部署Kubernetes Cluster
- 2022 年 1 月 3 日
- 筆記
- 雲計算docker/k8s/openstack
中文學習網站://www.kubernetes.org.cn/doc-16
部署docker服務
所有節點部署docker服務 curl -sSL https://get.daocloud.io/docker | sh systemctl start docker echo '{"registry-mirrors":["//reg-mirror.qiniu.com/"]}' >>/etc/docker/daemon.json systemctl daemon-reload systemctl restart docker
自己的yum安裝沒有鏡像源,需要配置源
[root@mcw7 ~]$ systemctl stop firewalld.service [root@mcw7 ~]$ yum install -y kubelet kubeadm kubectl Loaded plugins: fastestmirror base | 3.6 kB 00:00:00 epel | 4.7 kB 00:00:00 extras | 2.9 kB 00:00:00 updates | 2.9 kB 00:00:00 (1/3): epel/x86_64/updateinfo | 1.0 MB 00:00:01 (2/3): epel/x86_64/primary_db | 7.0 MB 00:00:07 (3/3): updates/7/x86_64/primary_db | 13 MB 00:00:08 Determining fastest mirrors * base: mirrors.aliyun.com * extras: mirrors.aliyun.com * updates: mirrors.aliyun.com No package kubelet available. No package kubeadm available. No package kubectl available. Error: Nothing to do [root@mcw7 ~]$ ls /etc/yum.repos.d/ CentOS-Base.repo CentOS-Base.repo.backup CentOS-CR.repo CentOS-Debuginfo.repo CentOS-fasttrack.repo CentOS-Media.repo CentOS-Sources.repo CentOS-Vault.repo epel.repo
配置阿里kubernetes鏡像源以及yum安裝kubelet/kubeadm/kubectl
所有節點都要安裝kubelet/kubeadm/kubectl 阿里雲kubernetes鏡像源添加指導:https://developer.aliyun.com/mirror/kubernetes?spm=a2c6h.13651102.0.0.3e221b11Ki4Wu1 直接去阿里雲鏡像源找kubernetes,進行操作 CentOS / RHEL / Fedora cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/ enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg //mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF setenforce 0 yum install -y kubelet kubeadm kubectl用 systemctl enable kubelet && systemctl start kubelet
用kubeadm創建集群
官網://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
主機規劃
主機名 節點類型 ip mcw7 master 10.0.0.137 mcw8 node1 10.0.0.138 mcw9 node2 10.0.0.139
初始化Master
[root@mcw7 ~]$ kubeadm init --apiserver-advertise-address 10.0.0.137 --pod-network-cidr=10.244.0.0/24 ...... Server: ERROR: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running? errors pretty printing info , error: exit status 1 [ERROR Service-Docker]: docker service is not active, please run 'systemctl start docker.service' [ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables does not exist [ERROR FileContent--proc-sys-net-ipv4-ip_forward]: /proc/sys/net/ipv4/ip_forward contents are not set to 1 [ERROR SystemVerification]: error verifying Docker info: "Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?" [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...` To see the stack trace of this error execute with --v=5 or higher #運行報錯,這是因為docker daemon沒起 [root@mcw7 ~]$ systemctl start docker.service #啟動docker daemon ,然後初始化Master [root@mcw7 ~]$ kubeadm init --apiserver-advertise-address 10.0.0.137 --pod-network-cidr=10.244.0.0/24 [root@mcw7 ~]$ kubeadm init --apiserver-advertise-address 10.0.0.137 --pod-network-cidr=10.244.0.0/24 [init] Using Kubernetes version: v1.23.1 [preflight] Running pre-flight checks [WARNING Service-Docker]: docker service is not enabled, please run 'systemctl enable docker.service' [WARNING Swap]: swap is enabled; production deployments should disable swap unless testing the NodeSwap feature gate of the kubelet [WARNING Hostname]: hostname "mcw7" could not be reached [WARNING Hostname]: hostname "mcw7": lookup mcw7 on 10.0.0.2:53: no such host error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR NumCPU]: the number of available CPUs 1 is less than the required 2 [ERROR Mem]: the system RAM (976 MB) is less than the minimum 1700 MB [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...` To see the stack trace of this error execute with --v=5 or higher 再次運行報錯: 可用CPU 1的數量小於所需的2可用CPU 1的數量小於所需的2 系統RAM(976 MB)小於最小1700 MB 我的vmware創建的虛擬機是1G的,看來不夠
修改虛擬機配置


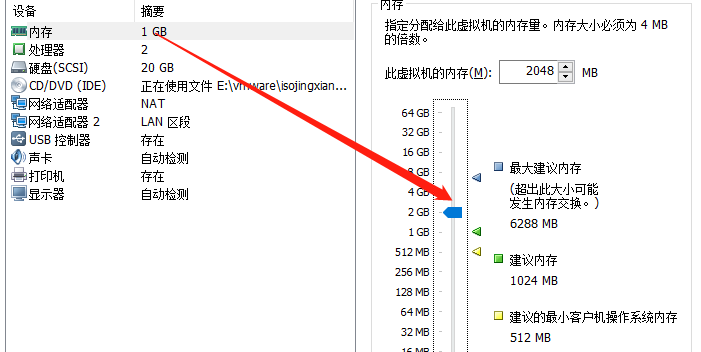
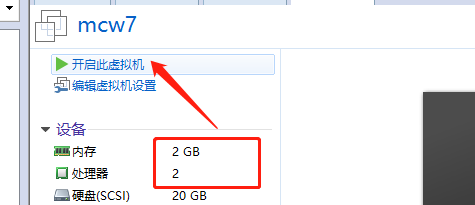
再次執行,卡住一段時間不懂,然後再次報錯:failed to pull image k8s.gcr.io/kube-apiserver:v1.23.1
這是因為k8s.gcr.io是國外網站,
這是因為k8s.gcr.io是國外網站, [root@mcw7 ~]$ kubeadm init --apiserver-advertise-address 10.0.0.137 --pod-network-cidr=10.244.0.0/24 [init] Using Kubernetes version: v1.23.1 [preflight] Running pre-flight checks [WARNING Service-Docker]: docker service is not enabled, please run 'systemctl enable docker.service' [WARNING Swap]: swap is enabled; production deployments should disable swap unless testing the NodeSwap feature gate of the kubelet [WARNING Hostname]: hostname "mcw7" could not be reached [WARNING Hostname]: hostname "mcw7": lookup mcw7 on 10.0.0.2:53: no such host [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR ImagePull]: failed to pull image k8s.gcr.io/kube-apiserver:v1.23.1: output: Error response from daemon: Get "//k8s.gcr.io/v2/": dial tcp 142.250.157.82:443: connect: connection timed out , error: exit status 1 ........ [ERROR ImagePull]: failed to pull image k8s.gcr.io/coredns/coredns:v1.8.6: output: Error response from daemon: Get "//k8s.gcr.io/v2/": dial tcp 74.125.204.82:443: connect: connection timed out , error: exit status 1 [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...` To see the stack trace of this error execute with --v=5 or higher
上面問題解決方法:
下載鏡像,使用國內鏡像,比如阿里雲鏡像
kubeadm init --image-repository=registry.aliyuncs.com/google_containers --pod-network-cidr=10.244.0.0/16 --kubernetes-version=v1.18.5 kubeadm init --apiserver-advertise-address 10.0.0.137 --pod-network-cidr=10.244.0.0/24 --image-repository=registry.aliyuncs.com/google_containers
結果還是不行
