聊聊我對 GraphQL 的一些認知

每隔一段時間就能看到一篇 GraphQL 的文章,但是打開文章一看,基本上就是簡單的介紹下 GraphQL 的特性。很多文章其實就是 github 上找個 GraphQL 的項目,然後按照對應的 demo 跑起來而已。有些文章明顯是沒有完整的項目實踐經歷,卻在狂吹 GraphQL 的各種優點,讓不熟悉 GraphQL 的同學以為這是神丹妙藥,弄不好還要在項目中實踐一番。
因為項目的背景(後面會講到),我有幸參與過 GraphQL 在實際項目中的落地,本篇文章我會談談我對 GraphQL 的一些理解,當然這個也僅供讀者參考。
GraphQL 優勢
不知道大家有沒有遇到過這樣的一些場景,某個服務有幾十個接口,更有甚者上百個也是有可能的。APP 或者其他下游要封裝一個功能,需要調用 10 個接口左右,可能這些接口還涉及到不同的團隊。不管開發,聯調,測試,還是對於調用方,整個鏈條功能太多了。隨着這些功能經過多個版本的迭代升級後,新+舊版本的接口誰也不敢大規模改動了,只能在原來的基礎上做代碼拼接,這基本就是祖傳代碼的由來。大部分同學基本的代碼素養是有的,但是也只能任由這些祖傳代碼慢慢腐爛,原因為很簡單,誰也不敢保證改動之後功能是不是有遺漏的地方。
有沒有這樣一個功能,將這些接口做一下聚合,然後將結果的集合返回給前端呢?在目前比較流行微服務架構體系下,有一個專門的中間層專門來處理這個事情,這個中間層叫 BFF(Backend For Frontend)。我曾經工作過的某公司想要將某業務的售賣相關功能給公司其他業務使用,但是接入方一看那麼多接口,瞬間就決定不接了,逼不得已該業務平台緊急開發了 BFF 相關功能讓其他業務方接入。
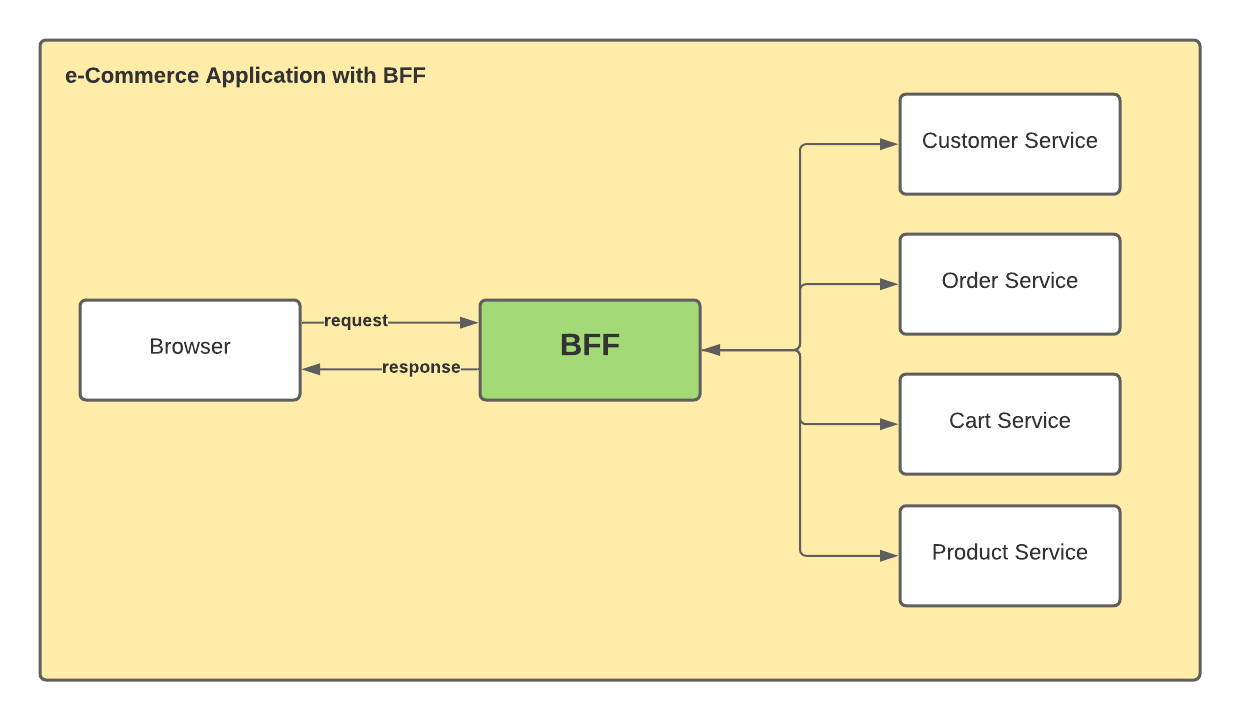
有些同學在稍微大點規模的公司做的工作就是合併各種接口,然後返回給調用方,這基本上就是 BFF 的主要工作內容了。除了類似 BFF 組建接入平台的方式,是否還有其他的方式能夠只發出一個請求就能獲取到一系列的接口返回值呢?
