消息隊列雜談
本篇文章聊聊消息隊列相關的東西,內容局限於我們為什麼要用消息隊列,消息隊列究竟解決了什麼問題,消息隊列的選型。
為了更容易的理解消息隊列,我們首先通過一個開發場景來切入。
不使用消息隊列的場景
首先,我們假設A同學負責訂單系統的開發,B、C同學負責開發積分系統、倉儲系統。我們知道,在一般的購物電商平台上,我們下單完成後,積分系統會給下單的用戶增加積分,然後倉儲系統會按照下單時填寫的信息,發出用戶購買的商品。
那問題來了,積分系統、倉儲系統如何感知到用戶的下單操作?
你可能會說,當然是訂單系統在創建完訂單之後調用積分系統、倉儲系統的接口了
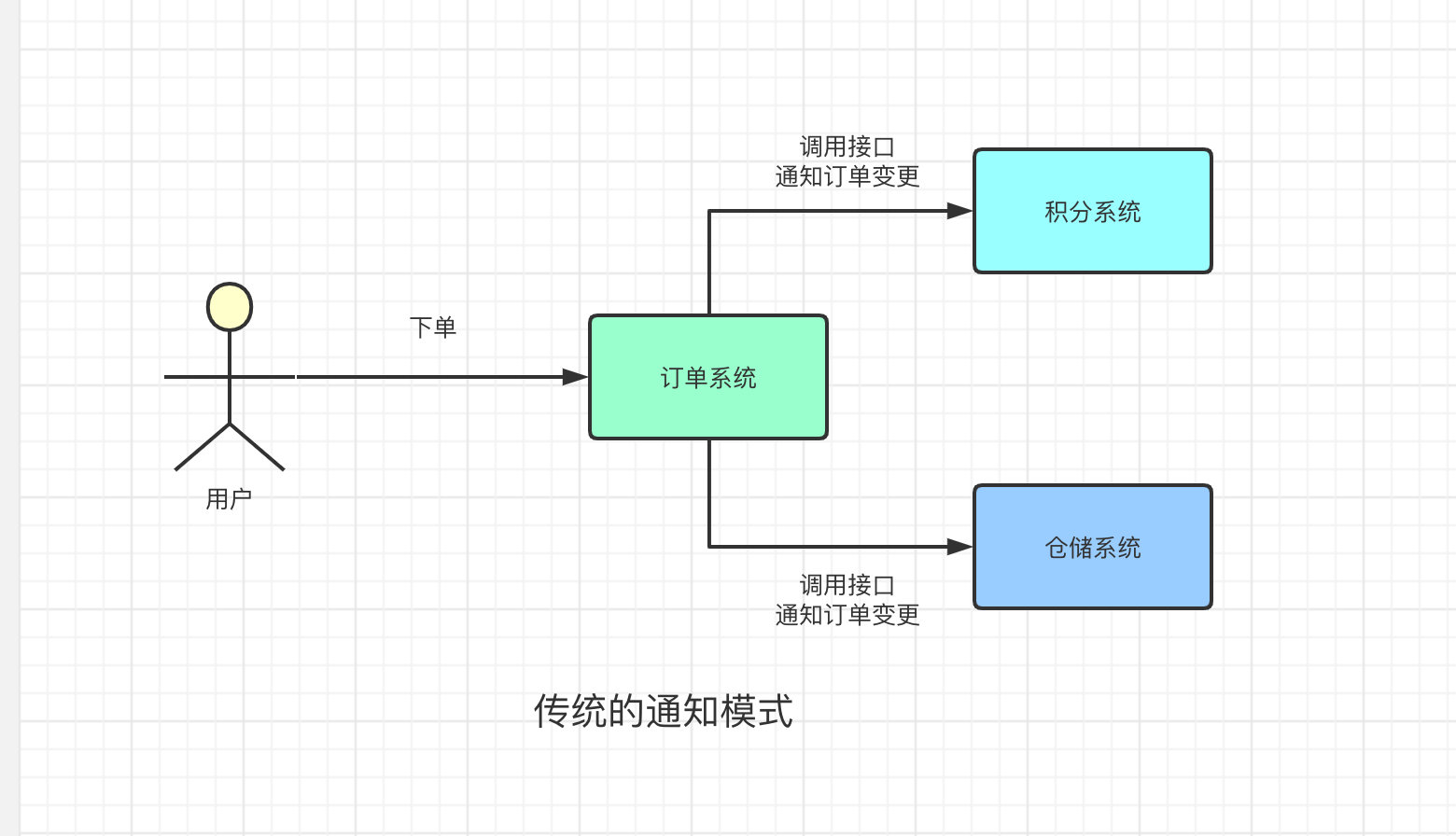
OK,直接調用接口的方式在目前來看沒有什麼問題。於是B、C同學就找到A同學,說讓他在訂單完成後,調用一下他們的接口來通知一下積分系統和倉儲系統,來給用戶增加積分、發貨。A同學想着,就這兩個系統,應該還好,OK我給你加了。
但是隨着系統的迭代,需要感知訂單操作的系統也越來越多,從之前的積分系統、倉儲系統2個系統,擴充到了5個。每個系統的負責同學都需要去找A同學,讓他人肉的把對應系統的通知接口加上。然後就因為加了這一個接口,又需要把訂單重新發佈一遍。
這對A同學來說實際上是很痛苦的一件事情,因為A同學有自己的任務、排期,一有新系統就需要去添加通知接口,發佈服務,會打亂A的開發計劃,增加開發量。同時還需要去梳理在開發期間,新增的代碼到底能不能夠上線。一旦不能上線,但是又沒有檢查到,上線就直接炸了。

