SOLID架構設計原則
最近通讀了《架構整潔之道》,受益匪淺,遂摘選出設計原則部分,與大家分享,希望大家能從中獲益。
以下為書中第3部分 設計原則的原文。
設計原則概述
通常來說,要想構建—個好的軟件系統,應該從寫整潔的代碼開始做起。畢竟,如果建築所使用的磚頭質量不佳,那麼架構所能起到的作用也會很有限。反之亦然,如果建築的架構設計不佳,那麼其所用的磚頭質量再好也沒有用。這就是SOLID設計原則所要解決的問題。
SOLID原則的主要作用就是告訴我們如何將數據和函數組織成為類,以及如何將這些類鏈接起來成為程序。請注意,這裡雖然用到了「類」這個詞,但是並不意味着我們將要討論的這些設計原則僅僅適用於面向對象編程。這裡的類僅僅代表了一種數據和函數的分組,每個軟件系統都會有自己的分類系統,不管它們各自是不是將其稱為「類」,事實上都是SOLID原則的適用領域。
一般情況下,我們為軟件構建中層結構的主要目標如下:
-
使軟件可容忍被改動
-
使軟件更容易被理解
-
構建可在多個軟件系統中復用的組件
我們在這裡之所以會使用「中層」這個詞,是因為這些設計原則主要適用於那些進行模塊級編程的程序員。SO凵D原則應該直接緊貼於具體的代碼邏輯之上,這些原則是用來幫助我們定義軟件架構中的組件和模塊的。
當然了,正如用好磚也會蓋歪樓一樣,採用設計良好的中層組件並不能保證系統的整體架構運作良好。正因為如此,我們在講完SOLID原則之後,還會再繼續針對組件的設計原則進行更進一步的討論,將其推進到高級軟件架構部分。
SOLID原則的歷史已經很悠久了,早在20世紀80年代末期,我在 USENET新聞組(該新聞組在當時就相當於今天的 Facebook)上和其他人辯論軟件設計理念的時候,該設計原則就已經開始逐漸成型了。隨着時間的推移,其中有一些原則得到了修改,有一些則被拋棄了,還有一些被合併了,另外也增加了一些。它們的最終形態是在2000年左右形成的,只不過當時採用的是另外一個展現順序。
2004年前後, Michael feathers的一封電子郵件提醒我:如果重新排列這些設計原則,那麼它們的首字母可以排列成SOLID——這就是SOLID原則誕生的故事。
在這一部分中,我們會逐章地詳細討論每個設計原則,下面先來做一個簡單摘要。
SRP:單一職責原則。
該設計原則是基於康威定律( Conway『s Law)的一個推論——軟件系統的最佳結構高度依賴於開發這個系統的組織的內部結構。這樣,每個軟件模塊都有且只有一個需要被改變的理由。
OCP:開閉原則。
該設計原則是由 Bertrand Meyer在20世紀80年代大力推廣的,其核心要素是:如果軟件系統想要更容易被改變,那麼其設計就必須允許新增代碼來修改系統行為,而非只能靠修改原來的代碼。
LSP:里氏替換原則。
該設計原則是 Barbara liskov在1988年提出的著名的子類型定義。簡單來說,這項原則的意思是如果想用可替換的組件來構建軟件系統,那麼這些組件就必須遵守同一個約定,以便讓這些組件可以相互替換。
ISP:接口隔離原則。
這項設計原則主要告誡軟件設計師應該在設計中避免不必要的依賴。
DIP:依賴反轉原則。
該設計原則指出高層策略性的代碼不應該依賴實現底層細節的代碼,恰恰相反,那些實現底層細節的代碼應該依賴高層策略性的代碼。
這些年來,這些設計原則在很多不同的出版物中都有過詳細描述。在接下來的章節中,我們將會主要關注這些原則在軟件架構上的意義,而不再重複其細節信息。如果你對這些原則並不是特別了解,那麼我建議你先通過腳註中的文檔熟悉一下它們,否則接下來的章節可能有點難以理解。
SRP:單一職責原則
SRP是SOLID五大設計原則中最容易被誤解的一。也許是名字的原因,很多程序員根據SRP這個名字想當然地認為這個原則就是指:每個模塊都應該只做一件事。
