Java的內存模型
寫在前面:
該系列文章,主要是為了深入學習Java完成的一條鏈,推薦閱讀的整體順序為:Java的內存模型(根源),一個java文件被執行的歷程,一個Java類的加載及JVM內存的分配,Java的垃圾回收機制及內存的劃分,Linux(六):系統運維常用命令(基本問題定位),Jvm內置命令的使用
其實本篇的題目叫做《Java的內存模型》有些不準確,更準確的說法應該是JVM的內存模型,但是這裡又牽扯了一些其他的前置知識,主要是想從Java入手,從源頭上梳理一遍整個Java底層運行的機制,中間會額外補充一些和題目無關的前置基礎,導致主講內存模型的篇幅所佔的比例就不是那麼絕對, 關於這點只能請小夥伴們多擔待些了。
JVM的內存模型
前戲 1:Java 「一次運行,到處編譯」 的真面目
說JVM內存模型之前,先聊一個老生常談的問題,為什麼Java可以 「一次編譯,到處運行」,這個話題最直接的答案就是,因為Java有JVM啊,解釋這個答案之前,我想先回顧一下一個語言被編譯的過程:
一般編程語言的編譯過程大抵就是,編譯——連接——執行,這裡的編譯就是,把我們寫的源代碼,根據語義語法進行翻譯,形成目標代碼,即彙編碼。再由彙編程序翻譯成機器語言(可以理解為直接運行於硬件上的01語言);然後進行連接,所謂連接就是將目標代碼與函數庫相連接,並將源程序所用的庫代碼與目標代碼合併,並形成最終可執行的二進制機器代碼(程序)。
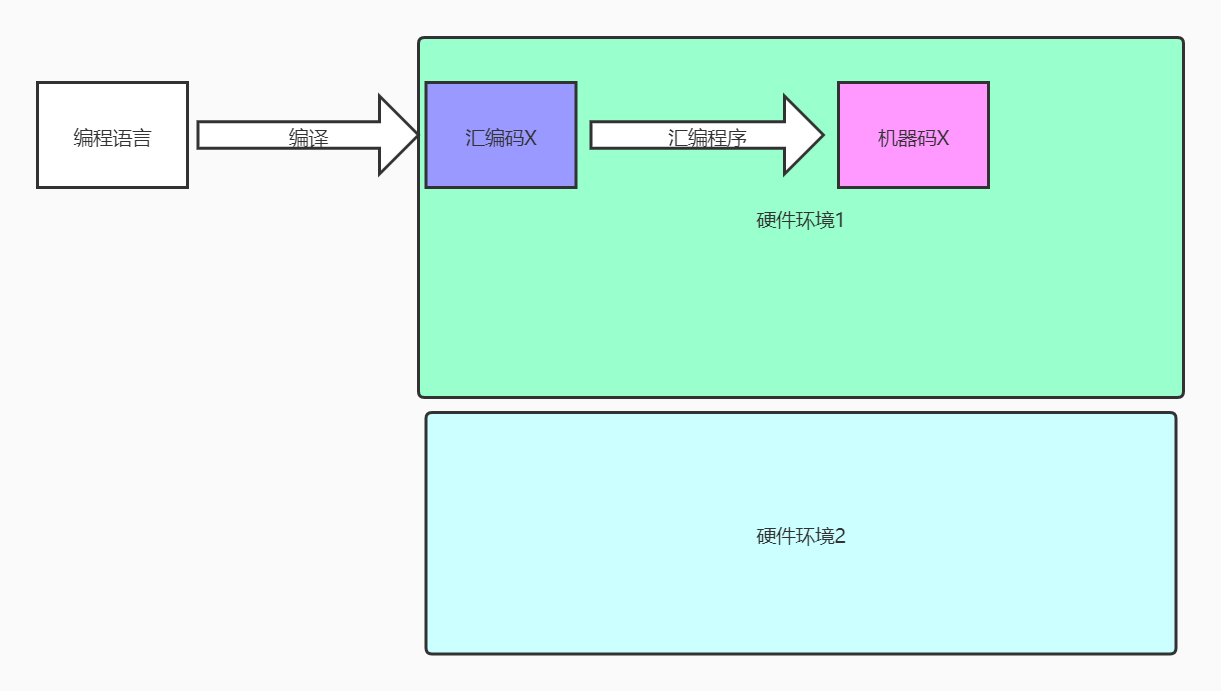
