Linux從頭學08:Linux 是如何保護內核代碼的?【從實模式到保護模式】

作 者:道哥,10+年的嵌入式開發老兵。
公眾號:【IOT物聯網小鎮】,專註於:C/C++、Linux操作系統、應用程序設計、物聯網、單片機和嵌入式開發等領域。 公眾號回復【書籍】,獲取 Linux、嵌入式領域經典書籍。
轉 載:歡迎轉載文章,轉載需註明出處。
在之前的 7 篇文章中,我們一直學習的是最原始的 8086 處理器中的最底層的基本原理,重點是內存的尋址方式。
也就是:CPU 是如何通過[段地址:偏移地址],來對內存進行尋址的。
不知道你是否發現了一個問題:
所有的程序都可以對內存中的任意位置的數據進行讀取和修改,即使這個位置並不屬於這個應用程序。
這是非常危險的,想一想那些心懷惡意的黑帽子黑客,如果他們想做一些壞事情,可以說是隨心所欲!
面對這樣的不安全行為,處理器一點辦法都沒有。
所以,Intel 從 80286 開始,就對增加了一個叫做保護模式的機制。
PS: 相應的,之前 8086 中的處理器執行模式就叫做「實模式」。
雖然 80286 沒有形成一定的氣候,但是它對後來的 80386 處理器提供了基礎,讓 386 獲得了極大的成功。
這篇文章,我們就從 80386 處理器開始,聊一聊
保護模式究竟保護了誰?
底層是通過什麼機制來實現保護模式的?
我們的學習目標,就是弄明白下面這張圖:
從 16 位進入到 32 位
8086 的 16 位模式
在 8086 處理器中,所有的寄存器都是 16 位的。
也正因為如此,處理器為了能夠得到 20 位的物理地址,需要把段寄存器的內容左移 4 位之後,再加上偏移寄存器的內容,才能得到一個 20 位的物理地址,最終訪問最大 1MB 的內存空間。
例如:在訪問代碼段的時候,把 cs 寄存器左移 4 位,再加上 ip 寄存器,就得到 20 位的物理地址了;
20 位的地址,最大尋址範圍就是 2 的 20 次方 = 1 MB 的空間;
還記得我們第 1 篇文章Linux 從頭學 01:CPU 是如何執行一條指令的?中的寄存器示意圖嗎?

