Flink Sql 之 Calcite Volcano優化器(源碼解析)
Calcite作為大數據領域最常用的SQL解析引擎,支持Flink , hive, kylin , druid等大型項目的sql解析
同時想要深入研究Flink sql源碼的話calcite也是必備技能之一,非常值得學習
我們內部也通過它在做自研的sql引擎,通過一套sql支持關聯查詢任意多個異構數據源(eg : mysql表join上 hbase表在做一個聚合計算)
因為calcite功能比較多,本文主要還是從calcite重要的主流程源碼入手,主要側重在VolcanoPlanner的優化器上
梳理一下Calcite SQL執行的幾個階段

總結下來就是
1. 通過Parser解析器將傳入的sql解析成一顆詞法樹,SqlNode作為樹的節點
2. 做詞法的校驗Validate,類型校驗,元數據校驗等等
3. 將校驗好的SqlNode樹轉換成對應的關係代數表達式,也是一顆樹,RelNode作為節點
4. 將RelNode關係代數表達式樹,通過內置的兩種優化器Volcano , Hep 優化關係代數表達式得到最優邏輯代數的一顆樹,也是RelNode
5. 最優的邏輯代數表達式(RelNode),會被轉換成對應的可執行的物理執行計劃(轉換邏輯根據框架有所不同),像Flink就轉成他的Operator去運行
來詳細的看下每個階段
1. Sql語句解析成語法樹階段(SQL – > SqlNode)
