集群通信:從心跳說起
本文首發 Nebula Graph 官網://nebula-graph.com.cn/posts/cluster-communication-heartbeat/
在用戶使用 Nebula Graph 的過程中,經常會遇到各種問題,通常我們都會建議先通過 show hosts 查看集群狀態。可以說,整個 Nebula Graph 的集群狀態都是靠心跳機制來構建的。本文將從心跳說起,幫助你了解 Nebula Graph 集群各個節點之間通信的機制。
什麼是心跳?有什麼作用?

Nebula Graph 集群一般包含三種節點,graphd 作為查詢節點,storaged 作為存儲節點,metad 作為元信息節點。本文說的心跳,主要是指 graphd 和 storaged 定期向 metad 上報信息的這個心跳,藉助心跳,整個集群完成了以下功能。(相關參數是 heartbeat_interval_secs)
在 Nebula Graph 中經常提及的 raft 心跳則是用於擁有同一個 partition 的多個 storaged 之間的心跳,和本文提的心跳並不相同。
1. 服務發現
當我們啟動一個 Nebula Graph 集群時,需要在對應的配置文件中填寫 meta_server_addrs。graphd 和 storaged 在啟動之後,就會通過這個 meta_server_addrs 地址,向對應的 metad 發送心跳。通常來說,graphd 和 storaged 在連接上 metad 前是無法對外進行服務的。當 metad 收到心跳後,會保存相關信息(見下文第 2 點),此時就能夠通過 show hosts 看到對應的 storaged 節點,在 2.x 版本中,也能夠通過 show hosts graph 看到 graphd 節點。
2. 上報節點信息
在 metad 收到心跳時,會將心跳中的 ip、port、節點類型、心跳時間等等信息保存,以供後續使用(見下文)。
除此以外 storaged 在自身 leader 數量變化的時候也會上報 leader 信息,在 show hosts 中看到的 Leader count 和 Leader distribution 就是通過心跳彙報的。
3. 更新元信息
當客戶通過 console 或者各種客戶端,對集群的元信息進行更改之後(例如 create/drop space、create/alter/drop tag/edge、update configs 等等),通常在幾秒之內,整個集群就都會更新元數據。
每次 graphd 和 storaged 在心跳的響應中會包含一個 last_update_time,這個時間是由 metad 返回給各個節點的,用於告知 metad 自身最後一次更新元信息的時間。當 graphd 或者 storaged 發現 metad 的元信息有更新,就會向 metad 獲取相應信息(例如 space 信息、schema 信息、配置更改等等)。
我們以創建一個 tag 為例,如果在 graphd/storaged 獲取到新創建的這個 tag 信息之前,我們無法插入這個 tag 數據(會報類似 No schema found 這樣的錯誤)。而當通過心跳獲取到對應信息並保存至本地緩存後,就能夠正常寫入數據了。
心跳上報的信息有什麼用?
