JDK1.7-HashMap原理
JDK1.7 HashMap
如何在源碼上添加自己的注釋
打開jdk下載位置

解壓src文件夾,打開idea,ctrl+shift+alt+s打開項目配置
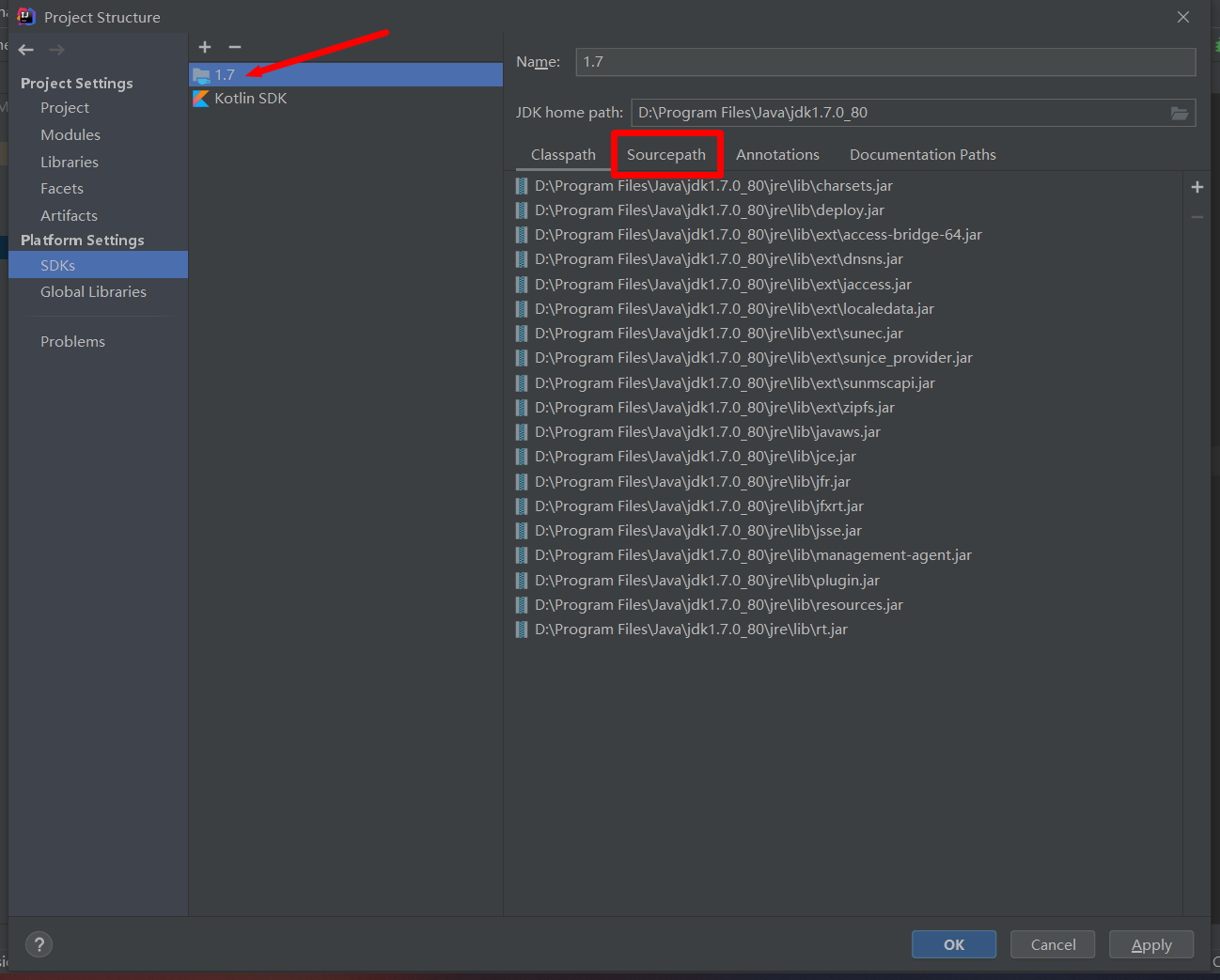
選擇jdk版本1.7,然後點擊Sourcepath
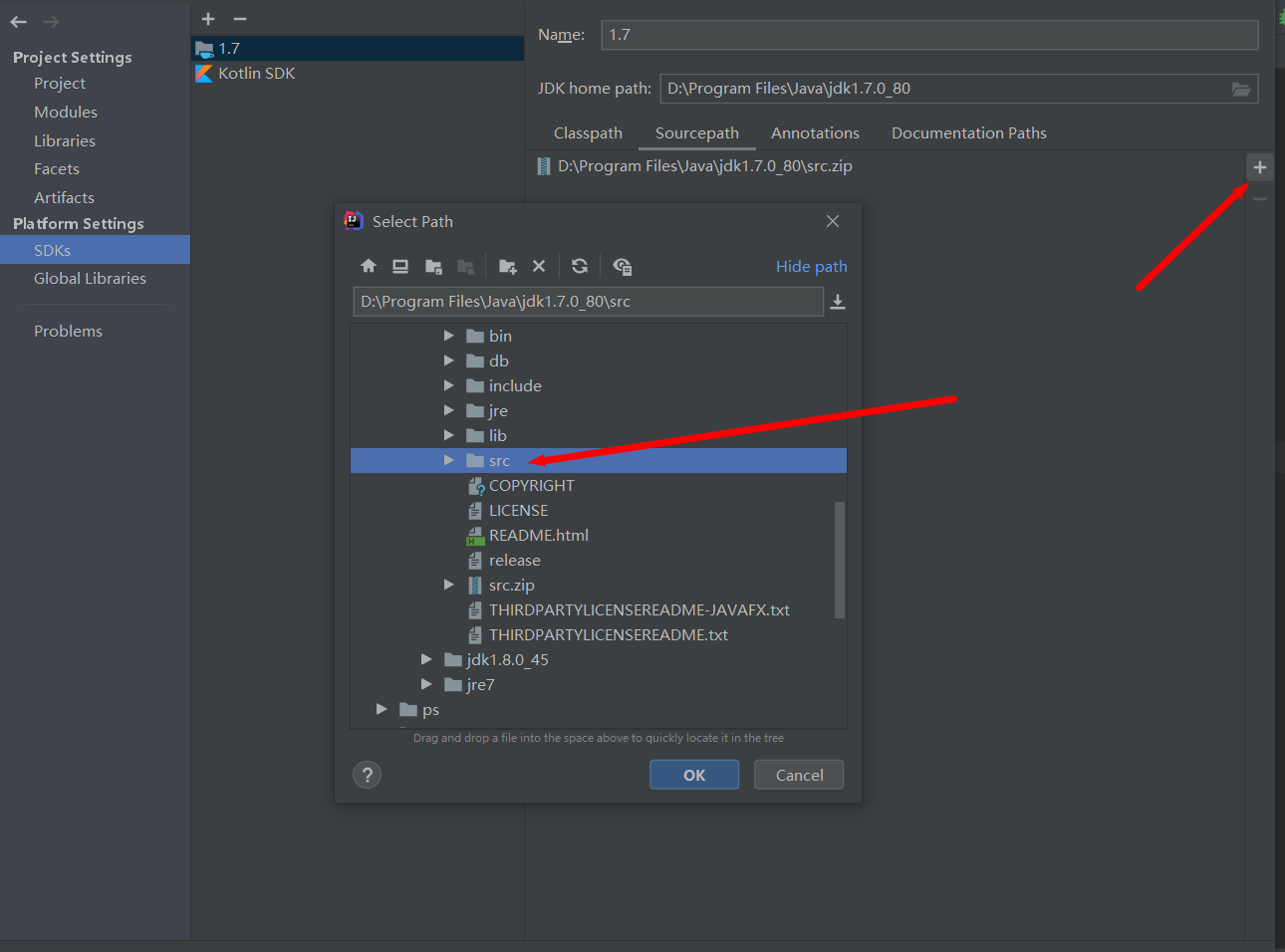
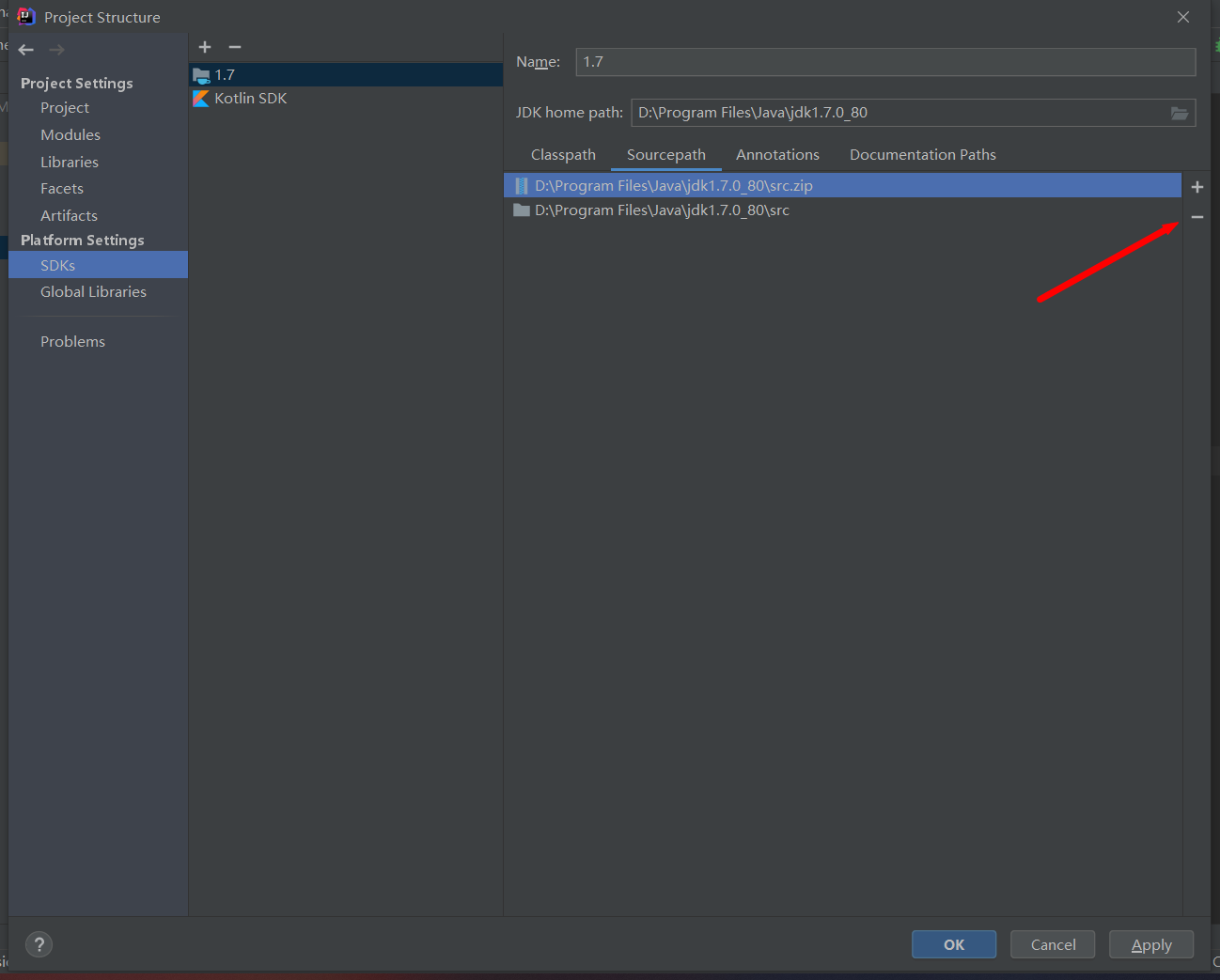
選擇剛剛解壓的src文件目錄,然後選擇src.zip的文件點擊- 號,項目中只留下剛才解壓的src文件即可
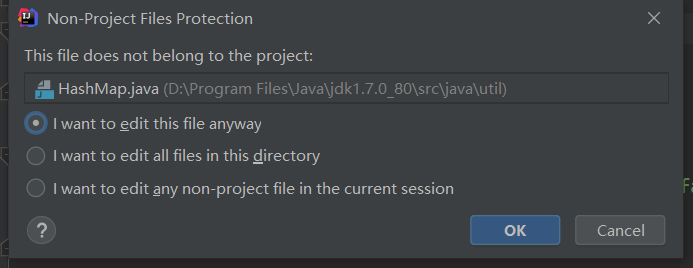
打開源碼,輸入時會出一個提示框,直接點擊ok即可,然後就可以輸入自己的注釋了
在開始前先了解一下JDK1.7的HashMap的數據結構,就算沒有研究過源碼也聽過JDK1.7中HashMap是數組加鏈表,1.8中是數組加鏈表加紅黑樹,今天我們主要研究1.7,首先數組肯定都知道,鏈表這個一聽以為是很難的東西,其實一點也不難
什麼叫鏈表呢,以java代碼形式
假設現在有一個節點,里有具體的值和下一個節點的引用
public class Node{
private int number;
private Node next;
}
當節點的next引用指向下一個Node節點,許多的節點連接起來就叫做鏈表
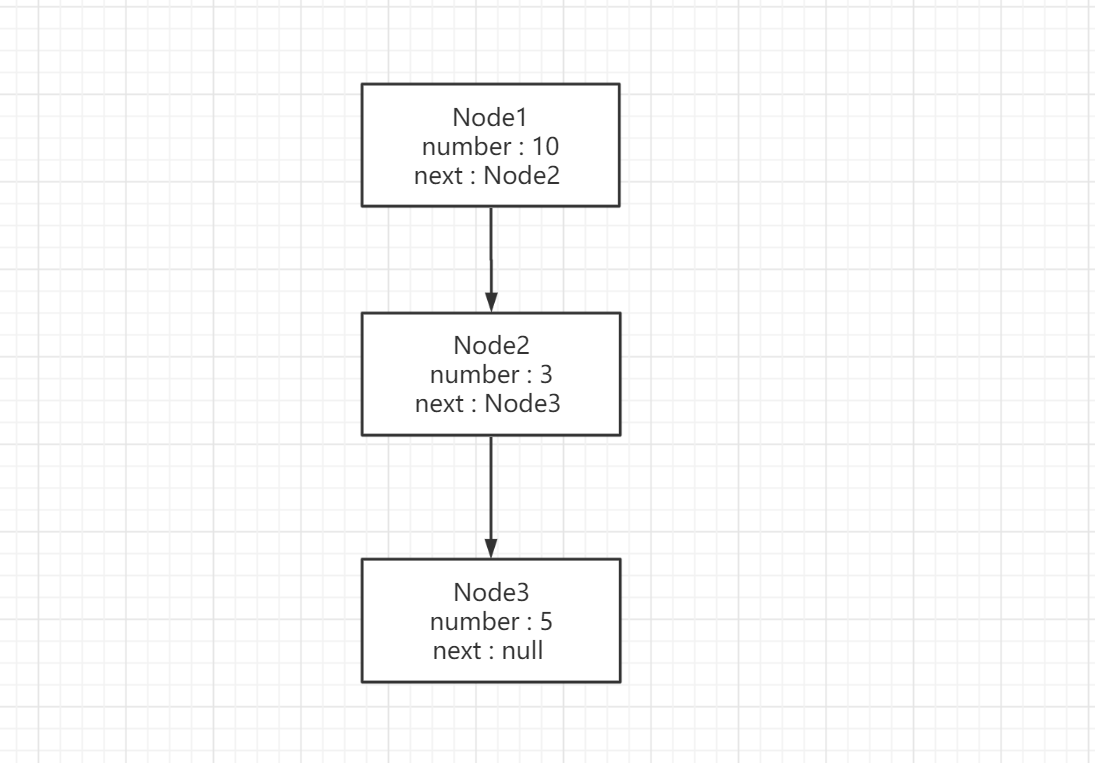
JDK1.7的數據結構就是如下圖所示
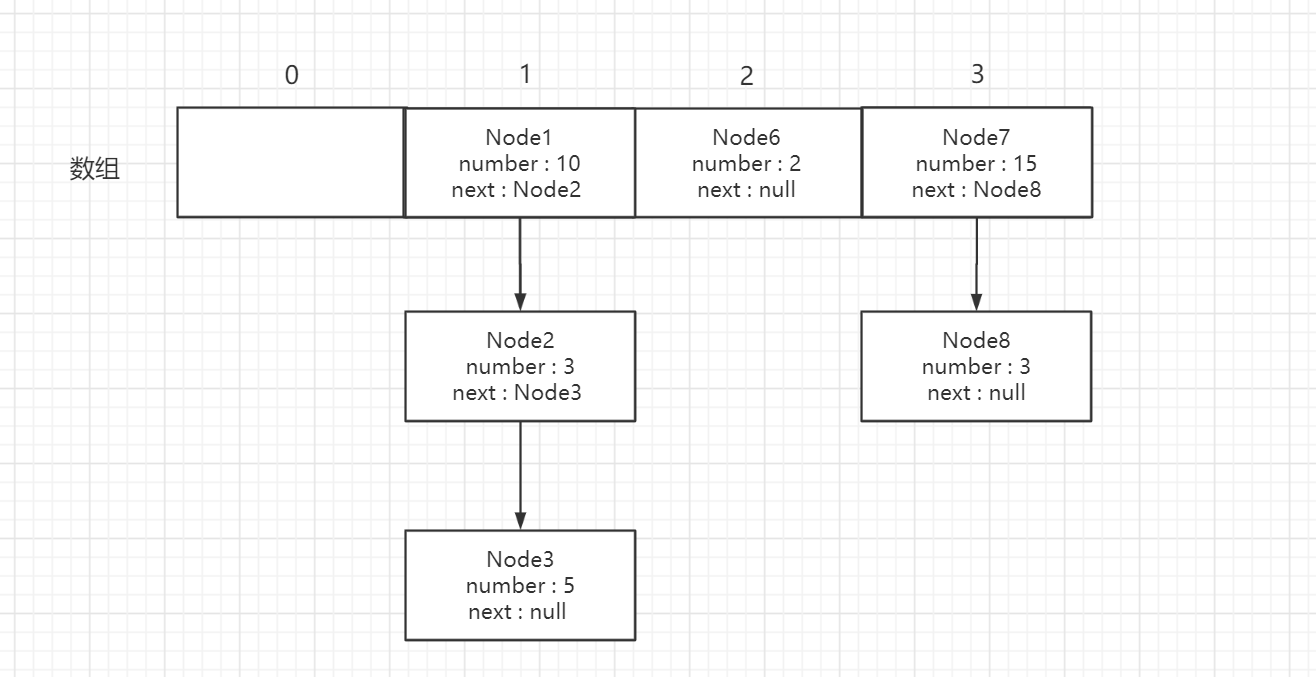
在開始前建議自己跟着打開對應的類,方法來自己看一看源碼,不然很容易就不知道在哪裡了
HashMap中的全局變量
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final Entry<?, ?>[] EMPTY_TABLE = {};
transient Entry<K, V>[] table = (Entry<K, V>[]) EMPTY_TABLE;
transient int size;
int threshold;
final float loadFactor;
transient int modCount;
我們來看一下全局變量,簡單描述一下它們的作用
DEFAULT_INITIAL_CAPACITY
