寫操作系統之實現進程
C語言和彙編語言混合編程
方法
本節的「混合編程」不是指在C語言中使用彙編語言,或在彙編語言中使用C語言。它是指在C程序中使用彙編語言編寫的函數、變量等,或者反過來。
混合編程的核心技巧是兩個關鍵字:extern和global。
有A、B兩個源碼文件,A是C語言源碼文件,B是彙編語言源碼文件。在B中定義了變量、函數,要用global導出才能在A中使用;在B中要使用A中的變量、函數,要用extern導入。
用最簡單的話說:使用extern導入,使用global導出。
在A中使用B中的函數或變量,只需在B中導出。
在B中使用A中的函數或變量,只需在B中導入。
是這樣嗎?
請看例程。
例程
代碼
bar.c是C語言寫的源碼文件,foo.asm是彙編寫的源碼文件。在foo.asm中使用bar.c中創建的函數,在bar.c中使用foo.asm提供的函數。foo.asm創建的函數用global導出,使用bar.c中創建的函數前使用extern導入。
foo.asm。
extern choose
[section .data]
GreaterNumber equ 51
SmallerNumber equ 23
[section .text]
global _start
global _displayStr
_start:
push GreaterNumber
push SmallerNumber
call choose
add [esp+8] ; 人工清除參數佔用的棧空間
; 必須調用 exit,否則會出現錯提示,程序能運行。
mov eax, 1 ; exit系統調用號為1
mov ebx, 0 ; 狀態碼0:正常退出
int 0x80
ret
; _displayStr(char *str, int len)
_displayStr:
mov eax, 4 ; write系統調用號為4
mov ebx, 1 ; 文件描述符1:標準輸出stdout
; 按照C函數調用規則,最後一個參數最先入棧,它在棧中的地址最大。
mov ecx, [ebp + 4] ; str
mov edx, [ebp + 8] ; len。ebp + 0 是 cs:ip中的ip
int 0x80
ret ; 一定不能少
bar.c。
void choose(int a, int b)
{
if(a > b){
_displayStr("first", 5);
}else{
_displayStr("second", 6);
}
return;
}
代碼講解
導入導出
extern choose,把choose函數導入到foo.asm中。
global _displayStr,導出foo.asm中的函數,提供給其他文件例如bar.c使用。
系統調用
系統調用模板。
; code-A
mov eax, 4 ; write系統調用號為4
mov ebx, 1 ; 文件描述符1:標準輸出stdout
; 按照C函數調用規則,最後一個參數最先入棧,它在棧中的地址最大。
mov ecx, [ebp + 4] ; str
mov edx, [ebp + 8] ; len。ebp + 0 是 cs:ip中的ip
int 0x80
; code-B
; 必須調用 exit,否則會出現錯提示,程序能運行。
mov eax, 1 ; exit系統調用號為1
mov ebx, 0 ; 狀態碼0:正常退出
int 0x80
兩段代碼展示了系統調用int 0x80的用法。暫時不必理會「系統調用」這個概念。
使用int 0x80時,eax的值是希望執行的系統函數的編號。例如,exit的編號是1,當eax中的值是1時,int 0x80會調用exit。write的編號是4。
exit和write的函數原型如下。
void exit(int status);
int write(int handle, void *buf, int nbyte);
ebx、ecx、edx中的值分別是系統調用函數的第一個參數、第二個參數、第三個參數。
編譯運行
用下面的命令編譯然後運行。
nasm -f elf foo.o foo.asm
gcc -o bar.o bar.c -m32
ld -s -o kernel.bin foo.o bar.o -m elf_i386
# 運行
./kernel.bin
切換堆棧和GDT
是什麼
在《開發加載器》中,我們已經完成了一個簡單的內核。那個內核是用彙編語言寫的,使用的GDT在實模式下創建。在以後的開發中,我們講主要使用C語言開發。能在C語言中使用彙編語言中的變量,例如GDT,可是,要往GDT中增加一個全局描述符或修改全局描述符的屬性,在C語言中,就非常不方便了。到了用C語言編寫的內核源代碼中,要想方便地修改GDT或其他在彙編中創建的變量,需要把用彙編源碼創建的GDT中的數據複製到用C語言創建的變量中來。
切換GDT,簡單地說,就是,把彙編源代碼中的變量的值複製到C語言源代碼中的變量中來。目的是,在C語言源代碼中更方便地使用這些數據。
切換堆棧,除了使用更方便,還為了修改堆棧的地址。
切換堆棧的理由,我也不是特別明白這樣做的重要性。
怎麼做
- 彙編代碼文件kernel.asm,C語言代碼文件main.c。
- 在C語言代碼中定義變量
gdt_ptr。 - 在kernel.asm中導入
gdt_ptr。 - 在kernel.asm中使用
sgdt [gdt_ptr]把寄存器gdtptr中的數據保存到變量gdt_ptr中。 - 在main.c中把GDT複製到main.c中的新變量中,並且修改GDT的界限。
- 在kernel.asm中重新加載
gdt_ptr中的GDT信息到寄存器gdtptr中。
請在下面的代碼中體會上面所寫的流程。
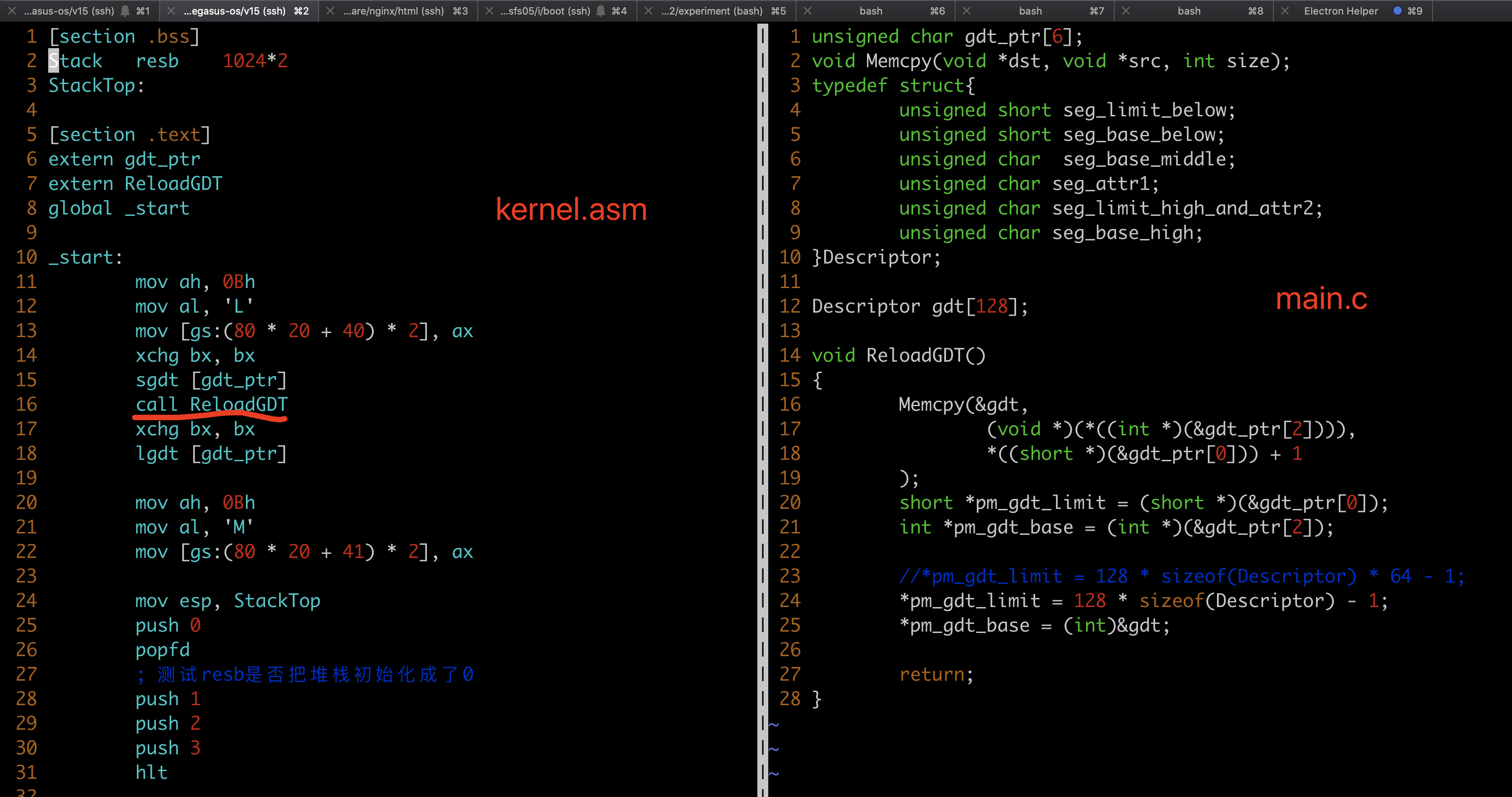
代碼講解
sgdt [gdt_ptr],把寄存器gdtptr中的數據保存到外部變量gdt_ptr中。
寄存器gdtptr中存儲的數據的長度是6個位元組,前2個位元組存儲GDT的界限,後4個位元組存儲GDT的基地址。在《開發引導器》中詳細講解過這個寄存器的結構,不清楚的讀者可以翻翻那篇文章。
切換GDT
void Memcpy(void *dst, void *src, int size);
typedef struct{
unsigned short seg_limit_below;
unsigned short seg_base_below;
unsigned char seg_base_middle;
unsigned char seg_attr1;
unsigned char seg_limit_high_and_attr2;
unsigned char seg_base_high;
}Descriptor;
Descriptor gdt[128];
Memcpy(&gdt,
(void *)(*((int *)(&gdt_ptr[2]))),
*((short *)(&gdt_ptr[0])) + 1
);
把在實模式下建立的GDT複製到新變量gdt中。
這段代碼非常考驗對指針的掌握程度。我們一起來看看。
gdt_ptr[2]是gdt_ptr的第3個位元組的數據。&gdt_ptr[2]是gdt_ptr的存儲第3個位元組的數據的內存空間的內存地址。(int *)(&gdt_ptr[2])),把內存地址的數據類型強制轉換成int *。一個內存地址,只能確定是一個指針類型,但不能確定是指向哪種數據的指針。強制轉換內存地址的數據類型為int *後,就明確告知編譯器這是一個指向int數據的指針。- 指向int數據的指針意味着什麼?指針指向的數據佔用4個位元組。
(*((int *)(&gdt_ptr[2])))是指針(int *)(&gdt_ptr[2]))指向的內存空間(4個位元組的內存空間)中的值。從寄存器gdtptr的數據結構看,這個值是GDT的基地址,也是一個內存地址。Memcpy的函數原型是void Memcpy(void *dst, void *src, int size);,第一個參數dst的類型是void *,是一個內存地址。(void *)(*((int *)(&gdt_ptr[2])))中最外層的(void *)把內存地址強制轉換成了void *類型。gdt_ptr[0])是gdt_ptr的第1個位元組的數據,&gdt_ptr[0])是存儲gdt_ptr的第1個位元組的數據的內存空間的內存地址。(short *)(&gdt_ptr[0]),把內存地址的數據類型強制轉換成short *。short *ptr這種類型的指針指向兩個位元組的內存空間。假如,ptr的值是0x01,那麼,short *ptr指向的內存空間是內存地址為0x01、0x02的兩個位元組。- 說得再透徹一些。