這一個階段其實不是calcite實現的,而是calcite自己定義了一套sql語法分析規則模板,通過javaCC這個框架去實現的
拉代碼來看下
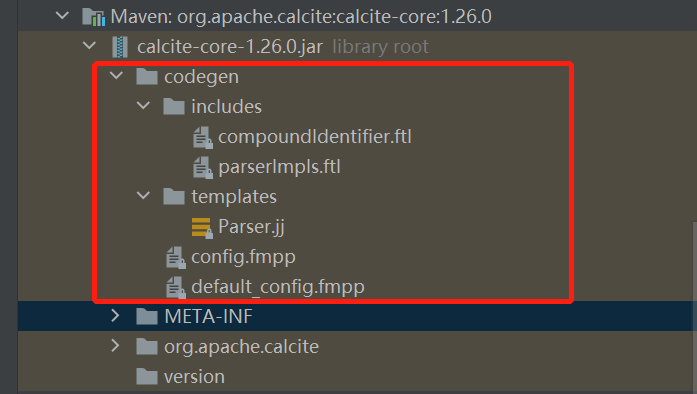
源碼中那個Parser.jj就是calcite核心的語法模板了,比如說我們要為flink sql添加什麼語法比如count window就要修改這裡
其中定義了是什麼sql token 如何返回sqlNode的具體邏輯
看個例子
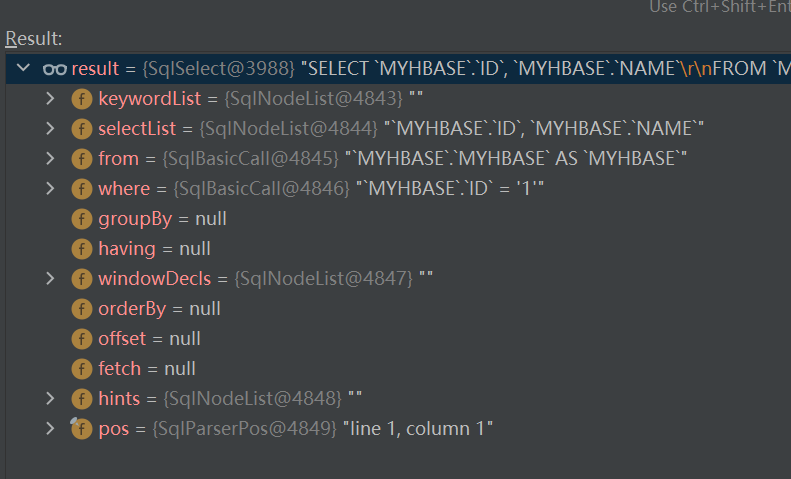
"select ID,NAME from MYHBASE.MYHBASE where ID = '1' "
就會被解析成這樣一顆sqlNode樹
這裡就不贅述了,javacc 可以參考官網(//javacc.github.io/javacc/)
2 . 語法校驗validator階段
這裡通過校驗器去校驗,這裡不展開了,不是重點
3. 將sqlNode轉成relNode的邏輯表達式樹(sqlNode – > relNode)
這裡calcite有默認的sql2rel轉換器org.apache.calcite.sql2rel.SqlToRelConverter
這裡也先不展開了
4. 邏輯關係代數樹優化(relNode – > relNode)
這裡是中重點中的重點!!!為什麼有那麼多框架選擇Calcite就是因為它的sql優化
通過3階段我們得到了一個relNode樹,但這裡這顆樹並不是最優解,而calcite通過自身的兩種優化器planner得到一個優化後的best樹