沒錯,後者的確也是一個設計原則,即確保一個函數只完成一個功能。我們在將大型函數重構成小函數時經常會用到這個原則,但這只是一個面向底層實現細節的設計原則,並不是SRP的全部。
在歷史上,我們曾經這樣描述SRP這一設計原則:
任何一個軟件模塊都應該有且僅有一個被修改的原因。
在現實環境中,軟件系統為了滿足用戶和所有者的要求,必然要經常做出這樣那樣的修改。而該系統的用戶或者所有者就是該設計原則中所指的「被修改的原因」。所以,我們也可以這樣描述SRP:
任何一個軟件模塊都應該只對一個用戶(User)或系統利益相關者( Stakeholder)負責。
不過,這裡的「用戶」和「系統利益相關者」在用詞上也並不完全準確,它們很有可能指的是一個或多個用戶和利益相關者,只要這些人希望對系統進行的變更是相似的,就可以歸為一類——一個或多有共同需求的人。在這裡,我們將其稱為行為者( actor)。
所以,對於SRP的最終描述就變成了:
任何一個軟件模塊都應該只對某一類行為者負責。
那麼,上文中提剄的「軟件模塊」究竟又是在指什麼呢?大部分情況下,其最簡單的定義就是指一個源代碼文件。然而,有些編程語言和編程環境並不是用源代碼文件來存儲程序的。在這些情況下,「軟件模塊」指的就是一組緊密相關的函數和數據結構。
在這裡,「相關」這個詞實際上就隱含了SRP這一原則。代碼與數據就是靠着與某一類行為者的相關性被組合在一起的。
或許,理解這個設計原則最好的辦法就是讓大家來看一些反面案例。
反面案例1:重複的假象。
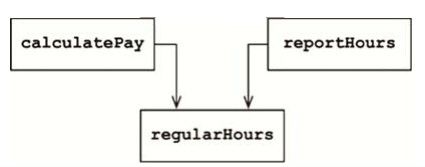
這是我最喜歡舉的一個例子:某個工資管理程序中的 Employee類有三個函數 calculate Pay()、reportHours()和save()。

如你所見,這個類的三個函數分別對應的是三類非常不同的行為者,違反了SRP設計原則。
calculatePay()函數是由財務部門制定的,他們負責向CFO彙報。
reportHours()函數是由人力資源部門制定並使用的,他們負責向COO彙報。
save()函數是由DBA制定的,他們負責向CTO彙報。
這三個函數被放在同一個源代碼文件,即同一個Employee類中,程序員這樣做實際上就等於使三類行為者的行為耦合在了一起,這有可能會導致CFO團隊的命令影響到COO團隊所依賴的功能。
例如, calculatePay()函數和 reportHours()函數使用同樣的邏輯來計算正常工作時數。程序員為了避免重複編碼,通常會將該算法單獨實現為個名為 regularHours()的函數(見下圖)。
接下來,假設CFO團隊需要修改正常工作時數的計算方法,而COO帶領的HR團隊不需要這個修改,因為他們對數據的用法是不同的。
這時候,負責這項修改的程序員會注意到calculate Pay()函數調用了 regularHours()函數,但可能不會注意到該函數會同時被reportHours()調用。
於是,該程序員就這樣按照要求進行了修改,同時CFO團隊的成員驗證了新算法工作正常。這項修改最終被成功部署上線了。
但是,COO團隊顯然完全不知道這些事情的發生,HR仍然在使用 reportHours()產生的報表,隨後就會發現他們的數據出錯了!最終這個問題讓COO十分憤怒,因為這些錯誤的數據給公司造成了幾百萬美元的損失。
與此類似的事情我們肯定多多少少都經歷過。這類問題發生的根源就是因為我們將不同行為者所依賴的代碼強湊到了一起。對此,SRP強調這類代碼一定要被分開。
反面案例2:代碼合併
一個擁有很多函數的源代碼文件必然會經歷很多次代碼合併,該文件中的這些函數分別服務不同行為者的情況就更常見了。
