tensorflow學習筆記——DenseNet
- 2020 年 12 月 12 日
- 筆記
- 深度學習常用算法及筆記
完整代碼及其數據,請移步小編的GitHub地址
傳送門:請點擊我
如果點擊有誤://github.com/LeBron-Jian/DeepLearningNote
這裡結合網絡的資料和DenseNet論文,捋一遍DenseNet,基本代碼和圖片都是來自網絡,這裡表示感謝,參考鏈接均在後文。下面開始。
DenseNet 論文寫的很好,有想法的可以去看一下,我這裡提供翻譯地址:
深度學習論文翻譯解析(十五):Densely Connected Convolutional Networks
自ResNet提出以後,ResNet的變種網絡層出不窮,都各有其特點,網絡性能也有一定的提升。本文學習CVPR 2017最佳論文 DenseNet,論文中提出的 DenseNet(Dense Convolutional Network)主要還是和ResNet以及Inception網絡做對比,思想上有所借鑒,但是卻是全新的結構,網絡結構並不複雜,卻非常有效,在CIFAR指標上全面超越ResNet,可以說是DenseNet吸收了ResNet 最精華的部分,並在此上做了更加創新的工作,使得網絡性能進一步提升。
1,ResNet VS DenseNet
首先,我們通過對ResNet的對比來大概了解一下 DenseNet。
下圖為ResNet網絡的短路連接機制(其中+代表的是元素級相加操作)。

可以看出ResNet是每個層與前面的某層(一般是2~3層)短路連接到一起,連接方式是通過元素級相加。
DenseNet的基本思路與ResNet一致,但是它建立的是前面所有層與後面層的密集連接(dense connection),它的名稱也是由此而來。DenseNet的另外一大特色是通過特徵在channel上的連接來實現特徵重用(feature reuse)。這些特點讓DenseNet在參數和計算成本更少的情形下實現比ResNet更優的性能。
相比ResNet,DenseNet提出了一個更激進的密集連接機制:即互相連接所有的層,具體來說就是每個層都會接受其前面所有層作為其額外的輸入。ResNet是每個層與前面的某層(一般是2~3層)短路連接在一起,連接方式是通過元素級相加。而在DenseNet中,每個層都會與前面所有層在 channel維度上連接(Concat)在一起(這裡各個層的特徵圖大小是相同的,後面會說明),並作為下一層的輸入。對於一個 L 層的網絡,DenseNet共包含L*(L+1)/2 個連接,相比ResNet,這是一種密集連接。而且DenseNet是直接Concat來自不同層的特徵圖,這可以實現特徵重用,提高效率,這一特點是DenseNet和ResNet最主要的區別。
需要明確一點,Dense connectivity 僅僅是在一個 Dense Block 里的,不同 Dense Block 之間是沒有Dense Connectivity的。
下圖為DenseNet網絡的密集連接機制(其中C代表的是 channel級連接操作),在DenseNet中直接 concat來自不同層的特徵圖,這可以實現特徵重用,提升效率,這一特點是DenseNet與ResNet最主要的區別。
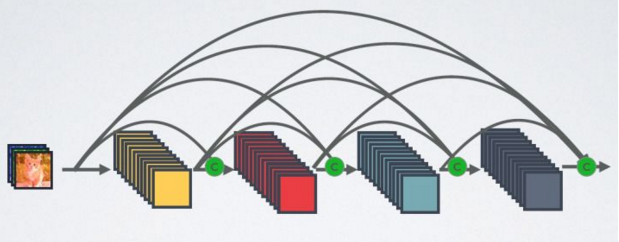
如果用公式表示的話,傳統的網絡在 l 層的輸出為:
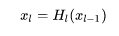
而對於ResNet,增加了來自上一層輸入的 identity函數:
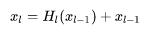 在DenseNet中,會連接前面所有層作為輸入:
在DenseNet中,會連接前面所有層作為輸入:
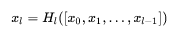
其中,上面的 Ht(*) 代表是非線性轉換函數(non-linear-transformation),它是一個組合操作,其可能包括一系列的 BN(Batch Normalization),ReLU,Pooling及其Conv操作。注意這裡的 l 層與 l-1 層之間實際上包含多個卷積層。
1.1 Keras中add和 concatenate 操作的不同
說起ResNet和DenseNet的區別了,就不得不說一下代碼層面了,畢竟我們的目的是實現它。
首先說結論,ResNet的使用都是 add 操作,而DenseNet和InceptionNet使用的都是 concatenate操作。
關於 Concatenate 操作
拼接,H,W 都不改變,但是通道數增加。
網絡結構設計中很重要的一種操作,經常用於將特徵聯合,多個卷積提取框架提取的特徵融合或者是將輸出層的信息進行融合。Densenet 是做通道的合併,而Concatnate 是通道數的合併,也就是說描述圖像本身的特徵增加了,而每一特徵下的信息是沒有增加的。
Keras 中 Concatnate 函數與 concatnate 函數
這裡直接分析源碼,不多分析只看區別:
首先是 Concatenate()函數:
class Concatenate(_Merge):
"""Layer that concatenates a list of inputs.
It takes as input a list of tensors,
all of the same shape except for the concatenation axis,
and returns a single tensor, the concatenation of all inputs.
# Arguments
axis: Axis along which to concatenate.
**kwargs: standard layer keyword arguments.
"""
再來是 concatenate()函數:
def concatenate(inputs, axis=-1, **kwargs):
"""Functional interface to the `Concatenate` layer.
