IO多路復用原理&場景
為了講多路復用,當然還是要跟風,採用鞭屍的思路,先講講傳統的網絡 IO 的弊端,用拉踩的方式捧起多路復用 IO 的優勢。
為了方便理解,以下所有代碼都是偽代碼,知道其表達的意思即可。
IO多路復用的歷史
阻塞 IO
服務端為了處理客戶端的連接和請求的數據,寫了如下代碼。
listenfd = socket(); // 打開一個網絡通信端口
bind(listenfd); // 綁定
listen(listenfd); // 監聽
while(1) {
connfd = accept(listenfd); // 阻塞建立連接
int n = read(connfd, buf); // 阻塞讀數據
doSomeThing(buf); // 利用讀到的數據做些什麼
close(connfd); // 關閉連接,循環等待下一個連接
}
這段代碼會執行得磕磕絆絆,就像這樣。

可以看到,服務端的線程阻塞在了兩個地方,一個是 accept 函數,一個是 read 函數。
如果再把 read 函數的細節展開,我們會發現其阻塞在了兩個階段。
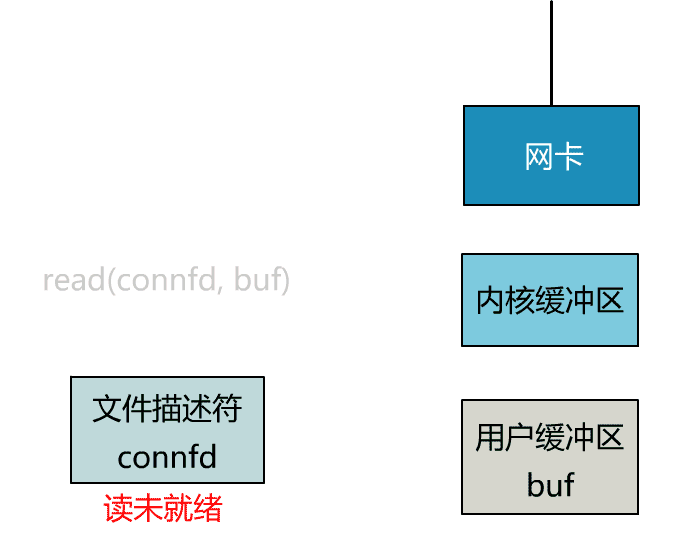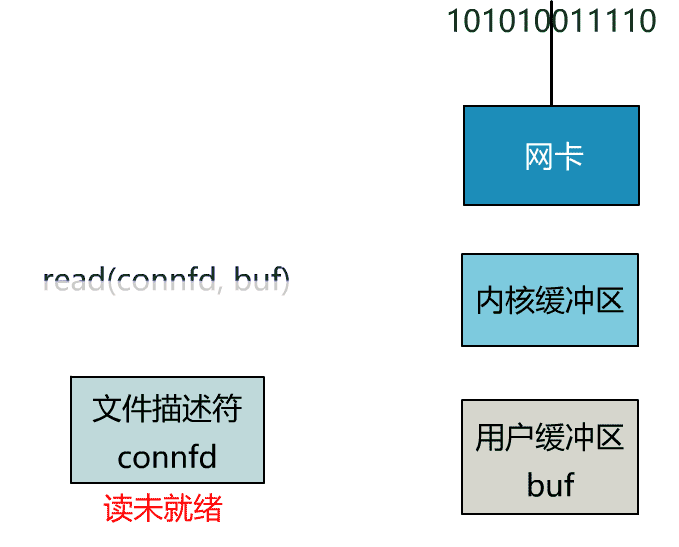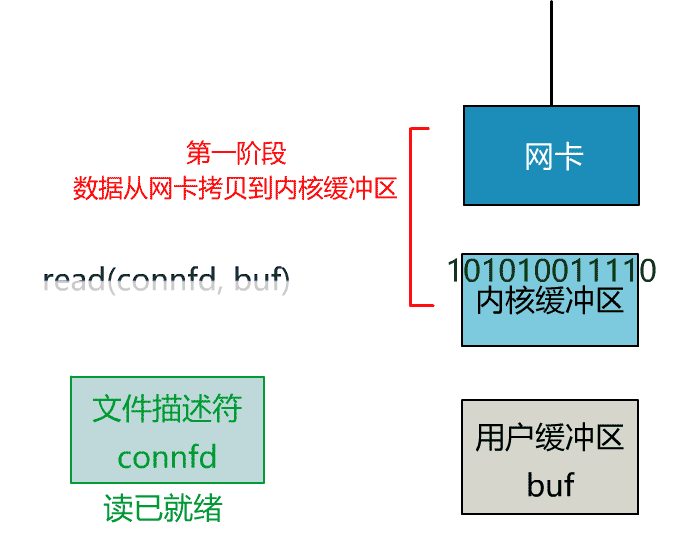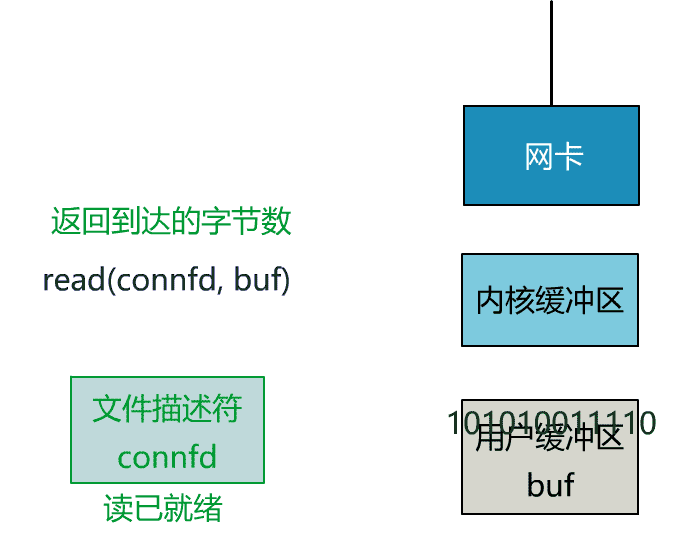
這就是傳統的阻塞 IO。
整體流程如下圖。
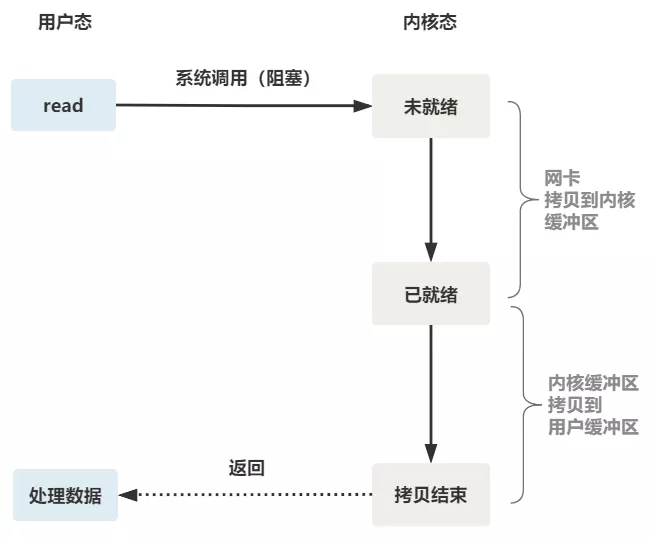
所以,如果這個連接的客戶端一直不發數據,那麼服務端線程將會一直阻塞在 read 函數上不返回,也無法接受其他客戶端連接。
這肯定是不行的。
非阻塞 IO
為了解決上面的問題,其關鍵在於改造這個 read 函數。
有一種聰明的辦法是,每次都創建一個新的進程或線程,去調用 read 函數,並做業務處理。