例如,CTO團隊的DBA決定要對 Employee數據庫表結構進行簡單修改。與此同時,COO團隊的HR需要修改工作時數報表的格式。
這樣一來,就很可能出現兩個來自不同團隊的程序員分別對 Employee類進行修改的情況。不出意外的話,他們各自的修改一定會互相衝突,這就必須要進行代碼合併。
在這個例子中,這次代碼合併不僅有可能讓CTO和COO要求的功能出錯,甚至連CFO原本正常的功能也可能受到影響。
事實上,這樣的案例還有很多,我們就不一一列舉了。它們的一個共同點是,多人為了不同的目的修改了同一份源代碼,這很容易造成問題的產生。
而避免這種問題產生的方法就是將服務不同行為者的代碼進行切分。
解決方案
我們有很多不同的方法可以用來解決上面的問題每一種方法都需要將相關的函數劃分成不同的類。
其中,最簡單直接的辦法是將數據與函數分離,設計三個類共同使用一個不包括函數的、十分簡單的EmployeeData類(見下圖),每個類只包含與之相關的函數代碼,互相不可見,這樣就不存在互相依賴的情況了。
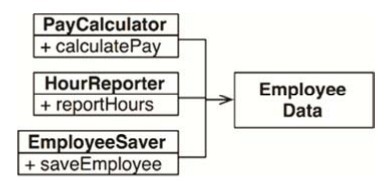
這種解決方案的壞處在於:程序員現在需要在程序里處理三個類。另一種解決辦法是使用 Facade設計模式(見下圖)。

這樣一來, Employee Facade類所需要的代碼量就很少了,它僅僅包含了初始化和調用三個具體實現類的函數。
當然,也有些程序員更傾向於把最重要的業務邏輯與數據放在一起,那麼我們也可以選擇將最重要的函數保留在 Employee類中,同時用這個類來調用其他沒那麼重要的函數(見下圖)。

讀者也許會反對上面這些解決方案,因為看上去這裡的每個類中都只有一個函數。事實上並非如此,因為無論是計算工資、生成報表還是保存數據都是一個很複雜的過程,每個類都可能包含了許多私有函數。
總而言之,上面的每一個類都分別容納了一組作用於相同作用域的函數,而在該作用域之外,它們各自的私有函數是互相不可見的。
本章小結
單一職責原則主要討論的是函數和類之間的關係——但是它在兩個討論層面上會以不同的形式出現。在組件層面,我們可以將其稱為共同閉包原則( Common Closure Principle),在軟件架構層面,它則是用於奠定架構邊界的變更軸心( Axis of Change)。我們在接下來的章節中會深入學習這些原則。
OCP:開閉原則
開閉原則(OCP)是 Bertrand Meyer在1988年提出的,該設計原則認為:
設計良好的計算機軟件應該易於擴展,同時抗拒修改。
換句話說,一個設計良好的計算機系統應該在不需要修改的前提下就可以輕易被擴展。
其實這也是我們研究軟件架構的根本目的。如果對原始需求的小小延伸就需要對原有的軟件系統進行大幅修改,那麼這個系統的架構設計顯然是失敗的。
儘管大部分軟件設計師都已經認可了OCP是設計類與模塊時的重要原則,但是在軟件架構層面,這項原則的意義則更為重大。
下面,讓我們用一個思想實驗來做一些說明。
思想實驗
假設我們現在要設計一個在Web頁面上展示財務數據的系統,頁面上的數據要可以滾動顯示,其中負值應顯示為紅色。
接下來,該系統的所有者又要求同樣的數據需要形成一個報表,該報表要能用黑白打印機打印,並且其報表格式要得到合理分頁,每頁都要包含頁頭、頁尾及欄目名。同時,負值應該以括號表示。
顯然,我們需要增加一些代碼來完成這個要求。但在這裡我們更關注的問題是,滿足新的要求需要更改多少舊代碼。
一個好的軟件架構設計師會努力將舊代碼的修改需求量降至最小,甚至為0。
但該如何實現這一點呢?我們可以先將滿足不同需求的代碼分組(即SRP),然後再來調整這些分組之間的依賴關係(即DIP)