# Arguments
inputs: A list of input tensors (at least 2).
axis: Concatenation axis.
**kwargs: Standard layer keyword arguments.
# Returns
A tensor, the concatenation of the inputs alongside axis `axis`.
"""
return Concatenate(axis=axis, **kwargs)(inputs)
concatenate() 函數 是 Concatenate() 函數的接口函數,我們可以使用兩個中的任意一個,但是方法要寫正確。後面我們會做代碼驗證。
關於 Add 操作
加,H,W,C 都不改變,只是相應元素的值會改變。
信息之間的疊加,ResNet是做值的疊加,通道數是不變的。add是描述圖像的特徵下的信息量增多了,但是描述圖像的維度本身沒有增加,只是在每一維度下信息量在增加。
Keras 中 Add 函數與 add 函數
這裡直接分析源碼,不多分析只看區別:
首先是 Add()函數:
class Add(_Merge):
"""Layer that adds a list of inputs.
It takes as input a list of tensors,
all of the same shape, and returns
a single tensor (also of the same shape).
# Examples
```python
import keras
input1 = keras.layers.Input(shape=(16,))
x1 = keras.layers.Dense(8, activation='relu')(input1)
input2 = keras.layers.Input(shape=(32,))
x2 = keras.layers.Dense(8, activation='relu')(input2)
# equivalent to added = keras.layers.add([x1, x2])
added = keras.layers.Add()([x1, x2])
out = keras.layers.Dense(4)(added)
model = keras.models.Model(inputs=[input1, input2], outputs=out)
```
"""
再來是 add()函數:
def add(inputs, **kwargs):
"""Functional interface to the `Add` layer.
# Arguments
inputs: A list of input tensors (at least 2).
**kwargs: Standard layer keyword arguments.
# Returns
A tensor, the sum of the inputs.
# Examples
```python
import keras
input1 = keras.layers.Input(shape=(16,))
x1 = keras.layers.Dense(8, activation='relu')(input1)
input2 = keras.layers.Input(shape=(32,))
x2 = keras.layers.Dense(8, activation='relu')(input2)
added = keras.layers.add([x1, x2])
out = keras.layers.Dense(4)(added)
model = keras.models.Model(inputs=[input1, input2], outputs=out)
```
"""
return Add(**kwargs)(inputs)
add() 函數 是 Add() 函數的接口函數,我們可以使用兩個中的任意一個,但是方法要寫正確。後面我們會做代碼驗證。
代碼展示Keras中四個函數的區別
代碼如下:
from keras.layers import Concatenate, Add, add, concatenate
import numpy as np
import tensorflow as tf
matrix1 = np.array([[1,2,3], [4,5,6]])
matrix2 = np.array([[11,22,33], [44,55,66]])
# 將一個numpy數據轉換為tensor
t1 = tf.convert_to_tensor(matrix1)
t2 = tf.convert_to_tensor(matrix2)
print(t1)
print(t2)
'''
[[1 2 3]
[4 5 6]]
[[11 22 33]
[44 55 66]]
Tensor("Const:0", shape=(2, 3), dtype=int32)
Tensor("Const_1:0", shape=(2, 3), dtype=int32)
'''
exp_Add = Add()([t1, t2])
exp_Concatenate = Concatenate()([t1, t2])
print(exp_Add)
print(exp_Concatenate)
# 要對tensor進行操作,需要先啟動一個Session
with tf.Session() as sess:
print('exp_Concatenate is ', exp_Add.eval())
print('exp_Concatenate is ', exp_Concatenate.eval())
'''
exp_Concatenate is [[12 24 36]
[48 60 72]]
exp_Concatenate is [[ 1 2 3 11 22 33]
[ 4 5 6 44 55 66]]
Tensor("add_1/add:0", shape=(2, 3), dtype=int32)
Tensor("concatenate_1/concat:0", shape=(2, 6), dtype=int32)
'''
exp_Add1 = add([t1, t2])
exp_Concatenate1 = concatenate([t1, t2])
print(exp_Add1)
print(exp_Concatenate1)
'''
Tensor("add_2/add:0", shape=(2, 3), dtype=int32)
Tensor("concatenate_2/concat:0", shape=(2, 6), dtype=int32)
'''
with tf.Session() as sess:
print(exp_Add1.eval() == exp_Add.eval())
print(exp_Concatenate1.eval() == exp_Concatenate.eval())
'''
[[ True True True]
[ True True True]]
[[ True True True True True True]