[root@mcw7 ~]$ kubeadm init --apiserver-advertise-address 10.0.0.137 --pod-network-cidr=10.244.0.0/24 --image-repository=registry.aliyuncs.com/google_containers [init] Using Kubernetes version: v1.23.1 [preflight] Running pre-flight checks [WARNING Service-Docker]: docker service is not enabled, please run 'systemctl enable docker.service' [WARNING Swap]: swap is enabled; production deployments should disable swap unless testing the NodeSwap feature gate of the kubelet [WARNING Hostname]: hostname "mcw7" could not be reached [WARNING Hostname]: hostname "mcw7": lookup mcw7 on 10.0.0.2:53: no such host [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local mcw7] and IPs [10.96.0.1 10.0.0.137] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [localhost mcw7] and IPs [10.0.0.137 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [localhost mcw7] and IPs [10.0.0.137 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "kubelet.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Starting the kubelet [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [kubelet-check] Initial timeout of 40s passed. [kubelet-check] It seems like the kubelet isn't running or healthy. [kubelet-check] The HTTP call equal to 'curl -sSL //localhost:10248/healthz' failed with error: Get "//localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused. [kubelet-check] It seems like the kubelet isn't running or healthy. [kubelet-check] The HTTP call equal to 'curl -sSL //localhost:10248/healthz' failed with error: Get "//localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused. [kubelet-check] It seems like the kubelet isn't running or healthy. [kubelet-check] The HTTP call equal to 'curl -sSL //localhost:10248/healthz' failed with error: Get "//localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused. [kubelet-check] It seems like the kubelet isn't running or healthy. [kubelet-check] The HTTP call equal to 'curl -sSL //localhost:10248/healthz' failed with error: Get "//localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused. [kubelet-check] It seems like the kubelet isn't running or healthy. [kubelet-check] The HTTP call equal to 'curl -sSL //localhost:10248/healthz' failed with error: Get "//localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused. Unfortunately, an error has occurred: timed out waiting for the condition This error is likely caused by: - The kubelet is not running - The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled) If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands: - 'systemctl status kubelet' - 'journalctl -xeu kubelet' Additionally, a control plane component may have crashed or exited when started by the container runtime. To troubleshoot, list all containers using your preferred container runtimes CLI. Here is one example how you may list all Kubernetes containers running in docker: - 'docker ps -a | grep kube | grep -v pause' Once you have found the failing container, you can inspect its logs with: - 'docker logs CONTAINERID' error execution phase wait-control-plane: couldn't initialize a Kubernetes cluster To see the stack trace of this error execute with --v=5 or higher
從DockerHub的其它倉庫拉取
如何手動下載需要的鏡像://blog.csdn.net/weixin_43168190/article/details/107227626 獲取需要的docker鏡像名稱 [root@mcw7 ~]$ kubeadm config images list k8s.gcr.io/kube-apiserver:v1.23.1 k8s.gcr.io/kube-controller-manager:v1.23.1 k8s.gcr.io/kube-scheduler:v1.23.1 k8s.gcr.io/kube-proxy:v1.23.1 k8s.gcr.io/pause:3.6 k8s.gcr.io/etcd:3.5.1-0 k8s.gcr.io/coredns/coredns:v1.8.6
[root@mcw7 ~]$ kubeadm reset [reset] Reading configuration from the cluster... [reset] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' W0103 19:18:50.468316 14754 reset.go:101] [reset] Unable to fetch the kubeadm-config ConfigMap from cluster: failed to get config map: Get "//10.0.0.137:6443/api/v1/namespaces/kube-system/configmaps/kubeadm-config?timeout=10s": dial tcp 10.0.0.137:6443: connect: connection refused [reset] WARNING: Changes made to this host by 'kubeadm init' or 'kubeadm join' will be reverted. [reset] Are you sure you want to proceed? [y/N]: y [preflight] Running pre-flight checks W0103 19:18:55.832129 14754 removeetcdmember.go:80] [reset] No kubeadm config, using etcd pod spec to get data directory [reset] Stopping the kubelet service [reset] Unmounting mounted directories in "/var/lib/kubelet" [reset] Deleting contents of config directories: [/etc/kubernetes/manifests /etc/kubernetes/pki] [reset] Deleting files: [/etc/kubernetes/admin.conf /etc/kubernetes/kubelet.conf /etc/kubernetes/bootstrap-kubelet.conf /etc/kubernetes/controller-manager.conf /etc/kubernetes/scheduler.conf] [reset] Deleting contents of stateful directories: [/var/lib/etcd /var/lib/kubelet /var/lib/dockershim /var/run/kubernetes /var/lib/cni] The reset process does not clean CNI configuration. To do so, you must remove /etc/cni/net.d The reset process does not reset or clean up iptables rules or IPVS tables. If you wish to reset iptables, you must do so manually by using the "iptables" command. If your cluster was setup to utilize IPVS, run ipvsadm --clear (or similar) to reset your system's IPVS tables. The reset process does not clean your kubeconfig files and you must remove them manually. Please, check the contents of the $HOME/.kube/config file.
又一個問題:查看失敗系統日誌
命令輸出日誌: It seems like the kubelet isn’t running or healthy. The HTTP call equal to ‘curl -sSL //localhost:10248/healthz’ failed with error: Get “//localhost:10248/healthz”: dial tcp [::1]:10248: connect: connection refused.
系統日誌報錯:unning with swap on is not supported, please disable swap! or set --fail-swap-on flag to false. [root@mcw7 ~]$ tail -100 /var/log/messages ...... Jan 3 19:26:00 mcw7 kubelet: I0103 19:26:00.904313 16215 server.go:693] "--cgroups-per-qos enabled, but --cgroup-root was not specified. defaulting to /" Jan 3 19:26:00 mcw7 kubelet: E0103 19:26:00.904525 16215 server.go:302] "Failed to run kubelet" err="failed to run Kubelet: running with swap on is not supported, please disable swap! or set --fail-swap-on flag to false. /proc/swaps contained: [Filename\t\t\t\tType\t\tSize\tUsed\tPriority /dev/sda2 partition\t793596\t0\t-1]" Jan 3 19:26:00 mcw7 systemd: kubelet.service: main process exited, code=exited, status=1/FAILURE Jan 3 19:26:00 mcw7 systemd: Unit kubelet.service entered failed state. Jan 3 19:26:00 mcw7 systemd: kubelet.service failed.