以上這些寄存器都是 16 位的,在這種模式下,對內存的訪問只能分段進行。
而且每一個段的偏移地址,最大只能到 64 KB 的範圍(2 的 16 次方)。
在訪問代碼段的時候,使用 cs:ip 寄存器;
在訪問數據段的時候,使用 ds 寄存器;
在訪問棧的時候,使用 ss:sp 寄存器;
80386 的 32 位模式
進入到 32 位的處理器之後,這些寄存器就擴展到 32 位了:
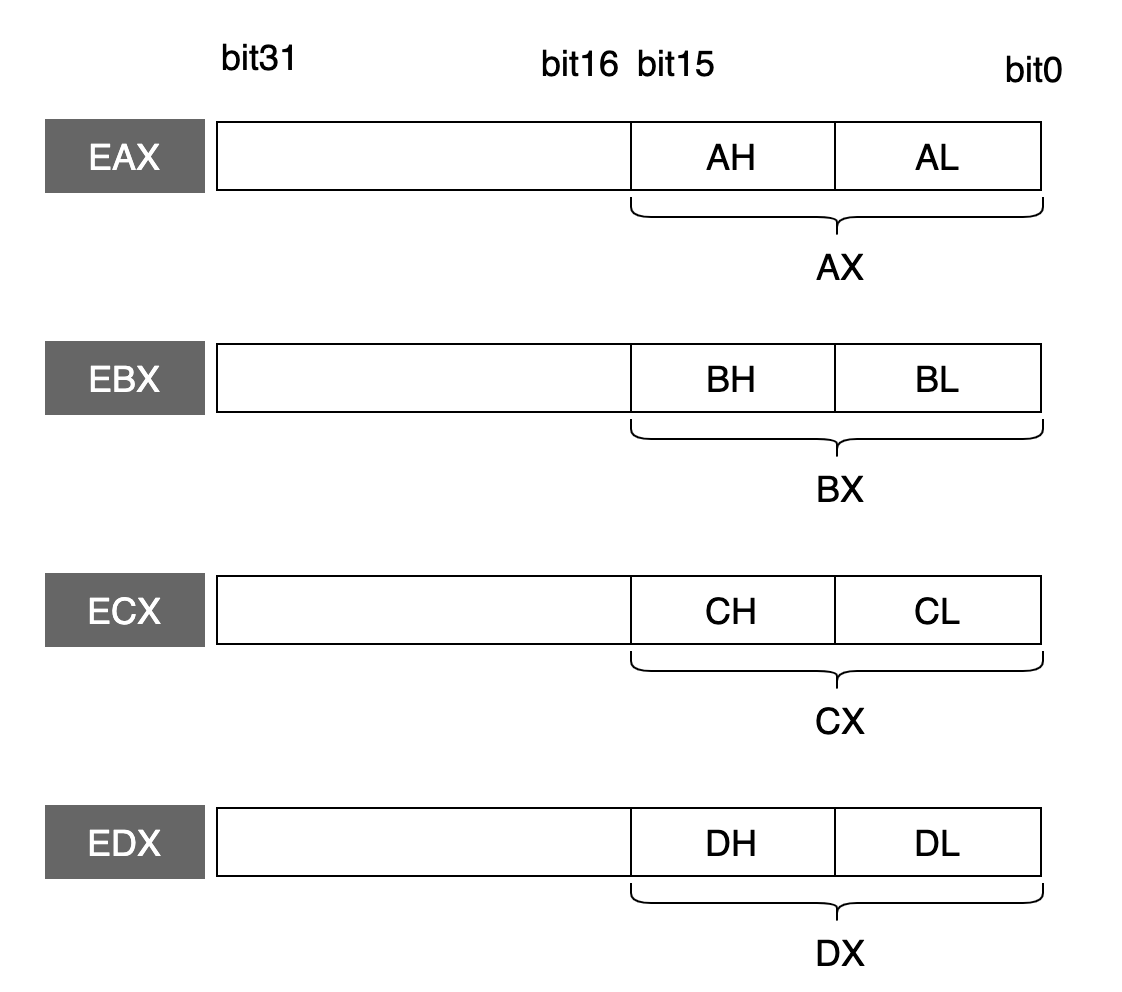
從寄存器的名稱上可以出,在最前面增加了字母 E,表示 Extend 的意思。
這些 32 位的寄存器,低 16 位保持與 16 位處理器的兼容性,也就是可以使用 16 位的寄存器(例如:AX),也可以使用 8 位的寄存器(例如:AH, AL)。
注意:高 16 位不可以獨立使用。
下面這張圖是 32 位處理器的另外 4 個通用寄存器(注意它們是不能按照 8 位寄存器來使用的):

在 32 位的模式下,處理器中的地址線達到了 32 位,最大的內存空間可尋址能力達到 4 GB(2 的 32 次方)。
在 32 位處理器中,依然可以兼容 16 位的處理模式,此時依然使用 16 位的寄存器;
如果不兼容的話,就會失去很大的市場佔有率;
是不是感覺到上面的寄存器示意圖中漏掉了什麼東西?
是的,圖中沒有展示出段寄存器(cs, ds, ss等等)。
這是因為在 32 位模式下,段寄存器依然是 16 位的長度,但是對其中內容的解釋,發生了非常非常大的變化。
它們不再表示段的基地址,而是表示一個索引值以及其他信息。
通過這個索引值(或者叫索引號),到一個表中去查找該段的真正基地址(有點類似於中斷向量表的查找方式):
有些書上把描述符稱之為:段選擇子;
也有一些書上把段寄存器中的值稱之索引值,把段描述符在 GDT 中的偏移量稱之為選擇子;
不必糾結於稱呼,明白其中的道理就可以了;
正是因為處理器有 32 根地址線,可尋址的範圍已經非常大了(4 GB),因此理論上它是不需要像 8086 中那樣的尋址方式(段地址左移 4 位 + 偏移地址)。
但是由於 x86 處理器的基因,在 32 位模式下,依然要以段為單位來訪問內存。
這裡請大家不要繞暈了:剛才描述的段寄存器的內容時,僅僅是說明如何來找到一個段的基地址,也即是說:
對於 8086 來說,段寄存器中的內容左移 4 位之後,就是段的基地址;
對於 80386 來說,段寄存器中的內容是一個表的索引號,通過這個索引號,去查找表中相應位置中的內容,這個內容中就有段的基地址(如何查找,下文有描述);
找到了這個段的基地址之後,在訪問內存的時候,仍然是按照段機制+偏移量的方式。
由於在 32 位處理器中,存儲偏移地址的寄存器都是 32 位的,最大偏移地址可達 4 GB,所以,我們可以把段的基地址設置為 0x0000_0000:

這樣的分段方式,稱作「平坦模型」,也可以理解為沒有分段。
看到這裡,是否聯想起之前的一篇文章中,我們曾經畫過一張 Linux 操作系統中的分段模型:

現在是不是大概就明白了:為什麼這 4 個段的基地址和段的長度,都是一樣的?
從實模式進入到保護模式
如何進入保護模式
CPU 是如何判斷:當前是執行的是實模式?還是保護模式?
在處理器內部,有一個寄存器 CR0。這個寄存器的 bit0 位的值,就決定了當前的工作模式:

bit0 = 0: 實模式;
bit1 = 1: 保護模式;
在處理器上電之後,默認狀態下是工作在實模式。
當操作系統做好進入保護模式的一切準備工作之後,就把 CR0 寄存器的 bit0 位設置為 1,此後 CPU 就開始工作在保護模式。
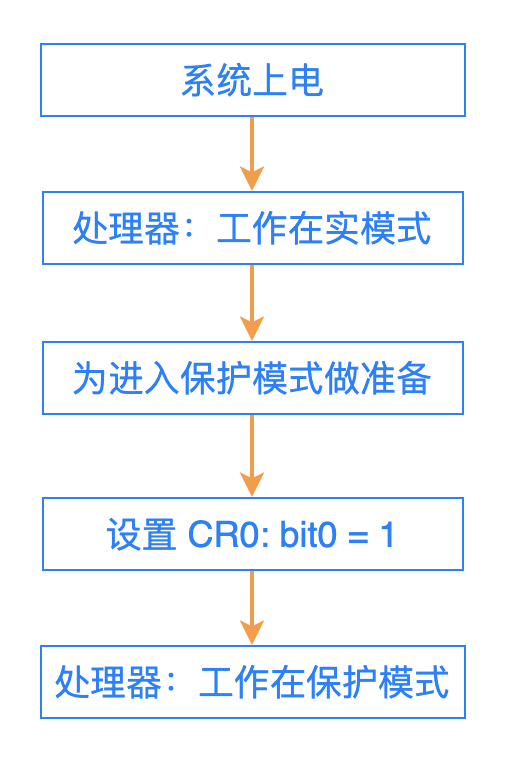
也就是說:在 bit0 設置為 1 之前,CPU 都是按照實模式下的機制來進行尋址(段地址左移 4 位 + 偏移地址);
當 bit0 設置為 1 之後,CPU 就按照保護模式下的機制來進行尋址(通過段寄存器中的索引號,到一個表中查找段的基地址,然後再加上偏移地址)。
GDT 全局描述符表
由於這張表中的每一個條目(Entry),描述的是一個段的基本信息,包括:基地址、段的長度界限、安全級別等等,因此我們稱之為全局描述符表(Global Descriper Table, GDT)。