short *ptr,指向一片內存空間,ptr的值是這片內存空間的初始地址,而short *告知這片內存空間的長度。short *表示這片內存空間有2個位元組,int *表示這片內存空間有4個位元組,char *表示這片內存空間有1個位元組。 *((short *)(&gdt_ptr[0]))是內存空間中的值,是gdt_ptr[0]、gdt_ptr[1]兩個位元組中存儲的數據。從gdtptr的數據結構來看,這兩個位元組中存儲的是GDT的界限。- GDT的長度 = GDT的界限 + 1。
- 現在應該能理解
Memcpy這條語句了。從GDT的基地址開始,複製GDT長度那麼長的數據到變量gdt中。 gdt是C代碼中存儲GDT的變量,它的數據類型是Descriptor [128]。Descriptor是表示描述符的結構體。gdt是包含128個描述符的數組。這符合GDT的定義。- 把GDT從彙編代碼中的變量或者說某個內存空間複製到gdt所表示的內存空間後,就完成了GDT的切換。
修改gdtptr
先看代碼,然後講解代碼。下面的代碼緊跟上面的代碼。可在本節的開頭看全部代碼。
short *pm_gdt_limit = (short *)(&gdt_ptr[0]);
int *pm_gdt_base = (int *)(&gdt_ptr[2]);
//*pm_gdt_limit = 128 * sizeof(Descriptor) * 64 - 1;
*pm_gdt_limit = 128 * sizeof(Descriptor) - 1;
*pm_gdt_base = (int)&gdt;
- 由於GDT已經被保存到了新的內存空間中,以後將使用這片內存中的GDT,所以,需要更新寄存器
gdtptr中存儲的GDT的基地址和GDT界限。 - 使用
lgdt [gdt_ptr]更新gdtptr中的值。要更新gdtptr中的值,需要先更新gdt_ptr中的值。 - 更新
gdt_ptr的過程,又是玩耍指針的過程。熟悉指針的讀者,能輕鬆看懂這幾條語句,不需要我啰里啰嗦的講解。 - 在前面,我說過,指針,表示這個變量的值是一個內存地址;而指針的類型(或者說指針指向的數據的數據類型)告知從這個內存地址開始有多少個位元組的數據。再說得簡單一些:指針,告知內存的初始地址;指針的類型,告知內存的長度。
pm_gdt_limit是一個short *指針。它的含義是是一段初始地址是&gdt_ptr[0]、長度是2個位元組的內存空間。這是什麼?聯想到寄存器gdtptr的數據結構,它是GDT的界限。- 用通用的方法理解
pm_gdt_base。它是GDT的基地址。 - 新的GDT表中有128個描述符,相應地,新GDT的界限是
128個描述符*一個描述符的長度-1。 - 更新
gdt_ptr的前2個位元組的數據的語句是*pm_gdt_limit = 128 * sizeof(Descriptor) - 1。 - 如果理解這種語句有困難,就理解它的等價語句:
mov [eax], 54。 - 新GDT的基址是多少?就是變量gdt的內存地址。
更新gdt_ptr的值後,在彙編代碼中用lgdt [gdt_ptr]重新加載新GDT到寄存器gdtptr中。就這樣,完成了切換GDT。
切換堆棧
代碼講解
把esp的中的數據修改為進入內核後的一段內存空間的初始地址,這就是切換堆棧。
切換堆棧的相關代碼如下。我們先看代碼,然後理解關鍵語句。
[section .bss]
Stack resb 1024*2
StackTop:
[section .text]
mov esp, StackTop
Stack resb 1024*2,從Stack所表示的內存地址開始,把2048個byte設置成0。
StackTop:是一個標號,表示一段2kb的內存空間的堆棧的棧頂。
mov esp, StackTop,把堆棧的棧頂設置成StackTop。
[section .bss],表示後面的代碼到下一個節標識前都是.bss節,一般放置未初始化或初始化為0的數據。
[section .text],表示後面的代碼到下一個標識前都是.text節,一般放置指令。
在彙編語言寫的源文件中,這些節標識是給程序員看的,非要把數據初始化寫到.text節,編譯器也能給你正常編譯。
push 0
;push 0xFFFFFFFF
popfd
popfd把當前堆棧棧頂中的值更新到eflags中。
eflags
eflags是一個寄存器。先看看它的結構圖。
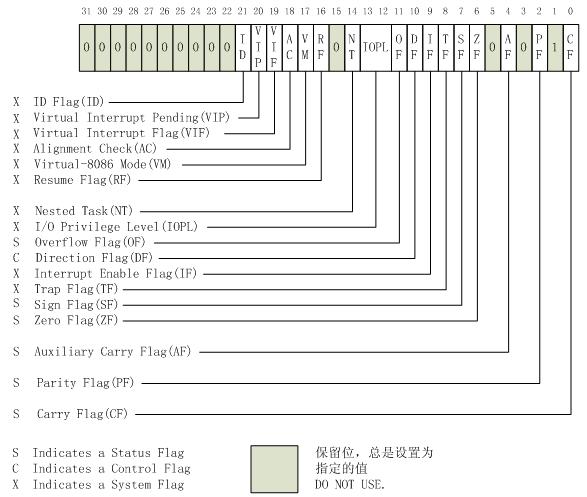
不用我多說,看一眼這張圖,就知道它有多複雜。
eflags有32個位元組,幾乎每個位元組都有不同的含義。要完全弄明白它很費時間。我只掌握下面這些。
- 在bochs中查看eflags的值,使用
info eflags。對查看到的結果,大寫的位表示為1,小寫的表示為0;如:SF 表示1,zf 表示0。 - 使用
popfd或popf能更新eflags的值。pof,將棧頂彈入 EFLAGS 的低 16 位。popfd,將棧頂彈入 EFLAGS的全部空間。
- 算術運算和eflags的狀態標誌(即CF、PF、AF、ZF、SF)這些有關係。例如,算術運算的結果的最高位進位或錯位,CF將被設置成1,反之被設置成0。
下面是在bochs中查看到的eflags中的值。
# code-A
eflags 0x00000002: id vip vif ac vm rf nt IOPL=0 of df if tf sf zf af pf cf
<bochs:4> info eflags
id vip vif ac vm rf nt IOPL=0 of df if tf sf zf af pf cf
# code-B
eflags 0x00247fd7: ID vip vif AC vm rf NT IOPL=3 OF DF IF TF SF ZF AF PF CF
<bochs:9> info eflags
ID vip vif AC vm rf NT IOPL=3 OF DF IF TF SF ZF AF PF CF
錯位是什麼?
code-A。eflags 0x00000002的意思是,eflags的初始值是0x00000002。對照eflags的結構圖,第1位是保留位,值是1,其他位全是0,最終結果就是0x2。
code-B。eflags 0x00247fd7,eflags的初始值是0x00247fd7。為什麼會是這個結果?因為我入棧數據
0xFFFFFFFF,然後執行了popfd。換言之,我把eflags的值設置成了0xFFFFFFFF。然而eflags中有些保留位的值總是0,有些非保留位又必須是某種值,0xFFFFFFFF和這些默認值(或保留值)綜合之後變成了0x00247fd7。說了這麼多,最重要的一點是:解讀info eflags的結果。eflags 0x00000002中的0x00000002是eflags中的數據。
中斷
本篇的中心是實現進程,我想從本文第一個字開始就寫怎麼實現進程。可是實現進程需要用到GDT、堆棧,還要用到中斷。不先寫這些,先寫進程,寫進程時要用到這些再寫這些內容,那成了倒敘了。到時候,寫進程的實現不能連貫又要插入中斷這些內容。
是什麼
現代操作系統都支持多進程。我們的電腦上同時運行瀏覽器、聽歌軟件和編輯器,就是證明。同一時刻、同一個CPU只運行一個進程。CPU怎麼從正在運行的進程轉向執行另外一個進程呢?為進程切換提供契機的就是中斷。
CPU正在運行瀏覽器,我們敲擊鍵盤,會產生鍵盤中斷,CPU會執行鍵盤中斷例程。
CPU正在運行瀏覽器,即使我們沒有敲擊鍵盤,可是CPU已經被瀏覽器使用了很長時間,按一定頻率產生的時鐘中斷髮生,CPU會在執行時鐘中斷例程時切換到其他進程。
上面是幾個中斷的例子。看了這些例子,回答一下中斷是什麼?中斷,就是停止正在執行的指令,陷入操作系統指令,目的往往是切換到其他指令。
實現機制–通俗版
再用通俗的例子,從中斷的實現機制,說明中斷是什麼。用數組對比理解中斷的實現機制。
- 中斷髮生,產生一個中斷向量號(數組索引)。
- 在IDT(數組)中,根據向量號(數組索引),找到中斷例程(數組元素)。
- 執行中斷例程。
簡單說,發生了一件事,CPU中止手頭的工作,去執行另一種工作。每件事都有對應的工作。
中斷分為內部中斷和外部中斷。