這裡才是整個calcite的核心,calcite提供的兩種優化器
HepPlanner規則優化器(簡單理解為定義許多規則Rule,只要能符合優化規則的樹節點的就按規則轉換,得到一顆規則優化後的樹,這個比較簡單)
VolcanPanner代價優化器(基於代價cost,樹會根據rule一直迭代,不停計算更新root relnode節點的代價值,來找到最優的樹)
先來看下
select ID,NAME from a where ID = '1'
這樣sql轉換而來的一顆RelNode樹長什麼樣子
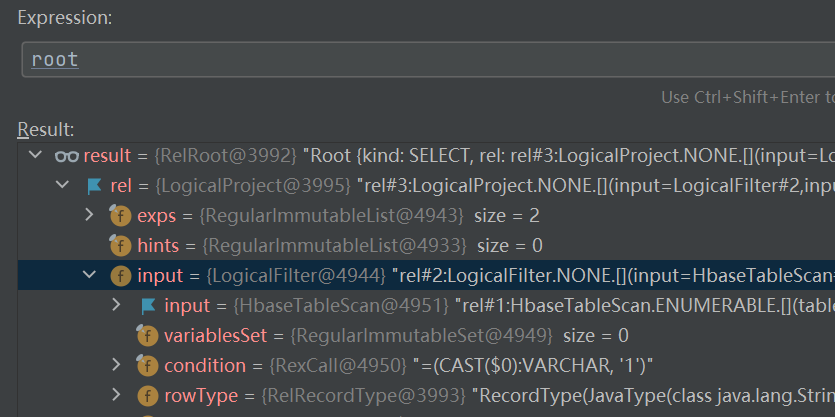
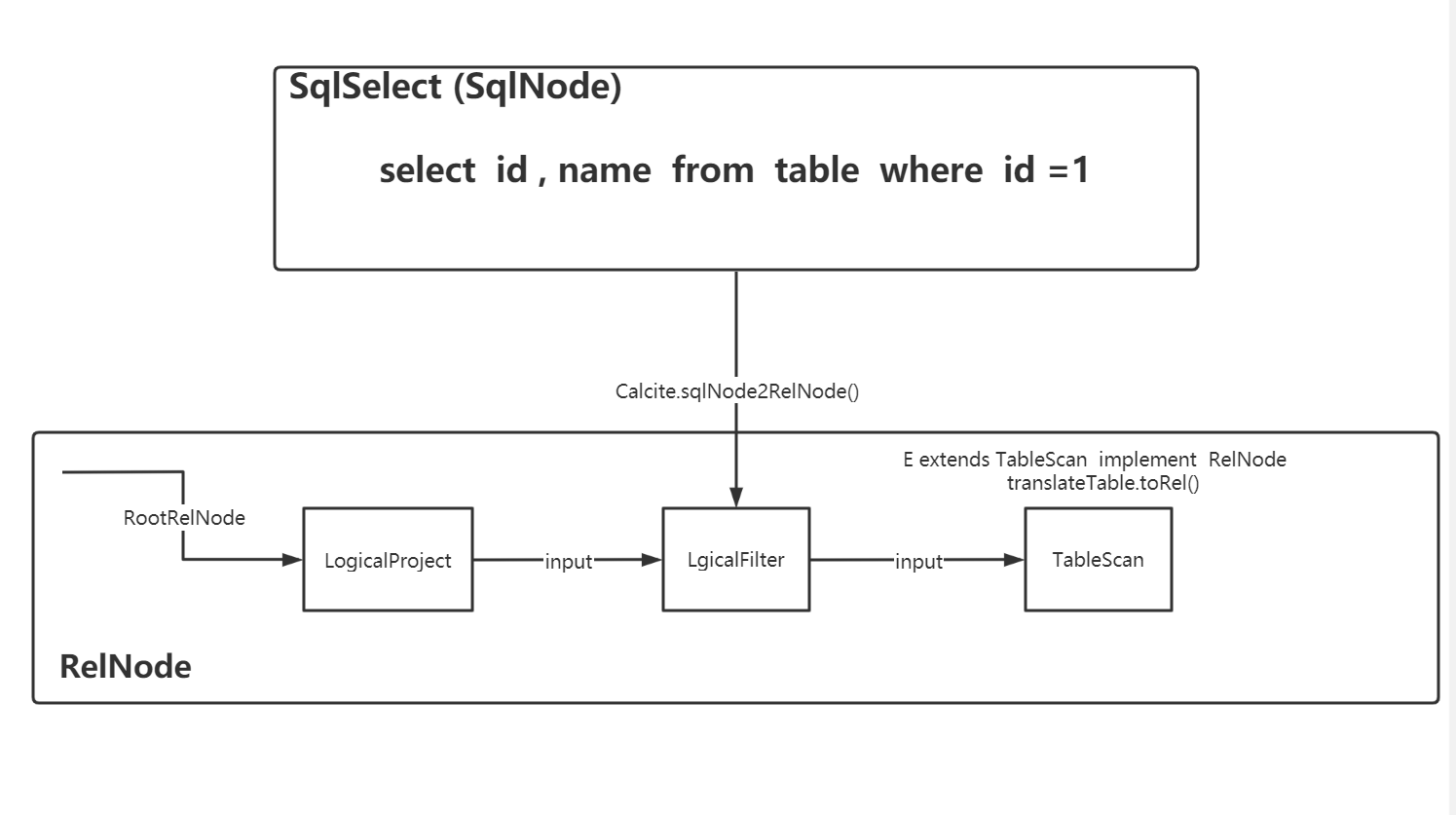
可以看到很多節點都是以Logical命名的,因為這是3階段通過calcite默認的轉化器(SqlToRelConverter)轉換而來的邏輯節點,邏輯節點是沒有物理屬性的也無法運行的
接下來進入calcite的代價cost優化器VolcanoPlanner進行優化

返回的就是代價最優的解
進去calcite的optimize方法
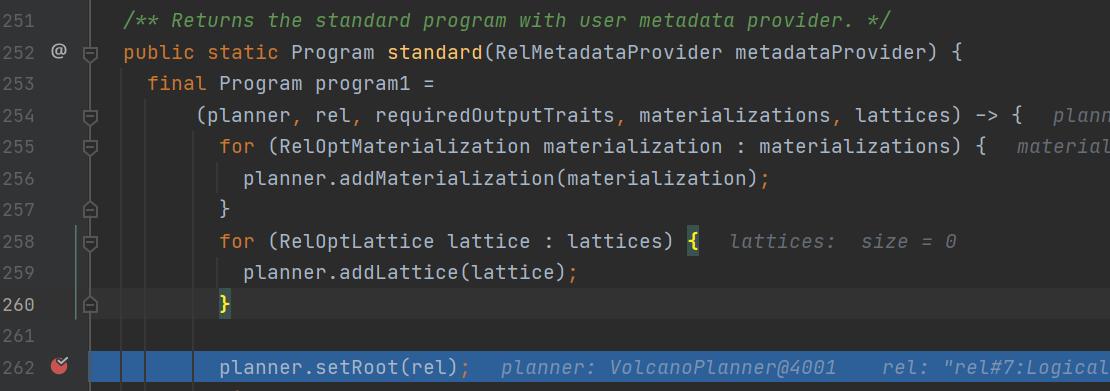
首先calcite會將我們上一階段得到的relNode設置到我們代價Volcano優化器的root里去
在其中 org.apache.calcite.plan.volcano.VolcanoPlanner.registerImpl() 方法中