默認的初始容量,而大小使用了一個左移運算符,怎麼來看它的值呢?java中所有的位運算都是在二進制的情況下進行的
首先1的二進制是 0000 0001 而<< 4 符號的意思是將所有的數字往左邊移動4位,移出來的位置用0替換
也就是 0001 0000 轉換為10進制就是16,也就是HashMap的默認容量
MAXIMUM_CAPACITY
最大容量,也是使用位運算符,1<<30 轉換為10進制就是1073741824
DEFAULT_LOAD_FACTOR
默認的負載因子,默認為0.75f,現在可能不太理解,先有個印象即可
Entry[] EMPTY_TABLE
初始化的一個空數組
Entry<K, V>[] table = (Entry<K, V>[]) EMPTY_TABLE
真正存儲數據的數組
size
存儲元素的個數,map.size()方法就是直接返回這個變量
public int size() {
return size;
}
threshold
臨界值,當容量到達這個容量是進行判斷是否擴容,而這個臨界值計算公式就是,容量大小乘以負載因子,如果初始化沒有設置map的大小和負載因子的話,默認就是16*0.75=12
loadFactor
如果創建HashMap時設置了負載因子,那麼會賦值給這個變量,沒有特殊需求的話一般不需要設置這個值,太大導致鏈表過長,影響get方法效率,太小會導致經常進行擴容浪費性能
modCount
HashMap的結構被修改的次數,用於迭代器
構造方法
首先來看無參構造
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
調用了重載的構造,傳入的就是默認大小(16)和默認的負載因子大小(0.75f)
那麼我們來看有參構造
public HashMap(int initialCapacity, float loadFactor) {
//初始容量不能小於0
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//初始容量是否大於最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
//如果大於最大容量,則將容量設置為最大容量
initialCapacity = MAXIMUM_CAPACITY;
//如果負載係數小於0或者不是一個數字拋出異常
