從哈夫曼編碼中我們學到了什麼?
大家還記得我們在數據結構里學的哈夫曼編碼嗎?今天我們就來重新溫習一下哈夫曼編碼,以及通過哈夫曼編碼,我們能學到什麼核心思想呢。在開始之前,我們先回顧一下什麼是哈夫曼編碼。哈夫曼編碼是一種對數據進行壓縮的編碼方式,可以有效節省存儲空間。我們來看一個例子,假如我們有一個長度為200的字符串電文要傳輸,並且只包含6種不同的字符,分別是A、B、C、D、E、F。如果明文傳輸的話,那每個字符佔一個位元組,就會佔用200位元組的空間。為了節省空間,我們可以採用3個二進制位來表示一個字符。如下所示:
a(000)、b(001)、c(010)、d(011)、e(100)、f(101)那我們就可以用200*3=600個二進制位來傳輸,而原來明文需要佔用1600個二進制位(1個位元組等於8個二進制位),所以節省了空間。那還有沒有更節省空間的方式了呢?那就是哈夫曼編碼了。
哈夫曼編碼
哈夫曼編碼不僅會考慮不同字符的個數,同樣會考慮每個字符出現的頻率,根據頻率的不同,選擇不同長度的編碼。由於哈夫曼編碼採用的是不等長的,那我們每次應該讀取幾位來解壓縮呢?這個問題就會導致解壓縮會複雜一些。為了避免解壓縮過程中的歧義,哈夫曼編碼要求給各個字符的編碼時,不會出現某個編碼是另一個編碼前綴的情況。
