講透樹2 | 樹的遍歷復盤專題
1 前言
大家好,「樹」的刷題已經有一段時間了。
一來二去時間上有所拖延。之前總結過「樹」的基礎遍歷,這一篇來具體題目看看,對於基礎遍歷能遇到哪些問題。
下圖是咱們之前規定的「基礎遍歷」的一些題目。
圍繞,前中後序遍歷對於N叉樹的適用性,已經層序遍歷不同的打印方式,有哪些注意點。
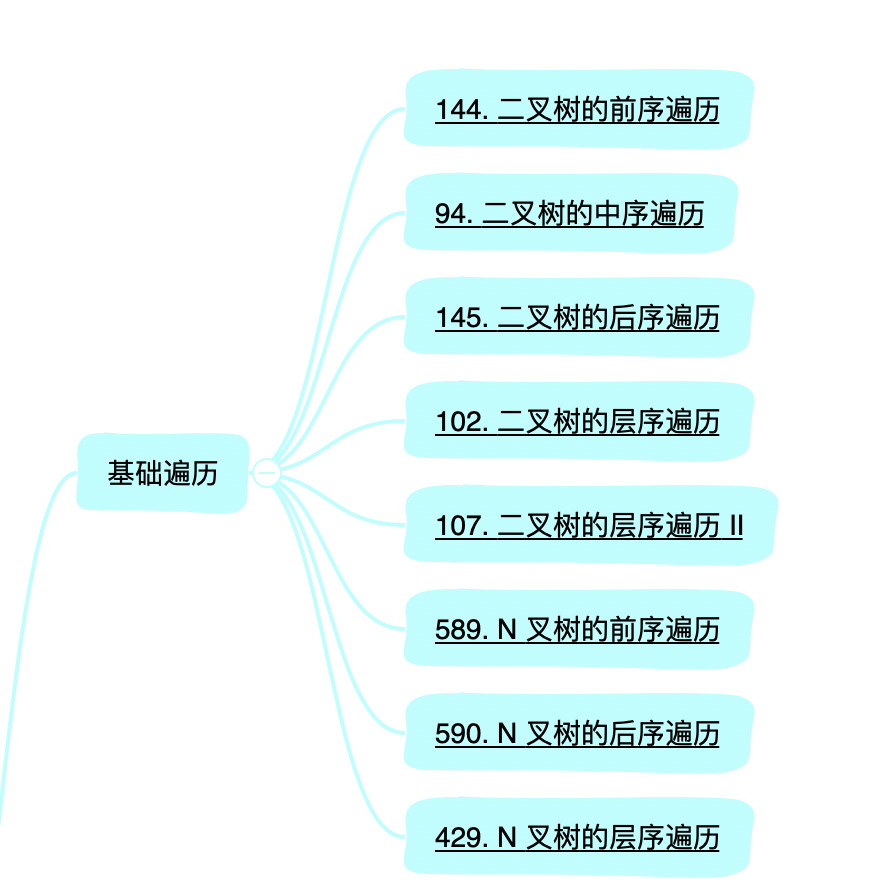
題目如下:
102.二叉樹的層序遍歷
//leetcode-cn.com/problems/binary-tree-level-order-traversal
589.N 叉樹的前序遍歷
//leetcode-cn.com/problems/n-ary-tree-preorder-traversal
107.二叉樹的層序遍歷 II
//leetcode-cn.com/problems/binary-tree-level-order-traversal-ii
145.二叉樹的後序遍歷
//leetcode-cn.com/problems/binary-tree-postorder-traversal
94.二叉樹的中序遍歷
//leetcode-cn.com/problems/binary-tree-inorder-traversal
429.N 叉樹的層序遍歷
//leetcode-cn.com/problems/n-ary-tree-level-order-traversal
144.二叉樹的前序遍歷
//leetcode-cn.com/problems/binary-tree-preorder-traversal
590.N 叉樹的後序遍歷
//leetcode-cn.com/problems/n-ary-tree-postorder-traversal
以上,在 github 記錄://github.com/xiaozhutec/share_leetcode
2 分類
前面我們說過一些基礎的「樹」的遍歷,直達鏈接://mp.weixin.qq.com/s/nTB41DvE7bfrT7_rW_gfXw
有了之前的基礎,很直觀的,可以將上述遍歷的題目分為兩類兩方面
兩類:
第一類,分別是前序遍歷、中序遍歷和後續遍歷
第二類,層次遍歷
兩方面:
第一方面,遞歸實現,適用於前序遍歷、中序遍歷和後續遍歷
第二方面,非遞歸實現適用於前序遍歷、中序遍歷、後續遍歷以及層次遍歷
3 遞歸遍歷
在之前 //mp.weixin.qq.com/s/nTB41DvE7bfrT7_rW_gfXw 的一篇文章中已經詳細說過了遞歸的方式,大家可重新翻開看看。
然後該篇文章由於涉及到 N 叉樹的遍歷方式,因此,咱們對二叉樹和N叉樹進行對比代碼設計,由於其相似性,很容易就破解這幾個題目
首先,定義「樹」結點類,二叉樹和 N叉樹的結點定義不同點
# 二叉樹
class TreeNode(object):
def __init__(self, val, left=None, right=None):
self.val = val
self.left = left
self.right = right
# N叉樹
class Node(object):
def __init__(self, val=None, children=[]):
self.val = val
self.children = children
看起來區別是二叉樹的左右孩子和 N叉樹的孩子們結點的區別,其實本質是一樣的,同理二叉樹的左右孩子也能寫成children列表的形式。
即:
