【MaixPy3文檔】寫好 Python 代碼!
本文是給有一點 Python 基礎但還想進一步深入的同學,有經驗的開發者建議跳過。
前言
上文講述了如何認識開源項目和一些編程方法的介紹,這節主要來說說 Python 代碼怎麼寫的一些演化過程和可以如何寫的參考,在現在的 Sipeed 開源社區/社群里,有太多的新手不知道如何寫好 Python 代碼,尤其是嵌入式中的 Python 代碼也是有不少的技巧和觀念需要注意的,至少讓這篇文章從循環開始說起。
可以把本文當作一篇經驗之談,主要是探討代碼穩定性與性能,以及一些計算機知識的拓展。
循環執行代碼
當寫下第一行代碼的時候,在電腦上的 Python 解釋器運行效果是這樣的。
print('Hello World')
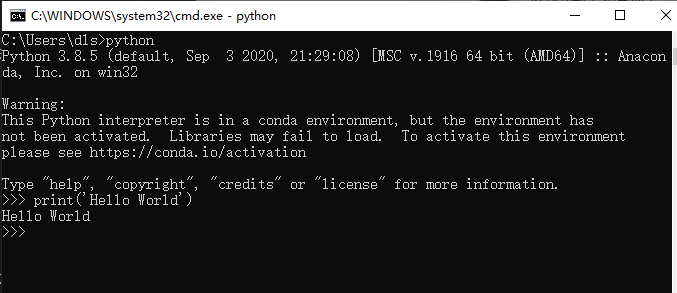
而嵌入式設備上的 python 是通過串口(serial)傳出來。
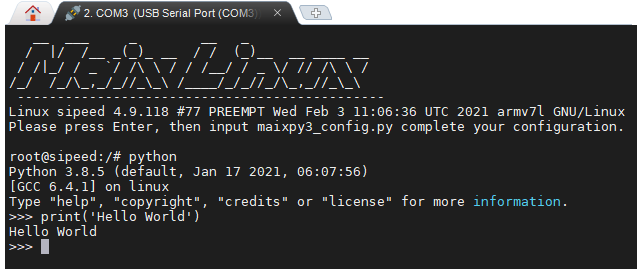
當寫完了第一行 Hello World 的 print 函數,總不能一直複製、粘貼代碼吧。
print('Hello World')
print('Hello World')
print('Hello World')
print('Hello World')
print('Hello World')
也不是只運行驗證功能就好了吧,所以加上了循環(while)執行代碼。
while True:
print('Hello World')
如果想要穩定一些,最好還要為它加入異常機制,保證它不會因為 Python 代碼的運行出錯而停下來。
while True:
try:
print('Hello World')
except Exception as e:
pass
循環代碼中為什麼需要異常機制
是不是以為 print 這樣的代碼就不會出錯?其實不然,其實程序越接近底層硬件越容易出錯。
從功能上說上文兩者之間並沒有什麼區別,都是輸出,但你會發現串口輸出可能會出現下面幾類情況。
- 串口芯片損壞或線路斷路、串口到芯片的通路損壞導致的串口沒有數據輸出。
- 串口線路數據不穩定、串口協議(波特率、停止位)等配置錯誤導致的數據亂碼。
這就意味着你會遇到很多來自硬件上的問題,所以要注意到這些意外。
那在軟件代碼上會發生什麼有關於硬件上的意外呢?
通常有無響應、無應答、未連接等不成功的錯誤,它們是來自 IO 的錯誤。
- 當網絡連接失敗後需要超時重連,傳輸數據通道閑置時需要定時檢查心跳數據包。
- 當配置文件寫入後通常會讀出來確認真的寫入了,也是為了防止出錯,可能是存儲介質出錯,也可能是邏輯出錯。
- 當用戶向輸入框填了錯誤數據,不用寫怎麼判斷和處理,不合法的數據拋出異常就行。
因為這些現象太多不確定的可能性,才會需要對代碼進行異常捕獲機制,來決定是否放過這次意外,可能會在下一次的循環就恢復了,這樣就能夠基本保證了 Python 代碼循環的穩定性了。
來自外部/硬件上異常機制
這樣就足夠了嗎?