解決方案:
1. 關掉swapoff
swapoff -a
2. 注釋掉配置
vi /etc/fstab
注釋掉最後一行swap的
#UUID=6042e061-f29b-4ac1-9f32-87980ddf0e1f swap swap defaults 0 0
3、重啟虛擬機,我這裡是虛擬機,如果是生產或其它,可要想好了
reboot now
我這裡關閉swap了,暫時不改配置重啟 [root@mcw7 ~]$ free -m total used free shared buff/cache available Mem: 1823 192 202 8 1427 1412 Swap: 774 0 774 [root@mcw7 ~]$ swapoff -a [root@mcw7 ~]$ free -m total used free shared buff/cache available Mem: 1823 193 203 8 1426 1412 Swap: 0 0 0
重試初始化
[root@mcw7 ~]$ kubeadm init --apiserver-advertise-address 10.0.0.137 --pod-network-cidr=10.244.0.0/24 --image-repository=registry.aliyuncs.com/google_containers [init] Using Kubernetes version: v1.23.1 [preflight] Running pre-flight checks [WARNING Service-Docker]: docker service is not enabled, please run 'systemctl enable docker.service' [WARNING Hostname]: hostname "mcw7" could not be reached [WARNING Hostname]: hostname "mcw7": lookup mcw7 on 10.0.0.2:53: no such host error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists [ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists [ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists [ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...` To see the stack trace of this error execute with --v=5 or higher [root@mcw7 ~]$ kubeadm reset [root@mcw7 ~]$ ls /etc/kubernetes #每次初始化都會生成 /etc/kubernetes目錄及下面的文件,刪除然後重新初始化 manifests pki [root@mcw7 ~]$ rm -rf /etc/kubernetes
重新初始化後還是同樣的報錯
kubeadm reset rm -rf /etc/kubernetes [root@mcw7 ~]$ kubeadm init --apiserver-advertise-address 10.0.0.137 --pod-network-cidr=10.244.0.0/24 --image-repository=registry.aliyuncs.com/google_containers ....... [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [kubelet-check] Initial timeout of 40s passed. [kubelet-check] It seems like the kubelet isn't running or healthy. [kubelet-check] The HTTP call equal to 'curl -sSL //localhost:10248/healthz' failed with error: Get "//localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused.
查看系統日誌報錯:failed to run Kubelet: misconfiguration: kubelet cgroup driver: \”systemd\” is different from docker cgroup driver: \”cgroupfs\””
無法運行Kubelet:配置錯誤:Kubelet cgroup驅動程序:\「systemd\」與docker cgroup驅動程序:\「cgroupfs\」不同
[root@mcw7 ~]$ tail -100 /var/log/messages #查看系統日誌 ...... Jan 3 19:57:01 mcw7 kubelet: E0103 19:57:01.212358 25354 server.go:302] "Failed to run kubelet" err="failed to run Kubelet: misconfiguration: kubelet cgroup driver: \"systemd\" is different from docker cgroup driver: \"cgroupfs\"" Jan 3 19:57:01 mcw7 systemd: kubelet.service: main process exited, code=exited, status=1/FAILURE Jan 3 19:57:01 mcw7 systemd: Unit kubelet.service entered failed state. Jan 3 19:57:01 mcw7 systemd: kubelet.service failed.
上述日誌表明:kubelet的cgroup driver是cgroupfs,docker的 cgroup driver是systemd,兩者不一致導致初始化失敗 解決方案: 1、嘗試過修改kubelet的cgroup dirver(文件位置:/etc/systemd/system/kubelet.service.d/10-kubeadm.conf),但是每次啟動minikube時會被覆蓋掉,於是只能放棄這種處理方式,轉去修改docker的cgroup dirver設置; 2、打開文件/usr/lib/systemd/system/docker.service,如下圖,將紅框中的systemd改為cgroupfs: 也就是啟動文件的ExecStart配置項,修改 參數 --exec-opt native.cgroupdirver=systemd \ 為 --exec-opt native.cgroupdirver=cgroupfs \ \是換行符 docker 不再設置native.cgroupdriver=systemd,或將 systemd 改成 cgroupfs,重啟docker systemctl daemon-reload && systemctl restart docker 檢查 docker info|grep "Cgroup Driver" 是否輸出 Cgroup Driver: cgroupfs 3、 重置未初始化成功的kubeadm配置 echo y|kubeadm reset 修改docker,只需在/etc/docker/daemon.json中,添加"exec-opts": ["native.cgroupdriver=systemd"]即可,本文最初的docker配置可供參考。
修改kubelet:
cat > /var/lib/kubelet/config.yaml <<EOF apiVersion: kubelet.config.k8s.io/v1beta1 kind: KubeletConfiguration cgroupDriver: systemd EOF 重啟docker 與 kubelet: systemctl daemon-reload systemctl restart docker systemctl restart kubelet 檢查 docker info|grep "Cgroup Driver" 是否輸出 Cgroup Driver: systemd
這裡選擇方案3
[root@mcw7 ~]$ ls /etc/kubernetes admin.conf controller-manager.conf kubelet.conf manifests pki scheduler.conf [root@mcw7 ~]$ echo y|kubeadm reset #使用這種方法應該是跳過詢問階段,下次試試其它的是不是也可以這樣 [root@mcw7 ~]$ ls /etc/kubernetes #重設之後,配置刪除了,留下兩個目錄 manifests pki
參考查看別人的daemon配置
安裝 docker 並配置 (kubernetes官方推薦docker等使用systemd作為cgroupdriver)
mkdir /etc/docker cat > /etc/docker/daemon.json <<EOF { "exec-opts": ["native.cgroupdriver=systemd"], "log-driver": "json-file", "log-opts": { "max-size": "100m" }, "storage-driver": "overlay2", "storage-opts": [ "overlay2.override_kernel_check=true" ], "data-root": "/data/docker" } EOF
我給它這樣配置,加個鏡像加速的試試。
其實是可以的,後面有過程,這裡不能放在同一個花括號,是因為字典內的分隔符逗號是個中文
cat > /etc/docker/daemon.json <<EOF { "registry-mirrors":["//reg-mirror.qiniu.com/","//docker.mirrors.ustc.edu.cn/","//hub-mirror.c.163.com/"], "exec-opts": ["native.cgroupdriver=cgroupfs"] } EOF [root@mcw7 ~]$ ls /etc/docker/ key.json [root@mcw7 ~]$ cat > /etc/docker/daemon.json <<EOF > { > "registry-mirrors":["//reg-mirror.qiniu.com/","//docker.mirrors.ustc.edu.cn/","//hub-mirror.c.163.com/"], > "exec-opts": ["native.cgroupdriver=cgroupfs"] > } > EOF [root@mcw7 ~]$ cat /etc/docker/daemon.json { "registry-mirrors":["//reg-mirror.qiniu.com/","//docker.mirrors.ustc.edu.cn/","//hub-mirror.c.163.com/"], "exec-opts": ["native.cgroupdriver=cgroupfs"] } #添加後重啟docker daemon失敗,去掉配置,只留加速的 "exec-opts": ["native.cgroupdriver=cgroupfs"] [root@mcw7 ~]$ cat /etc/docker/daemon.json { "registry-mirrors":["//reg-mirror.qiniu.com/","//docker.mirrors.ustc.edu.cn/","//hub-mirror.c.163.com/"] } [root@mcw7 ~]$ systemctl daemon-reload [root@mcw7 ~]$ systemctl restart docker.service [root@mcw7 ~]$
如下,用兩個花括號可以生效,放一個裏面好像不行。用兩個花括號是否是正確的做法,有啥問題,以後再驗證
