Linux從頭學03:如何告訴 CPU,代碼段、數據段、棧段在內存中什麼位置?

作 者:道哥,10+年的嵌入式開發老兵。
公眾號:【IOT物聯網小鎮】,專註於:C/C++、Linux操作系統、應用程序設計、物聯網、單片機和嵌入式開發等領域。 公眾號回復【書籍】,獲取 Linux、嵌入式領域經典書籍。
轉 載:歡迎轉載文章,轉載需註明出處。
前兩篇文章,我們一起學習了 8086 處理器中關於 CPU、內存的基本使用方式,重點對段寄存器和內存的尋址方式進行了介紹。
可能有些小夥伴會對此不屑:現在都是多核的現代處理器,操作系統已經變得非常的強大,為何還去學習這些古董知識?
前幾天看到下面這段話,可以來回答這個問題:
「我們都希望學習最新的、使用的東西,但學習的過程是客觀的。」
「任何合理的學習過程(儘可能排除走彎路、盲目探索、不成系統)都是一個循序漸進的過程。」
「我們必須先通過一個易於全面把握的事物,來學習和探索一般的規律和方法。」
就拿學習 Linux 操作系統來說,作為一個長期的學習計劃,不太可能一上來就閱讀最新的 Linux 5.13 版本的代碼。
更有可能是先學習 0.11 版本,理解了其中的一些原理、思想之後,再循序漸進的向高版本進行學習、探索。
那麼對於 《Linux 從頭學》這個系列的文章來說,我是希望自己能夠把學習路線再拉長一些,從更底層的硬件機制、驅動原理開始,由簡入繁,一步一步最終把 Linux 操作系統這個塊硬骨頭給啃下來。
那麼今天我們就繼續 8086 下的學習,來看看一個相對「完整」程序的基本結構。
