騰訊看點視頻推薦索引構建方案
- 2020 年 12 月 1 日
- 筆記
一、背景
在視頻推薦場景中,一方面我們需要讓新啟用的視頻儘可能快的觸達用戶,這一點對於新聞類的內容尤為關鍵;另一方面我們需要快速識別新物品的好壞,通過分發的流量,以及對應的後驗數據,來判斷新物品是否值得繼續分發流量。
而這兩點對於索引先驗數據和後驗數據的延遲都有很高的要求。下文將為大家介紹看點視頻推薦的索引構建方案,希望和大家一同交流。文章作者:紀文忠,騰訊QQ端推薦研發工程師。
註:這裡我們把視頻創建時就帶有的數據稱為先驗數據,如tag,作者賬號id等,而把用戶行為反饋的數據稱為後驗數據,如曝光、點擊、播放等。
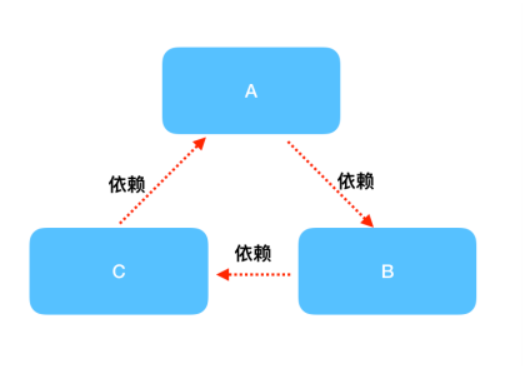
二、看點視頻推薦整體架構

從數據鏈路來看此架構圖,從下往上來看,首先視頻內容由內容中心通過消息隊列給到我們,經過一定的處理入庫、建索引、生成正排/倒排數據,這時候在存儲層可召回的內容約有1千萬條。
然後經過召回層,通過用戶畫像、點擊歷史等特徵召回出數千條視頻,給到粗排層;粗排將這數千條視頻打分,取數百條給到精排層;精排再一次打分,給到重排;重排根據一定規則和策略進行打散和干預,最終取10+條給到用戶;
視頻在用戶側曝光後,從上之下,是另一條數據鏈路:用戶對視頻的行為,如曝光、點擊、播放、點贊、評論等經過上報至日誌服務,然後通過實時/離線處理產生特徵回到存儲層,由此形成一個循環。
基於此架構,我們需要設計一套召回/倒排索引,能夠以實時/近實時的延遲來處理所有數據。
三、方案設計
在舊方案中,索引是每半小時定時構建的,無法滿足近實時的要求。在分析這個索引構建的方案時,我們遇到的主要挑戰有:
-
數據雖不要求強一致性,但需要保證最終一致性;
-
後驗數據寫入量極大,看點用戶行為每日達到百億+;
-
召回系統要求高並發、低延遲、高可用。
1. 業界主流方案調研

通過對比業界主流方案,我們可以看到,基於Redis的方案靈活性較差,直接使用比較困難,需要進行較多定製化開發,可以首先排除。
因此我們可選擇的方案主要在自研或者選擇開源成熟方案。經過研究,我們發現如果自研索引開發成本較高,而簡單的自研方案可能無法滿足業務需求,完善的自研索引方案所需要的開發成本往往較高,往往需要多人的團隊來開發維護,最終我們選擇了基於ES的索引服務。
至於為什麼選擇基於ES,而不是選擇基於Solr,主要是因為ES有更成熟的社區,以及有騰訊雲PaaS服務支持,使用起來更加靈活方便。
2. 數據鏈路圖
(1)方案介紹
如下圖所示:

這個方案從數據鏈路上分為兩大塊。
第一塊,先驗數據鏈路,就是上半部分,我們的數據源主要來自內容中心,通過解析服務寫入到CDB中。其中這個鏈路又分為全量鏈路和增量鏈路。
全量鏈路主要是在重建索引時才需要的,觸發次數少但也重要。它從DB這裡dump數據,寫入kafka,然後通過寫入服務寫入ES。
增量鏈路是確保其實時性的鏈路,通過監聽binlog,發送消息至kafka,寫入服務消費kafka然後寫入ES。
第二塊,是後驗數據鏈路。看點的用戶行為流水每天有上百億,這個量級直接打入ES是絕對扛不住的。所以我們需要對此進行聚合計算。
這裡使用Flink做了1分鐘滾動窗口的聚合,然後把結果輸出到寫模塊,得到1分鐘增量的後驗數據。在這裡,Redis存儲近7天的後驗數據,寫模塊消費到增量數據後,需要讀出當天的數據,並於增量數據累加後寫回Redis,並發送對應的rowkey和後驗數據消息給到Kafka,再經由ES寫入服務消費、寫入ES索引。
(2)一致性問題分析
這個數據鏈路存在3個一致性問題需要小心處理:
第一,Redis寫模塊這裡,需要先讀出數據,累加之後再寫入。先讀後寫,需要保證原子性,而這裡可能存在同時有其他線程在同一時間寫入,造成數據不一致。
解決方案1是通過redis加鎖來完成;解決方案2如下圖所示,在kafka隊列中,使用rowkey作為分區key,確保同一rowkey分配至同一分區,而同一隻能由同一消費者消費,也就是同一rowkey由一個進程處理,再接着以rowkey作為分線程key,使用hash算法分線程,這樣同一rowkey就在同一線程內處理,因此解決了此處的一致性問題。另外,通過這種方案,同一流內的一致性問題都可以解決。

第二,還是Redis寫模塊這裡,我們知道Redis寫入是需要先消費kafka的消息的,那麼這裡就要求kafka消息commit和redis寫入需要在一個事務內完成,或者說需要保證原子性。
如果這裡先commit再進行redis寫入,那麼如果系統在commit完且寫入redis前宕機了,那麼這條消息將丟失掉;如果先寫入,在commit,那麼這裡就可能會重複消費。
如何解決這個一致性問題呢?我們通過先寫入redis,並且寫入的信息裡帶上時間戳作為版本號,然後再commit消息;寫入前會比較消息版本號和redis的版本號,若小於,則直接丟棄;這樣這個問題也解決了。
第三,我們觀察到寫入ES有3個獨立的進程寫入,不同流寫入同一個索引也會引入一致性問題。這裡我們可以分析出,主要是先驗數據的寫入可能會存在一致性問題,因為後驗數據寫入的是不同字段,而且只有update操作,不會刪除或者插入。
舉一個例子,上游的MySQL這裡刪除一條數據,全量鏈路和增量鏈路同時執行,而剛好全量Dump時剛好取到這條數據,隨後binlog寫入delete記錄,那麼ES寫入模塊分別會消費到插入和寫入兩條消息,而他自己無法區分先後順序,最終可能導致先刪除後插入,而DB里這條消息是已刪除的,這就造成了不一致。
那麼這裡如何解決該問題呢?其實分析到問題之後就比較好辦,常用的辦法就是利用Kfaka的回溯能力:在Dump全量數據前記錄下當前時間戳t1,Dump完成之後,將增量鏈路回溯至t1即可。而這段可能不一致的時間窗口,也就是1分鐘左右,業務上是完全可以忍受的。
線上0停機高可用的在線索引升級流程如下圖所示:

(3)寫入平滑
由於Flink聚合後的數據有很大的毛刺,導入寫入ES時服務不穩定,cpu和rt都有較大毛刺,寫入情況如下圖所示:

此處監控間隔是10秒,可以看到,由於聚合窗口是1min,每分鐘前10秒寫入達到峰值,後面逐漸減少,然後新的一分鐘開始時又周期性重複這種情況。
對此我們需要研究出合適的平滑寫入方案,這裡直接使用固定閾值來平滑寫入不合適,因為業務不同時間寫入量不同,無法給出固定閾值。
最終我們使用以下方案來平滑寫入:

我們使用自適應的限流器來平滑寫,通過統計前1分鐘接收的消息總量,來計算當前每秒可發送的消息總量。具體實現如下圖所示,將該模塊拆分為讀線程和寫線程,讀線程統計接收消息數,並把消息存入隊列;令牌桶數據每秒更新;寫線程獲取令牌桶,獲取不到則等待,獲取到了就寫入。最終我們平滑寫入後的效果如圖所示:



在不同時間段,均能達到平滑的效果。
四、召回性能調優
1. 高並發場景優化
由於存在多路召回,所以召回系統有讀放大的問題,我們ES相關的召回,總qps是50W。這麼大的請求量如果直接打入ES,一定是扛不住的,那麼如何來進行優化呢?
由於大量請求的參數是相同的,並且存在大量的熱門key,因此我們引入了多級緩存來提高召回的吞吐量和延遲時間。
我們多級緩存方案如下圖所示:

這個方案架構清晰,簡單明了,整個鏈路: 本地緩存(BigCache)<->分佈式緩存(Redis)<->ES。
經過計算,整體緩存命中率為95+%,其中本地緩存命中率75+%,分佈式緩存命中率20%,打入ES的請求量大約為5%。這就大大提高了召回的吞吐量並降低了RT。
該方案還考慮緩了存穿透和雪崩的問題,在線上上線之後,不久就發生了一次雪崩,ES全部請求失敗,並且緩存全部未命中。起初我們還在分析,究竟是緩存失效導致ES失敗,還是ES失敗導致設置請求失效,實際上這就是經典的緩存雪崩的問題。
我們分析一下,這個方案解決了4點問題:
-
本地緩存定時dump到磁盤中,服務重啟時將磁盤中的緩存文件加載至本地緩存。
-
巧妙設計緩存Value,包含請求結果和過期時間,由業務自行判斷是否過期;當下游請求失敗時,直接延長過期時間,並將老結果返回上游。
-
熱點key失效後,請求下遊資源前進行加鎖,限制單key並發請求量,保護下游不會被瞬間流量打崩。
-
最後使用限流器兜底,如果系統整體超時或者失敗率增加,會觸發限流器限制總請求量。
2. ES性能調優
(1)設置合理的primary_shards
primary_shards即主分片數,是ES索引拆分的分片數,對應底層Lucene的索引數。這個值越大,單請求的並發度就越高,但給到上層MergeResult的數量也會增加,因此這個數字不是越大越好。
根據我們的經驗結合官方建議,通常單個shard為1~50G比較合理,由於整個索引大小10G,我們計算出合理取值範圍為1~10個,接下里我們通過壓測來取最合適業務的值。壓測結果如下圖所示:


根據壓測數據,我們選擇6作為主分片數,此時es的平均rt13ms,99分位的rt為39ms。
(2)請求結果過濾不需要的字段
ES返回結果都是json,而且默認會帶上source和_id,_version等字段,我們把不必要的正排字段過濾掉,再使用filter_path把其他不需要的字段過濾掉,這樣總共能減少80%的包大小,過濾結果如下圖所示:

包大小由26k減小到5k,帶來的收益是提升了30%的吞吐性能和降低3ms左右的rt。
(3)設置合理routing字段
ES支持使用routing字段來對索引進行路由,即在建立索引時,可以將制定字段作為路由依據,通過哈希算法直接算出其對應的分片位置。
這樣查詢時也可以根據指定字段來路由,到指定的分片查詢而不需要到所有分片查詢。根據業務特點,我們將作者賬號id puin 作為路由字段,路由過程如下圖所示:

這樣一來,我們對帶有作者賬號id的召回的查詢吞吐量可以提高6倍,整體來看,給ES帶來了30%的吞吐性能提升。
(4)關閉不需要索引或排序的字段
通過索引模板,我們將可以將不需要索引的字段指定為”index”:false,將不需要排序的字段指定為”doc_values”:false。這裡經測試,給ES整體帶來了10%左右的吞吐性能提升。
五、結語
本文介紹了看點視頻推薦索引的構建方案,服務於看點視頻的CB類型召回。其特點是,開發成本低,使用靈活方便,功能豐富,性能較高,符合線上要求。
上線以來服務於關注召回、冷啟動召回、tag畫像召回、賬號畫像召回等許多路召回,為看點視頻帶來較大業務增長。未來隨着業務進一步增長,我們會進一步優化該方案,目前來看,該技術方案還領先於業務一段時間。最後歡迎各位同學交流,歡迎在評論區留言。