一個真實數據集的完整機器學習解決方案(上)

更多精彩內容,歡迎關注公眾號:數量技術宅。想要獲取本期分享的完整策略代碼,請加技術宅微信:sljsz01
引言
我們到底應該怎麼學會、靈活使用機器學習的方法?技術宅做過小小的調研,許多同學會選擇一本機器學習的書籍,或是一門機器學習的課程來系統性地學習。而在學完書本、課程後,並不清楚如何將這些理論、技術應用到實際的項目流程中。
這就好比,你的機器學習知識儲備中已經有了一塊塊碎片化的機器學習知識,但不知道怎樣才能將它們融合成一個整體。在本次的分享中,技術宅將借用國外機器學習大牛的數據,為大家系統的講解一個針對真實數據集的完整機器學習解決方案,讓你碎片化的知識,一文成型。
我們先來看,一個完整的機器學習工程的實現步驟:
1. 數據預處理
2. 探索性數據特徵統計
3. 特徵工程與特徵選取
4. 建立基線
5. 機器學習建模
6. 超參數調優
7. 測試集驗證
首先,我們來看本次機器學習模型想要解決的問題 。我們使用的是紐約市的公共可用建築能源數據(數據源下載地址:
//www.nyc.gov/html/gbee/html/plan/ll84_scores.shtml),想要實現的是通過該數據集,利用機器學習算法建立模型,該模型可以預測出紐約市建築物的能源之星評分,而且我們要求實現的模型,即篩選出的影響評分的特徵,儘可能具有可解釋性。我們將使用範例數據集,通過Python對上述的每個步驟,分步實現。而該項目的完整代碼,我們也將在文章的最後分享給大家。
通過對於我們想要實現的這一模型的簡單分析,可以知道我們需要做的是一個有監督的回歸機器學習模型:
其一,我們訓練的數據集中,既有潛在的特徵變量,也有目標,整個學習過程就是找到目標與特徵之間的有效映射模型
其二,紐約市建築物的能源之星評分,是一個0-100的連續變量,而非分類標籤,構建的模型屬於回歸的範疇
