京東白條數據架構進化之路:要在數據的不確定性中探索架構的穩定性
京東白條的快速發展滿足了當前人們日益增長的消費需求。在京東商城上用京東白條來支付,已經成為一大批用戶的消費習慣,更是在某種意義上成為了京東對外的『標籤』。而作為一家互聯網金融消費平台,京東白條的後台技術團隊更是不容忽視的存在。而其也正是支撐京東白條自 2014 年初上線伊始,至今服務數億用戶的最終根源所在。正是京東白條技術團隊多年的努力,才造就了當前京東白條的『土生土長』,但具有京東白條特色的金融級數據庫選型方法論。
當京東白條的金融類業務啟動時,現任京東白條研發負責人張棟芳,雖然預料到了其數據體量的大幅度增長,卻沒有想到這種增長將導致數據庫選型方面的一系列變化,以及對數據庫未來發展模式的啟發。
作為京東科技旗下的殺手級金融消費應用,今天的京東白條已經成長為服務數億用戶、日均產生巨額流量的龐大金融生態。在業務和數據量飛速增長的同時,京東白條後台的研發人員,也在緊張的焦頭爛額中….
這一點,完美契合了京東白條後台數據架構的成長過程。
1、技術的保質期:從 MySQL 到 NoSQL 再到 DBRep
對於技術人而言,沒有永遠正確的技術,只有最適合於當下的技術選型。
京東白條業務誕生之初正是互聯網金融與消費行業的高速發展期,經歷這些年的發展,從草根走向專業,從弱小走向規模,從分散走向統一,從雜亂走向規範。京東白條的發展,正是一步步見證了國內互聯網消費金融產業的快速迭代。
同樣,京東白條的技術選型歷程,也可作為國內互聯網消費金融產業發展過程的一個縮影。
從技術架構的角度來看,並沒有絕對的好與不好,需要放在彼時的背景下來看,要考慮業務的時效價值、團隊的規模和能力、環境基礎設施等等方面。只有架構演進的生命周期適時匹配好業務的生命周期,才能發揮最好的效果。
2014~2015
Solr + HBase 的方案解決了核心、非核心業務系統對關鍵數據庫的訪問問題,Solr 作為被檢索字段的索引,HBase 用作全量的數據存儲。
-
通過 Solr 集群分擔部分讀和寫的業務,緩解核心庫的壓力;
-
Solr 擴展體驗上欠佳,對業務也存在較大的入侵。
2015~2016
引入 NoSQL 方案,業務數據以月份進行分表存儲在 MongoDB 集群中,階段性滿足了結算處理場景中海量數據導入導出的需求。
-
查詢熱點數據效率高,非結構化的存儲方式易於修改表結構;
-
依然面對着擴展差、對業務入侵強的局面,而且耗內存。
2016~2017
隨着業務快速發展,數據量突破百億大關,此時 MongoDB 面臨著容量和性能的雙重考驗。京東白條大數據平台通過 DBRep 以 MySQL Slave 的形式採集變動信息並存儲到消息中心,最後落盤到 ES 和 HBase 中。
-
該方案具有較強的數據實時性,擴展性良好;
-
基於業務框架的數據分片難以降低代碼維護成本。
2、為了讓你能夠更痛快的剁手,他們先『分解』了自己的後台架構
網購,貴在手速,但也在於錢包的厚度。京東白條的誕生就是為了解決用戶錢包的厚度問題。如今,京東白條也打起了「閃電戰」。為了保證用戶在消費過程中的體驗,後台數據庫的穩定性與規律性,就成為了京東白條技術側亟待考慮和平衡的問題。