我在京東 APP 上隨便截圖了一個商品
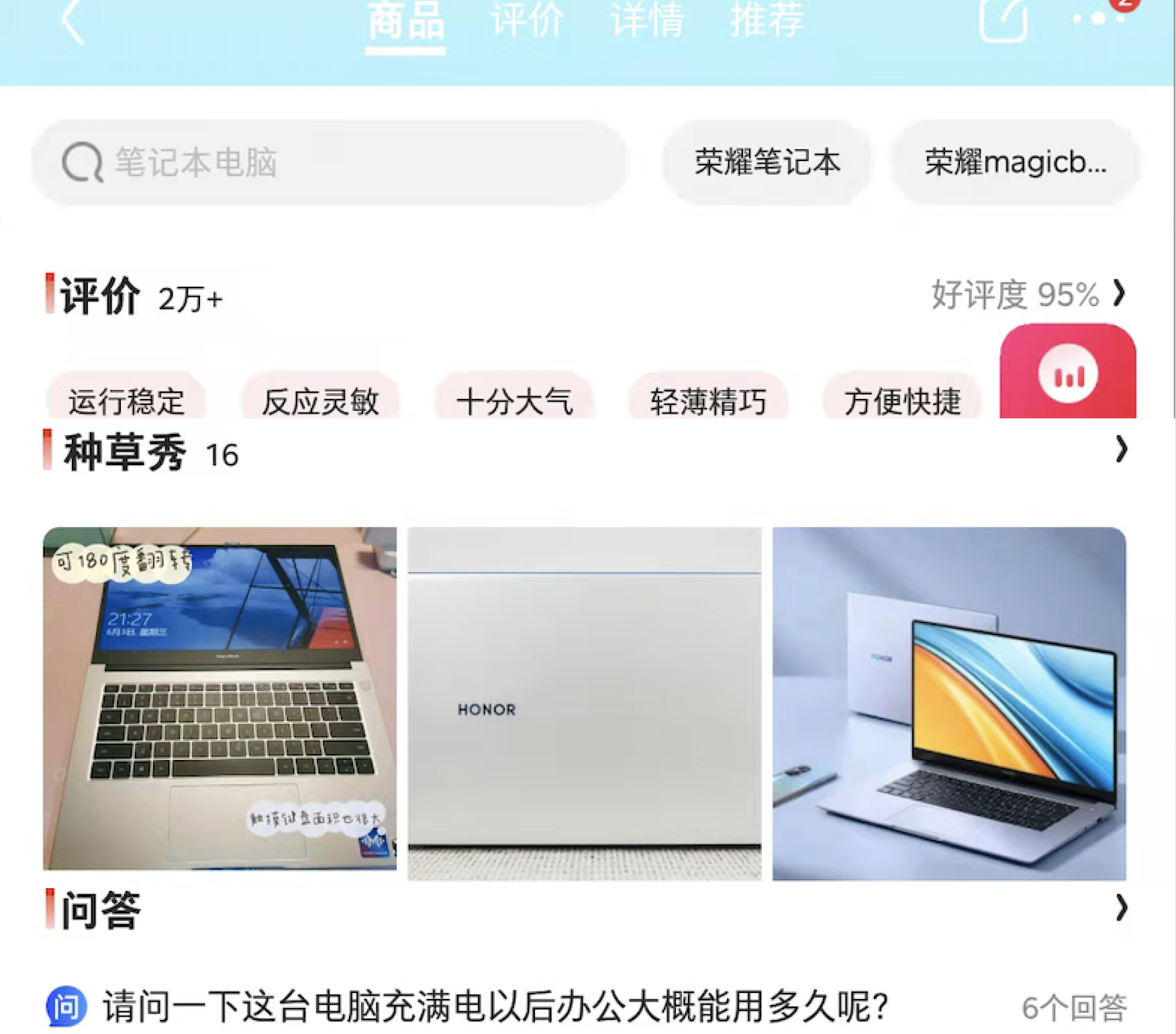
類似這個頁面,當用戶打開這個頁面的時候,按照目前比較流行的 REST 接口,需要 APP 至少發起下面這些請求:
- 獲取商品詳情接口
- 獲取商品價格、優惠相關的接口
- 獲取評價接口
- 獲取種草秀接口
- 獲取問答接口
這些接口一般來說都比較重,裏面有很多當前頁面並不需要的字段,那有沒有一種可能:APP 端發一次請求就能獲取這個頁面需要的所有字段,同時 APP 還能根據自己的需求只請求自己需要的字段呢?
