elasticsearch document的索引過程分析
- 2019 年 10 月 3 日
- 筆記
elasticsearch專欄:https://www.cnblogs.com/hello-shf/category/1550315.html
一、預備知識
1.1、索引不可變
看到這篇文章相信大家都知道es是倒排索引,不了解也沒關係,在我的另一篇博文中詳細分析了es的倒排索引機制。在es的索引過程中為了滿足一下特點,落盤的es索引是不可變的。
1 不需要鎖。如果從來不需要更新一個索引,就不必擔心多個程序同時嘗試修改。 2 一旦索引被讀入文件系統的緩存(譯者:在內存),它就一直在那兒,因為不會改變。只要文件系統緩存有足夠的空間,大部分的讀會直接訪問內存而不是磁盤。這有助於性能提升。 3 在索引的聲明周期內,所有的其他緩存都可用。它們不需要在每次數據變化了都重建,使文本可以被搜索因為數據不會變。 寫入單個大的倒排索引,可以壓縮數據,較少磁盤IO和需要緩存索引的內存大小。
當然,不可變的索引有它的缺點,首先是它不可變!你不能改變它。如果想要搜索一個新文 檔,必須重建整個索引。這不僅嚴重限制了一個索引所能裝下的數據,還有一個索引可以被更新的頻次。所以es引入了動態索引。
1.2、動態索引
下一個需要解決的問題是如何在保持不可變好處的同時更新倒排索引。答案是,使用多個索引。不是重寫整個倒排索引,而是增加額外的索引反映最近的變化。每個倒排索引都可以按順序查詢,從最老的開始,最後把結果聚合。 Elasticsearch底層依賴的Lucene,引入了 per-segment search 的概念。一個段(segment)是有完整功能的倒排索引,但是現在Lucene中的索引指的是段的集合,再加上提交點(commit point,包括所有段的文件),如圖1所示。新的文檔,在被寫入磁盤的段之前,首先寫入內存區的索引緩存。然後再通過fsync將緩存中的段刷新到磁盤上,該段將被打開即段落盤之後開始能被檢索。
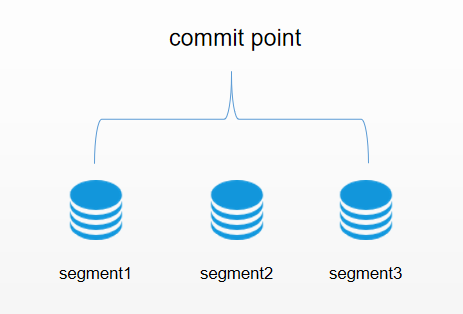
看到這裡如果對分段還是有點迷惑,沒關係,假如你熟悉java語言,ArrayList這個集合我們都知道是一個動態數組,他的底層數據結構其實就是數組,我們都知道數組是不可變的,ArrayList是動過擴容實現的動態數組。在這裡我們就可以將commit point理解成ArrayList,segment就是一個個小的數組。然後將其組合成ArrayList。假如你知道Java1.8的ConcurrentHashMap的分段鎖相信你理解這個分段就很容易了。
1.3、幾個容易混淆的概念
在es中“索引”是分片(shard)的集合,在lucene中“索引”從宏觀上來說就是es中的一個分片,從微觀上來說就是segment的集合。
“document的索引過程”這句話中的這個“索引”,我們可以理解成es為document簡歷索引的過程。
二、document索引過程
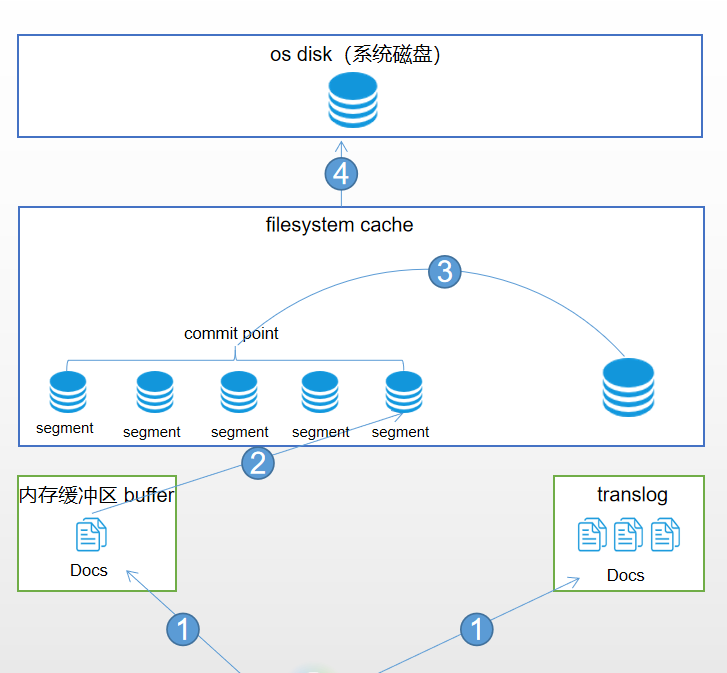
文檔被索引的過程如上面所示,大致可以分為 內存緩衝區buffer、translog、filesystem cache、系統磁盤這幾個部分,接下來我們梳理一下這個過程。
階段1:
這個階段很簡單,一個document文檔第一步會同時被寫進內存緩衝區buffer和translog。
階段2:
refresh:內存緩衝區的documents每隔一秒會被refresh(刷新)到filesystem cache中的一個新的segment中,segment就是索引的最小單位,此時segment將會被打開供檢索。也就是說一旦文檔被刷新到文件系統緩存中,其就能被檢索使用了。這也是es近實時性(NRT)的關鍵。後面會詳細介紹。
