集群、限流、緩存 BAT 大廠無非也就是這麼做
- 2019 年 10 月 3 日
- 筆記

前言
前陣子有網友詢問,如何優化網站?這個問題真的很大,跟他簡單的聊了一下,隨便說了幾點,覺得有必要整理一篇文章出來,正好前陣子在做爬蟲博客,於是把大體思路分享出來,與大家互通有無,共同進步。
優化
版本一
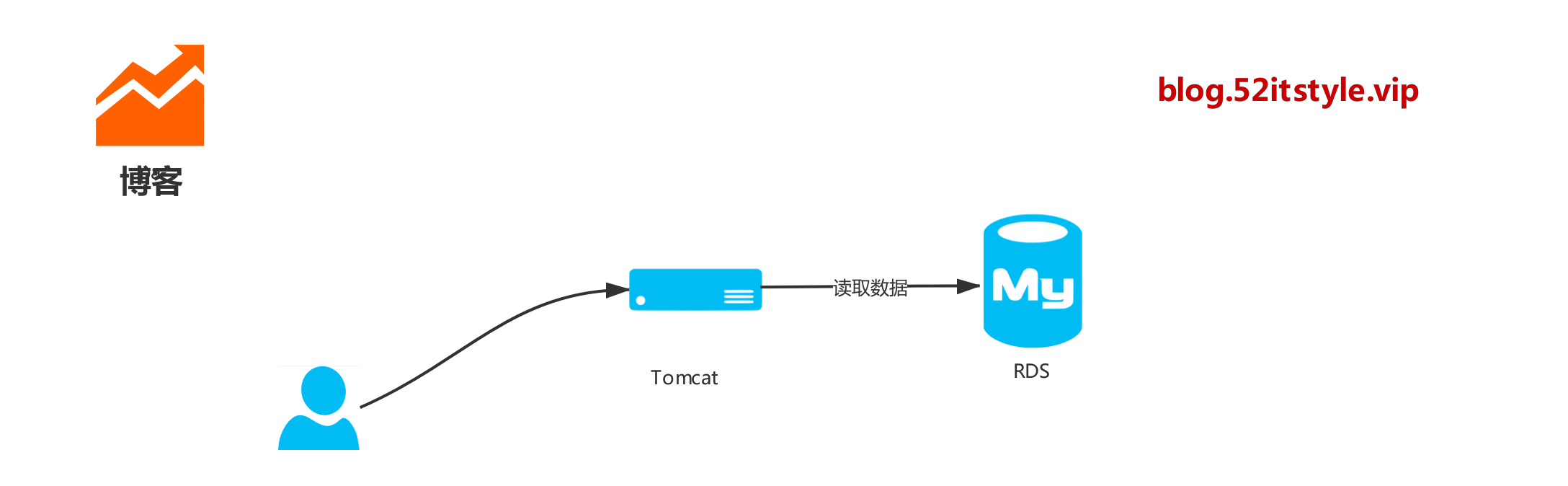
系統開始是這樣子的,一個 Tomcat 拖着一個 MySql 服務,跑在一個 2C 4G 的Linux服務器上,所有的請求都走 Tomcat,所有的查詢都走 MySql,看起來像一句廢話?
