TKE用戶故事 | 作業幫檢索服務基於Fluid的計算存儲分離實踐
作者
呂亞霖,2019年加入作業幫,作業幫基礎架構-架構研發團隊負責人,在作業幫期間主導了雲原生架構演進、推動實施容器化改造、服務治理、GO微服務框架、DevOps的落地實踐。
張浩然,2019年加入作業幫,作業幫基礎架構-高級架構師,在作業幫期間,推動了作業幫雲原生架構演進、負責多雲k8s集群建設、k8s組件研發、linux內核優化調優、底層服務容器化相關工作。
背景
大規模檢索系統一直都是各個公司平台業務的底層基石,往往是以千台裸金屬服務器級別的超大規模集群的方式運行,數據量巨大,對於性能、吞吐、穩定性要求極為苛刻,故障容忍度很低。 除了運行層面外,超大規模集群和海量數據場景下的數據迭代和服務治理也往往是一個巨大的挑戰:增量和全量的數據分發效率,短期和長期的熱點數據追蹤等都是需要深入研究的問題 本文將介紹作業幫內部設計實現的基於 fluid 計算存儲分離架構,能夠顯著降低大規模檢索系統類服務的複雜度,使得大規模檢索系統可以像正常在線業務一樣平滑管理。
大規模檢索系統所面臨的問題
作業幫的眾多學習資料智能分析和搜索功能中都依賴於大規模數據檢索系統,我們的集群規模在千台以上,總數據量在百 TB 級別以上,整個系統由若干分片組成,每個分片由若干服務器加載相同的數據集,運行層面上我們要求性能達到 P99 1.Xms,吞吐量高峰百 GB 級,穩定性要求 99.999% 以上。
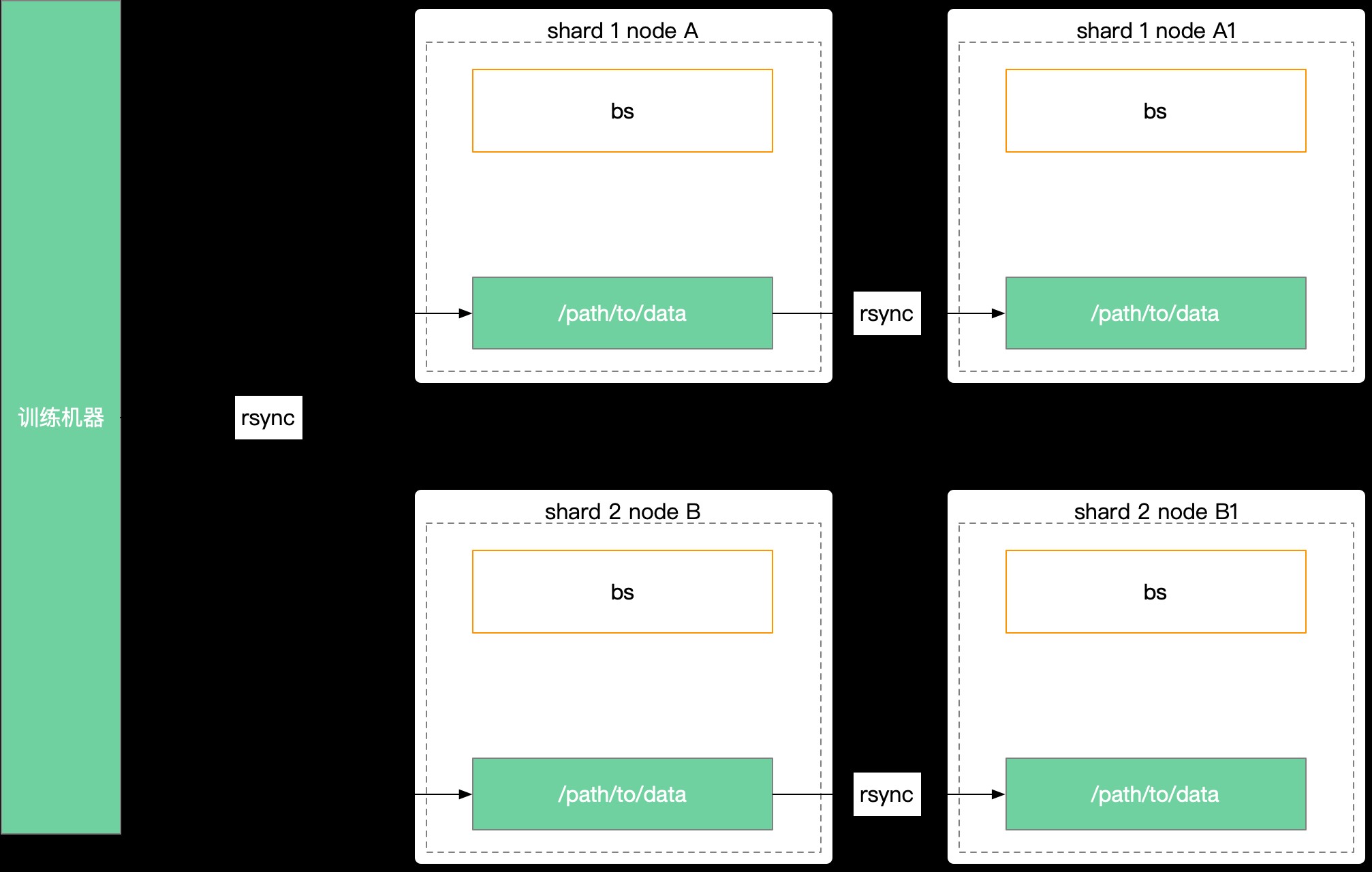
以往環境中為了提高數據讀取效率和穩定性,更多的在考慮數據本地化存儲,我們的檢索系統每日產生索引項並需要進行 TB 級別的數據更新,這些數據通過離線建庫服務產出之後,需要分別更新到對應的分片中,這種模式下帶來了許多其他挑戰,比較關鍵的問題集中在數據迭代和擴展性上:
-
數據集合的離散:由於實際運行中,每個分片的每個節點都需要複製下來本分片所有數據,由此帶來了同步數據下發困難的問題。實際運行中如果要同步數據到單服務器節點,需要使用分級下發,先下發一級(十級)由一級分發給二級(百級)再分發給三級(千級),這個分發周期長且需要層層校驗來保證數據準確性。
-
業務資源彈性擴縮較弱:原先的系統架構採用的是計算和存儲緊耦合,數據存儲和算力資源緊密捆綁,資源靈活擴展能力不高,擴容往往需要以小時為單位進行,缺乏應對突發峰值流量擴容能力。
-
單分片數據擴展性不足:單分片數據上限受分片集群內的單機存儲上限限制。如果達到存儲上限,往往需要拆分數據集,而這種拆分不是由業務需求驅動的。
而數據迭代和擴展性的問題又不得不帶來了成本壓力和自動化流程上的薄弱。
通過對檢索系統運行和數據更新流程的分析,當前面臨的關鍵問題是由於計算和存儲的耦合所帶來的,因此我們考慮如何去解耦計算和存儲,只有引入計算存儲分離的架構才能夠從根本上解決複雜度的問題 計算存儲分離最主要的就是將每個節點存儲本分片全量數據的方式拆分開,將分片內的數據存儲在邏輯上的遠程機器上 但是計算存儲分離又帶來了其他的問題,比如穩定性問題,大數據量下的讀取方式和讀取速度,對業務的入侵程度等等問題,雖然存在這些問題,但是這些問題都是可解決以及易解決的 基於此我們確認計算存儲分離一定是該場景下的良方,可以從根本上解決系統複雜度的問題。
