bottom-up形式的non-local操作,將低層特徵(尺寸大的)分別用於高層特徵的增強。
Feature Pyramid Transformer

FPT的特徵轉換流程如圖2所示,輸入為金字塔特徵,首先對每層特徵分別進行ST、GT、RT特徵增強得到多個增強後的特徵,然後對增強的特徵按尺寸進行排序,將相同大小的特徵concate到一起,通過卷積將增強後的特徵維度恢復到輸入時的相同維度。
Non-Local Interaction Revisited
由於論文提出的特徵增強操作與non-local操作有很大關係,這裡需要先介紹下non-local的思想。常規non-local操作的輸入為單特徵圖X上的queries(Q), keys(K)和values(V),輸出與X尺寸相同的增強特徵\hat{X}:

q_i=f_q(X_i)\in Q,k_j=f_k(X_j)\in K,v_j=f_v(X_j)\in V,f_q(\cdot)、f_k(\cdot)和f_v(\cdot)為對應的線性變換,X_i和X_j為特徵圖X上的第i^{th}和j^{th}位置上的特徵,F_{sim}為相似度函數,默認為點積,F_{nom}為歸一化函數,默認為softmax,F_{mul}為權重集成函數,默認為矩陣相乘,\hat{X}_i為輸出特徵圖\hat{X}的第i^{th}位置上的特徵。
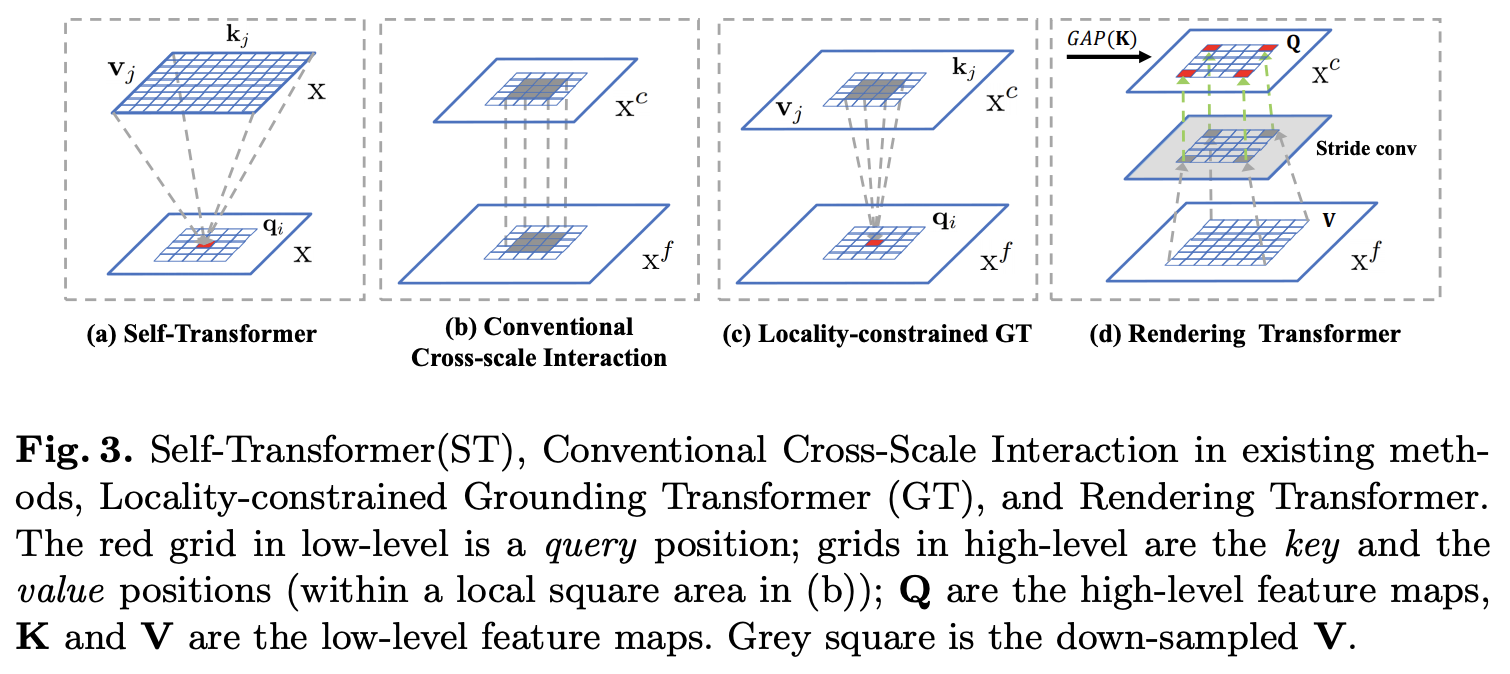
Self-Transformer
ST為改進版non-local操作,如圖1a所示,主要有兩點不同:
- 將q_i和k_j分為\mathcal{N}部分,然後計算每部分的每組q_{i,n}和k_{j,n}相似度分數s^n_{i,j}
- 相似度計算使用改進的MoS(Mixture of Softmaxes)函數F_{mos}:
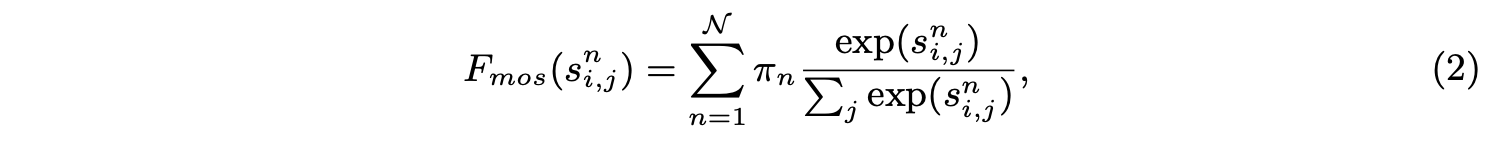
\pi_n=Softmax(w^T_n \overline{k})為特徵集成時的權重,w_n為可學習的線性變換,\overline{k}為所有k_j的均值。