編譯運行的整個流程,有一個前提,那就是到彙編的層面,指令編碼就和處理器的架構強關聯了,說白點就是和硬件關聯了,可以粗暴的理解為,一類硬件機器只認識一種彙編,一種機器只認一種機器碼。在這個基礎下,很容易就會發現一個問題,一個編程語言經過編譯、連接形成的可運行的機器碼X,可以在硬件環境1的情況下運行,當機器碼X到硬件環境2,就未必可以運行了,或者說運行結果就不是硬件環境1的結果了,所以,同一個程序,換台PC,我們就可能需要重新編譯、打包成可運行在當前硬件環境的程序。這樣在工程化運用中真的是災難。
現在我們回到開篇問題的答案,之所以Java可以「一次編譯,到處運行」,是因為有JVM,為了便於理解,我們可以這樣認為:JVM就是一個完備的中間環境,它提供編譯運行Java位元組碼的全套環境,換句話說,它就像一個小隔離空間,我的Java程序只要編譯一次,只要滿足可以跑在JVM中,那它就可以隨便移植在任何硬件環境中,所以Java的「一次編譯,到處運行」的本質就是,它處處都要依賴JVM,它其實就是一個運行在JVM中的寄生蟲,這也是為什麼想要運行環境,你就必須要裝JDK的原因。
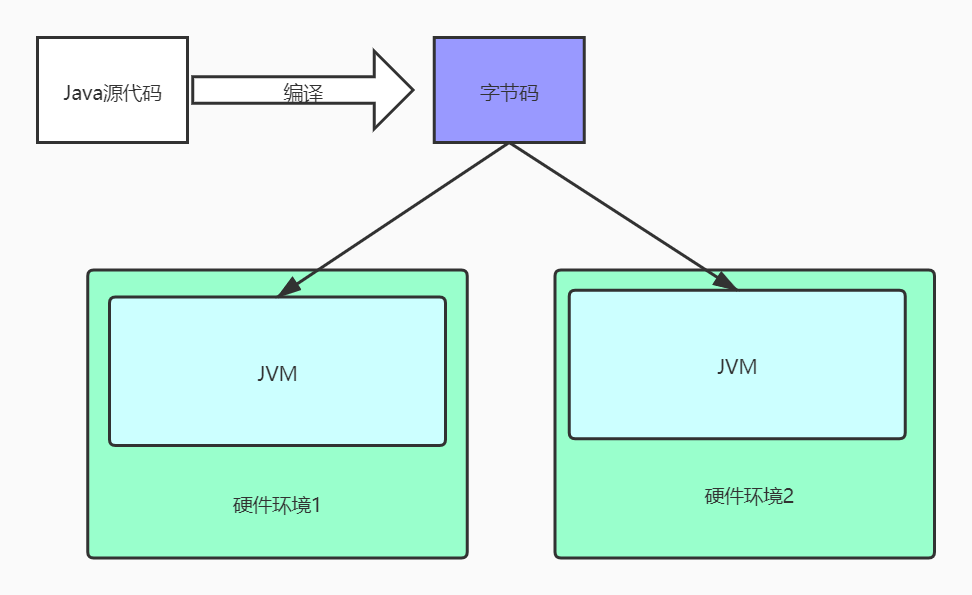
前戲二:JVM的本質和位置
上面的理解只不過是為了更快的入戲,但是上面的理解過於粗暴,下面細膩一下JVM的性質以及它所處的位置:
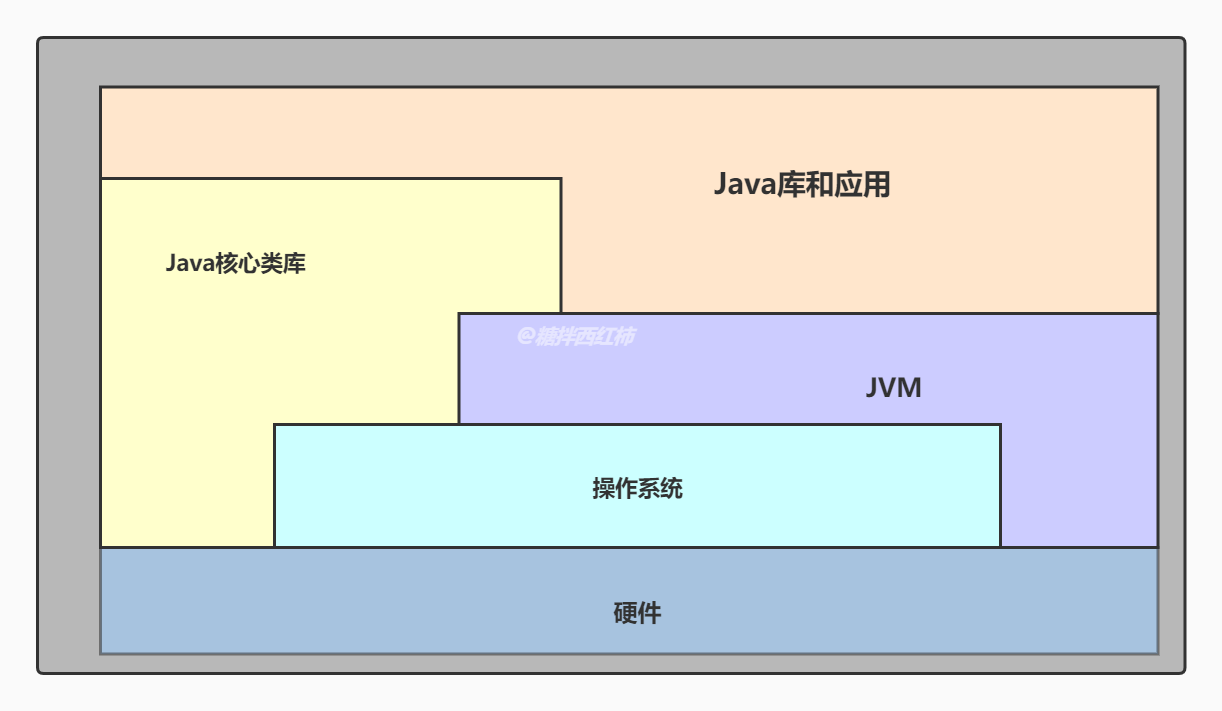