讀取軟盤使用的int 13是內部中斷,敲擊鍵盤產生的中斷是外部中斷,時鐘中斷也是外部中斷。
實現機制–嚴謹版
實現流程
- 建立中斷向量表。
- 創建變量
IdtPtr,用GdtPtr類比理解。必須緊鄰中斷向量表。 - 創建中斷向量表中的向量對應的中斷例程。不確定是否需要緊鄰中斷向量表,我目前是這麼做的。
- 用
lidt [IdtPtr]把中斷向量表的內存地址等信息加載到寄存器IDTPtr。用GdtPtr寄存器類比理解這個寄存器。
工作流程
- 根據中斷向量號在IDT中找到中斷描述符。
- 中斷描述符中包含中斷例程所在代碼段的選擇子和中斷例程在代碼段中的偏移量。
- 根據選擇子和偏移量找到中斷例程。
- 運行中斷例程。
再看看下面這張圖,想必能很好理解上面的文字了。
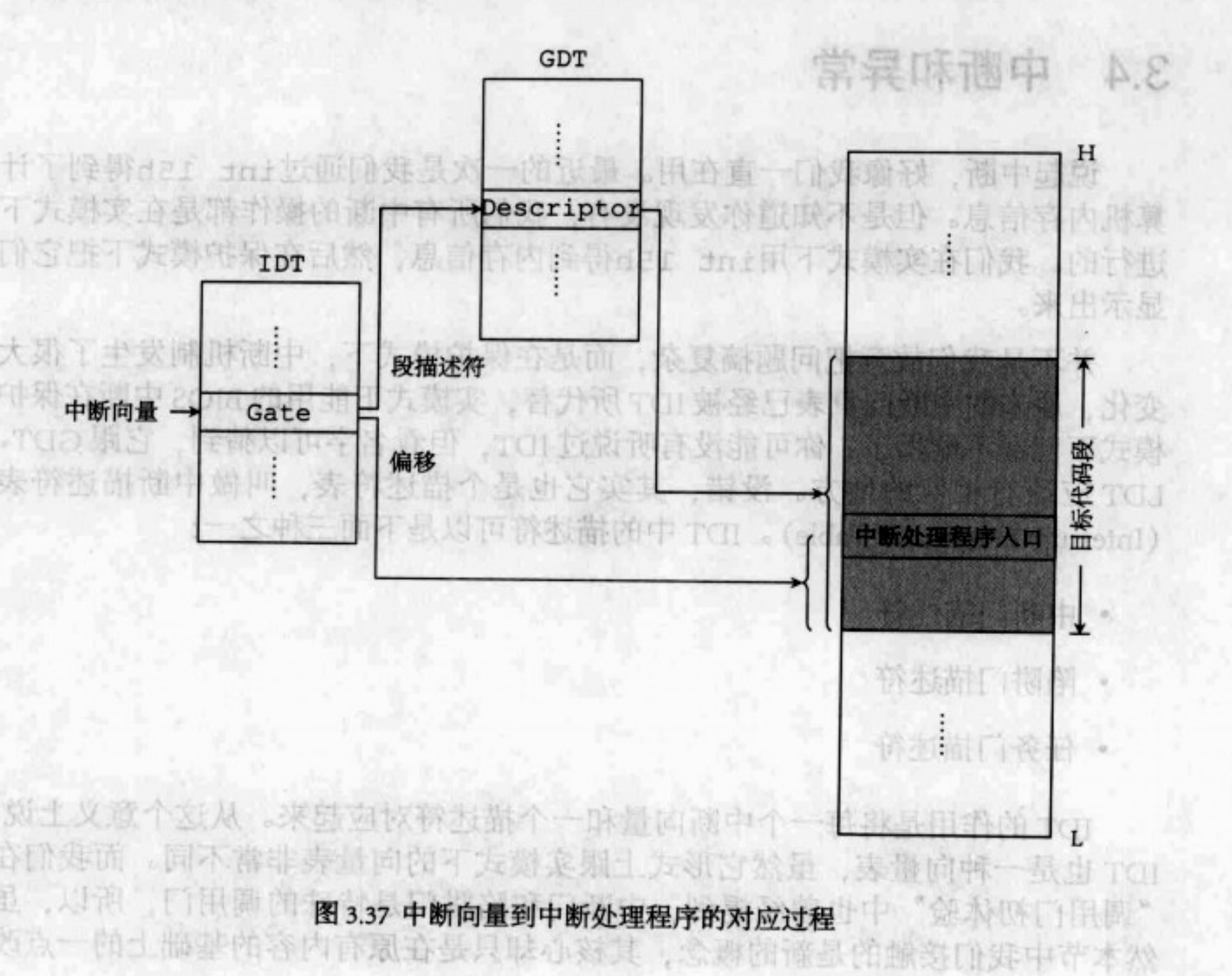
代碼
前面講過的工作流程,會在下面的代碼中一一體現。一起來看看。
建立IDT
IDT是中斷向量表。類似GDT,也是內存中的一塊區域。但它內部包含的全是”門描述符”。
IDT中的每個門描述符的名稱是中斷向量號,選擇子是中斷向量號對應的處理中斷的代碼。
; 門
; 門描述符,四個參數,分別是:目標代碼段的偏移量、目標代碼段選擇子、門描述符的屬性、ParamCount
%macro Gate 4
dw (%1 & 0FFFFh) ; 偏移1
dw %2 ; 選擇子
dw (%4 & 1Fh) | ((%3 << 8) & 0FF00h) ; 屬性
dw ((%1 >> 16) & 0FFFFh) ; 偏移2
%endmacro ; 共 8 位元組
; 門描述符,四個參數,分別是:目標代碼段的偏移量、目標代碼段選擇子、門描述符的屬性、ParamCount
; 屬性是 1110,或者是0111。不確定是小端法或大端法,所以有兩種順序的屬性。
; 屬性是 0111 0001。錯誤.
; 屬性應該是 1000 1110
[SECTION .idt]
ALIGN 32
[BITS 32]
LABEL_IDT:
%rep 32
Gate Superious_handle, SelectFlatX, 08Eh, 0 ; 屬性是 1110,或者是0111。不確定是小端法或大端法,所以有兩種順序的屬性。
%endrep
.20h: Gate ClockHandler, SelectFlatX, 08Eh, 0
;.80h: Gate ClockHandler, SelectFlatX, 08Eh, 0
%rep 222
Gate Superious_handle, SelectFlatX, 08Eh, 0
%endrep
IDT_LEN equ $ - LABEL_IDT
IdtPtr dw IDT_LEN - 1
dd 0
;END OF [SECTION .idt]
SelectFlatX是一個GDT選擇子,ClockHandler是中斷例程在這個選擇子指向的代碼段中的偏移量。
IDT是門描述符(一種數據結構,類似GDT中的全局描述符)組成的表,佔據一段內存空間。確定一段內存空間只需兩個要素:初始地址和界限大小。IdtPtr就提供了這兩個要素。
使用下面的語句把IDT的初始地址和界限大小加載到IDTPtr寄存器。
lidt [IdtPtr]
建立中斷例程
_SpuriousHandler:
SpuriousHandler equ _SpuriousHandler - $$
mov al, 'A'
mov ah, 0Fh
mov [gs:(80*20+20)*2], ax
iretd
_UserIntHandler:
UserIntHandler equ _UserIntHandler - $$
mov al, 'A'
mov ah, 0Fh
mov [gs:(80*20+20)*2], ax
iretd
_ClockHandler:
ClockHandler equ _ClockHandler - $$
; error: operation size not specified
;inc [gs:(80*20 + 21)*2]
xchg bx, bx
inc byte [gs:(80*20 + 21)*2]
; 發送EOF
mov al, 20h
out 20h, al
; 不明白iretd和ret的區別
iretd
上面的代碼和IDT在同一代碼段。SpuriousHandler、UserIntHandler是段內的兩個偏移量。
_SpuriousHandler:
SpuriousHandler equ _SpuriousHandler - $$
mov al, 'A'
mov ah, 0Fh
mov [gs:(80*20+20)*2], ax
iretd
不能完全理解這種寫法。不過,可暫且當作一種語法規則去記住就行了。以後有類似功能需要實現,就用這種寫法。不過,我也試着分享一下自己的看法。
上面的代碼其實等價於下面的代碼。
SpuriousHandler equ _SpuriousHandler - $$
_SpuriousHandler:
mov al, 'A'
mov ah, 0Fh
mov [gs:(80*20+20)*2], ax
iretd
要了解這段代碼,需了解一點彙編知識。
彙編語言中有個概念「標號”。上面的SpuriousHandler和_SpuriousHandler就是標號,前者是非指令的標號,後者是指令的標號。指令的標號必須在標識符後面加上冒號。上面的中斷例程中的_SpuriousHandler後面確實有冒號。指令前的標號表示這塊指令中的第一條指令的內存地址。
使用宏Gate創建中斷描述符,需要用到中斷例程在段內的偏移量。_SpuriousHandler是在內存中的內存地址,這個內存地址是相對於本段段首的內存地址還是相對於其他某個參照量呢?我也不知道。假如,這個內存地址是相對於其他某個參照量,它就不是在本段內的偏移量。為了確保在宏中使用的是偏移量,因此我們使用_SpuriousHandler - $$也就是SpuriousHandler而不是_SpuriousHandler。
當中斷向量號是在0~127(包括0和127)時,會執行中斷處理代碼SpuriousHandler。
當中斷向量號是080h時,會執行中斷處理代碼UserIntHandler。
調用中斷
調用中斷的語句很簡單,如下:
int 00h
int 01h
int 10h
int 20h
小結
- 中斷,由硬件或軟件觸發,迫使CPU停止執行當前指令,切換到其他指令,目的是讓計算機響應新工作。
- 提供中斷向量,在IDT中尋找中斷描述符,根據在中斷描述符中找到的段選擇子和偏移量,找到中斷例程並執行。
- 一句話,根據中斷向量找到中斷例程並執行。
- 為什麼能根據中斷向量找到中斷例程?這是更底層的硬件工作機制。我們只需為硬件提供IDT的初始地址和界限就行。
- 本小節介紹中斷省略了中斷髮生時保存CPU的快照、堆棧和特權級的轉移。
外部中斷
時鐘中斷、鍵盤中斷、鼠標中斷,還有其他中斷在同一時刻產生,CPU應該處理哪個中斷?事實上,CPU並不直接和這些產生中斷的硬件打交道,而是通過一個」代理”。代理會按照優先級規則從眾多中斷中挑選一個再交給CPU處理。
處理中斷的這個代理就是8259A。它是一個硬件。看看8259A的示意圖。
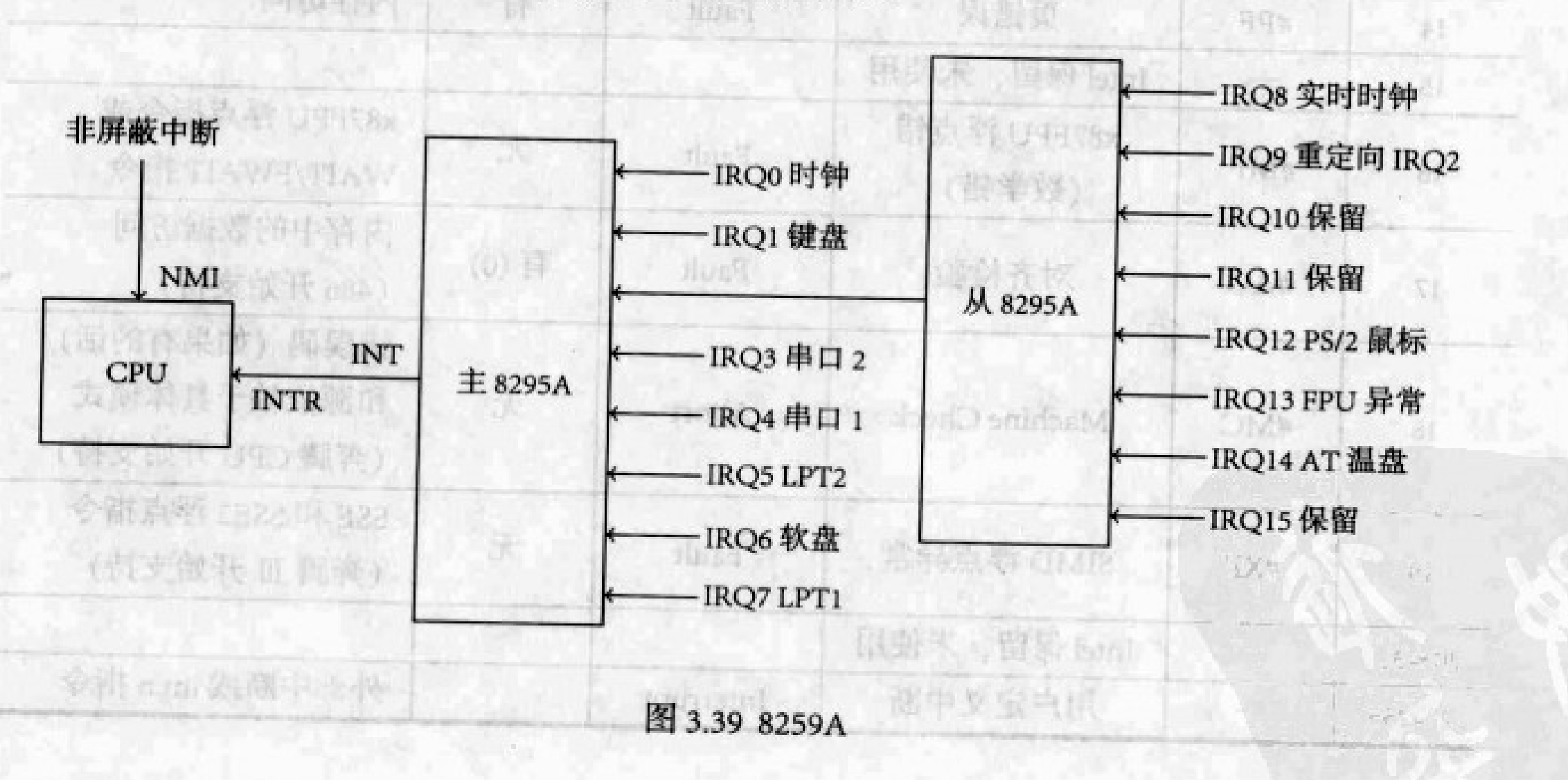
8259A只是處理可屏蔽中斷的代理。
8259A
我們使用兩個8259A,一個是主片,一個是從片,從片掛載在主片上。
8259A有8個引腳,每個引腳能掛載一個會產生中斷的硬件,例如硬盤;當然,每個引腳也能掛載另外一個8259A。主從兩個8259A能掛載15個硬件。
8259A是可編程硬件,通過向相應的端口寫入ICW和OCW數據實現編程。下面的代碼展示了如何對它編程。
初始化8259A
; /home/cg/os/pegasus-os/v25/kernel.asm
Init_8259A:
; ICW1
mov al, 011h
out 0x20, al
call io_delay
out 0xA0, al
call io_delay
; ICW2
mov al, 020h
out 0x21, al
call io_delay
mov al, 028h
out 0xA1, al
call io_delay
; ICW3
mov al, 004h
out 0x21, al
call io_delay
mov al, 002h
out 0xA1, al
call io_delay
; ICW4
mov al, 001h