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// 設置負載因子,臨界值此時為容量大小,後面第一次put時由inflateTable(int toSize)方法計算設置
this.loadFactor = loadFactor;
threshold = initialCapacity;
//空方法,由其他實現類實現
init();
}
put方法
擴容就是在put方法中實現的,來看代碼
public V put(K key, V value) {
// 如果table引用指向成員變量EMPTY_TABLE,那麼初始化HashMap(設置容量、臨界值,新的Entry數組引用)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// HashMap 支持key為null
if (key == null)
//key為null單獨調用存儲空key的方法
return putForNullKey(value);
//計算key的hash值
int hash = hash(key);
// 根據hash值和表當前的長度,得到一個在數組中的下標,重點關注一下indexFor方法的實現。
// 該算法主要返回一個索引,0 到 table.length-1的數組下標。
int i = indexFor(hash, table.length);
//接下來,找到 table[i]處,以及該處的數據鏈表,看是否存在相同的key;判斷key相同,
// 首先判斷hash值是否相等,然後再 判斷key的equals方法是否相等
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
//首先判斷hash,如果對象的hashCode方法沒有被重寫,那麼hash值相等兩個對象一定相等
//並且判斷如果key相等或者key的值相等那麼覆蓋並返回舊的value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//進行添加操作
addEntry(hash, key, value, i);
return null;
}
我們來一步一步看,首先來看第一個判斷
// 如果table引用指向成員變量EMPTY_TABLE,那麼初始化HashMap(設置容量、臨界值,新的Entry數組引用)
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