幾個重要的段寄存器
在 x86 系統中,段尋址機制以及相關的寄存器是如此的重要,以至於我忍不住在這裡,把幾個段寄存器再小結一下。
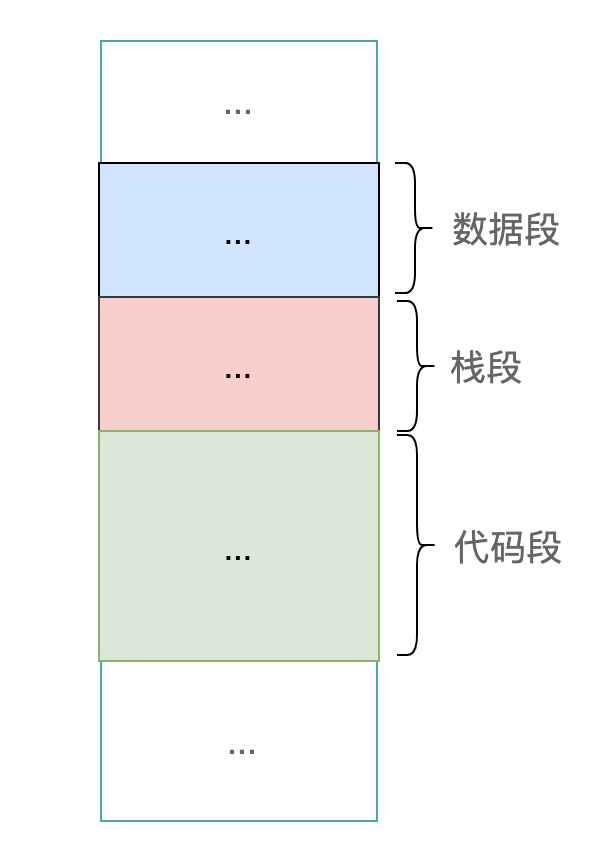
代碼段:用來存放代碼,段的基地址放在寄存器 CS 中,指令指針寄存器 IP 用來表示下一條指令在段中的偏移地址;
數據段:用來存放程序處理的數據,段的基地址存放在寄存器 DS 中。對數據段中的某個數據進行操作時,直接在彙編代碼中通過立即數或寄存器來指定偏移地址;
棧段:本質上也是用來存放數據,只不過它的操作方式比較特殊而已:通過 PUSH 和 POP 指令來進行操作。段的基地址存放在寄存器 SS 中,棧頂單元的偏移地址存放在寄存器 IP 中。
這裡的段,本質上是我們把內存上的某一塊連續的存儲空間,專門存儲某一類的數據。
我們之所以能夠這麼做,是因為 CPU 通過以上幾個寄存器,讓我們這樣的「安排」稱為一種可能。
一句話總結:CPU 將內存中的某個段的內容當做代碼,是因為 CS:IP 指向了那裡;CPU 將某個段當做棧,是因為 CS:SP 指向了那裡。
在之前的一篇文章中,演示了一個 ELF 格式的可執行文件中,具體包含了哪些段《Linux系統中編譯、鏈接的基石-ELF文件:扒開它的層層外衣,從位元組碼的粒度來探索》:
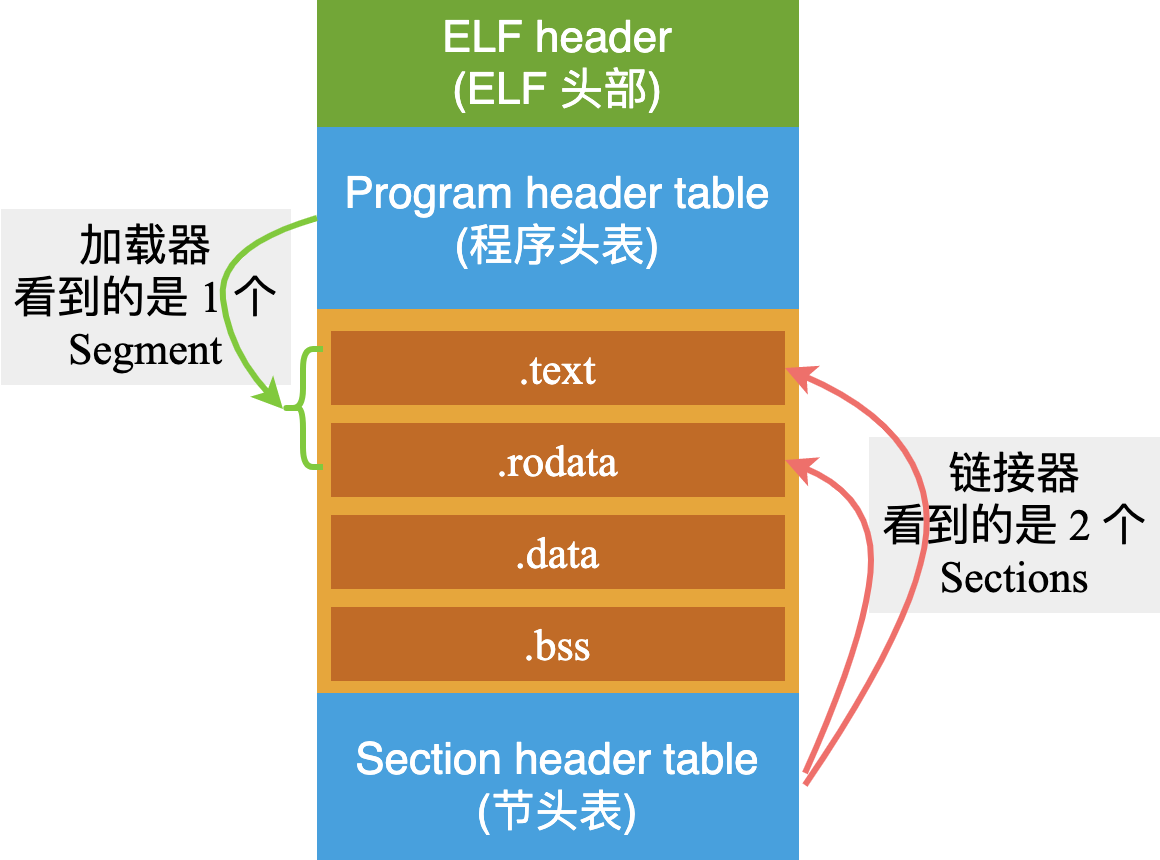
雖然這張圖中描述的段結構更複雜,但是從本質上來說,它與 8086 中描述的段結構是一樣的!