利用SRP,我們可以按下圖中所展示的方式來處理數據流。即先用一段分析程序處理原始的財務數據,以形成報表的數據結構,最後再用兩個不同的報表生成器來產生報表。
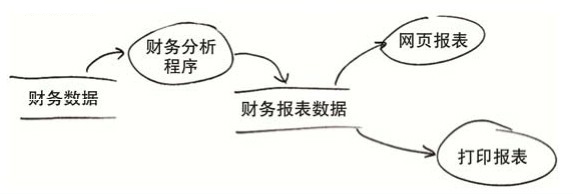
這裡的核心就是將應用生成報表的過程拆成兩個不同的操作。即先計算出報表數據,再生成具體的展示報表(分別以網頁及紙質的形式展示)。
接下來,我們就該修改其源代碼之間的依賴關係了。這樣做的目的是保證其中一個操作被修改之後不會影響到另外一個操作。同時,我們所構建的新的組織形式應該保證該程序後續在行為上的擴展都無須修改現有代碼。
在具體實現上,我們會將整個程序進程劃分成一系列的類,然後再將這些類分割成不同的組件。下面,我們用下圖中的那些雙線框來具體描述一下整個實現。在這個圖中,左上角的組件是Controller,右上角是 Interactor,右下角是Database,左下角則有四個組件分別用於代表不同的 Presente和VieW。
在圖中,用「I」標記的類代表接口,用

首先,我們在圖中看到的所有依賴關係都是其源代碼中存在的依賴關係。這裡,從類A指向類B的箭頭意味着A的源代碼中涉及了B,但是B的源代碼中並不涉及A。因此在圖中,FinancialDataMapper在實現接口時需要知道FinancialDataGateway的實現,而FinancialDataGateway則完全不必知道FinancialDataMapper的實現。
其次,這裡很重要的一點是這些雙線框的邊界都是單向跨越的。也就是說,上圖中所有組件之間的關係都是單向依賴的,如下圖所示,圖中的箭頭都指向那些我們不想經常更改的組件。
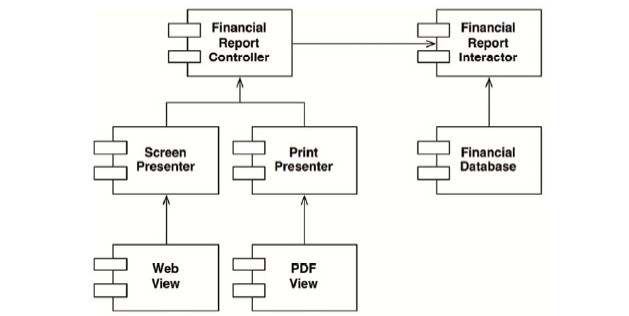
讓我們再來複述一下這裡的設計原則:如果A組件不想被B組件上發生的修改所影響,那麼就應該讓B組件依賴於A組件。
所以現在的情況是,我們不想讓發生在 Presenter上的修改影響到 Controller,也不想讓發生在view上的修改影響到 Presenter。而最關鍵的是,我們不想讓任何修改影響到 Interactor。
其中, Interactor組件是整個系統中最符合OCP的。發生在 Database、 Controller、 Presenter甚至view上的修改都不會影響到 Interactor。
為什麼 interactor會被放在這麼重要的位置上呢?因為它是該程序的業務邏輯所在之處, Interactor中包含了其最高層次的應用策略。其他組件都只是負責處理周邊的輔助邏輯,只有 Interactor才是核心組件。
雖然 Controller組件只是 interactor的附屬品,但它卻是 Presenter和vew所服務的核心。同樣的,雖然 Presenter組件是 Controller的附屬品,但它卻是view所服務的核心。
另外需要注意的是,這裡利用「層級」這個概念創造了一系列不同的保護層級。譬如, Interactor是最高層的抽象,所以它被保護得最嚴密,而Presenter比view的層級高,但比 Controller和Interactor的層級低。
以上就是我們在軟件架構層次上對OCP這一設計原則的應用。軟件架構師可以根據相關函數被修改的原因、修改的方式及修改的時間來對其進行分組隔離,並將這些互相隔離的函數分組整理成組件結構,使得高階組件不會因低階組件被修改而受到影響。
依賴方向的控制
如果剛剛的類設計把你嚇着了,別害怕!你剛剛在圖表中所看到的複雜度是我們想要對組件之間的依賴方向進行控制而產生的。