[root@mcw7 ~]$ systemctl daemon-reload [root@mcw7 ~]$ cat /etc/docker/daemon.json { "registry-mirrors":["//reg-mirror.qiniu.com/","//docker.mirrors.ustc.edu.cn/","//hub-mirror.c.163.com/"] } {"exec-opts": ["native.cgroupdriver=cgroupfs"]} [root@mcw7 ~]$ systemctl daemon-reload [root@mcw7 ~]$ systemctl restart docker.service [root@mcw7 ~]$ docker info|grep "Cgroup Driver" Cgroup Driver: cgroupfs [root@mcw7 ~]$
重設重初始化試試
[root@mcw7 ~]$ kubeadm reset
[root@mcw7 ~]$ kubeadm init –apiserver-advertise-address 10.0.0.137 –pod-network-cidr=10.244.0.0/24 –image-repository=registry.aliyuncs.com/google_containers
還是報錯,貌似我上面配置錯了
配置錯誤:kubelet cgroup驅動程序「 systemd」與docker cgroup驅動程序「 cgroupfs」 不相同,
我先把docker的cgroupfs改成systemd 吧
貌似修改沒 成功
root@mcw7 ~]$ vim /etc/docker/daemon.json [root@mcw7 ~]$ cat /etc/docker/daemon.json { "registry-mirrors":["//reg-mirror.qiniu.com/","//docker.mirrors.ustc.edu.cn/","//hub-mirror.c.163.com/"] } {"exec-opts": ["native.cgroupdriver=systemd"]} [root@mcw7 ~]$ systemctl daemon-reload [root@mcw7 ~]$ systemctl restart docker.service [root@mcw7 ~]$ docker info |grep "Cgroup Driver" Cgroup Driver: cgroupfs 如下修改就生效了,只有這一行 [root@mcw7 ~]$ vim /etc/docker/daemon.json [root@mcw7 ~]$ cat /etc/docker/daemon.json {"exec-opts": ["native.cgroupdriver=systemd"]} [root@mcw7 ~]$ systemctl daemon-reload [root@mcw7 ~]$ systemctl restart docker.service [root@mcw7 ~]$ docker info |grep "Cgroup Driver" Cgroup Driver: systemd [root@mcw7 ~]$
看如下配置,之前不能放在同一個花括號,是因為字典內的分隔符逗號是個中文
[root@mcw7 ~]$ vim /etc/docker/daemon.json [root@mcw7 ~]$ cat /etc/docker/daemon.json { "registry-mirrors":["//reg-mirror.qiniu.com/","//docker.mirrors.ustc.edu.cn/","//hub-mirror.c.163.com/"], "exec-opts": ["native.cgroupdriver=systemd"] } [root@mcw7 ~]$ systemctl daemon-reload [root@mcw7 ~]$ systemctl restart docker.service [root@mcw7 ~]$ docker info |grep "Cgroup Driver" Cgroup Driver: systemd [root@mcw7 ~]$
重設重初始化試試,後面顯示我的Kubernetes初始化成功
[root@mcw7 ~]$ echo y|kubeadm reset [root@mcw7 ~]$ kubeadm init --apiserver-advertise-address 10.0.0.137 --pod-network-cidr=10.244.0.0/24 --image-repository=registry.aliyuncs.com/google_containers [init] Using Kubernetes version: v1.23.1 [preflight] Running pre-flight checks #初始化前的檢查 [WARNING Service-Docker]: docker service is not enabled, please run 'systemctl enable docker.service' [WARNING Hostname]: hostname "mcw7" could not be reached [WARNING Hostname]: hostname "mcw7": lookup mcw7 on 10.0.0.2:53: no such host [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key #生成token和證書 [certs] apiserver serving cert is signed for DNS names [kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local mcw7] and IPs [10.96.0.1 10.0.0.137] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [localhost mcw7] and IPs [10.0.0.137 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [localhost mcw7] and IPs [10.0.0.137 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "kubelet.conf" kubeconfig file #生成kubeconfig文件,bubelet用這個文件與master通信 [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Starting the kubelet [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for "kube-apiserver" [control-plane] Creating static Pod manifest for "kube-controller-manager" [control-plane] Creating static Pod manifest for "kube-scheduler" [etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests" [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [apiclient] All control plane components are healthy after 11.505693 seconds [upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config-1.23" in namespace kube-system with the configuration for the kubelets in the cluster NOTE: The "kubelet-config-1.23" naming of the kubelet ConfigMap is deprecated. Once the UnversionedKubeletConfigMap feature gate graduates to Beta the default name will become just "kubelet-config". Kubeadm upgrade will handle this transition transparently. [upload-certs] Skipping phase. Please see --upload-certs [mark-control-plane] Marking the node mcw7 as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers] [mark-control-plane] Marking the node mcw7 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule] [bootstrap-token] Using token: 7fmuqu.hbr7n14o7kpbx8iw [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace [kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key [addons] Applied essential addon: CoreDNS 安裝附加組件 kube-proxy 和coredns [addons] Applied essential addon: kube-proxy Your Kubernetes control-plane has initialized successfully! #初始化成功 To start using your cluster, you need to run the following as a regular user: #提示如何配置kubectl mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 10.0.0.137:6443 --token 7fmuqu.hbr7n14o7kpbx8iw \ --discovery-token-ca-cert-hash sha256:9794706d7eadeecbc14ba8372fab500d90c624748c2c45ae212d0f32889e4071 [root@mcw7 ~]$ #提示如何註冊其它節點到集群
但是在系統日誌中還是有報錯信息的
[root@mcw7 ~]$ tail -100f /var/log/messages Jan 3 20:59:23 mcw7 kubelet: I0103 20:59:23.623761 41877 cni.go:240] "Unable to update cni config" err="no networks found in /etc/cni/net.d" Jan 3 20:59:25 mcw7 kubelet: E0103 20:59:25.779159 41877 kubelet.go:2347] "Container runtime network not ready" networkReady="NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized"
初始化master後查看容器