如果這個判斷成立,也就是說這個數組還沒有進行過初始化,則調用inflateTable(threshold);方法來進行初始化,傳入的參數為臨界值,我們來看inflateTable方法
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
// 首先計算容量, toSize 容量為 threshold,在構造方法中,threshold默認等於初始容量,也就是16
int capacity = roundUpToPowerOf2(toSize);
// 然後重新計算 threshold的值,默認為 capacity * loadFactor
//Math.min 方法用於返回兩個參數中的最小值
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
//初始化數組 容量為 capacity
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
roundUpToPowerOf2方法,簡單來看一下這個方法的作用
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
//判斷參數的值是否大於最大容量
return number >= MAXIMUM_CAPACITY
//如果大於將返回最大容量
? MAXIMUM_CAPACITY
/**
* 如果小於1返回1
* highestOneBit方法可以簡單理解為返回小於等於輸入的數字最近的2的次方數
* 例如
* 2的1次方 2
* 2的2次方 4
* 2的3次方 8
* 2的4次方 16
* 2的5次方 32
* 小於15,並且距離15最近的2的次方數 : 8
* 小於16,並且距離15最近的2的次方數 : 16
* 小於17,並且距離15最近的2的次方數 : 16
*/
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
具體方法實現就不繼續研究了,不是這篇的主題,繼續來看inflateTable方法中內容
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
這一步操作是重新計算threshold的值,也就是臨界值,通過計算出的容量大小乘以負載因子大小來算出臨界值的大小
Math.min方法是判斷兩個值大小,返回小的那個,如果參數具有相同的值,則結果為相同的值。如果任一值為NaN,則結果為NaN