事實上有些錯誤不源於 Python 代碼,可能來自於底層 C 代碼,或其他程序,上文說的異常機制只能捕獲 Python 異常,不能捕獲來自其他語言的異常。
所以實際情況比想像的要更嚴峻一些,當你無法解決不穩定的系統帶來其他異常的時候,通常在服務器程序上設計會在外部附加一個守護程序(如調試程序)來定時檢查自己的程序,例如可以檢查下面的一些情況。
- 檢查當前的系統是否能聯網
- 檢查數據庫的通路是否正常
- 檢查指定的程序是否在運行
總得來說,你要為你的程序做一個監控程序,可以是守護程序,也可以是看門狗。
具體怎麼實現,可以了解一些守護進程的實現。
看門狗(watchdog)是什麼?
- 看門狗就是定期的查看芯片內部的情況,一旦發生錯誤就向芯片發出重啟信號的電路。
- 看門狗命令在程序的中斷中擁有最高的優先級。
- 防止程序跑飛。也可以防止程序在線運行時候出現死循環。
什麼意思?
所謂的守護程序是靠一個軟件去監控另一個軟件的狀態,而看門狗的工作行為描述如下:
假設有一條需要定時吃飯(更新)的狗、如果不定時喂它(feed)就會餓着肚子叫。那麼問題來了,什麼時候狗會叫呢?因為人(芯片)死了,沒人喂它了。(這也許是一個冷笑話)
所以當看門狗開始工作了的時候,就說明芯片已經不知道在幹嘛了,反正沒有在喂狗(feed),此時可以認為芯片已經跑飛了,程序已經沒有在工作,沒有綁定處理的中斷函數的話,就只能重啟了。
任何硬件產品都有可能出現意外和錯誤,看門狗相當於芯片上的最後一層保障機制,通常它可能會發生在函數棧的指針參數執行出錯,導致後續的喂狗操作再也到不了,芯片程序進入空轉,有些程序在設計上還會多了一層中斷函數處理,可以讓你試圖糾正這種錯誤,或是把這些錯誤打印出來。
具體怎麼實現,可以查閱不同芯片提供的程序接口或寄存器。
優化!優化!!優化!!!
當你的程序已經跑起來以後,你會發現程序並沒有達到令人滿意的效果,在性能、內存上都沒有經過任何考慮,只是實現了最起碼的功能而已,那麼完成了功能以後,可以如何繼續呢?
當然,在優化程序之前得先建立計算代碼執行時間的觀念,建立起最簡單的性能指標,如在代碼加上時間計算。
def func():
i = 20**20000
import time
last = time.time()
func()
tmp = time.time() - last
print(tmp)
在 CPU I5-7300HQ 的計算機上見到每一次的循環的時間間隔約為 0.000997781753540039 不足 1ms 即可完成。
PS C:\Users\dls\Documents\GitHub\MaixPy3> & C:/Users/dls/anaconda3/python.exe c:/Users/dls/Documents/GitHub/MaixPy3/test.py
0.000997781753540039
注意不要寫到 print(time.time() - last) ,因為重定向後的 print 是相當耗時的,尤其是當內容輸出到串口終端或網頁前端的時候,如下使用 M2dock 設備來演示一下串口輸出。
重定向指改變內容要輸出的地方
root@sipeed:/# python3
Python 3.8.5 (default, Jan 17 2021, 06:07:56)
[GCC 6.4.1] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> def func():
... i = 20**20000
...
>>> import time
>>> last = time.time()
>>> func()
>>> tmp = time.time() - last
>>> print(tmp)
0.09001994132995605
>>>
>>>
>>> def func():
... i = 20**20000
...