之所以稱之為全局的,是因為每一個應用程序還可以把段描述符信息,放在自己的一個私有的局部描述符表中(Local Descriper Table,LDT),在以後的文章中一定會介紹到。
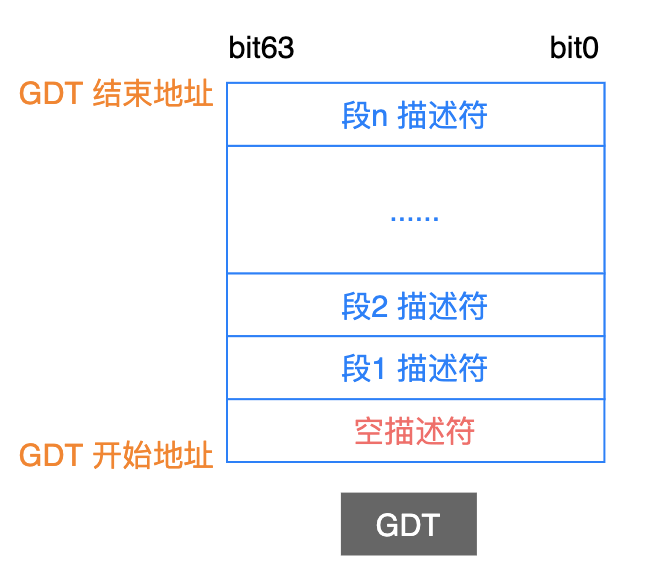
處理器規定:第一個描述符必須為空,主要是為了規避一些程序錯誤。
從上圖中可以看出:GDT 中每一個條目的長度是 8 個位元組,其中描述了一個段的具體信息,如下所示:
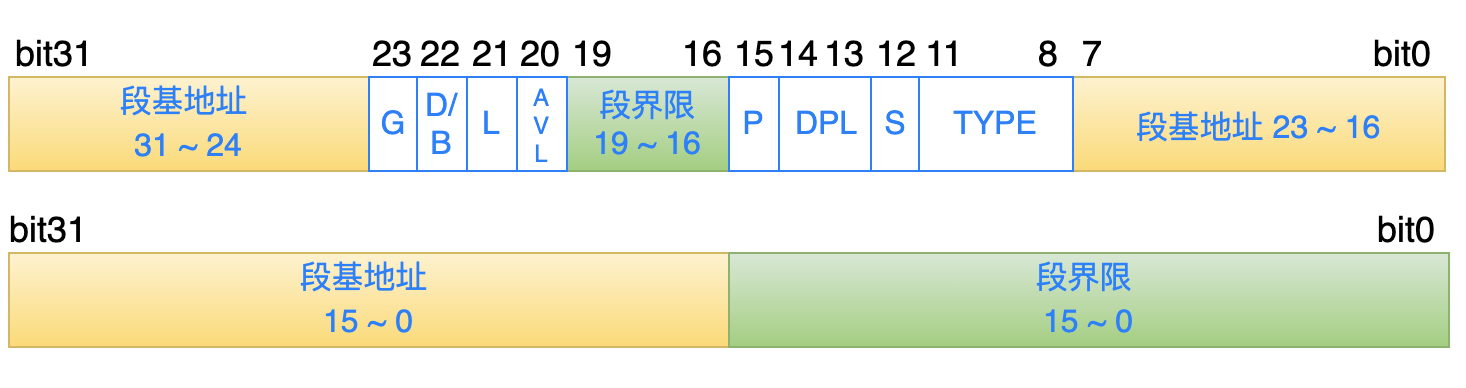
黃色部分:表示這個段在內存中的基地址。
綠色部分:表示這個段的最大長度是多少。
第一次看到這張圖時,是不是心中有 2 個疑問:
為什麼段的基地址不是用連續的 32 bit 位來表示?
段的界限怎麼是 20 位的?20 位只能表示 1 MB 的範圍啊?
第一個問題的答案是:歷史原因(兼容性)。
第二問題的答案是:在每一個描述符中的標誌位 G,對段的界限進行了進一步的粒度描述:
如果 G = 0: 表示段界限是以位元組為單位,此時,段界限的最大表示範圍就是 1 MB;
如果 G = 1:表示段界限是以 4 KB 為單位,此時,段界限的最大表示範圍就是 4 GB( 1 MB 乘以 4KB);
為了完整性,我把所有標誌位的含義都匯總如下,方便參考:
D/B (bit22):用來決定數據段 or 棧段使用的偏移寄存器是 16 位 還是 32 位。