Linux 2.6 中的線性地址區間
在一個現代操作系統中,一個進程中使用的的地址空間,一般稱作虛擬地址(也稱作邏輯地址)。
虛擬地址首先經過段轉換,得到線性地址;然後線性地址再經過分頁轉換,得到最終的物理地址。
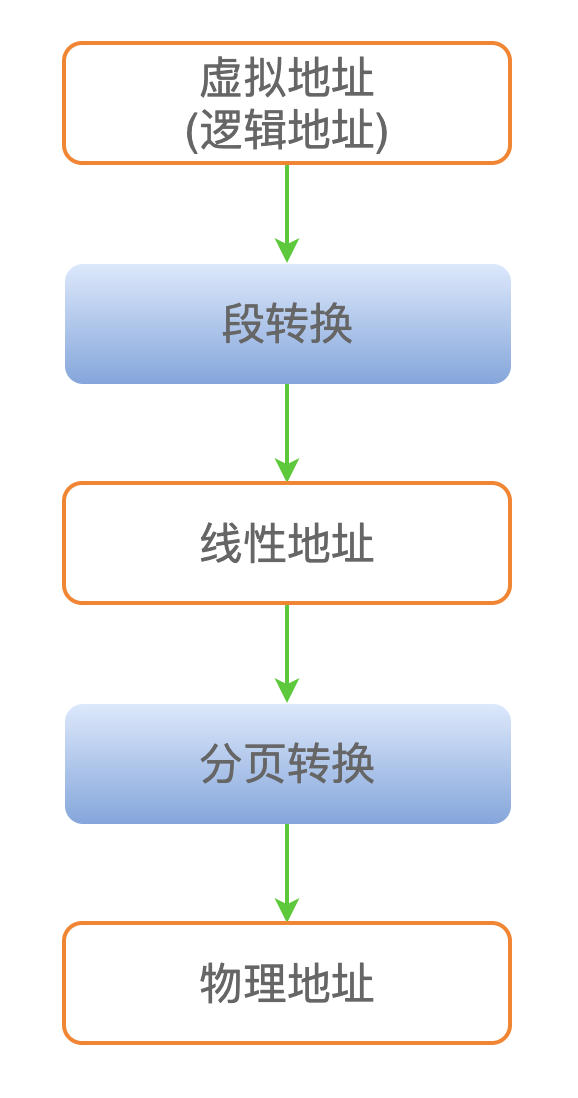
這裡再啰嗦一下,很多書籍中隊內存地址的稱呼比較多,都是根據作者的習慣來稱呼。
我是按照上圖的方式來理解的: 編譯器產生的地址叫做虛擬地址,也叫做邏輯地址,然後經過兩級轉換,得到最終的物理地址。
在 Linux 2.6 代碼中,由於 Linux 把整個 4 GB 的地址空間當做一個「扁平」的結果來處理(段的基地址是 0x0000_0000,偏移地址的最大值是 4GB),因此虛擬地址(邏輯地址)在數值上等於線性地址。
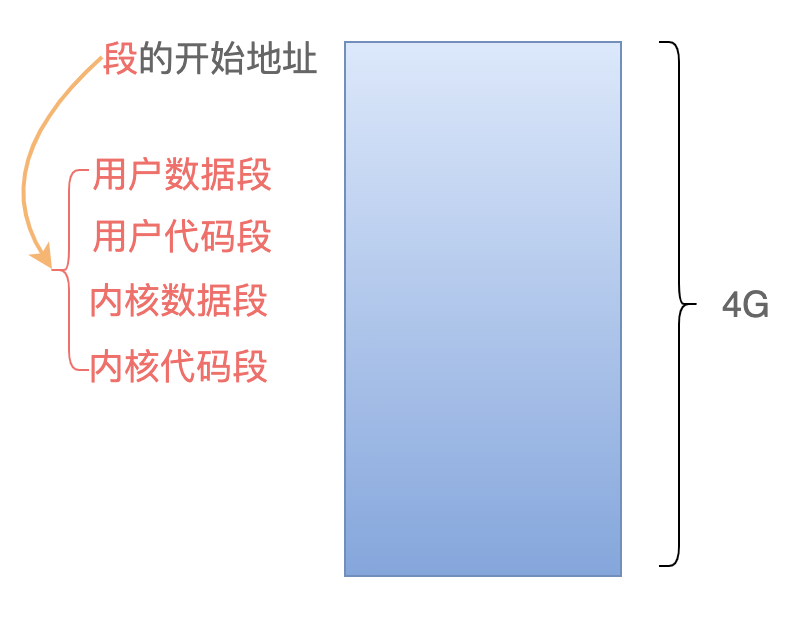
我們再結合上次給出的這張圖來理解:

這張圖的意思是:在 Linux 2.6 中,用戶代碼段的開始地址是 0,最大範圍是 4 GB;用戶數據段的開始地址是 0,最大範圍也是 4 GB;內核的數據段和代碼段也是如此。
為什麼:虛擬地址(邏輯地址)在數值上等於線性地址?