while(1) {
connfd = accept(listenfd); // 阻塞建立連接
pthread_create(doWork); // 創建一個新的線程
}
void doWork() {
int n = read(connfd, buf); // 阻塞讀數據
doSomeThing(buf); // 利用讀到的數據做些什麼
close(connfd); // 關閉連接,循環等待下一個連接
}
這樣,當給一個客戶端建立好連接後,就可以立刻等待新的客戶端連接,而不用阻塞在原客戶端的 read 請求上。

不過,這不叫非阻塞 IO,只不過用了多線程的手段使得主線程沒有卡在 read 函數上不往下走罷了。操作系統為我們提供的 read 函數仍然是阻塞的。
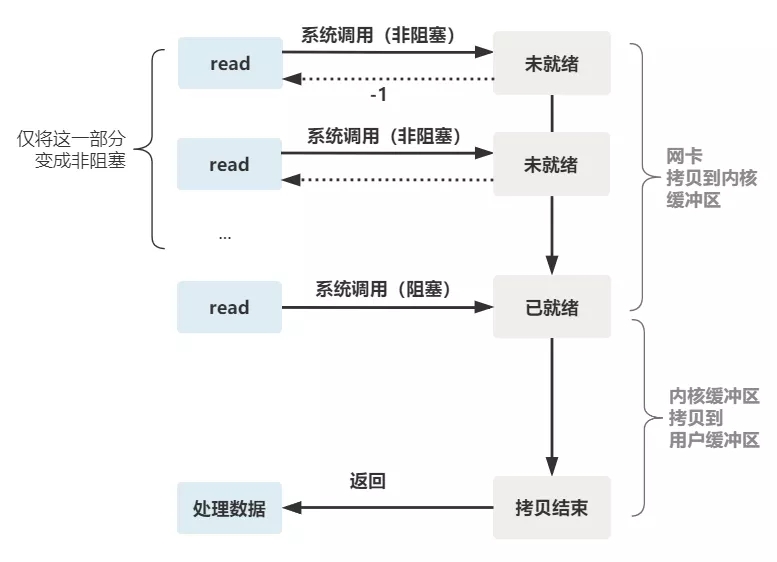
所以真正的非阻塞 IO,不能是通過我們用戶層的小把戲,而是要懇請操作系統為我們提供一個非阻塞的 read 函數。
這個 read 函數的效果是,如果沒有數據到達時(到達網卡並拷貝到了內核緩衝區),立刻返回一個錯誤值(-1),而不是阻塞地等待。
操作系統提供了這樣的功能,只需要在調用 read 前,將文件描述符設置為非阻塞即可。
fcntl(connfd, F_SETFL, O_NONBLOCK);
int n = read(connfd, buffer) != SUCCESS);
這樣,就需要用戶線程循環調用 read,直到返回值不為 -1,再開始處理業務。
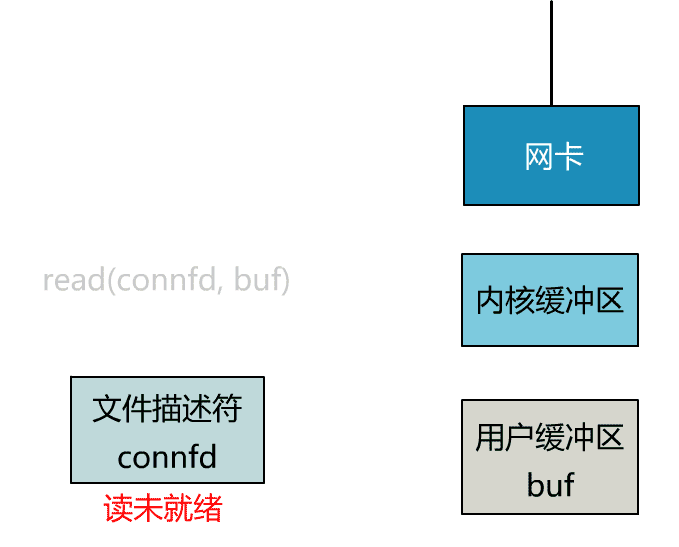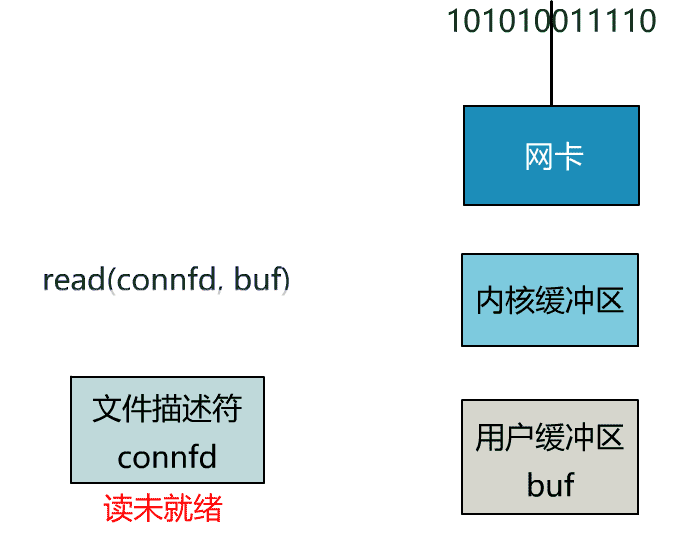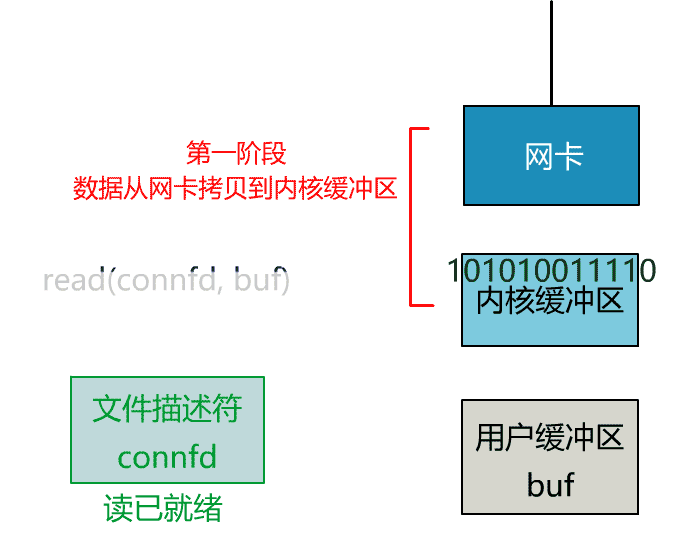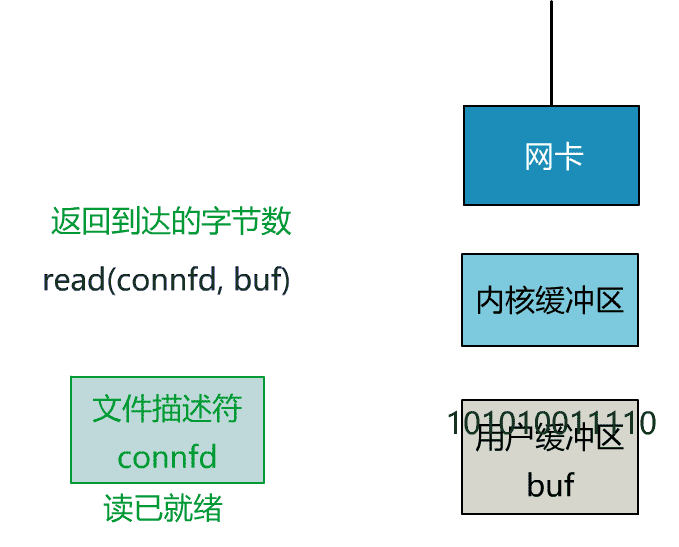
這裡我們注意到一個細節。