L (bit21):在 64 位系統中才會使用,暫時先忽略。
AVL (bit20):處理器沒有使用這一位內容,被操作系統可以利用這一位來做一些事情。
P (bit15):表示這個段的內容,當前是否已經駐留在物理內存中。

在 Linux 系統中,每一個應用程序都擁有 4 GB(32位處理器) 的虛擬內存空間,而且一個系統中可以同時存在多個應用程序。
這些應用程序在虛擬內存中的代碼段、數據段等等,最終都是要映射到物理內存中的。
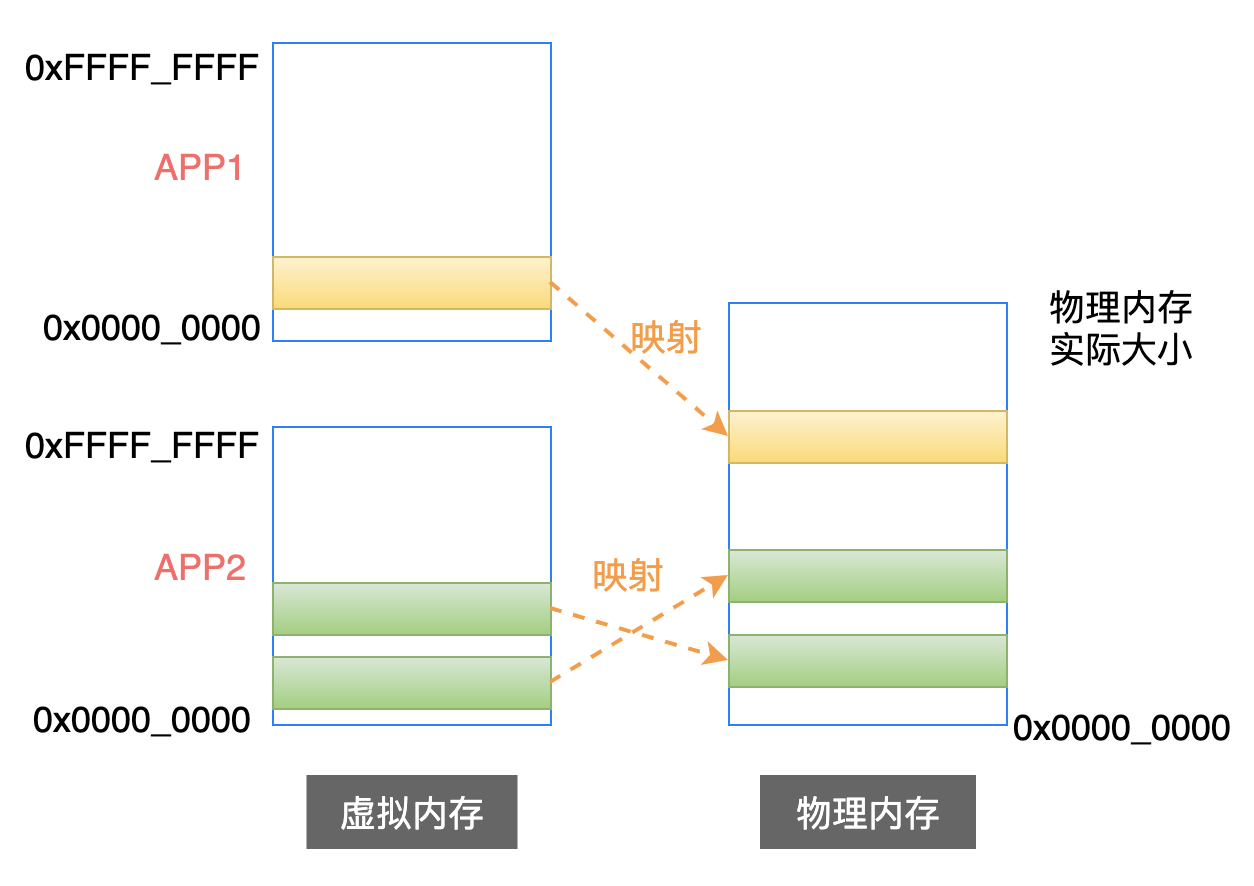
但是物理內存的空間畢竟是有限的,當物理內存緊張的時候,操作系統就會把當前不在執行的那些段的內容,臨時保存在硬盤上(此時,這個段描述符的 P 位就設置為 0),這稱之為換出。
當這個被換出的段需要執行時,處理器發現 P 位為 0,就知道段中的內容不在物理內存中,於是就在物理內存中找出一塊空閑的空間,然後把硬盤中的內容複製到物理內存中,並且把 P 位設置為 1,這稱之為換入。
DPL (bit14 ~ 13):指定段的特權級別,處理器一共支持 4 個特權級別:0,1,2,3(特權級別最低)。
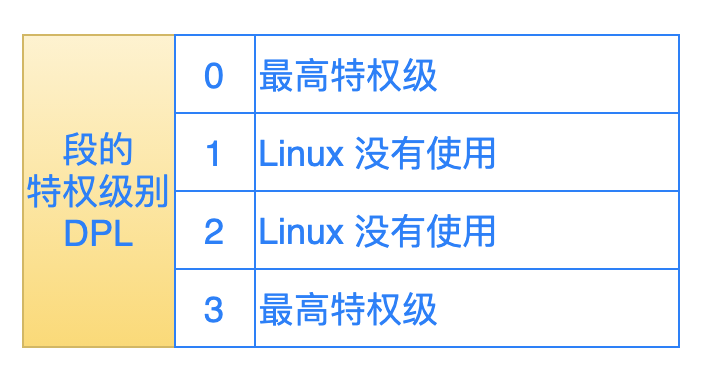
比如:操作系統的代碼段的特權級別是 0,而一個應用程序在剛開始啟動的時候,操作系統給它分配的特權級別是 3,那麼這個應用程序就不能直接去轉移到操作系統的代碼段去執行。
在 Linux 操作系統中,只利用了 0 和 3 這兩個特權級別。
S (bit12):決定這個段的類型。