通常工作中所接觸的基本是Java庫和應用以及Java核心類庫,知道如何使用就可以了,但是歸根結底代碼都是要編譯成class文件由Java虛擬機裝載執行,所產生的結果或者現象都可以通過Java虛擬機的運行機制來解釋。一些相同的代碼會由於虛擬機的實現不同而產生不同結果。
然後是我們要介紹的JVM,首先我們要明確一個概念,JVM它並不是某一個具體的產品,也不是一個成品的軟件,更準確地說JVM是一種理論規範,對JVM的具體實現要麼是軟件,要麼是軟件和硬件的組合,JVM可以由不同的廠商來實現成不同的產品。由於廠商的不同必然導致JVM在實現上的一些不同,像國內就有著名的TaobaoVM;
在Java平台的結構中,可以看出,Java虛擬機(JVM)處在核心的位置,是程序與底層操作系統和硬件無關的關鍵。它的下方是移植接口,移植接口由兩部分組成:適配器和Java操作系統,其中依賴於平台的部分稱為適配器;JVM通過移植接口在具體的平台和操作系統上實現;在JVM的上方是Java的基本類庫和擴展類庫以及它們的API, 利用Java API編寫的應用程序(application)和小程序(Java applet)可以在任何Java平台上運行而無需考慮底層平台,就是因為有Java虛擬機(JVM)實現了程序與操作系統的分離,從而實現了Java的平台無關性。
JVM在它的生存周期中有一個明確的任務,那就是裝載位元組碼文件,一旦位元組碼進入虛擬機,它就會被解釋器解釋執行,或者是被即時代碼發生器有選擇的轉換成機器碼執行,即Java程序被執行。因此當Java程序啟動的時候,就產生JVM的一個實例;當程序運行結束的時候,該實例也跟着消失了。
JVM的內存模型總覽