out 0x21, al
call io_delay
out 0xA1, al
call io_delay
; OCW1
;mov al, 11111110b
mov al, 11111101b
out 0x21, al
call io_delay
mov al, 11111111b
out 0xA1, al
call io_delay
ret
; 讓CPU空轉四次
io_delay:
; 讓CPU空轉一次
nop
nop
nop
nop
ret
ICW和OCW的數據結構
ICW的全稱是Initialization Command Word,OCW的全稱是Operation Commnd Word。
OCW簡單一些,只需寫入ICW1就能滿足我們的需求。向主8259A的0x21寫入OCW1,向從8259A的0xA1寫入OCW1,作用是屏蔽或放行某個中斷,1表示屏蔽,0表示放行。
四個ICW都被用到了。必須按照下面的順序寫入ICW和OCW。
- 通過0x20端口向主8259A寫入ICW1,通過0xA0端口向從8259A寫入ICW1。
- 通過0x21端口向主8259A寫入ICW2,通過0xA1端口向從8259A寫入ICW2。
- 通過0x21端口向主8259A寫入ICW3,通過0xA1端口向從8259A寫入ICW3。
- 通過0x21端口向主8259A寫入ICW4,通過0xA1端口向從8259A寫入ICW4。
- 向主8259A的0x21寫入OCW1,向從8259A的0xA1寫入OCW1。
像這樣寫入數據,有點怪異。
寫入ICW2、ICW3、ICW4的端口相同,怎麼區分寫入的數據呢?我是這樣理解的。由8259A自己根據寫入的端口和順序來識別。對於主片,第一次向0x20端口寫入的是ICW1,第二次向0x21端口寫入的是ICW2,第三次向0X21端口寫入的是ICW3,第五次向0x21端口寫入的是OCW1。從片也像這樣根據端口和順序來識別接收到的數據。
為什麼要這麼寫代碼?我猜測,是8259A提供的使用方法要求這麼做。不必糾結這個。就好比使用微信支付的SDK,不需要糾結為啥要求按某種方式傳參一樣。
需要我們仔細琢磨的是ICW和OCW的數據結構。先看它們的數據結構圖,再逐個分析它們的值。

ICW1的值是011h,把011h轉換成二進制數據是00010001b。對照ICW1的數據結構,第0位是1,表示需要寫入ICW4。第1位是0,表示主8259A掛載了從8259A。第4位是1,因為8259A規定ICW1的第4位必須是1。其他位都是0,對照上圖中的ICW1能很容易看明白。
ICW2表示8259A掛載的硬件對應的中斷向量號的初始值。主8259A的ICW2的值是020h,表示掛載在它上面的硬件對應的中斷向量號是020h到027h。主8259A的ICW2的值是028h,表示掛載在它上面的硬件對應的中斷向量號是028h到02Fh。
ICW3的數據結構比較特別,主片的ICW3的數據結構和從片的ICW3的格式不同。主片的ICW3用位圖表示序號,從片的ICW3用數值表示序號。主片的ICW3是004h,把004h轉化成二進制數00000100b,第2個bit是1,表示主片的第2個引腳(引腳編號的初始值是0)掛載從片。從片的ICW3是002h,數值是2。
ICW3的工作機制是這樣的。從片認為自己掛載到了主片的第2個引腳上。主片向所有掛載在它上面的硬件發送數據時,數據中會包含這些數據的接收方是掛載在第2個引腳上的硬件。每個硬件接收到數據後,檢查一下自己的ICW3中的值是不是2,如果是2,就認為這些數據是發給自己的;如果不是2,就認為這些數據不是發給自己的然後丟棄這些數據。
OCW1的結構很簡單。下圖右側的注釋是主片的,如果是從片,只需把IRQ0到IRQ7換成IRQ0到IRQ15。
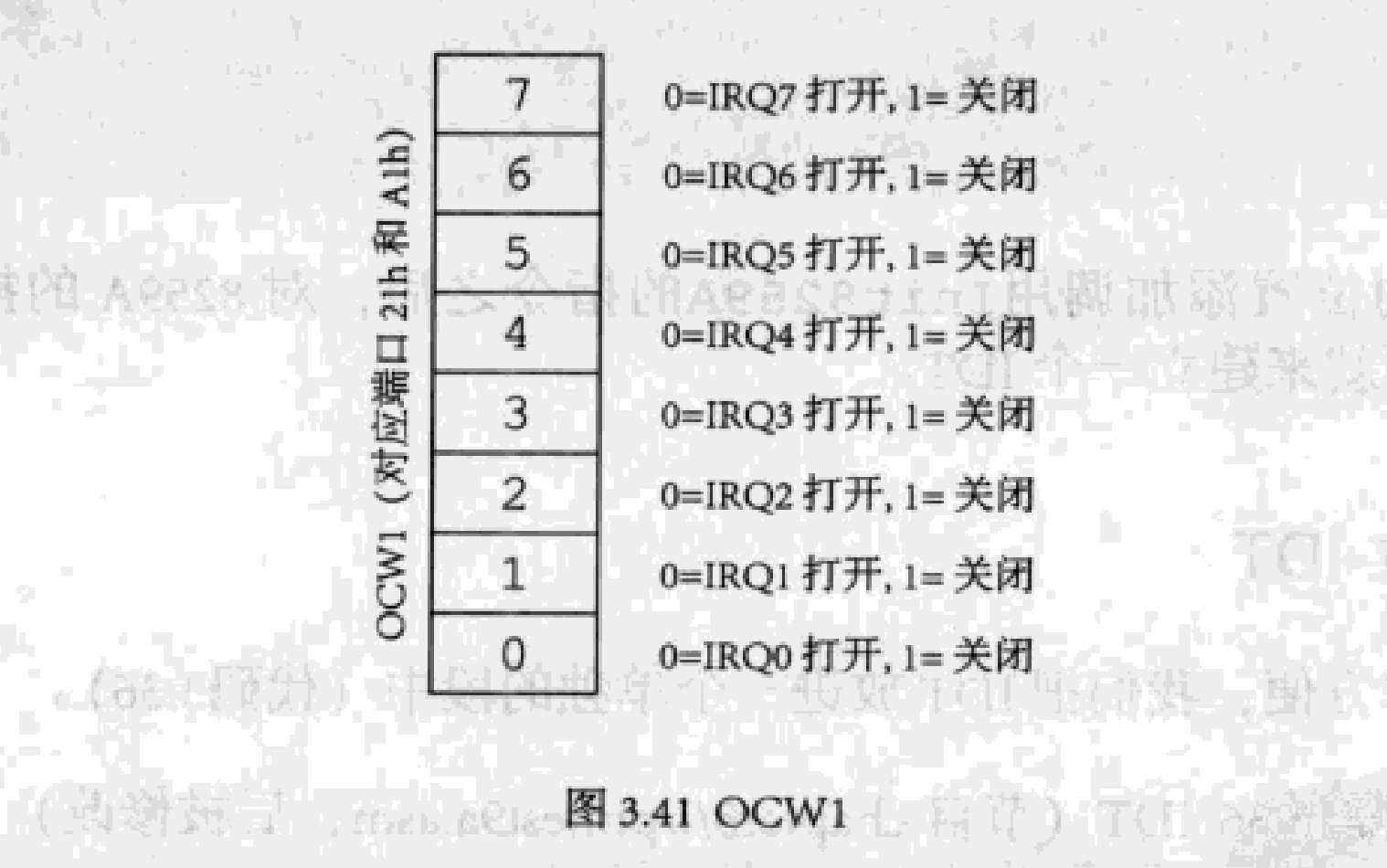
主片的OCW1是11111101b,表示打開放行鍵盤中斷;如果是11111110b,表示放行時鐘中斷。
從片的OCW1是11111111b,表示屏蔽IRQ8到IRQ15這些中斷。
實現單進程
進程是一個運行中的程序實體,擁有獨立的邏輯控制流和地址空間。這是進程的標準定義。
我們實現進程,關注進程的三要素:進程體、進程表和堆棧。進程體所在的代碼段和堆棧所在的堆棧段共同構成進程的地址空間。獨立的邏輯控制流是指每個進程好像擁有一個獨立的CPU。
什麼叫擁有獨立的CPU?我的理解是,進程在運行過程中,數據不被非自身修改,核心是:不受干擾,就像CPU只運行一個進程一樣不受非法修改數據、代碼等。
下面詳細介紹進程的三要素。
進程三要素
進程體
用C語言編寫進程體。外觀上,進程體是一個C語言編寫的函數。例如下面的函數TestA。
進程表
CPU的快照
CPU並不是一直運行一個進程,而是總是運行多個進程。怎麼實現讓進程獨享CPU的效果呢?使用進程表實現。
CPU運行A、B進程。A進程運行1分鐘後,CPU選擇了B進程運行,B進程運行1分鐘後,CPU又開始運行A進程。假如A進程中有一個局部變量num,num的初始值是0;第一次運行結束時,num的值變成了5;當A進程重新開始運行時,必須保證局部變量的值是5,而不是0。不僅是num的值需要是第一次運行結束時的值,A的所有值都必須是第一次運行結束時的值。
說了這麼多,只為了引申出進程表的作用。進程表在進程初始化時提供進程的初始信息,在進程被休眠時保存當前CPU的值,換句話說,為CPU建立一張快照。
為CPU建立快照,就是把寄存器中的值保存起來。保存到哪裡?保存到進程表。
進程表的主要元素是一系列寄存器的值,然後還有一些進程信息,例如進程的名稱、優先級等。
// 進程表 start
typedef struct{
// 中斷處理程序壓棧,手工壓棧
unsigned int gs;
unsigned int fs;
unsigned int es;
unsigned int ds;
// pushad壓棧,順序固定
unsigned int edi;
unsigned int esi;
unsigned int ebp;
// 在這裡消耗了很多時間。為啥需要在這裡補上一個值?這是因為popad依次出棧的數據中有這麼個值,
// 如果不補上這一位,出棧時數據不能依次正確更新到寄存器中。
unsigned int kernel_esp;
unsigned int ebx;
unsigned int edx;
unsigned int ecx;
unsigned int eax;
// 中斷髮生時壓棧
unsigned int eip;
unsigned int cs;
unsigned int eflags;
unsigned int esp; // 漏掉了這個。iretd會出棧更新esp。
unsigned int ss;
}Regs;
typedef struct{
Regs s_reg;
// ldt選擇子
unsigned short ldt_selector;
// ldt
Descriptor ldts[2];
unsigned int pid;
}Proc;
Proc是進程表,有四部分組成:寄存器組、GDT選擇子ldt_selector、LDT、進程ID–pid。
寄存器組保存CPU的快照數據,存儲在棧s_reg中。根據入棧操作的執行方式不同,分為三部分。
手工壓棧入棧的是和下列變量同名的寄存器的值。
// 中斷處理程序壓棧,手工壓棧
unsigned int gs;
unsigned int fs;
unsigned int es;
unsigned int ds;
用pushad入棧的是和下列變量同名的寄存器的值。
// pushad壓棧,順序固定
unsigned int edi;
unsigned int esi;
unsigned int ebp;
// 在這裡消耗了很多時間。為啥需要在這裡補上一個值?這是因為popad依次出棧的數據中有這麼個值,
// 如果不補上這一位,出棧時數據不能依次正確更新到寄存器中。
unsigned int kernel_esp;
unsigned int ebx;
unsigned int edx;
unsigned int ecx;
unsigned int eax;
中斷髮生時自動入棧的是和下列變量同名的寄存器的值。
// 中斷髮生時壓棧
unsigned int eip;
unsigned int cs;
unsigned int eflags;
unsigned int esp; // 漏掉了這個。iretd會出棧更新esp。
unsigned int ss;