簡單分析完我們想要解決的問題,接下來,我們就遵循上述七個步驟,依次開發實現我們想要的模型。
數據預處理
在實際的數據集中,包含互聯網數據、金融數據等,往往都會存在缺失值和異常值,我們進行機器學習的建模,第一步就需要對數據進行清洗,並在清洗的過程中處理這些缺失、異常。
我們使用pandas讀取準備好的csv數據集

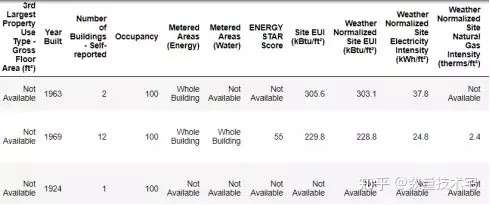
我們讀入的Dataframe共有60列,此處只截取了一部分的數據因子。其中,能源之星得分(ENERGY STAR Score)是我們需要預測的目標列,而其餘的列,我們都可以將它看作是潛在能夠構成特徵的變量,對於這些列,我們最好都能夠清楚每一列的數據代表的含義,以便於我們能夠更好的在將來解釋這個模型。
對於我們想要預測的目標列,能源之星得分(ENERGY STAR Score),我們來做一個詳細的說明:該得分來自紐約州每年所提交的能源使用情況報告,使用的是1~100的百分制排名,分數越高越好,代表該建築物使用能源的效率的越高,相對來說更加節能環保。
接下來,我們使用dataframe的info()方法查看每一列的數據類型:

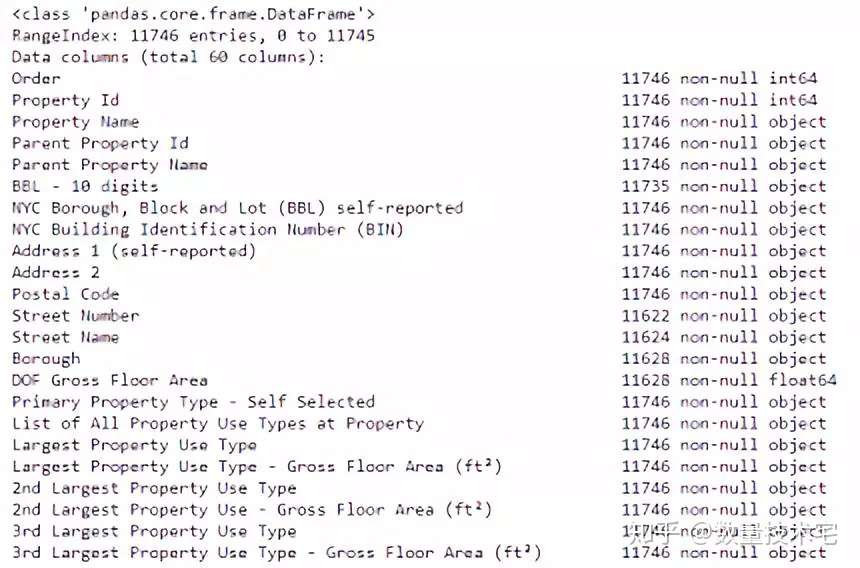
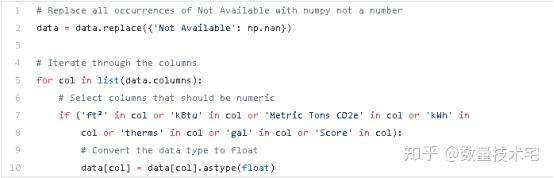
可以看到,其中有相當多的列屬於objects類型(非數據類型)。如果我們需要用這些列來形成模型的特徵,就需要將其轉換為數值數據類型。我們將所有「Not Available」條目替換為np.nan,然後再將相關列轉換為float數據類型,如此一來,所有的列,就都納入分析範圍了。
在處理完非數據類型的列後,我們在進行機器學習模型訓練前,必須對缺失數據進行處理。缺失數據的處理方式一般有兩者:刪除、填充,刪除指的是直接刪除缺失數據對應的行或列,而填充可以有前向填充、均值填充等多種方式。對於樣例中的數據集,我們先來看每列中缺失值的數量。