而且,如果5個系統如果有哪個需要額外的字段,或者是更新了接口什麼的,都需要麻煩A同學修改。5個系統就這樣跟A系統強耦合在了一起。
除此之外,整個創建訂單的調用鏈因為同步調用這5個系統的通知接口而加長,這減慢了接口的響應速度,降低了用戶側的購物、下單體驗。前面的至少影響的還是內部的員工,但是現在直接是影響到了用戶,明顯是不可取的方案。

可以看到,整個的調用鏈路加長了,更別提,在同步調用中,如果其餘的系統發生了錯誤,或者是調用其他系統的時候出現了網絡抖動,核心的下單流程就會被阻塞住,甚至會在下單的界面提示提示用戶出錯,整個的購物體驗又被拉低了一個檔次。更何況,在實際的業務中,調用鏈比這個長的多。
可能有人會說了, 這不就是個同步調用問題嘛?訂單系統的核心邏輯,我還是採用同步來處理,但是後續的通知我採用異步的方式,用線程池去處理,這樣調用鏈路不就恢復正常了?

就單純對於減少鏈路來說,的確可行。但是如果某一個流程失敗了呢?難道失敗就失敗了嗎?我下單成功了不漲積分?該給我發的貨甚至沒有發貨?這合理嗎?

同時,失敗了訂單系統是不是要去處理呢?否則因為其他的系統拉垮了整個主流程,誰還來你這買東西呢?
那有什麼辦法,既能夠減少調用的鏈路,又能夠在發生錯誤的時候重試呢?歸根結底,核心思想就是像增加積分、返優惠券的流程不應該和主流程耦和在一起,更不應該影響主流程。
試想,我們能不能在訂單系統完成自己的核心邏輯之後,把訂單創建的消息放到一個隊列中去,然後訂單系統就返回給用戶下單成功的結果了。然後其他的系統從這個隊列中收到了下單成功的消息,就各自的去執行各自的操作,例如增加積分、返優惠券等等操作。
後續如果有新的系統需要感知訂單創建的消息,直接去訂閱這個隊列,消費裏面的消息就好了?這雖然跟真實的消息的隊列有些出入,但其思路是完成吻合的。
為什麼需要消息隊列
通過上面的例子,我們大致就能夠理解為什麼要引入消息隊列了,這裡簡單總結一下。
異步
對於實時性不是很高的業務,例如給用戶發送短訊、郵件通知,調用第三方的接口,都可以放到消息隊列里去。因為相對於核心訂單流程來說,短訊、郵件晚一些發送,對用戶來說影響不是很大。同時還可以提升整個鏈路的響應時間。
削峰
假設我們有服務A,是個無狀態的服務。通過橫向擴展,它可以輕鬆抗住1w的並發量,但是這N個服務實例,底層訪問的都是同一個數據庫。數據庫能抗住的並發量是有限的,如果你的機器足夠好的話,可能能夠抗住5000的並發,如果服務A的所有請求全部打向數據庫,會直接把數據打掛。

解耦
像上文舉的例子,訂單系統在創建了訂單之後需要通知其他的所有系統,這樣一來就把訂單系統和其餘的系統強耦合在了一起。後續的可維護性、擴展性都大大降低了。
而通過消息隊列來關聯所有系統,可以達到解耦的目的。