[ True True True True True True]]
'''
2,DenseNet網絡架構
當CNNs增加深度的時候,就會出現一個緊要的問題:當輸入或者梯度的信息通過很多層之後,它可能會消失或過度膨脹。研究表明,如果卷積網絡在接近輸入和接近輸出地層之間包含較短地連接,那麼,該網絡可以顯着地加深,變得更精確並且能夠更有效的訓練。在論文中提出的架構為了確保網絡層之間的最大信息流,將所有層直接彼此連接。為了保持前饋特性,每個層從前面的所有層獲得額外的輸入,並將自己的特徵映射傳遞到後面的所有層。該論文基於這個觀察提出了以前饋的方式將每個層與其他層連接的密集卷積網絡(DenseNet)。
原作者通過觀察目前深度網絡的一個重要特點就是都加入了 shorter connections,能夠讓網絡更深,更準確,更高效。作者充分利用了 skip connections ,設計了一種稠密卷積神經網絡(Dense Convolutional Network),讓每一層都接受它前面所有層的輸出。對於傳統卷積結構,L層一共有L個 connections,但DenseNet,L層一共有L(L-1)/2 個 Connection。
2.1 DenseNet閃光點
- 1,相比ResNet 擁有更少的參數數量
- 2,旁路加強了特徵的重用
- 3,網絡更易於訓練,並具有一定的正則效果
- 4,緩解了梯度消失(gradient vanishing)和模型退化(model degradation)的問題
2.2 DenseNet 網絡分析
DenseNet 是一種具有密集連接的卷積神經網絡。在該網絡中,任何兩層之間都有直接的連接,也就是說,網絡每一層的輸入都是前面所有層輸出的並集,而該層所學習的特徵圖也會被直接傳給其後面所有層作為輸入。
下圖是一個五層的密集塊:
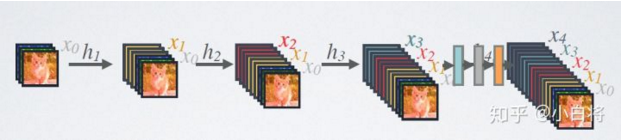
DenseNet 的前向過程如上圖所示,可以更直觀地理解其密集連接方式,比如 h3 的輸入不僅包括來自 h2 的 x2,還包括前面兩層的 x1 和 x2,他們是在 channel 維度上連接在一起的。
下圖給出了DenseNet的網絡結構,它共包含 4個 DenseBlock,各個 DenseBlock之間通過Transition 連接在一起。
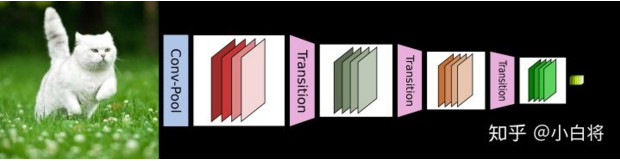
CNN網絡一般要經過Pooling或者 stride>1 的Conv 來降低特徵圖的大小,而DenseNet的密集連接方式需要特徵圖大小保持一致。為了解決這個問題,DenseNet網絡中使用 DenseBlock + Transition 的結構,其中 DenseBlock 是包含很多層的模塊,每個層的特徵圖大小相同,層與層之間採用密集連接方式。而 Transition模塊是連接兩個相鄰的 DenseBlock ,並且通過 Pooling使特徵圖大小降低。
2.3 Dense Block
首先展示一下Dense Block網絡結構:
Dense Block模塊:BN + ReLU + Conv(3*3) + dropout
transition layer模塊:BN + ReLU + Conv(1*1)(filter_num:m) + dropout + Pooling(2*2)
我們知道DenseNet的網絡結構主要由DenseBlock和 Transition組成,下面具體來學習網絡的實現細節,首先看網絡結構:
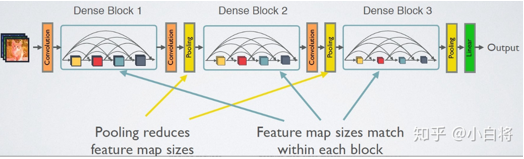
在DenseBlock中,各個層的特徵圖大小一致,可以在channel維度上連接。DenseBlock中的非線性組合 H(*) 採用的是 BN+ReLU+3*3Conv 的結構,如下圖所示:
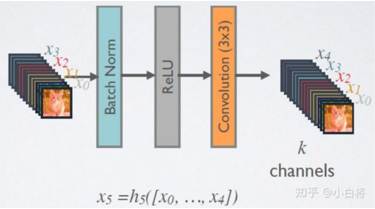
該架構與ResNet相比,在將特性傳遞到層之前,沒有通過求和來組合特性,而是通過連接他們的方式來組合特性。因此第 x 層(輸入層不算在內)將由 x個輸出的特徵圖,這些輸入是之前所有層提取出的特徵信息,或者說採用 x 個卷積核, x 在DenseNet稱為 growth rate,這是一個超參數,一般情況下使用較小的 k(比如12),就可以得到較佳的性能。假定輸入層的特徵圖的 channels 數為 k0,那麼 l 層的輸入的 channel 數為 k0 + k(l – 1),因此隨着層數的增加,儘管k設定的較小,DenseBlock的輸入會非常多,不過這是由於特徵重用所造成的,每個層僅有 K 個特徵是自己獨有的,因為它的密集連接特性,研究人員將其稱為 Dense Convolutional Network(DenseNet)。
因為不需要重新學習冗餘特徵圖,這種密集連接模式相對於傳統的卷積網絡只需要更少的參數。傳統的前饋體系結構可以看做是具有一種狀態的算法,這種狀態從一個層傳遞到另一個層。每個層從其前一層讀取狀態並將其寫入後續層。它改變狀態,但也傳遞需要保留的信息。研究提出的密集網絡體系結構明確區分了添加到網絡的信息和保留的信息。密集網層非常窄(例如:每層12個過濾器),僅向網絡的「集體知識」添加一小組特徵映射,並且保持其餘特徵映射不變,並且最終分類器基於網絡中的所有特徵映射做出決策。
除了參數更少,另一個DenseNets 的優點是改進了整個網絡的信息流和梯度,這使得他們易於訓練。每個層直接訪問來自損失函數和原始輸入信號的梯度,帶來了隱式深度監控。這使得訓練深層網絡變得更簡單。此外,研究人員觀察到密集連接具有規則化效果,這減少了對訓練集較小的任務的過擬合。
2.4 DenseNet-B
首先展示一下 DenseNet-B 網絡結構:
Dense Block模塊:BN + ReLU + Conv(1*1)(filter_num:4K) + dropout + BN + ReLU + Conv(3*3) + dropout
transition layer模塊:BN + ReLU + Conv(1*1)(filter_num:m) + dropout + Pooling(2*2)
密集連接不會帶來冗餘嗎?不會!密集連接這個詞給人的第一感覺就是極大地增加了網絡的參數量和計算量。但是實際上DenseNet比其他網絡效率更高,其關鍵就在於網絡每層計算量的減少以及特徵的重複利用。DenseNet 則是讓 l 層的輸入直接影響到之後的所有層,它的輸出為:xl = H1([X0, X1, … Xl-1]),其中 [X0, x1, …Xl-1] 就是將之前的 feature map 以通道的維度進行合併。並且由於每一層都包含之前所有層的輸出信息,因此其只需要很少的特徵圖就夠了,這也是為什麼 DenseNet的參數量較其他模型大大減少的原因。這種Dense Connection 相當於每一層都直接連接 input 和 loss,因此就可以減輕梯度消失現象,這樣更深網絡不是問題。需要明確一點,Dense Connectivity 僅僅是在一個 Dense Block里的,不同Dense Block 之間是沒有Dense Connectivity的,比如下圖所示:

天底下沒有免費的午餐,網絡自然也不例外。在同層深度下獲得更好的收斂率,自然是由額外代價的,其代價之一就是其恐怖如斯的內存佔用。
每一個DenseBlock模塊的輸出維度有多大呢?
