第52篇-即時編譯器
- 2022 年 1 月 12 日
- 筆記
一般來說,Java代碼會先被HotSpot VM解釋執行,之後將統計出的熱點代碼通過即時編譯器C1、C2或Graal編譯成機器碼,直接運行在底層硬件之上。解釋器在之前的文章中已經介紹了不少,但是編譯器還沒有介紹,關於Java涉及到的編譯器如下圖所示。
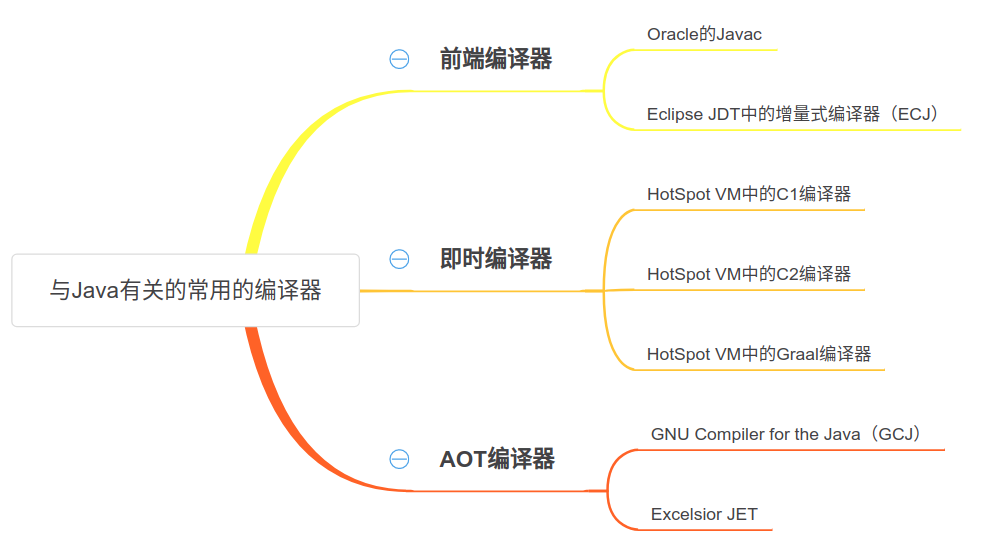
前端編譯器就是將遵循Java語言規範的Java源代碼編譯為遵循Java虛擬機規範的位元組碼,其中《深入解析Java編譯器:源碼剖析與實例詳解》一書中已經詳細介紹過Javac的實現,這裡不再過多介紹。
對於HotSpot VM來說,即時編譯器主要有C1、C2和Graal。這些編譯器會根據相關的統計信息區分出熱點代碼,然後將熱點代碼直接編譯為可在硬件上運行的機器碼。C2和Graal(實驗性質的編譯器,可用來替換C2)的實現比較複雜,大家有興趣的可自行研究,我們後面將會對C1編譯器進行詳細介紹。
AOT(ahead-of-time)編譯器試圖通過在執行之前編譯應用程序代碼來儘可能的降低運行時開銷。AOT編譯器在Java中使用的並不多,所以不做過多介紹。
Java在運行過程中,使用最多的就是解釋器和C1、C2編譯器。那麼解釋執行和編譯執行有哪些優點呢?
- 解釋器優點:當程序需要迅速啟動的時候,解釋器可以首先發揮作用,省去了編譯的時間,立即執行。解釋執行佔用更小的內存空間。同時,當編譯器進行的激進優化失敗的時候,還可以進行逆優化來恢復到解釋執行的狀態。另外還有一個優點就是,解釋器相對來說實現比較簡單,所以對一些新功能特性的支持要比在編譯器中實現快一些。
- 編譯器優點:在程序運行時,隨着時間的推移,編譯器逐漸發揮作用,把越來越多的代碼編譯成本地代碼之後,可以獲得更高的執行效率。
解釋器相對編譯器來說,性能會稍差一些(雖然編譯執行過程中已經採取了許多的優化手段,如之前介紹的棧頂緩存、將多個位元組碼指令合併的超級指令和常量池緩存等),所以會在解釋執行過程中還是會使用編譯來獲取更高的性能。因此,在HotSpot VM運行過程中,解釋器與編譯器經常配合工作,它們之間會來回切換,如下圖所示。

HotSpot VM中內置的兩個即時編譯器Client Compiler和Server Compiler,也就是我們上面說的C1和C2 編譯器。之前我們在研究解釋器的運行原理時,通常會給虛擬機配置選項-Xint來強制HotSpot VM在解釋模式下運行,此時編譯器不會介入工作;如果我們想要HotSpot VM強制運行於編譯模式時,可配置-Xcomp選項,這時候將優先採用編譯方式執行,但是解釋器仍然要在編譯無法進行的情況下接入執行過程。如果我們想要研究某一款編譯器,還可以指定-client和-server選項強制HotSpot VM通過C1或C2來編譯運行。
我們可以通過虛擬機java -version 命令查看當前默認的運行模式。例如我在JDK8版本上運行命令後的輸出結果如下:
mazhi@mazhi:~$ java -version java version "1.8.0_192" Java(TM) SE Runtime Environment (build 1.8.0_192-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.192-b12, mixed mode)
其中的mixed mode指出了默認的運行模式為混合模式,也就是會解釋執行,會編譯執行,也會在C1和C2中選擇編譯執行。