為保證業務系統在數據激增情況下始終能保持高效運行,京東白條技術團隊在設計初期使用了數據分片數據架構,發揮極致性能的同時也兼顧代碼的可控性,採用基於應用框架的數據拆分方案完成了數據拆分工作。
其實說來說去,本質上就是一個問題,即隨着產品的升級迭代,早期的解決方案逐漸演變為了阻礙今天前進的絆腳石。通過業務框架實現的數據分片方案導致業務代碼複雜度增加、維護成本不斷攀升,緊耦合的弊端逐漸顯露,應用每次升級都需要投入較多的精力對分片做相應調整,研發人員難以專註於業務本身。
於是,解耦成了京東白條技術突圍的唯一關鍵。在京東白條而言,主要從以下這四個方面開始解耦:
-
數據架構解耦,降低架構之間的耦合度,確保不會因單獨業務線變更而導致多個後端架構的調整;
-
技術架構解耦,簡化業務系統升級工作所帶來的複雜研發流程;
-
業務關係解耦,需要讓用戶在使用過程中每個動作都不受影響,不另外產生新的學習成本,為系統提供良好的擴展能力,從容應對「618」和「11.11」等平台大促活動;
-
研發流程解耦,解放後端研發生產力,減少業務代碼的複雜度。
因後台數據庫與業務之間的耦合度過高,為整個業務的發展埋下了增速放緩的隱患。面對如上訴求,京東白條技術團隊經權衡後開始考慮使用成熟的分庫分表組件來承擔這部分工作,讓業務系統升級和架構調整不再複雜。 但京東白條業務體量巨大,是名副其實的金融級高並發、海量數據的業務場景,因此在選擇分庫分表組件時應具備以下 4 個特點:
-
產品成熟穩定。只有成熟且穩定維護的產品,才能夠給京東白條這樣一款體量的金融產品予以穩定性的保證。使用數據分片來進行架構解耦,本身就是為了確保穩定性;
-
極致性能表現。金融場景下的應用,對於數據響應、實時反饋等性能的要求非常高。尤其在交易這種敏感且特殊的場景下,對於性能的表現,一點也不能馬虎;
-
處理海量數據。京東白條需要處理海量的用戶數據,尤其在「618」、「11.11」等大促節日下,面對蜂擁而至海量交易數據與請求,要能夠在短時間內快速處理;
-
架構靈活擴展。業務靈活多變是當前互聯網產品的共性。
對此,京東白條從多個方面考慮自研框架與成熟分庫分表中間件 ShardingSphere 優劣性,性能對比圖如下:
| 基於自研框架分片 | 基於 ShardingSphere 分片 | |
|---|---|---|
| 性能 | 高 | 高 |
| 代碼耦合度 | 高 | 低 |
| 業務入侵程度 | 高 | 低 |
| 升級難度 | 高 | 低 |
| 擴展性 | 一般 | 良好 |
最終,京東白條選擇採用 Apache ShardingSphere 來進行金融級別的數據庫分片任務。
3、場景趨於融合,但數據庫卻無法相容:Apache ShardingSphere 解決方案