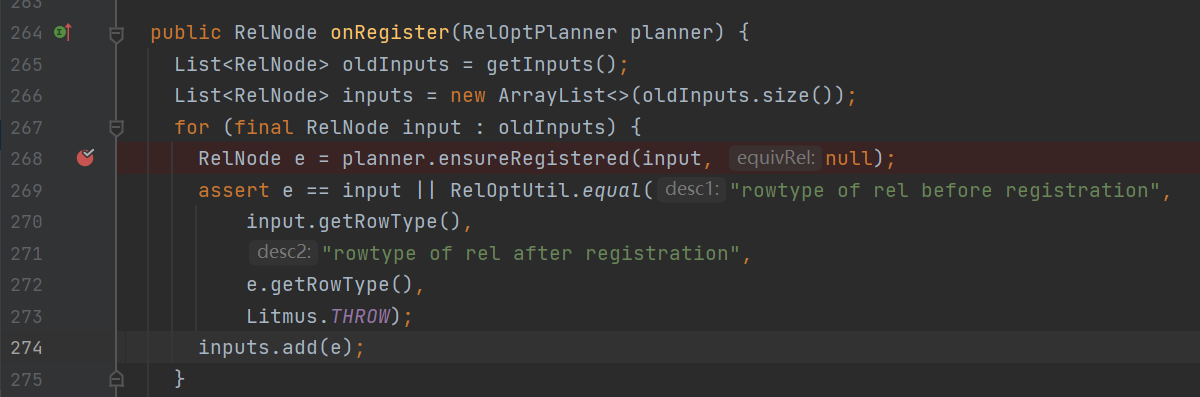
斷點的地方在register的過程中會先將relnode的input先註冊
在ensureRestered方法中
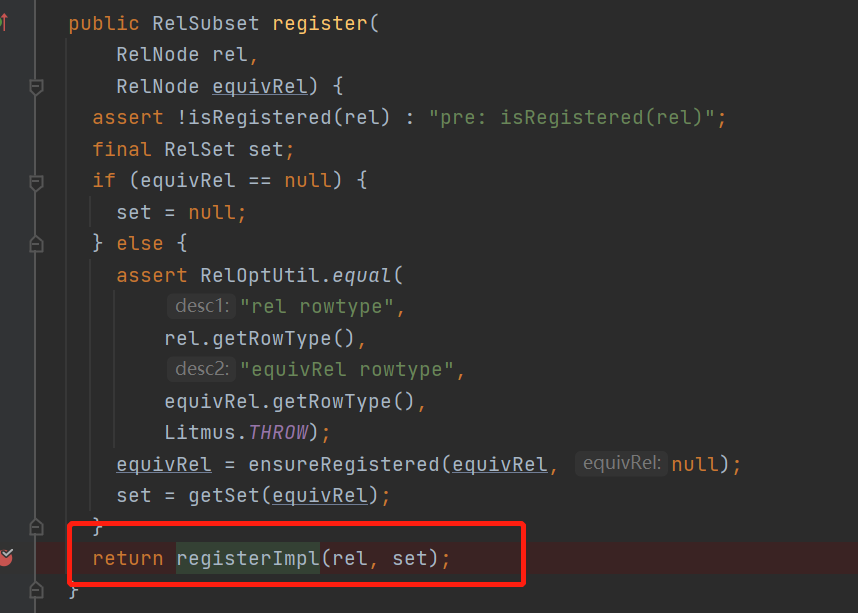
可以看到有繞回了registerImpl()方法
也就是樹的子節點深度遍歷先註冊
接下來看一下註冊過程
既然是深度遍歷回到剛才看的VolcanoPlanner.registerImpl()方法中看下onRegister()方法之後做了什麼

可以看到要觸發規則了,這裡就要穿插一個概念,calcite中的Rule

從類描述中我們可以知道,規則可以將一個表達式轉換成另一個,什麼意思呢,來看下有哪些抽象方法
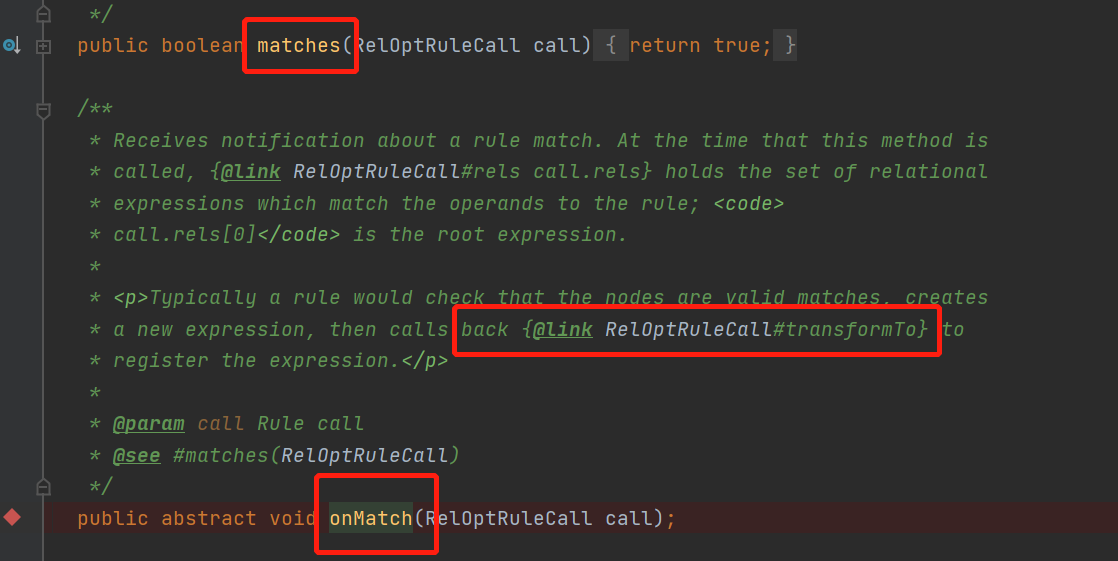
什麼意思呢?歸納起來就是兩個核心方法
matches()返回當前的relnode是否能匹配上此規則rule
onMatch () 當匹配上此規則時,這個方法會被調用,在其中可以調用transformTo()方法,這個方法的作用就是將一個relNode轉換成另一個relNode
規則就是整個calcite的核心了,其實所有的sql優化都是由對應的rule組成的,將sql的優化邏輯實現為對應的rule讓對應的relNode樹節點做對應的轉換來得到最優的best執行計劃
ok回到我們的主流程上,繼續上面的volcanoPlanner.fireRule()方法看看如何觸發規則的