入棧的順序是這樣的:中斷髮生時自動入棧——>pushad入棧——>手工入棧。
出棧的順序是這樣的:手工出棧——>popad出棧——>iretd出棧。
寄存器中的數據的入棧順序和s_reg的成員的上下順序相反。
s_reg的成員的上下順序和寄存器中的數據出棧的順序一致。
IA-32的pushad指令在堆棧中按順序壓入這些寄存器的值:EAX,ECX,EDX,EBX,ESP,EBP,ESI和EDI。
IA-32的popad指令從堆棧中按順序彈出棧元素到這些寄存器:EDI,ESI,EBP,ESP,EBX,EDX,ECX,EAX。
可以看出,pushad和popad正好是相反的運算。
需要注意,CPU的esp中的值並不是由pushad壓入堆棧,而是在中斷髮生時自動壓入堆棧的。這麼說還不準確。pushad入棧的數據雖然也是esp中的值,卻不是為進程建立快照時需要保存的值。發生中斷前,堆棧是進程的堆棧;發生中斷進入中斷例程後,堆棧已經變成了內核棧。為進程建立快照需要保存的是進程的堆棧棧頂而不是內核堆棧的棧頂。esp的值有兩次被壓入s_reg,但是,CPU恢復之前的進程時使用的是中斷髮生時自動壓入堆棧的esp中的值。
恢復之前的進程時,先把之前由pushad入棧的esp的值更新到esp中,最後被iretd把中斷髮生時自動壓入堆棧的esp中的值更新到esp中。這正是我們期望的結果。
能不能刪除s_reg的kernel_esp成員?不能。pushad、popad總是操作8個數據和對應的寄存器,如果缺少一個數據,建立快照或從快照中恢復時會出現數據錯誤。
有一個疑問需要解釋:s_reg明明是一個結構體,怎麼說它是棧,還對它進行壓棧出棧操作呢?
我認為這是一個疑問,是受高級編程語言中的堆棧影響。在潛意識中,我認為,先進後出的結構才是堆棧;具備這種特性還不夠,似乎還必須是一個結構體。完全不是這樣的。只要按照「先進後出」的原則對一段存儲空間的數據進行操作,這段存儲空間就能被稱之為堆棧。
其他
ldt_selector這個名字不是很好,因為,它是GDT的選擇子,卻容易讓人誤以為是LDT的選擇子。
LDT是一段內存空間,和局部描述符的集合。GDT是全局描述符的集合。局部描述符和全局描述符的數據結構一樣。通過ldt_selector在GDT中找到對應的全局描述符。這個全局描述符記錄LDT的信息:初始地址和界限大小。
ldts就是LDT,只包含兩個描述符,一個是代碼段描述符,一個是數據段、堆棧段等描述符。它被存儲在進程表中。
pid是進程ID。
堆棧
int proc_stack[128];
// proc 是進程表
proc->s_reg.esp = (int)(proc_stack + 128);
在前面已經說過,堆棧也好,隊列也好,都是一段存儲空間,只需按照特定的原則讀寫這段存儲空間,例如「先進後出」,就是堆棧或隊列。不要以為只有像那些數據結構書中那樣定義的數據結構才是堆棧或隊列。
把esp設置成proc_stack + 128,體現了堆棧從高地址向低地址向下生長。堆棧的數據類型是int [128],對應esp是一個32位寄存器。
proc_stck是堆棧的初始地址,加128後,已經到了堆棧之外。把初始棧頂的值設置成堆棧之外,有沒有問題?
沒有問題。push指令的執行過程是:先移動棧頂指針,再存儲數據。初始狀態,往堆棧中入棧4,過程是這樣的:
- 堆棧指針減去1,esp的值是
proc_stack + 128 - 1。proc_stack + 127在堆棧proc_stack內部,從數組角度看,是最後一個元素。 - 再存儲數據,
proc_stack[127] = 4。
啟動進程
準備好進程三要素後,怎麼啟動進程?啟動進程包括進程「第一次」啟動和進程「恢復」啟動。先探討進程「第一次啟動」。
進程「第一次啟動」,是特殊的「恢復」啟動。是不是這樣呢?是可以的。在一個進程死亡前,將會經歷很多次「恢復」啟動,第一次啟動只是從初始狀態「恢復」啟動而已。CPU不關注進程是第一次啟動還是「恢復」啟動。程序計數器指向什麼指令、寄存器中有什麼數據,它就執行什麼指令。我們只需把進程的初始快照放入CPU就能啟動進程。快照在進程表中,要把進程表中的值放入CPU。下面的restart把進程快照放入CPU並啟動進程。
; 啟動進程
restart:
mov eax, proc_table
mov esp, eax
; 加載ldt
lldt [proc_table + 68]
; 設置tss.esp0
lea eax, [proc_table + 68]
mov [tss + 4], eax
; 出棧
pop gs
pop fs
pop es
pop ds
popad
iretd
這個函數的每行代碼都大有玄機,需要琢磨一番。
restart做了兩件事:恢復快照,把程序計數器指向進程體。
恢復快照分為設置LDTPtr寄存器、設置tss.esp0、設置其他寄存器的值。
lldt [proc_table + 68],設置LDTR寄存器的值。LDTR的數據結構和選擇子一樣。sizeof(Regs)的值是68,所以proc_table + 68是進程表的成員ldt_selector的內存地址。
在這裡耗費了不少時間,原因是我誤以為
LDTR的結構和GDTR的結構相同。二者的結構並不相同。
mov [tss + 4], eax,設置tss.esp0。tss是個比較麻煩的東西,在後面專門講解。
從pop gs到iretd,設置其他寄存器的值。
iretd,依次出棧數據並更新ss、esp、eflags、cs、eip`這些寄存器的值。
cs、eip被更新為進程的代碼段和進程體的入口地址後,進程就啟動了。
代碼
void kernel_main()
{
Proc *proc = proc_table;
proc->ldt_selector = LDT_FIRST_SELECTOR;
Memcpy(&proc->ldts[0], &gdt[CS_SELECTOR_INDEX], sizeof(Descriptor));
// 修改ldt描述符的屬性。全局cs的屬性是 0c9ah。
proc->ldts[0].seg_attr1 = 0xba;
Memcpy(&proc->ldts[1], &gdt[DS_SELECTOR_INDEX], sizeof(Descriptor));
// 修改ldt描述符的屬性。全局ds的屬性是 0c92h
proc->ldts[1].seg_attr1 = 0xb2;
// 初始化進程表的段寄存器
proc->s_reg.cs = 0x05; // 000 0101
proc->s_reg.ds = 0x0D; // 000 1101
proc->s_reg.fs = 0x0D; // 000 1101
proc->s_reg.es = 0x0D; // 000 1101
//proc->s_reg.ss = 0x0D; // 000 1101
proc->s_reg.ss = 0x0D; // 000 1100
// 0x3b--> 0011 1011 --> 0011 1 001
// 1001
proc->s_reg.gs = GS_SELECTOR & (0xFFF9);
// proc->s_reg.gs = 0x0D;
// 初始化進程表的通用寄存器
proc->s_reg.eip = (int)TestA;
proc->s_reg.esp = (int)(proc_stack + 128);
// 抄的於上神的。需要自己弄清楚。我已經理解了。
// IOPL = 1, IF = 1
// IOPL 控制I/O權限的特權級,IF控制中斷的打開和關閉
proc->s_reg.eflags = 0x1202;
// 啟動進程,扣動扳機,砰!
dis_pos = 0;
// 清屏
for(int i = 0; i < 80 * 25 * 2; i++){
disp_str(" ");
}
restart();
while(1){}
}
代碼的條理很清晰,做了下面幾件事:
- 選擇進程表。
- 填充進程表。在
restart中,填充的是CPU。 - 清除屏幕上的字符串。
- 啟動進程。
- 讓CPU永遠執行指令。
代碼詳解
填充進程表是主要部分,詳細講解一下。
ldt_selector
proc->ldt_selector = LDT_FIRST_SELECTOR;,設置指向進程的LDT的選擇子。這是GDT選擇子,通過這個選擇子在GDT中找到對應的全局描述符,然後通過這個全局描述符找到LDT。
LDT_FIRST_SELECTOR的值是0x48。為什麼是0x48?