假設一個L層的Dense Block模塊中輸出K個 feature map,即網絡增長率為K,其中已經加入了Bottleneck單元,那麼第L層的輸入為K0 + K*(L-1)(其中第K0為輸入層的維度),而總共輸出的維度為:第一層的維度 + 第二層的維度 + 第三層的維度 + … + 第L層的維度,加入Bottleneck單元後每層的輸出維度為4K,那麼最終 Dense Block模塊的輸出維度為4K*L。也就是說隨着Dense Block 模塊深度的加深,即隨着層數L的增加,最終輸出的 feature map 的維度也是一個很大的數,為了解決這個問題,在transition layer模塊中加入了1*1卷積做降維。
為了解決這個問題,在Dense Block模塊中加入了 Bottleneck單元,如下圖所示,即 BN + ReLU + 1*1Conv + BN + ReLU + 3*3 Conv,稱為 DenseNet-B結構。其中1*1Conv降維得到 4k 個特徵圖它起到的作用是降低特徵數量,從而提升計算效率(K為增長率)。
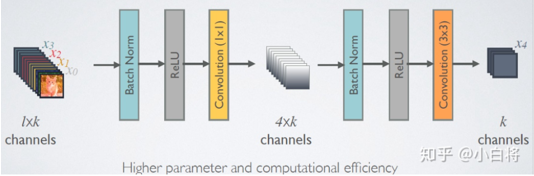
2.5 DenseNet-BC
首先展示一下 DenseNet-BC 網絡結構:
Dense Block模塊:BN + ReLU + Conv(1*1)(filter_num:4K) + dropout + BN + ReLU + Conv(3*3) + dropout
transition layer模塊:BN + ReLU + Conv(1*1)(filter_num:θm,其中 0<θ<1,文章取θ=0.5) + dropout + Pooling(2*2)
對於 Transition層,它主要是連接兩個相鄰的 DenseBlock,並且降低特徵圖大小。Transition層包括一個1*1的卷積和 2*2 的 AvgPooling,結構為:BN + ReLU + 1*1 Conv + 2*2 AvgPooling。另外,Transition層可以起到壓縮模型的作用。假定 Transition的上接 DenseBlock得到的特徵圖 channels 數為 m,Transition可以產生 |θm| 個特徵(通過卷積層),其中 θ € (0, 1] 是壓縮係數(compression rate),當 θ = 1 時,特徵個數經過 Transition層沒有變換,即無壓縮,而當壓縮係數小於1時,這種結構稱為 DenseNet-C,文章使用 θ=0.5 。對於使用 Bottleneck 層的 DenseBlock結構和壓縮係數小於1的Transition 組合結構稱為 DenseNet-BC。
3,DenseNet的優缺點分析
參考地址://blog.csdn.net/comway_Li/article/details/82055229
DenseNet 的核心思想在於建立了不同層之間的連接關係,充分利用了feature,進一步減輕了梯度消失問題,加深網絡不是問題,而且訓練效果非常好。另外利用bottleneck layer,Transition layer 以及較小的 growth rate 使得網絡變窄,參數減少,有效抑制了過擬合,同時計算量也減少了。DenseNet優點很多,而且在和ResNet的對比中優勢還是非常明顯的。
3.1 作者提出算法的出發點
目前來看,深度卷積網絡挑戰主要有:
- 1,Underfitting(欠擬合):一般來說,模型越為複雜,表現能力越強,越不融合欠擬合。但是深度網絡不一樣,表現表達能力夠,但是算法不能達到那個全局最優(ResNet基本解決)
- 2,Overfitting(過擬合):泛化能力下降
- 3,實際系統的部署問題,如何提升效率和減少內存,能量消耗
那麼如何消除上述的冗餘性?得到更緊湊的結構?更好的泛化性能?由隨機網絡深度,我們就得知訓練時扔掉大部分層卻效果不錯,說明冗餘性很多,每一層乾的事情很少,只學一點東西。
所以目的就是減少不必要的計算,提高泛化性能。
3.2 算法優點
綜合來看,DenseNet的優勢主要體現在以下幾個方面:
- 抗過擬合,由於密集連接方式,DenseNet提升了梯度的反向傳播,使得網絡更容易訓練。由於每層可以直達最後的誤差信號,實現了隱式的「deep supervision」;所以DenseNet具有非常好的抗過擬合性能,尤其適合於訓練數據相對匱乏的應用。
- 參數更小且計算更高效,這有點違反直覺,由於DenseNet是通過concat特徵來實現短路連接,實現了特徵重用,並且採用較小的growth rate,每個層所獨有的特徵圖是比較小的;達到了與ResNet相當的精度,DenseNet所需的計算量也只有ResNet的一半左右。計算效率在深度學習實際應用中的需求非常強烈。
- 泛化性更強,如果沒有 data augmention,CIFAR-100下,ResNet表現下降很多,DenseNet下降不多,說明DenseNet泛化性能更強。
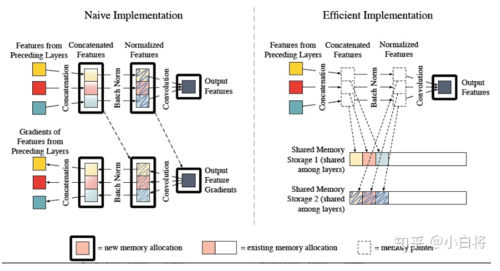