非阻塞的 read,指的是在數據到達前,即數據還未到達網卡,或者到達網卡但還沒有拷貝到內核緩衝區之前,這個階段是非阻塞的。
當數據已到達內核緩衝區,此時調用 read 函數仍然是阻塞的,需要等待數據從內核緩衝區拷貝到用戶緩衝區,才能返回。
整體流程如下圖
IO 多路復用
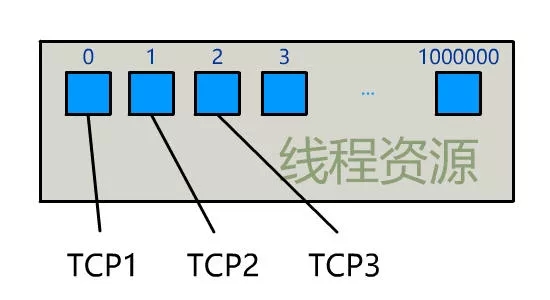
為每個客戶端創建一個線程,服務器端的線程資源很容易被耗光。
當然還有個聰明的辦法,我們可以每 accept 一個客戶端連接後,將這個文件描述符(connfd)放到一個數組裡。
fdlist.add(connfd);
然後弄一個新的線程去不斷遍歷這個數組,調用每一個元素的非阻塞 read 方法。
while(1) {
for(fd <-- fdlist) {
if(read(fd) != -1) {
doSomeThing();
}
}
}
這樣,我們就成功用一個線程處理了多個客戶端連接。
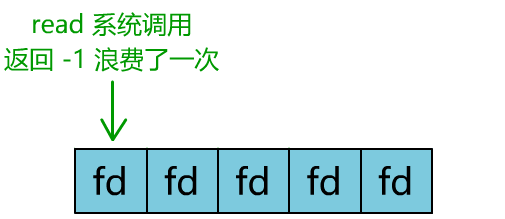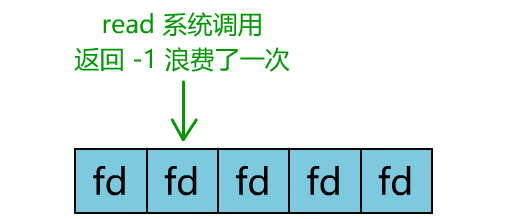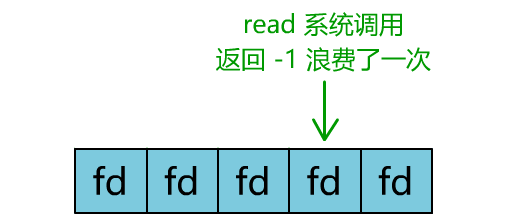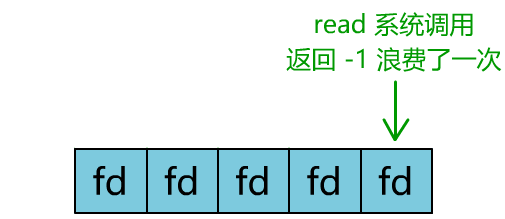
你是不是覺得這有些多路復用的意思?
但這和我們用多線程去將阻塞 IO 改造成看起來是非阻塞 IO 一樣,這種遍歷方式也只是我們用戶自己想出的小把戲,每次遍歷遇到 read 返回 -1 時仍然是一次浪費資源的系統調用。
在 while 循環里做系統調用,就好比你做分佈式項目時在 while 里做 rpc 請求一樣,是不划算的。
所以,還是得懇請操作系統老大,提供給我們一個有這樣效果的函數,我們將一批文件描述符通過一次系統調用傳給內核,由內核層去遍歷,才能真正解決這個問題。
select