例如,FinancialReportGenerator和FinancialDataMapper之間的FinancialDataGateway接口是為了反轉 interactor與Database之間的依賴關係而產生的。同樣的,FinancialReportPresente接口與兩個View接口之間也類似於這種情況。
信息隱藏
當然, FinancialReportRequester接口的作用則完全不同,它的作用是保護FinancialReportController不過度依賴於Interactor的內部細節。如果沒有這個接口,則Controller將會傳遞性地依賴於 Financialentities。
這種傳遞性依賴違反了「軟件系統不應該依賴其不直接使用的組件」這一基本原則。之後,我們會在討論接口隔離原則和共同復用原則的時候再次提到這一點。
所以,雖然我們的首要目的是為了讓 Interactor屏蔽掉發生在 Controller上的修改,但也需要通過隱藏 Interactor內部細節的方法來讓其屏蔽掉來自Controller的依賴。
本章小結
OCP是我們進行系統架構設計的主導原則,其主要目標是讓系統易於擴展,同時限制其每次被修改所影響的範圍。實現方式是通過將系統劃分為一系列組件,並且將這些組件間的依賴關係按層次結構進行組織,使得高階組件不會因低階組件被修改而受到影響。
LSP:里氏替換原則
1988年, Barbara liskov在描述如何定義子類型時寫下了這樣一段話:
這裡需要的是一種可替換性:如果對於每個類型是S的對象o1都存在一個類型為T的對象o2,能使操作T類型的程序P在用o2替換o1時行為保持不變,我們就可以將S稱為T的子類型。
為了讓讀者理解這段話中所體現的設計理念,也就是里氏替換原則(LSP),我們可以來看幾個例子。
繼承的使用指導
假設我們有一個 License類,其結構如下圖所示。該類中有一個名為 callee()的方法,該方法將由Billing應用程序來調用。而 License類有兩個「子類型」 :PersonalLicense與 Businesslicense,這兩個類會用不同的算法來計算授權費用。
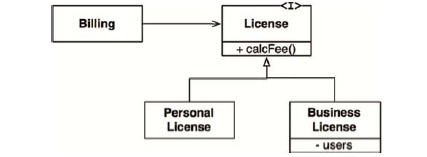
上述設計是符合LSP原則的,因為 Billing應用程序的行為並不依賴於其使用的任何一個衍生類。也就是說,這兩個衍生類的對象都是可以用來替換License類對象的。
正方形/長方形問題
正方形/長方形問題是一個著名(或者說臭名遠揚)的違反LSP的設計案例。
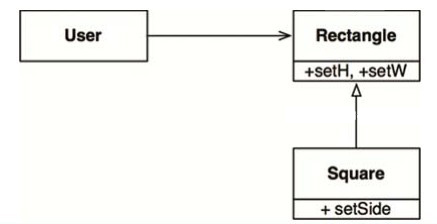
在這個案例中, Square類並不是 Rectangle類的子類型,因為 Rectangle類的高和寬可以分別修改,而 Square類的高和寬則必須一同修改。由於User類始終認為自己在操作 Rectangle類,因此會帶來一些混淆。例如在下面的代碼中:
Rectangle r
r.setw(5)
r.setH(2)
assert( rarea()==10)
很顯然,如果上述代碼在…處返回的是 Square類,則最後的這個 assert是不會成立的。
如果想要防範這種違反LSP的行為,唯一的辦法就是在User類中增加用於區分 Rectangle和 Square的檢測邏輯(例如增加if語句)。但這樣一來,User類的行為又將依賴於它所使用的類,這兩個類就不能互相替換了。
LSP與軟件架構
在面向對象這場編程革命興起的早期,我們的普遍認知正如上文所說,認為LSP只不過是指導如何使用繼承關係的一種方法,然而隨着時間的推移,LSP逐漸演變成了一種更廣泛的、指導接口與其實現方式的設計原則。