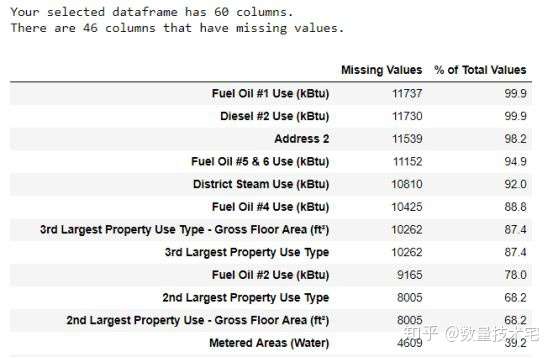
從上圖的統計結果中,%of Total Values列表示缺失數據量占該列總數據量的百分比。對於缺失數據量超過一定比例的列,加入機器學習模型訓練數據,顯然會受到缺失值的影響,因此,我們考慮剔除缺失值超過一定比例的列數據。
除了缺失數據外,我們還需要對離群數據進行進一步的處理,離群數據或是由一些偶發現象產生,或是本身數據在存儲的過程中出現了錯誤,它們會對特徵的計算值產生較大的影響。我們對於離群值採用縮尾處理(Winsorize) ,具體是指,對於低於第一四分位數(Q1) – 3 *四分位差、高於第三四分位數(Q3) + 3 *四分位差的數值,進行縮尾。
處理完缺失數據、離群數據後,我們進入下一環節。
探索性數據特徵統計
探索性數據統計分析(簡稱EDA)是對我們預處理完的數據進行探索性分析的階段,通過EDA,我們可以初步知道數據的一些統計特徵,以幫助我們更加合理的選擇和使用數據構建特徵。
單變量統計特徵
由於所有數據列中,能源之星得分(ENERGY STAR Score)是最重要的、也是我們要預測的目標變量,於是我們先通過hist函數,畫出能源之星得分的直方圖,來看一下能源之星得分的一個具體的分佈。
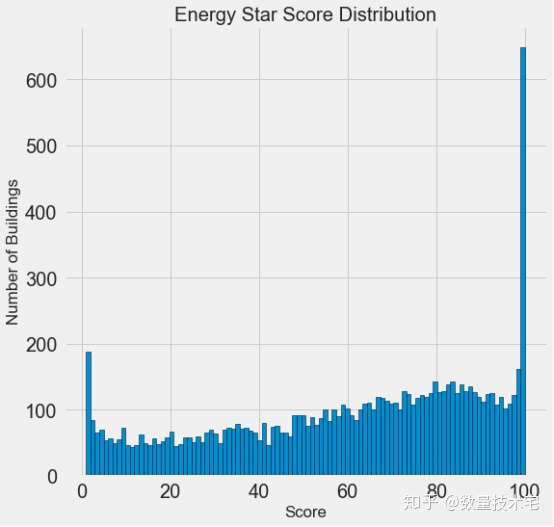
通過hist繪製的直方圖可以看到,能源之星得分這一目標變量,既不是均勻分佈,也不是類似正態分佈那樣的鐘形曲線,而是一個兩端分佈頻率極高,中間分佈頻率較低且不均勻的一個分佈。
這個分佈看上去比較奇怪,但如果仔細看一下能源之星得分的官方定義,它是基於「自我報告的能量使用」,也就是要求每個建築物的所有者自行報告能源的使用情況,這就好比每個學生在考試的時候能自定成績,那誰又不想拿滿分呢?而對於0分頻率的突然增高,或許是因為有些建築物年久失修,連所有者也幾乎放棄治療了。