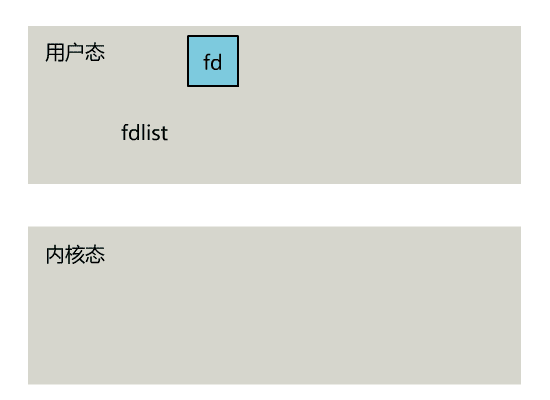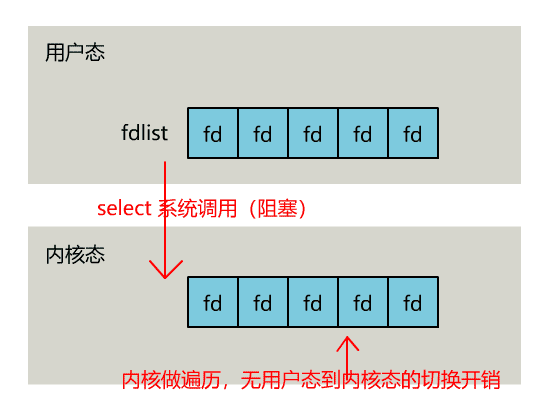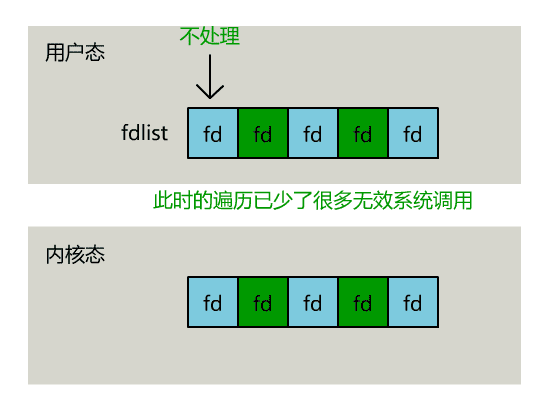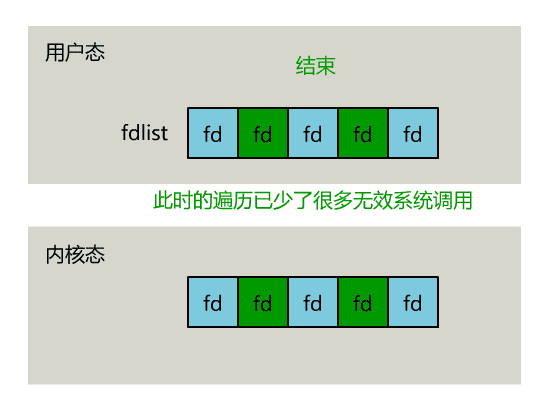
select 是操作系統提供的系統調用函數,通過它,我們可以把一個文件描述符的數組發給操作系統, 讓操作系統去遍歷,確定哪個文件描述符可以讀寫, 然後告訴我們去處理:
select系統調用的函數定義如下。
int select(
int nfds,
fd_set *readfds,
fd_set *writefds,
fd_set *exceptfds,
struct timeval *timeout);
// nfds:監控的文件描述符集里最大文件描述符加1
// readfds:監控有讀數據到達文件描述符集合,傳入傳出參數
// writefds:監控寫數據到達文件描述符集合,傳入傳出參數
// exceptfds:監控異常發生達文件描述符集合, 傳入傳出參數
// timeout:定時阻塞監控時間,3種情況
// 1.NULL,永遠等下去
// 2.設置timeval,等待固定時間
// 3.設置timeval里時間均為0,檢查描述字後立即返回,輪詢
服務端代碼,這樣來寫。
首先一個線程不斷接受客戶端連接,並把 socket 文件描述符放到一個 list 里。
while(1) {
connfd = accept(listenfd);
fcntl(connfd, F_SETFL, O_NONBLOCK);
fdlist.add(connfd);
}
然後,另一個線程不再自己遍歷,而是調用 select,將這批文件描述符 list 交給操作系統去遍歷。
while(1) {
// 把一堆文件描述符 list 傳給 select 函數
// 有已就緒的文件描述符就返回,nready 表示有多少個就緒的
nready = select(list);
...