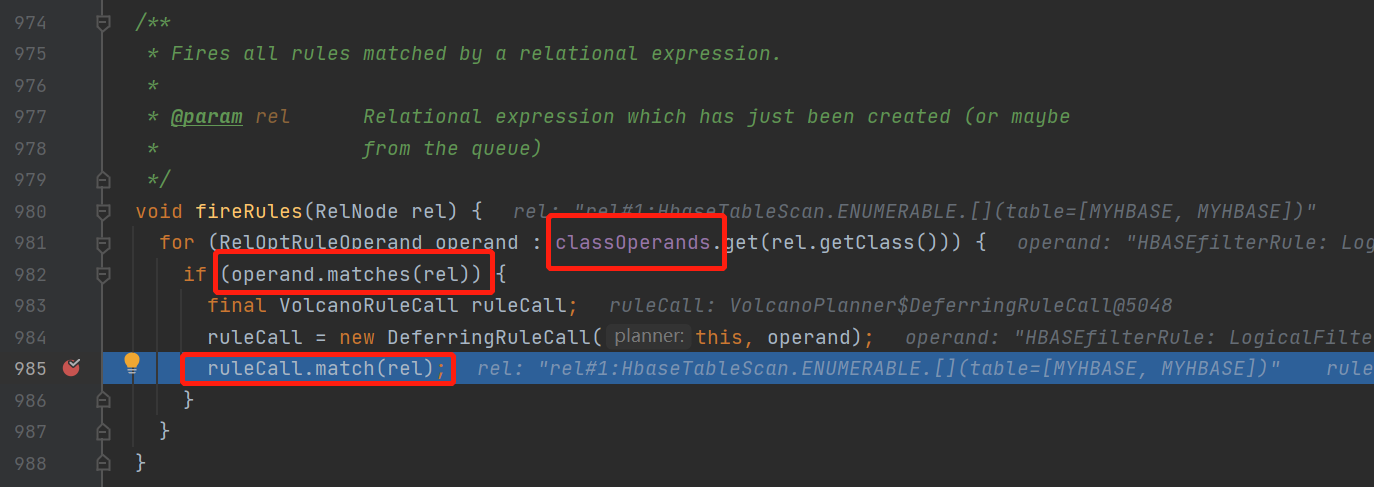
這裡邏輯是比較簡單的,就是當relnode滿足rule就調用volcanoRuleCall的match()方法
但是有個地方需要注意,這裡的classOperands這裡包含了relNode以及所有可能匹配上這個relnode的規則的映射關係,並且可以向上也可以向下
具體是什麼意思呢?
假設我有一個LogicFilter的RelNode,然後定義了兩個規則
RuleA
operand(Logicalfilter.class, operand(TableScan.class))
RuleB
operand(Logicalproject.class, operand(Logicalfilter.class))
那這兩個rule都會進入這個可能匹配上的映射關係classOperands裏面去
當匹配上rule以後,接着來繼續看代碼
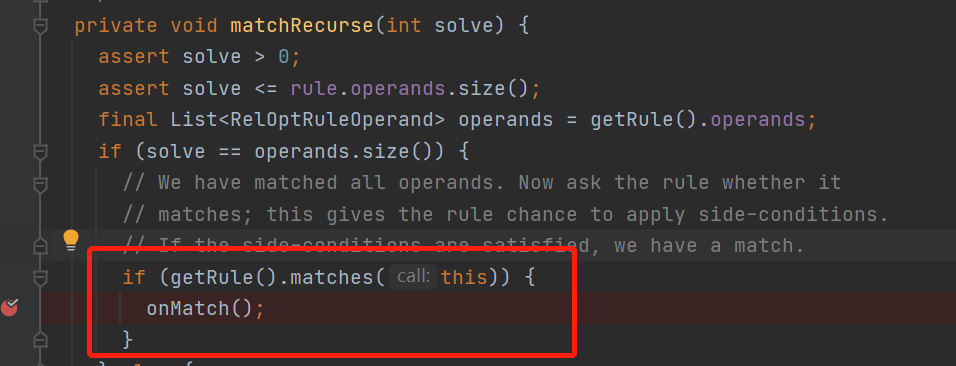
然後走到了volcanoPlanner.DeferringRuleCall的onMatch中
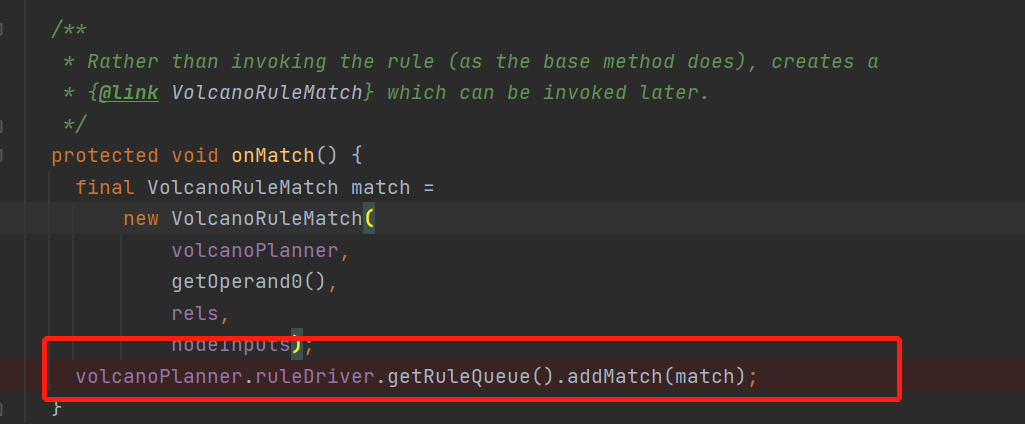
這裡就是把這個rule的加入到了IterativeRuleDriver中的ruleQueue,這個隊列就是專門用來存放已經匹配上的rule的,不難發現這些匹配上的rule只是存在隊列裏面,但還沒有執行這些規則
那多久會執行呢?