但是,無論能源之星得分的分佈多麼不合乎常理,它都是我們這個項目需要預測的唯一目標,我們更需要關注的是如何準確的預測分數。
分組特徵
我們可以先用其中的某一個變量對所有的建築物進行一次分類,再在每個分類中計算該分類的能源之星得分的數據分佈。我們可以按類別對密度圖進行着色,以查看變量對分佈影響。我們首先查看建築物分佈類型對於能源之星得分的影響,如下是實現代碼與可視化結果。
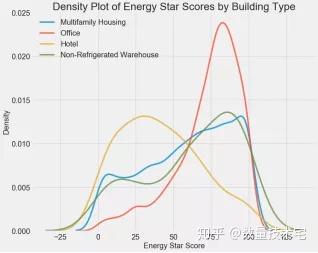
上圖直觀地反應出了不同建築物類型,對於得分確實存在較大的影響,比如辦公樓在高得分段分佈頻率更高,而酒店的低得分區域分佈頻率更高。因此,建築物類型應該是一個比較重要的影響變量。由於建築物類型是一個離散變量,我們可以通過對建築物類型進行獨熱編碼,將他們轉換為數值變量。
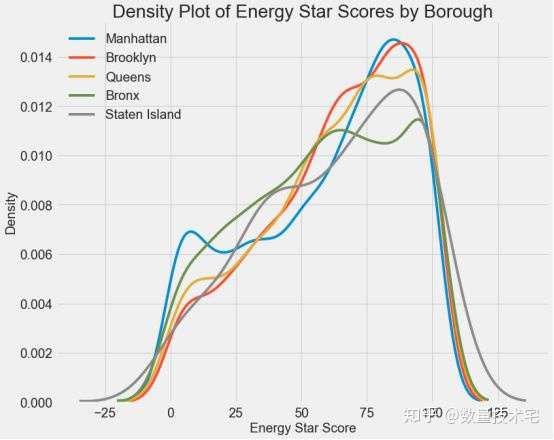
我們再來看一個紐約市下屬不同行政區域對於能源之星得分的影響,從下圖可以看出,不同區域對於得分基本上沒有區分度,也能說明該變量大概率不是一個好的特徵變量。
相關性統計
我們可以使用皮爾遜(Pearson)相關係數來衡量目標與其他數據列的相關關係,從而找到與目標變量相關性(正負)最強的列的排序。


我們分佈截取了負相關性、正相關性最高的兩組變量,可以看到,負相關性的變量,其相關性的絕對數值更高,並且最負相關的幾項類別變量幾乎都與能源使用強度(EUI)有關。EUI表示建築物的能源使用量是其規模或其他特性的函數(越低越好)。直觀來看,顯著的負相關性是有意義的:隨着EUI的增加,能源之星評分趨於下降。
雙變量分析
我們還可以使用散點圖來對雙變量進行分析,並在散點圖中用不同顏色,代表某個變量所區分的不同子類別,比如下圖以不同建築物的類型作為分類,繪製的能源之星評分與Site EUI(即負相關排名第一變量)的二維散點圖。