之後將初始化一個Entry類型的數組賦值給table
//初始化數組 容量為 capacity
table = new Entry[capacity];
那麼我們現在來看一下這個Entry類
static class Entry<K, V> implements Map.Entry<K, V> {
final K key;
V value;
Entry<K, V> next;
int hash;
}
那麼和開頭舉的例子Node基本一樣的思路,在類中單獨定義一個用來存儲下一個節點的變量next
回到put方法,來看下一個判斷
// HashMap 支持key為null
if (key == null)
//key為null單獨調用存儲空key的方法
return putForNullKey(value);
我們來看一下這個putForNullKey方法
private V putForNullKey(V value) {
//獲取下標為0的Entry節點
for (Entry<K, V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
//空方法
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
在HashMap中,key為null的entry會存儲在下標0的位置,上面進行覆蓋操作,來看addEntry方法
void addEntry(int hash, K key, V value, int bucketIndex) {
/* JDK1.7以後的擴容條件;size大於等於threshold,並且新添加元素所在的索引值不等為空
也就是即使當size達到或超過threshold,新增加元素,只要不會引起hash衝突則不擴容;
JDK1.8去掉了為null的判斷
*/
if ((size >= threshold) && (null != table[bucketIndex])) {
//將大小擴容到原來的兩倍
resize(2 * table.length);
//如果key為null,將放到index為0的位置,否則進行取hash的操作
hash = (null != key) ? hash(key) : 0;
//根據獲取的hash值進行獲取下標
bucketIndex = indexFor(hash, table.length);