TYPE (bit11 ~ 8):用來描述段的一些屬性,例如:可讀、可寫、擴展方向、代碼段的執行特性等等。

這裡的依從屬性不太好理解,它主要用於決定:從一個低特權級別的代碼,是否可以進入另一個高特權級別的代碼。
如果可以進入,那麼當前任務的請求級別 RPL 是否發生改變(以後會討論這個問題)。
另外,操作系統可以把 A 標誌,加入到物理內存的換出換入計算策略中。
這樣的話,就可以避免把最近頻繁訪問的物理內存換出,達到更好的系統性能。
GDTR 全局描述符表寄存器
還有一個問題需要處理:GDT 表本身也是數據,也是需要存放在內存中的。
那麼: 它存放在內存中的什麼位置呢?CPU 又怎麼能知道這個起始位置呢?
在處理器的內部,有一個寄存器:GDTR (GDT Register),其中存儲了兩個信息:

我們可以從上一篇文章Linux從頭學07:【中斷】那麼重要,它的本質到底是什麼?中,中斷向量表的安裝過程中進行類比:
程序代碼把每一個中斷的處理程序地址,放在中斷向量表中的對應位置;
中斷向量表的起始地址放在內存的 0 地址處;
也就是說:處理器是到固定的地址 0 處,查找中斷向量表的,這是一個固定的地址。
而對於 GDT 表而言,它的起始地址不是固定的,而是可以放在內存中的任意位置。
只要把這個位置存放到寄存器 GDTR 中,處理器在需要的時候就可以通過 GDTR 來定位到 GDT 的起始地址。
其實,GDT 在上電剛開始的時候,也不能放在內存中的任意位置。
因為在進入保護模式之前,處理器還是工作在實模式,只能尋址 1 MB 的內存空間,因此,GDT 只能放在 1 MB 內的地址空間中。
在進入保護模式之後,能尋址更大的地址空間了,此時就可以重新把 GDT 放在更大的地址空間中了,然後把這個新的起始地址,存儲到 GDTR 寄存器中。
從 GDTR 寄存器中的內容可以看出,它不僅存儲了 GDT 的起始地址,而且還限制了 GDT 的長度。
這個長度一共是 16 位,最大值是 64 KB( 2 的 16 次方),而一個段描述符信息是 8 B,那麼 64 KB 的空間,最多一共可以存放 8192 個描述符。
這個數字,對於操作系統或者是一般的應用程序來說,是綽綽有餘了。
段描述符的查找原理
在上面的段寄存器示意圖中,我們只說明了段寄存器依然是 16 位的。
在保護模式下,對其中內容的解釋,與實模式下是大不相同的。
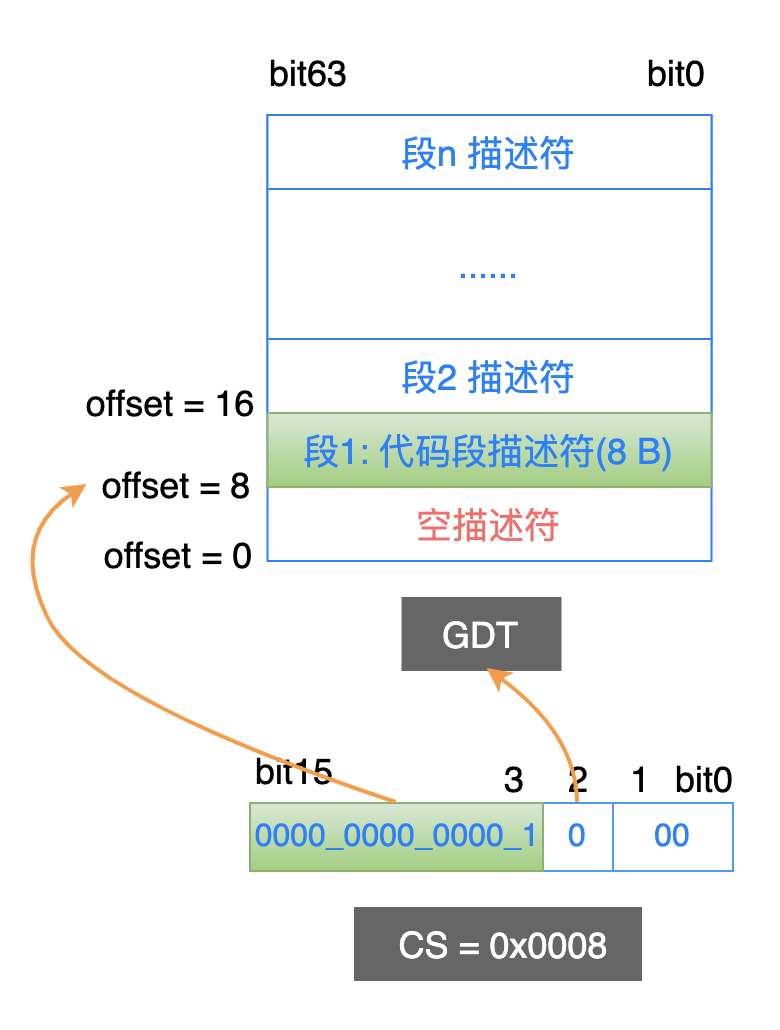
我們以代碼段寄存器 CS 為例:

RPL: 表示當前正在執行的這個代碼段的請求特權級;
TI: 表示到哪一個表中去找這個段的描述信息:全局描述符表(GDT) or 局部描述符表(LDT)?
TI = 0 時,到 GDT 中找段描述符;
TI = 1 時,到 LDT 中找段描述符;
假設當前代碼段寄存器 cs 的值為 0x0008,處理器按照保護模式的機制來解釋其中的內容:
TI = 0,表示到 GDT 中查找段描述符;
RPL = 0,表示請求特權級別是 0;
描述符索引是 1,表示這個段描述符在 GDT 中的第 1 個條目中。由於每一個描述符佔用 8 個位元組,因此這個描述符的開始地址位於 GDT 中的偏移地址為 8 的位置(1 * 8 = 8);
找到了這個段描述符條目之後,就可以從中獲取到這個代碼段的具體信息了:
代碼段的基地址在內存中什麼位置;
代碼段的最大長度是多少(在獲取指令時,如果偏移地址超過這個長度,就引發異常);
代碼段的特權級別是多少,當前是否駐留在物理內存中等等;
另外,從上文描述的 GDTR 寄存內容知道,它限制了 GDT 中最多一共可以存放 8192 個描述符。
我們再從代碼段寄存器中,描述符索引字段所佔據的 13 個 bit 位可以計算出,最多可以查找 8192 個段描述符。
2 的 13 次方 = 8192。
至此,處理器就在保護模式下,查找到了一個段的所有信息。
下面步驟就是:到這個段所在的內存空間中,執行其中的代碼,或者讀寫其中的數據。
下一篇文章我們繼續。。。
—— End ——
這篇文章主要描述了 80386 處理器中的保護模式下,段寄存器的使用,以及通過段描述符來查找段的具體信息。
從描述的內容來看,已經和我們的最終目標:Linux 操作系統中的執行方式,越來越接近了!
因為這些底層知識,都是 Linux 操作系統賴以運行的基礎。
理解了這些基礎內容,後面在學習 Linux 的具體模塊時,就可以回過頭來查一下它在處理器層面的底層支撐。
最後,如果這篇文章對您有一點幫助,請轉發給身邊的技術小夥伴,也是對我繼續輸出文章的最大鼓勵和動力!
讓我們一起出發,向著目標繼續邁進!
推薦閱讀
【1】C語言指針-從底層原理到花式技巧,用圖文和代碼幫你講解透徹
【2】一步步分析-如何用C實現面向對象編程
【3】原來gdb的底層調試原理這麼簡單
【4】內聯彙編很可怕嗎?看完這篇文章,終結它!
其他系列專輯:精選文章、C語言、Linux操作系統、應用程序設計、物聯網

星標公眾號,能更快找到我!