要注意的一點是,如果實現方式不當的話,DenseNet可能耗費很多GPU顯存,一種高效的實現如下圖所示,更多細節可以見這篇論文Memory-Efficient Implementation of DenseNets。不過我們下面使用Pytorch框架可以自動實現這種優化。
3.3 如何對DenseNet的模型做改進
1,每層開始的瓶頸層(1*1 卷積)對於減少參數量和計算量非常有用
2,像VGG和ResNet那樣每做一次下採樣(down-sampling)之後都把層寬度(growth rate)增加一倍,可以提高 DenseNet 的計算效率(FLOPS efficiency)
3,與其他網絡一樣,DenseNet的深度和寬度應該均衡的變化,當然DenseNet 每層的寬度要遠小於其他模型
4,每一層設計得較窄會降低 DenseNet 在GPU 上的運行效率,但可能會提高再 CPU 上的運行效率
3.4 DenseNet 是否耗費顯存
如果出現DenseNet在訓練時對內存消耗非常厲害。這個問題其實是算法實現不優帶來的。當前的深度學習框架對 DenseNet 的密集連接沒有很好的支持,我們只能藉助於反覆的拼接(Concatenation)操作,將之前層的輸出與當前層的輸出拼接在一起,然後傳給下一層。對於大多數框架(如 Torch 和 TensorFlow),每次拼接操作都會開闢新的內存來保存拼接後的特徵。這樣就導致一個L層的網絡,要消耗相當於L(L+1)/2 層網絡的內存(第i 層的輸出在內存里被存了 (L-i+1)份)。
解決這個問題的思路其實並不能,我們只需要預先分配一塊緩存,供網絡中所有的拼接村(Concatenation layer)共享使用,這樣DenseNet對內存的消耗便從平方級降到了線性級別。在梯度反傳過程中,我們再把相應卷積層的輸出複製到該緩存,就可以重構每一層的輸入特徵,進而計算梯度。當然網絡中由於Batch Normalization層的存在,實現起來還有一些需要注意的細節。
新的實現極大地減少了 DenseNet 在訓練時對顯存的消耗,比如論文中 190 層的 DenseNet 原來幾乎佔滿了 4塊 12G的內存的GPU,而優化後的代碼僅需要 9G 的顯存,在單卡上就能訓練。
另外就是網絡在推理(或測試)的時候對內存的消耗,這個是我們在實際產品中(尤其是在移動設備上)部署深度學習模型時最關心的問題。不同於訓練,一般神經網絡的推理過程不需要一直保留每一層的輸出,因此可以在每計算好一層的特徵後便將前面層特徵佔用的內存釋放掉,而DenseNet則需要始終保存所有前面層的輸出。但是考慮到 DenseNet每一層產生的特徵圖很少,所以在推理的時候佔用內存不會多於其他網絡。
4,DenseNet算法總結分析
4.1,DenseNet網絡三種結構的區分
文章同時提出了DenseNet,DenseNet-B,DenseNet-BC三種結構,上面也學習了,這裡再單獨提出來,具體區別如下:
DenseNet
- Dense Block模塊:BN+Relu+Conv(3*3)+dropout
- transition layer模塊:BN+Relu+Conv(1*1)(filternum:m)+dropout+Pooling(2*2)
DenseNet-B
- Dense Block模塊:BN+Relu+Conv(1*1)(filternum:4K)+dropout+BN+Relu+Conv(3*3)+dropout
- transition layer模塊:BN+Relu+Conv(1*1)(filternum:m)+dropout+Pooling(2*2)
DenseNet-BC
- Dense Block模塊:BN+Relu+Conv(1*1)(filternum:4K)+dropout+BN+Relu+Conv(3*3)+dropout
- transition layer模塊:BN+Relu+Conv(1*1)(filternum:θm,其中0<θ<1,文章取θ=0.5) +dropout +Pooling(2*2)
其中,DenseNet-B在原始DenseNet的基礎上,加入Bottleneck layers, 主要是在Dense Block模塊中加入了1*1卷積,使得將每一個layer輸入的feature map都降為到4k的維度,大大的減少了計算量。
4.2 問題1:pooling
因為神經網絡從輸入到輸出趨勢就是 channel 數逐漸增加, feature map逐漸縮小,而使 feature map 縮小的操作就是 pooling,pooling 前後 feature map 不一樣,這種情況下 concatenation 是沒有用的,這種情況下論文將一個大網絡分成幾個 dense blocks,中間使用 transition layers(一個作用就是 pooling)進行連接。
transition block層的代碼如下:
def transition_block(input,nb_filter,dropout_rate=None,pooltype=1,weight_decay=1e-4):