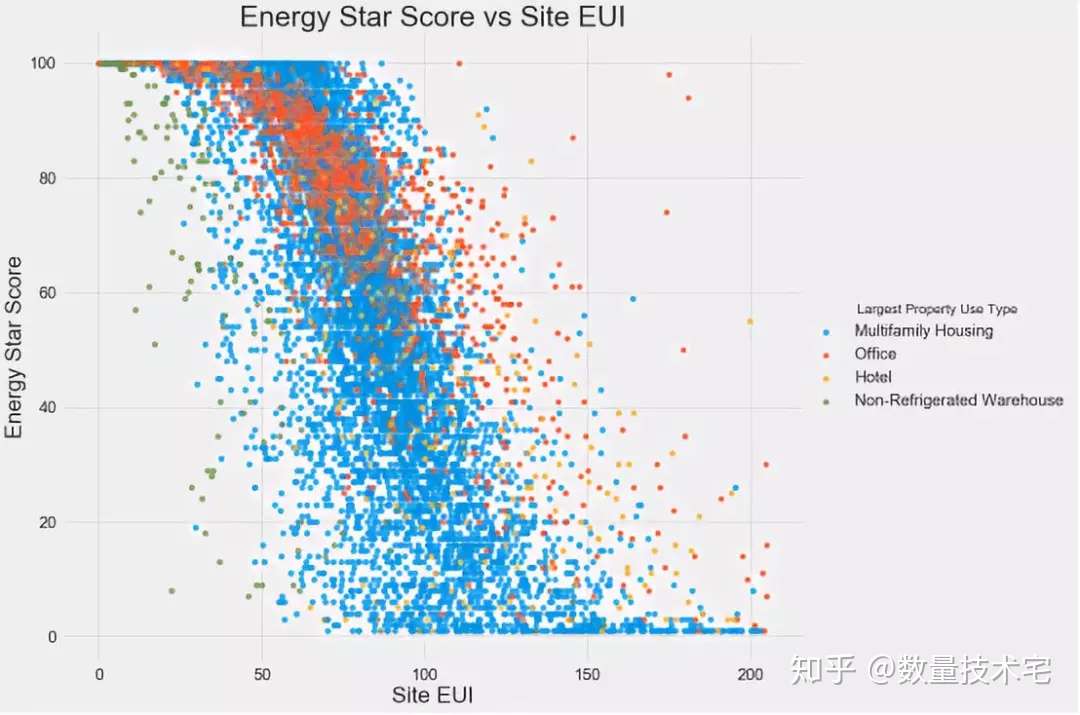
通過這個圖,可以印證我們在此前計算的相關性係數,不同類型的建築物,隨着SiteEUI的減少,能源之星得分呈現上升態勢。
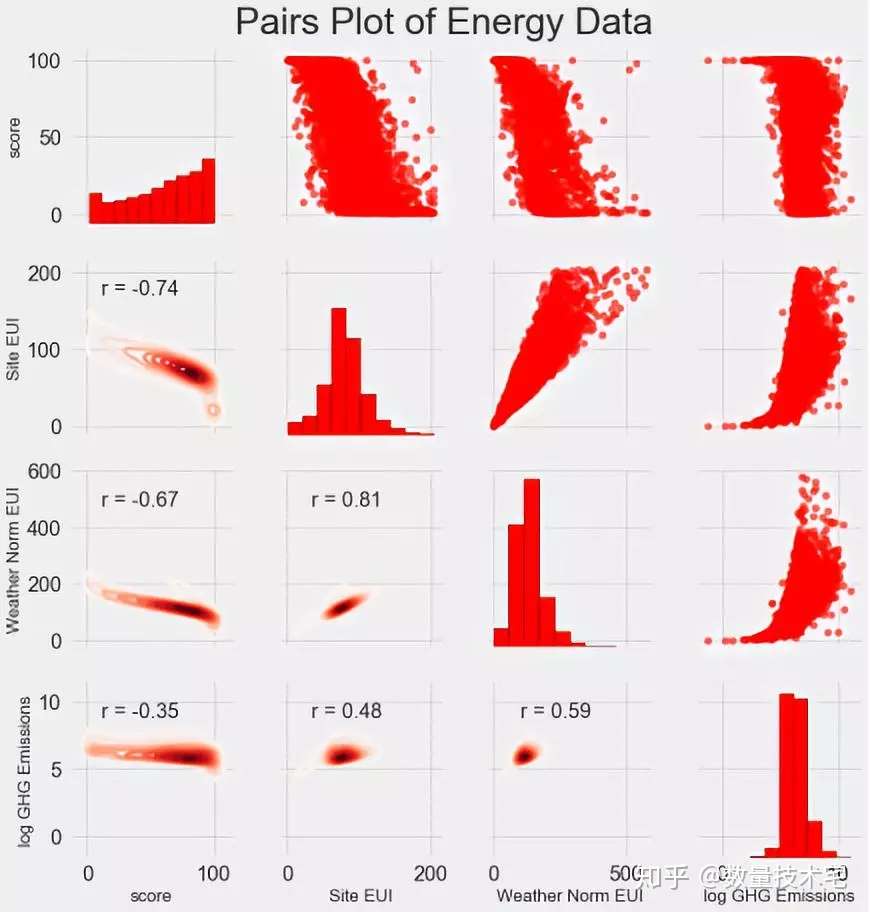
此外,成對圖(Pairs Plot)也是一種很不錯的分析工具,比如4*4的Pairs Plot,我們就能同時分析4組變量相互之間的聯合分佈與相關關係,我們使用seaborn可視化庫和PairGrid函數來創建Pais Plot–上三角部分使用散點圖,對角線使用直方圖以及下三角形使用二維核密度圖和相關係數。
特徵工程與特徵選取
特徵工程和特徵選取,可以說是整個機器學習項目中最為關鍵的一步。一個機器學習模型在樣本內外能否有優異的表現,模型的構建與參數的選擇,並不是最重要的,最重要的還是特徵對於目標的預測能力。如果特徵的預測能力足夠強,即使簡單的線性模型,也能有較好的擬合能力。我們先來簡單解釋一下特徵工程和特徵選取:
特徵工程:特徵工程是指通過原始數據,提取或創建新特徵,在這個過程中,可能需要對部分原始變量進行轉換。例如對於某些非正態分佈數據取自然對數、對分類變量進行獨熱(one-hot)編碼,使得他們能夠被納入模型訓練中。
特徵選取:特徵選取在實際過程中是一項需要經驗的操作,往往通過刪除無效或重複的數據特徵以幫助模型更好地學習和總結數據特徵並創建更具可解釋性的模型。特徵選擇更多的是對特徵做減法,只留下那些相對重要的特徵,在刪除的過程中,需要特別注意避免重要特徵被刪除的情況。
機器學習模型只能從我們提供的數據和特徵中學習,所以必須確保數據中有預測我們目前所需要的全部數據,如果我們提供的數據特徵維度不夠豐富,最終的學習效果也許會達不到我們的預期。