}
不過,當 select 函數返回後,用戶依然需要遍歷剛剛提交給操作系統的 list。
只不過,操作系統會將準備就緒的文件描述符做上標識,用戶層將不會再有無意義的系統調用開銷。
while(1) {
nready = select(list);
// 用戶層依然要遍歷,只不過少了很多無效的系統調用
for(fd <-- fdlist) {
if(fd != -1) {
// 只讀已就緒的文件描述符
read(fd, buf);
// 總共只有 nready 個已就緒描述符,不用過多遍歷
if(--nready == 0) break;
}
}
}
正如剛剛的動圖中所描述的,其直觀效果如下。(同一個動圖消耗了你兩次流量,氣不氣?)
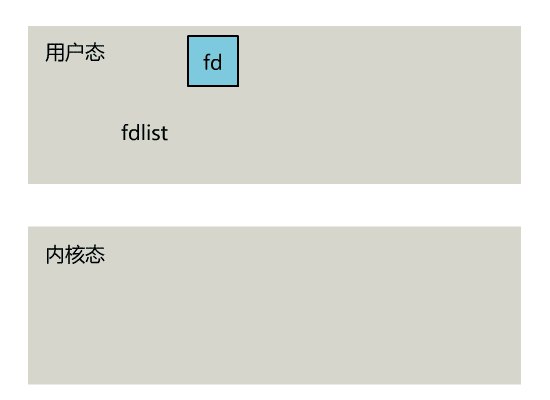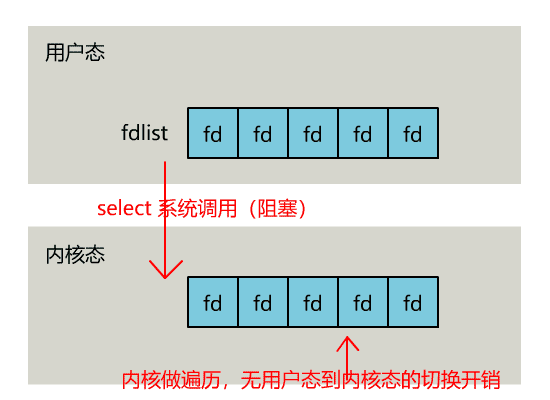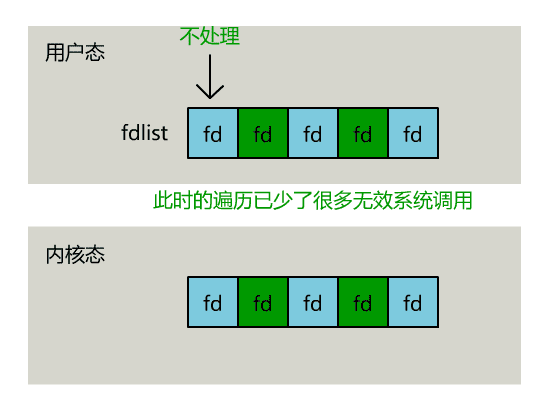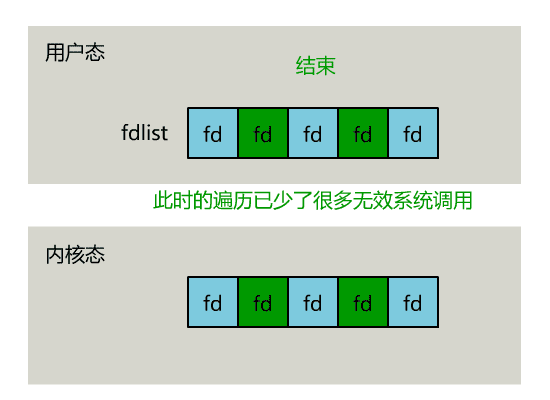
可以看出幾個細節:
select 調用需要傳入 fd 數組,需要拷貝一份到內核,高並發場景下這樣的拷貝消耗的資源是驚人的。(可優化為不複製)
select 在內核層仍然是通過遍歷的方式檢查文件描述符的就緒狀態,是個同步過程,只不過無系統調用切換上下文的開銷。(內核層可優化為異步事件通知)
select 僅僅返回可讀文件描述符的個數,具體哪個可讀還是要用戶自己遍歷。(可優化為只返回給用戶就緒的文件描述符,無需用戶做無效的遍歷)
整個 select 的流程圖如下。
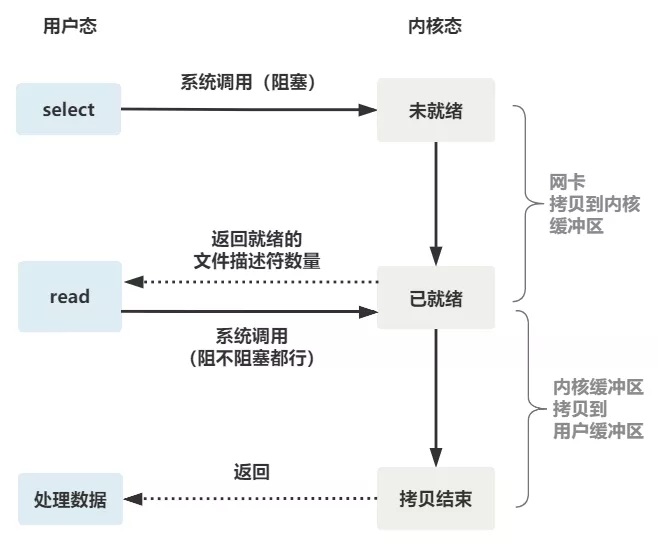
可以看到,這種方式,既做到了一個線程處理多個客戶端連接(文件描述符),又減少了系統調用的開銷(多個文件描述符只有一次 select 的系統調用 + n 次就緒狀態的文件描述符的 read 系統調用)。
poll
poll 也是操作系統提供的系統調用函數。
int poll(struct pollfd *fds, nfds_tnfds, int timeout);
struct pollfd {
intfd; /*文件描述符*/
shortevents; /*監控的事件*/
shortrevents; /*監控事件中滿足條件返回的事件*/
};
它和 select 的主要區別就是,去掉了 select 只能監聽 1024 個文件描述符的限制。
epoll
epoll 是最終的大 boss,它解決了 select 和 poll 的一些問題。
還記得上面說的 select 的三個細節么?
\1. select 調用需要傳入 fd 數組,需要拷貝一份到內核,高並發場景下這樣的拷貝消耗的資源是驚人的。(可優化為不複製)
\2. select 在內核層仍然是通過遍歷的方式檢查文件描述符的就緒狀態,是個同步過程,只不過無系統調用切換上下文的開銷。(內核層可優化為異步事件通知)
\3. select 僅僅返回可讀文件描述符的個數,具體哪個可讀還是要用戶自己遍歷。(可優化為只返回給用戶就緒的文件描述符,無需用戶做無效的遍歷)