這裡提到的接口可以有多種形式——可以是Java風格的接口,具有多個實現類;也可以像Ruby一樣,幾個類共用一樣的方法簽名,甚至可以是幾個服務響應同一個REST接口。
LSP適用於上述所有的應用場景,因為這些場景中的用戶都依賴於一種接口,並且都期待實現該接口的類之間能具有可替換性。
想要從軟件架構的角度來理解LSP的意義,最好的辦法還是來看幾個反面案例。
違反LSP的案例
假設我們現在正在構建一個提供的士調度服務的系統。在該系統中,用戶可以通過訪問我們的網站,從多個的士公司內尋找最適合自己的的士。當用戶選定車子時,該系統會通過調用 restful服務接口來調度這輛車。
接下來,我們再假設該 restful調度服務接口的UR被存儲在司機數據庫中。一旦該系統選中了最合適的的士司機,它就會從司機數據庫的記錄中讀取相應的URI信息,並通過調用這個URI來調度汽車。
也就是說,如果司機Bob的記錄中包含如下調度URI:
purplecab. com/driver/ Bob
那麼,我們的系統就會將調度信息附加在這個URI上,並發送這樣一個PUT請求:
purplecab. com/driver/Bob
/pickup Address/24 Maple St
/pickupTime/153
/destination/ORD
很顯然,這意味着所有參與該調度服務的公司都必須遵守同樣的REST接口,它們必須用同樣的方式處理 pickupAddress、 pickup Time和 destination字段。
接下來,我們再假設Acme的士公司現在招聘的程序員由於沒有仔細閱讀上述接口定義,結果將destination字段縮寫成了dest。而Acme又是本地最大的的士公司,另外, Acme CEO的前妻不巧還是我們CEO的新歡……你懂的!這會對系統的架構造成什麼影響呢?
顯然,我們需要為系統増加一類特殊用例,以應對Acme司機的調度請求。而這必須要用另外一套規則來構建。
最簡單的做法當然是增加一條i語句:
if(driver.getDispatchUri().startsWith(「acme.com))...
然而很明顯,任何一個稱職的軟件架構師都不會允許這樣一條語句出現在自己的系統中。因為直接將「acme「這樣的字串寫入代碼會留下各種各樣神奇又可怕的錯誤隱患,甚至會導致安全問題。
例如,Acme也許會變得更加成功,最終收購了Purple的士公司。然後,它們在保留了各自名字的同時卻統一了彼此的計算機系統。在這種情況下,系統中難道還要再增加一條「 purple「的特例嗎?
軟件架構師應該創建一個調度請求創建組件,並讓該組件使用一個配置數據庫來保存URI組裝格式,這樣的方式可以保護系統不受外界因素變化的影響。例如其配置信息可以如下

但這樣一來,軟件架構師就需要通過増加一個複雜的組件來應對並不完全能實現互相替換的 restful服務接口。
本章小結
LSP可以且應該被應用於軟件架構層面,因為一旦違背了可替換性,該系統架構就不得不為此増添大量複雜的應對機制。
ISP:接口隔離原則
「接口隔離原則」這個名字來自下圖所示的這種軟件結構。

在圖中所描繪的應用中,有多個用戶需要操作OPS類。現在,我們假設這裡的User1隻需要使用op1,User2隻需要使用op2,User3隻需要使用op3。
在這種情況下,如果OPS類是用Java編程語言編寫的,那麼很明顯,User1雖然不需要調用op2、op3,但在源代碼層次上也與它們形成依賴關係。
這種依賴意味着我們對OPS代碼中op2所做的任何修改,即使不會影響到User1的功能,也會導致它需要被重新編譯和部署。
這個問題可以通過將不同的操作隔離成接口來解決,具體如下圖所示。
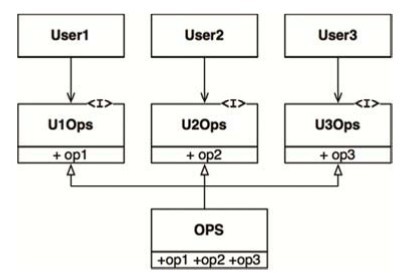