「博主你前戲真多,你是不是不行鴨……」
「啊…這…前戲多了,才能更好享受……」
額…前面的前戲確實有些多了,但是主要是為了更好的接洽後面的內容,不然直接上五大內存部分,說什麼線程私有、公有,個人感覺很突兀。
好了,不廢話了,下面開始上主菜
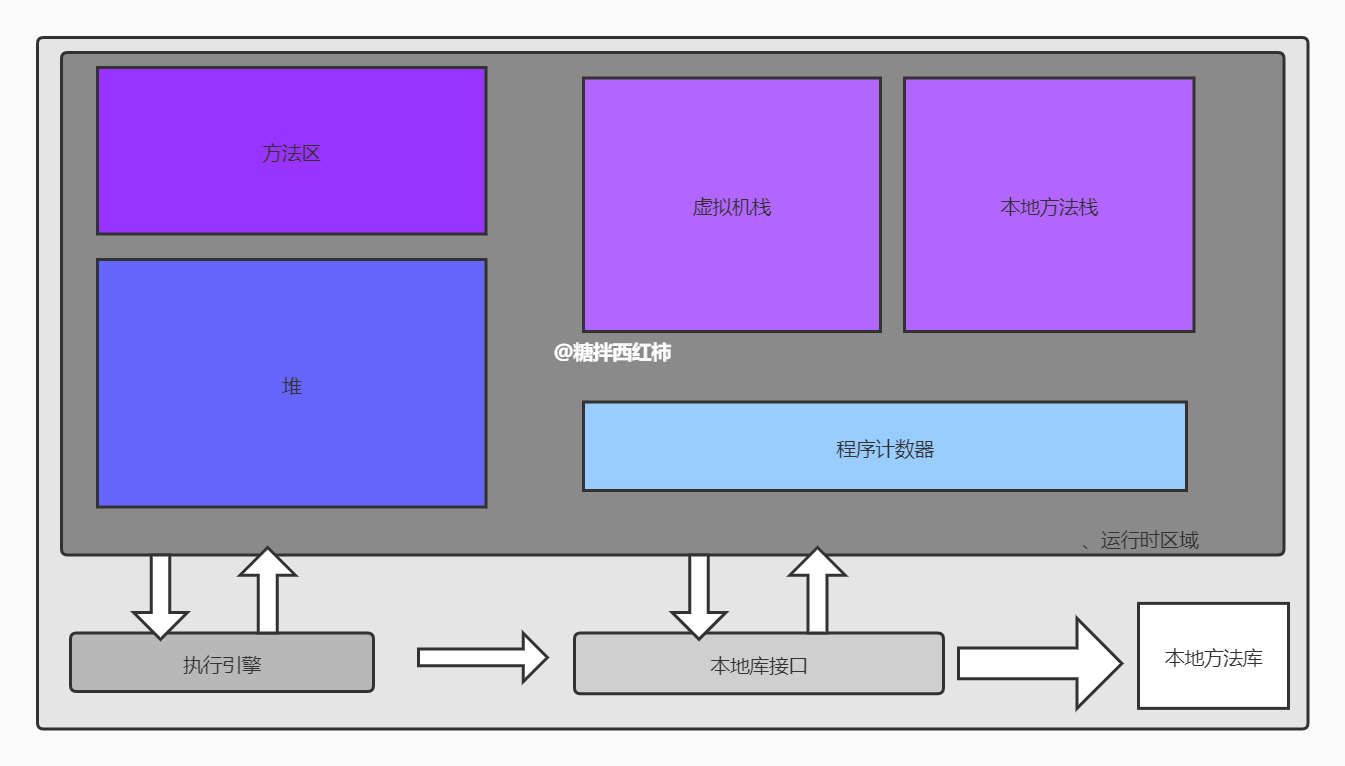
總體來講,JVM會將Java進程所管理的內存劃分為若干不同的數據區域. 這些區域有各自的用途、創建/銷毀時間。以上這張圖,就是Java的編譯運行過程,上半部分(運行時區域)其實就是JVM的內存分配,它把從操作系統獲取來的內存空間進行了獨立的劃分,分別為方法區、堆、虛擬機棧、本地方法棧、程序計數器。下半部分就是連接——運行階段的,JVM將Java語言處理完畢,變成適配與當前機器的機器碼,然後與本地庫進行連接,運行。
線程私有區域
線程私有數據區域生命周期與線程相同, 依賴用戶線程的啟動/結束而創建/銷毀(在Hotspot VM內, 每個線程都與操作系統的本地線程直接映射, 因此這部分內存區域的存/否跟隨本地線程的生/死)。
程序計數器
一塊較小的內存空間, 作用是當前線程所執行位元組碼的行號指示器(類似於傳統CPU模型中的PC), PC在每次指令執行後自增, 維護下一個將要執行指令的地址. 在JVM模型中, 位元組碼解釋器就是通過改變PC值來選取下一條需要執行的位元組碼指令,分支、循環、跳轉、異常處理、線程恢復等基礎功能都需要依賴PC完成(僅限於Java方法, Native方法該計數器值為undefined).