x = BatchNormalization(axis=-1,epsilon=1.1e-5)(input)
x = Activation('relu')(x)
x = Conv2D(nb_filter,(1,1),kernel_initializer='he_normal', padding='same', use_bias=False,
kernel_regularizer=l2(weight_decay))(x)
if(dropout_rate):
x = Dropout(dropout_rate)(x)
if(pooltype==2):
x = AveragePooling2D((2,2),strides=(2,2))(x)
elif(pooltype==1):
x = ZeroPadding2D(padding=(0,1))(x)
x = AveragePooling2D((2,2),strides=(2,1))(x)
elif(pooltype==3):
x = AveragePooling2D((2,2),strides=(2,1))(x)
return x,nb_filter
4.3 問題2:指數增長的通道數
當看到DenseNet的公式的時候,我們肯定會想到通道數增長速度的問題。
輸入通道數為 c0 = k0,卷積不改變通道數,那麼第一層通道數為 c1 = c0 + k0 = 2k0,第二層通道數為 c2 = c0+c1+k0 = K0+2K0+k0 =4K0,…,很輕鬆證明:Cn = 2n-1k0,這種指數級別的通道數是不允許存在的,過多的通道數會極大的增加參數量,從而降低運行速度。
所以論文首先給出了一個限定條件,即方程 Hl(*) 輸出的通道數不是 Cn = 2n-1k0,而是一個固定的k(論文使用了一個專門的術語growth rate 表示這個參數),即每一層都是固定的通道數,但是輸入 [x0, x1, ….xn] 的通道數為 k0+k(l-1),這種通道數的差別表明方程 Hl(*) 有一個維度壓縮過程。
growth rate 靠卷積得到固定通道數:
def conv_block(input,growth_rate,dropout_rate=None,weight_decay=1e-4):
x = BatchNormalization(axis=-1,epsilon=1.1e-5)(input)
x = Activation('relu')(x)
x = Conv2D(growth_rate,(3,3),kernel_initializer='he_normal', padding = 'same')(x)
if(dropout_rate):
x = Dropout(dropout_rate)(x)
return x
論文認為固定為 k 的通道數表明了網絡的全局狀態,而隨着 feature map 的逐步縮小,表示信息越來越集中了,越來越成為高級特徵了。
但是論文研究又發現L和k的增加會使得網絡表現更好,注意,k=8的結果會比k=32的結果要差幾個百分點,但是 k=32會讓網絡的顯存佔用超級大。
也可以使用 1*1 的卷積網絡,所以總的網絡就變成了 BN-ReLU-Conv(1*1)-BN-ReLU-Conv(3*3),輸出的通道數為 4k 能夠利用 1*1 卷積核先將通道數降低(畢竟 k 為32顯得有點小,實際項目還可能設置為 8)。
dense_block的代碼:
def dense_block(x,nb_layers,nb_filter,growth_rate,droput_rate=0.2,weight_decay=1e-4):
for i in range(nb_layers):
cb = conv_block(x,growth_rate,droput_rate,weight_decay)
x = concatenate([x,cb],axis=-1)
nb_filter +=growth_rate
return x ,nb_filter
4.4 問題3:參數過多
DenseNet不斷堆積卷積網絡,參數增長是很明顯的,所以一般使用卷積網絡壓縮輸入:The initial convolution layer comprises 2k convolutions of size 7*7 with stride 2;
對應的代碼為:
_nb_filter = 64
# conv 64 5*5 s=2
x = Conv2D(_nb_filter ,(5,5),strides=(2,2),kernel_initializer='he_normal', padding='same',
use_bias=False, kernel_regularizer=l2(_weight_decay))(input)
為了防止 dense block 將卷積通道數線性增加,使得後期通道數過多,transition layers 一般會對通道數進行縮減:to further improve model compactness, we can reduce the number of feature-maps at transition layers.