>>> import time
>>> last = time.time()
>>> func()
>>> print(time.time() - last)
1.480057954788208
>>>
可以看到相差可能有 1 秒,而事實上只需要 90ms 就可以完成 func 函數的運算,這就產生了誤差導致不準確,若是使用 jupyter 輸出就會看到 0.026456356048583984 需要 26ms 可以較為準確的推算出它的真實運算結果。
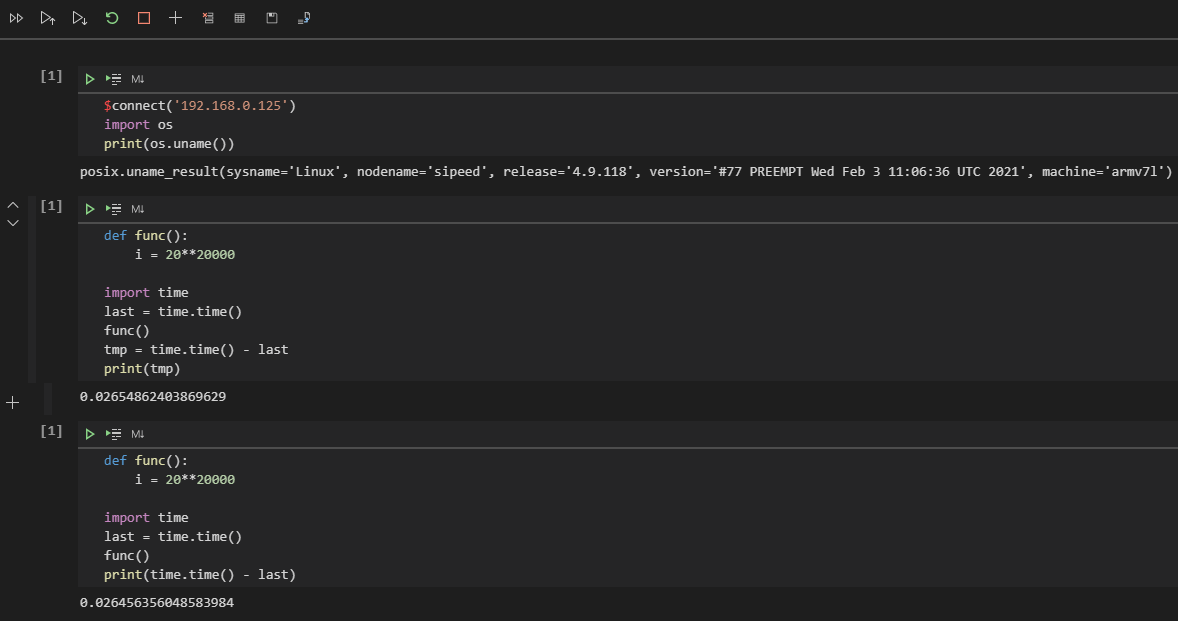
為什麼會造成這種差異的原因是因為串口依次輸入命令執行會存在誤差,而 jupyter 是通過網絡 socket 連接傳輸顯示到屏幕上,所以耗時誤差只會發生在運算重定向輸出結果的時候,最終結果會較為貼近真實運算結果,通過保存下述代碼文件來運行即可得知真實情況下約為 28ms 完成。
root@sipeed:/# cat test.py
def func():
i = 20**20000
import time
last = time.time()
func()
tmp = time.time() - last
print(tmp)
root@sipeed:/# python test.py
0.028677940368652344
root@sipeed:/#
所以從現在建立起最基礎的計算耗時,並且認知到在計算機的世界裏,毫秒其實已經很慢了,然後可以類比一種感受,人眼感到流暢的畫面至少是 24 fps ,而平時的視頻在 15 fps 的流動是不會讓你感受到卡頓的,如果低於這個閾值,則會出現卡頓造成心理上的不愉快,這個 15 fps 意味着每秒 15 張存在變化的畫面,如果用程序來類比就是 1000 ms / 15 = 66 ms ,也就是每個流程操作最好是在 66ms 內完成,這樣用戶才不會覺得卡頓,同理,當 1000ms / 24 = 41ms 就可以確保用戶體驗這個軟件的時候會覺得流暢。
有了基本的性能指標,就有了優化的對比參考,如果是一些測試框架會幫助你自動完成每個函數的耗時統計,但在沒有現成框架工具的時候就要稍微辛苦一下自己了。
講一些經典案例
在日常中存在最多操作就是循環和判斷,顯然最好的優化就是減少不必要的指令操作,可以通過改變代碼的執行結構來進行優化,下面就來具體分析吧。
如某個向網絡上發送數據的操作,最初可能會按人類直覺寫出以下的代碼,這是一種不用思考也可以很容易寫出來的同步阻塞式的結構,每一條語句都是滿足了某些條件再繼續執行。
def xxxx_func():
import random
return random.randint(0, 1)
while True:
is_idle = True
if is_idle is True:
print('try start')
is_ready = xxxx_func()
if is_ready is True:
print('try ready')
is_connected = xxxx_func()
if is_connected is True:
print('try connect')
is_send = xxxx_func()
if is_send is True:
print('try send')
is_reply = xxxx_func()
if is_reply is True:
print('wait reply')
is_exit = xxxx_func()
if is_exit is True:
print('operate successfully')
而優化只需要加狀態變量改寫成狀態機結構(fsm)就可以了,所有代碼都可以平行化執行,並根據執行頻率的重要程度(權重)調整各項判斷的順序,尤其是移除一些不必要的判斷。
def xxxx_func():
return 1
# state value
is_idle, is_ready, is_connected, is_send, is_reply, is_exit = 0, 1, 2, 3, 4, 5
state = is_idle
while state != is_exit:
if state is is_reply:
print('wait reply')
state = is_exit if xxxx_func() else is_send
continue
if state is is_send:
print('try send')
state = is_reply if xxxx_func() else is_connected
continue
if state is is_connected:
print('try connect')
state = is_send if xxxx_func() else is_ready
continue
if state is is_ready:
print('try ready')
state = is_connected if xxxx_func() else is_idle
continue
if state is is_idle:
print('try start')
state = is_ready
continue
這樣改造執行結構後,每個代碼之間的上下文關係並不強烈,是否執行某個語句取決於系統對於某個狀態是否滿足,如果狀態失敗也不會倒退回最初的判斷,也就不需要每次都對各個狀態做檢查,檢查只會發生在出錯的時候狀態跌落(state – 1)。