所以 epoll 主要就是針對這三點進行了改進。
\1. 內核中保存一份文件描述符集合,無需用戶每次都重新傳入,只需告訴內核修改的部分即可。
\2. 內核不再通過輪詢的方式找到就緒的文件描述符,而是通過異步 IO 事件喚醒。
\3. 內核僅會將有 IO 事件的文件描述符返回給用戶,用戶也無需遍歷整個文件描述符集合。
具體,操作系統提供了這三個函數。
第一步,創建一個 epoll 句柄
int epoll_create(int size);
第二步,向內核添加、修改或刪除要監控的文件描述符。
int epoll_ctl(
int epfd, int op, int fd, struct epoll_event *event);
第三步,類似發起了 select() 調用
int epoll_wait(
int epfd, struct epoll_event *events, int max events, int timeout);
使用起來,其內部原理就像如下一般絲滑。

如果你想繼續深入了解 epoll 的底層原理,推薦閱讀飛哥的《圖解 | 深入揭秘 epoll 是如何實現 IO 多路復用的!》,從 linux 源碼級別,一行一行非常硬核地解讀 epoll 的實現原理,且配有大量方便理解的圖片,非常適合源碼控的小夥伴閱讀。
後記
大白話總結一下。
一切的開始,都起源於這個 read 函數是操作系統提供的,而且是阻塞的,我們叫它 阻塞 IO。
為了破這個局,程序員在用戶態通過多線程來防止主線程卡死。
後來操作系統發現這個需求比較大,於是在操作系統層面提供了非阻塞的 read 函數,這樣程序員就可以在一個線程內完成多個文件描述符的讀取,這就是 非阻塞 IO。
但多個文件描述符的讀取就需要遍歷,當高並發場景越來越多時,用戶態遍歷的文件描述符也越來越多,相當於在 while 循環里進行了越來越多的系統調用。
後來操作系統又發現這個場景需求量較大,於是又在操作系統層面提供了這樣的遍歷文件描述符的機制,這就是 IO 多路復用。
多路復用有三個函數,最開始是 select,然後又發明了 poll 解決了 select 文件描述符的限制,然後又發明了 epoll 解決 select 的三個不足。
所以,IO 模型的演進,其實就是時代的變化,倒逼着操作系統將更多的功能加到自己的內核而已。
如果你建立了這樣的思維,很容易發現網上的一些錯誤。
比如好多文章說,多路復用之所以效率高,是因為用一個線程就可以監控多個文件描述符。
這顯然是知其然而不知其所以然,多路復用產生的效果,完全可以由用戶態去遍歷文件描述符並調用其非阻塞的 read 函數實現。而多路復用快的原因在於,操作系統提供了這樣的系統調用,使得原來的 while 循環里多次系統調用,變成了一次系統調用 + 內核層遍歷這些文件描述符。
就好比我們平時寫業務代碼,把原來 while 循環里調 http 接口進行批量,改成了讓對方提供一個批量添加的 http 接口,然後我們一次 rpc 請求就完成了批量添加。
一個道理。
以上來源於 你管這破玩意叫 IO 多路復用?