# 二叉樹
class TreeNode(object):
def __init__(self, val, children=[]):
self.val = val
self.children = children
而這裡二叉樹的 children 只有兩個孩子,即左孩子 left 和右孩子 right。
描述完上述的孩子結點的定義,下面再看看遞歸的遍歷方式。
# 二叉樹
res = []
def pre_order(root):
if not root:
return
res.append(root.val)
pre_order(root.left)
pre_order(root.right)
# N叉樹
res = []
def pre_order(root):
if not root:
return
res.append(root.val)
for node in root.children:
pre_order(node)
看出區別了嗎?區別就在 res.append(root.val) 之後的代碼。
二叉樹的寫法是先遞歸左孩子,再遞歸右孩子。
N叉樹的寫法是,利用 for 循環,依次遞歸孩子結點。
所以,區別就是遞歸的寫法,二叉樹寫兩次遞歸,N叉樹寫N次遞歸
都是一樣的邏輯,是不是很簡單。類似於先序遍歷,其中中序遍歷和後續遍歷,都是同樣的邏輯去處理(N叉樹,N可代表從2到n)
github 查看詳細代碼://github.com/xiaozhutec/share_leetcode
4 非遞歸遍歷
非遞歸遍歷先序、中序和後續遍歷的詳細邏輯在也這裡已經寫了,可以返回頭看看 //mp.weixin.qq.com/s/nTB41DvE7bfrT7_rW_gfXw,用長圖的形式以及講的非常明白了。
層次遍歷在「樹-自頂向下」的類別中運用的比較多,相比較於遞歸解法,利用層次遍歷更加容易理解,而且代碼框架比較單一,具體的介紹和案例會在下一篇《講透樹 | 自頂向下類別題目專題》中進行介紹。
本文的非遞歸遍歷主要針對的是層次遍歷。那為什麼之前講的比較明白了,這裡又會說呢?
是這樣,之前講解的層次遍歷,咱們打印出來的形式和 LeetCode 題目中打印出來的形式是有些區別的。而且僅僅因為打印的區別,會引出不一樣的一個思路,後面很多情況都會遇到這樣的思維方式。
如下:
# 經典層次遍歷打印形式
['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I']
# LeetCode 中打印的形式
[['A'], ['B', 'C', 'D'], ['E', 'F', 'G', 'H', 'I']]
是的,LeetCode 中打印的形式是要求將每一層的結點元素單獨放到一個 list 中,最後再放置到一個大的 list 中。
傳統層次遍歷打印形式
先來簡單回顧一下,傳統的打印方式。
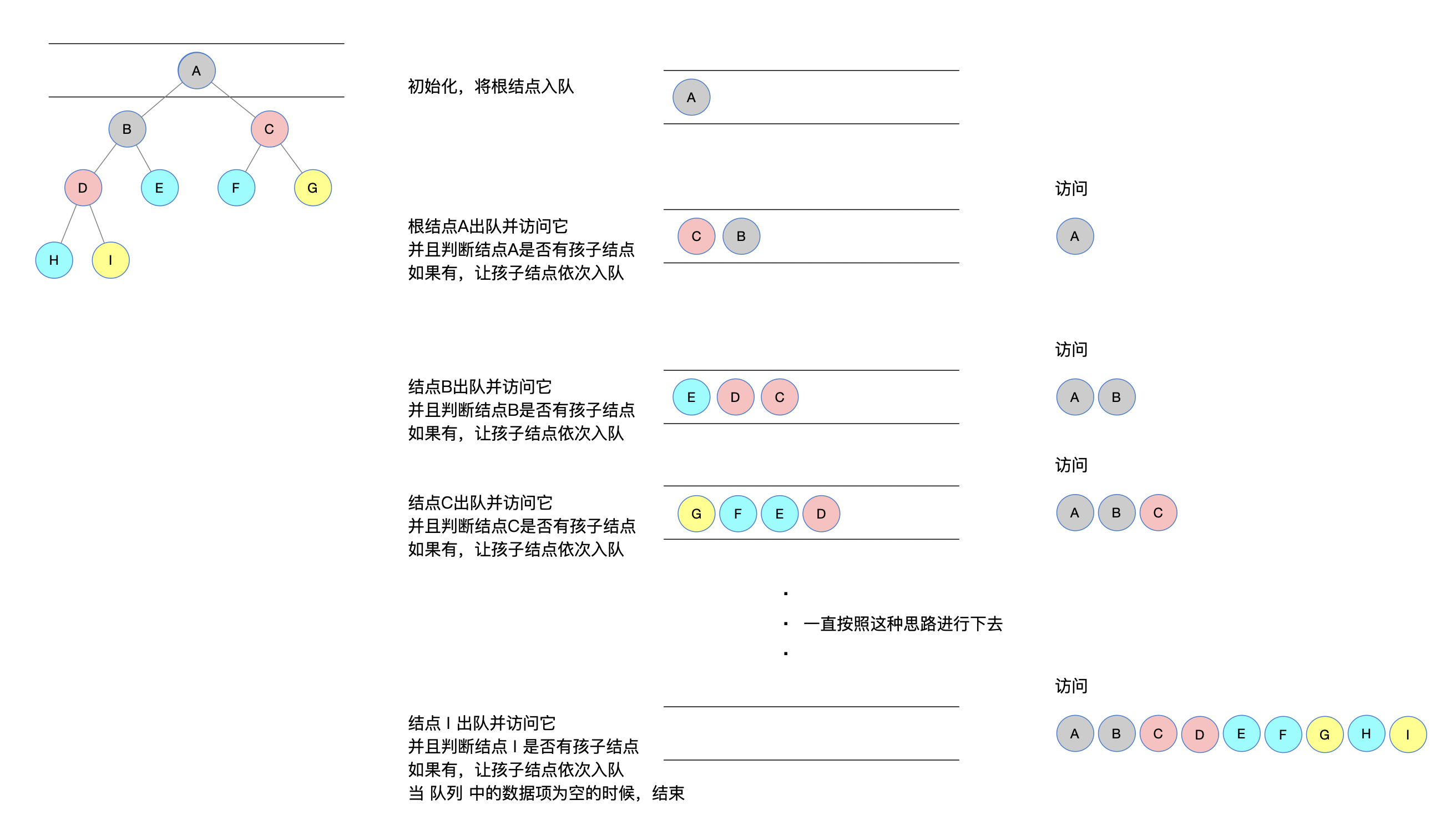
跟着上述圖中的描述,動手畫一下就會明白特別的簡單。
一句話總結就是:
循環判斷隊列 queue 中是否有元素,如果有,訪問該元素並且判斷該結點元素是否有孩子結點,如果有,孩子結點依次入隊 queue,否則,繼續循環執行。
看代碼:
while queue:
node = queue.pop()
res.append(node.val)
if node.left:
queue.appendleft(node.left)
if node.right:
queue.appendleft(node.right)