像上圖這種模式,如果後續再有新系統需要感知訂單創建的消息,只需要去消費「訂單系統」發送到MQ中的消息即可。同樣,訂單系統如果需要感知其餘系統的某些事件,也只是從MQ中消費即可。
通過MQ,達成服務之間的松耦合,服務內的高內聚,提升了服務的自治性。
消息隊列選型
已知的消息隊列有Kafka、RocketMQ、RabbitMQ和ActiveMQ。但是由於ActiveMQ現在用的公司比較少了,這裡就不做討論,我們着重討論前三種。
Kafka
Kafka最初來自於LinkedIn,是用於做日誌收集的工具,採用Java和Scala開發。其實那個時候已經有ActiveMQ了,但是在當時ActiveMQ沒有辦法滿足LinkedIn的需求,於是Kafka就應運而生。
在2010年底,Kakfa的0.7.0被開源到了Github上。到了2011年,由於Kafka非常受關注,被納入了Apache Incubator,所有想要成為Apache正式項目的外部項目,都必須要經過Incubator,翻譯過來就是孵化器。旨在將一些項目孵化成完全成熟的Apache開源項目。
你也可以把它想像成一個學校,所有想要成為Apache正式開源項目的外部項目都必須要進入Incubator學習,並且拿到畢業證,才能走入社會。於是在2012年,Kafka成功從Apache Incubator畢業,正式成為Apache中的一員。
Kafka擁有很高的吞吐量,單機能夠抗下十幾w的並發,而且寫入的性能也很高,能夠達到毫秒級別。但是有優點就有缺點,能夠達到這麼高的並發的代價是,可能會出現消息的丟失。至於具體的丟失場景,我們後續會討論。
所以一般Kafka都用於大數據的日誌收集,這種日誌丟個一兩條無傷大雅。
而且Kafka的功能較為簡單,就是簡單的接收生產者的消息,消費者從Kafka消費消息。
RabbitMQ
RabbitMQ是很多公司對於ActiveMQ的替代方法,現在仍然有很多公司在使用。其優點在於能保證消息不丟失,同Kafka,天平往數據的可靠性方向傾斜必然導致其吞吐量下降。其吞吐量只能夠達到幾萬,比起Kafka的十萬吞吐來說,的確是較低的。如果遇到需要支撐特別高並發的情況,RabbitMQ可能會無法勝任。
但是RabbitMQ有比Kafka更多的高級特性,例如消息重試和死信隊列,而且寫入的延遲能夠降低到微妙級,這也是RabbitMQ一大特點。
但RabbitMQ還有一個致命的弱點,其開發語言為Erlang,現在國內精通Erlang的人不多,社區也不怎麼活躍。這也就導致可能公司內沒有人能夠去閱讀Erlang的源碼,更別說基於其源碼進行二次開發或者排查問題了。所以就存在RabbitMQ出了問題可能公司里沒人能夠兜的住,維護成本非常的高。
之所以有中小型公司還在使用,是覺得其不會面臨高並發的場景,RabbitMQ的功能已經完全夠用了。
RocketMQ
RocketMQ來自阿里,同Kakfa一樣也是從Apache Incubator出來的頂級項目,用Java語言進行開發,單機吞吐量和Kafka一樣,也是十w量級。
RocketMQ的前身是阿里的MetaQ項目,2012年在淘寶內部大量的使用,在阿里內部迭代到3.0版本之後,將MetaQ的核心功能抽離出來,就有了RocketMQ。RocketMQ整合了Kafka和RabbitMQ的優點,例如較高的吞吐量和通過參數配置能夠做到消息絕對不丟失。
其底層的設計參考了Kafka,具有低延遲、高性能、高可用的特點。不同於Kafka的單一日誌收集功能,RocketMQ被廣泛運用於訂單、交易、計算、消息推送、binlog分發等場景。
之所以能夠被運用到多種場景,這要歸功於RocketMQ提供的豐富的功能。例如延遲消息、事務消息、消息回溯、死信隊列等等。
-
延遲消息 就是不會立即消費的消息,例如某個活動開始前15分鐘提醒用戶這樣的場景 -
事務消息 其主要解決數據庫事務和MQ消息的數據一致性,例如用戶下單,先發送消息到MQ,積分增加了,但是訂單系統在發出消息之後掛了。這樣用戶並沒有下單成功,但是積分卻增加了,明顯是不符合預期的 -
消息回溯 顧名思義,就是去消費某個Topic下某段時間的歷史消息 -
死信隊列 沒有被正常消費的消息,首先會按照RocketMQ的重試機制重試,當達到了最大的重試次數之後,如果消費仍然失敗,RocketMQ不會立即丟掉這條消息,而是會把消息放入死信隊列中。放入死信隊列的消息會在3天後過期,所以需要及時的處理
消息隊列會丟消息嗎
在不使用消息隊列的場景中,我們吹了很多消息隊列的優點,但同時也提到了消息隊列可能會丟失消息,我們也可以通過參數的配置來使消息絕對不丟失。
那消息是在什麼情況下丟失的呢?消息隊列中的角色可以分為3類,分別是生產者、MQ和消費者。一條消息在整個的傳輸鏈路中需要經過如下的流程。