因為,我把GDT設計成了下列表格這個樣子。每個選擇子的值是由它在GDT中的位置也就是索引決定的。為什麼這些描述符在GDT中的索引(位置)不連貫呢?這是因為我設計的GDT中還有許多為了進行其他測試而填充的描述符。
選擇子的高13位是描述符在描述符表中的偏移量,當然,偏移量的單位是一個描述符的長度;低13位存儲TI和CPL。
| 全局描述符 | 索引 | 選擇子 |
|---|---|---|
| 空描述符 | 0 | 高13位是0,第3位是0,最終結果是0b,0x0 |
| 代碼段描述符 | 1 | 高13位是1,第3位是0,最終結果是1000b,0x8 |
| 數據段描述符 | 6 | 高13位是6,第3位是0,最終結果是110 000b,0x30 |
| 視頻段描述符 | 7 | 高13位是7,第3位是0,最終結果是111 000b,0x38 |
| TSS段描述符 | 8 | 高13位是8,第3位是0,最終結果是1000 000b,0x40 |
| LDT段描述符 | 9 | 高13位是9,第3位是0,最終結果是1001 000b,0x48 |
LDT
根據ldt_selector找到LDT,LDT的內存地址已經確定了,就在進程表中,不能更改。要讓ldt_sector間接指向進程表中的LDT,只能在指向LDT的全局描述符下功夫。
// 初始化LDT
// 對應ldts只有兩個元素。
int ldt_size = 2 * sizeof(Descriptor);
// int ldt_attribute = 0x0c92; // todo ldt的屬性怎麼確定?
int ldt_attribute = 0x82; // todo ldt的屬性怎麼確定?
// proc_table[0].ldts 只是在代碼段中的偏移量,需要加上所在代碼段的基地址。
int ldt_base = VirAddr2PhyAddr(ds_phy_addr, proc_table[0].ldts);
// 全局描述符的基地址、界限、屬性都已經知道,足以創建一個全局描述符。
// ldt_base 是段基值,不是偏移量。
InitDescriptor(&gdt[LDT_FIRST_SELECTOR_INDEX], ldt_base, ldt_size - 1, ldt_attribute);
唯一要特別著墨的是ldt_attribute為什麼是0x82?
指向LDT的全局描述符的特徵有:可讀、代碼段、粒度是1bit、32位。翻翻《寫操作系統之開發加載器》,搬過來下面的表格。
| A | W | E | X | S | DPL | DPL | P | AVL | L | D/B | G |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
在上面的表格中填入LDT的全局描述符的屬性。G位是0而不是1。LDT只佔用16個bit,不需要使用4KB來統計長度。W位是1,表示LDT是可讀可寫的。我們會看到,確實需要對LDT進行寫操作。
要特別注意,S位是0,因為,LDT是一個系統段,不是代碼段也不是數據段。TSS也是系統段。
從右往左排列表格的第二行的每個單元格,得到屬性值。它是0000 1000 0010b,轉換成十六進制數0x82。
我以前提出的問題在今天被我自己解答了,這就叫「溫故而知新」。就是不知道做這些事有沒有用。
填充進程體的LDT。
Memcpy(&proc->ldts[0], &gdt[CS_SELECTOR_INDEX], sizeof(Descriptor));
// 修改ldt描述符的屬性。全局cs的屬性是 0c9ah。
proc->ldts[0].seg_attr1 = 0xba;
Memcpy(&proc->ldts[1], &gdt[DS_SELECTOR_INDEX], sizeof(Descriptor));
// 修改ldt描述符的屬性。全局ds的屬性是 0c92h
proc->ldts[1].seg_attr1 = 0xb2;
上面的代碼的思路是:複製GDT中的代碼段描述符、數據段描述符到LDT中,然後修改LDT中的描述符的屬性。
段寄存器的值
s_reg.cs是LDT中第一個描述符的選擇子。這個選擇子高13位是索引0,低3位是TI和RPL,TI是1,RPL是1,綜合得到選擇子的值是0x5。按同樣的方法計算出其他段寄存器的值是0xD。
gs的值比較特別。在上面的代碼中,我為了把gs的RPL設置得和其他段選擇子的RPL相同,把視頻段選擇子的RPL也設置成了1,這不是必要的。視頻段描述符依然是GDT中的描述符。proc->s_reg.gs = GS_SELECTOR & (0xFFF9);,體現了前面所說的一切。
由於代碼中錯誤的注釋,再加上我在一瞬間弄錯了C語言運算符&的運算規則,在此浪費了不少時間。我誤把&當成彙編語言中的運算符。
eip的值
eip存儲程序計數器。程序計數器是下一條要執行的指令的地址,在操作系統中,是指令在代碼段中的偏移量。
要在啟動進程前把eip的值設置成進程體的入口地址。函數名就是進程體的入口地址,C語言中的函數和彙編語言中的函數都是如此。入口地址是函數的第一條指令的地址。
proc->s_reg.eip = (int)TestA;,正如我們看到的,直接使用TestA就能把函數的入口地址賦值給s_reg.eip。前面的(int)為了消除編譯器的警告信息。
如果TestA是一個變量,使用變量名得到的是變量中存儲的值而不是變量的存儲地址。為什麼?編譯器就是這麼做的。我的理解,函數名和數組名類似。
eflags的值
eflags
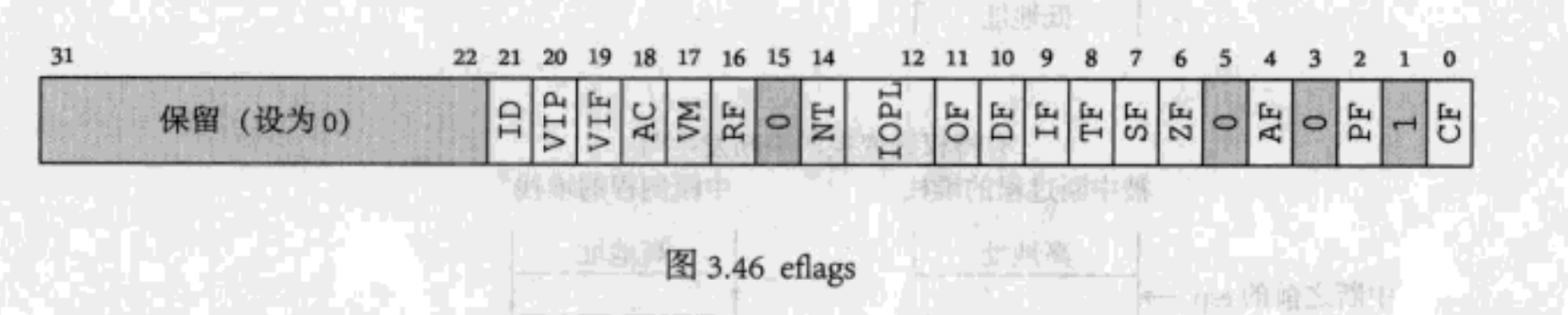
又見到eflags了。上次看過eflags後,我到現在還心有餘悸。這一次,我們關注eflags中的IOPL。
IOPL控制用戶程序對敏感指令的使用權限。敏感指令是in、ins、out、outs、cli、sti這些指令。
IOPL佔用2個bit。它存儲在eflags中,只能在0特權級下通過popf、iretd修改。
使用IOPL設置一個特權級的用戶程序對所有端口的訪問權限,使用I/O位圖對一個特權級的用戶程序設置個性化的端口訪問權限(能訪問部分端口、不能訪問另外的端口)。
用戶程序的CPL<IOPL,用戶程序能訪問所有端口。否則,從I/O位圖中查找用戶程序對端口的訪問權限。
為什麼把eflags的值設置成0x1202?我們把IOPL設置成1,把IF設置成1,綜合而成,最終結果是0x1202。
IF是1,在restart中執行iretd後,打開了中斷。恢復進程後一定要打開中斷,才能在進程運行過程中處理其他中斷。
IOPL的值如果設置為0,CPL是1的進程就不能執行敏感指令。
IF和IOPL的值設置成當前數據,還比較好理解。讓我感覺困難的是eflags冗長的結構和計算最終數值的繁瑣方法。不過,我找到一個表格(見下面的小節「eflags”結構表格),大大減少了麻煩。
我怎麼使用這個表格?IOPL是1,那麼,eflags的值是0x1000;IF的值是1,那麼,eflags的值是0x0200;第1個bit是保留位,值是1,那麼,eflags的值是0x0002。把這些eflags進行|運算,最終結果是0x1202。正好和代碼中的值相同,這是一個巧合。但表格提供了一種方法,就是只計算相應元素時eflags的值是多少。用這種方法,能避免每次都需要畫一個32位的表格然後逐個單元格填充數據。計算段屬性也可以用這種方式簡化計算方法。
計算eflags的唯一難點是弄清楚每個位的含義。
有空再看這個eflags,此刻只想儘快離開這個知識點。
eflags結構表格
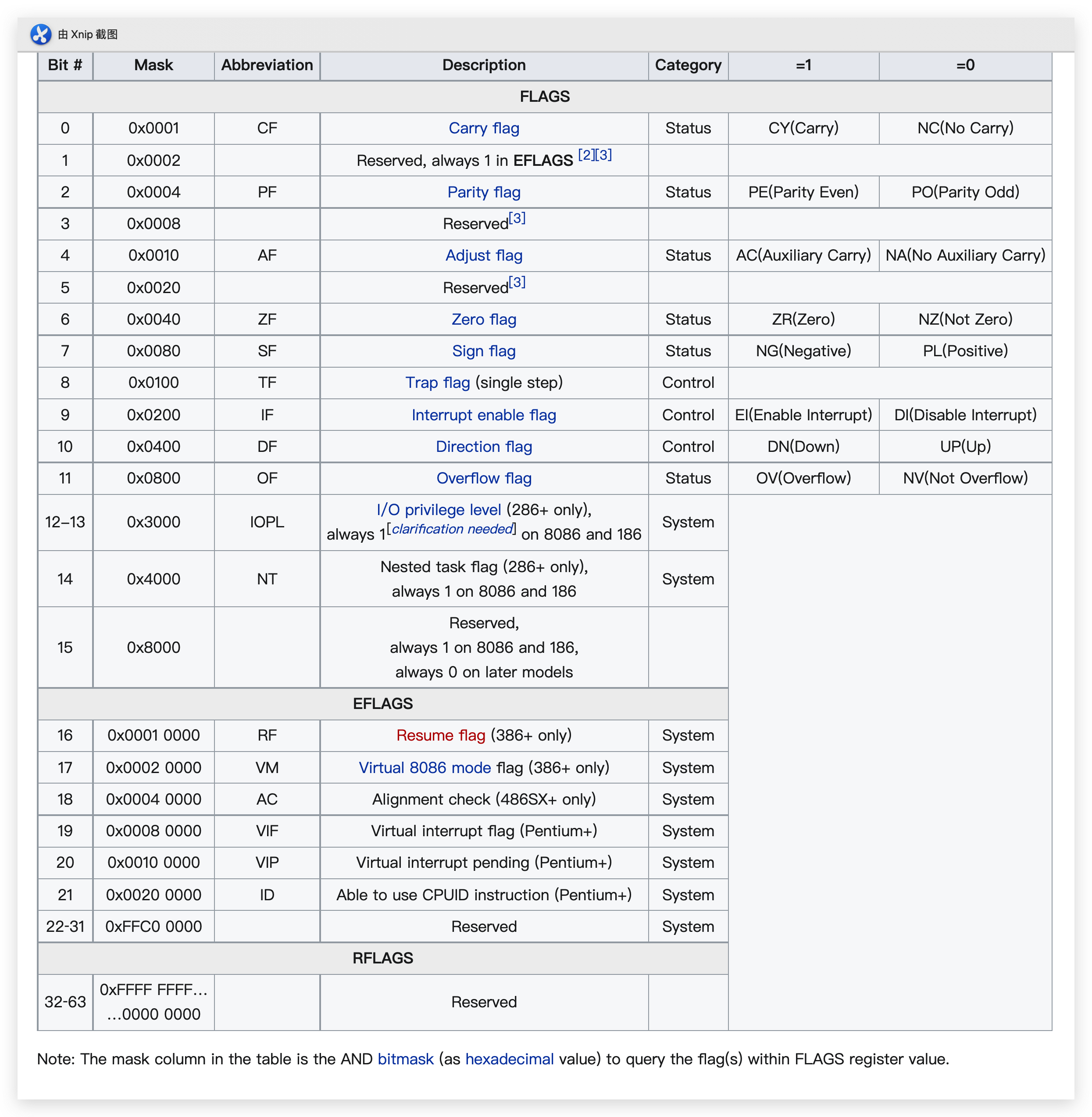
剩餘
剩下的代碼的功能是清屏、啟動進程、讓CPU永遠執行。在前面已經講過,不再贅述。
實現多進程
簡單改造上面的單進程代碼,就能啟動多個進程。真的是這樣嗎?很遺憾,真的不是這樣。
準備好多個進程三要素很容易,可是,單進程代碼缺少切換到其他進程的機制。一旦執行準備好的第一個進程,就會一直執行這個進程,沒有契機執行其他進程。需加入中斷例程、建立快照的代碼,再加上多個進程需要的材料,就能實現多進程。現在,我們開始把單進程代碼改造為多進程代碼。
多個進程要素
進程體
void TestA()
{
while(1){
disp_str("A");
disp_int(2);
disp_str(".");