資源是有限的,那麼如何有效的利用資源,提升服務性能?Tomcat 號稱能抗住數十萬並發訪問,但是這事也得分場景,還得有足夠牛逼的機器。
Tomcat 優化
Tomcat支持以下三種模式:
-
BIO:一個線程處理一個請求,缺點:並發量高時,線程數較多,浪費資源,Tomcat7或以下在Linux系統中默認使用這種方式。
- NIO:利用Java的異步IO處理,可以通過少量的線程處理大量的請求。Tomcat8在Linux系統中默認使用這種方式。Tomcat7 必須修改Connector配置來啟(conf/server.xml配置文件):
<Connector port="8080" protocol="org.apache.coyote.http11.Http11NioProtocol" connectionTimeout="20000" redirectPort="8443"/>- APR(Apache Portable Runtime):從操作系統層面解決io阻塞問題。Linux如果安裝了apr和native,Tomcat直接啟動就支持apr。
為了方便易用這裡我們選擇NIO模式,小夥伴們直接下載使用 Tomcat8 以上版本即可,連接池什麼的一般使用默認的即可。
版本二

可能部分小夥伴知道 Tomcat 容器處理靜態請求的性能力並不強,所以這裡需要一款能處理靜態文件請求又超牛逼的服務,這裡推薦 Nginx,當然你可以使用其變種 Tengine、OpenResty 才實現動靜分離。
版本三
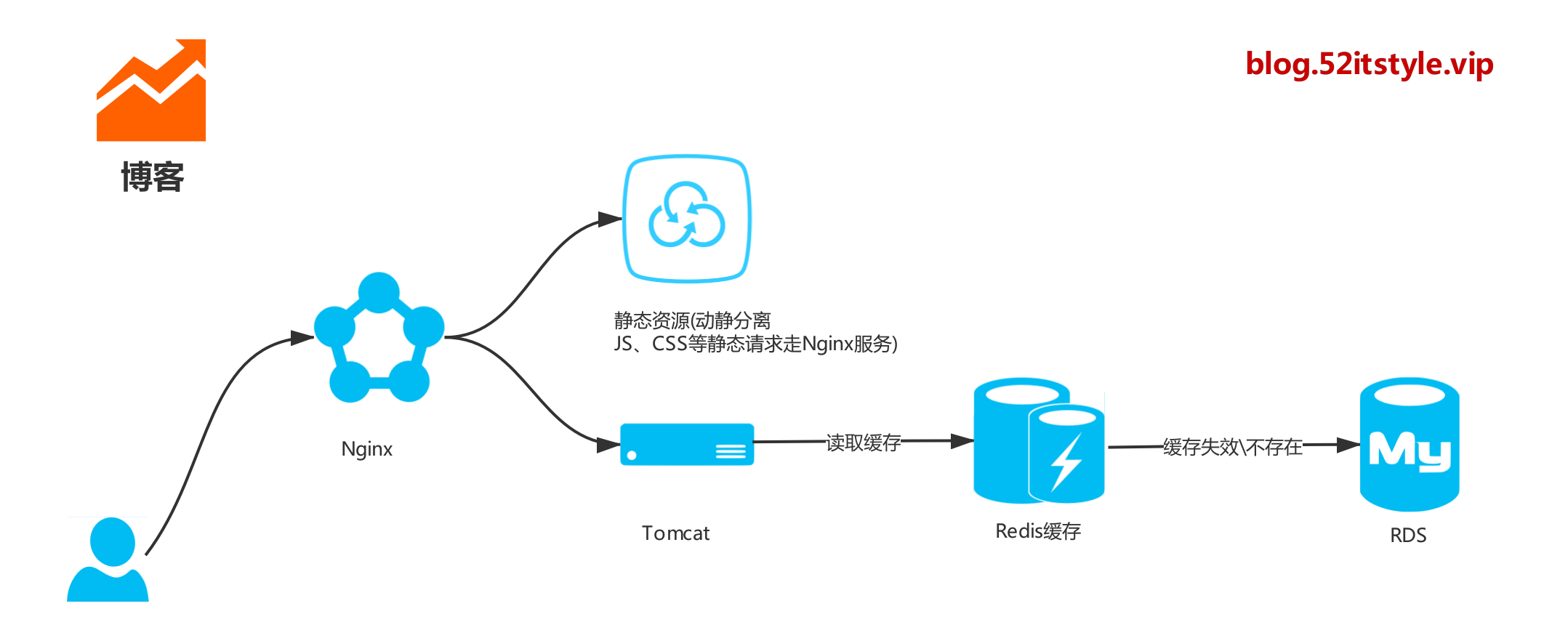