生產者將消息發送給MQ,MQ接收到這條消息後會將消息存儲到磁盤上,消費者來消費的時候就會把消息返給消費者。先給出結論,在這3種場景下,消息都有可能會丟失。
接下來我們一步一步來分析一下。
生產者發送消息給MQ
生產者在發送消息的過程中,由於某些意外的情況例如網絡抖動等,導致本次網絡通信失敗,消息並沒有被發送給MQ。
MQ存儲消息
當MQ接收到了來自生產者的消息之後,還沒有來得及處理,MQ就突然宕機,此時該消息也會丟失。
即使MQ開始處理消息,並且將該消息寫入了磁盤,消息仍然可能會丟失。因為現代的操作系統都會有自己的OS Cache,因為和磁盤交互是一件代價相當大的事情,所以當我們寫入文件的時候會先將數據寫入OS Cache中,然後由OS調度,根據策略觸發真正的I/O操作,將數據刷入磁盤。
而在刷入磁盤之前,MQ如果宕機,在OS Cache中的數據就會全部丟失。
消費者消費消息
當消息順利的經歷了生產者、MQ之後,消費者拉取到了這條消息,但是當其還沒來得及處理的時候,消費者突然宕機了,這條消息就丟了(當然你如果沒有提交Offset的話,重啟之後仍然可以消費到這條消息)
原來我們以為用上了消息隊列,就萬無一失了,沒想到逐步分析下來能有這麼多坑。任何一個步驟出錯都有可能導致消息丟失。那既然這樣,上文提到的可以通過參數配置來實現消息不會丟失是怎麼一回事呢?
這裡我們不去聊具體的MQ是如何實現的,我們來聊聊消息零丟失的實現思路。
消息最終一致性方案
涉及到的系統有訂單系統、MQ和積分系統,訂單系統為生產者,積分系統為消費者。
首先訂單系統發送一個訂單創建的消息給MQ,該消息的狀態為Prepare狀態,狀態為Prepare狀態的消息不會被消費者給消費到,所以可以放心的發送。
然後訂單系統開始執行自身的核心邏輯,你可能會說,訂單系統本身的邏輯執行失敗了怎麼辦?剛剛的prepare消息不就成了臟數據?實際上在訂單系統的事務失敗之後,就會觸發回滾操作,就會向MQ發送消息,將該條狀態為Prepare的數據給刪除。
訂單系統核心事務成功之後,就會發送消息給MQ,將狀態為prepare的消息更新為commit。沒錯,這就是2PC,一個保證分佈式事務數據一致性的協議。

眼尖的你可能發現了一個問題,我發送了prepare消息之後,還沒來得及執行本地事務,訂單系統就掛了怎麼辦?此時訂單系統即使重啟也不會向MQ發送刪除操作,這個prepare消息不就是一直存在MQ中了?
先給出結論,不會。
如果訂單系統發送了prepare消息給MQ之後自己就宕機了,MQ確實會存在一條不會被commit的數據。MQ為了解決這個問題,會定時輪詢所有prepare的消息,跟對應的系統溝通,這條prepare消息是要進行重試還是回滾。所以prepare消息不會一直存在於MQ中。這樣一來,就保證了消息對於生產者的DB事務和MQ中消息的數據一致性。
再來看一種更加極端的情況,假設訂單系統本地事務執行成功之後,發送了commit消息到MQ,此時MQ突然掛了。導致MQ沒有收到該commit消息,在MQ中該消息仍然處於prepare狀態,這怎麼辦?
同樣的,依賴於MQ的輪詢機制和訂單系統溝通,訂單系統會告訴MQ這個事務已經完成了,MQ就會將這條消息設置成commit,消費者就可以消費到該消息了。
接下來的流程就是消息被消費者消費了,如果消費者消費消息的時候本地事務失敗了,則會進行重試,再次嘗試消費這條消息。
好了以上就是本篇博客的全部內容了,如果你覺得這篇文章對你有幫助,還麻煩點個贊,關個注,分個享,留個言。
歡迎微信搜索關注【SH的全棧筆記】,查看更多相關文章