[root@mcw7 ~]$ docker ps |awk '{print $3,"\t",$NF}' IMAGE NAMES "/usr/local/bin/kube…" k8s_kube-proxy_kube-proxy-c5zmm_kube-system_5897b315-6a17-4d8b-82c6-7712ade54560_0 "/pause" k8s_POD_kube-proxy-c5zmm_kube-system_5897b315-6a17-4d8b-82c6-7712ade54560_0 "kube-scheduler k8s_kube-scheduler_kube-scheduler-mcw7_kube-system_5a3a66c7da6759d92afea91cd2972f6e_2 "kube-apiserver k8s_kube-apiserver_kube-apiserver-mcw7_kube-system_fc840a9b537be965fe104fc9cbddd14f_2 "kube-controller-man…" k8s_kube-controller-manager_kube-controller-manager-mcw7_kube-system_3e1d477612039be74973ec7803946c3a_3 "etcd k8s_etcd_etcd-mcw7_kube-system_93c9b21b665d4c633156ae2d5739fb33_3 "/pause" k8s_POD_kube-scheduler-mcw7_kube-system_5a3a66c7da6759d92afea91cd2972f6e_0 "/pause" k8s_POD_kube-controller-manager-mcw7_kube-system_3e1d477612039be74973ec7803946c3a_0 "/pause" k8s_POD_kube-apiserver-mcw7_kube-system_fc840a9b537be965fe104fc9cbddd14f_0 "/pause" k8s_POD_etcd-mcw7_kube-system_93c9b21b665d4c633156ae2d5739fb33_0 [root@mcw7 ~]$
初始化master後查看所有命名空間(貌似很多服務名稱都拼接了主機名了)所有Pod情況
[machangwei@mcw7 ~]$ kubectl get pod --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-6d8c4cb4d-2296m 1/1 Running 1 (27m ago) 4h18m kube-system coredns-6d8c4cb4d-lphb2 1/1 Running 1 (27m ago) 4h18m kube-system etcd-mcw7 1/1 Running 3 4h18m kube-system kube-apiserver-mcw7 1/1 Running 2 4h18m kube-system kube-controller-manager-mcw7 1/1 Running 4 (27m ago) 4h18m kube-system kube-flannel-ds-8gzfq 1/1 Running 0 32m kube-system kube-proxy-c5zmm 1/1 Running 0 4h18m kube-system kube-scheduler-mcw7 1/1 Running 3 (27m ago) 4h18m [machangwei@mcw7 ~]$
使用普通用戶配置kubectl
我這裏是在master操作的
su - machanwei mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config
安裝Pod網絡
還在普通用戶下,執行命令部署flannel網絡方案
[machangwei@mcw7 ~]$ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+ podsecuritypolicy.policy/psp.flannel.unprivileged created clusterrole.rbac.authorization.k8s.io/flannel created clusterrolebinding.rbac.authorization.k8s.io/flannel created serviceaccount/flannel created configmap/kube-flannel-cfg created daemonset.apps/kube-flannel-ds created [machangwei@mcw7 ~]$
kube-flannel.yml內容


--- apiVersion: policy/v1beta1 kind: PodSecurityPolicy metadata: name: psp.flannel.unprivileged annotations: seccomp.security.alpha.kubernetes.io/allowedProfileNames: docker/default seccomp.security.alpha.kubernetes.io/defaultProfileName: docker/default apparmor.security.beta.kubernetes.io/allowedProfileNames: runtime/default apparmor.security.beta.kubernetes.io/defaultProfileName: runtime/default spec: privileged: false volumes: - configMap - secret - emptyDir - hostPath allowedHostPaths: - pathPrefix: "/etc/cni/net.d" - pathPrefix: "/etc/kube-flannel" - pathPrefix: "/run/flannel" readOnlyRootFilesystem: false # Users and groups runAsUser: rule: RunAsAny supplementalGroups: rule: RunAsAny fsGroup: rule: RunAsAny # Privilege Escalation allowPrivilegeEscalation: false defaultAllowPrivilegeEscalation: false # Capabilities allowedCapabilities: ['NET_ADMIN', 'NET_RAW'] defaultAddCapabilities: [] requiredDropCapabilities: [] # Host namespaces hostPID: false hostIPC: false hostNetwork: true hostPorts: - min: 0 max: 65535 # SELinux seLinux: # SELinux is unused in CaaSP rule: 'RunAsAny' --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: flannel rules: - apiGroups: ['extensions'] resources: ['podsecuritypolicies'] verbs: ['use'] resourceNames: ['psp.flannel.unprivileged'] - apiGroups: - "" resources: - pods verbs: - get - apiGroups: - "" resources: - nodes verbs: - list - watch - apiGroups: - "" resources: - nodes/status verbs: - patch --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: flannel roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: flannel subjects: - kind: ServiceAccount name: flannel namespace: kube-system --- apiVersion: v1 kind: ServiceAccount metadata: name: flannel namespace: kube-system --- kind: ConfigMap apiVersion: v1 metadata: name: kube-flannel-cfg namespace: kube-system labels: tier: node app: flannel data: cni-conf.json: | { "name": "cbr0", "cniVersion": "0.3.1", "plugins": [ { "type": "flannel", "delegate": { "hairpinMode": true, "isDefaultGateway": true } }, { "type": "portmap", "capabilities": { "portMappings": true } } ] } net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan" } } --- apiVersion: apps/v1 kind: DaemonSet metadata: name: kube-flannel-ds namespace: kube-system labels: tier: node app: flannel spec: selector: matchLabels: app: flannel template: metadata: labels: tier: node app: flannel spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/os operator: In values: - linux hostNetwork: true priorityClassName: system-node-critical tolerations: - operator: Exists effect: NoSchedule serviceAccountName: flannel initContainers: - name: install-cni-plugin image: rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.0 command: - cp args: - -f - /flannel - /opt/cni/bin/flannel volumeMounts: - name: cni-plugin mountPath: /opt/cni/bin - name: install-cni image: quay.io/coreos/flannel:v0.15.1 command: - cp args: - -f - /etc/kube-flannel/cni-conf.json - /etc/cni/net.d/10-flannel.conflist volumeMounts: - name: cni mountPath: /etc/cni/net.d - name: flannel-cfg mountPath: /etc/kube-flannel/ containers: - name: kube-flannel image: quay.io/coreos/flannel:v0.15.1 command: - /opt/bin/flanneld args: - --ip-masq - --kube-subnet-mgr resources: requests: cpu: "100m" memory: "50Mi" limits: cpu: "100m" memory: "50Mi" securityContext: privileged: false capabilities: add: ["NET_ADMIN", "NET_RAW"] env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace volumeMounts: - name: run mountPath: /run/flannel - name: flannel-cfg mountPath: /etc/kube-flannel/ volumes: - name: run hostPath: path: /run/flannel - name: cni-plugin hostPath: path: /opt/cni/bin - name: cni hostPath: path: /etc/cni/net.d - name: flannel-cfg configMap: name: kube-flannel-cfg
