記一次生產事故的排查與優化——Java服務假死
一、現象
在服務器上通過curl命令調用一個Java服務的查詢接口,半天沒有任何響應。關於該服務的基本功能如下:
1、該服務是一個後台刷新指示器的服務,即該服務會將用戶需要的指示器數據提前計算好,放入redis中,當用戶請求指示器數據時便從redis中獲取;
2、指示器涉及到的模型數據更新時會發送消息到kafka,該服務監聽kafka消息,收到消息後觸髮指示器刷新任務;
3、對於一些特殊的指示器,其涉及的項目和模型較多,且數據量比較大,無法通過kafka消息來觸發刷新,否則一直處於刷新過程中,便每隔10分鐘定時進行指示器的刷新,以盡量保證的數據的及時性;
4、該服務不對外提供接口,只預留一些指示器刷新的監控接口,供內部開發人員使用;
5、相同代碼還部署了另外一個服務對外開放,用戶請求指示器數據時就向其請求,如果redis緩存中有便直接返回,沒有的話那個服務便實時計算。
二、排查
1、打印堆棧
看到上述的現象,第一反應就是服務掛了,於是便通過jps命令查看該服務的進程號,發現服務還在。那麼會不會是tomcat的線程被佔滿,沒有線程去響應請求,但是按理說是不會的,因為該服務並沒有對外提供接口。抱着好奇心還是通過jstack pid命令打印出堆棧來查看,如下圖所示。發現當前只有10個tomcat的線程,並且都處於空閑狀態,那麼就不可能因為線程被佔滿而導致curl接口沒有響應。
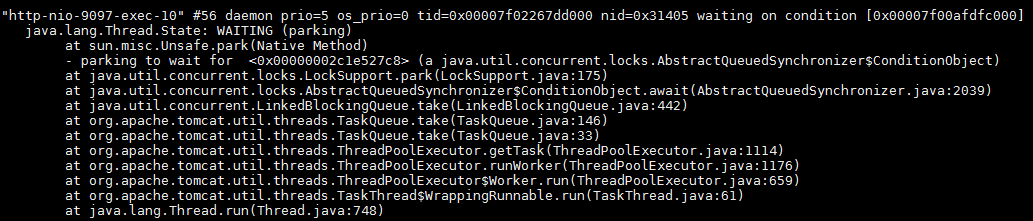
2、查看socket連接
就在一籌莫展之時,同事告訴我zabbix監控那邊會每隔一分鐘調用該服務的查詢接口來獲取當前的刷新任務數,從而展示在zabbix上進行實時監控。這時趕緊調用netstat -anp|grep 9097命令查看一下當前是否有請求,發現zabbix那邊的請求全部卡死了。

這些卡死的請求全部都在ESTABLISHED狀態,基本上把tomcat的socket連接全部佔滿了,這下終於明白為啥調用查詢接口,服務沒有響應了,但是為什麼這些查詢接口會卡死呢?