裏面的動圖特別的形象,為了怕文章刪除,因此完全copy過來。
IO多路復用高效的原因
IO多路復用之所以高效的原因是用一個線程監控多個文件描述符(socket句柄)的狀態,根本原因是操作系統提供了系統調用(select、epollo),使得原來用戶代碼內的while循環內的多次系統調用變成了一次系統調用+內核層遍歷這些文件描述符。
select的三個缺點:
1.連接數受限
2.採用遍歷文件句柄集合方式獲取就緒的句柄,在文件連接數多的情況下效率低
3.數據由內核copy到用戶態
poll只是改善了select第一個缺點,連接數不再受限。
epoll改變了select三個缺點。
select和poll獲取就緒狀態句柄事件複雜度O(n),epoll獲取就緒狀態句柄事件複雜度O(1)。
epoll會把哪個channel發生了什麼IO就緒通知給用戶,採用的是事件驅動模型,因此複雜度是O(1)。。
表面上看epoll的性能最好,但是在連接數少並且連接都十分活躍的情況下,select和poll的性能可能比epoll好,畢竟epoll的通知機制需要很多函數回調。
select低效是因為每次它都需要輪詢。但低效也是相對的,視情況而定。
IO多路復用解決的什麼問題
IO多路復用解決的是阻塞IO中1連接1線程模式在高並發場景下線程過多導致的切換效率問題,採用多路復用減少線程數量,從而減少線程切換次數,提高cpu利用率,但並不能提高IO。因此只有當服務器瓶頸是大量連接的線程切換時,才會提高效率,比如web就非常適合採用IO多路復用。相反連接數少的情況下,沒必要使用多路復用。
web server的特點是:並不能限定某個時間段有多少個用戶對服務器發起請求,即不能讓連接數成為你服務的瓶頸。而且高並發web應用有一個特點就是fast fail:快速響應,如果在指定時間內響應不了,直接返回失敗。所以每個連接處理的業務邏輯,不會過於複雜——否則就放到異步任務中。大量連接、每個連接的負載較輕的情況,是nio的常用場景。所以web server非常適用nio。
epoll比selector性能一定更好嗎
從IO多路復用分析來看,selector採用輪詢socket句柄集合來判斷是否有事件就緒,epoll是通過回調機制來通知用戶來喚醒socket就緒,epoll比selector要高效,但是為什麼實際中使用的中間件dubbbo、rocketmq的通信netty都是使用的NIO selector方式,而非epoll呢?
以前時候我也一直以為epoll效率比select高(畢竟select和poll都是輪詢,即每次調用都掃描整個文件描述符集合,將其中就緒的文件描述符返回給用戶程序,因此它們檢測就緒事件算法複雜度是o(n),epoll採用回調方式,內核檢測到就緒的文件描述符,觸發回調,回調將該文件描述符對應的事件插入內核就緒隊列,內核最後在適當的時間將該就緒隊列中的內容拷貝到用戶空間。因此epoll無須輪詢整個文件描述符集合來檢測哪些事件就緒,其算法複雜度是o(1)),在linux上netty要選擇epoll,但是通過看dubbo、rocketmq等中間件的通信,發現都使用的select,經過查詢資料,認為這些中間件選擇選擇select的原因肯定是有過實際選型調用和實踐。
epoll引入了新的數據結構,帶來了複雜性,如果連接都是活躍連接,那麼select直接對整個socket句柄進行遍歷就可以獲取到整個連接就緒句柄,對於epoll來說,每次都要進行回調,回調太頻繁了(通常回調都是通過遍歷監聽器),這樣效率反而不如select。
對於dubbo、rocketmq採用selector是因為連接都是活動連接,且連接並不是特別多,那麼使用selector直接對整個socket句柄集合進行輪詢效率很高。而epoll更適合巨量的連接數,活動連接較少的情況,比如IM通信等。
總結:select時候連接大多數是活躍狀態,epoll適合連接數量多,但是活動連接較少的情況。
下圖解釋了select和epoll的壓測情況

IO多路復用在中間件的使用場景
IO多路復用即一個select/epollo管理多個channe,多個channel共用一個IO(這個IO認為是一個reactor線程,線程和select/epoll綁定)。
以下框架和中間件使用了IO多路復用,如netty,nginx、redis
為什麼nginx使用IO多路復用是多進程(單線程)
nginx通信也採用了IO多路復用,不同的是它採用的是多進程(單線程)形式。
netty使用IO多路復用是多線程形式,即多個IO線程,但是nginx是一個master進程用於accept(等同netty的boss線程),多個worker進程(每個worker進程只有一個IO線程)用於IO操作(等同netty的work線程,即IO線程),nginx這樣做的原因是為了高可用,如果Nginx 使用了多線程的模式,由於線程之間是共享同一個地址空間的,當某一個第三方模塊引發了一個地址空間導致的斷錯時 (eg: 地址越界), 會導致整個Nginx全部掛掉; 當採用多進程來實現時, 往往不會出現這個問題。nginx開放了插件機制,為了高可用,因此設置為多進程(單線程)模式。
參考
//blog.csdn.net/qq422431474/article/details/108244352
redis的網絡模型
redis在6.0之前採用的是單reactor模型,利用 select/epolle 等多路復用技術,在單線程(一個redis進程只有一個線程)的事件循環中不斷去處理事件(客戶端請求),操作內存,最後回寫響應數據到客戶端:因此6.0之前為了在多核服務器發揮redis性能,通常是一個服務器部署多個redis實例。redis採用單線程的原因是避免上下文切換,且因為操作的是內存,不會導致阻塞,因此cpu不是瓶頸,網絡IO才是瓶頸因此採用了單reactor模型。
隨着互聯網的高速發展,互聯網業務系統所要處理的線上流量越來越大,Redis 的單線程模式會導致系統消耗很多 CPU 時間在網絡 I/O 上從而降低吞吐量,為了提升 Redis 的性能因此需要優化網絡IO模型,因此redis6.0開始redis網絡模型採用的主從reactor模型,和netty的線程模型相同。
參考
//strikefreedom.top/multiple-threaded-network-model-in-redis
//javamana.com/2021/12/202112270226346085.html
netty為什麼選擇NIO而非AIO
NIO模型
我們常說的NIO指的是同步非阻塞,非阻塞是因為select檢測到socket句柄沒有就緒事件(該socket網卡到內核沒有數據),直接返回;同步指的是讀就緒(數據到了內核),select調用,把數據從內核讀取到用戶空間。
AIO模型
AIO異步非阻塞,客戶端的I/O請求都是由內核先完成了再通知(回調)用戶線程進行處理,AIO又稱為NIO2.0,在JDK7才開始支持。
看起來AIO要比NIO高效的多,但是netty為什麼選擇NIO而非AIO呢?