不同於OS以進程為單位調度, JVM中的並發是通過線程切換並分配時間片執行來實現的. 在任何一個時刻, 一個處理器內核只會執行一條線程中的指令. 因此, 為了線程切換後能恢復到正確的執行位置, 每條線程都需要有一個獨立的程序計數器, 這類內存被稱為「線程私有」內存。
JAVA代碼編譯後的位元組碼在未經過JIT(實時編譯器)編譯前,其執行方式是通過「位元組碼解釋器」進行解釋執行。簡單的工作原理為解釋器讀取裝載入內存的位元組碼,按照順序讀取位元組碼指令。讀取一個指令後,將該指令「翻譯」成固定的操作,並根據這些操作進行分支、循環、跳轉等流程。
從上面的描述中,可能會產生程序計數器是否是多餘的疑問。因為沿着指令的順序執行下去,即使是分支跳轉這樣的流程,跳轉到指定的指令處按順序繼續執行是完全能夠保證程序的執行順序的。假設程序永遠只有一個線程,這個疑問沒有任何問題,也就是說並不需要程序計數器。但實際上程序是通過多個線程協同合作執行的。
首先我們要搞清楚JVM的多線程實現方式。JVM的多線程是通過CPU時間片輪轉(即線程輪流切換並分配處理器執行時間)算法來實現的。也就是說,某個線程在執行過程中可能會因為時間片耗盡而被掛起,而另一個線程獲取到時間片開始執行。當被掛起的線程重新獲取到時間片的時候,它要想從被掛起的地方繼續執行,就必須知道它上次執行到哪個位置,在JVM中,通過程序計數器來記錄某個線程的位元組碼執行位置。因此,程序計數器是具備線程隔離的特性,也就是說,每個線程工作時都有屬於自己的獨立計數器。
程序計數器的特點
1.線程隔離性,每個線程工作時都有屬於自己的獨立計數器。
2.執行java方法時,程序計數器是有值的,且記錄的是正在執行的位元組碼指令的地址(參考上一小節的描述)。
3.執行native本地方法時,程序計數器的值為空(Undefined)。因為native方法是java通過JNI直接調用本地C/C++庫,可以近似的認為native方法相當於C/C++暴露給java的一個接口,java通過調用這個接口從而調用到C/C++方法。由於該方法是通過C/C++而不是java進行實現。那麼自然無法產生相應的位元組碼,並且C/C++執行時的內存分配是由自己語言決定的,而不是由JVM決定的。 4.程序計數器佔用內存很小,在進行JVM內存計算時,可以忽略不計。
5.程序計數器,是唯一一個在java虛擬機規範中沒有規定任何OutOfMemoryError的區域。
虛擬機棧
這裡的虛擬機棧主要是針對Java的方法執行,我們都知道方法在編程中使用的是棧的數據結構;每個方法被執行時會創建一個棧幀(Stack Frame)用於存儲局部變量表、操作數棧、動態鏈接、方法出口等信息. 每個方法被調用至返回的過程, 就對應着一個棧幀在虛擬機棧中從入棧到出棧的過程(VM提供了-Xss來指定線程的最大棧空間, 該參數也直接決定了函數調用的最大深度)。這裡特別說明一下局部變量表,這裡的局部變量表,其實就是我們定義的方法內部的變量,它基本的範圍包括基本數據類型(如boolean、int、double等) 、對象引用(reference : 不等同於對象本身, 可能是一個指向對象起始地址的指針, 也可能指向一個代表對象的句柄或其他與此對象相關的位置),也就是我們私下常說的『堆棧』中的『棧』。
Java虛擬機使用局部變量表來完成方法調用時的參數傳遞。局部變量表的長度在編譯期已經決定了並存儲於類和接口的二進制表示中,一個局部變量可以保存一個類型為boolean、byte、char、short、float、reference和returnAddress的數據,兩個局部變量可以保存一個類型為long和double的數據。
Java虛擬機提供一些位元組碼指令來從局部變量表或者對象實例的字段中複製常量或變量值到操作數棧中,也提供了一些指令用於從操作數棧取走數據、操作數據和把操作結果重新入棧。在方法調用的時候,操作數棧也用來準備調用方法的參數以及接收方法返回結果。
每個棧幀中都包含一個指向運行時常量區的引用支持當前方法的動態鏈接。在Class文件中,方法調用和訪問成員變量都是通過符號引用來表示的,動態鏈接的作用就是將符號引用轉化為實際方法的直接引用或者訪問變量的運行是內存位置的正確偏移量。
總的來說,Java虛擬機棧是用來存放局部變量和過程結果的地方。