下面我們就來介紹一下C1和C2編譯器。內容基本照搬R大中此文章的內容//hllvm-group.iteye.com/group/topic/39806,只是做了一些配圖和修改。
1、C1編譯器
我們可以將C1編譯器大概分為3個編譯階段,其主要的關注點是局部優化,沒有對程序執行太多的全局優化,因為全局優化比較耗時。C1編譯器的大概執行過程如下圖所示。
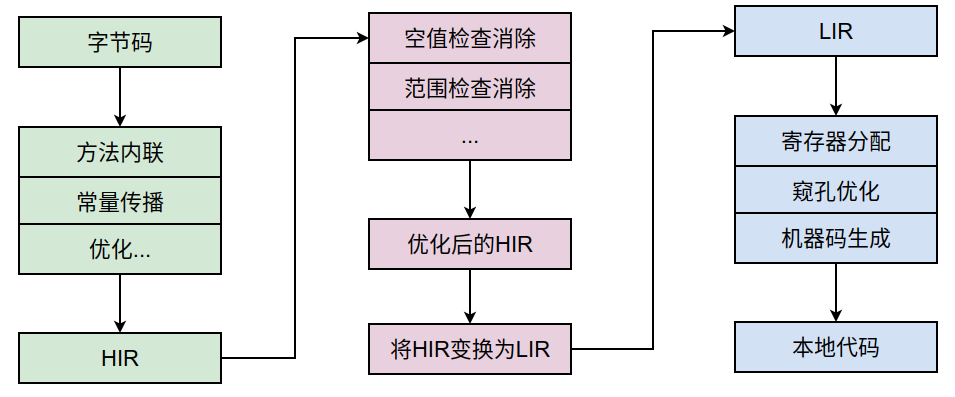
下面簡單介紹一下這幾個階段。
(1)將位元組碼轉換為HIR
一個平台獨立的前端將位元組碼構造成一種高級中間代碼表示(High-Level Intermediate Representaion , HIR)。C1的高層IR名為HIR(High-level Intermediate Representation),是一種比較傳統的IR,有基本塊構成的控制流圖(control-flow graph,CFG)和基本塊內的SSA形式的數據依賴圖。
- HIR的控制流圖是雙向鏈接的,也就是說每個基本塊都有指向前驅節點(predecessor)和指向後繼節點(successor)的指針。
- HIR的數據依賴圖則是單向鏈接的,只有use-def鏈,而不顯式維護def-use鏈。每個數據節點持有指向它的參數的指針,而不知道它自己的值被什麼節點使用。這使得C1很容易做前向數據流分析(forward dataflow analysis),而不那麼方便做後向數據流分析(backward dataflow analysis)。它需要用一個單獨的趟來得到def-use信息。
C1在將位元組碼轉換為HIR的過程中,會在位元組碼上完成一部分基礎優化,如方法內聯、常量傳播等。C1做的優化還是比較簡單,主要有這麼一些:
- 消除冗餘的空指針檢查(null check elimination)
- 消除條件表達式(conditional expression elimination,CEE)
- 合併基本塊
- 基於必經節點的全局值標號(dominator-based GVN)
最新版的HotSpot C1新加了
- 消除數組邊界檢查(range check elimination,RCE)
- 比較簡單的循環不變量外提(loop invariant code motion,LICM)
C1在方法內聯上只用了比較簡單的策略:它能內聯可以靜態判定實現者的、位元組碼大小不大於MaxInlineSize(= 35位元組)的方法。這包括靜態方法、private的實例方法以及final的虛方法。同時它也可以依賴類層次分析(class hierarchy analysis,CHA)來內聯只有單一實現者的虛方法。對於無法內聯的虛方法調用,C1和C2都會生成單態內聯方法調用緩存(monomorphic inline-cache)來加速虛方法調用。代碼里對應的是CompiledIC。
值標號主要用於消除冗餘表達式的計算,並常跟表達式簡化(algebraic simplification)和常量摺疊(constant folding)並用。在這方面,C1在解析位元組碼時只做局部值標號(local value numbering,LVN),也就是只在基本塊內做值標號。而C2此時做的是全局值標號(global value numbering,GVN),也就是在方法內可以跨基本塊邊界做值標號——Ideal Graph根本就沒有基本塊邊界,值標號很自然就是全局的。