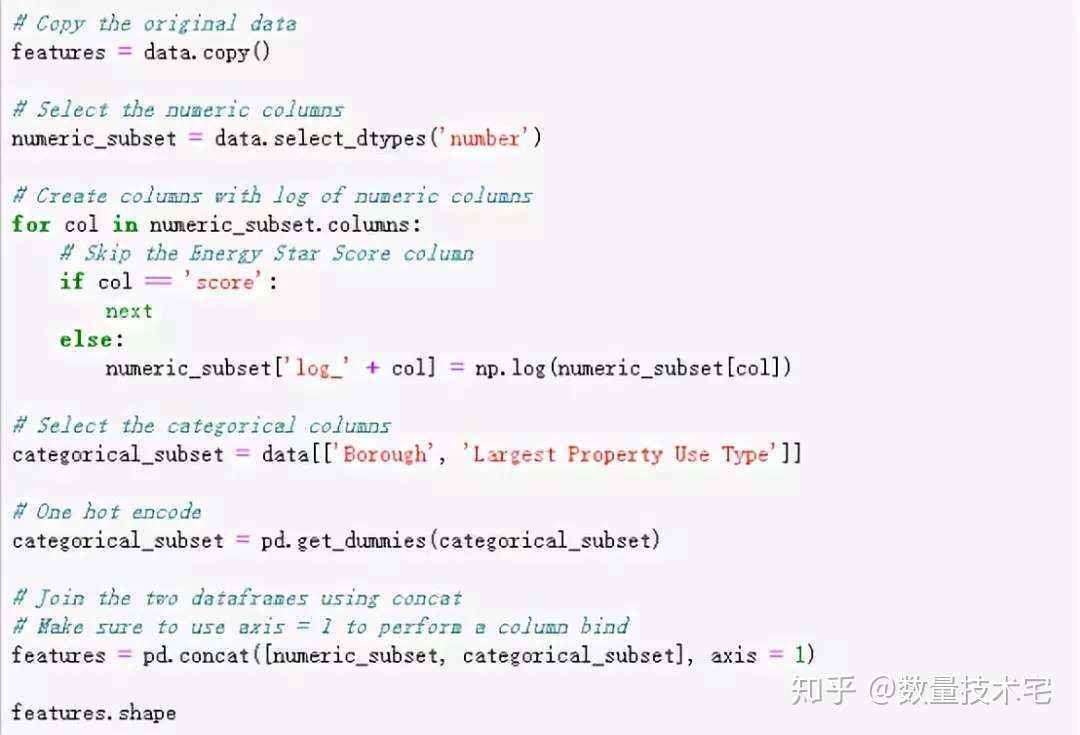
接下來,我們對本次項目的數據集分兩塊進行特徵工程。第一是對於分類變量,採用獨熱(one-hot)編碼進行分類,轉換為數值。獨熱(one-hot)編碼在模型的訓練數據中包含分類變量時,應用很常見。比如,我們的某個變量包含三個類別,那麼就用001、010、100三個獨熱編碼,分別對應三個原始分類。
第二是對數值型數據取對數。我們知道,很多原始的數據的分佈都不是正態分佈,如果我們直接將數據放入模型訓練,可能存在由數據偏態分佈帶來的潛在偏差,於是,我們對所有數值特徵取自然對數並添加到原始數據中。以下是上述兩個特徵工程操作步驟的Python代碼實現。
完成上述特徵工程後,我們的變量維度又增加了許多(獨熱編碼、指數變換),這其中大概率存在着一些冗餘的變量,比如高度相關的變量。以下圖為例,Site EUI與Weather Norm EUI,這兩個變量的相關係數高達0.997,顯然我們不需要都做保留。
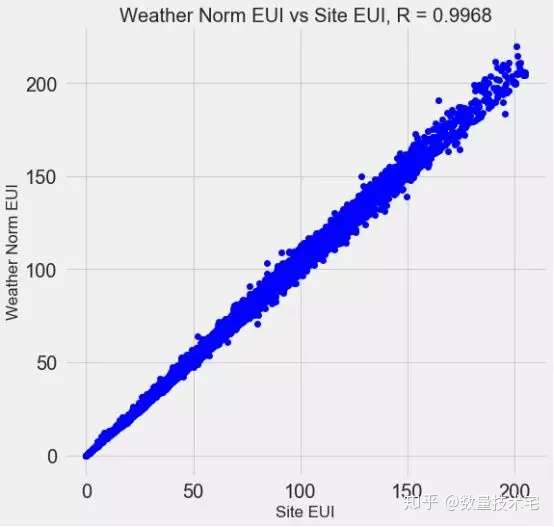
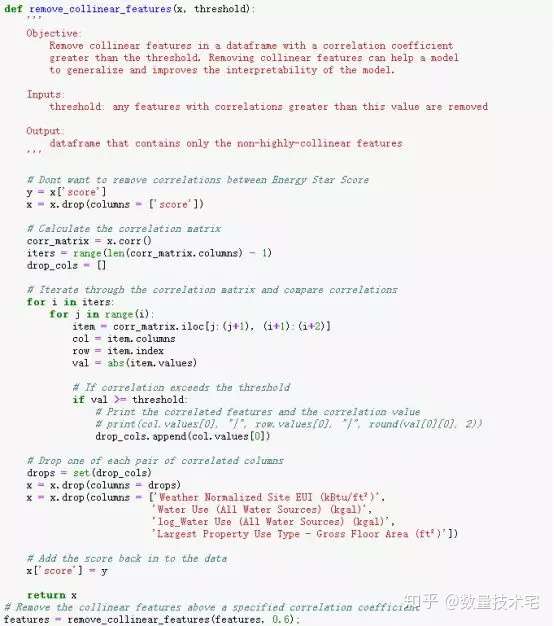
這些相關性很高的變量,在模型中我們稱之為共線性(collinear),消除變量之間的共線性,能夠讓機器學習模型更魯棒並且具有更強的可解釋性。我們將使用相關係數來識別和刪除共線性的冗餘特徵,具體做法是,我們通過循環遍歷,兩兩計算除目標變量外所有變量的相關係數,當某兩個變量相關係數大於一定閾值,我們就放棄其一,具體實現代碼如下。篩選完成後,剩下64列特徵和1列目標特徵(能源之星得分)。

建立基線(Baseline)
在完成特徵工程和冗餘特徵的篩選後,我們開始下一步工作:建立模型績效對比的基準,我們也把它稱之為基線(Baseline)。我們通過基線來與最終模型的績效評估指標對比,如果機器學習最終訓練得到的模型沒有超越基線,那麼說明該模型並不適用該數據集,或是我們的特徵工程特徵選取存在着問題。