答案是肯定的,那就是 GraphQL。
query jdGoodsQuery {
goods {
detail {
id
pictures(first: 10) {
pic_id
thumb
}
spec {
name
size
weight
}
}
price {
price
origin_price
market_price
}
comment(first: 10) {
comment_id
topic_id
content
from_uid
}
self_show(first: 10) {
id
pic_id
}
}
}
對於上面京東商品詳情的截圖,類似這樣的一個 Query 就可以把這個頁面需要的所有的字段都獲取到。
對於 REST 接口還有另外一個比較棘手的問題。當業務升級的時候,接口不可避免的需要升級,一個比較常見的問題,某個字段在新版本升級後不需要了,如何優雅的處理舊接口以及舊字段呢?
可能有些同學說,可以強行推動下游去升級,限定期限進行升級,如果下游不升級概不負責,這種方式基本只能自己欺騙自己了,因為當你接口下線導致業務方報錯,這個責任只能你自己負責了。特別的,當某些接口是直接面對消費者時,這個問題會變得更加棘手。
2016 年那會就職過的一家做 AI 產品的公司,上市了一款智能讀書的兒童產品,其基本功能就是繪本圖書翻一頁讀一頁,這也算是 HomeAI 落地比較成功的產品了,這個產品在天貓、京東的銷量還可以。在 AI 風口的那會,最開始的定位的功能就是讀書,隨着市場的拓展,功能也逐漸變得複雜起來,當時最痛苦的事情莫過於短短 3 個月內,接口版本號從 v1 增加到 v12。由於當時產品的理念認為強制升級是不優美的,不符合產品設計美學,導致這款產品是沒有強制升級功能的,於是導致的結果是 v1 到 v12 的接口總是有用戶在使用的。你可能會說發公告、短訊通知用戶在某個期限內升級,如果不升級,出現產品無法使用情況概不負責,這也是行不通的,特別那些用戶付費的產品,如果萬一不能使用的話,那 12315 是會找上門的。
就在我們被無法下線的 API 接口折磨的時候,經過調研之後發現 GraphQL 正好有一個功能,「API 演進無需劃分版本」,這不是瞌睡來了就有枕頭嗎,於是在技術負責人帶領下(GraphQL 改造項目還沒上線,他去了 Microsoft),我們開始推進 GraphQL 的改造工作。
說到這裡基本上就把 GraphQL 的最容易吸引人的優點介紹完了。我們要知道沒有任何技術是「銀彈」,當某些人給你狂吹某個技術的優點,而沒有說這項技術的缺點限制,或者簡略的一筆帶過的時候,你就需要小心了,說不定你就是那個小白鼠。
下面就進入我經歷的 GraphQL 項目遇到的問題,也許我的處理方式是不正確,以下觀點僅供參考。
GraphQL 難題
社區活躍度問題
GraphQL 是由 Facebook 開發,Facebook 也成立了 GraphQL 基金會,但是 Facebook 官方只提供了 JS 版本的開源實現,其他語言的實現都是 GraphQL 對應語言的非官方社區實現的,這就造成不同語言的理解和實現是有差異的。比如 Graphql schema 的合併工具,只有 JS 官方實現有對應的實現。
GraphQL 屬於那種大家都覺得很不錯,但是經過近 10 年的發展,依然是不溫不火。