京東白條採用 Apache ShardingSphere-JDBC 解決方案處理在線應用。ShardingSphere-JDBC 是 Apache ShardingSphere 的第一款產品,它定位為輕量級 Java 框架,在 Java 的 JDBC 層提供的額外服務。它使用客戶端直連數據庫,以 jar 包形式提供服務,無需額外部署和依賴,可理解為增強版的 JDBC 驅動,完全兼容 JDBC 和各種 ORM 框架。
ShardingSphere-JDBC 的以下特點能夠很好地滿足白條業務場景:
-
產品成熟:經數年打磨產品成熟度高,且社區活躍;
-
性能良好:微內核、輕量化的設計,性能損耗極小;
-
改造量小:支持原生的 JDBC 接口,研發工作量小;
-
擴展靈活:搭配使用遷移同步組件輕鬆實現數據擴展。
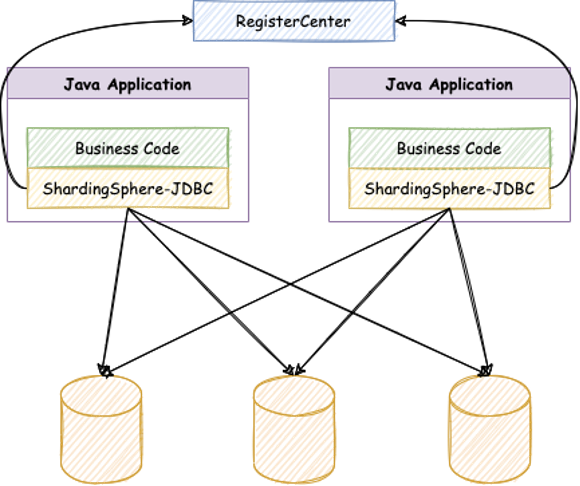
經內部大量系統性驗證之後,Apache ShardingSphere 成為了京東白條數據分片中間件的首選方案,2018 年底正式開始對接。
產品適配
為全面支撐白條業務、提供更好的業務體驗,Apache ShardingSphere 在京東白條業務落地過程中對產品的功能和性能方面進行了更多的支持和提升,產品再一次經歷典型案例的打磨。
- 升級 SQL 引擎
白條的業務邏輯非常複雜且龐大,多樣化場景的需求對 SQL 的兼容程度有着較高要求,Apache ShardingSphere 重構了 SQL 解析模塊,並支持了更多的 SQL。經兩團隊通力合作,京東白條業務與 Apache ShardingSphere 相結合的各項指標滿足預期,性能與原生 JDBC 幾乎一致。
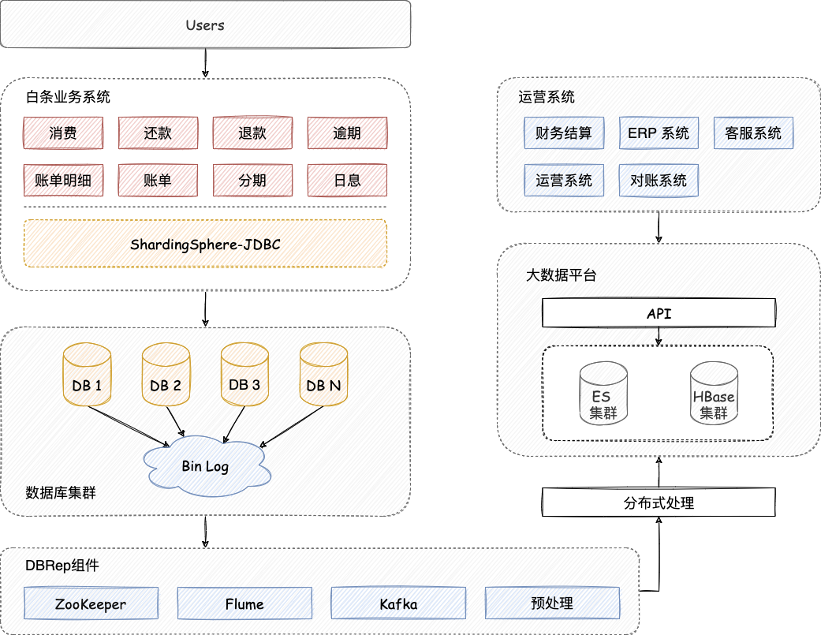
關於對接過程中的問題詳情及方案,請通過《Apache ShardingSphere 對接京東白條實戰》一文來了解。
業務割接
Apache ShardingSphere 使用定製化 HASH 策略對數據進行分片,有效避免了熱點數據問題,拆分後的數據節點數達近萬個,整個割接過程大約持續了 4 周左右的時間。
-
DBRep 讀取數據,通過 Apache ShardingSphere 將數據同步至目標數據庫集群;
-
兩套集群並行運行,數據遷移後再使用自研工具對業務和數據進行校驗。
DBRep 是 ShardingSphere-Scaling 產品設計的基石,Scaling 具備的自動化能力為後續的遷移擴容工作提供了更多的便利。
配好業務的生命周期,才能發揮最好的效果。
價值收益
- 簡化升級路徑
通過架構解耦,業務系統升級所涉及技術棧得到有效縮短,研發團隊不再需要關注分表設計,精力全部聚焦於業務本身,升級路徑得到大幅度優化;
- 節省研發力量
引入成熟的 Apache ShardingSphere 無需重新開發分表組件,在簡化業務升級路徑的基礎上節省了大量研發力量;
- 架構靈活擴展
搭配使用 Scaling 同步遷移組件從容面對「618」和「11.11」等大型活動,系統靈活擴容。
4、面對新的不穩定業態,需要相對穩定的標準來應對
如何理解不穩定,並平衡這種不穩定。