對於回歸問題,一個合理的基線是通過預估測試集中所有示例的運行結果為訓練集中目標結果的均值,並根據均值計算平均絕對誤差(MAE)。選擇MAE作為基線有兩方面考慮,一是它的計算簡單,二是其可解釋性強。
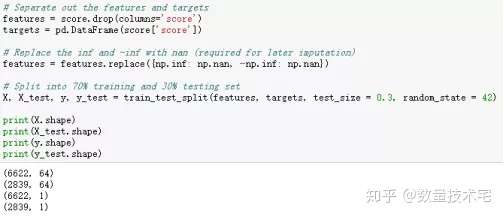
在計算基線前,我們需要先將原始數據劃分為訓練集和測試集,這也是為了在後續的處理過程中,絕對避免數據泄露的發生。我們採用比較常規的70%原始數據進行訓練,30%用於測試。
劃分完訓練與測試集,我們再計算MAE的數值,並計算基線。由下圖結果可以看到,計算得出預估模型表現為66,在測試集中的誤差約為25左右(百分制)。可以說是比較容易達到的性能。

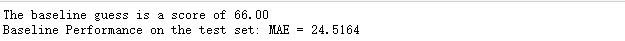
深夜碼字,困意襲來,上篇暫且先到這裡,下篇爭取明天更完
關注 「數量技術宅」不迷路(下篇精彩繼續),您的點贊、轉發,是我輸出乾貨,最大的動力


往期乾貨分享推薦閱讀
【數量技術宅|量化投資策略系列分享】基於指數移動平均的股指期貨交易策略
AMA指標原作者Perry Kaufman 100+套交易策略源碼分享
【數量技術宅|金融數據系列分享】套利策略的價差序列計算,恐怕沒有你想的那麼簡單
【數量技術宅|量化投資策略系列分享】成熟交易者期貨持倉跟隨策略
【數量技術宅|金融數據分析系列分享】為什麼中證500(IC)是最適合長期做多的指數
商品現貨數據不好拿?商品季節性難跟蹤?一鍵解決沒煩惱的Python爬蟲分享
【數量技術宅|金融數據分析系列分享】如何正確抄底商品期貨、大宗商品
【數量技術宅|量化投資策略系列分享】股指期貨IF分鐘波動率統計策略
【數量技術宅 | Python爬蟲系列分享】實時監控股市重大公告的Python爬蟲