缺點就是需要消耗一些記錄狀態的變量(●’◡’●),不過代碼的拓展性和維護性就上來了。
可以根據實際情況增加狀態的判斷或是減少狀態的轉移(調整狀態轉移範圍),如直接設置 state = is_ready,假設某些操作是已知的就可以跳過,可以添加 continue 跳過一些不可能發生的狀態。
還有嗎?
進一步優化還可以幹掉 if 直接將狀態與函數聯合索引執行,簡化代碼如下。
is_a, is_b, is_c = 0, 1, 2
state = is_a
def try_b():
global state
state = is_c
def try_a():
global state
state = is_b
func = [try_a, try_b]
while state != is_c:
func[state]()
# print(state)
基於上述結構給出一個示例代碼參考。
class xxxx_fsm:
is_start, is_ready, is_connected, is_send, is_reply, is_exit = 0, 1, 2, 3, 4, 5
def xxxx_func(self):
return 1
def __init__(self):
self.func = [self.try_start, self.try_ready, self.try_connect, self.try_send, self.wait_reply]
self.state = __class__.is_start # state value
def wait_reply(self):
self.state = __class__.is_exit if self.xxxx_func() else __class__.is_send
def try_send(self):
self.state = __class__.is_reply if self.xxxx_func() else __class__.is_connected
def try_connect(self):
self.state = __class__.is_send if self.xxxx_func() else __class__.is_ready
def try_ready(self):
self.state = __class__.is_connected if self.xxxx_func() else __class__.is_start
def try_start(self):
self.state = __class__.is_ready
def event(self):
self.func[self.state]()
def check(self):
return self.state != __class__.is_exit
tmp = xxxx_fsm()
while tmp.check():
tmp.event()
# print(tmp.state)
其實上述的有限狀態機並非萬能的代碼結構,只是剛好很適合拆分已知的複雜業務邏輯的同步阻塞代碼,那麼還有什麼結構可以選擇嗎?有的,此前說的都是同步阻塞的代碼,所以還有所謂的異步執行的代碼。
說說異步的執行方式
在這之前的代碼都是按每個循環的步驟有序執行完成功能(同步執行),但現實生活中的操作一定是按順序發生的嗎?其實不然,其實很多操作可能會在任意時刻發生。
想像一個程序,它會響應來自網絡的數據,也會響應來自人類的按鍵輸入操作,這兩個操作如果按上述的結構來寫,可能會是下面這樣。
import time, random
def check_http():
time.sleep(random.randint(0, 3))
return random.randint(0, 1)
def http_recv():
while True:
if check_http():
print('http_recv')
break
def check_key():
time.sleep(random.randint(0, 2))
return random.randint(0, 1)
def key_press():
while True:
if check_key():
print('key_press')
break
while True:
http_recv()
key_press()
可以看到 http_recv 和 key_press 兩個事件的檢查會各自佔據一段不知何時會觸發或結束的檢測的時間,程序只能循環等待這些事件會不會發生(或稱輪詢)。
這是個看起來可以工作但浪費了很多時間的程序,現實里接收到許多用戶的網絡連接,而服務程序不可能只服務某個用戶的連接。
所以改寫異步的第一步就是簡化代碼中不必要的循環,將每個需要循環等待的部分拆分成非阻塞的函數。
非阻塞意味着某個操作會在有限的時間內結束,期望某個函數能夠在較短的時間(10ms)內退出,退出不代表功能結束,只是需要把這個時間讓出去給其他函數調用。
import time, random
http_state, key_state = 0, 0
def http_recv():
global http_state
if http_state:
print('http_recv')
def key_press():
global key_state
if key_state:
print('key_press')
def check_state():
global key_state, http_state