}
//創建entry
createEntry(hash, key, value, bucketIndex);
}
來看擴容resize()方法,傳入的是2倍的舊數組的長度
void resize(int newCapacity) {
//將舊table賦值給oldTable
Entry[] oldTable = table;
//獲取舊table長度
int oldCapacity = oldTable.length;
//如果長度已經等於最大限制設置為Integer的最大值
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
//創建新table,長度為參數為傳入的參數newCapacity
Entry[] newTable = new Entry[newCapacity];
//該方法將oldTable的數據複製到了newTable
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//將新擴容的table改為當前hashmap的存儲table
table = newTable;
//重新計算閾值
threshold = (int) Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
在擴容方法中主要關注將數據轉移的transfer方法
void transfer(Entry[] newTable, boolean rehash) {
//獲取新創建的table長度
int newCapacity = newTable.length;
//遍歷舊table
for (Entry<K, V> e : table) {
/*代碼第一次判斷如果當前下標entry是否為空,
如果為空則切換到下一個Entry節點
如果不為空,第二次就是判斷當前下標的entry是否形成鏈表
如果形成鏈表將一直判斷是否有下一個節點,當把該下標鏈表遍歷完畢後,
然後切換到下一個entry節點進行相同的操作
* */
while (null != e) {
//獲取下一個entry
Entry<K, V> next = e.next;
if (rehash) {
/**
* 判斷e.key是否為null,如果為null將e.hash賦值為0
* 否則調用hash()方法進行計算hash
*/
e.hash = null == e.key ? 0 : hash(e.key);