另外值得一提的是,C1解析位元組碼得到的IR包含整個方法的邏輯,而C2則可能只包含方法的一部分邏輯——沒執行過的或者很少執行的分支、涉及尚未加載或已卸載的類的地方、許多拋異常的地方等等,這些部分C2假定不會發生所以都不編譯;一旦在運行時真的執行到了這些地方,代碼就會通過逆優化(deoptimization)回到解釋器去繼續執行。這樣可以讓C2的IR更小、類型更精準,以便容忍後續的更耗時的優化。
(2)將HIR變換為LIR
一個平台相關的後端從 HIR 中產生低級中間代碼表示(Low-Level Intermediate Representation ,LIR),而在此之前會在 HIR 上完成另外一些優化,如空值檢查消除,範圍檢查消除等,讓HIR 更為高效。C1的低層IR叫LIR(Low-level Intermediate Representation)。它雖然叫做低層IR,但語義相對其它優化編譯器的LIR來說還是比較高級(也就是說比較抽象,沒那麼貼近目標機器指令),只是能夠顯式刻畫寄存器的使用而已。HIR與LIR之間有固定的對應關係。LIR不是SSA形式的,在從HIR轉換過來的時候需要退出SSA形式。
(3)將LIR轉換為本地代碼
在平台相關的後端使用線性掃描算法(Linear Scan Register Allocation)在 LIR 上分配寄存器,做窺孔(Peephole)優化,然後產生機器碼。 C1使用幾乎線性時間開銷的線性掃描寄存器分配(linear scan register allocation,LSRA)。它具體使用的變種近似與原始LSRA和後來的second chance binpacking的混合形態。
最後就到代碼生成(code generation)了。這裡C1和C2都是像套用模板似的把低層IR映射為機器碼。
C1的LIR跟目標機器碼還有一定距離,所以不一定能一對一映射過去。簡單的運算,如算數運算,通常是一對一映射過去的;而一些比較複雜的操作,例如分配新對象、類型檢查之類的則有大塊的機器碼模板。
2、C2編譯器
C2專門面向服務端的典型應用,並為服務端的性能配置特別調整過的編譯器,是一個充分優化過的高級編譯器。C2編譯器的大概執行過程如下圖所示。
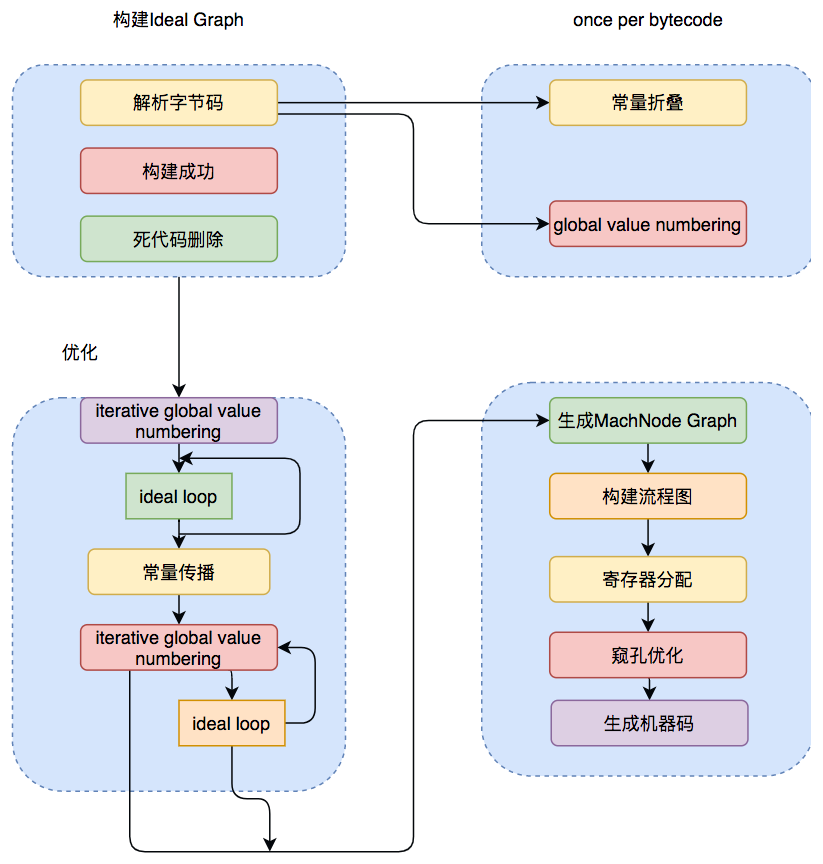
圖片來源://tech.meituan.com/2020/10/22/java-jit-practice-in-meituan.html
C2的高層IR名為Ideal Graph,是一種比較少見的sea-of-nodes形式的IR,屬於PDG(program dependence graph,程序依賴圖),在同一層IR里顯式記述了控制流、數據流與內存副作用依賴,而沒有顯式的基本塊結構。其數據流的部分也是SSA形式的。
Ideal Graph的所有依賴都通過顯式的雙向鏈接來維護,無論是前向還是後向分析做起來都很方便。而且,由於沒有顯式的基本塊結構,它在優化過程中不維護代碼調度順序(schedule),所以使許多原本只適用在局部(基本塊內)的簡單優化變得可以在全局(跨基本塊)適用,使C2能維持相對簡單的結構來達到更好的優化效果。
C1與C2都在解析(parse)位元組碼的時候通過抽象解釋把Java位元組碼轉換為SSA形式的IR。
C2轉換成SSA形式的過程隱含了複寫傳播(copy propagation)優化。 C1和C2都在解析位元組碼的過程中做方法內聯(method inlining)以及值標號(value numbering)優化。
C2在方法內聯上則更為激進:除了C1能內聯的之外,C2還能使用profile信息來內聯無法靜態判定實現者的方法——假如profiling發現某個虛方法調用點實際只調用到了1、2個實現者,那麼C2就可以把這1、2個實現者給內聯進來。
C2則是做迭代式優化。這包括:
- 迭代式全局值標號(iterative GVN)
- 條件常量傳播(conditional constant propagation,CCP)
- 循環優化(Ideal Loop),包括消除數組邊界檢查(RCE)、循環不變量外提(LICM)、循環展開(loop unrolling)、循環剝離(loop peeling)、基於superword的循環再合併、循環向量化等等
- 逃逸分析(escape analysis)與標量替換(scalar replacement)、鎖消除( lock elision)搭配使用
- Java代碼模式優化,例如字符串拼接優化(string concatenation optimization)、消除自動裝箱(autoboxing elimination)等
- 增量式方法內聯(incremental inlining)
大致數了一下,不保證全部優化都列舉出來了。
它是專門面向服務端的典型應用,並為服務端的性能配置特別調整過的編譯器,也是一個充分優化過的高級編譯器,幾乎能達到 GNU C++ 編譯器使用-O2 參數時的優化強度,它會執行所有的經典的優化動作,如
- 無用代碼消除(Dead Code Elimination)
- 循環展開(Loop Unrolling)
- 循環表達式外提(Loop Expression Hoisting)
- 消除公共子表達式(Common Subexpression Elimination)
- 常量傳播(Constant Propagation)
- 基本塊重排序(Basic Block Reordering)
等等,還會實施一些與 Java 語言特性密切相關的優化技術,如範圍檢查消除(Range Check Elimination)、空值檢查消除(Null Check Elimination ,不過並非所有的空值檢查消除都是依賴編譯器優化的,有一些是在代碼運行過程中自動優化 了)等。另外,還可能根據Interpreter或Client Compiler 提供的性能監控信息,進行一些不穩定的激進優化,如 守護內聯(Guarded Inlining)、分支頻率預測(Branch Frequency Prediction)等。
C2的低層IR叫Mach Node Graph。它非常貼近目標機器指令,幾乎能一對一的直接映射到機器碼上。從Ideal Graph轉換到Mach Node Graph需要做指令選擇(instruction selection),還有在代碼調度(scheduling)之後重新創建帶有顯式基本塊結構的控制流圖。
C2的指令選擇通過樹改寫的方式實現,這種系統叫做bottom-up rewrite system,BURS。
C2則使用了更耗時的、比較傳統的Chaitin-Briggs式圖着色寄存器分配(graph-coloring register allocation)。
在寄存器分配後,C1與C2都會做一趟窺孔優化(peephole optimization)來小範圍的優化代碼序列。這算是平台相關優化的一部分。
最後就到代碼生成(code generation)了。這裡C1和C2都是像套用模板似的把低層IR映射為機器碼。
C2的Mach Node跟目標機器碼已經非常接近了,大部分能直接映射為機器碼;有少量需要大塊機器碼模板的情況。
本人對C2不是很了解,所以如果有機會也會研究一下,然後再回來內化這一部分知識。
公眾號 深入剖析Java虛擬機HotSpot 已經更新虛擬機源代碼剖析相關文章到60+,歡迎關注,如果有任何問題,可加作者微信mazhimazh,拉你入虛擬機群交流