階段3:
merge:每秒都會有新的segment生成,這將意味着用不了多久segment的數量就會爆炸,每個段都將十分消耗文件句柄、內存、和cpu資源。這將是系統無法忍受的,所以這時,我們急需將零散的segment進行合併。ES通過後台合併段解決這個問題。小段被合併成大段,再合併成更大的段。然後將新的segment打開供搜索,舊的segment刪除。
階段4:
flush:經過階段3合併後新生成的更大的segment將會被flush到系統磁盤上。這樣整個過程就完成了。但是這裡留一個包袱就是flush的時機。在後面介紹translog的時候會介紹。
不要着急,接下來我們將以上步驟拆分開來詳細分析一下。
2.1、近實時化搜索(NRT)
在早起的lucene中,只有當segement被寫入到磁盤,該segment才會被打開供搜索,和我們上面所說的當doc被刷新到filesystem cache中生成新的segment就將會被打開。
因為 per-segment search 機制,索引和搜索一個文檔之間是有延遲的。新的文檔會在幾分鐘內可以搜索,但是這依然不夠快。磁盤是瓶頸。提交一個新的段到磁盤需要 fsync 操作,確保段被物理地寫入磁盤,即時電源失效也不會丟失數據。但是 fsync 是昂貴的,它不能在每個文檔被索引的時就觸發。
所以需要一種更輕量級的方式使新的文檔可以被搜索,這意味這移除 fsync 。
位於Elasticsearch和磁盤間的是文件系統緩存。如前所說,在內存索引緩存中的文檔被寫入新的段,但是新的段首先寫入文件系統緩存,這代價很低,之後會被同步到磁盤,這個代價很大。但是一旦一個文件被緩存,它也可以被打開和讀取,就像其他文件一樣。
在es中每隔一秒寫入內存緩衝區的文檔就會被刷新到filesystem cache中的新的segment,也就意味着可以被搜索了。這就是ES的NRT——近實時性搜索。
簡單介紹一下refresh API
如果你遇到過你新增了doc,但是沒檢索到,很可能是因為還未自動進行refresh,這是你可以嘗試手動刷新
POST /student/_refresh
性能優化
在這裡我們需要知道一點refresh過程是很消耗性能的。如果你的系統對實時性要求不高,可以通過API控制refresh的時間間隔,但是如果你的新系統很要求實時性,那你就忍受它吧。
如果你對系統的實時性要求很低,我們可以調整refresh的時間間隔,調大一點將會在一定程度上提升系統的性能。
PUT /student { "settings": { "refresh_interval": "30s" } }
2.2、合併段——merge
通過每秒自動刷新創建新的段,用不了多久段的數量就爆炸了。有太多的段是一個問題。每個段消費文件句柄,內存,cpu資源。更重要的是,每次搜索請求都需要依次檢查每個段。段越多,查詢越慢。
ES通過後台合併段解決這個問題。小段被合併成大段,再合併成更大的段。
這是舊的文檔從文件系統刪除的時候。舊的段不會再複製到更大的新段中。 這個過程你不必做什麼。當你在索引和搜索時ES會自動處理。
我們再來總結一下段合併的過程。
1 選擇一些有相似大小的segment,merge成一個大的segment 2 將新的segment flush到磁盤上去 3 寫一個新的commit point,包括了新的segment,並且排除舊的那些segment 4 將新的segment打開供搜索 5 將舊的segment刪除
optimize API 最好描述為強制合併段API。它強制分片合併段以達到指定 max_num_segments 參數。這是為了減少段的數量(通常為1)達到提高搜索性能的目的。