後端服務鏈接資源是寶貴的,在高並發下,會拖慢整個系統的響應時間。這裡我們可以把一些熱點數據進行緩存,後端讀取緩存,如果數據存在則直接返回,否則再去讀取數據庫。
版本四

資源是有限的,但用戶可能是無限的,還可能有一些惡意用戶、爬蟲、熱點搜索。為了大部門用戶可以正常訪問,這裡我們使用前置限流,通過令牌桶算法或者漏桶算法實現多樣的限流方案。
版本五
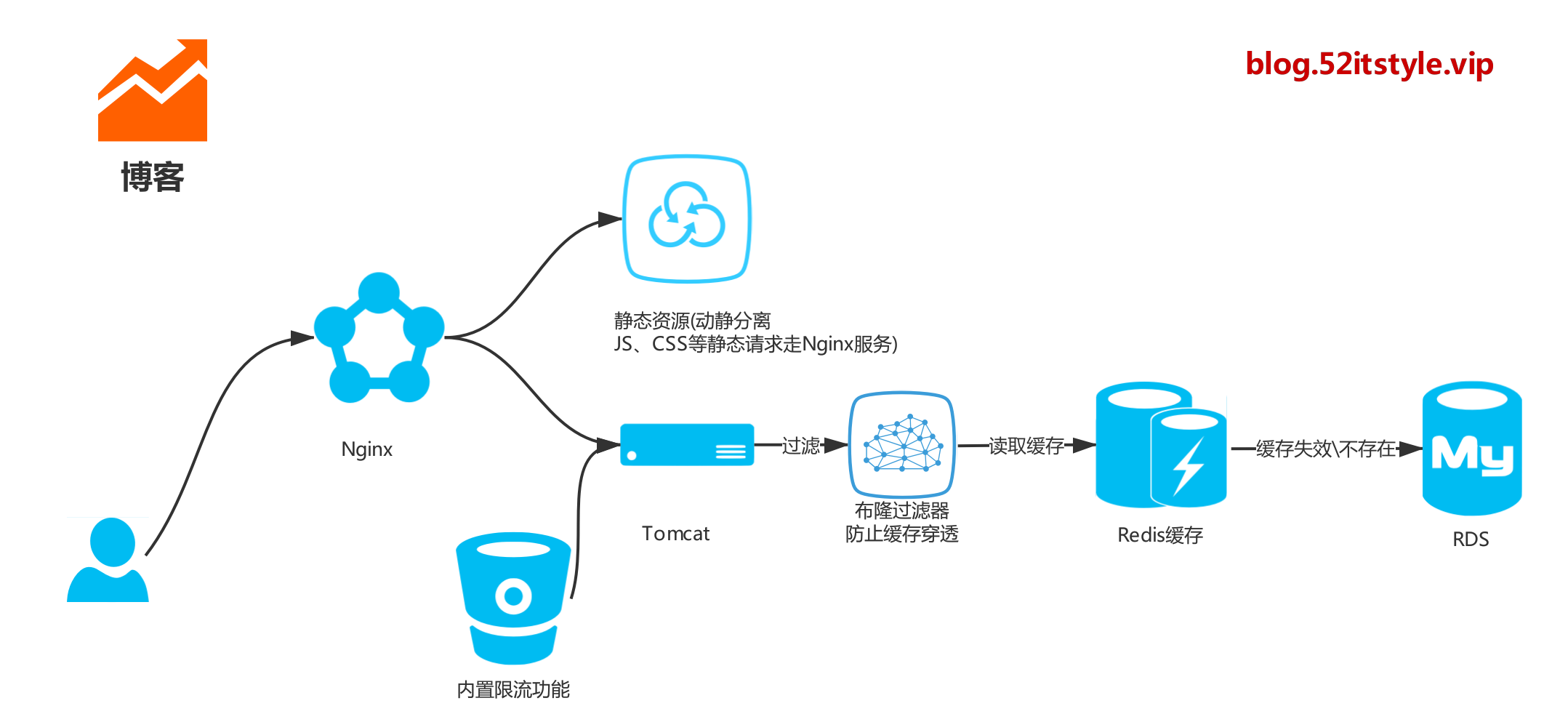
在博客系統中,為了提升響應速度,加入了 Redis 緩存,把文章主鍵 ID 作為 key 值去緩存查詢,如果不存在對應的 value,就去數據庫中查找 。這個時候,如果請求的並發量很大,就會對後端的數據庫服務造成很大的壓力。這裡我們使用布隆過濾器對空命中進行攔截處理。
終極版

-
如果僅僅對於一個博客而已一個Nginx 足夠了,後面可以帶多個Tomcat 做負載均衡進群
-
Nginx 應用層面做限流,後端單個服務可以做接口限流
-
後端服務用戶 Session 可以集中存儲到 Redis 中
-
布隆過濾攔截防止緩存穿透
-
熱點數據讀取 Redis 緩存
-
如有必要 Redis 、MySql 可以做主從集群
小結
優化過程可能僅僅是冰山一角,但大體思路差不多就是這個樣子,發現問題然後解決問題,本來架構就是演進而來的。
參考
很多小夥伴問作圖工具是什麼 ? 點這裡:https://www.processon.com/i/58c8a5c7e4b06344137ffc14