回到主流程當我們setRoot里的所有relnode子節點都register以後
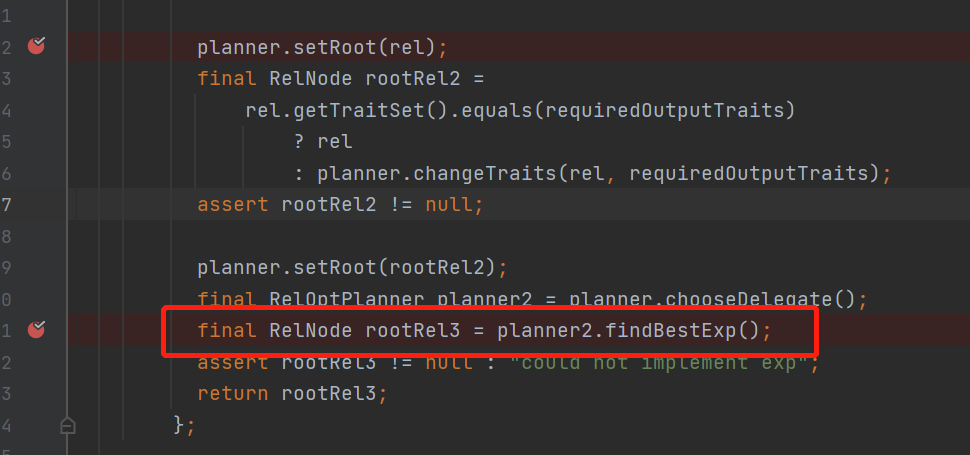
會走具體planner的findBestExp()方法,從名字可以看出來找到最優的表達式
這裡要提前說一下,claicte的優化原理是,它假定如果一個表達式最優,那它的局部也是最優的,那當前relNode的best我們也就只用關心,從
1.子節點的所有best加起來
2. 自己能匹配上的所有規則,以及剩下部位的best加起來
從中比較得到的就是當前relnode的最優解了
引用個圖
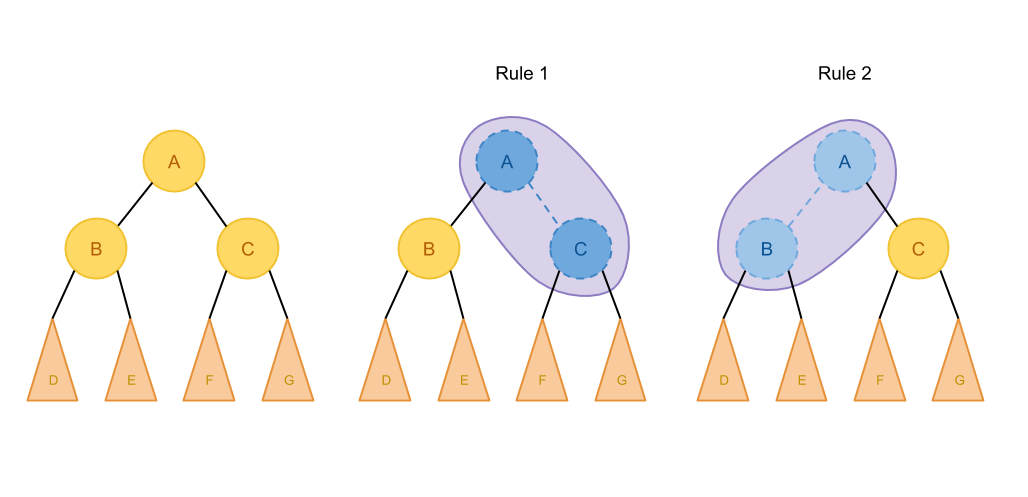
如果A只能匹配這兩種規則,那我們枚舉求最優解的時候就只用考慮這幾張情況
關於原理不太了解的可以看看這篇 //io-meter.com/2018/11/01/sql-query-optimization-volcano/
接着看findBestexp()
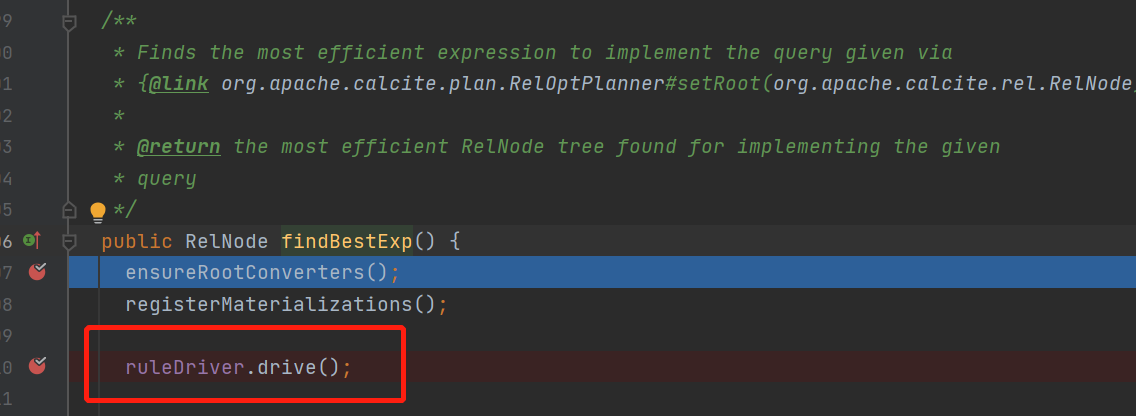