線性地址 = 段基址 + 虛擬地址(偏移量),因為段基址為 0 ,所以線性地址在數值上等於虛擬地址。
Linux 之所以要這樣安排,是因為它不想過多的利用 x86 提供的段機制來進行內存地址的管理,而是想充分利用分頁機制來進行更加靈活的地址管理。
還有一點需要提醒一下:
在上述描述的文字中,我都會標明一個機制或者策略,它是由 x86 平台提供的,還是由 Linux 操作系統提供的。
對於分頁機制也是如此,x86 硬件提供了分頁機制,但是 Linux 在 x86 提供的這個分頁機制的基礎上,進行了擴展,以達到更加靈活的內存地址管理目的。
因此,各位小夥伴在看一些書籍的時候,心中要有一個譜:當前描述內容的上下文環境是什麼。
當我們創建一個進程的時候,在內核中就會記錄這個進程所擁有的所有線性地址區間。
進程所擁有的所有線性地址區間是一個動態的過程,根據程序的需求隨時進行擴展或縮小。例如:把一個文件映射到內存,動態加載/卸載一個動態庫等等。
我們知道,內核在操作物理內存的時候,是通過「頁框」這個單位來管理的。
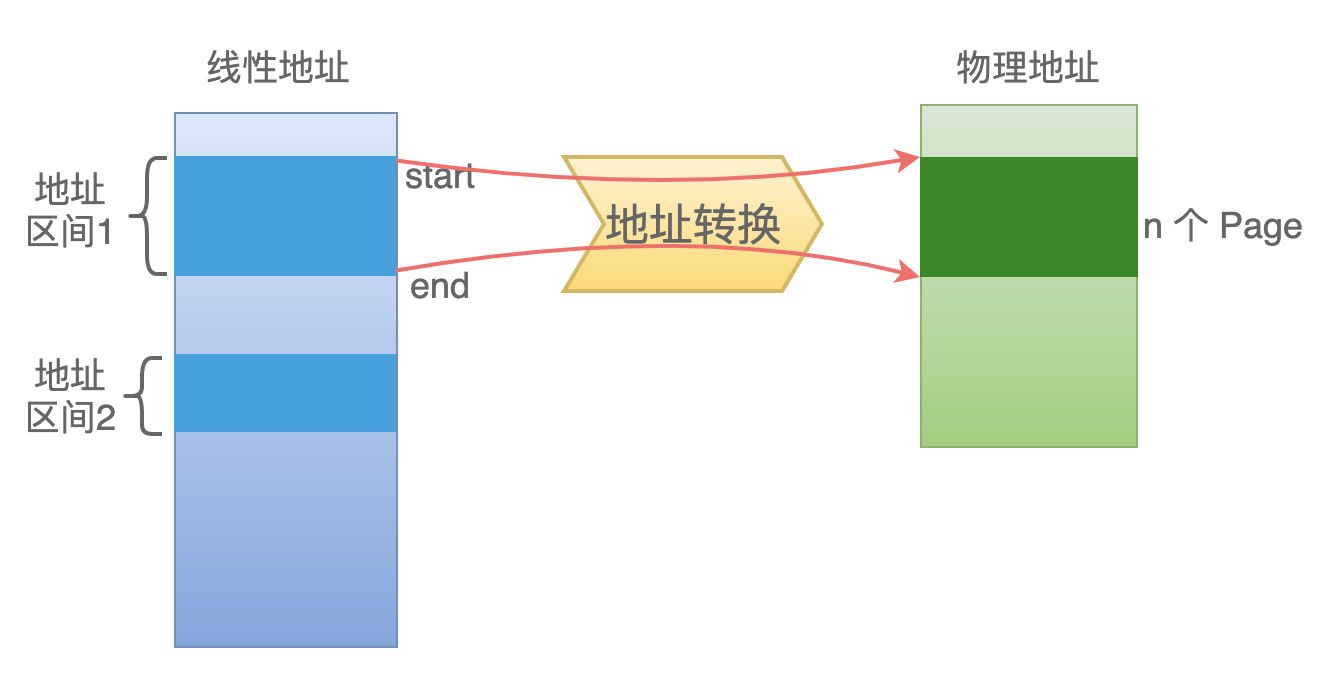
一個頁框可以包含 1-n 個頁,每一頁的大小一般是 4 KB,這是對物理內存的管理。