delay(1);
}
}
void TestB()
{
while(1){
disp_str("B");
disp_int(2);
disp_str(".");
delay(1);
}
}
void TestC()
{
while(1){
disp_str("C");
disp_int(3);
disp_str(".");
delay(1);
}
}
三個函數分別是進程A、B、C的進程體。不能再像前面那樣直接把函數名賦值給s_reg.eip了,因為在循環中不能使用固定值。新方法是建立一個進程體入口地址的數組。這個數組中的元素的數據類型是函數指針。
先了解一下函數指針。
#include <stdio.h>
int max(int x, int y)
{
return x > y ? x : y;
}
int main(void)
{
/* p 是函數指針 */
int (* p)(int, int) = & max; // &可以省略
int a, b, c, d;
printf("請輸入三個數字:");
scanf("%d %d %d", & a, & b, & c);
/* 與直接調用函數等價,d = max(max(a, b), c) */
d = p(p(a, b), c);
printf("最大的數字是: %d\n", d);
return 0;
}
使用函數指針的代碼是:
// code-A
/* p 是函數指針 */
int (* p)(int, int) = & max; // &可以省略
d = p(p(a, b), c);
上面的代碼等價於下面的代碼。
// code-B
typedef int (* Func)(int, int);
Func p = & max; // &可以省略
d = p(p(a, b), c);
code-A在聲明變量的同時初始化變量。code-B先創建了數據類型,然後初始化一個這種類型的變量並初始化。我們等會使用code-B風格的方式創建函數指針。
函數指針語法似乎有點怪異,和普通指針語法差別很大。其實它們的差別不大。
int *p,聲明一個指針,指針名稱是p,數據類型是int *。
int (*p)(int, int),聲明一個函數指針,指針名稱是p,數據類型是int *(int, int)。
把這種表面風格不一樣的指針聲明語句看成」數據類型+變量名「,就會覺得它們的風格其實是一樣的。
typedef int (* Func)(int, int);,實質是typedef int *(int, int) Func;。
好了,函數指針語法這個障礙已經被消除了,我們繼續實現多進程。
前面,我說到,把進程體的入口放到數組中,存儲進程體的入口的數據類型需要是函數指針。代碼如下。
typedef void (*Func)();
typedef struct{
Func func_name;
unsigned short stack_size;
}Task;
Task task_table[3] = {
{TestA, A_STACK_SIZE},
{TestB, B_STACK_SIZE},
{TestC, C_STACK_SIZE},
};
設置eip的值的代碼是proc->s_reg.eip = (int)task_table[i].func_name;。
eip的值是進程體的入口,是一個內存地址;而函數名例如TestA就是內存地址,Task的成員func_name是一個指針,能夠把TestA等函數名賦值給它。把內存地址賦值給指針,這符合語法。
堆棧
// i是進程體在進程表數組中的索引;堆棧地址從高地址往低地址生長。
proc->s_reg.esp = (int)(proc_stack + 128 * (i+1));
進程表
#define PROC_NUM 3
Proc proc_table[PROC_NUM];
單進程代碼中,只有一個進程,因此只需要一個進程表。現在,有多個進程,要用一個進程表數組存儲進程表。填充進程表的大概思路是遍歷進程表數組,填充每個進程表。全部代碼如下。
void kernel_main()
{
counter = 0;
Proc *proc = proc_table;
for(int i = 0; i < PROC_NUM; i++){
proc->ldt_selector = LDT_FIRST_SELECTOR + 8 * i;
proc->pid = i;
Memcpy(&proc->ldts[0], &gdt[CS_SELECTOR_INDEX], sizeof(Descriptor));
// 修改ldt描述符的屬性。全局cs的屬性是 0c9ah。
proc->ldts[0].seg_attr1 = 0xba;
Memcpy(&proc->ldts[1], &gdt[DS_SELECTOR_INDEX], sizeof(Descriptor));
// 修改ldt描述符的屬性。全局ds的屬性是 0c92h
proc->ldts[1].seg_attr1 = 0xb2;
// 初始化進程表的段寄存器
proc->s_reg.cs = 0x05; // 000 0101
proc->s_reg.ds = 0x0D; // 000 1101
proc->s_reg.fs = 0x0D; // 000 1101
proc->s_reg.es = 0x0D; // 000 1101
proc->s_reg.ss = 0x0D; // 000 1100
// 需要修改gs的TI和RPL
// proc->s_reg.gs = GS_SELECTOR;
// proc->s_reg.gs = GS_SELECTOR | (0x101);
//proc->s_reg.gs = GS_SELECTOR;
//proc->s_reg.gs = GS_SELECTOR & (0x001);
// 0x3b--> 0011 1011 --> 0011 1 011
// 1001
proc->s_reg.gs = GS_SELECTOR & (0xFFF9);
proc->s_reg.eip = (int)task_table[i].func_name;
proc->s_reg.esp = (int)(proc_stack + 128 * (i+1));
// IOPL = 1, IF = 1
// IOPL 控制I/O權限的特權級,IF控制中斷的打開和關閉
proc->s_reg.eflags = 0x1202;
proc++;
}
proc_ready_table = proc_table;
dis_pos = 0;
// 清屏
for(int i = 0; i < 80 * 25 * 2; i++){
disp_str(" ");
}
dis_pos = 2;
restart();
while(1){}
}
大部分代碼和單進程代碼相同,只是在後者的基礎上增加了一個循環。此外,還有下面這些細微差別。
proc->ldt_selector = LDT_FIRST_SELECTOR + 8 * i;。指向進程的LDT的全局描述符在GDT中依次相鄰,相鄰描述符之間的差值是1,反映到指向LDT的選擇子的差別就是8。
proc->s_reg.eip = (int)task_table[i].func_name;,在前面專門解釋過。
proc->s_reg.esp = (int)(proc_stack + 128 * (i+1));。
proc_stack是堆棧空間,每個進程的堆棧是128個位元組。
第一個進程的初始堆棧棧頂是proc_stack + 128,第一個進程的初始堆棧棧頂是proc_stack + 128 + 128,第一個進程的初始堆棧棧頂是proc_stack + 128 + 128 + 128。
進程快照
多進程模型中,進程切換的契機是時鐘中斷。時鐘中斷每隔一段時間發生一次。在時鐘中斷例程中,根據某種策略,選擇時鐘中斷結束後要執行的進程是時鐘中斷髮生前的進程還是另外一個進程。選擇執行哪個進程,這就是進程調度。
進程在時鐘中斷前的數據、下一條要執行的指令等都需要保存起來,以便恢復進程時在前面的基礎上繼續執行,而不是另起爐灶。
進程快照是CPU在某個時刻的狀態,通過把CPU的狀態保存到進程表。在前面的小節「CPU快照」已經詳細介紹了方法。在此基礎上,一起來看看建立快照的代碼。