計算存儲分離架構解決複雜度問題
為了解決上述計算存儲分離所需要考慮的問題,新的計算存儲分離架構必須能達到以下目標:
-
讀取的穩定性,計算存儲分離終究是通過各種組件配合替換掉了原始文件讀取,數據加載方式可以替換,但是數據讀取的穩定性依然需要和原始保持同等水平。
-
每個分片千節點同時數據更新場景下,需要最大限度的提升讀取速度,同時對網絡的壓力需要控制在一定程度內。
-
支持通過 POSIX 接口讀取數據,POSIX 是最具備對各種業務場景的適應性的方式,這樣無需侵入業務場景下,屏蔽了下游變動對上游的影響。
-
數據迭代的流程的可控性,對於在線業務來說,數據的迭代理應被視為和服務迭代等同的 cd 流程,那麼數據迭代的可控性就及其重要,因為本身就是 cd 流程的一部分。
-
數據集合的可伸縮性,新的架構需要是一套可複製,易擴展的模式,這樣才能面對數據集合的伸縮、集群規模的伸縮具備良好的應對能力。
為了達成上述目標,我們最終選用了 Fluid 開源項目作為整個新架構的關鍵紐帶。
組件介紹
Fluid 是一個開源的 Kubernetes 原生的分佈式數據集編排和加速引擎,主要服務於雲原生場景下的數據密集型應用,例如大數據應用、AI應用等。通過 Kubernetes 服務提供的數據層抽象,可以讓數據像流體一樣在諸如 HDFS、OSS、Ceph 等存儲源和 Kubernetes 上層雲原生應用計算之間靈活高效地移動、複製、驅逐、轉換和管理。而具體數據操作對用戶透明,用戶不必再擔心訪問遠端數據的效率、管理數據源的便捷性,以及如何幫助 Kuberntes 做出運維調度決策等問題。
用戶只需以最自然的 Kubernetes 原生數據卷方式直接訪問抽象出來的數據,剩餘任務和底層細節全部交給 Fluid 處理。Fluid 項目當前主要關注數據集編排和應用編排這兩個重要場景。
數據集編排可以將指定數據集的數據緩存到指定特性的 Kubernetes 節點,而應用編排將指定該應用調度到可以或已經存儲了指定數據集的節點上。這兩者還可以組合形成協同編排場景,即協同考慮數據集和應用需求進行節點資源調度。

我們選擇使用 fluid 的原因
-
檢索服務已經完成容器化改造,天然適合 fluid。
-
Fluid 作為數據編排系統,使得上層無需知道具體的數據分佈就可以直接使用,同時基於數據的感知調度能力,可以實現業務的就近調度,加速數據訪問性能。
-
Fluid 實現了 pvc 接口,使得業務 pod 可以無感知的掛載進入 pod 內部,讓 pod 內可以像使用本地磁盤一樣無感知。
-
Fluid 提供元數據和數據分佈式分層緩存,以及高效文件檢索功能。
-
Fluid+alluxio 內置了多種緩存模式(回源模式,全緩存模式),不同的緩存策略(針對小文件場景的優化等)和存儲方式(磁盤,內存),對於不同的場景具備良好的適應性,無需太多修改即可滿足多種業務場景。
落地實踐
-