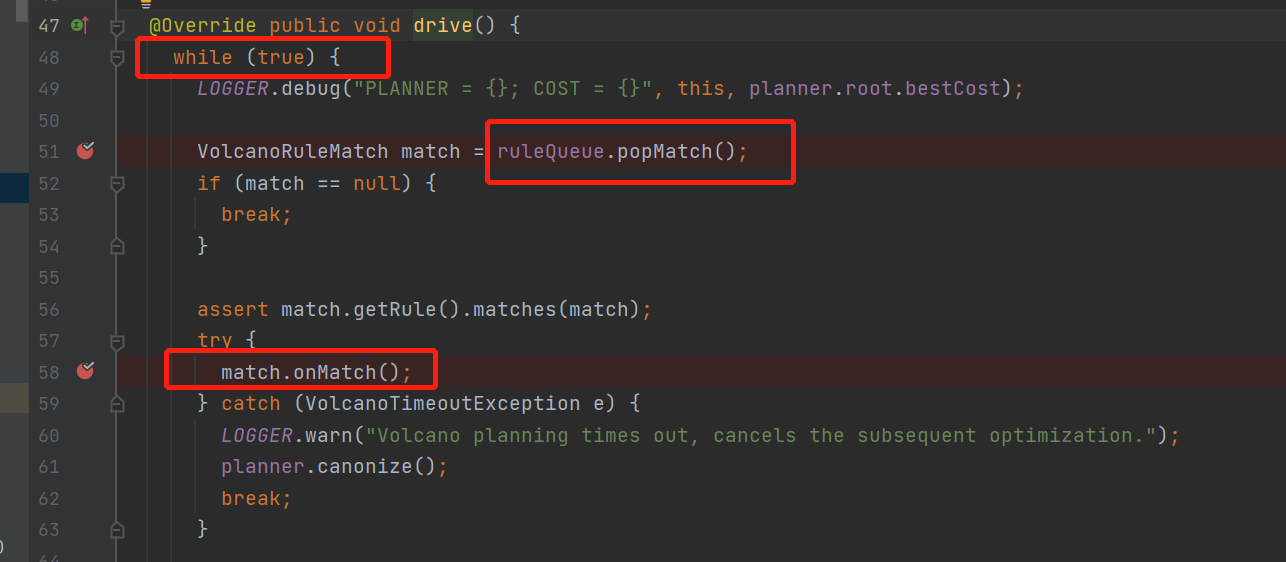
這裡就是整個優化尋找最優解bestExp的主loop了
不停的從queue中拿rule, 運行rule,直到所有rule都執行完才退出
沒錯這裡的這個queue就是前面說到的,當默認的relnode註冊進來的時候會把能匹配上的rule放這queue裏面去
這裡自然就有個疑問, 前面說到rule運行的時候會改變relNode節點,也就是添加relndoe的等價節點,
那這裡樹的結構變化會導致,之前不能匹配上的rule改變樹的結構後就能匹配上,那這裡能匹配上的rule不就漏了,那就接着看rule的onMatch()中用於轉換等價節點的方法transformTo()

其中轉換的新節點,在transformTo方法中又會執行register

也就是說新來的節點也會走一遍,默認relNode註冊的流程,當新節點註冊成等價節點會有新的規則匹配上的時候,又會將此rule加入rulequeu中等待下一次執行rule了
另外當這個relnode節點會被規則rule轉換時,生成的新relnode會被設置加入到這個relnode的等價節點中去