time.sleep(random.randint(0, 1))
key_state, http_state = random.randint(0, 2), random.randint(0, 2)
while True:
check_state()
http_recv()
key_press()
從邏輯上移除了等待,再通過統一的(check_state)檢查每個操作的狀態再決定是否喚醒該操作,變成只有滿足某個狀態才執行該操作,將此前的多個循環拆分出來。
但你會發現這樣寫還是有問題,這樣豈不是意味着所有代碼都要按這個接口來寫了嗎?那麼多的代碼,不可能全都可以拆分吧。
所以是時候加入異步 IO (asyncio)的 async 和 await 語法了!先來點簡單的。
import asyncio
async def test_task(name, tm):
await asyncio.sleep(tm)
print('%s over...' % name)
async def main(name):
import time
last = time.time()
await asyncio.gather(
test_task(name + 'A', 0.1),
test_task(name + 'B', 0.2),
test_task(name + 'C', 0.3),
)
print(name, time.time() - last)
loop = asyncio.get_event_loop()
tasks = [ main('l: '), main('r: ') ]
loop.run_until_complete(asyncio.wait(tasks))
運行結果如下:
PS python.exe test.py
r: A over...
l: A over...
r: B over...
l: B over...
r: C over...
l: C over...
r: 0.3076450824737549
l: 0.3076450824737549
可以看到代碼總共耗時為 0.3s 完成,但運行了兩次不同所屬的 main 函數以及各自調用三次不同延時的 test_task 任務,而 await asyncio.sleep(tm) 延時期間實際上是被 asyncio 拿去運行其他的 async 函數了,基於此結構可以這樣改寫。
import asyncio, random
async def key_press():
await asyncio.sleep(0.1)
key_state = random.randint(0, 1)
if key_state:
return 'have key_press'
async def http_recv():
await asyncio.sleep(0.2)
http_state = random.randint(0, 1)
if http_state:
return 'have http_recv'
async def run():
import time
while True:
task_list = [http_recv(), key_press()]
done, pending = await asyncio.wait(task_list, timeout=random.randint(0, 1) / 2)
print(time.time(), [done_task.result() for done_task in done])
await asyncio.sleep(0.2) # remove to run too fast.
loop = asyncio.get_event_loop()
loop.run_until_complete(run())
執行效果如下。
1615141673.93252 [None, None]
1615141674.134 [None, 'have http_recv']
1615141674.3350334 [None, None]
1615141674.7361133 ['have key_press', 'have http_recv']
1615141674.9365196 [None, None]
1615141675.1399093 ['have http_recv', None]
可以看到在運行 run 函數延時 await asyncio.sleep(0.2) 後就會循環加載異步事件函數執行,配置 asyncio.wait 函數的參數 timeout 會導致 random.randint(0, 1) / 2 秒後就會自行超時退出,退出的時候會收集當前的 key_press 和 http_recv 函數的運行結果,如果期間異步函數成功返回值(return 'have http_recv'),最終結果就會輸出 1615138982.9762554 ['have http_recv'] 表示有事件觸發並執行了,否則為 None ,這將在下一次循環重新提交異步函數列表 [http_recv(), key_press()] 執行。
注意 Python 3.7 以前的版本使用 loop = asyncio.get_event_loop() & loop.run_forever() & loop.run_until_complete() ,而後採用 asyncio.run() 了。每個編程語言都有自己的異步框架和語法特色,請根據實際情況選用。
考慮一下封裝模塊給其他人使用吧?