隨着數據的重要性日益凸顯,以及終端場景領域的持續細化,業務線『開枝散葉』已是常態,市場上的數據庫產品層出不窮。某種意義上,發展了許多年的京東白條,早已不再是當年的數據體量,其金融消費場景已經是一個相對穩定和成熟的場景而言,京東白條仍然是一個快速生長的互聯網巨量頭部產品,用戶和數據體量還遠沒有達到接近天花板級別。
這也意味着,隨着業務數據量的增長,未來京東白條還需要經歷多次具備『陣痛期』的架構轉型。而每一次轉型,無疑都是一次冒險,這對於追求穩定和體驗的金融級產品而言,無疑是需要慎重考慮的。
而在現階段通用的數據架構體系下,整個行業都在經歷一種新的不穩定業態。面對這種不穩定的業態,京東白條需要一種相對穩定的標準和生態,來『對抗』這種不穩定的趨勢。基於此,張棟芳提到了 Database Plus 的概念。
2018 年,Apache ShardingSphere 作者張亮就曾提出過 Database Plus 的概念。彼時數據庫已經呈現出碎片化的趨勢,企業在後端數據庫管理層面,已經開始產生不小的成本。如果能夠在數據庫上層重新建設起具備統一管理底層數據的中間層生態,對於企業以及工程師而言,都會極大提高研發與管理的效率。
所以,Sharding-JDBC 在京東內部,正式升級為 ShardingSphere,寓意打造一個新的生態,並在張亮和社區需求的引導下,逐步確立起了 Database Plus 的發展方向。伴隨着近日 Apache ShardingSphere 5.0.0 正式版的更新,Database Plus 理念已正式在 Apache ShardingSphere 生態中得到踐行。
目前,Apache ShardingSphere 通過可插拔架構,已能夠在數據庫上層構建起一套全新的數據治理生態,如讓傳統關係型數據庫同時具備水平擴展和數據加密的功能,或在傳統關係型數據庫的基礎上單獨打造分佈式數據庫解決方案等,而無需調整底層數據庫架構。
而這種技術,無疑是應對數據庫碎片化趨勢的最好方案之一。 而對於未來數據庫發展的理解,張棟芳認為,在多樣化的數據庫上層,構建起統一的數據管理平台,將數據庫能力分佈在中間層並實現可插拔化,追求功能與業務訴求的高度匹配,篩去冗餘的能力,並能夠在需要時進行快速變動,始終保證數據架構的整潔、專一。
5、事物終歸需要回歸到它的本質
從市場和用戶規模來看,中國有着全球最廣泛的互聯網用戶群體,產生着最大的數據體量,誕生了一系列成長最快速的互聯網科技公司….但是與龐大需求所不匹配的是,國內數據服務市場卻始終處於同質化競爭之下,沒能有顛覆海外數據庫巨頭的產品出現。
張棟芳認為,各家廠商專註於各自的應用場景之下,缺少一個抬頭環顧四周的過程。我們始終在談新技術,始終在追求業務的最高效化。但對於一些需要實現「大象起舞」的金融、證券、製造、零售等領域而言,最新的技術不一定是最適合他們的,在現有技術基礎上,提供增量能力的中間件,打造適配於當下業務場景的技術體系,而不是顛覆。
「事物需要回歸它的本質。」對於數據治理方式而言,同樣如此。
歡迎添加社區經理微信(ss_assistant_1)進入微信交流群,與眾多 ShardingSphere 愛好者一同交流