緩存節點和計算節點的分離: 雖然使用 fuse 和 worker 結合部署可以獲得更好的數據本地性能,但是在在線場景下,我們最終選用了緩存和計算節點分離的方案,原因是通過延長一定的啟動時間換來更優的彈性是值得的,以及我們並不希望業務節點穩定性問題和緩存節點的穩定性問題糾纏在一起。Fluid 支持 dataset 的可調度性,換言之就是緩存節點的可調度性,我們通過指定 dataset 的 nodeAffinity 來進行數據集緩存節點的調度,從而保證緩存節點可高效,彈性化的提供緩存服務。
-
在線場景的高要求: 對於在線業務場景,鑒於系統對於數據的訪問速度、完整性和一致性有較高的要求,因此不能出現數據的部分更新、非預期的回源請求等; 所以對數據緩存和更新策略的選擇就會很關鍵。
-
合適的數據緩存策略: 基於以上需求,我們選擇使用 Fluid 的全緩存模式。在全緩存模式下,所有請求只會走緩存,而不在回源到數據源,這樣就避免了非預期的長耗時請求。同時 dataload 的過程則由數據更新流程來把控,更安全和標準化。
-
結合權限流的更新流程: 在線業務的數據更新也是屬於 cd 的一種,同樣也需要更新流程來管控,通過結合了權限流程的 dataload 模式,使得線上數據發版更安全和標準化。
-
數據更新的原子性: 由於模型是由許多文件組成,只有所有的文件全部緩存起來之後,才是一份可以被使用的完整的模型;所以在全緩存無回源的前提下,就需要保證 dataload 過程的原子性, 在數據加載的過程中過,新版本數據不能被訪問到,只有在數據加載完成之後,才可以讀取到新版本數據。
-
以上方案和策略配合我們自動化的建庫和數據版本管理功能,大大提高了整體系統的安全性和穩定性,同時使得整個過程的流轉更加智能和自動化。

總結
基於 Fluid 的計算存儲分離架構,我們成功地實現:
-
分鐘級百 T 級別的數據分發。
-
數據版本管理和數據更新的原子性,使得數據分發和更新成為一種可管控,更智能的自動化流程。
-
檢索服務能夠像正常無狀態服務一樣,從而能夠輕鬆通過 TKE HPA 實現橫向擴展,更快捷的擴縮帶來了更高的穩定性和可用性。
展望
計算和存儲分離的模式使得以往我們認為非常特殊的服務可以被無狀態化,可以像正常服務一樣被納入 Devops 體系中,而基於 Fluid 的數據編排和加速系統,則是實踐計算和存儲分離的一個切口,除了用於檢索系統外,我們也在探索基於 Fluid 的 OCR 系統模型訓練和分發的模式。
在未來工作方面,我們計劃繼續基於 Fluid 優化上層作業的調度策略和執行模式,並進一步擴展模型訓練和分發,提高整體訓練速度和資源的利用率,另一方面也幫助社區不斷演進其可觀測性和高可用等,幫助到更多的開發者。
關於我們
更多關於雲原生的案例和知識,可關注同名【騰訊雲原生】公眾號~
福利:
①公眾號後台回復【手冊】,可獲得《騰訊雲原生路線圖手冊》&《騰訊雲原生最佳實踐》~
②公眾號後台回復【系列】,可獲得《15個系列100+篇超實用雲原生原創乾貨合集》,包含Kubernetes 降本增效、K8s 性能優化實踐、最佳實踐等系列。
③公眾號後台回復【白皮書】,可獲得《騰訊雲容器安全白皮書》&《降本之源-雲原生成本管理白皮書v1.0》
【騰訊雲原生】雲說新品、雲研新術、雲遊新活、雲賞資訊,掃碼關注同名公眾號,及時獲取更多乾貨!!