Java虛擬機棧可能發生如下異常情況: 如果Java虛擬機棧被實現為固定大小內存,線程請求分配的棧容量超過Java虛擬機棧允許的最大容量時,Java虛擬機將會拋出一個StackOverflowError異常。
如果Java虛擬機棧被實現為動態擴展內存大小,並且擴展的動作已經嘗試過,但是目前無法申請到足夠的內存去完成擴展,或者在建立新的線程時沒有足夠的內存去創建對應的虛擬機棧,那Java虛擬機將會拋出一個OutOfMemoryError異常。1.符號引用(Symbolic References):
符號引用以一組符號來描述所引用的目標,符號可以是任何形式的字面量,只要使用時能夠無歧義的定位到目標即可。例如,在Class文件中它以CONSTANT_Class_info、CONSTANT_Fieldref_info、CONSTANT_Methodref_info等類型的常量出現。符號引用與虛擬機的內存布局無關,引用的目標並不一定加載到內存中。在Java中,一個java類將會編譯成一個class文件。在編譯時,java類並不知道所引用的類的實際地址,因此只能使用符號引用來代替。比如org.simple.People類引用了org.simple.Language類,在編譯時People類並不知道Language類的實際內存地址,因此只能使用符號org.simple.Language(假設是這個,當然實際中是由類似於CONSTANT_Class_info的常量來表示的)來表示Language類的地址。各種虛擬機實現的內存布局可能有所不同,但是它們能接受的符號引用都是一致的,因為符號引用的字面量形式明確定義在Java虛擬機規範的Class文件格式中。
2.直接引用:
直接引用可以是
(1)直接指向目標的指針(比如,指向「類型」【Class對象】、類變量、類方法的直接引用可能是指向方法區的指針)
(2)相對偏移量(比如,指向實例變量、實例方法的直接引用都是偏移量)
(3)一個能間接定位到目標的句柄
直接引用是和虛擬機的布局相關的,同一個符號引用在不同的虛擬機實例上翻譯出來的直接引用一般不會相同。如果有了直接引用,那引用的目標必定已經被加載入內存中了。
本地方法棧
本地方法棧其實作用和虛擬機棧的作用一樣,不同的是,虛擬機棧是為虛擬機解析運行Java方法,而本地方法棧是為虛擬機調用Native方法服務(Native方法簡單點來說就是一個java調用非java代碼的接口。一個Native 方法是這樣一個java的方法:該方法的實現由非java語言實現)
線程共享區域
這一區域的生命周期,同虛擬機一致,也就是虛擬機內部的公共內存區域,隨虛擬機的啟動/關閉而創建/銷毀

堆區
這裡的堆,是虛擬機從操作系統那裡申請來的的內存空間,這塊空間是Java虛擬機所管理的內存中最大的一塊,並且是所有線程共享的一塊內存區域,Java堆在虛擬機啟動的時候被創建,主要用來為類實例對象和數組分配內存。這塊區域可以處於物理上不連續的內存空間中,只要邏輯上是連續的即可,就像我們的磁盤空間一樣,在實現時,既可以實現成固定大小的,也可以是擴展的,如果是可擴展的,則通過(-Xmx和-Xms控制),如果在隊中沒有內存完成實例分配,並且堆也無法再擴展時,將會拋出OutOfMemoryError異常。
Java堆是垃圾回收器管理的主要區域,很多時候也被稱為「GC」堆,在現在的實現上,堆被劃分成兩個不同的區域:新生代( Young )、老年代( Old );這也就是JVM採用的「分代收集算法」,簡單說,就是針對不同特徵的java對象採用不同的 策略實施存放和回收,自然所用分配機制和回收算法就不一樣。新生代( Young ) 又被劃分為三個區域:Eden、From Survivor、To Survivor。
方法區
方法區和Java堆一樣,是各個線程共享的內存區域,用於存儲已被虛擬機加載的類信息,常量、靜態變量,還包括在類、實例、接口初始化時用到的特殊方法。虛擬機規範上把方法區描述為堆的一個邏輯部分,但是它卻有一個別名叫做「非堆」,目的就是與Java的堆區分開來。
直接內存
直接內存並不是JVM運行時數據區的一部分, 但也會被頻繁的使用: 在JDK 1.4引入的NIO提供了基於Channel與Buffer的IO方式, 它可以使用Native函數庫直接分配堆外內存, 然後使用DirectByteBuffer對象作為這塊內存的引用進行操作(詳見: Java I/O 擴展), 這樣就避免了在Java堆和Native堆中來回複製數據, 因此在一些場景中可以顯著提高性能。