kube-flannel.yml
添加k8s-node1和k8s-node2
添加
主機名 節點類型 ip
mcw7 master 10.0.0.137
mcw8 k8s-node1 10.0.0.138
mcw9 k8s-node2 10.0.0.139
添加節點,是執行如下命令,這個命令是初始化master時命令行生成的。
kubeadm join 10.0.0.137:6443 –token 7fmuqu.hbr7n14o7kpbx8iw
kubeadm join –token 7fmuqu.hbr7n14o7kpbx8iw 10.0.0.137:6443 #或者,都一樣的
#這個是初始化生成的信息,應該是要下面這個完整的,不然報錯,上面那個的不行
kubeadm join 10.0.0.137:6443 –token 7fmuqu.hbr7n14o7kpbx8iw \
–discovery-token-ca-cert-hash sha256:9794706d7eadeecbc14ba8372fab500d90c624748c2c45ae212d0f32889e4071
如果沒有記下來,master上執行如下命令查看需要的信息,需要的只是TOKEN,ip端口就是master上的信息
[root@mcw7 ~]$ kubeadm token list TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS 7fmuqu.hbr7n14o7kpbx8iw 20h 2022-01-04T12:54:48Z authentication,signing The default bootstrap token generated by 'kubeadm init'. system:bootstrappers:kubeadm:default-node-token 查看6443端口是什麼?這裡查看是kube-apiserver服務,也就是添加節點,是要跟這個服務進行通信 [root@mcw7 ~]$ ss -lntup|grep 6443 tcp LISTEN 0 16384 :::6443 :::* users:(("kube-apiserver",pid=41659,fd=7)) 執行報錯; mcw8上將執行命令,沒添加節點成功 [root@mcw8 ~]$ kubeadm join 10.0.0.137:6443 --token 7fmuqu.hbr7n14o7kpbx8iw discovery.bootstrapToken: Invalid value: "": using token-based discovery without caCertHashes can be unsafe. Set unsafeSkipCAVerification as true in your kubeadm config file or pass --discovery-token-unsafe-skip-ca-verification flag to continue To see the stack trace of this error execute with --v=5 or higher mcw7上普通用戶查看節點情況,只有mcw7的 [machangwei@mcw7 ~]$ kubectl get nodes NAME STATUS ROLES AGE VERSION mcw7 Ready control-plane,master 4h4m v1.23.1 再次在mcw8上執行添加,這次使用初始化生成的兩行,完整的帶有--discovery-token-ca-cert-hash的 [root@mcw8 ~]$ kubeadm join 10.0.0.137:6443 --token 7fmuqu.hbr7n14o7kpbx8iw \ > --discovery-token-ca-cert-hash sha256:9794706d7eadeecbc14ba8372fab500d90c624748c2c45ae212d0f32889e4071 [preflight] Running pre-flight checks Server: ERROR: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running? errors pretty printing info , error: exit status 1 [ERROR Service-Docker]: docker service is not active, please run 'systemctl start docker.service' [ERROR FileContent--proc-sys-net-bridge-bridge-nf-call-iptables]: /proc/sys/net/bridge/bridge-nf-call-iptables does not exist [ERROR FileContent--proc-sys-net-ipv4-ip_forward]: /proc/sys/net/ipv4/ip_forward contents are not set to 1 [ERROR SystemVerification]: error verifying Docker info: "Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?" [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...` To see the stack trace of this error execute with --v=5 or higher 由上面的錯誤信息可知,docker daemon部署好後就沒起,我啟動一下;ipv4轉發沒有開啟 [root@mcw8 ~]$ systemctl start docker.service [root@mcw8 ~]$ vim /etc/sysctl.conf [root@mcw8 ~]$ sysctl -p [root@mcw8 ~]$ tail -1 /etc/sysctl.conf net.ipv4.ip_forward = 1 然後再試一下: [root@mcw8 ~]$ kubeadm join 10.0.0.137:6443 --token 7fmuqu.hbr7n14o7kpbx8iw --discovery-token-ca-cert-hash sha256:9794706d7eadeecbc14ba8372fab500d90c624748c2c45ae212d0f32889e4071 [preflight] Running pre-flight checks [kubelet-check] It seems like the kubelet isn't running or healthy. [kubelet-check] The HTTP call equal to 'curl -sSL //localhost:10248/healthz' failed with error: Get "//localhost:10248/healthz": dial tcp [::1]:10248: connect: connection refused. 查看系統日誌信息,又報錯了 [root@mcw8 ~]$ tail -100 /var/log/messages Jan 4 01:21:11 mcw8 kubelet: I0104 01:21:11.454777 21848 server.go:693] "--cgroups-per-qos enabled, but --cgroup-root was not specified. defaulting to /" Jan 4 01:21:11 mcw8 kubelet: E0104 01:21:11.455004 21848 server.go:302] "Failed to run kubelet" err="failed to run Kubelet: running with swap on is not supported, please disable swap! or set --fail-swap-on flag to false. /proc/swaps contained: [Filename\t\t\t\tType\t\tSize\tUsed\tPriority /dev/sda2 partition\t793596\t172\t-1]" 在mcw8上執行如下操作 cat > /etc/docker/daemon.json <<EOF { "registry-mirrors":["//reg-mirror.qiniu.com/","//docker.mirrors.ustc.edu.cn/","//hub-mirror.c.163.com/"], "exec-opts": ["native.cgroupdriver=systemd"] } EOF [root@mcw8 ~]$ swapoff -a [root@mcw8 ~]$ cat > /etc/docker/daemon.json <<EOF > { > "registry-mirrors":["//reg-mirror.qiniu.com/","//docker.mirrors.ustc.edu.cn/","//hub-mirror.c.163.com/"], > "exec-opts": ["native.cgroupdriver=systemd"] > } > EOF [root@mcw8 ~]$ systemctl daemon-reload [root@mcw8 ~]$ systemctl restart docker.service 然後再次添加報錯: [root@mcw8 ~]$ kubeadm join 10.0.0.137:6443 --token 7fmuqu.hbr7n14o7kpbx8iw --discovery-token-ca-cert-hash sha256:9794706d7eadeecbc14ba8372fab500d90c624748c2c45ae212d0f32889e4071 [preflight] Running pre-flight checks [WARNING Service-Docker]: docker service is not enabled, please run 'systemctl enable docker.service' [WARNING Hostname]: hostname "mcw8" could not be reached [WARNING Hostname]: hostname "mcw8": lookup mcw8 on 10.0.0.2:53: no such host error execution phase preflight: [preflight] Some fatal errors occurred: [ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists [ERROR Port-10250]: Port 10250 is in use [ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...` To see the stack trace of this error execute with --v=5 or higher 再次執行重設。