一個線性地址區間可以包含多個物理頁。每一個線性地址最終通過多級的頁錶轉換,來最終得到一個物理地址。
注意:上圖中,線性地址區間1,映射到物理地址空間中的 N 個 Page,這些 Page 有可能是連續的,也有可能不是連續的。
雖然在物理內存中是不連續的,但是由於被分頁轉換機制進行了屏蔽,我們在應用程序中都是按照連續的空間來使用的。
一個「完整」的 8086 彙編程序
我們再繼續回到 8086 系統中來。
這裡描述的地址,經過段地址轉換之後,就是一個物理地址,沒有經過複雜的頁錶轉換。
這也是我們以 8086 系統作為學習平台的目的:拋開複雜的操作系統,直接探索底層的東西。
在這個最簡單的彙編程序中,會使用到 3 個段:代碼段,數據段和棧段。
前面已經說到:所謂的段,就是一個地址空間。既然是一個地址空間,必然包含 2 個元素:從什麼地方開始,長度是多少。
還是直接上代碼:
assume ds:addr1, ss:addr2, cs:addr3
addr1 segment ; 把數據段安排在這個位置
db 32 dup (0) ; 這 32 個位元組,是數據段的大小
addr1 end
addr2 segment ; 把棧段安排在這個位置
db 32 dup(0) ; 這 32 個位元組,是棧段的大小
addr2 end