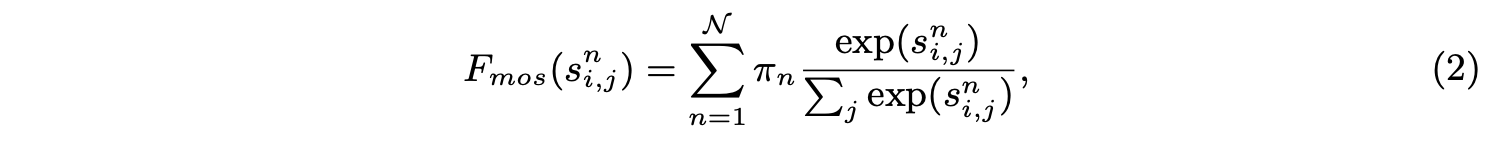
基於上述的改進,ST定義為:
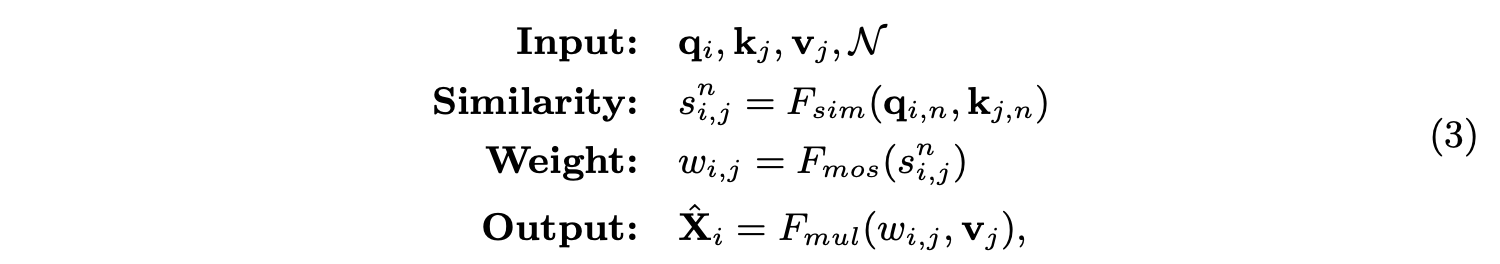
Grounding Transformer
GT是top-down形式的non-local操作,如圖2c所示,借用高層的粗粒度特徵X^c來增強低層的細粒度特徵X^f。在計算時,相似度計算由點積替換為更高效的歐氏距離F_{eud}:
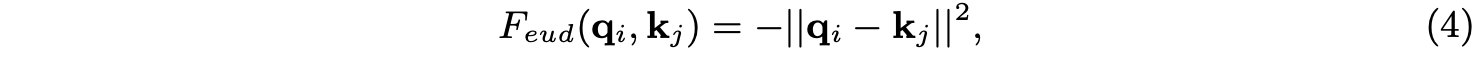
q_i=f_q(X^f_i),k_j=f_k(X^c_j)。GT跟ST一樣將q_i和k_j分為\mathcal{N}部分,完整的定義為:
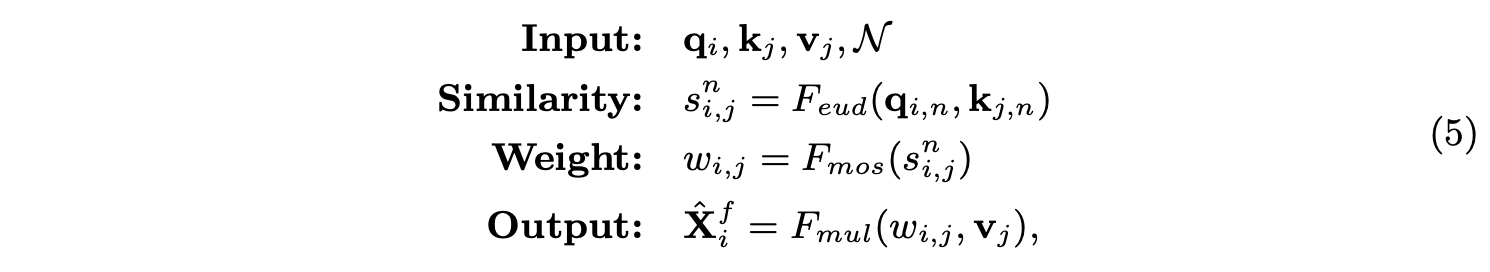
在特徵金字塔中,高低層特徵分別包含圖片的全局和局部信息,而對於語義分割任務,不需要關注過多高層的全局信息,更多的是需要query位置附近的上下文信息,所以圖3b的跨層卷積對語義分割任務十分有效。