對應的代碼為:
# 64 + 8 * 8 = 128 x ,_nb_filter = dense_block(x,8,_nb_filter,8,None,_weight_decay) #128 x,_nb_filter = transition_block(x,128,_dropout_rate,2,_weight_decay) #128 + 8 * 8 = 192 x ,_nb_filter = dense_block(x,8,_nb_filter,8,None,_weight_decay) #192->128 x,_nb_filter = transition_block(x,128,_dropout_rate,2,_weight_decay) #128 + 8 * 8 = 192 x ,_nb_filter = dense_block(x,8,_nb_filter,8,None,_weight_decay)
可以看到 transition block 的通道數都是 128,實際上後一個 transition block 輸入的通道數為 192,進行了通道的縮減。
4.5 熱力圖分析
在設計初,DenseNet便被設計成讓一層網絡可以使用所有值錢層網絡 feature map 的網絡結構,為了探索 feature 的復用情況,作者進行了相關實驗,作者訓練的 L=40,K=12 的DenseNet,對於任意Dense Block中的所有卷積層,計算之前某層 feature map 在該層權重的絕對值平均數,這一平均數表明了這一層對於之前某一層 feature 的利用率,下圖為由該平均數繪製出的熱力圖:
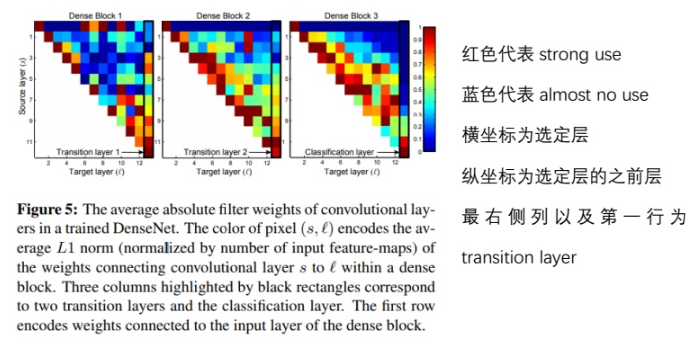
從圖中我們可以得出以下結論:
- 1,一些較早層提取出的特徵仍可能被較深層直接使用
- 2,即使是 Transition Layer也會使用到之前 DenseBlock中所有層的特徵
- 3,第2~3個DenseBlock中的層對之前Transition Layer利用率很低,說明 transition layer 輸出大量冗餘特徵,這也為DenseNet-BC提供了證據支持,即Compression的必要性
- 4,最後的分類層雖然使用了之前DenseBlock的多層信息,但是更偏向於使用最後幾個 feature map 的特徵,說明在網絡的最後幾層,某些 high-level 的特徵可能被產生。
5,Keras實現
訓練的話:對於沒有使用數據增強的數據集,在卷積層後使用了 dropout ,dropout的比例為 0.2。
DenseNet 的一個版本的Keras實現如下(如果想看其他版本,請去我的GitHub拿,地址在上面):
'''
this script is DenseNet model for Keras
link: //www.jianshu.com/p/274d050d517e
'''
from __future__ import print_function
from __future__ import absolute_import
from __future__ import division
from keras.models import Model, Sequential
from keras.layers import Flatten, Dense, Input, Conv2D, MaxPooling2D, BatchNormalization, Dropout
from keras.optimizers import Adam
from keras.layers import Input, Activation
from keras.layers.pooling import GlobalAveragePooling2D, AveragePooling2D, MaxPooling2D
from keras.regularizers import l2
from keras.layers import Concatenate, Add, add, concatenate
from keras.layers.normalization import BatchNormalization
import keras.backend as K
def conv_block(input_shape, nb_filter, bottleneck=False, dropout_rate=None, weight_decay=1e-4):
'''
Apply BatchNorm, Relu, 3*3 Conv2D, optional bottleneck block and dropout
Args:
input_shape: Input keras tensor
nb_filter: number of filters
bottleneck: add bottleneck block
dropout_rate: dropout rate
weight_decay: weight decay factor
returns: keras tensor with batch_norm, relu and convolution2d added (optional bottleneck)
'''
# 表示特徵軸,因為連接和BN都是對特徵軸來說
concat_axis = 1 if K.image_data_format() == 'channel_first' else -1
x = BatchNormalization(axis=concat_axis, epsilon=1.1e-5)(input_shape)
x = Activation('relu')(x)
# bottleneck 表示是否使用瓶頸層,也就是使用1*1的卷積層將特徵圖的通道數進行壓縮
if bottleneck:
inter_channel = nb_filter * 4
# He正態分佈初始化方法,參數由0均值,標準差為sqrt(2 / fan_in) 的正態分佈產生,其中fan_in權重張量的扇入
x = Conv2D(inter_channel, (1, 1), kernel_initializer='he_normal', padding='same',
use_bias=False, kernel_regularizer=l2(weight_decay))(x)
x = BatchNormalization(axis=concat_axis, epsilon=1.1e-5)(x)
x = Activation('relu')(x)
x = Conv2D(nb_filter, (3, 3), kernel_initializer='he_normal', padding='same',
use_bias=False)(x)
if dropout_rate:
x = Dropout(dropout_rate)(x)
return x
def transition_block(input_shape, nb_filter, compression=1.0, weight_decay=1e-4, is_max=False):
'''
過渡層是用來連接兩個 dense block,同時在最後一個dense block的尾部不需要使用過渡層
按照論文的說法:過渡層由四部分組成:
BatchNormalization ReLU 1*1Conv 2*2Maxpooling
Apply BatchNorm, ReLU , Conv2d, optional compression, dropout and Maxpooling2D
Args:
input_shape: keras tensor
nb_filter: number of filters
compression: caculated as 1-reduction, reduces the number of features maps in the transition block
(compression_rate 表示壓縮率,將通道數進行調整)
dropout_rate: dropout rate
weight_decay: weight decay factor
return :
keras tensor, after applying batch_norm, relu-conv, dropout maxpool
'''
# 表示特徵軸,因為連接和BN都是對特徵軸來說
concat_axis = 1 if K.image_data_format() == 'channel_first' else -1
x = BatchNormalization(axis=concat_axis, epsilon=1.1e-5)(input_shape)
x = Activation('relu')(x)
x = Conv2D(int(nb_filter * compression), (1, 1), kernel_initializer='he_normal',
padding='same', use_bias=False, kernel_regularizer=l2(weight_decay))(x)
# 論文提出使用均值池化層來做下採樣,不過在邊緣提取方面,最大池化層效果應該更好,可以加上接口
if is_max:
x = Maxpooling2D((2, 2), strides=(2, 2))(x)
else:
x = AveragePooling2D((2, 2), strides=(2, 2))(x)
return x
def dense_block(input_shape, nb_layers, nb_filter, growth_rate, bottleneck=False, dropout_rate=None,
weight_decay=1e-4, grow_nb_filters=True, return_concat_list=False):
'''
Bulid a dense_block where the output of each conv_block is fed to subsequent ones
此處使用循環實現了Dense Block 的密集連接
Args:
input_shape: keras tensor
nb_layers: the number of layers of conv_block to append to the model
nb_filter: number of filters
growth_rate: growth rate
weight_decay: weight decay factor