上面這個圖是 GraphQL 官方的 landscape,你仔細看上面公司圖標,一眼能看出來的大的公司只有 Github 了。Facebook 雖說是推出了 GraphQL 的規範以及 JS 的相關實現,但是他自己都沒有放出有關 GraphQL 的實際接口,讓人對這個技術的信任度都大打折扣。
當你遇到 GraphQL 問題的時候,要麼搜出來全是 JS 的相關實現,要麼乾脆就沒有人回答,總之 GraphQL 相關社區看着文檔很豐富,其實遇到問題時能搜到解決問題的有用的資料並不多。
緩存問題
緩存對於 REST 接口來說是很容解決的,但是在 GraphQL 中卻變得非常複雜。由於 GraphQL 的特性,即便它操作的是同一個實體,每次查詢可能都各不相同。
舉個例子,由於客戶端可以自定義其需要的字段,如某次請求只需要某個人的名字,但是在另外一次查詢中你可能也想知道他的消費積分。名字可能要查詢 user.userProfile 庫,而且消費積分可能要查詢第三方系統。本次查詢輸入的是單個 user_id,下次查詢輸入的可能就是 userId_list 了,為了解決這些查詢的緩存問題,你可能會設置很多 key 或者每個用戶設置 key-value 放入緩存,這些都不是很優美的解決方案,歸根到底還是因為 GraphQL 太多靈活,服務器的緩存如何設計都跟不上客戶端的靈活的查詢方式。
對於這個問題 Facebook 也有 DataLoader 的解決方案,當然只是 JS 版本的方案,其他語言的社區可能根本都沒有對應的實現。按照我當初的調研這個東西真的不好用,還不如自己做緩存來得快。
GraphQL 緩存不只對服務端不友好,同時對客戶端也是一個挑戰,需要用戶自己做客戶端的緩存,因為 GraphQL Query 只有一個路由,而且都是 POST 方式。
網關問題
GraphQL 是強類型的,所以必須需要一個 schema 的存在。按照當初的實踐經驗,客戶端有且只能存在一份 schema 文件,於是另外一個比較棘手的問題就出現了。
假如我們的服務是類似下圖這個樣子:
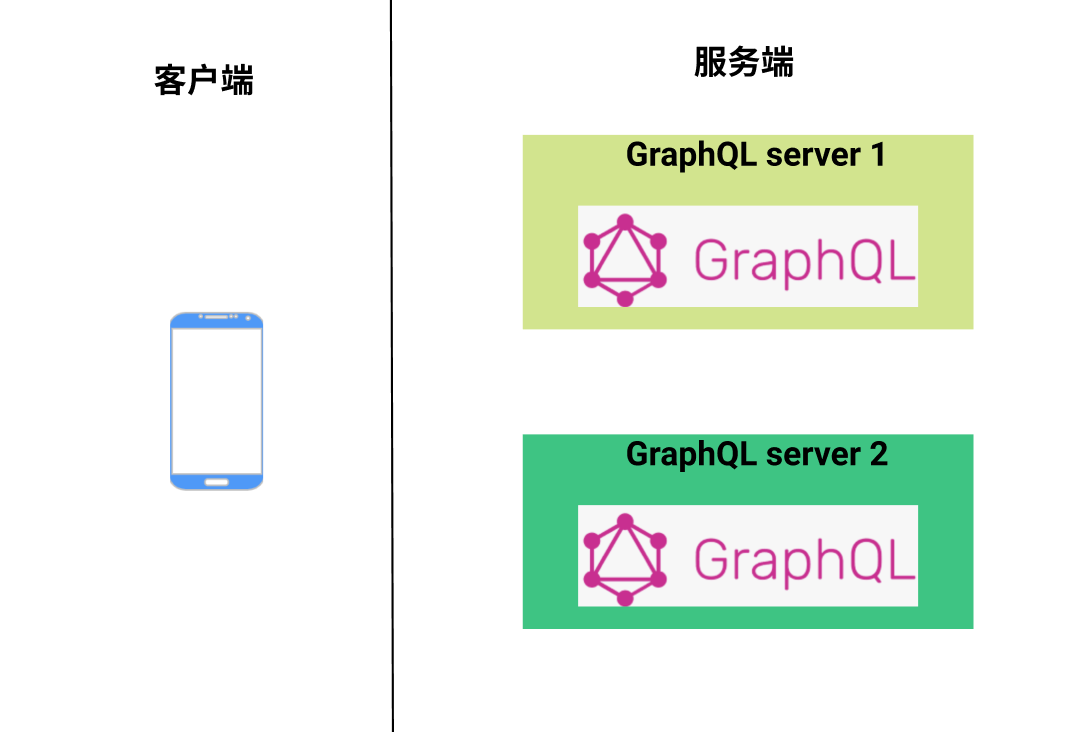
比如 server1 是商品服務,server2 是優惠服務,客戶端如果要對接這兩個服務的話,直接對接是不行的,因為客戶端只能有一個 schema, 但是服務端卻有兩個 schema 文件。
這種情況該如何處理呢?當初經過調研發現 JS 提供了 schema merge 的工具,而且僅僅是個工具。其他語言壓根就沒有這個玩意。
這個的設計還會帶來另外一個非常嚴重的問題,目前的 API 網關都是無法使用的。隨着業務規模的擴大,走上微服務是遲早的事情,但是如果服務端全是基於 GraphQL 開發的,那麼網關該如何處理呢?最近調研了下 APISIX 和 KONG 的最新版本,這兩個業界有影響力的網關也僅僅是支持 GraphQL 協議的轉發而已。
在我看來,在如今微服務比較流行市場下,GraphQL 唯一比較契合的場景的就是將 BFF 的 REST 換成 GraphQL,該 BFF 即做網關也做業務。其實這樣做,也不是很完美,即限定了客戶端只能有這一個 BFF,同時也讓 BFF 變得不純粹起來。看到美團有篇介紹 GraphQL 的實踐的文章,就是讓 GraphQL 做的 BFF 的相關工作,不過他們沒有將 GraphQL 暴露給客戶端,而是在 GraphQL 之上又包裹了一層 HTTP 接口。