再添加進集群,成功添加 [root@mcw8 ~]$ echo y|kubeadm reset [root@mcw8 ~]$ kubeadm join 10.0.0.137:6443 --token 7fmuqu.hbr7n14o7kpbx8iw --discovery-token-ca-cert-hash sha256:9794706d7eadeecbc14ba8372fab500d90c624748c2c45ae212d0f32889e4071 [preflight] Running pre-flight checks [WARNING Service-Docker]: docker service is not enabled, please run 'systemctl enable docker.service' [WARNING Hostname]: hostname "mcw8" could not be reached [WARNING Hostname]: hostname "mcw8": lookup mcw8 on 10.0.0.2:53: no such host [preflight] Reading configuration from the cluster... [preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -o yaml' [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Starting the kubelet [kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap... This node has joined the cluster: * Certificate signing request was sent to apiserver and a response was received. * The Kubelet was informed of the new secure connection details. Run 'kubectl get nodes' on the control-plane to see this node join the cluster. [root@mcw8 ~]$ 在mcw7這個主節點上查看到mcw8這個節點,已經加進來了,但是未準備好的 [machangwei@mcw7 ~]$ kubectl get nodes NAME STATUS ROLES AGE VERSION mcw7 Ready control-plane,master 4h55m v1.23.1 mcw8 NotReady <none> 3m11s v1.23.1 在mcw9上做同樣操作,這個節點也加入集群了 [machangwei@mcw7 ~]$ kubectl get nodes NAME STATUS ROLES AGE VERSION mcw7 Ready control-plane,master 5h52m v1.23.1 mcw8 Ready <none> 60m v1.23.1 mcw9 Ready <none> 22m v1.23.1 [machangwei@mcw7 ~]$ 查看mcw9這個節點所有容器。有三個退出的容器 [root@mcw9 ~]$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 2d7b99847855 e6ea68648f0c "/opt/bin/flanneld -…" 5 minutes ago Exited (1) 5 minutes ago k8s_kube-flannel_kube-flannel-ds-s4qmj_kube-system_a8082592-8c92-4c48-98dc-c6b52ebb9498_16 a97be18082b7 quay.io/coreos/flannel "cp -f /etc/kube-fla…" About an hour ago Exited (0) About an hour ago k8s_install-cni_kube-flannel-ds-s4qmj_kube-system_a8082592-8c92-4c48-98dc-c6b52ebb9498_0 881e2618fa9d registry.aliyuncs.com/google_containers/kube-proxy "/usr/local/bin/kube…" About an hour ago Up About an hour k8s_kube-proxy_kube-proxy-npmtv_kube-system_7f6b0d03-0d35-48ae-b091-5f1e0618ba85_0 0503318f5d3c rancher/mirrored-flannelcni-flannel-cni-plugin "cp -f /flannel /opt…" About an hour ago Exited (0) About an hour ago k8s_install-cni-plugin_kube-flannel-ds-s4qmj_kube-system_a8082592-8c92-4c48-98dc-c6b52ebb9498_0 75e85cb833df registry.aliyuncs.com/google_containers/pause:3.6 "/pause" About an hour ago Up About an hour k8s_POD_kube-proxy-npmtv_kube-system_7f6b0d03-0d35-48ae-b091-5f1e0618ba85_0 625efe596472 registry.aliyuncs.com/google_containers/pause:3.6 "/pause" About an hour ago Up About an hour k8s_POD_kube-flannel-ds-s4qmj_kube-system_a8082592-8c92-4c48-98dc-c6b52ebb9498_0 [root@mcw9 ~]$
查看所有的Pod的狀態以及Pod詳情等等
名字帶有kube-flannel-ds的,應該是三個k8s節點,根據時間上來猜測,Running 的應該是mcw7主節點,
Error 的 是之前加進去的mcw8節點,CrashLoopBackOff是最後加進去的mcw9節點
[machangwei@mcw7 ~]$ kubectl get pod --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-6d8c4cb4d-2296m 1/1 Running 1 (122m ago) 5h53m kube-system coredns-6d8c4cb4d-lphb2 1/1 Running 1 (122m ago) 5h53m kube-system etcd-mcw7 1/1 Running 3 5h53m kube-system kube-apiserver-mcw7 1/1 Running 2 5h53m kube-system kube-controller-manager-mcw7 1/1 Running 4 (123m ago) 5h53m kube-system kube-flannel-ds-5pxmj 0/1 Error 16 (5m19s ago) 61m kube-system kube-flannel-ds-8gzfq 1/1 Running 0 128m kube-system kube-flannel-ds-s4qmj 0/1 CrashLoopBackOff 9 (72s ago) 24m kube-system kube-proxy-4lmsx 1/1 Running 0 61m kube-system kube-proxy-c5zmm 1/1 Running 0 5h53m kube-system kube-proxy-npmtv 1/1 Running 0 24m kube-system kube-scheduler-mcw7 1/1 Running 3 (123m ago) 5h53m [machangwei@mcw7 ~]$ 當k8s節點加入集群後,會運行起三個容器,如下:有kube-proxy,POD_kube-flannel-ds,POD_kube-proxy [root@mcw8 ~]$ docker ps |awk '{print $2,"\t",$3,"\t",$NF}' ID IMAGE NAMES registry.aliyuncs.com/google_containers/kube-proxy "/usr/local/bin/kube…" k8s_kube-proxy_kube-proxy-4lmsx_kube-system_fb743f5c-0f44-43a7-ad7e-78817ddafc12_0 registry.aliyuncs.com/google_containers/pause:3.6 "/pause" k8s_POD_kube-flannel-ds-5pxmj_kube-system_0972d5b3-a774-44cc-94b1-6765ec8f4256_0 registry.aliyuncs.com/google_containers/pause:3.6 "/pause" k8s_POD_kube-proxy-4lmsx_kube-system_fb743f5c-0f44-43a7-ad7e-78817ddafc12_0 [root@mcw8 ~]$ 下面查看mcw9這個節點的Pod具體情況 [machangwei@mcw7 ~]$ kubectl describe pod kube-flannel-ds-s4qmj --namespace=kube-system Name: kube-flannel-ds-s4qmj Namespace: kube-system Priority: 2000001000 Priority Class Name: system-node-critical Node: mcw9/10.0.0.139 Start Time: Tue, 04 Jan 2022 02:23:58 +0800 Labels: app=flannel controller-revision-hash=5947899bf6 pod-template-generation=1 tier=node Annotations: <none> Status: Running IP: 10.0.0.139 IPs: IP: 10.0.0.139 Controlled By: DaemonSet/kube-flannel-ds Init Containers: install-cni-plugin: Container ID: docker://0503318f5d3cfddd264f8b9519679ff429f6c23b5cabea4c3a9f3aabf023c716 Image: rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.0 Image ID: docker-pullable://rancher/mirrored-flannelcni-flannel-cni-plugin@sha256:bfe8f30c74bc6f31eba0cc6659e396dbdd5ab171314ed542cc238ae046660ede Port: <none> Host Port: <none> Command: cp Args: -f /flannel /opt/cni/bin/flannel State: Terminated Reason: Completed Exit Code: 0 Started: Tue, 04 Jan 2022 02:24:20 +0800 Finished: Tue, 04 Jan 2022 02:24:20 +0800 Ready: True Restart Count: 0 Environment: <none> Mounts: /opt/cni/bin from cni-plugin (rw) /var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-j5mrk (ro) install-cni: Container ID: docker://a97be18082b79da0effeeaea374a2cd02afc61ec0fb6e03c900ad000656b8179 Image: quay.io/coreos/flannel:v0.15.1 Image ID: docker-pullable://quay.io/coreos/flannel@sha256:9a296fbb67790659adc3701e287adde3c59803b7fcefe354f1fc482840cdb3d9 Port: <none> Host Port: <none> Command: cp Args: -f /etc/kube-flannel/cni-conf.json /etc/cni/net.d/10-flannel.conflist State: Terminated Reason: Completed Exit Code: 0 Started: Tue, 04 Jan 2022 02:25:53 +0800 Finished: Tue, 04 Jan 2022 