隨着代碼越寫越多,項目越來越大,大到可能不是你一個人寫的時候,你就要開始注意工程項目的管理了,這與個人寫代碼時的優化略微不同,主要強調的是不同代碼之間的接口分離,盡量不干涉到他人的實現和提交,所以在寫代碼的時候,不妨為自己準備一個獨立模塊,以方便與其他人寫的分離或是導入其他(import)模塊。
若是在某個目錄(mod)下存在一個 __init__.py 的話,它就會變成 Python 模塊,且名為 mod ,其中 __init__.py 的內容可能如下:
def code():
print('this is code')
而且在該目錄下還存在一個額外的代碼文件(如 tmp.py )內容如下:
info = 'nihao'
對於開發者或用戶來說,在 import mod 的時候會調用 mod 目錄下的 __init__.py ,而 from mod import tmp 會調用 mod 目錄下的 tmp.py 代碼。
>>> import mod
>>> mod
<module 'mod' from 'C:\\mod\\__init__.py'>
>>> mod.code()
this is code
>>> from mod import tmp
>>> tmp
<module 'mod.tmp' from 'C:\\mod\\tmp.py'>
>>> tmp.info
'nihao'
>>>
這樣你寫的代碼就可以作為一個模塊被其他人所使用了,注意 import 只會加載並執行一次,想要再次加載請使用 reload 函數。
如何進行內存或空間上的分析?
這裡就推薦 memory_profiler 開源工具,快去體驗吧。
使用方法:python -m memory_profiler example.py
from memory_profiler import profile
@profile
def my_func():
a = [1] * (10 ** 6)
b = [2] * (2 * 10 ** 7)
del b
return a
運行結果:
Line # Mem usage Increment Occurences Line Contents
============================================================
3 38.816 MiB 38.816 MiB 1 @profile
4 def my_func():
5 46.492 MiB 7.676 MiB 1 a = [1] * (10 ** 6)
6 199.117 MiB 152.625 MiB 1 b = [2] * (2 * 10 ** 7)
7 46.629 MiB -152.488 MiB 1 del b
8 46.629 MiB 0.000 MiB 1 return a
總結
其實所謂的優化就是在程序上不斷追求無延遲、零等待、魯棒性、藝術品、最佳實踐等指標。
當完成了自己的某個作品,多少都會希望自己的作品是最好的,又或是越做越好的。熬夜辛苦寫下的程序,用盡自己的腦力和各種邏輯思維來不斷打磨它,儘可能的把它變成一件藝術品,然後為之自豪和興奮,恨不得向它人炫耀自己的成果。
但願你不會在往後的一堆垃圾代碼中失去了最初喜歡上編程的心情。
附錄:多線程?多進程?該不該使用?
事實上多線程和多進程都是建立在操作系統之上的概念,由於操作系統中存在不同優先級的中斷函數,其中優先級較高的函數棧會打斷優先級低的函數棧執行,並且優先級高的操作結束就會輪到優先級低的操作,優先級高的操作通常都會被設計成儘快結束退出(哪怕是失敗),不然用戶程序就會像老爺爺一樣緩慢運行了。
多線程是由擁有內存空間進程(某個程序)創造出來的,多線程函數「看上去」是彼此並行的,並且共用所屬進程的內存數據,而不同進程之間申請的內存空間並不互通,所以當你想要實現守護進程的程序,是需要對其他進程進行通信的(如卸載程序時會檢查並發送信號停止要卸載的程序),並非是在代碼中修改一個變量那麼簡單。
事實上我並不鼓勵用戶在 Python 上使用多線程,因為全局解釋器鎖(GIL)的存在,CPython 解釋器中執行的每一個 Python 線程,都會先鎖住自己,以阻止別的線程執行。而 CPython 解釋器會去輪詢檢查線程 GIL 的鎖住情況,每隔一段時間,Python 解釋器就會強制當前線程去釋放 GIL,這樣別的線程才能有執行的機會。總得來說 CPython 的實現決定了使用多線程並不會帶來性能的提升,反而會帶來線程安全的問題,尤其是需要線程資源同步了。
警告:請不要在每個線程中都寫上不會退出的死循環,多線程的並不是拿來偷懶的工具。