顯然, 本機直接內存的分配不會受到Java堆大小的限制(即不會遵守-Xms、-Xmx等設置), 但既然是內存, 則肯定還是會受到本機總內存大小及處理器尋址空間的限制, 因此動態擴展時也會出現OutOfMemoryError異常。
從栗子來理解內存模型
這裡我們引入一個比較簡單的程序樣例,從具體的代碼角度去理解Jvm的內存
一個person類
public class Persion { private String name; public static String aninmal = "dog" public Persion(String name){ this.name = name } public String getName() { return name; } public void setName(String name) { this.name = name; } }
一個App類
public class App { public static void main( String[] args ) { Persion persion1 = new Persion("張三"); Persion persion2 = new Persion("李四"); persoion1.setName("王五"); } }
程序開始運行,系統啟動了一個Java虛擬機進程,Java虛擬機定位到方法區中App類的main()方法的位元組碼,開始執行它的指令。分別去創建Persion1和Persion2(這裡我們以persion對象為跟蹤點)

1、程序從main方法開始執行,既然提到了方法,根據上面的知識,我們知道,它首先會在棧區動工。在JAVA虛擬機進程中,每個線程都會擁有一個方法調用棧,用來跟蹤線程運行中一系列的方法調用過程,棧中的每一個元素就被稱為棧幀,每當線程調用一個方法的時候就會向方法棧壓入一個新幀。這裡的幀用來存儲方法的參數、局部變量和運算過程中的臨時數據。這時候執行main方法的主線程會在棧區申請一片區域。根據源碼,它會識別出persion1和persion2分別為兩個變量,並且給它們定性是方法內局部變量,因此,它被會添加到了執行main()方法的主線程的JAVA方法調用棧中。
2、 接下來就是 「=」 賦值操作了,Java虛擬機接受運行指令,發現右側是個對象實例,於是就直奔方法區而去,試圖找到Persion類的類型信息。首次運行,發現並沒有找到Persion的信息,這時候Java虛擬機根據預設的規則,在無法找到類信息的情況下,自行去加載Persion類,把Persion類的類型信息存放在方法區里。
3、 現在Persion類的信息已經被加載到了方法區,這裡Persion類中的靜態變量animal也會被填充上值「dog」存放於方法區,此時Java虛擬機根據我們代碼中的兩句new指令,分別去堆中划出兩塊內存區域,分別用於存放persion實例1和persion實例2,這兩個實例對象分別擁有自己獨立的內存空間, 同時這倆實例持有着指向方法區的Persion類的類型信息的引用。這裡所說的引用,實際上指的是Persion類的類型信息在方法區中的內存地址,其實,就是有點類似於C語言里的指針,而這個地址呢,就存放了在persion實例1、persopn實例2的數據區里。我們也能發現persion實例1和persion實例2共享animal這個變量,也就是說,無論使用哪一個引用(persion1和persion2)去修改這個animal變量,任何一個Persion對象使用這個變量的時候,都會發生改變。
4、到此為止已經將main方法中的兩個成員變量persion1和persion2分別關聯到了堆中的對象。當Java虛擬機執行到persion1.setName()的時候,Java虛擬機根據main方法棧區中的persion1變量,定位到堆中的Persion名字為張三的實例(persion實例1),再根據這個實例所持有的類信息引用(或者說指針),定位到方法區的Persion類信息,從中獲得setName(String name)方法,然後棧區再壓入一個新幀,並在其中完成參數(String name)的複製,然後根據指令,將堆中的Persion實例1 空間中的Name變成「王五」,然後結束。