同樣,我們也假設這個例子是用Java這種靜態類型語言來實現的,那麼現在User1的源代碼會依賴於U1Ops和op1,但不會依賴於OPS。這樣一來,我們之後對OPS做的修改只要不影響到User1的功能,就不需要重新編譯和部署User1了。
ISP與編程語言
很明顯,上述例子很大程度上也依賴於我們所採用的編程語言。對於Java這樣的靜態類型語言來說,它們需要程序員顯式地 Import、use或者 include其實現功能所需要的源代碼。而正是這些語句帶來了源代碼之間的依賴關係,這也就導致了某些模塊需要被重新編譯和重新部署。
而對於Ruby和 Python這樣的動態類型語言來說,源代碼中就不存在這樣的聲明,它們所用對象的類型會在運行時被推演出來,所以也就不存在強制重新編譯和重新部署的必要性。這就是動態類型語言要比靜態類型語言更靈活、耦合度更松的原因。
當然,如果僅僅就這樣說的話,讀者可能會誤以為ISP只是一個與編程語言的選擇緊密相關的設計原則而非軟件架構問題,這就錯了。
ISP與軟件架構
回顧一下ISP最初的成因:在一般情況下,任何層次的軟件設計如果依賴於不需要的東西,都會是有害的。從源代碼層次來說,這樣的依賴關係會導致不必要的重新編譯和重新部署,對更高層次的軟件架構設計來說,問題也是類似的。
例如,我們假設某位軟件架構師在設計系統S時,想要在該系統中引入某個框架F。這時候,假設框架F的作者又將其捆綁在一個特定的數據庫D上,那麼就形成了S依賴於F,F又依賴於D的關係。
在這種情況下,如果D中包含了F不需要的功能,那麼這些功能同樣也會是S不需要的。而我們對D中這些功能的修改將會導致F需要被重新部署,後者又會導致S的重新部署。更糟糕的是,D中一個無關功能的錯誤也可能會導致F和S運行出錯。
本章小結
本章所討論的設計原則告訴我們:任何層次的軟件設計如果依賴了它並不需要的東西,就會帶來意料之外的麻煩。
DIP:依賴反轉原則
依賴反轉原則(DIP)主要想告訴我們的是,如果想要設計一個靈活的系統,在源代碼層次的依賴關係中就應該多引用抽象類型,而非具體實現。
也就是說,在Java這類靜態類型的編程語言中,在使用use、 Import、 include這些語句時應該只引用那些包含接口、抽象類或者其他抽象類型聲明的源文件,不應該引用任何具體實現。
同樣的,在Ruby、 Python這類動態類型的編程語言中,我們也不應該在源代碼層次上引用包含具體實現的模塊。當然,在這類語言中,事實上很難清晰界定某個模塊是否屬於「具體實現′。
顯而易見,把這條設計原則當成金科玉律來加以嚴格執行是不現實的,因為軟件系統在實際構造中不可避免地需要依賴到一些具體實現。例如,Java中的 String類就是這樣一個具體實現,我們將其強迫轉化為抽象類是不現實的,而在源代碼層次上也無法避免對 java.lang.String的依賴,並且也不應該嘗試去避免。
但 String類本身是非常穩定的,因為這個類被修改的情況是非常罕見的,而且可修改的內容也受到嚴格的控制,所以程序員和軟件架構師完全不必擔心String類上會發生經常性的或意料之外的修改。
同理,在應用DIP時,我們也不必考慮穩定的操作系統或者平台設施,因為這些系統接口很少會有變動。
我們主要應該關注的是軟件系統內部那些會經常變動的( volatile)具體實現模塊,這些模塊是不停開發的,也就會經常出現變更。
穩定的抽象層
我們每次修改抽象接口的時候,一定也會去修改對應的具體實現。但反過來,當我們修改具體實現時,卻很少需要去修改相應的抽象接口。所以我們可以認為接口比實現更穩定。
的確,優秀的軟件設計師和架枃師會花費很大精力來設計接口,以減少未來對其進行改動。畢竟爭取在不修改接口的情況下為軟件增加新的功能是軟件設計的基礎常識。