grow_nv_filters: flag to decode to allow number of filters to grow
return_concat_list: return the list of feature maps along with the actual output
returns:
keras tensor with nv_layers of conv_block append
其中 x=concatenate([x, cb], axis=concat_axis)操作使得x在每次循環中始終維護一個全局狀態
第一次循環輸入為 x, 輸出為 cb1,第二次輸入為 cb=[x,cb1],輸出為cb2,第三次輸入為cb=[x,cb1,cb2],輸出為cb3
以此類推,增長率為growth_rate 其實就是每次卷積時使用的卷積核個數,也就是最後輸出的通道數。
'''
concat_axis = 1 if K.image_data_format() == 'channel_first' else -1
x_list = [input_shape]
for i in range(nb_layers):
cb = conv_block(input_shape, growth_rate, bottleneck, dropout_rate, weight_decay)
x_list.append(cb)
x = concatenate([input_shape, cb], axis=concat_axis)
if grow_nb_filters:
nb_filter += growth_rate
if return_concat_list:
return x, nb_filter, x_list
else:
return x, nb_filter
def DenseNet_model(input_shape, classes, depth=40, nb_dense_block=3, growth_rate=12, include_top=True,
nb_filter=-1, nb_layers_per_block=[6, 12, 32, 32], bottleneck=False, reduction=0.0, dropout_rate=None,
weight_decay=1e-4, subsample_initial_block=False, activation='softmax'):
'''
Build the DenseNet model
Args:
classes: number of classes
input_shape: tuple of shape (channels, rows, columns) or (rows, columns, channels)
include_top: flag to include the final Dense layer
depth: number or layers
nb_dense_block: number of dense blocks to add to end (generally = 3)
growth_rate: number of filters to add per dense block
nb_filter: initial number of filters. Default -1 indicates initial number of filters is 2 * growth_rate
nb_layers_per_block: number of layers in each dense block.
Can be a -1, positive integer or a list.
If -1, calculates nb_layer_per_block from the depth of the network.
If positive integer, a set number of layers per dense block.
If list, nb_layer is used as provided. Note that list size must
be (nb_dense_block + 1)
bottleneck: add bottleneck blocks
reduction: reduction factor of transition blocks. Note : reduction value is inverted to compute compression
dropout_rate: dropout rate
weight_decay: weight decay rate
subsample_initial_block: Set to True to subsample the initial convolution and
add a MaxPool2D before the dense blocks are added.
subsample_initial:
activation: Type of activation at the top layer. Can be one of 'softmax' or 'sigmoid'.
Note that if sigmoid is used, classes must be 1.
Returns: keras tensor with nb_layers of conv_block appended
'''
concat_axis = 1 if K.image_data_format() == 'channel_first' else -1
if type(nb_layers_per_block) is not list:
print('nb_layers_per_block should be a list !!!')
return 0
final_nb_layer = nb_layers_per_block[-1]
nb_layers = nb_layers_per_block[:-1]
# compute initial nb_filter if -1 else accept users initial nb_filter
if nb_filter <= 0:
nb_filter = 2 * growth_rate
# compute compression factor
compression = 1.0 - reduction
# initial convolution
if subsample_initial_block:
initial_kernel = (7, 7)
initial_strides = (2, 2)
else:
initial_kernel = (3, 3)
initial_strides = (1, 1)
Inp = Input(shape=input_shape)
x =Conv2D(nb_filter, initial_kernel, kernel_initializer='he_normal', padding='same',
strides=initial_strides, use_bias=False, kernel_regularizer=l2(weight_decay))(Inp)
if subsample_initial_block:
x = BatchNormalization(axis=concat_axis, epsilon=1.1e-5)(x)
x = Activation('relu')(x)
x = Maxpooling2D((3, 3), strides=(2, 2), padding='same')(x)
# add dense blocks
for block_index in range(nb_dense_block-1):
x, nb_filter = dense_block(x, nb_layers[block_index], nb_filter, growth_rate,
bottleneck=bottleneck, dropout_rate=dropout_rate, weight_decay=weight_decay)
# add transition block
x = transition_block(x, nb_filter, compression=compression, weight_decay=weight_decay)
nb_filter = int(nb_filter * compression)
# the last dense block does not have a transition_block
x, nb_filter = dense_block(x, final_nb_layer, nb_filter, growth_rate, bottleneck=bottleneck,
dropout_rate=dropout_rate, weight_decay=weight_decay)
x = BatchNormalization(axis=concat_axis, epsilon=1.1e-5)(x)
x = Activation('relu')(x)
x = GlobalAveragePooling2D()(x)
if include_top:
x = Dense(classes, activation=activation)(x)
model = Model(Inp, output=x)
model.summary()
return model
if __name__ == '__main__':
DenseNet_model(input_shape=(227, 227, 3), classes=1000, bottleneck=True,
reduction=0.5)
Keras實現地址://github.com/titu1994/DenseNet
//github.com/flyyufelix/DenseNet-Keras
實現://blog.csdn.net/shi2xian2wei2/article/details/84425777
參考文獻://www.cnblogs.com/skyfsm/p/8451834.html
//www.cnblogs.com/zhhfan/p/10187634.html
//blog.csdn.net/Gentleman_Qin/article/details/84638700
包含了pytorch 的實現://zhuanlan.zhihu.com/p/37189203
//blog.csdn.net/u014380165/article/details/75142664