從netty issue上查看到netty作者的原話,主要原因總結如下:
Netty.4.Final 刪除了AIO的原因如下:
1.Netty不看重Windows上的使用,在Linux系統上,AIO的底層實現仍使用EPOLL,沒有很好實現AIO,因此在性能上沒有明顯的優勢,而且被JDK封裝了一層不容易深度優化。
2.Netty整體架構是reactor模型, 而AIO是proactor模型, 混合在一起會非常混亂,把AIO也改造成reactor模型看起來是把epoll繞個彎又繞回來。
3.AIO還有個缺點是接收數據需要預先分配緩存, 而不是NIO那種需要接收時才需要分配緩存, 所以對連接數量非常大但流量小的情況, 內存浪費很多。
4.Linux上AIO不夠成熟。

BIO 和 NIO 在應用場景上的區別?它們各有什麼優勢劣勢?
BIO 方式適用於連接數目比較小且固定的架構,這種方式對服務器資源要求比較高,對訪問響應速度沒有太高要求的架構中可以考慮,優點開發簡單,易上手,但是不適合連接數多且高並發的場景。小連接數,追求極快響應的場景比較適合 BIO。在文件傳輸方面,也適合使用bio,沒有線程切換。
NIO常說的是同步非阻塞IO,適合於連接數多且高並發IO場景,比如web服務器、rpc等場景。NIO(netty實現)不適合大文件傳輸,會導致IO線程一直處理這個socket的讀取從而導致其它socket的讀取阻塞。缺點是:用NIO同時保持連接數多了,會導致單個連接的網絡響應時間下降,因為總帶寬不變,且TCP本來就是非保證帶寬的技術實現。
典型場景:
BIO: 數據庫網絡引擎
NIO: web 服務/rpc服務
為什麼數據庫的網絡模型不選擇IO多路復用
工作中通常對db(mysql)都有連接數的監控,如果連接數達到了閾值(比如3000)會報警給dba,從而dba督促連接此db的項目組進行整改。而且測試環境還會對db進行定時kill連接。我們都知道mysql有連接數的限制,過高的連接會導致mysql性能下降(mysql是bio方式,為每個連接分配一個線程),那麼為什麼mysql不選用IO多路復用呢,不就沒有這個連接數限制問題了嗎?
要從IO多路復用和BIO的場景說起
bio為需要為每個連接分配個線程,在連接數多的情況下,導致頻繁線程上下文切換,cpu得不到充分利用。
IO多路復用解決的是阻塞IO中1連接1線程模式在高並發場景下線程過多導致的切換效率問題,採用多路復用減少線程數量,從而減少線程切換次數,提高cpu利用率,但並不能提高IO。因此只有當服務器瓶頸是大量連接的線程切換時,才會提高效率,比如web就非常適合採用IO多路復用。相反連接數少的情況下,沒必要使用多路復用。比如DB是IO密集型,瓶頸通常在磁盤IO上,不在連接數上。
因此原因如下:
1.jdbc規範發佈的早,那會只有bio,nio出現的晚,因此數據庫驅動都是針對BIO設計的。且 jdbc接口是同步化的。數據庫廠商只提供基於bio的jdbc實現。
2.對於DB而言,DB的瓶頸實際上是硬盤IO,用NIO引入更多的客戶端session最後的結果是session都停留在等待磁盤IO上,並沒法帶來業務實質優化。反而因為每個連接響應時間都變長,從而造成業務響應變壞,而且數據庫的一些實現,比如等鎖,搶鎖等,因為同時重入的session變多,更加容易造成連接等待時間變長,綜上,NIO對DB沒有什麼特別的好處。
3.DB訪問一般採用連接池這種現象是生態造成的。歷史上的BIO+連接池的做法經過多年的發展,已經解決了主要的問題。在Java的大環境下,這個方案是非常靠譜的,成熟的。而基於IO多路復用的方式儘管在性能上可能有優勢,但是其對整個程序的代碼結構要求過多,過於複雜。當然,如果有特定的需要,希望使用IO多路復用管理DB連接,是完全可行的。
當然採用IO多路復用的DB也有,比如redis。只是傳統的RDBMS數據庫由於歷史生態和收益(優勢)問題,通常還是採用的是BIO+線程池模式。
redis採用IO多路復用的原因是redis是基於內存操作,IO上不是瓶頸,瓶頸是網絡IO,因此採用IO多路復用。
參考//www.zhihu.com/question/23084473