how hosts、show parts這類命令都是通過 metad 中保存的各個節點心跳信息,組合顯示出來的。balance data、balance leader等運維命令,需要通過獲取當前集群內哪些 storaged 節點是在線狀態,實際也是通過 metad 判斷最近一次心跳時間是否在閾值之內。create space,當用戶創建一個 space 時,metad 也需要獲取 storaged 的狀態,將這個 space 的各個 partition 分配到在線的 storaged 中。
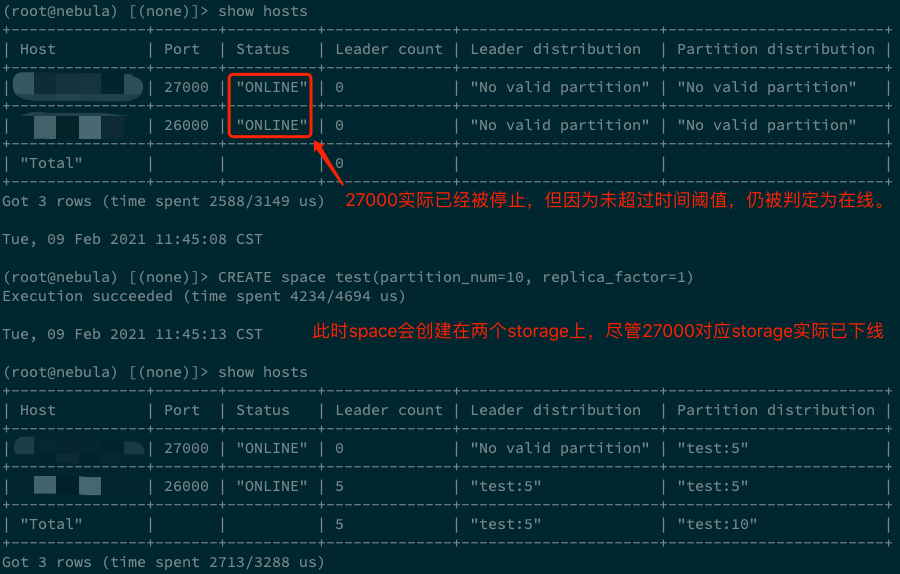
以用戶容易遇到的問題為例:假如我們啟動一個 storaged 後,關掉並修改端口號,然後再啟動 storaged。如果這個過程足夠快,那麼通過
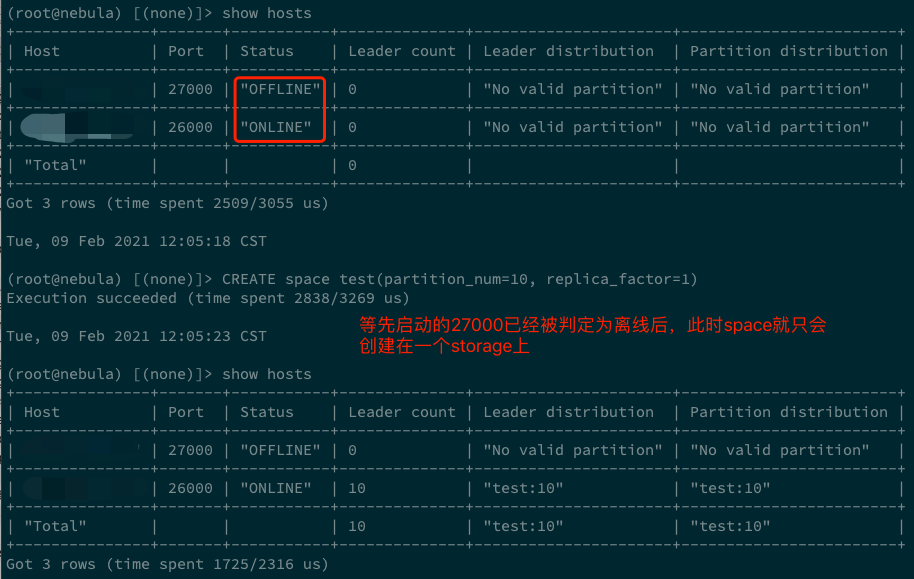
show hosts能看到兩個在線的 storaged。此時,如果新建一個 space,例如CREATE space test(partition_num=10, replica_factor=1),這個 test space 就會分佈在前後啟動的兩個 storage 上。但如果等到在 show hosts 中看到其中一個離線後,再執行CREATE space test(partition_num=10, replica_factor=1),即便離線的 storaged 再啟動,也只有一個 storaged 擁有這個 space(創建 test space 時 online 的那個 storaged)。
心跳的演變歷史
在 18-19 年的時候,當時的心跳機制沒有這麼完善。一方面,無論元信息是否更改,都會從 metad 獲取最新的元信息。而通常來說,元信息改動不會很頻繁,定期獲取元信息有一定的資源浪費。另一方面,想要將一個 storaged 節點加入和移除都是通過類似 add/delete hosts 這樣的命令,採取的是類似白名單的機制。對於其他沒有認證過的節點,都無法對外服務,這樣做固然也有一些優勢,帶來的最大問題就是不夠友好。
因此,在 19 年底開始,我們對心跳做了一系列的改動,特別鳴謝社區用戶 @zhanggguoqing。經過一段時間的驗證踩坑後,基本就形成了現在的形式。
額外的補充
有關心跳還有一個涉及到的問題就是 cluster.id 這個文件。它實際是為了防止 storaged 與錯誤的 metad 通信,大致原理如下:
- 首先,metad 在啟動的時候會根據
meta_server_addrs這個參數,生成一個 hash 值並保存在本地 kv 中。 - storaged 在啟動的時候會嘗試從 cluster.id 這個文件中獲取對應 metad 的 hash 值,並附送在心跳中發送(如果文件不存在,則第一次使用 0 代替。收到心跳響應時,將 metad 的 hash 值保存在 cluster.id 這個文件中,後續一直使用該值)。
- 在心跳處理中,metad 會比較本地 hash 值和來自 storaged 心跳請求中的 hash 值,如果不匹配則拒絕。此時,storaged 是無法對外服務的,也就是 Reject wrong cluster host 這個日誌的由來。
以上就是心跳機制大致的介紹,感興趣的你可以參考下源碼實現,GitHub 傳送門://github.com/vesoft-inc/nebula-graph。