3、查看JVM基本信息
想要弄明白這個問題,還是要查看一下JVM內部的信息,是否內存溢出或者CPU佔滿,這裡採用arthas插件,下載arthas後就可以通過java -jar arthas-boot.jar直接啟動。
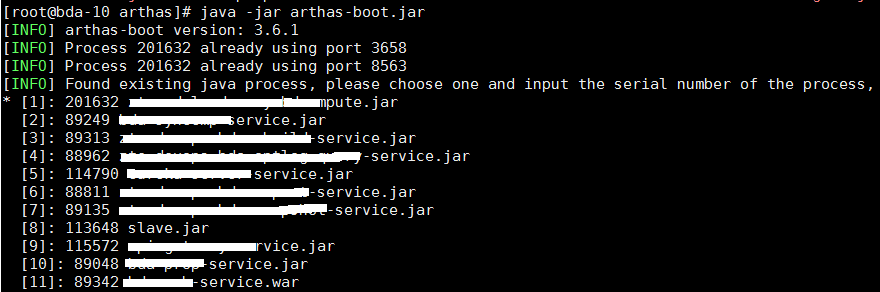
該服務是第一個,選擇1按enter鍵進入
通過dashboard命令查看服務運行的基本信息
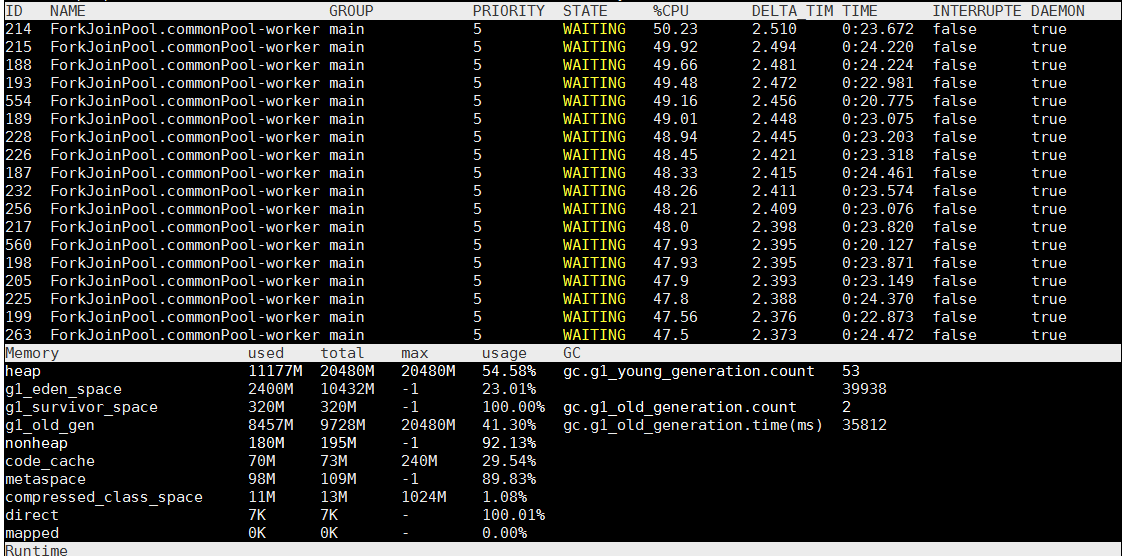
從上圖可以看出,CPU佔用率不是很高,但是內存佔用率比較高,特別是老年代,該服務總共分配了20G的內存,新生代10G,老年代10G 。服務啟動不久後就進行了Full GC,很快老年代就被佔滿,這說明有很多大對象在內存中,並且沒有被Minor GC回收掉,進入了老年代。
4、查看GC日誌
為了驗證我的猜想,通過jstat -gcutil 221446 1s命令每隔1s將GC信息實時打印出來,如下圖所示。
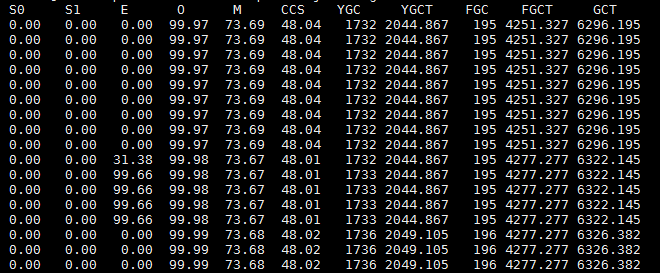
E表示Eden區的內存佔用率,O表示老年代的內存佔用率,YGC表示年輕代GC的次數,YGCT表示年輕代GC的時間總和,FGC表示Full GC的次數,FGCT表示Ful GC的時間總和。從上圖可以看出,在195次Full GC後,Eden區僅僅過了4秒內存就基本上滿了,這時又發生了Full GC,即第196次Full GC。
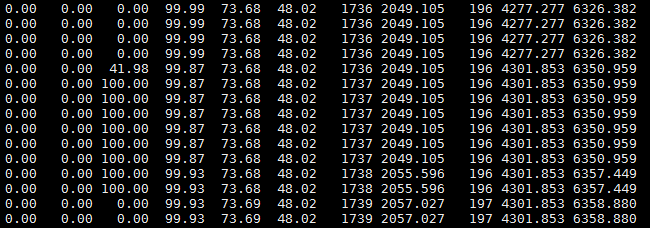
從上圖可以看出,用兩次的FGCT相減,即4301減去4277,可以知道196次Full GC花了大約24秒,這期間服務基本上處於停滯的狀態,而且從Full GC後的老年代內存佔用率可以看出,並沒有回收老年代多少內存,佔用率依舊很高。這意味着幾秒後又將進行Full GC操作,反覆循環。由此看出,該服務基本上一直處於卡死的狀態,內存將要溢出。那麼,到底是什麼對象長期佔據着內存呢?