下面我們來具體看一下哈夫曼編碼的編碼過程。首先我們假設這6個字符出現的頻率如下圖所示:

我們把每個字符當作一個節點,並且把他們插入到優先級隊列中(按照頻率由小到大來排序)。然後我們從隊列中取出頻率最小的兩個節點 A、B,然後新建一個節點 X,把頻率設置為兩個節點的頻率之和,並把這個新節點 X 作為節點 A、B 的父節點。最後再把 X 節點放入到優先級隊列中。重複這個過程,直到隊列中沒有數據。如下圖所示:


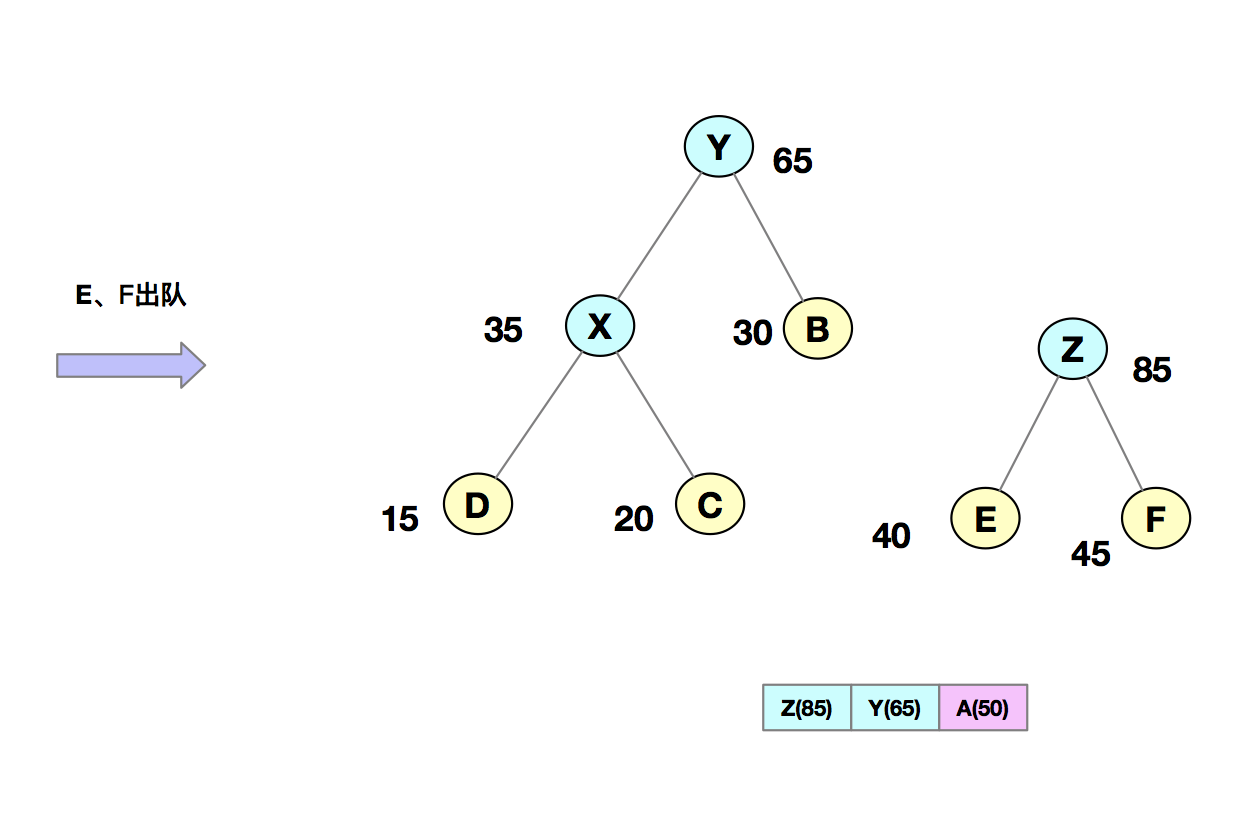
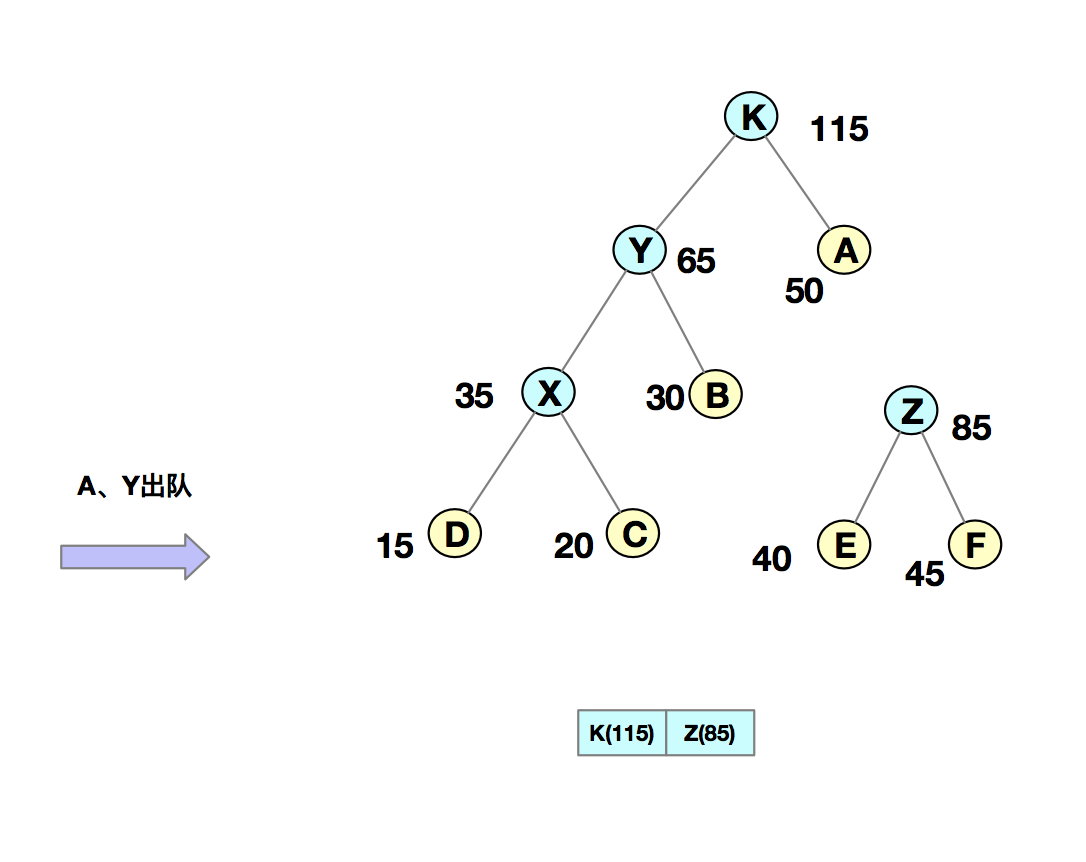
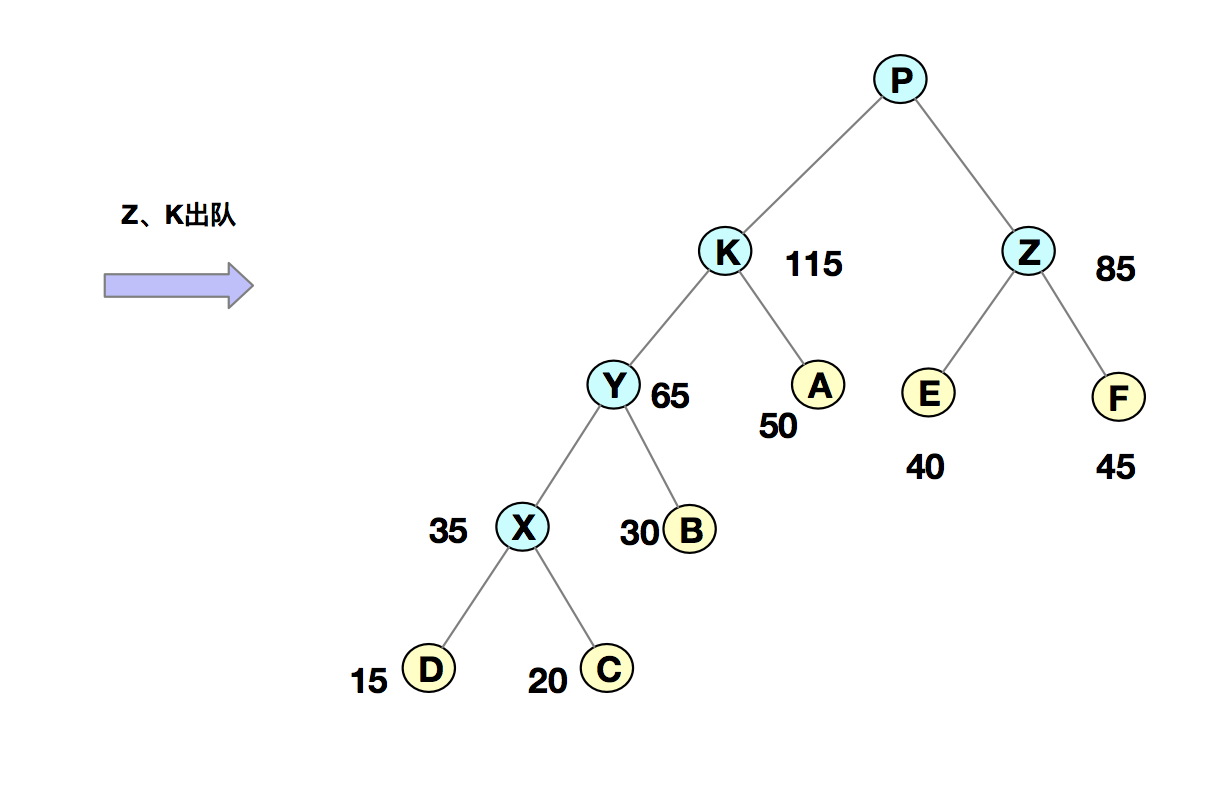
然後,我們給每一條邊加上一個權值,指向左子節點的邊記為 0,指向右子節點的邊,標記為 1,那從根節點到葉節點的路徑就是葉節點對應字符的哈夫曼編碼。