addr3 segment ; 把代碼段安排在這個位置
start
mov ax, addr1
mov ds, ax ; 設置數據段寄存器
mov ax, addr2
mov ss, ax ; 設置棧段寄存器
mov sp, 20h ; 設置棧頂指針寄存器
... ; 其他代碼
addr3 ends
end start
以上就是一個彙編代碼的基本程序結構,我們給它安排了 3 個段。
3 個標號:addr1、addr2 和 addr3,代表了每一個段的開始地址。在代碼段的開始部分,把數據段標號 addr1 代表的地址,賦值給 DS 寄存器;把棧段標號 addr2 代表的地址,賦值給 SS 寄存器。
這裡的標號,是不是與 C 語言中的 goto 標號很類似? 都是表示一個地址。
注意這裡賦值給棧頂指針 SP 寄存器的值是 20H。
因為棧段的使用是從高地址向低地址方向進行的,所以需要把棧頂指針設置為最大地址單元的下一個地址空間。
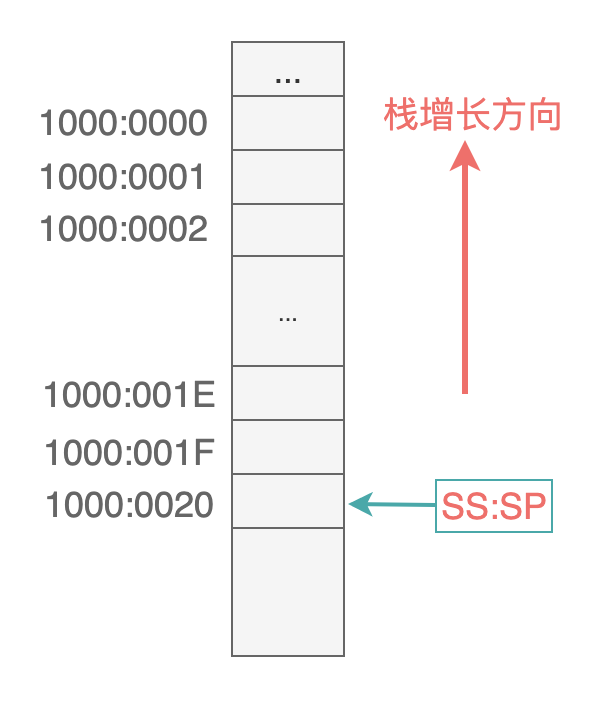
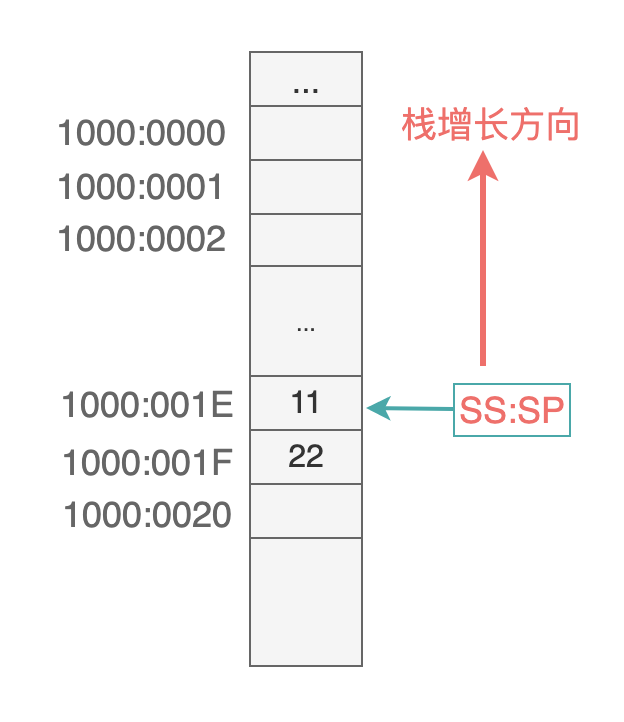