5、分析dump文件
這時想起,該服務為了提高相似指示器的計算效率,使用了google的緩存guava。每次計算完指示器後會將該指示器涉及到的模型數據存儲在緩存中,下次計算相同模型的指示器時可以直接從內存中獲取,而不需要訪問數據庫,因為數據量比較大,所以可以顯著提升查詢指示器的效率。guava緩存的失效時間是30分鐘,也就是說30分鐘內的Full GC是無法回收多少內存的。為了證明我的猜想,就在服務啟動參數上增加了-XX:+HeapDumpOnOutOfMemoryError。這樣在服務內存溢出時會自動生成dump文件,將dump文件導出,通過VisualVM就可以分析出究竟是什麼佔據着內存。
由於我的電腦內存有限,無法打開20G的dump文件,就將服務內存調整為3G,guava緩存分配2G,運行一段時間就生成了dump文件,通過VisualVm打開,如下圖所示。

從上圖可以看出,byte數組佔據了46%的內存空間,點擊byte[]實例可以看到具體是哪些數據佔據了內存,如下圖所示。
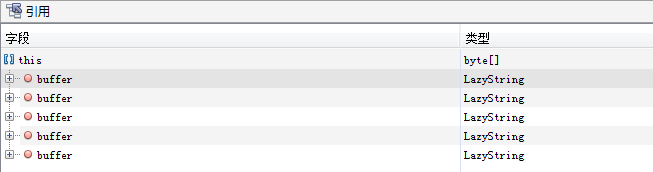
可以看到byte數組有大量的LazyString類型,即com.mysql.cj.util.LazyString,點擊詳情查看。
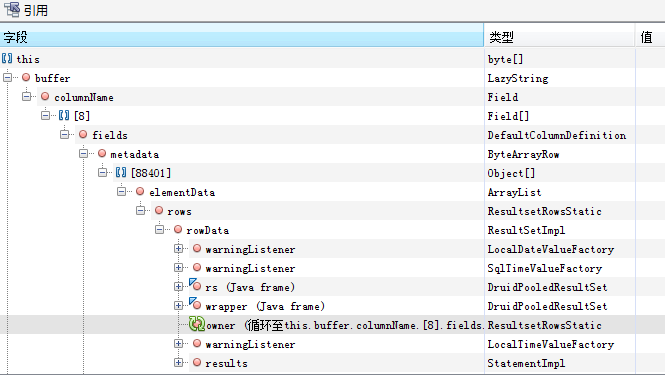
發現好多ResultSet沒有被釋放,這就是查詢指示器模型數據的返回結果。由於這些模型數據都被緩存對象引用着,而且緩存的有效期是30分鐘,所以新生代GC無法回收,直到進入老年代,如果沒有超過30分鐘緩存有效期Full GC也不會回收,所以內存被佔滿。由於這些指示器計算都是並發的,30個線程同步查詢數據會導致內存中有大量的數據緩存對象,從而導致內存溢出。
三、優化
針對以上分析出的原因,有以下兩點優化建議:
1、不再使用guava緩存,每次都實時查詢指示器的數據。因為該服務是後台刷新服務,將計算的好指示器結果存入redis緩存,不需要直接給用戶提供服務。因此,該服務不需要計算很快,只需要正確即可,取消guava緩存後新生代GC會很快回收掉不再使用的大對象,使得這些對象不會進入老年代引發Full GC,即使進入老年代也能通過Full GC回收掉,不至於內存溢出。
2、降低線程的並發數。雖然不使用緩存會提高內存的使用率,但是如果並發數過高,並且指示器數據量過大,那麼在某一瞬間內存也會被佔滿,且不會被Minor GC回收掉,從而進入老年代,直到觸發Full GC。
只有做到以上兩點,並且適當調大服務內存,這樣才會盡量讓大量的垃圾數據在年輕代就GC掉,而不是進入到老年代引發Full GC。
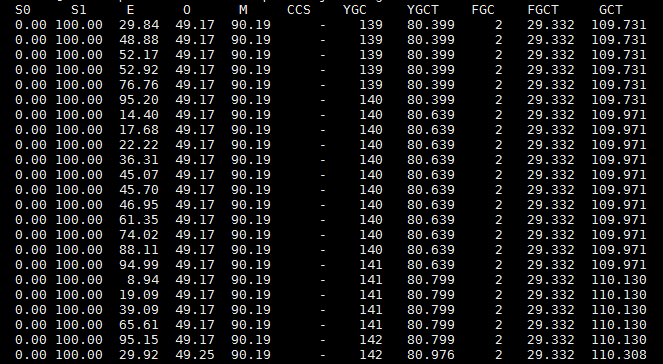
上圖是優化後的GC日誌,可以看出,新生代GC後回收了很多垃圾,並且很少一分部分對象會進入到老年代,這樣會減少Full GC的次數,從而解決系統卡死的問題。
四、總結
通過本次事故的排查,對於服務假死這樣的現象,一般的排查過程為:
1、查看服務進程是否存在;
2、根據進程號查看CPU佔用率和內存佔用率,這裡可以使用arthas這樣第三方的插件,也可以使用jdk自帶的工具,如jstack,jstat,jmap等;
3、查看GC日誌;
4、如果有內存溢出情況,可以查看dump文件找出溢出點。

