【kafka學習筆記】kafka的基本概念
在了解了背景知識後,我們來整體看一下kafka的基本概念,這裡不做深入講解,只是初步了解一下。
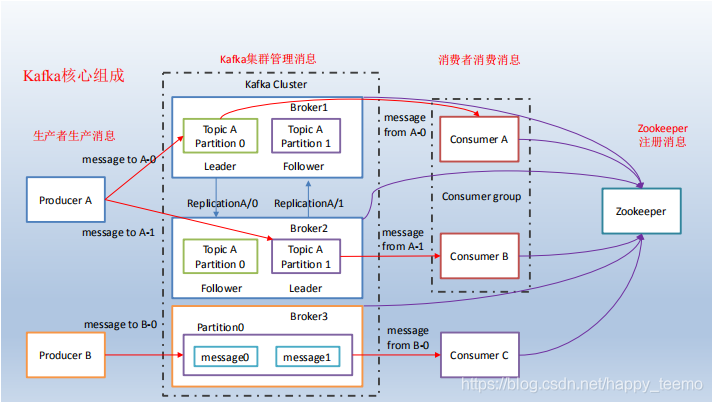
kafka的消息架構
注意這裡不是設計的架構,只是為了方便理解,腦補的三層架構。從代碼的實現來看,kafka其實就一層,不像MySQL分了服務層、引擎層之類的。
主題層
首先是主題層,Topic(主題),比如用戶消息,命名為’user_message’;支付消息,命名為’pay_message’。兩者互不干擾,等於是兩條道。
注意這裡的Topic是邏輯概念,落到硬件上,應該叫partition(分區),為了提升吞吐量,kafka將一個主題分成了多個區,就像MongoDB 和 Elasticsearch 中的 Sharding、HBase 中的 Region,這是分佈式的前提。

值得注意的是,kafka只保證單個partition上的順序。談到順序,我們了解一下offest,它標記了消費者在這個partiotion上讀到了哪一條。
那麼我們想要順序消費,也要提升消費速度,怎麼辦?
- 如果兩個消費者同時消費同一個topic下的同一個partition,很顯然,他們會重複消費。因為每個消費者的offest是獨立保存的。
- 如果我們分成兩個partition,假設topic的數據是123456, 採用隨機分配的策略,partition1上的可能是135,2上面是246,消費者A讀取1,B讀取2,這樣就不會重複消費了,但是如果A的速度很快,可能A都到5了,B的2還沒讀完。這就導致了亂序消費。
- 很簡單,在上面的方案中,我們將隨機分配改成哈希分配,從業務層將一個業務邏輯的消息發送到同一個partition上,比如用戶ID。如果你的運氣足夠不好,可能會出現一個partition消息多,另一個少的情況。
好了,回顧下, topic,partition,offest。
分區層
在實際應用中, 我們往往將partition分配在不同的磁盤上,利用多磁盤來增加讀寫效率。但是既然是分佈式,必然需要多個機器,而一個機器,我們常常稱為一個broker(節點)。
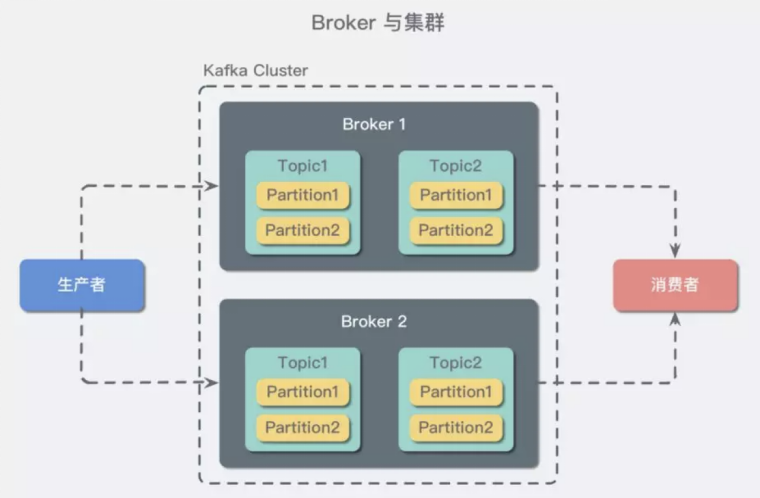
多節點不一定要再不同的機器上,只是我們之所以需要多節點就是為了防止意外宕機,如果都在同一台上,一死就全死了,毫無意義。
每個broker都有一套冗餘數據,也叫做 repliaction(副本)。(天天網遊裏面下副本,今天終於知道副本是啥了吧。其實網遊之所以有副本,就是為了防止玩家都湧入一個機器,在大家進入副本的時候,就切換到一個新的機器上了,和其他副本互不干擾。)
那麼如果我們有三個節點,客戶端怎麼知道需要連接哪個呢?這就引入了兩個概念,leader(領導者),follower(跟隨者)。對了,還有個管家,叫zookeeper,它負責管理所有broker的IP地址,是否存活,然後怎麼選取領導者,怎麼換領導者。這中間的算法,我們後面再細細講。
總之,zookeeper會選取leader,然後生產者和消費者只和leader交互。那麼follower做啥?就是跟着跑,把leader的消息不斷拉到本地,準備有一天等領導掛了自己成為新的領導。
(這裡和MySQL不一樣,MySQL的從庫還負責給客戶端讀。)
好了,回顧下, broker,replication,leader,follower。
消息層
這一層主要是存儲信息和消費者的offest。值得注意的是,消息是可以壓縮的,上一篇也提到了,這樣可以大大減少網絡帶寬。但是具體細節後面再說。
總結
kafka的陌生詞彙還是挺多的,自己在腦海中多過兩遍,總整體,到部分,有個基本概念就好,後面談到的時候能更好地理解。