假設把第一個數據入棧時(eg: 先執行 mov ax, 1234h,再執行 push ax),CPU 要做的事情是: 先執行 SP = SP - 2,此時 SS:SP 指向 1000:001E,然後再把 1234h 存儲到這個地址空間:
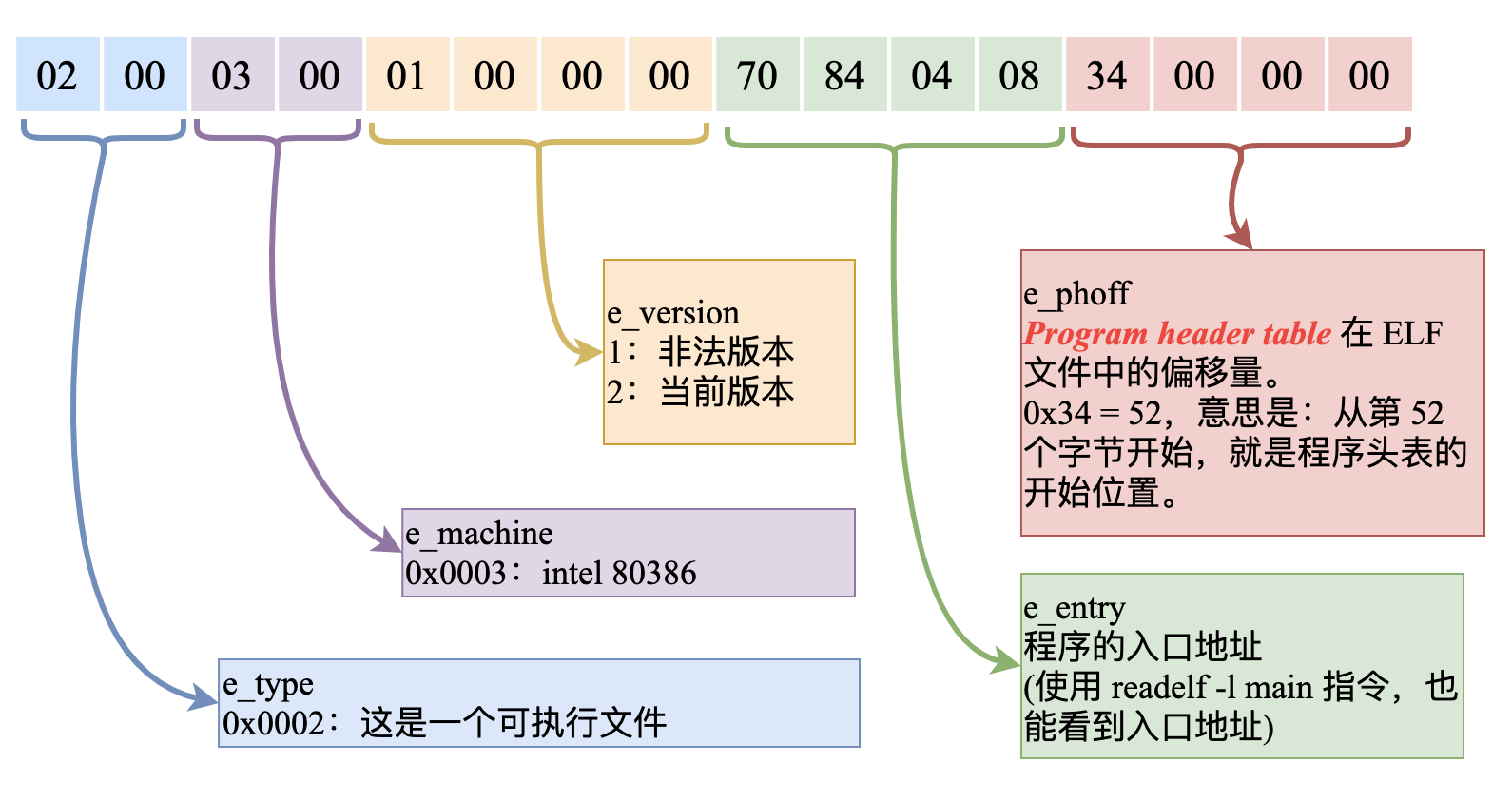
另外,代碼中最後一句 end start,用來告訴編譯器:代碼段中 start 標號代表的地址,就是這個程序的入口地址,編譯之後這個入口地址信息也會被寫入可執行程序中。
當可執行文件被加載到內存中之後,加載程序會找到這個入口地址,然後把 CS:IP 設置為指向這個入口地址,從而開始執行第一條指令。
我們再來對比一下《Linux系統中編譯、鏈接的基石-ELF文件:扒開它的層層外衣,從位元組碼的粒度來探索》中列出的 ELF 可執行文件中的入口地址,它與上面 8086 下的 start 標號代表的入口地址,在本質上都是一樣的道理:
—— End ——
推薦閱讀
【1】C語言指針-從底層原理到花式技巧,用圖文和代碼幫你講解透徹
【2】一步步分析-如何用C實現面向對象編程
【3】原來gdb的底層調試原理這麼簡單
【4】內聯彙編很可怕嗎?看完這篇文章,終結它!
其他系列專輯:精選文章、C語言、Linux操作系統、應用程序設計、物聯網

星標公眾號,能更快找到我!