到目前為止,我們已經把哈夫曼編碼的講完了。現在我們把這個問題抽象一下,哈夫曼編碼的目標是用較少的空間來存儲給定長度的字符串。那我們該如何對字符串的字符進行編碼,才能使得空間最小呢?一個直觀的想法是,我們把出現頻率比較多的字符,用稍微短一些的編碼;把出現頻率比較少的字符,用稍微長一些的編碼。這就是貪心算法的思想。下面我們來分析一下,對於什麼樣的問題,我們可以採用貪心算法呢?
貪心算法模型
如果你遇到針對一組數據,定義了限制值和期望值,希望從中選出幾個數據,在滿足限制值的情況下,期望值最大。我們首先要想到使用貪心算法。回到哈夫曼編碼的例子,期望值就是編碼後長度最小,限制值就是給定的字符串。這組數據指的就是字符串中的每個不相同的字符,我們對每個字符進行編碼,對給定的字符串進行編碼,使得編碼後的長度最小。
然後嘗試看下這個問題是否可以用貪心算法解決。在對限制值同等貢獻量的情況下,我們選擇對期望值貢獻最大的數據。哈夫曼編碼每個字符對限制值的貢獻量是相同的,都是一個字符的貢獻,選擇編碼最短的,對期望值的貢獻最大。所以,我們把出現頻率最多的字符,用最少的編碼來表示。
以後,在遇到這類問題時,我們就可以考慮一下是否可以抽象成貪心算法模型,如果符合貪心算法模型,那這類問題就可以迎刃而解了。
更多有趣知識,請關注公眾號。如果想要本文的pdf版本,可以在私信我。