02:25:53 +0800 Ready: True Restart Count: 0 Environment: <none> Mounts: /etc/cni/net.d from cni (rw) /etc/kube-flannel/ from flannel-cfg (rw) /var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-j5mrk (ro) Containers: kube-flannel: Container ID: docker://0039225dc56bd11b7a6ec41763daa61a85f128f0bf501bdc3dc6d49504da64a1 Image: quay.io/coreos/flannel:v0.15.1 Image ID: docker-pullable://quay.io/coreos/flannel@sha256:9a296fbb67790659adc3701e287adde3c59803b7fcefe354f1fc482840cdb3d9 Port: <none> Host Port: <none> Command: /opt/bin/flanneld Args: --ip-masq --kube-subnet-mgr State: Waiting Reason: CrashLoopBackOff Last State: Terminated Reason: Error Exit Code: 1 Started: Tue, 04 Jan 2022 03:18:15 +0800 Finished: Tue, 04 Jan 2022 03:18:16 +0800 Ready: False Restart Count: 15 Limits: cpu: 100m memory: 50Mi Requests: cpu: 100m memory: 50Mi Environment: POD_NAME: kube-flannel-ds-s4qmj (v1:metadata.name) POD_NAMESPACE: kube-system (v1:metadata.namespace) Mounts: /etc/kube-flannel/ from flannel-cfg (rw) /run/flannel from run (rw) /var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-j5mrk (ro) Conditions: Type Status Initialized True Ready False ContainersReady False PodScheduled True Volumes: run: Type: HostPath (bare host directory volume) Path: /run/flannel HostPathType: cni-plugin: Type: HostPath (bare host directory volume) Path: /opt/cni/bin HostPathType: cni: Type: HostPath (bare host directory volume) Path: /etc/cni/net.d HostPathType: flannel-cfg: Type: ConfigMap (a volume populated by a ConfigMap) Name: kube-flannel-cfg Optional: false kube-api-access-j5mrk: Type: Projected (a volume that contains injected data from multiple sources) TokenExpirationSeconds: 3607 ConfigMapName: kube-root-ca.crt ConfigMapOptional: <nil> DownwardAPI: true QoS Class: Burstable Node-Selectors: <none> Tolerations: :NoSchedule op=Exists node.kubernetes.io/disk-pressure:NoSchedule op=Exists node.kubernetes.io/memory-pressure:NoSchedule op=Exists node.kubernetes.io/network-unavailable:NoSchedule op=Exists node.kubernetes.io/not-ready:NoExecute op=Exists node.kubernetes.io/pid-pressure:NoSchedule op=Exists node.kubernetes.io/unreachable:NoExecute op=Exists node.kubernetes.io/unschedulable:NoSchedule op=Exists Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 57m default-scheduler Successfully assigned kube-system/kube-flannel-ds-s4qmj to mcw9 Normal Pulling 57m kubelet Pulling image "rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.0" Normal Pulled 57m kubelet Successfully pulled image "rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.0" in 7.945886633s Normal Created 57m kubelet Created container install-cni-plugin Normal Started 57m kubelet Started container install-cni-plugin Normal Pulling 57m kubelet Pulling image "quay.io/coreos/flannel:v0.15.1" Normal Created 55m kubelet Created container install-cni Normal Pulled 55m kubelet Successfully pulled image "quay.io/coreos/flannel:v0.15.1" in 1m31.255703561s Normal Started 55m kubelet Started container install-cni Normal Pulled 54m (x4 over 55m) kubelet Container image "quay.io/coreos/flannel:v0.15.1" already present on machine Normal Created 54m (x4 over 55m) kubelet Created container kube-flannel Normal Started 54m (x4 over 55m) kubelet Started container kube-flannel Warning BackOff 2m23s (x245 over 55m) kubelet Back-off restarting failed container [machangwei@mcw7 ~]$ 繼續查看,Pod的情況,從restart這一列可以看到,重試次數和最後一次重試時間。重試這裡指的是重新去 docker pull拉取鏡像。但是這裡顯沒有成功過,狀態一直是非running的正常狀態。我們也可以手動去docker pull鏡像的 [machangwei@mcw7 ~]$ kubectl get pod --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE kube-system coredns-6d8c4cb4d-2296m 1/1 Running 1 (165m ago) 6h35m kube-system coredns-6d8c4cb4d-lphb2 1/1 Running 1 (165m ago) 6h35m kube-system etcd-mcw7 1/1 Running 3 6h36m kube-system kube-apiserver-mcw7 1/1 Running 2 6h36m kube-system kube-controller-manager-mcw7 1/1 Running 4 (165m ago) 6h36m kube-system kube-flannel-ds-5pxmj 0/1 CrashLoopBackOff 24 (96s ago) 104m kube-system kube-flannel-ds-8gzfq 1/1 Running 0 170m kube-system kube-flannel-ds-s4qmj 0/1 CrashLoopBackOff 17 (2m33s ago) 67m kube-system kube-proxy-4lmsx 1/1 Running 0 104m kube-system kube-proxy-c5zmm 1/1 Running 0 6h35m kube-system kube-proxy-npmtv 1/1 Running 0 67m kube-system kube-scheduler-mcw7 1/1 Running 3 (165m ago) 6h36m 雖然查看Pod狀態不是running,但是我么查看k8s節點,狀態都已經是ready狀態 [machangwei@mcw7 ~]$ kubectl get nodes NAME STATUS ROLES AGE VERSION mcw7 Ready control-plane,master 6h43m v1.23.1 mcw8 Ready <none> 111m v1.23.1 mcw9 Ready <none> 74m v1.23.1
[root@mcw7 ~]$ docker ps |awk ‘{print $3,”\t”,$NF}’IMAGE NAMES”/usr/local/bin/kube…” k8s_kube-proxy_kube-proxy-c5zmm_kube-system_5897b315-6a17-4d8b-82c6-7712ade54560_0″/pause” k8s_POD_kube-proxy-c5zmm_kube-system_5897b315-6a17-4d8b-82c6-7712ade54560_0″kube-scheduler k8s_kube-scheduler_kube-scheduler-mcw7_kube-system_5a3a66c7da6759d92afea91cd2972f6e_2″kube-apiserver k8s_kube-apiserver_kube-apiserver-mcw7_kube-system_fc840a9b537be965fe104fc9cbddd14f_2″kube-controller-man…” k8s_kube-controller-manager_kube-controller-manager-mcw7_kube-system_3e1d477612039be74973ec7803946c3a_3″etcd k8s_etcd_etcd-mcw7_kube-system_93c9b21b665d4c633156ae2d5739fb33_3″/pause” k8s_POD_kube-scheduler-mcw7_kube-system_5a3a66c7da6759d92afea91cd2972f6e_0″/pause” k8s_POD_kube-controller-manager-mcw7_kube-system_3e1d477612039be74973ec7803946c3a_0″/pause” k8s_POD_kube-apiserver-mcw7_kube-system_fc840a9b537be965fe104fc9cbddd14f_0″/pause” k8s_POD_etcd-mcw7_kube-system_93c9b21b665d4c633156ae2d5739fb33_0[root@mcw7 ~]$