;中斷髮生時會依次入棧ss、esp、eflags、cs、eip
; 建立快照
pushad
push ds
push es
push fs
push gs
時鐘中斷例程
代碼
hwint0:
; 建立快照
pushad
push ds
push es
push fs
push gs
mov dx, ss
mov ds, dx
mov es, dx
mov esp, StackTop
sti
push ax
; 進程調度
call schedule_process
; 置EOI位
mov al, 20h
out 20h, al
pop ax
cli
; 啟動進程
jmp restart
堆棧變化
中斷髮生時,esp的值是TSS中的esp0,ss是TSS中的ss0。
在hwint0中,mov esp, StackTop把esp設置成內核棧StackTop,ss依然是TSS中的ss0。
在restart中,把esp設置成從中斷中要恢復執行的進程的進程表proc_table_ready,ss還是TSS中的ss0。
進程恢復後,esp是進程表中的esp,ss是進程表中的ss。
在這些堆棧變化中,只有第一次變化,需要解釋。其他的變化,都很好懂。
中斷髮生時,CPU會自動從TSS中獲取ss和esp的值。欲知詳情,請看下一個小節。
TSS
TSS的全稱是task state segment,中文全稱是」任務狀態段「。它是硬件廠商提供給操作系統的一個硬件,功能是保存CPU的快照。但主流操作系統都沒有使用TSS保存CPU的快照,而是使用我們在上面見過的那種方式保存CPU的快照。
結構圖
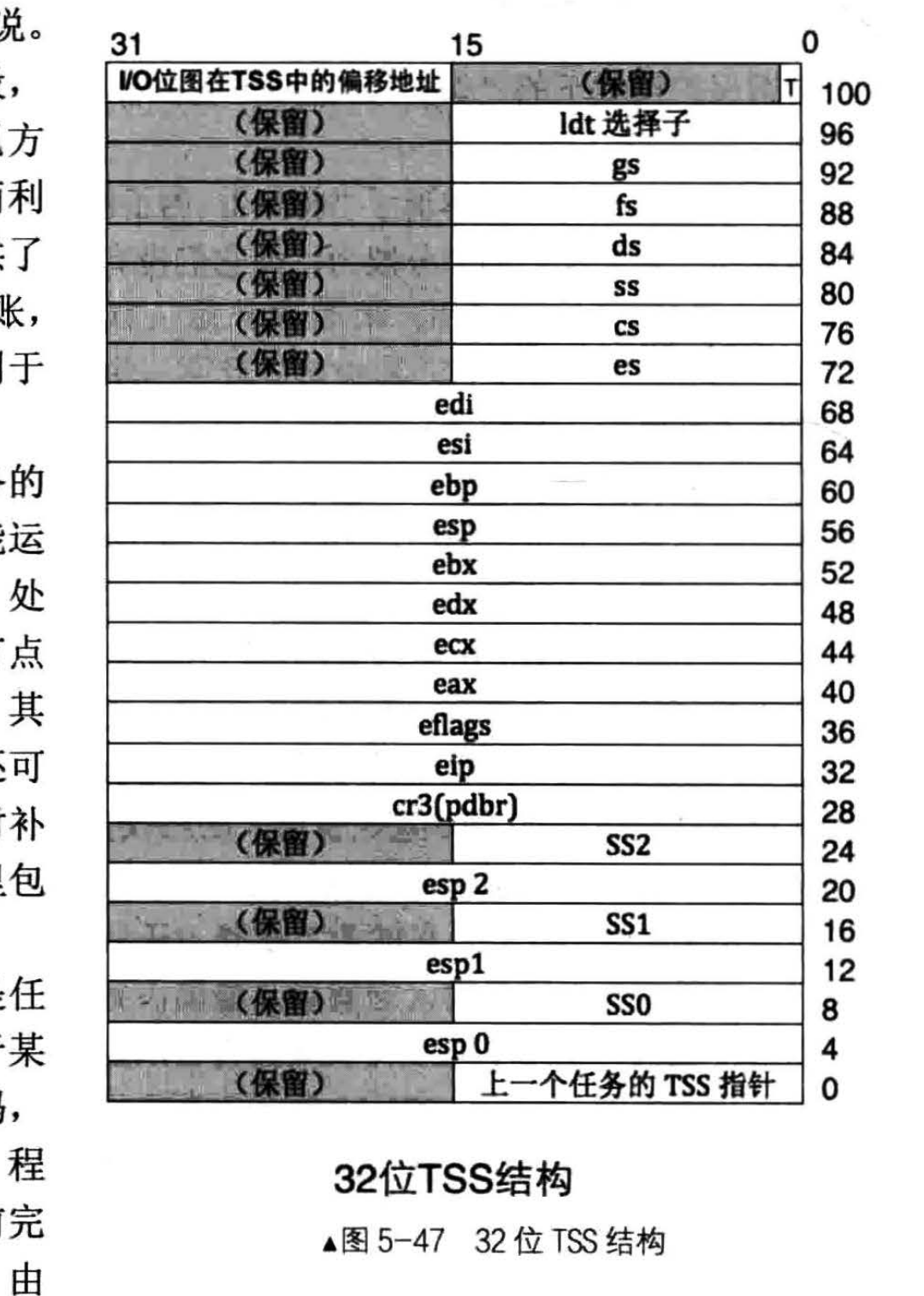
結構代碼
typedef struct{
// 上一個任務的TSS指針
unsigned int last_tss_ptr;
unsigned int esp0;
unsigned int ss0;
unsigned int esp1;
unsigned int ss1;
unsigned int esp2;
unsigned int ss2;
unsigned int cr3;
unsigned int eip;
unsigned int eflags;
unsigned int eax;
unsigned int ecx;
unsigned int edx;
unsigned int ebx;
unsigned int esp;
unsigned int ebp;
unsigned int esi;
unsigned int edi;
unsigned int es;
unsigned int cs;
unsigned int ss;
unsigned int ds;
unsigned int fs;
unsigned int gs;
unsigned int ldt;
unsigned int trace;
unsigned int iobase;
}TSS;
結構圖中的ss0、ss1這類高16位是保留位的成員也用32位來存儲。iobase也是。這麼多成員,我們只使用了ss0、esp0、iobase。
填充
進程初次啟動前,往進程表中填入了要更新到TSS中的數據。看代碼。
tss.ss0 = DS_SELECTOR;
為什麼沒有填充esp0?其實有填充,在restart中。
; 設置tss.esp0
lea eax, [proc_table + 68]
mov [tss + 4], eax
從TSS的結構圖,能計算出tss + 4是esp0的地址,所以上面的代碼是把進程表中的s_reg的棧頂(最高地址)存到了TSS的esp0中。
中斷髮生時,CPL是0,CPU會自動從TSS中選擇對應的ss0和esp0;如果CPL是1,CPU會選擇ss1和esp1。
進程初次啟動前,TSS中的ss0和esp0分別被設置成進程的ss和進程表的s_reg的最高地址。中斷髮生時,CPU從TSS中取出ss0和esp0,然後壓棧。注意,此時的ss0和esp0分別是我們在前面設置的被中斷的進程的ss和進程表的s_reg的最高地址。就這樣,CPU發生中斷時的狀態被保存到了該進程的進程表中。
在中斷例程的末尾,TSS中的ss和esp0被設置成即將從中斷中恢復的進程的ss和s_reg的最高地址。當中斷再次發生時,CPU狀態會被保存到這個進程的進程表中。
中斷重入
時鐘中斷髮生後,執行時鐘中斷例程,未執行完時鐘中斷例程前又發生了鍵盤中斷,這種現象就叫中斷重入。
處理思路
發生中斷重入時,怎麼處理?迅速結束重入的中斷例程,不完成正常情況下應該完成的功能,然後接着執行被重入的中斷例程。具體思路是:
- 設置一個變量k_reenter,初始值是2。當然也能把初始值設置成3、4或其他值。
- 當中斷髮生時,k_reenter減去1。
- 在中斷例程中,執行完成特定功能例如進程調度代碼前,檢查k_reenter的值是不是1。
- 是1,執行進程調度代碼,更換要被恢復執行的進程。
- 不是1,跳過進程調度代碼,不更換要被恢復執行的進程,也就是說,繼續執行被中斷的進程。
- 在中斷例程的末尾,k_reenter加1。
代碼
; k_reenter 的初始值是0。
hwint0:
; 建立快照
pushad
push ds
push es
push fs
push gs
mov dx, ss
mov ds, dx
mov es, dx
mov fs, dx
mov al, 11111001b
out 21h, al
; 置EOI位 start
mov al, 20h
out 20h, al
; 置EOI位 end
inc dword [k_reenter]
cmp dword [k_reenter], 0
jne .2
.1:
mov esp, StackTop
.2:
sti
call clock_handler
mov al, 11111000b
out 21h, al
cli
cmp dword [k_reenter], 0
jne reenter_restore
jmp restore
; 恢復進程
restore:
; 能放到前dword 面,和其他函數在形式上比較相似
mov esp, [proc_ready_table]
lldt [esp + 68]
; 設置tss.esp0
lea eax, [esp + 68]
mov dword [tss + 4], eax
reenter_restore:
dec dword [k_reenter]
; 出棧
pop gs
pop fs
pop es
pop ds
popad
iretd
k_reenter的初始值是0,中斷髮生時,執行到第一條cmp dword [k_reenter], 0語句,當這個中斷是非重入中斷時,k_reenter的值是0;當這個中斷是重入中斷時,k_reenter的值是2,總之k_reenter的值大於0。
上面的判斷需要琢磨一番。
代碼中,對重入中斷的處理是:
- 跳過
mov esp, StackTop。沒有更改esp的值。 - 執行
reenter_restore。沒有更換要被恢復的進程。也就是說,恢復被重入中斷打斷的進程。
在上面的代碼中,無論是重入中斷還是非重入中斷,都執行了完成特定功能的代碼。不應該如此。以後找機會優化。
原子操作
在中斷例程中,建立快照結束後,執行了sti打開中斷。為什麼要打開中斷?因為發生中斷時,(什麼?CPU嗎?)會自動關閉中斷。在完成特定功能的代碼執行完後、恢復快照到CPU前,又會關閉中斷。執行iretd後,中斷又被打開。
建立快照前、恢復快照前,都關閉了中斷。為什麼?為了確保CPU能一氣呵成、不受其他與建立或恢復快照無關的指令修改快照或CPU的狀態。想像一下,在建立快照的過程中,正要執行push eax時,又發生了其他中斷,在新中斷的中斷例程中無法根據k_reenter識別新中斷是不是重入中斷。為了避免這種混亂的狀況,必須保證建立CPU快照的過程不被打斷。恢復進程的過程也是一樣。
我無法模擬這種混亂的情況。這個解釋似乎有點牽強,擱置,看我以後能不能想出更好的例子。
特權級
CPU有四個特權級,分別是0特權級、1特權級、2特權級、3特權級。特權級從0特權級到3特權級的權限依次遞減。操作系統運行在0特權級,用戶進程運行在3特權級,系統任務運行在1特權級。
參考資料
《一個操作系統的實現》
《操作系統真相還原》
x86 and amd64 instruction reference