}
//通過當前遍歷舊錶的entry的hash值和新table的長度來獲取在新表的下標位置
int i = indexFor(e.hash, newCapacity);
/*
* jdk1.7是進行頭插法,也就是不需要知道當前下標位置是否存在Entry
* 只需要將舊錶中Entry節點,通過計算出下標位置
* 在新添加的Entry中直接將當前下標元素賦值給next屬性,然後新添加的節點賦值給當前下標
*/
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
其中有幾個需要關注的方法
//hash()======這個方法簡單理解為來通過key來計算hash,在get時通過hash可以確保是同一個entry對象
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded & ~
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
//indexFor()===========
/**
這裡使用&於運算符,兩個相同為1返回1,否則返回0,例如
0010 1101
1010 1011
結果 0010 1001
*/
static int indexFor(int h, int length) {
return h & (length - 1);
}
我們現在回到resize擴容方法,這個方法中最主要的就是這個將舊數組中數據複製到新數組中這個transfer()方法了,其他的操作上面都有注釋,對應着看應該可以看懂
這裡再主要說一下indexFor方法,在初始化HashMap時為什麼在設置初始大小的時候必須為2的倍數
下面以HashMap初始化大小為16為例
首先&運算符兩都為1才為1,否則為0
假設hash值為….1010 1010 而現在hashmap的長度為16,即(16-1)=15
hash:1010 1010
15: 0000 1111
因為15的低四位為1,也就是說通過&位運算符能對結果造成影響的只有低四位的四個1,其他高為都為0
這也是hash()方法的用處盡量讓其他位參與hash運算,達到更加分散的hash值
假設初始大小為單數,例如15,那麼通過(length - 1);,結果為14,14的二進制為
0000 1110
那麼和計算出的hash進行&運算能對結果進行影響的位數會減少1位,這還是好的情況,如果傳入的初始大小為17那麼會怎樣?