複雜度問題
GraphQL 最大的好處就是客戶端能按需查詢,是便利了客戶端,但是把問題的複雜度都移交給了服務器。服務器也不是想查就能查的,畢竟服務器也是資源限制的,不可能無限制的讓客戶端去索取。
query deep3 {
viewer {
albums {
songs{
author {
company {
address {
...
}
}
}
}
}
}
}
由於 GraphQL 要追求從一個類型能查到 schema 的任意類型。比如這樣的查詢,能無限嵌套下去,每個 Type 對服務器來說都是對應的查詢,服務器肯定承受不了的。
如何限制呢?GraphQL 提出的有複雜度和深度的相關概念,但是這兩個值該如何去計算,只能靠服務器開發人員的估計。於是這樣的場景就經常出現,開發初期約定複雜度 1000,過了兩天客戶端同學找了過來要提高到 3000,全是無盡的扯皮,不管設置多少,由於客戶端查詢的多樣性總有不夠用的情形出現。而且這個複雜度、深度是全局的,不是每一個 Query 能單獨配置,這樣就會造成這兩個值最後變得可有可無。
限流問題
限流也是 GraphQL 的最難解決的難題之一,服務端不可能沒有限流的,不然服務器穩定性就保障不了。對於 REST 來說接口的路由都是固定不變的,針對於不同的 URI 做限流是很容做到的。但是 GraphQL 限流的難點在哪裡呢?
query maliciousQuery {
album(id: "some-id") {
photos(first: 9999) {
album {
photos(first: 9999) {
album {
photos(first: 9999) {
album {
#... Repeat this 10000 times...
}
}
}
}
}
}
}
}
這個請求會導致什麼問題呢?客戶端會發起一個請求 maliciousQuery,這個請求會去查詢 some-id 的 album,這個 album 獲取這個相冊里的最大 9999 張圖片,每個圖片又要查詢到所屬的相冊,就這麼無限制的嵌套下去。這樣的查詢,服務器根本就影響不來,上面說到的複雜度和深度其實有點用處,但是用處不大。
曾經遇到這樣的真實場景,GraphQL 項目已經部署線上,複雜度和深度也配置了,客戶端同學在獲取商品分頁列表的同時也將對應商品詳情以及商品詳情的級聯內容給取了出來,導致的結果服務器直接 OOM。原因跟上面這個例子很相似,就是嵌套的查詢過多導致的。這個問題其實跟複雜度和深度是相關的,但是複雜度和深度真的是很難評估。
所以 GraphQL 限流的難題就在於客戶端只發起一次請求,但是在服務器端可能被放大無數倍。如何能夠有效的評估某個值能讓客戶端的嵌套比較合理,根據實踐經驗來看,這個值不是官方提供的複雜度和深度能解決的。
不過好消息 GraphQL 提供一種評估 GraphQL 限流的方式,另外一個中文版本的理論解析解決 GraphQL 的限流難題。理論是一回事,不過實施起來依然是困難重重。
結論
本文主要介紹了我曾經經歷過的 GraphQL 落地的一點感悟,距離如今也有一段時間了,GraphQL 留給我的印象就停留在這些無法解決的問題上。曾經有人諮詢我想用 GraphQL 去重構某個服務,被我比較激動的給打消了這個念頭。這篇文章可能也有寫的不對的地方,歡迎同學們指出。