就是不斷判斷隊列中隊首是夠有元素,如果有元素,訪問該結點元素,並且判斷該結點是否有孩子結點,如果有,則依次入隊。繼續循環判斷。
其實N叉樹來說的話,也是一樣的邏輯,只不過是把二叉樹中的兩個孩子,換為N個孩子,進行入隊操作。
while queue:
node = queue.pop()
res.append(node.val)
for child_node in node.children:
queue.appendleft(child_node)
一樣的道理!是不是比較簡單。
LeetCode 中題目打印方式
也是用一幅圖來描述,相較於經典的層次遍歷,每層單獨存放會稍微複雜一些,需要變換一點點思路。
核心一句話
queue 中存放的是當前層的結點集,level_queue 存放的下一層的結點集合。
每次循環遍歷當前層queue中結點的同時,將該層結點集寫進一個臨時list,將下一層的結點入隊到 level_queue 中。之後將 level_queue 賦值給 queue,循環執行,直到 queue 為空。
最後,將每層臨時 list 寫到一個大的 list 中
「點擊下圖查看高清原圖」👇

上圖是以二叉樹進行舉例子,其實和 N叉樹的邏輯幾乎是一致的,咱們先來看二叉樹的相關核心代碼:
def levelOrder(self, root):
res = []
if not root:
return res
queue = [root]
while queue:
level_queue = [] # 臨時記錄每一層結點
level_res = [] # 臨時記錄每一行的結點值
for node in queue: # 循環遍歷每一層所有的結點
level_res.append(node.val)
if node.left:
level_queue.append(node.left)
if node.right:
level_queue.append(node.right)
queue = level_queue
res.append(level_res)
return res
類似的思路,來看看 N叉樹的層次遍歷代碼:
def levelOrder_leetcode(self, root):
res = []
queue = [root]
if not root:
return res
while queue:
level_queue = [] # 臨時保存每一層結點元素便於下一次進行迭代
level_res = [] # 臨時保存每一層結點值
for node in queue:
level_res.append(node.val)
if node.children:
for child_node in node.children:
level_queue.append(child_node)
queue = level_queue
res.append(level_res)
return res
到這裡,應該已經非常熟悉二叉樹和N叉樹的一些區別了,依舊是在 level_res.append(node.val) 之後的幾行代碼的區別。
本篇文章主要是想說明開篇說的一些關於 LeetCode 上基礎的「樹遍歷」的核心解決思路。
代碼和本文的文檔都在 //github.com/xiaozhutec/share_leetcode,需要的小夥伴可以自行下載代碼運行跑起來!
github 內容剛剛開始更新,感興趣的可以一起來學習。私信我 「LeetCode刷題」 群里一起刷題進步。
手裡有 star 的,有空可以幫我點點 star。謝過大家!

