深度強化學習中稀疏獎勵問題Sparse Reward
- 2021 年 8 月 3 日
- 筆記
- deeplearning, 強化學習
Sparse Reward
推薦資料
強化學習算法在被引入深度神經網絡後,對大量樣本的需求更加明顯。如果智能體在與環境的交互過程中沒有獲得獎勵,那麼該樣本在基於值函數和基於策略梯度的損失中的貢獻會很小。
針對解決稀疏獎勵問題的研究主要包括:1
-
Reward Shaping:獎勵設計與學習
-
經驗回放機制
-
探索與利用
-
多目標學習和輔助任務
1. Reward Shaping
人為設計的 「密集」獎勵。
例如,在機械臂「開門」的任務中,原始的稀疏獎勵設定為:若機械臂把門打開,則給予「+1」獎勵,其餘情況下均給予「0」獎勵。然而,由於任務的複雜性,機械臂從隨機策略開始,很難通過自身探索獲得獎勵。為了簡化訓練過程,可以使用人為設計的獎勵:1)在機械臂未碰到門把手時,將機械臂與門把手距離的倒數作為獎勵;2)當機械臂接觸門把手時,給予「+0.1」獎勵;3)當機械臂轉動門把手時,給予「+0.5」獎勵;4)當機械臂完成開門時,給予「+1」獎勵。這樣,通過人為設計的密集獎勵,可以引導機械臂完成開門的操作,簡化訓練過程。
2. 逆向強化學習
針對人為設計獎勵中存在的問題,Ng等2提出了從最優交互序列中學習獎勵函數的思路,此類方法稱為」逆強化學習」。
3. 探索與利用(好奇法):
在序列決策中,智能體可能需要犧牲當前利益來選擇非最優動作,期望能夠獲得更大的長期回報。
在 DRL領域中使用的探索與利用方法主要包括兩類:基於計數的方法和基於內在激勵的方法。其目的是構造虛擬獎勵,用於和真實獎勵函數共同學習。由於真實的獎勵是稀疏的,使用虛擬獎勵可以加快學習的進程。
ICM3(逆環境模型)—— 改進的基於內在激勵的方法
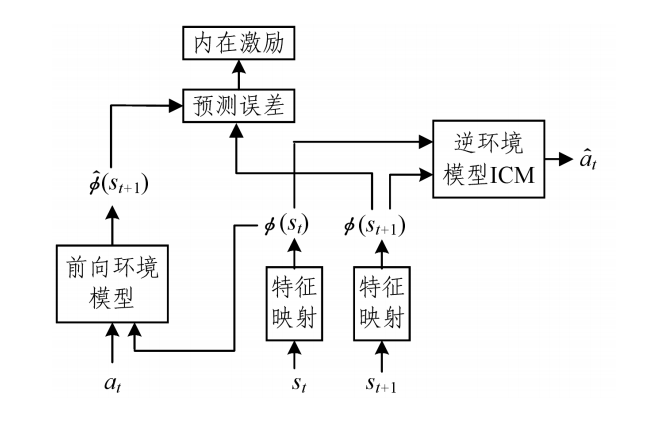
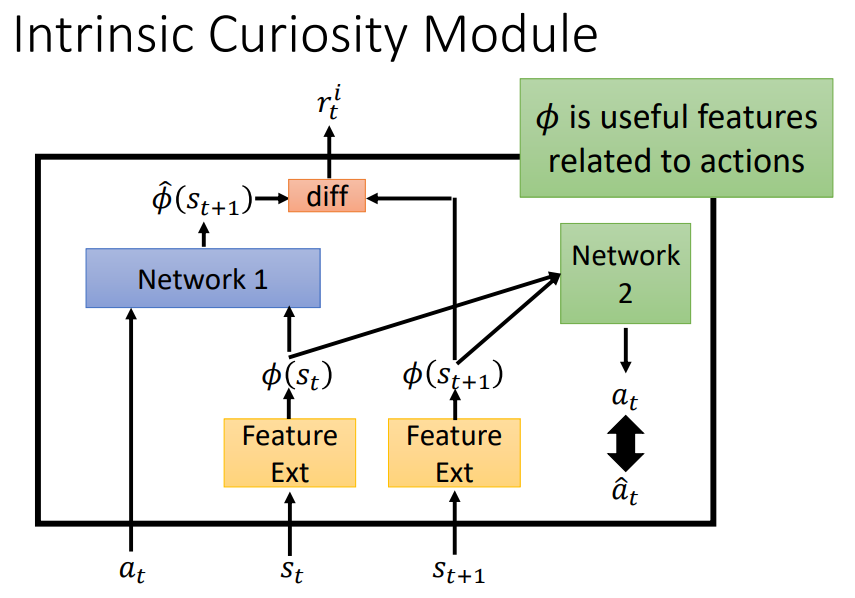
- Network 1:預測的狀態S與實際狀態S差別越大,回報r越大,鼓勵冒險
- Network 2:輸入 \(S_t\) 和 \(S_{t+1}\) ,預測動作 \(a_t\) ,與真實動作差別大時,表示無關緊要的狀態。
- ICM 通過學習可以在特徵空間中去除與預測動作無關的狀態特徵,在特徵空間中構建環境模型可以去除環境噪聲。
4. 多目標學習——層次強化學習
- 智能體可以從已經到達的位置來獲得獎勵。在訓練中使用虛擬目標替代原始目標,使智能體即使在訓練初期也能很快獲得獎勵,極大地加速了學習過程。
- 將一個單一目標,拆解為多個階段的多層級的目標。
5. 輔助任務
在稀疏獎勵情況下,當原始任務難以完成時,往往可以通過設置輔助任務的方法加速學習和訓練。
-
Curriculum Learning,「課程式」強化學習:
當完成原始任務較為困難時,獎勵的獲取是困難的。此時,智能體可以先從簡單的、相關的任務開始學習,然後不斷增加任務的難度,逐步學習更加複雜的任務。
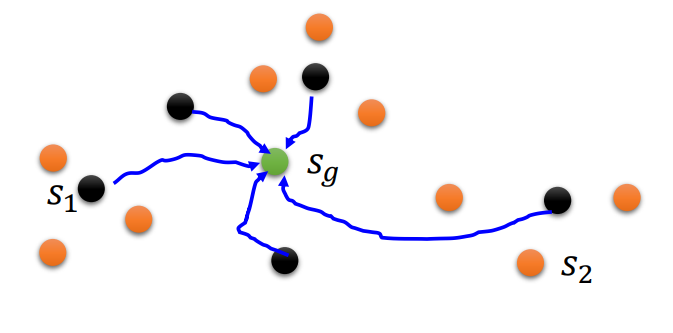
- 直接添加輔助任務:第二類方法是直接在原任務的基礎上添加並行的輔助任 務,原任務和輔助任務共同學習。