也就是說,如果想要在軟件架構設計上追求穩定,就必須多使用穩定的抽象接口,少依賴多變的具體實現。下面,我們將該設計原則歸結為以下幾條具體的編碼守則:
應在代碼中多使用抽象接口,盡量避免使用那些多變的具體實現類。這條守則適用於所有編程語言無論靜態類型語言還是動態類型語言。同時,對象的創建過程也應該受到嚴格限制,對此,我們通常會選擇用抽象工廠( abstract factory)這個設計模。
不要在具體實現類上創建衍生類。上一條守則雖然也隱含了這層意思,但它還是值得被單獨拿出來做次詳細聲明。在靜態類型的編程語言中,繼承關係是所有一切源代碼依賴關係中最強的、最難被修改的,所以我們對繼承的使用應該格外小心。即使是在稍微便於修改的動態類型語言中,這條守則也應該被認真考慮。
不要覆蓋( override)包含具體實現的函數。調用包含具體實現的函數通常就意味着引入了源代碼級別的依賴。即使覆蓋了這些函數,我們也無法消除這其中的依賴——這些函數繼承了那些依賴關係在這裡,控制依賴關係的唯一辦法,就是創建一個抽象函數,然後再為該函數提供多種具體實現。
應避免在代碼中寫入與任何具體實現相關的名字或者是其他容易變動的事物的名字。這基本上是DIP原則的另外一個表達方式。
工廠模式
如果想要遵守上述編碼守則,我們就必須要對那些易變對象的創建過程做一些特殊處理,這樣的謹慎是很有必要的,因為基本在所有的編程語言中,創建對象的操作都免不了需要在源代碼層次上依賴對象的具體實現。
在大部分面向對象編程語言中,人們都會選擇用抽象工廠模式來解決這個源代碼依賴的問題。
下面,我們通過下圖來描述一下該設計模式的結構。如你所見, Application類是通過 Service接口來使用 Concretelmp類的。然而, Application類還是必須要構造 Concretelmpl類實例。於是,為了避免在源代碼層次上引入對 Concretelmpl類具體實現的依賴,我們現在讓 Application類去調用ServiceFactory接口的 makeSvc方法。這個方法就由 ServiceFactorylmpl類來具體提供,它是ServiceFactoryl的一個衍生類。該方法的具體實現就是初始化一個 Concretelmpl類的實例,並且將其以 Service類型返回。

中間的那條曲線代表了軟件架構中的抽象層與具體實現層的邊界。在這裡,所有跨越這條邊界源代碼級別的依賴關係都應該是單向的,即具體實現層依賴抽象層。
這條曲線將整個系統劃分為兩部分組件:抽象接口與其具體實現。抽象接口組件中包含了應用的所有高階業務規則,而具體實現組件中則包括了所有這些業務規則所需要做的具體操作及其相關的細節信息。
請注意,這裡的控制流跨越架構邊界的方向與源代碼依賴關係跨越該邊界的方向正好相反,源代碼依賴方向永遠是控制流方向的反轉——這就是DIP被稱為依賴反轉原則的原因。
具體實現組件
在上圖中,具體實現組件的內部僅有一條依賴關係,這條關係其實是違反DIP的。這種情況很常見,我們在軟件系統中並不可能完全消除違反DIP的情況。通常只需要把它們集中於少部分的具體實現組件中,將其與系統的其他部分隔離即可。
絕大部分系統中都至少存在一個具體實現組件我們一般稱之為main組件,因為它們通常是main函數所在之處。在圖中,main函數應該負責創建 ServiceFactorylmp實例,並將其賦值給類型為 ServiceFactory的全局變量,以便讓 Application類通過這個全局變量來進行相關調用。
本章小結
在系統架構圖中,DIP通常是最顯而易見的組織原則。我們把圖中的那條曲線稱為架構邊界,而跨越邊界的、朝向抽象層的單向依賴關係則會成為一個設計守則——依賴守則。