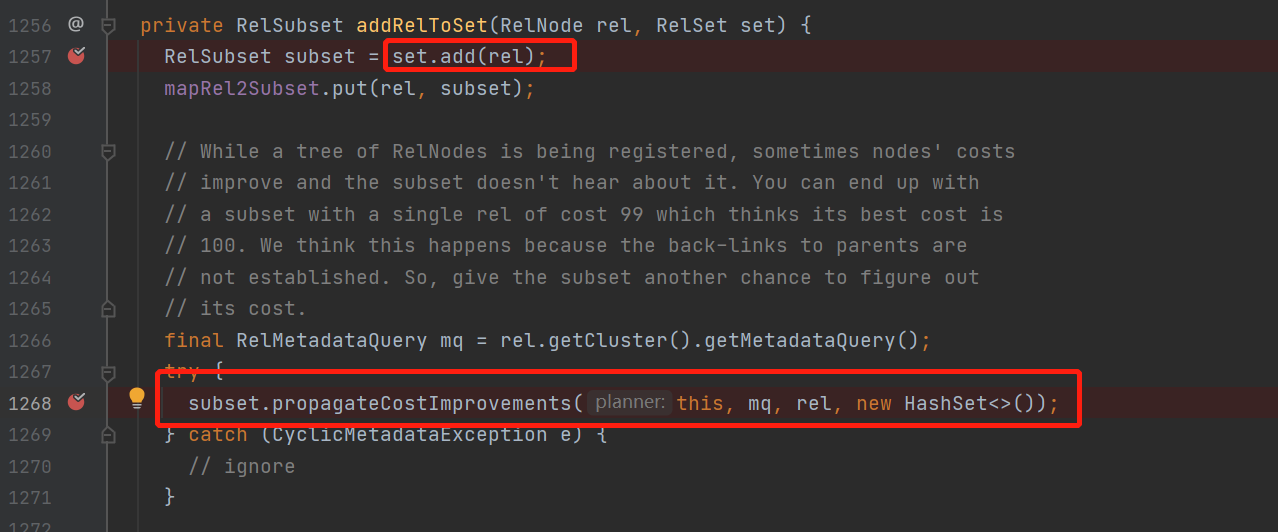
加入等價節點,並且在propagateCostImprovement方法中
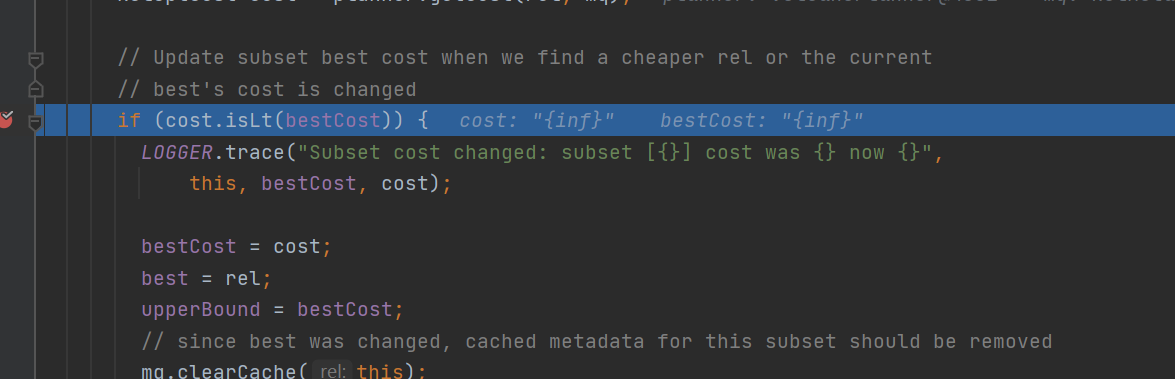
計算當前等價節點會不會使,當前relnode的cost代價下降,如果下降了,那就更新當前relnode的bestcost並且向上冒泡修改父relnode的最優bestCost
while true 一直觸發拉取ruleQueue中的rule,直到rule為空
然後rule會添加新的等價節點
新的等價節點如果更優cost,更新整棵樹的best Relnode
新的等價節點relnode會匹配上新的規則,新的rule加入到rulequeue中
進入下一次循環,直到沒有rule可以匹配上,這樣bestexp就可以返回優化後的最優的relnode了
之後就是根據這個最優的relnode,不同的框架翻譯成自己的api
calciet終於說完,,之後就可以開始解析flink sql的源碼了