17通過length-1的操作為16,16的二進制為0001 0000,那麼再和hash值進行&的操作
hash: 1010 1010
16: 0001 0000
只有兩種情況,0000 0000 和0001 0000 ,那麼設置的hashmap的大小將毫無作用,
只會在0000 0000 和0001 0000 的位置進行put操作,而0000 0000 為0下標,用來添加null的key那麼添加的數據將會全部添加 到16的位置!
那我們回到addEntry()方法中
void addEntry(int hash, K key, V value, int bucketIndex) {
/* JDK1.7以後的擴容條件;size大於等於threshold,並且新添加元素所在的索引值不等為空
也就是當size達到或超過threshold,新增加元素,只要不會引起hash衝突則不擴容;
JDK1.8去掉了為null的判斷
*/
if ((size >= threshold) && (null != table[bucketIndex])) {
//將大小擴容到原來的兩倍
resize(2 * table.length);
//如果key為null,將放到index為0的位置,否則進行取hash的操作
hash = (null != key) ? hash(key) : 0;
//根據獲取的hash值進行獲取下標
bucketIndex = indexFor(hash, table.length);
}
//創建entry
createEntry(hash, key, value, bucketIndex);
}
resize()方法下面取hash操作的hash()方法和獲取下標的indexFor方法都已經在上面寫過,這裡就不再贅述
接下來主要來看createEntry方法
void createEntry(int hash, K key, V value, int bucketIndex) {
//先獲取當前下標entry節點,也可能為null
Entry<K, V> e = table[bucketIndex];
//如果有entry節點,那麼在添加新的entry時將會形成鏈表
table[bucketIndex] = new Entry<>(hash, key, value, e);
//將hashmap的大小加1
size++;
}
因為hash值,所在下標位置都已經獲取過了,所以方法傳入參數直接使用
到這裡put方法中putForNullKey()添加null key的方法就完成了,我們返回put方法繼續
//put方法,省略一些剛剛寫過的方法
int hash = hash(key);
int i = indexFor(hash, table.length);
//接下來,找到 table[i]處,以及該處的數據鏈表,看是否存在相同的key;判斷key相同,
// 首先判斷hash值是否相等,然後再 判斷key的equals方法是否相等
for (Entry<K, V> e = table[i]; e != null; e = e.next) {
Object k;
//首先判斷hash,如果對象的hashCode方法沒有被重寫,那麼hash值相等兩個對象一定相等
//並且判斷如果key相等或者key的值相等那麼覆蓋並返回舊的value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//進行添加操作
addEntry(hash, key, value, i);
return null;
最上面hash()和indexFor()方法上面寫過,不再贅述,中間的判斷覆蓋參考注釋應該可以理解,而下面的addEntry方法上面也寫過
get方法
如果理解了put方法後,get方法會相對簡單很多
public V get(Object key) {
//判斷如果key等於null的話,直接調用得到nullkey的方法
if (key == null)
return getForNullKey();
//通過getEntry方法的到entry節點
Entry<K, V> entry = getEntry(key);
//判斷如果為null返回null,否則返回entry的value
return null == entry ? null : entry.getValue();
}
首先來看key為null的情況
private V getForNullKey() {
//如果hashmap的大小為0返回null
if (size == 0) {
return null;
}
/**
開始研究時有個問題困擾着我,寫博客時突然明白了,
問題就是既然已知key為null的entry都會被放入下標0的位置,為什麼還要循環,直接獲取0下標的entry覆蓋不行嗎
然後我在寫indexFor方法時想到,不僅僅null的key下標為0,如果一個hash算法算完後通過indexFor方法
算出的下標正好是0呢,它就必須通過循環來找到那個key為null的entry
*/
for (Entry<K, V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
邏輯比較簡單,就不解釋了,我們回到get看下一個getEntry方法
final Entry<K, V> getEntry(Object key) {
//如果hashmap的大小為0返回null
if (size == 0) {
return null;
}
//判斷key如果為null則返回0,否則將key進行hash
int hash = (key == null) ? 0 : hash(key);
//indexFor方法通過hash值和table的長度獲取對應的下標
//遍歷該下標下的(如果有)鏈表
for (Entry<K, V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
//判斷當前entry的key的hash如果和和參入的key相同返回當前entry節點
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
到此JDK1.7中HashMap的基本get,put方法就完成了
本文僅個人理解,如果有不對的地方歡迎評論指出或私信,謝謝٩(๑>◡<๑)۶