POST /logstash-2019-10-01/_optimize?max_num_segments=1
一般場景下盡量不要手動執行,讓它自動默認執行就可以了
2.3、容災與可靠存儲
沒用 fsync 同步文件系統緩存到磁盤,我們不能確保電源失效,甚至正常退出應用後,數據的安全。為了ES的可靠性,需要確保變更持久化到磁盤。
我們說過一次全提交同步段到磁盤,寫提交點,這會列出所有的已知的段。在重啟,或重新 打開索引時,ES使用這次提交點決定哪些段屬於當前的分片。
當我們通過每秒的刷新獲得近實時的搜索,我們依然需要定時地執行全提交確保能從失敗中 恢復。但是提交之間的文檔怎麼辦?我們也不想丟失它們。
上面doc索引流程的階段1,doc分別被寫入到內存緩衝區和translog,然後每秒都將會把內存緩衝區的docs刷新到filesystem cache中的新segment,然後眾多segment會進行不斷的壓縮,小段被合併成大段,再合併成更大的段。每次refresh操作後,內存緩衝區的docs被刷新到filesystem cache中的segemnt中,但是tanslog仍然在持續的增大增多。當translog大到一定程度,將會發生一個commit操作也就是全量提交。
詳細過程如下:
1、 doc寫入內存緩衝區和translog日誌文件 2、 每隔一秒鐘,內存緩衝區中的docs被寫入到filesystem cache中新的segment,此時segment被打開並供檢索使用 3、 內存緩衝區被清空 4、 重複1~3,新的segment不斷添加,內存緩衝區不斷被清空,而translog中的數據不斷累加 5、 當translog長度達到一定程度的時候,commit操作發生 5-1、 內存緩衝區中的docs被寫入到filesystem cache中新的segment,打開供檢索使用 5-2、 內存緩衝區被清空 5-3、 一個commit ponit被寫入磁盤,標明了所有的index segment 5-4、 filesystem cache中的所有index segment file緩存數據,被fsync強行刷到磁盤上 5-5、 現有的translog被清空,創建一個新的translog
其實到這裡我們發現fsync還是沒有被捨棄的,但是我們通過動態索引和translog技術減少了其使用頻率,並實現了近實時搜索。其次通過以上步驟我們發現flush操作包括filesystem cache中的segment通過fsync刷新到硬盤以及translog的清空兩個過程。es默認每30分鐘進行一次flush操作,但是當translog大到一定程度時也會進行flush操作。
對應過程圖如下
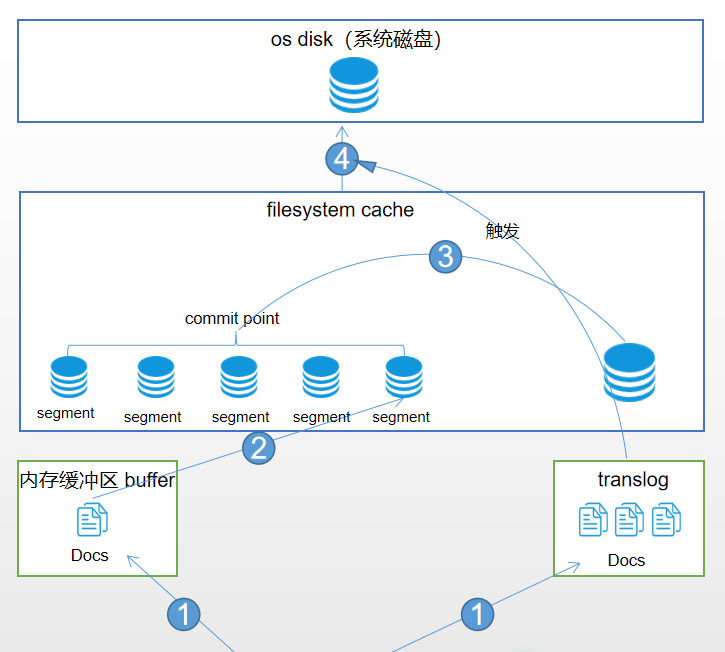
5-5步驟不難發現只有內存緩衝區中的docs全部刷新到filesystem cache中並fsync到硬盤,translog才會被清除,這樣就保證了數據不會丟失,因為只要translog存在,我們就能根據translog進行數據的恢復。
簡單介紹一下flush API
手動flush如下所示,但是並不建議使用。但是當要重啟或關閉一個索引,flush該索引是很有用的。當ES嘗試恢復或者重新打開一個索引時,它必須重放所有事務日誌中的操作,所以日誌越小,恢復速度越快。
POST /student/_flush
三、更新和刪除
前面我們說過es的索引是不可變的,那麼更新和刪除是如何進行的呢?
參考文獻:
《elasticsearch-權威指南》
如有錯誤的地方還請留言指正。
原創不易,轉載請註明原文地址:https://www.cnblogs.com/hello-shf/p/11553317.html