由於GT操作是全局計算,所以論文提出了局部約束(Locality-constrained)的GT操作LGT,如圖3c所示,每個q_i只與高層局部區域的k_j和v_j進行計算。高層局部區域以q_i對應的位置為中心,邊長(square size)為固定值。如果高層的局部區域越出了特徵圖,則使用0代替。
Rendering Transformer
與GT相反,RT是bottom-up形式的non-local操作,借用低層的細粒度特徵來增強高層的粗粒度特徵。RT也是局部約束(Locality-constrained)的,以channel-wise進行計算的,定義高層特徵為Q,低層特徵為K和V,計算步驟包含如下:
- 對K和進行全局平均池化得到權重w。
- 使用權重w對Q進行加權得到Q_{att}。
- 對V進行帶stride的$3\times 3卷積下採樣得到V_{dow}$。
- 使用$3\times 3卷積對Q_{att}進行調整,並與V_{dow}相加,再過一層$3\times 3卷積後輸出。
完整RT的定義為:

F_{att}(\cdot)為外積函數,F_{scov}(\cdot)為帶stride的$3\times 3卷積,F_{conv}(\cdot)為用於調整的$3\times 3卷積,F_{add}(\cdot)為包含$3\times 3$卷積的特徵相加函數。
Experiments
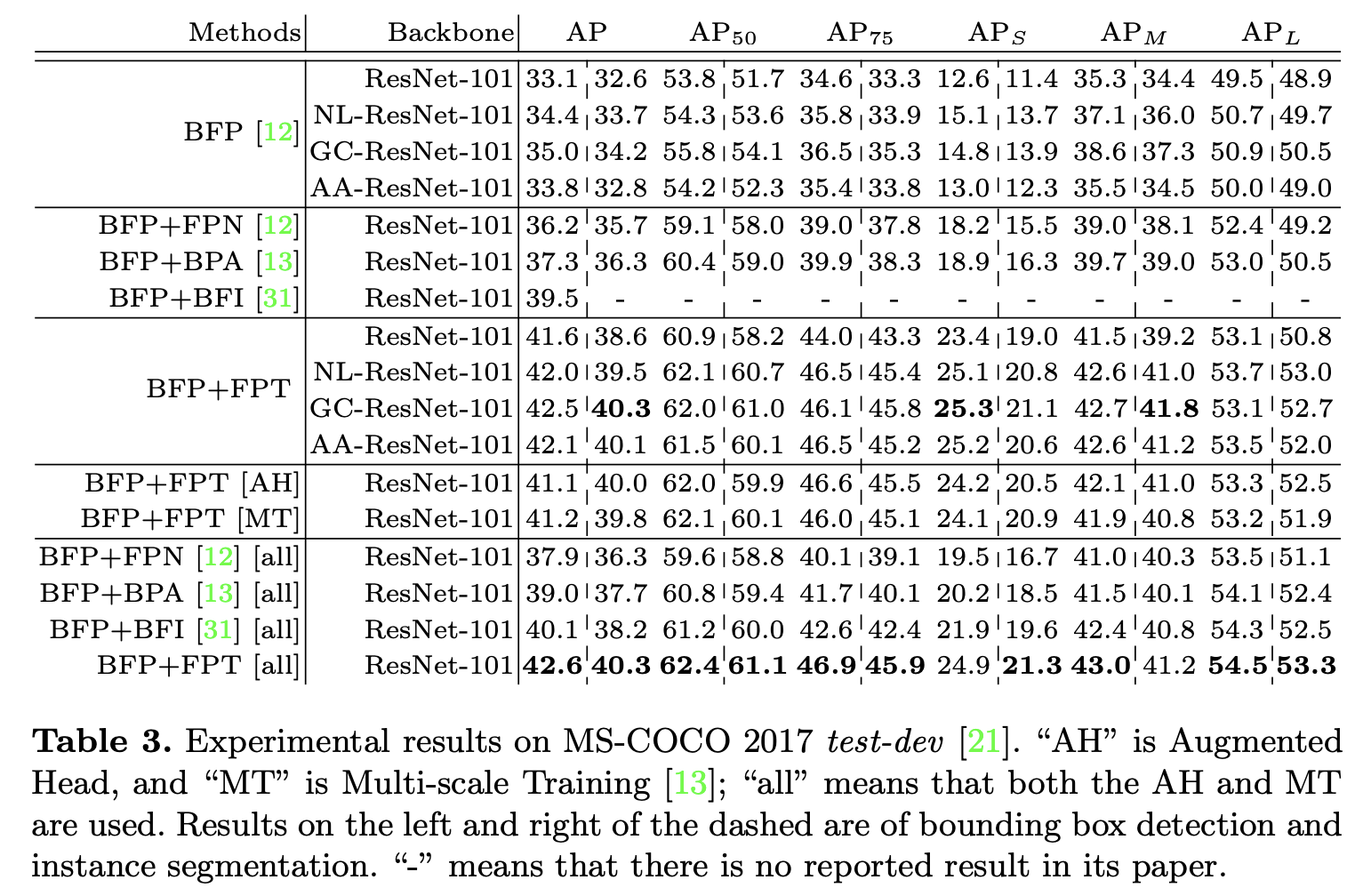
在COCO上與其它算法的對比實驗。
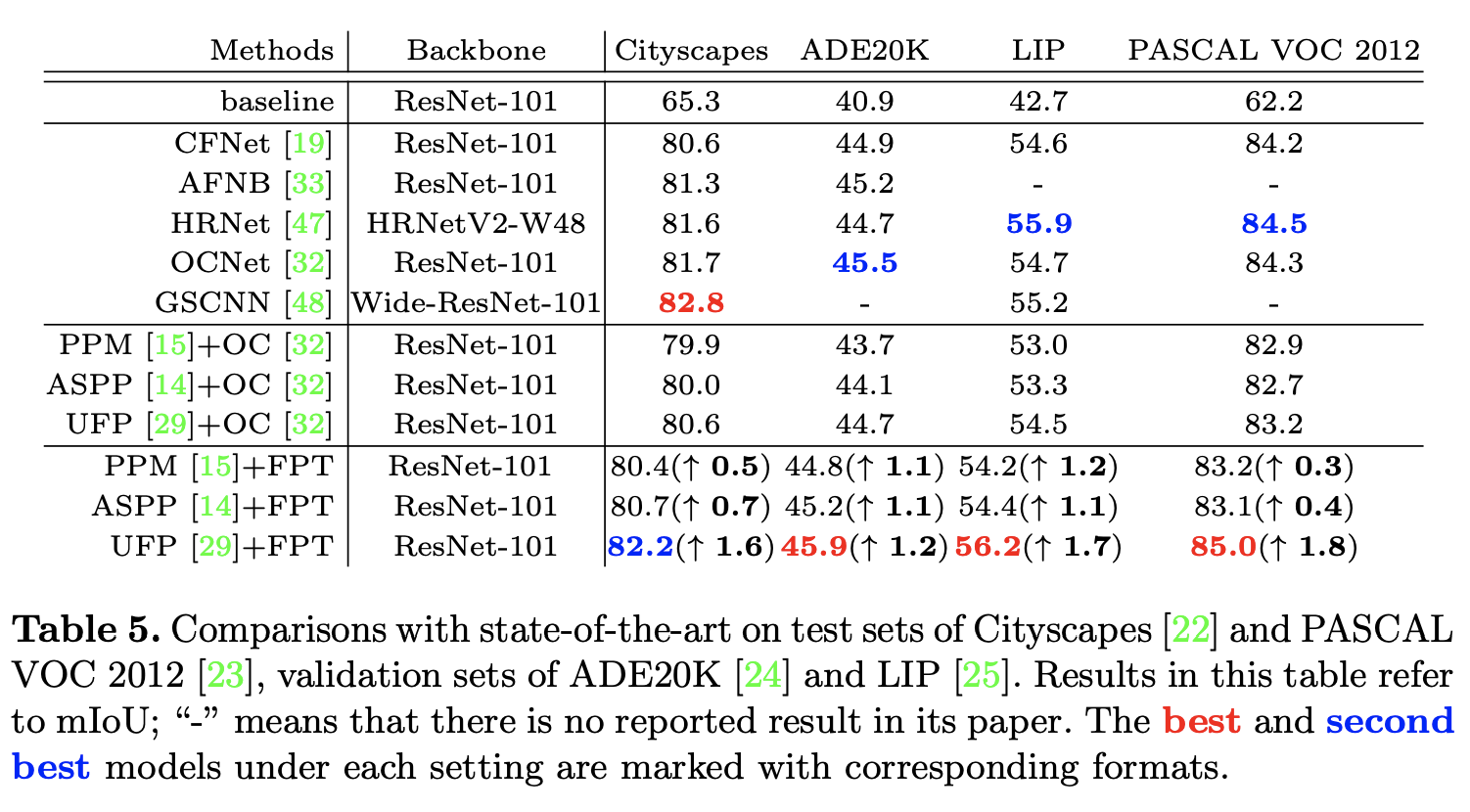
在多個數據集上的進行語義分割性能對比。
Conclusion
論文提出用於特徵金字塔的高效特徵交互方法FPT,包含3種精心設計的特徵增強操作,分別用於借鑒層內特徵進行增強、借鑒高層特徵進行增強以及借鑒低層特徵進行增強,FPT的輸出維度與輸入一致,能夠自由嵌入到各種包含特徵金字塔的檢測算法中,從實驗結果來看,效果不錯。
如果本文對你有幫助,麻煩點個贊或在看唄~
更多內容請關注 微信公眾號【曉飛的算法工程筆記】



